
© Robert Kacpura, 123RF.com
Web-basierte Entwicklerwerkzeuge wie Bugzilla oder Github bieten ein Web-API, über das man sie mit eigenen Skripten abfragen und in bestimmten Grenzen auch fernsteuern kann.
Entwickler hantieren nicht nur mit Editor und Compiler, sondern auch mit zahlreichen Hilfswerkzeugen. Bei diesen handelt es sich häufig um Webanwendungen oder Webdienste – von Repositories wie Github [1] bis zu Bugtracking-Systemen wie Bugzilla [2].
Die Bedienung erfolgt über den Browser, was nur vordergründig bequem ist: Wer nur eine kurze Information benötigt, muss erst die Seiten des Dienstes ansteuern, sich einloggen und dann ein paar mehr oder weniger verschachtelte Menüpunkte durchklicken. Wiederkehrende Aufgaben lassen sich zudem nur selten automatisieren.
Glücklicherweise bieten praktisch alle großen Web-basierten Werkzeuge eine Programmierschnittstelle an. Sie nutzt im Regelfall das bewährte HTTP-Protokoll. Das hat wiederum den Vorteil, dass sich der Dienst von Skriptsprachen und anderen Webanwendungen aus ansprechen und fernsteuern lässt.
Hausnummer
Die meisten Dienste und Webanwendungen spendieren zunächst jedem Termin, jedem Projekt, jedem Bugreport, also jedem einzelnen Objekt eine eigene Webadresse. So ist beispielsweise auf Github der Bugreport (»Issue« ) Nummer »624« im Repository »jekyll« des Benutzers »mojombo« unter der Adresse »https://api.github.com/repos/mojombo/jekyll/issues/624« zu erreichen. Wer diese URL einfach mit einem Browser ansteuert, erhält von Github das entsprechende Objekt zurück. Im Beispiel sind das alle verfügbaren Informationen über Bug 624 (Abbildung 1). Statt per Browser kann der Anwender die URL auch mit dem Kommandozeilen-Client Curl aufrufen:
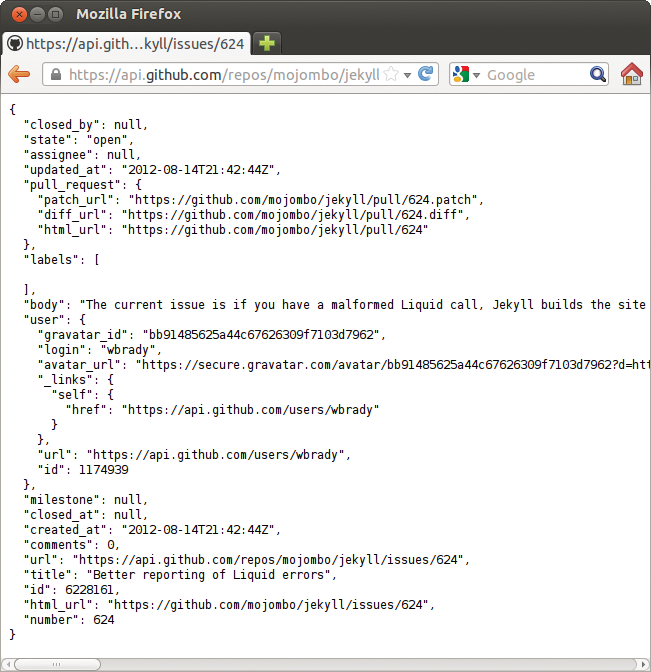
Abbildung 1: Informationen über einen bestimmten Bug stellt Github unter einer eindeutigen Webadresse bereit.
curl -i "https://api.github.com/repos/mojombo/jekyll/issues/624"
Komfortabler geht das aber mit Hilfe einer Programmiersprache. Listing 1 zeigt exemplarisch den Zugriff aus Python 2.7. Es verwendet »urllib2« aus der Standardbibliothek [3] und ist einfach zu lesen: Zunächst bastelt es eine Anfrage an Github und schickt diese dann mit »urllib2.urlopen()« ab. Die vom Server zurückgelieferte Antwort landet in der gleichnamigen Variablen. Aus ihr extrahiert schließlich »antwort.read()« alle zum Bugreport gehörenden Informationen, die wiederum die Variable »inhalt« aufnimmt.
Listing 1
Zugriff mit urllib2
01 import urllib2
02 request = urllib2.Request('https://api.github.com/repos/mojombo/jekyll/issues/624', data='')
03 request.get_method = lambda: 'GET'
04 antwort = urllib2.urlopen(request)
05 inhalt = antwort.read()
06 print inhalt
Python 3 splittet das »urllib2« -Modul in die beiden Nachfolger »urllib.request« und »urllib.error« . Alternativ zur »urllib2« kann man auch »httplib« (in Python 3 »http.client« ) verwenden [4], den entsprechenden Code zeigt Listing 2. Dabei ist aber zu beachten, dass Github nicht HTTP, sondern die verschlüsselte Variante HTTPS nutzt. Python muss daher mit SSL-Unterstützung übersetzt sein, was bei allen großen Distributionen der Fall sein sollte.
Listing 2
Zugriff mit httplib
01 import httplib
02
03 connection = httplib.HTTPSConnection('api.github.com')
04 connection.request('GET', 'https://api.github.com/repos/mojombo/jekyll/issues/624', '')
05 antwort = connection.getresponse()
06
07 inhalt = antwort.read()
08 print inhalt
Allerdings prüfen »urllib2« und »httplib« nicht das vom Server zurückgesendete Zertifikat. Der Anwender kann sich folglich nicht sicher sein, ob er tatsächlich mit einem Github-Server oder mit einem Schwindler kommuniziert.
Github liefert alle Daten in der Javascript Object Notation (Json) aus. Die Informationen lassen sich somit leicht weiterverarbeiten, denn für viele Sprachen existieren passende Bibliotheken. Unter Python heißt das Modul »json« und gehört seit Version 2.6 zur Standardbibliothek [5]. Listing 3 zeigt, wie der Programmierer damit die Serverantwort in ein Python-Objekt umwandelt.
Listing 3
Rückgabe als Python-Objekt
01 import json 02 import urllib2 03 04 [...] 05 06 inhalt = antwort.read() 07 08 #Wandle inhalt in Objekt um: 09 githubissue = json.loads(inhalt) 10 print githubissue
Die Anfragen an Github lassen sich über angehängte Parameter weiter konkretisieren. Beispielsweise liefert
curl -i "https://api.github.com/repos/mojombo/jekyll/issues?state=close"
alle geschlossenen Bugreports (»Issues« ) aus dem Repository »jekyll« des Benutzers »mojombo« zurück. Sollten es mehr als 30 sein, verteilt sie Github auf mehrere Seiten. Eine Seite lässt sich mit dem Parameter »?page=« abrufen:
curl -i "https://api.github.com/repos/mojombo/jekyll/issues?state=close?page=2"
Ob es weitere Seiten gibt und unter welchen URLs diese erreichbar sind, schreibt Github mit in seine Antwort. Diese teilt sich gemäß HTTP-Standard in einen Kopfbereich (Header) und einen Rumpf mit den Nutzdaten (Body). In Python liefert in Listing 1 die Zeile »inhalt = antwort.read()« den Rumpf. An die Informationen im Header gelangt der Programmierer hiermit:
antwort.headers.getheader('name')
Dabei steht »name« für die gesuchte Zusatzinformation. Die Angaben zur Seitenzahl legt Github im Header unter der Bezeichnung »Link« ab. Wie man damit in Python die Seitenzahl ermittelt, zeigt Listing 4. Sollten weitere Seiten vorhanden sein, liefert Github wie in Abbildung 2 entsprechende URLs zurück. Die erste verweist dabei auf die nächste Seite (»next« ), die folgende URL auf die letzte (»last« ). Zudem gibt es noch Links zur ersten Seite (»first« ) und zur vorherigen (»prev« ).
Listing 4
Auslesen des Link im Header
01 import urllib2
02 request = urllib2.Request('https://api.github.com/repos/mojombo/jekyll/issues', data='')
03 request.get_method = lambda: 'GET'
04 antwort = urllib2.urlopen(request)
05 seiten = antwort.headers.getheader('Link')
06 if seiten != 'None' :
07 print 'Es gibt weiteref Seiten: ' + seiten
08 else :
09 print 'Es gibt keine weiteren Seiten.'
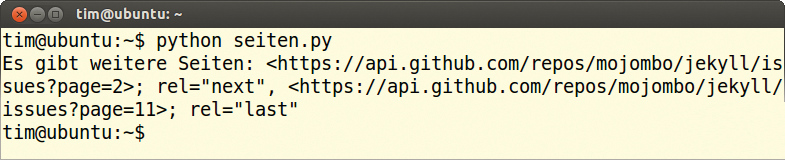
Abbildung 2: Informationen zur Paginierung stehen im Header. In diesem Fall verteilt Github alle Issues des Projekts auf insgesamt 11 Seiten.
In ihrer Anfrage schicken der Browser, Curl oder Python nicht nur die URL an den Server, sondern im Header noch ein paar weitere Angaben. Darunter befindet sich auch immer der Name einer Aktion, die Github ausführen soll. In Listing 1 möchte Python das Issue mit der Adresse »https://api.github.com/repos/mojombo/jekyll/issues/624« abholen. Die entsprechende Aktion dazu heißt »GET« .
Methodik
Neben »GET« gibt der HTTP-Standard noch weitere dieser so genannten Methoden oder Verben vor. Dazu zählt »DELETE« , das die Ressource »/repos/mojombo/jekyll/issues/624« und somit das Issue löschen würde. Diese Methode gehörte schon zur ersten Version von HTTP, im Internet ignorieren sie jedoch die meisten Webserver.
Welche der im HTTP-Standard verzeichneten Methoden tatsächlich welche Aktion auslösen, hängt vom jeweiligen Dienst beziehungsweise der Webanwendung ab. Um in Github ein neues Issue dem Repository »test« hinzuzufügen, das der Benutzer »hans« betreut, müsste ein Python-Programmierer nur einen entsprechenden Request zusammenbauen und die »POST« -Methode wählen:
request = urllib2.Request("https://api.github.com/repos/hans/test/issues")
request.get_method = lambda: 'POST'
Hier fehlt noch ein beschreibender Text für das Issue. Diesen erwartet Github im Body der empfangenen Nachricht im Json-Format:
issue = '{"title": "Bug", "body":"Bug gefunden." }'
antwort = urllib2.urlopen(req, issue)
Das Issue besitzt einen Titel, der Pflicht ist, sowie einen optionalen »body« , in dem der Anwender den Bug näher erläutern kann. Als Antwort auf die obige Anfrage liefert Github jedoch einen »404 not found« -Fehler – selbst wenn »hans« und sein »test« -Repository existieren.
Wer darf das?
Der Grund ist einfach: Damit Witzbolde nicht massenhaft Issues mit Werbebotschaften einreichen, verlangt Github bei bestimmten Aktionen eine Authentifizierung. Wie viele andere Webanwendungen verwendet der Dienst dabei das Oauth2-Verfahren [6]. In der einfachsten Variante fordert der Benutzer dabei mit seinem Usernamen und Passwort bei Github ein Token an, das er dann jeder weiteren Anfrage beifügt.
Wie das unter Python funktioniert, zeigt Listing 5. Zunächst kodiert es den Benutzernamen (»hans« ) und das Passwort (»geheim« ) als Base64. Mit dem Ergebnis stellt es eine Anfrage an Github zusammen. In den Header der Anfrage kommen Benutzername und Passwort (Zeile 8). Der Body enthält ein Json-Objekt mit einer kurzen Notiz sowie dem Bereich, für den Zutritt gewünscht ist – in diesem Fall das Repository (»repo« ).
Listing 5
Issue anlegen mit Token
01 import urllib2
02 import json
03 import base64
04
05 # Token anfordern:
06 base64string = base64.encodestring('hans:geheim').replace('\n', '')
07 request = urllib2.Request("https://api.github.com/authorizations")
08 request.add_header("Authorization", "Basic %s" % base64string)
09
10 result = urllib2.urlopen(request, '{"note": "Access to your repository.", "scopes": ["repo"]}')
11 result = json.loads('\n'.join(result.readlines()))
12 token = result['token']
13
14 # Issue einfuegen:
15 issue = '{"title": "Bug", "body": "Ich habe da einen Bug gefunden." }'
16
17 request = urllib2.Request("https://api.github.com/repos/timschuermann/test/issues")
18 request.add_header("Authorization", "token %s" % token)
19 request.get_method = lambda: 'POST'
20 antwort = urllib2.urlopen(request, issue)
21
22 #Rueckmeldung ausgeben:
23 print antwort.getcode()
24 print antwort.headers.getheader('content-type')
25 print antwort.read()
Das Ergebnis dieser Anfrage ist schließlich das Token, verpackt im Json-Format. Die Zeilen 11 und 12 lösen das Token heraus. Die nächsten Zeilen setzen dann wie gezeigt die Anfrage zum Anlegen eines Issue zusammen. Die Methode »add_header()« in Zeile 18 baut das Token in den Header der Anfrage ein. Damit landet das Issue erfolgreich in Github (Abbildungen 3 und 4).
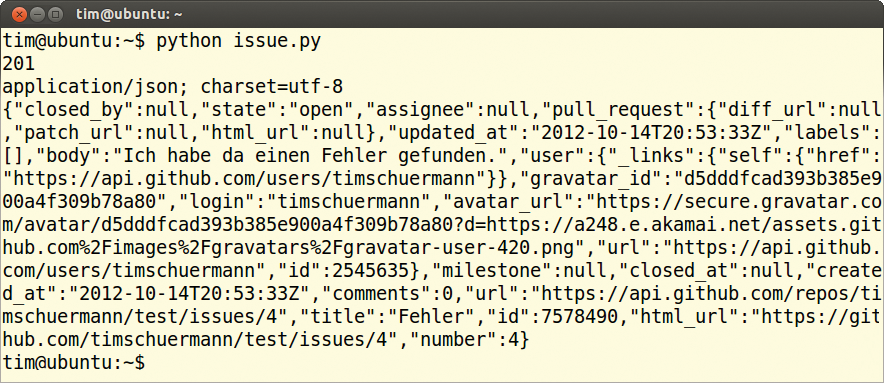
Abbildung 3: Das von Python abgeschickte Issue …
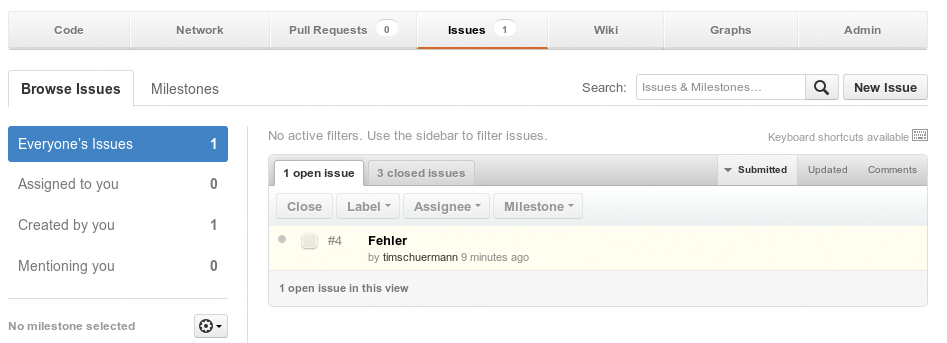
Abbildung 4: … landet auch in Github.
Falls bei der Verarbeitung ein Fehler auftritt, schickt Github eine Antwort zurück, die im Body die Fehlermeldung im Json-Format enthält, beispielsweise:
{"message":"Problems parsing JSON"}
Aus diesem Grund sollte der Programmierer die Antwort – wie in Listing 5 gezeigt – noch auswerten. Die Methode »getcode()« ermittelt dabei den Statuscode. Nach dem gleichen Prinzip lassen sich auch Repositories, Kommentare und alle übrigen Github-Objekte anlegen, manipulieren und löschen. Welche HTTP-Methode mit welcher URL welche Aktion auslöst, verraten die Github-Developer-Seiten [7].
Listing 5 braucht mit der »urllib2« ziemlich viele Codezeilen. Verkürzen lässt sich das durch den Einsatz von externen Bibliotheken wie beispielsweise »requests« [8]. Eine einfache Anfrage reduziert sich damit auf folgende zwei Zeilen:
antwort = requests.get(' https://api.github.com/repos/hans/test/issues')
print antwort.text
Eine Programmierschnittstelle, die mit URLs und HTTP arbeitet, bezeichnet man als RESTful, die Schnittstelle als REST-API (siehe auch die Einführung zu diesem Themenschwerpunkt).
Google Code
Auch das Projekthosting-Angebot Google Code arbeitet mit einem REST-ähnlichen API, kommuniziert dabei aber mit XML-Daten und erlaubt darüber nur den Zugriff auf die Bugreports eines einzigen Projekts [9]. Alle Issues des Projekts »python-twitter« liefert beispielsweise diese Anfrage:
curl -i "https://code.google.com/feeds/issues/p/python-twitter/issues/full"
Zur Authentifizierung fordert der Benutzer auch hier mit Benutzername und Passwort ein Token an, wobei er aber in diesem Fall den Benutzernamen und das Passwort als Parameter an die URL anhängt. Wem der Weg über die URLs zu kompliziert ist, für den stellt Google ein eigenes API für Python [10] und Java [11] bereit. Um mit diesem so genannten “Issue Tracking API for Python” alle Issues des Projekts »python-twitter« abzurufen, genügt die erste Zeile aus Listing 6. Die beiden anderen durchlaufen lediglich die Issues und geben deren Titel aus.
Listing 6
Issue Tracking API
01 issues = client.get_issues('python-twitter')
02 for i in issues.entry:
03 print i.title.text
OTRS
Das Ticketsystem OTRS hingegen geht einen etwas anderen Weg und nutzt Soap (siehe auch die Einführung zu diesem Themenschwerpunkt). Um diese Schnittstelle zu nutzen, packt der Programmierer die von OTRS auszuführenden Funktionen zusammen mit den dazu benötigten Daten in eine XML-Datei, deren Aufbau dem Soap-Standard folgt. Diese schickt er an das Ticketsystem, genauer gesagt an das Skript hinter »https://OTRS-Server/otrs/rpc.pl« .
Grundsätzlich lassen sich so alle OTRS-Klassen aufrufen, die in der API-Dokumentation aufgeführt sind [12]. Per Hand eine Soap-gemäße XML-Datei zusammenzusetzen ist jedoch eine ziemlich aufwändige Angelegenheit. Da Python keine Standardbibliothek für Soap enthält, kann der Bastler hier nur auf Bibliotheken von Dritten zurückgreifen. Die Dokumentation der Soap-Schnittstelle ist zudem äußerst dürftig bis nicht vorhanden. Kleine Beispiele für PHP, die auf die Tickets zugreifen, finden sich immerhin unter [13] sowie unter [14].
Bugzilla
Der Bugtracker Bugzilla geht ähnlich wie OTRS vor, nutzt aber den Standard XML-RPC. Auch dabei verpackt das Clientprogramm beziehungsweise ein Skript die gewünschte Aktion in einer XML-Datei. Diese schickt der Client dann an das Skript »http://Bugzilla-Server/xmlrpc.cgi« , das die gewünschte Aktion ausführt. Die verschickten XML-Dateien sind jedoch bei XML-RPC wesentlich einfacher aufgebaut. Zudem bieten viele Sprachen dafür fertige Bibliotheken an, so auch Python mit der »xmlrpclib« [15] (ab Python 3 »xmlrpc.client« ). Als kleines Beispiel zeigt Listing 7, wie man alle Informationen zum »Product« mit der ID »1« abholt.
Listing 7
Informationen über ein Produkt
01 import xmlrpclib
02 proxy = xmlrpclib.ServerProxy("http://localhost/bugzilla/xmlrpc.cgi", use_datetime=True)
03
04 try:
05 id = {'ids': [1]}
06 response = proxy.Product.get(id)
07 print response
08 except xmlrpclib.Fault, error:
09 print "Fehlercode: %s" % error.faultCode
10 print error.faultString
Produktmanagement
Die Funktion »Product.get()« bietet Bugzilla in seinem API an [16]. Sie verlangt einen Parameter »ids« , der wiederum in einer Liste die IDs aller Produkte nennt, für die Bugzilla die Informationen ausspucken soll. Den Namen des Parameters und seinen Wert übergibt der Programmierer beim Einsatz der »xmlrpclib« als Dictionary (»id« in Listing 7).
Auf diese Weise lassen sich auch alle übrigen Funktionen des Bugzilla-API aufrufen [17]. Ist für einen Funktionsaufruf auch eine Authentifizierung notwendig, meldet der Client sich mit der Funktion »User.login()« an [18]. Bugzilla liefert dann ein Cookie zurück, das der Benutzer jedem weiteren Funktionsaufruf beilegen muss.
Alternativ zu XML-RPC kann der Bugzilla-Nutzer auch die Json-Variante Json-RPC heranziehen [19]. Hierfür verpackt der Client die auszuführenden Funktionen im Json-Format.Außerdem gibt es für Python noch Bibliotheken von Drittanbietern, mit denen der Zugriff auf Bugzilla mit nur wenigen Zeilen Code gelingt, beispielsweise die Bugzillatools [20].
Fazit
Viele Dienste bieten wie Github eine Schnittstelle nach dem REST-Prinzip, die Authentifizierung erfolgt meist über Oauth. Der Zugriff über die URL und HTTP-Methoden ist in der Praxis unkompliziert und lässt sich mit nahezu jeder Programmiersprache durchführen. Allerdings sind die Manipulationsmöglichkeiten damit auch etwas beschränkt. Ein dickes und mächtiges API bieten nur die auf XML-RPC beziehungsweise Soap basierenden Webanwendungen.
Eine solche Schnittstelle zu nutzen ist andererseits gerade bei Soap mitunter recht umständlich und kompliziert. Eine Wahl hat der Anwender dabei nur selten: Die überwiegende Mehrheit der Dienste und Webanwendungen bietet nur ein einziges API. Immerhin darf er sich gelegentlich zwischen XML und Json als Austauschformat entscheiden. (mhu)
Infos
- Github: https://github.com/
- Bugzilla: http://www.bugzilla.org/
- Python-Bibliothek »urllib2« : http://docs.python.org/library/urllib2.html
- Python-Bibliothek »httplib« : http://docs.python.org/library/httplib.html
- Python-Bibliothek »json« : http://docs.python.org/library/json.html
- Oauth-Verfahren bei Github: http://developer.github.com/v3/oauth/
- Github-API-Dokumentation: http://developer.github.com/
- Requests: http://docs.python-requests.org/en/latest/index.html
- Google Code Issue Tracker API: http://code.google.com/p/support/wiki/IssueTrackerAPI
- Google Code Issue Tracker API for Python: http://code.google.com/p/support/wiki/IssueTrackerAPIPython
- Google Code Issue Tracker API for Java: http://code.google.com/p/support/wiki/IssueTrackerAPIJava
- OTRS-Entwicklerseiten: http://dev.otrs.org
- PHP-Beispiel für den Zugriff auf OTRS: http://faq.otrs.org/otrs/public.pl?Action=PublicFAQZoom&ItemID=369
- PHP-Beispiel für den Zugriff auf OTRS: http://www.iniy.org/?p=20&lang=de
- Xmlrpclib: http://docs.python.org/library/xmlrpclib.html
- Bugzilla-Schnittstelle für Produkte: http://www.bugzilla.org/docs/tip/en/html/api/Bugzilla/WebService/Product.html
- Bugzilla-API: http://www.bugzilla.org/docs/tip/en/html/api/
- Informationen zum Anmeldeverfahren in Bugzilla: http://www.bugzilla.org/docs/tip/en/html/api/Bugzilla/WebService.html#LOGGING_IN
- Bugzilla-Webservice: http://www.bugzilla.org/docs/tip/en/html/api/Bugzilla/WebService.html
- Bugzillatools: http://pypi.python.org/pypi/bugzillatools/0.5.2
- Listings zu diesem Artikel: https://www.linux-magazin.de/static/listings/magazin/2012/12/entwickler-tools





