
Mit seiner Multithreading-Fähigkeit hilft C++11 dem Programmierer dabei, von der Leistung moderner Mehrkern- und Mehrprozessorsysteme zu profitieren. Dieser Artikel führt in die mehrgleisige Datenverarbeitung ein und zeigt, dass die ersten eigenen Threads rasch programmiert sind.
Die wegweisenden Artikel“The Free Lunch is Over” [1] und “Welcome to the Jungle” [2] der C++-Koryphäe Herb Sutter bringen ein Problem moderner Software-Entwicklung auf den Punkt: Der Gleichschritt bei Performanceverbesserung der CPU und Anforderungen der Software ist nach 30 Jahren merklich aus dem Takt geraten. Es reicht nicht mehr aus, einfach auf eine schnellere CPU zu setzen. In der modernen Hardwarewelt müssen Programmiersprachen mit homogenen, ja sogar mit heterogenen Multicore-Architekturen umgehen können. C++11 schafft das mit Hilfe der neuen Multithreading-Funktionalität.
Rechenaufgabe
Bevor diese Artikelserie auf deren verzwickte Details eingeht, soll zuerst ein einfaches Beispiel den Respekt vor dem Unbekannten nehmen. Das Skalarprodukt zweier gleich großer Vektoren »v« und »w« der Länge »n+1« ist (vereinfacht) dadurch definiert, dass die einzelnen Werte »v[i]« und »w[i]« multipliziert und deren Produkte addiert werden:
v[0]*w[0] + v[1]*w[1] + ... v[n]*w[n]
Wem diese Erklärung nicht formal genug ist, der sei auf [3] verwiesen. Die Berechnung erledigt in Listing 1 der Algorithmus »std::inner_product()« aus der Standard Template Library [4].
Listing 1
Sequenzielles Berechnen des Skalarprodukts
01 #include <chrono>
02 #include <iostream>
03 #include <random>
04 #include <vector>
05
06 static const int NUM= 10000000;
07
08 long long getDotProduct(std::vector<int>& v,std::vector<int>& w){
09 return std::inner_product(v.begin(),v.end(),w.begin(),0LL);
10 }
11
12 int main(){
13
14 std::cout << std::endl;
15
16 // get NUM random numbers from 0 .. 100
17 std::random_device seed;
18
19 // generator
20 std::mt19937 engine(seed());
21
22 // distribution
23 std::uniform_int_distribution<int> dist(0,100);
24
25 // fill the vectors
26 std::vector<int> v, w;
27 v.reserve(NUM);
28 w.reserve(NUM);
29 for (int i=0; i< NUM; ++i){
30 v.push_back(dist(engine));
31 w.push_back(dist(engine));
32 }
33
34 // measure the execution time
35 std::chrono::system_clock::time_point start = std::chrono::system_clock::now();
36 std::cout << "getDotProduct(v,w): " << getDotProduct(v,w) << std::endl;
37 std::chrono::duration<double> dur = std::chrono::system_clock::now() - start;
38 std::cout << "Sequential Execution: "<< dur.count() << std::endl;
39
40 std::cout << std::endl;
41
42 }
Das abgedruckte Programm berechnet das Skalarprodukt zweier Vektoren mit 10 Millionen Elementen. Die Rechenarbeit findet in der Funktion »getDotProduct()« in Zeile 8 statt. Ungewöhnlich ist nur die Initialisierung des Rückgabewerts »0LL« . Dieses C++11-Literal steht für die Zahl »long long 0« und stellt sicher, dass das Ergebnis der summierten Multiplikationen in den Rückgabetyp passt.
Diese ungewöhnlich große Variable ist notwendig, denn das Ergebnis des Skalarprodukts (Abbildung 1) bewegt sich in einem sehr hohen Bereich: Der Datentyp »long long« kann Zahlen im Wertebereich von mindestens -9 223 372 036 854 755 808 bis +9 223 372 036 854 755 807 (mehr als 9 Trillionen) darstellen. Einen schönen Überblick über Datentypen für verschieden große natürliche Zahlen gibt der Wikipedia-Artikel unter [5].
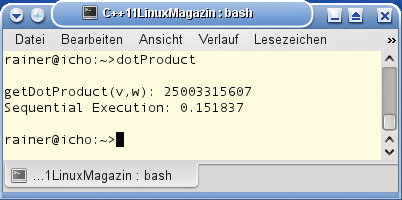
Abbildung 1: Berechnen des Skalarprodukts durch einen einzigen Thread.
Zufall beschafft Material
Um die Vektoren in den Zeilen 30 und 31 (Listing 1) mit Werten für das Rechenbeispiel zu füllen, initialisiert Zeile 20 den Zufallszahlenerzeuger mit einem zufälligen Startwert. Dieser produziert gleich verteilte Zufallszahlen im Bereich von 0 bis 100. Die Zeilen 27 und 28 stellen mit »v.reserve(NUM)« sicher, dass der Speicher für den Vektor in einem Rutsch reserviert wird. Das ergibt bei Vektoren dieser Länge durchaus Sinn, denn es erspart das aufwändige mehrfache Reservieren von Speicher. Zeile 36 veranlasst die Berechnung und gibt das Skalarprodukt der zwei Vektoren aus. Dank der neuen Zeitbibliothek »chrono« ist ziemlich einfach zu bestimmen, wie lange das Ausführen der Funktion dauert. Zeile 35 ermittelt die Zeit vor dem Funktionsaufruf, Zeile 37 stellt die Zeit danach fest und berechnet die Zeitdifferenz.
Wer eine kompakte Darstellung der neuen Zeitbibliothek sucht, wird in der Webpräsenz von Anthony Williams [6] fündig. Abbildung 1 zeigt, wie lange der PC des Autors zum Berechnen des Skalarprodukts braucht.
Arbeitsteilung
Das sollte deutlich schneller gehen, da die Ausführungszeit von der Rechenpower der Hardware abhängt. Immerhin steht ein Vierkernsystem unter dem Schreibtisch. Bei der ersten Implementierung hatte ein einziges Core die ganze Arbeit zu erledigen, während die drei verbleibenden auf Beschäftigung warteten. Dabei lässt sich das Verarbeiten eines Vektors leicht in vier gleich große Arbeitspakete aufteilen, sodass auch das Skalarprodukt etwa viermal so schnell berechnet sein sollte (Abbildung 2).
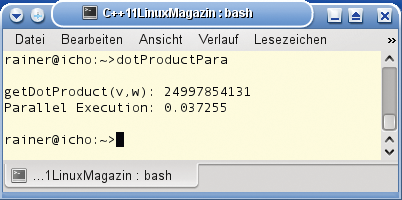
Abbildung 2: Der Einsatz von vier parallelen Threads verkürzt die Laufzeit deutlich.
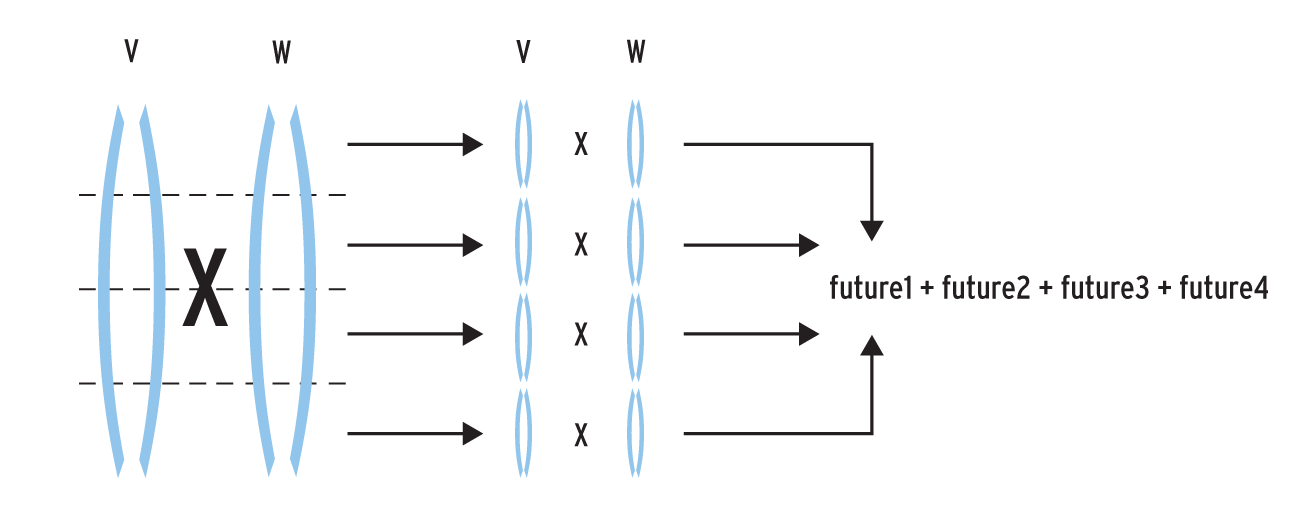
Der Code in Listing 2 verteilt in der Funktion »getDotProduct()« die Berechnung des Skalarprodukt auf vier Threads. Dazu zerschneidet er die zu verarbeitenden Vektoren in vier Portionen. Grafisch ist die Aufteilung in Abbildung 3 dargestellt.
Listing 2
Paralleles Berechnen des Skalarprodukts
01 #include <chrono>
02 #include <iostream>
03 #include <future>
04 #include <random>
05 #include <thread>
06 #include <vector>
07
08 static const int NUM= 10000000;
09
10 long long getDotProduct(std::vector<int>& v, std::vector<int>& w){
11
12 auto future1= std::async(
13 [&]{return std::inner_product(&v[0],&v[v.size()/4],
14 &w[0],0LL);}
15 );
16
17 auto future2= std::async(
18 [&]{return std::inner_product(&v[v.size()/4],&v[v.size()/2],
19 &w[v.size()/4],0LL);}
20 );
21
22 auto future3= std::async(
23 [&]{return std::inner_product(&v[v.size()/2],&v[v.size()*3/4],
24 &w[v.size()/2],0LL);}
25 );
26
27 auto future4= std::async(
28 [&]{return std::inner_product(&v[v.size()*3/4],&v[v.size()],
29 &w[v.size()*3/4],0LL);}
30 );
31 return future1.get() + future2.get() + future3.get() + future4.get();
32 }
33
34
35 int main(){
36
37 std::cout << std::endl;
38
39 // get NUM random numbers from 0 .. 100
40 std::random_device seed;
41
42 // generator
43 std::mt19937 engine(seed());
44
45 // distribution
46 std::uniform_int_distribution<int> dist(0,100);
47
48 // fill the vectors
49 std::vector<int> v, w;
50 v.reserve(NUM);
51 w.reserve(NUM);
52 for (int i=0; i< NUM; ++i){
53 v.push_back(dist(engine));
54 w.push_back(dist(engine));
55 }
56
57 // measure the execution time
58 std::chrono::system_clock::time_point start = std::chrono::system_clock::now();
59 std::cout << "getDotProduct(v,w): " << getDotProduct(v,w) << std::endl;
60 std::chrono::duration<double> dur = std::chrono::system_clock::now() - start;
61 std::cout << "Parallel Execution: "<< dur.count() << std::endl;
62
63 std::cout << std::endl;
64
65 }
Das Übersetzen von Listing 2 ist ein wenig aufwändiger als im vorigen Fall: Die Threading-Funktionalität erfordert es, unter Linux gegen die »pthread« -Bibliothek zu linken. Die Kommandozeile
g++ -std=c++0x -o dotProductParadotProductPara.cpp -lpthread
stellt dies sicher. Die parallele Ausführung der Funktion »getDotProduct()« ist tatsächlich um den Faktor 4 schneller, wie Abbildung 2 zeigt. C++11 hat sichergestellt, dass jeder Thread auf einem anderen Prozessorkern abläuft.
Threads erzeugen
Der Unterschied der beiden Implementierungen reduziert sich auf die Funktion »getDotProduct()« . Der Schlüssel zum Verständnis liegt in Listing 2 in den Funktionsaufrufen dieser Form:
auto future= std::async([&]{return std::inner_product(...);})
Durch »std::async« wird das Arbeitspaket asynchron in einem eigenen Thread ausgeführt. Dies ist aber nur die halbe Wahrheit: Tatsächlich startet »std::async()« nicht notwendigerweise einen neuen Thread. Die C++11-Implementierung behält es sich vor, »std::async()« wie einen gewöhnlichen Funktionsaufruf zu verwenden, der im aufrufenden Prozess ausgeführt wird.
Entscheidungskriterium für C++11, einen neuen Thread zu starten, kann die Anzahl der Prozessorkerne, die Anzahl der bereits aktiven Threads oder die Größe des Arbeitspakets sein: Die intelligente C++11-Implementierung optimiert die Thread-Ausführung für die vorhandene Hardware-Architektur. Der Aufruf »std::async()« gibt mit »auto futureN« eine Referenz auf sich selbst zurück. Über sie lässt sich das Ergebnis der Thread-Ausführung durch »futureN.get()« (Zeile 31) abfragen.
Während der ausführende Thread als Promise bezeichnet wird, nennt sich der Thread, der das Ergebnis anfordert, Future. Der Aufruf von »future.get« ist blockierend. Das heißt: Liegt das Ergebnis des Promise noch nicht vor, wartet der Future auf den Rückgabewert.
Nach dem Aufruf von »std::async()« in Zeile 12 bleibt nur eine alte Bekannte, die Lambda-Funktion [7], in der Form
[&]{return std::inner_product(&v[0],&v[v.size()/4],&w[0],0LL);})
übrig. Sie berechnet das Skalarprodukt von »v« und »w« , in diesem Thread für das erste Viertel der beiden Vektoren. Übrigens erfasst die Lambda-Funktion in diesem Beispiel die zwei Vektoren per Referenz »[&]« , um nicht mehrfach kopieren zu müssen. Das ist allerdings nicht in jedem Fall eine gute Idee. Der Kasten “Erfassen der Variablen” erläutert Hinergründe und Alternativen.
Erfassen der Variablen
Eine Quelle für subtile Bugs sei gleich im ersten Artikel zum Thema Multithreading in C++11 genannt: Erfasst ein Thread eine Variable per Referenz und nicht per Copy, ist Vorsicht geboten. Zum einen muss der Programmierer gegebenenfalls den Zugriff auf die gemeinsame Variable schützen, zum anderen muss die Variable für die gesamte Lebenszeit der Threads gültig sein.
Beide Punkte werden durch die Threads in »getDotProduct()« nicht verletzt. Der Zugriff auf die Elemente der Vektoren ist nur lesend und die Vektoren gelten für die ganze Lebenszeit der Threads.
Aufgrund dieser impliziten Gefahren sollte ein Thread in der Regel seine Variablen per Copy erfassen und nur im begründeten Anwendungsfall per Referenz. Eine Ausnahme kann – wie im konkreten Fall »getDotProduct()« – in der Ausführungsgeschwindigkeit des Algorithmus oder darin begründet sein, dass alle Threads die gleiche Variable referenzieren sollen.
Threading vertieft
Zugegeben, dieses Beispiel war einigermaßen konstruiert. Die Lösung beruht nämlich auf dem Wissen des Entwicklers, dass der verwendete PC vier Prozessoren besitzt. Doch C++11 bietet weitere Werkzeuge, um Aufgaben wie die Berechnung des Skalarprodukts auf die jeweils vorliegende PC-Architektur maßzuschneidern. Deren Einsatz erfordert allerdings mehr Wissen über die Multithreading-Fähigkeiten von C++11.
Der nächste Artikel befasst sich daher nochmals mit Wissenwertem zu Threads. Dieses Know-how umfasst die Verwaltung der Threads sowie ihre Parametrisierung mit einem Arbeitspaket. Das ist aber erst der Anfang fortgeschrittener Techniken – bleiben Sie dran. (mhu)
Infos
- Herb Sutter, “The Free Lunch is Over”: http://www.gotw.ca/publications/concurrency-ddj.htm
- Herb Sutter, “Welcome to the Jungle”: http://herbsutter.com/welcome-to-the-jungle/
- Skalarprodukt: http://de.wikipedia.org/wiki/Skalarprodukt
- »inner_product()« : http://www.cplusplus.com/reference/std/numeric/inner_product/
- »0LL« : http://de.wikipedia.org/wiki/Integer_%28Datentyp%29
- Zeitbibliothek: http://www.stdthread.co.uk/doc/headers/chrono.html
- Rainer Grimm, “Kurz und knackig”: Linux-Magazin 02/12, S. 92
- Listings zu diesem Artikel: https://www.linux-magazin.de/static/listings/magazin/2012/04/cpp





