
© Andrey Kiselev, 123RF
Sie erkennen mit klarem Blick die wirklich relevanten Beziehungen im Social Web, verstehen die Sprache, finden zielstrebig die kürzesten Wege und optimieren Besucherströme. Das sind die Aufgaben, die Graphdatenbanken mit Bravour erledigen. Dieser Artikel vergleicht fünf blaublütige Open-Source-Vertreter.
Peter kennt Paula, Köln verbindet eine Autobahn mit Dortmund, von Marvin führt ein Netzwerkkabel zu Zaphod. Solche Beziehungen lassen sich durchaus anschaulich aufzeichnen (Abbildung 1) und die entstandenen Gebilde bezeichnen Informatiker als Graphen. Zusammen mit den passenden Algorithmen eignen sie sich beispielsweise hervorragend, um Routen zu berechnen, Beziehungsstrukturen auszumachen (Wer kennt wen?), Engpässe in Netzwerken aufzuspüren, Rohrleitungssysteme zu optimieren oder die Staubildung auf der Autobahn zu analysieren.

Abbildung 1: Ein einfacher Graph zeigt die Beziehungen zwischen Personen.
Platzsparend
In der Praxis prügeln Anwendungsentwickler ihre Graphen irgendwie in relationale Datenbanken, was bei komplexen Beziehungen jedoch viel Speicherplatz, Geschwindigkeit und nicht zuletzt Hirnschmalz seitens der Programmierer fordert. Graphdatenbanken empfehlen sich hier als die bessere Lösung: Sie legen die Beziehungsgeflechte, Straßenkarten und Netzwerke platzsparend auf der Festplatte ab, ermöglichen schnelle Abfragen und bieten teilweise sogar noch einige effiziente Analysealgorithmen.
Während andere Datenbankmodelle die Graphdatenbanken in den 90er Jahren etwas in den Hintergrund drängten, erhielten sie in den letzten Jahren mit dem Boom der No-SQL-DBs deutlich mehr Aufmerksamkeit. Treibende Kraft sind vor allem die Forschungen für das Semantic Web sowie Entwicklungen im Bereich der Geo-Informationssysteme – Google Maps und Openstreetmap (Abbildung 2) lassen grüßen.
Abbildung 2: Auch Straßenkarten sind mathematisch gesehen nichts anderes als Graphen.
Aber auch Suchmaschinen greifen gerne auf ihre Dienste zur Sprach- und Textanalyse sowie beim Aufbau von Wissensdatenbanken zurück. Wie stark sich der Funktionsumfang der einzelnen Graphdatenbanken unterscheidet, zeigt ein Vergleich der fünf quelloffenen Vertreter Neo4j, Graph DB, Info Grid, Hyper Graph DB und Vertex DB (Tabelle 1).
Knoten, Kanten und Labels
Die Grundlagen sind bei allen Probanden gleich. Wer die Beziehung zwischen Peter und Paula aufzeichnen will, malt für jede Person einen Kreis oder Kasten und verbindet diese mit einem Strich. Informatiker bezeichnen die Kreise als Knoten (Nodes), die Striche heißen Kanten (Edges).
Die Edges gibt es in zwei Geschmacksrichtungen: Gerichtete Kanten stellen gewissermaßen Einbahnstraßen dar, die in der Grafik ein Pfeil repräsentiert. Beispielsweise ist Peter der Vater von Klaus, aber nicht umgekehrt. Ungerichtete Kanten gelten in beiden Richtungen. So fährt man auf der Autobahn von Dortmund nach Köln, aber auch umgekehrt von Köln nach Dortmund.
Die Graphdatenbanken verwenden meist zwei entgegengesetzt gerichtete Kanten anstelle einer ungerichteten (wie in Abbildung 1 zwischen Peter und Paula). Die Beschriftungen an den Kanten, welche die Art der Beziehung repräsentieren (zum Beispiel “ist verheiratet mit”), heißen Label.
Diese Terminologie ist die in der Mathematik und Informatik gebräuchliche, fast alle Graphdatenbanken verwenden jedoch ihr ganz eigenes Vokabular, das der Anwender erst einmal lernen muss. Beispielsweise sind die Labels häufig auch als Typ einer Kante bezeichnet.
Properties
Knoten und Kanten lassen sich noch mit weiteren Informationen spicken, etwa dem Namen und dem Alter einer Person. Der so mit Eigenschaften (Properties) aufgebrezelte Graph heißt Property Graph. In der Regel sind die Properties einfache Schlüssel-Wert-Paare, im Beispiel also etwa: Alter: 16. Hyper Graph DB speichert sogar immer gleich komplette Java-Objekte.
Um bei sehr großen Graphen die Übersicht zu erhöhen, fassen Entwickler Knoten zu einem neuen, dicken Hyperknoten zusammen – eine Kante verbindet dann mehr als zwei Knoten. Beispielsweise könnte man auf einer Straßenkarte die Städte Dortmund, Essen, Bochum und Duisburg zum Knoten »Ruhrgebiet« zusammenlegen. Analog lassen sich Kanten zu Hyperkanten vereinen. Die so entstehenden Hypergraphen verdauen Graph DB und Hyper Graph.
Oft ist es erlaubt, für Knoten und Kanten einen Typ beziehungsweise ein Schema zu definieren. Damit kann die Datenbank automatisch die Konsistenz sicherstellen beziehungsweise erst mal prüfen, ob zwischen zwei Knoten überhaupt eine Kante erlaubt ist. Kommerzielle Datenbanken bieten zudem häufig eine Art Versionsverwaltung, die sich jede Änderung an einem Knoten merkt. Auf diese Weise kann der Benutzer Manipulationen protokollieren, visualisieren oder rückgängig machen. Von den fünf kostenlosen Graphdatenbanken beherrscht das allerdings keine einzige.
Traversion
Kennt Peter meinen Kumpel Dieter? Komme ich von Berlin nach Köln? Wer solche Fragen beantworten will, muss die Kanten im Graphen ablaufen, was traversieren heißt. Interessant ist in der Regel natürlich der kürzeste Weg zwischen zwei Knoten, womit ein Staubsaugervertreter auch die effizienteste Route durch das nächste Wohngebiet erfährt (Traveling-Salesman-Problem). Für derartige Probleme bot im Test nur Neo4j ein paar effiziente eingebaute Algorithmen beziehungsweise Abfragen an, bei den anderen Probanden muss sie der Anwender selbst implementieren.
Polyglott mit Cypher und Gremlin
Während bei relationalen Datenbanken SQL als Standard-Abfragesprache etabliert ist, verwendet so gut wie jede Graphdatenbank ihre ganz eigene Graph Query Language – die natürlich nicht zu den anderen kompatibel ist. Die Sprachen sind zudem meist noch auf bestimmte Anwendungsgebiete zugeschnitten. So erkennt etwa Cypher von Neo4j besonders gut Muster, während GQL aus Sones Graph DB den Fokus auf die Traversierung legt.
Mit der eigens für Graphendatenbanken zugeschnittenen Sprache Gremlin gibt es zudem so etwas wie einen Standardisierungsversuch [1]. Sie hat sich auf die Traversierung spezialisiert, kommt aber bei den freien Graphdatenbanken nur in Neo4j zum Einsatz. Durchgesetzt hat sich bei fast allen Graphdatenbanken lediglich eine REST-Schnittstelle (Representational State Transfer, [2]), mit der Clients die Datenbank über spezielle HTTP-Anfragen manipulieren.
REST und Json tragen die Daten übers Netz
In der Regel wandern dabei die Daten nach dem Json-Standard übers Netz, häufig ist es auch erlaubt, sie in einem XML-Dokument zu verpacken. Natürlich bieten die Datenbanken auch Schnittstellen zu einer oder mehreren Programmiersprachen, Anwendungsentwickler müssen nur eine mitgelieferte (Client-)Bibliothek hinzulinken und greifen dann bequem über die darin mitgebrachten Funktionen und Objekte in der ihnen gewohnten Programmiersprache auf den eigentlichen Datenbestand zu.
Bis auf die kostenlose Fassung von Sones Graph DB fassen die Graphdatenbanken mehrere einzelne Aktionen zu einer Transaktion zusammen, wie Neo4j erfüllen sie dabei teilweise sogar das ACID-Prinzip (Atomicity, Consistency, Isolation and Durability, [3]).
Um auf Anfragen möglichst schnell eine Antwort liefern zu können, indizieren Graphdatenbanken ähnlich wie ihre relationalen Kollegen den Datenbestand. In der Regel muss der Admin den Datenbanken zunächst mitteilen, welche Daten zu indizieren sich überhaupt lohnt. Bei einigen Datenbanken ist der Index selbst wieder ein Graph, viele freie Datenbanken nutzen aber herkömmliche Speichermethoden, besonders beliebt sind Key-Value-Stores (wie die Berkeley DB).
Replikation nach dem Peer-to-Peer-Konzept
Damit ein Server bei vielen oder komplexen Anfragen nicht in die Knie geht, repliziert der erfahrene Admin die Datenbank auf zusätzlichen Servern. Es ist aber recht schwierig, Graphen auf mehreren Servern konsistent zu halten. Nur drei freie Datenbanken nehmen sich dieses Themas an: Neo4j nutzt das Single-Master-/Multiple-Slave-Konzept, bei dem ein Master-Server seine Daten auf mehrere Slave-Server kopiert. Auf diese Kopien darf der Anwender nur lesend zugreifen. Änderungen nimmt nur der Master vor und propagiert sie zu seinen Slaves. Info Grid und Hyper Graph DB bevorzugen hingegen ein Peer-to-Peer-Konzept, bei dem jede Datenbank alle anderen Kollegen auf dem Laufenden hält.
Ähnlich spannend wird das Partitionieren der Datenbank: Wird ein Graph zu groß für einen Server, könnte ihn der Admin auf mehrere Server verteilen. Dazu müsste er ihn an einer Stelle zerschneiden – aber dummerweise gibt es noch keinen Algorithmus, der automatisch die perfekte Schnittstelle findet. Immerhin existieren recht gute Heuristiken, die etwa darauf achten, die Anzahl der zerschnittenen Kanten zu minimieren (Stichwort Min-Cut). Dabei können die Graphen aber in ungleichmäßige Teile zersplittern, womit wiederum ein Server mehr Arbeit erhält als die anderen. Bis auf Info Grid und Hyper Graph DB bieten die kostenlosen Graphdatenbanken daher erst gar keine verteilte Datenhaltung an.
Erstaunlicherweise sind die meisten freien Graphdatenbanken in Java programmiert, nur die deutsche Firma Sones nutzt C# für ihre Graph DB. Vertex DB setzt auf Ruby. Allesamt laufen damit jedoch in einer virtuellen Maschine, die maßgeblich die Performance beeinflusst (siehe Kasten “Benchmarking”). Dennoch ignorieren die Entwickler andere, unter manchen Umständen schnellere Sprachen wie etwa C oder C++.
Benchmarking
Wer die Verarbeitungsgeschwindigkeit der Datenbanken in einem Benchmark vergleichen möchte, stößt unweigerlich auf mehrere Probleme: Zunächst sind die Graphdatenbanken auf unterschiedliche Anwendungsgebiete zugeschnitten. Während beispielsweise Sones Graph DB aus dem Bereich der Analyse sozialer Netzwerke kommt, liegen die Wurzeln von Hyper Graph DB in der künstlichen Intelligenz. Obendrein nutzen alle Datenbanken unterschiedliche Abfragesprachen. So ist Cypher von Neo4j auf die Mustererkennung spezialisiert, Graph DB hingegen auf die Traversierung von Graphen. Unter dem Strich würde man also Äpfel mit Birnen vergleichen.
Problem – vergleichbare Datenbasis
Ein weiteres Problem ist die Datenbasis. Um verlässliche Ergebnisse zu erhalten und die Datenbanken zu stressen, müssen möglichst große Graphen her. Gerade bei Graphdatenbanken sind die jedoch sehr anwendungsspezifisch und obendrein auch noch meist gut unter Verschluss. Paradebeispiel sind Straßenkarten, an die man durchweg nur gegen eine nicht zu knappe Gebühr und mit Knebelverträgen herankommt.
Sones hat für seine Datenbank immerhin einen kleinen Benchmark entwickelt [4]. Er ist allerdings für die Graph DB optimiert und soll primär verschiedene (Server-)Hardware beziehungsweise Plattformen miteinander vergleichen. Als Datenbasis nutzt Sones zudem zufallsgenerierte Graphen, deren Größe und Laufzeit der Anwender frei bestimmen kann (Abbildung 3). Vergleichszahlen von Referenzsystemen muss man derzeit mit der Lupe in älteren Whitepapers suchen [5].
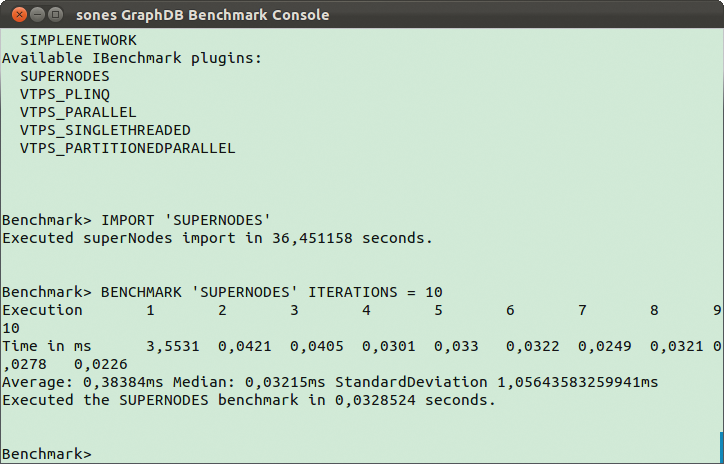
Abbildung 3: Für die Graph DB stellt Sones einen Benchmark bereit, der auf zufällig generierten Graphen arbeitet.
Ergo: Derzeit gibt es keinen (praxisnahen) Benchmark oder Belastungstest, mit dem man alle Graphdatenbanken zuverlässig vergleichen könnte. Wer vor der Entscheidung steht, kommt nicht umhin, mehrere Produkte auf seiner eigenen Datenbasis auszuprobieren.
Neo4j
Zu den ältesten Graphdatenbanken zählt Neo4j. 2003 als Unterbau eines Contentmanagement-Systems entstanden, gliederten sie die Entwickler 2007 in ein eigenständiges Produkt aus. Heute koordiniert die Firma Neo Technologies die Weiterentwicklung, die Finanzierung geschieht über kostenpflichtigen Support. Neo4j lässt sich sowohl als eigenständiger Datenbankserver betreiben als auch in eigene Java-Programme einbetten. Letzteres soll vor allem die Verarbeitungsgeschwindigkeit erhöhen. Der Neo4j-Server bietet unter »http://localhost:7474« eine Webanwendung zur Administration der Datenbank (Abbildung 4). Darüber hinaus darf der Admin den Server über Plugins aufbohren.
Abbildung 4: Neo4j bringt gleich eine Webapplikation mit, in der der Admin Abfragen und Steuerkommandos absetzen kann.
Wie der Datenbankentwickler aus seinem Java-Programm heraus die Datenbank anspricht, zeigt das Beispiel aus Listing 1. Für Java-Programmierer sollte es selbsterklärend sein – der Einstieg in Neo4j fällt somit relativ leicht. Mittlerweile existieren aber auch Anbindungen an zahllose andere Sprachen, darunter Ruby, Python, Scala, Closure und C#. Besonders beliebt ist Neo4j bei Jruby-Entwicklern. Seit Version 1.4 besitzt Neo4j eine eigene Abfragesprache (Cypher), die vor allem zur vereinfachten Mustererkennung gedacht ist, alternativ lässt sich Neo4j auch in Gremlin ansprechen.
Listing 1
Java-Zugriff auf Neo4j
01 // Datenbank in /var/speicherort anlegen und neue Beziehung definieren:
02 GraphDatabaseService datenbank = new EmbeddedGraphDatabase("/var/speicherort");
03 private static enum RelTypes implements RelationshipType { erreichbar }
04 // Transaktion starten:
05 Transaction tx = datenbank.beginTx();
06 // Knoten definieren:
07 Node dortmund = datenbank.createNode();
08 Node koeln = datenbank.createNode();
09 // Properties setzen:
10 dortmund.setProperty("Name", "Dortmund");
11 koeln.setProperty("Name", "Köln");
12 // Kanten erzeugen:
13 Relationship a1_do_k = dortmund.createRelationshipTo(koeln, RelTypes.erreichbar);
14 Relationship a1_k_do = koeln.createRelationshipTo(dortmund, RelTypes.erreichbar);
15 // Daten Speichern und alles beenden:
16 tx.success();
17 tx.finish();
18 datenbank.shutdown();
Komplexe Beziehungsmuster
Kanten sind für Neo4j Beziehungen, die einen Typ besitzen (wie etwa das “ist verheiratet mit”) und weitere Properties aufnehmen können. Diese bestehen wiederum aus Schlüssel-Wert-Paaren, wobei die Werte nur einfache, bekannte Datentypen wie Strings oder Integer-Zahlen sein dürfen.
Die Graphen speichert Neo4j in Dateien mit eigenem Format, um den Index kümmert sich Apache Lucene [6]. Indizieren kann Neo4j nur die Properties von Knoten und Kanten, wobei der Entwickler die Indizes obendrein selbst verwalten muss. Das ist zwar etwas aufwändiger, dafür lassen sich aber auch nur interessante Teile des Graphen indizieren.
Neo4j legt seine Daten übrigens immer auf der Festplatte ab, ein Betrieb als In-Memory-Datenbank (siehe den nächsten Artikel in diesem Schwerpunkt) ist derzeit nicht möglich.
Einen Durchlauf durch einen Graphen darf der Programmierer äußerst flexibel steuern. So legt er beispielsweise fest, in welcher Reihenfolge Neo4j die Kanten eines Knotens abarbeiten und welche Verzweigungen es überhaupt weiter verfolgen soll. Darüber hinaus bietet Neo4j hilfreiche Graph-Algorithmen an, etwa den kürzesten Weg nach Dijkstra oder den A*-Algorithmus.
Neo4j erlaubt die Replikation im Netz. Dabei küren alle beteiligten Server selbstständig einen Write-Master. Nur er führt alle Schreiboperationen aus, seine anderen Kollegen übernehmen lediglich asynchron seinen Datenbestand und beantworten Leseoperationen. Sollte der Write-Master ausfallen, bestimmt die verbleibende Gruppe einen neuen.
Neo4j selbst steht als so genannte Community Edition unter der GPLv3. Die Advanced Edition bringt Monitoring-Fähigkeiten mit, unterliegt aber der AGPLv3. Diese Lizenz gilt auch für die größte Enterprise-Edition, die noch Replikation respektive Hochverfügbarkeit enthält. Mit Neoclipse stellen die Entwickler ein “visuelles Graphdatenbankwerkzeug” bereit, das auf der IDE Eclipse basiert [7].
Konkursverwaltung: Sones Graph DB
Ihren Ursprung hat Graph DB in der Modellierung und Speicherung sozialer Netze. Daher verwundert es nicht, dass der 2007 in Erfurt gegründete Hersteller Sones die Verwandtschaftsbeziehungen aus der Zeichentrickserie “The Simpsons” als Beispiel nutzt [8].
Sones Graph DB ist in C# geschrieben und basiert somit auf dem Dotnet-Framework beziehungsweise unter Linux auf Mono. Nach Sones eigenen Messungen arbeitet die Datenbank unter Mono sogar schneller als mit dem Dotnet-Framework unter Windows [9]. Weitere Anbindungen existieren an Java und PHP. Sones speichert die eigentlichen Daten im eigenen Dateisystem Graph-FS. Die Datenbank selbst erlaubt gerichtete Hyperkanten. Die damit entstehenden Gebilde bezeichnet Sones als Property Hypergraph.
Knoten oder Kante
Für Graph DB sind sowohl Properties als auch Kanten Attribute, eine Unterscheidung fällt der Typ: Handelt es sich etwa um einen String oder Integer, ist es eine Property, beim Typ Knoten hingegen eine Kante.
Graph DB bringt eine eigene Abfragesprache namens GQL mit, die sich sichtlich an SQL orientiert. Wie man in relationalen Datenbanken erst eine Tabelle anlegt, muss man in ihr zunächst definieren, wie ein Knoten aussieht beziehungsweise welche Informationen er speichert. Das sieht dann beispielsweise so aus:
CREATE ABSTRACT VERTEX TYPE Person ATTRIBUTES (String Name) MANDATORY (Name)INDICES (Name)
Dieser Befehl teilt Graph DB mit, dass es im Graphen Knoten gibt, die einen »String« unter der Bezeichnung »Name« speichern, dessen Angabe auch zwingend erforderlich ist (»MANDATORY« ) und indiziert werden soll (»INDICES« ). Aufgrund des Schlüsselworts »ABSTRACT« kann man jedoch nicht direkt Personen-Knoten erstellen, sondern muss erst einen oder mehrere weitere Knotentypen von diesem ableiten:
CREATE VERTEX TYPES Freund EXTENDS Person ATTRIBUTES (Integer Alter, SET<Freund> kennt)
Die Graph DB kann folglich Eigenschaften zwischen Knoten vererben. Jetzt darf der Admin passende Freunde erzeugen und miteinander verbinden:
INSERT INTO Freund VALUES (Name = 'Peter', Alter = 52) INSERT INTO Freund VALUES (Name = 'Paula', Alter = 34) LINK Freund (Name = 'Peter') TO Freund(Name = 'Paula') VIA kennt
Auch wer aus einer der unterstützten Programmiersprachen C#, PHP, Java oder Javascript heraus auf die Datenbank zugreifen möchte, muss GQL-Anweisungen absetzen. Das Einfügen eines Knotens sieht unter C# wie folgt aus:
var ergebnis = GraphDSServer.Query(SecToken, \ TransactionID, "INSERT INTO Freund VALUES \ (Name ='Peter', Alter = 52)",SonesGQLConstants.GQL);
C#-Nutzer dürfen außerdem eine Anfrage auch mit speziellen Funktionen zusammenstöpseln, was aber schon bei einfachen Queries schnell zu unübersichtlichem Spaghetticode führt.
Der Datenbankserver stellt eine kleine Webanwendung namens Web Shell bereit, über die der Anwender den Datenbestand direkt per GQL im Browser manipuliert. Dazu muss er nach dem Start der Datenbank nur die URL »http://localhost:9975/WebShell« ansteuern (Abbildung 5). Die Web Shell liefert ihre Ausgaben im Json- oder XML-Format. Gleiches gilt für den, der per REST zugreift.
Abbildung 5: An der Web Shell von Graph DB lässt sich Sones’ Datenbank wie in einer Linux-Shell verwalten.
Sones Graph DB gibt es in einer kostenlosen Variante, die unter der AGPLv3 steht. Gegenüber der kommerziellen Ausgabe arbeitet sie ausschließlich im Hauptspeicher (In-Memory-Datenbank). Schaltet jemand den Server ab, sind alle gespeicherten Daten futsch. Des Weiteren fehlen der Open-Source-Fassung Transaktionen und Properties an Kanten. Die gibt es erst seit der 2011 erschienenen Version 2.0, die zudem modular aufgebaut ist und sich so um neue Funktionen oder Abfragesprachen erweitern lässt.
Kurz vor Redaktionsschluss musste Sones Insolvenz anmelden. Wie es mit der Firma und der Datenbank weitergeht, war noch unklar. Ein Teil der Nutzergemeinde möchte jedoch zumindest die Open-Source-Variante erhalten und weiterentwickeln.
Info Grid
Das Info-Grid-Projekt werkelt nicht nur an einer einfachen Graphdatenbank, sondern an einem ganzen Framework, mit dem sich vollständige Webanwendungen klöppeln lassen. Das Framework enthält Bausteine zur Nutzerverwaltung, Rechtemanagement und sogar ein Templatesystem, das die Datenbankinhalte aufbereitet und etwa als HTML-Seite oder XML-Dokument ausgibt. Als Programmiersprache dient Java, die Webanwendungen samt Graphdatenbank laufen auf einem Java-EE-Anwendungsserver (Enterprise Edition).
Info Grid soll vor allem Informationen aus unterschiedlichen Quellen zusammenführen. Paradebeispiel ist das Einsammeln mehrerer Newsfeeds, die das Framework aufbereitet und in Form eines Graphen der Webanwendung zur Verfügung stellt. Die eigentlichen Daten bleiben dabei in ihren externen Quellen liegen, Info Grid erstellt für sie nur einen virtuellen Graphen. Für den Anwender bleibt dieser Vorgang unsichtbar – er erfährt nicht, wo die Daten liegen.
Eine Info-Grid-Datenbank kann mit anderen Kolleginnen in einem Netzwerk über das XPRISO-Protokoll [10] kommunizieren. Dieses erlaubt sowohl auf den Datenbestand der anderen Instanzen zuzugreifen als auch eine Peer-to-Peer-Replikation durchzuführen. Die direkt in Info Grid abgelegten Informationen kann die Datenbank entweder im Speicher behalten, als Datei auf die Festplatte packen oder an andere Dienste weiterreichen, etwa an Hadoop [11], Amazon S3 oder sogar eine relationale Datenbank.
Info Grid bezeichnet Knoten als Mesh Objects, zwischen denen Beziehungen (Relationships) existieren. Der damit entstehende Graph ist eine Mesh Base. Wer den Knoten einem Typ zuordnet, stellt sicher, dass der Node nur ganz bestimmte Properties erhält. Was da wie erlaubt ist, bestimmt der Admin in einer XML-Datei, dem so genannten Model. Info Grid gibt ein paar Properties vor, darunter die eindeutige Identifikationsnummer und sogar ein Ablaufdatum, nach dem es den Knoten auf Wunsch wieder löscht.
Angeheftete Eigenschaften
Seit Version 2 der Datenbank darf man nur noch den Knoten Properties anheften, was die Entwickler mit einer höheren Verarbeitungsgeschwindigkeit begründen. Wer an den Kanten Properties benötigt, muss selbst weitere Zwischenknoten einfügen – die assoziativen Knoten. Darüber hinaus gibt es nur ungerichtete Kanten, die auch noch zwingend zwei Knoten miteinander verbinden müssen. Obendrein kann Info Grid die Properties nicht indizieren.
Jede Änderung im Graphen erzeugt ein Ereignis (Event), für das sich Objekte als so genannte Listener registrieren lassen. Info Grid benachrichtigt sie dann automatisch beim Eintreten des Events. Auf diese Weise kann der Anwender beispielsweise automatisch auf eine neue Meldung in einem Newsfeed reagieren. Listing 2 zeigt in einem Beispiel, wie er in Java eine Info-Grid-Datenbank anlegt und sie mit ein paar Knoten füttert. Das Vorgehen ähnelt dabei Neo4j.
Listing 2
Java-Zugriff auf Info Grid
01 // In-Memory-Datenbank erstellen:
02 MeshBase datenbank = MMeshBase.create();
03 MeshObjectLifecycleManager molm = datenbank.getMeshObjectLifecycleManager();
04 // Transkation festlegen:
05 Transaction tx = datenbank.createTransactionAsap();
06 // Knoten erzeugen:
07 MeshObject dortmund = molm.createMeshObject();
08 MeshObject koeln = molm.createMeshObject();
09 //Properties setzen:
10 dortmund.setProperty("Name", "Dortmund");
11 koeln.setProperty("Name", "Köln");
12 //mit Kante verbinden:
13 dortmund.relate(koeln);
14 // Transaktion abschicken:
15 if(tx!=null) tx.commitTransaction();
Die Info-Grid-Entwickler stellen auf ihrer Homepage eine Beispiel-Webanwendung namens Mesh World bereit [12]. Die bietet netterweise auch Einblick in den Graphen und die Möglichkeit, ihn dort relativ bequem zu manipulieren. Treibende Kraft hinter Info Grid ist die Firma Net Mesh, die auch kommerziellen Support anbietet [13].
Hyper Graph DB
Aus der Ecke der künstlichen Intelligenz stammt Hyper Graph DB. Wie der Name bereits andeutet, arbeitet sie mit Hypergraphen, bei denen der Anwender sogar Kanten mit anderen Kanten in Beziehung setzen darf. Im Gegensatz zur Konkurrenz versteht sich Hyper Graph DB als reine eingebettete Datenbank (Embedded Database). Wer sie verwenden will, muss immer eine eigene Anwendung darum herumstricken.
Das funktioniert derzeit nur in Java, Anbindungen oder Konvertierungen an andere Sprachen fehlen. Dafür nehmen die Knoten des verwalteten Graphen beliebige Java-Objekte auf, man muss sie nur in die Datenbank schieben und dann mit Kanten verbinden. Wie simpel und einfach das über die Bühne geht, veranschaulicht Listing 3.
Listing 3
Java-Zugriff auf Hyper Graph DB
01 // Datenbank erstellen:
02 HyperGraph graph = HGEnvironment.get("/var/speicherort");
03 // Transaktion einleiten:
04 graph.getTransactionManager().beginTransaction();
05 // Knoten einfügen, Stadt ist eine vom Autor definierte Java-Klasse:
06 HGHandle dortmund = graph.add(new Stadt("Dortmund"));
07 HGHandle koeln = graph.add(new Stadt("Köln"));
08 // mit einfacher Kante verbinden:
09 HGHandle kante = graph.add(new HGPlainLink(dortmund, koeln));
10 // Transaktion abschließen:
11 graph.getTransactionManager().commit();
Die »add()« -Methoden packen ein Java-Objekt in jeweils einen Knoten und liefern anschließend ein Handle zurück. Über diesen Fingerabdruck wird der Admin den Knoten später in der Datenbank wiederfinden beziehungsweise mit anderen Hyper-Graph-Methoden manipulieren. Um die Knoten zu speichern, serialisiert Hyper Graph zunächst die Java-Objekte mit dem entsprechenden Java-API und schiebt sie anschließend in eine Berkeley-DB-Datenbank [14]. Diese Arbeitsweise ist für Programmierer extrem bequem, gleichzeitig aber auch wenig performant.
Kanten sind in Hyper Graph DB ebenfalls einfache Java-Objekte, die nur das dafür abgestellte Interface »HGLink« implementieren. Bildlich kann man sie sich wie bei Info Grid als Zwischenknoten vorstellen. Normalerweise müsste Listing 3 also eine eigene Java-Klasse erstellen, die das Interface »HGLink« implementiert. Um dem Entwickler etwas Arbeit zu ersparen, bringt Hyper Graph DB bereits ein paar fertige Klassen mit. So ist etwa »HGPlainLink« aus Zeile 9 eine einfache, unbeschriftete Kante.
Die Arbeit mit Hyper Graph DB geht somit schnell von der Hand. Wer in der Dokumentation stöbert, stolpert jedoch schnell über eine etwas gewöhnungsbedürftige Terminologie. So heißen die Grundbausteine eines Graphen Atome. Sie besitzen einen bestimmten Typ und können beliebige Nutzdaten aufnehmen. Sofern ein Atom mit einem oder anderen Kollegen eine Verbindung eingeht, handelt es sich um einen Link (Kante), andernfalls übernehmen sie die Funktion eines Node (Knoten).
Um an gespeicherte Atome wieder heranzukommen, bastelt sich der Programmierer mit eigens dafür abgerichteten Java-Objekten und -Methoden eine Anfrage zusammen. Auf Wunsch kann Hyper Graph DB eine solche Abfrage zunächst analysieren, daraus einen Abfrageplan erstellen und sich diesen merken. Eine erneute Anfrage läuft dann wesentlich schneller ab. Traversierungen lassen sich wie bei Neo4j umfassend steuern, darüber hinausgehende Algorithmen gibt es aber nicht.
Mehrere einzelne Hyper-Graph-Instanzen arbeiten auf Wunsch auch als Agenten-basierte Peer-to-Peer-Datenbank zusammen. Alle Beteiligten kommunizieren dabei über das JXTA-Protokoll [15] oder das aus dem Instant Messaging bekannte XMPP-Jabber.
Vertex DB
Der jüngste Vertreter im Bunde hört auf den Namen Vertex DB und ist in mehrfacher Hinsicht ein Unikum. Zunächst nimmt die Datenbank Befehle ausschließlich via HTTP entgegen. Dabei kommen lediglich »POST« – und »GET« -Anfragen zum Einsatz, es handelt sich also nicht um eine vollständige REST-Schnittstelle. Antworten liefert die Datenbank als Text- oder Json-Dokument zurück. Transaktionen bildet der Anwender, in dem er mehrere Vertex-DB-Befehle in einer »POST« -Anfrage zusammenfasst.
Vom Admin entfernte Knoten landen nicht umgehend im Nirvana, Vertex DB besitzt eine Garbage Collection, die immer mal wieder anspringt und die Datenbank aufräumt. Und so genannte Queues beinhalten Befehle, die die Datenbank zeitgesteuert ausführt.
Ungewöhnlich ist auch die Arbeitsweise, die sich an der Fuse-Schnittstelle von Linux orientiert: Knoten sind für Vertex DB Verzeichnisse. In ihnen speichert die Datenbank Schlüssel-Wert-Paare. Schlüssel und Werte müssen Strings sein. Beginnt der Schlüssel mit einem Unterstrich »_« , repräsentiert der Wert im Knoten gespeicherte Nutzdaten, etwa das »_Alter« einer Person. Fehlt der Unterstrich, interpretiert Vertex DB den Wert als Verweis auf einen anderen Knoten.
Entsprechend sind die Datenbankanfragen den Dateisystemoperationen nachempfunden. Einen Knoten erzeugt der Anwender beispielsweise, indem er ein neues Verzeichnis über »mkdir« anlegt. Der entsprechende HTTP-Request sieht so aus:
GET /res/paula?action=mkdir
Ein Graph lässt sich leider bislang nur eingeschränkt oder umständlich per Hand traversieren. Seine Daten landen im Hintergrund in der eingebauten Tokyo-Cabinet-Datenbank [16].
Vertex DB gibt es in mehreren Implementierungen. Die ursprüngliche Fassung hatte ihr Entwickler noch in Ruby geschrieben. Es gibt mittlerweile auch Portierungen auf Lua und Javascript. Diese beiden Versionen verlangen im Gegensatz zu ihrer älteren Schwester alle Anfragen in einem speziellen Json-Format, die der Admin per HTTP-»POST« übermittelt.
Große Unterschiede im Testfeld
Funktionsumfang und Arbeitsweisen der getesteten Graphdatenbanken unterscheiden sich stark voneinander. Meist sind die Probanden auf bestimmte Arbeits- und Anwendungsbereiche zugeschnitten, es kann keine universelle Empfehlung für einen Kandidaten geben.
Neo4j ist von allen Kandidaten am längsten im Praxiseinsatz erprobt und bietet die meisten Schnittstellen zu Programmiersprachen. Die Datenbank empfiehlt sich besonders, wenn viele Graphendurchläufe anstehen und man diese flexibel steuern möchte. Neo4j findet sich zudem in verschiedenen Frameworks wieder, etwa in Bio4j, das Proteine verwaltet [17].
Sones Graph DB fühlt sich im Bereich des Informationsmanagements am wohlsten – also immer dann, wenn irgendwelche Dinge zu anderen in Beziehungen stehen oder der Programmierer Informationen miteinander verknüpfen muss. Die Sprache GQL ist zwar proprietär, dafür aber gerade für Umsteiger aus dem SQL-Umfeld schnell erlernt. Dummerweise ist der Funktionsumfang der Open-Source-Fassung stark beschnitten und niemand weiß im Moment so recht, wie es nach dem Insolvenzverfahren gegen Sones mit Graph DB weitergeht.
Java EE oder doch AI?
Wer auf Basis der Java Enterprise Edition eigene Webanwendungen entwickeln möchte, sollte Info Grid ins Visier nehmen. Die Datenbank spielt ihre Vorteile aus, wenn sie verschiedene Datenquellen aggregieren soll oder mit Beziehungen hantiert. Allerdings indiziert Info Grid die Properties nicht und kennt nur ungerichtete Kanten.
Hyper Graph DB spielt ihre Stärken im Bereich der künstlichen Intelligenz, der Sprachanalyse und dem Semantic Web aus – also genau dort, wo auch ihre Wurzeln liegen. Da der Entwickler der Datenbank nur Java-Objekte zu übergeben braucht, geht die Programmierung flott von der Hand. Im Gegenzug muss man mit Performance-Einbußen rechnen. Die Datenbankabfragen sind flexibel und mächtig, aber in komplexen Fällen auch schnell unübersichtlich.
Vertex DB ist noch jung, dafür aber auch klein, leichtgewichtig und schnell zu verstehen. Kanten lassen sich nicht mit Properties spicken und komplexe Traversierungen sind noch nicht möglich.
Alternative Zwitterwesen
Es gibt noch viele weitere Datenbanken, die ebenfalls Graphen einsetzen, aber eher als Zwitter einzustufen sind. So gehört beispielsweise Orient DB [18] eigentlich zu den dokumentorientierten Datenbanken, speichert aber Beziehungen als Graphen.
Darüber hinaus gibt es zahlreiche Graph-Bibliotheken, die ihre Graphen in normalen (SQL-)Datenbanken parken. Ein Beispiel hierfür ist Apache Hama [19]. Nimmt man es ganz genau, dann gehören eigentlich Hyper Graph DB und Vertex DB auch in diese Gruppe. Die Grenzen im Bereich der Graphdatenbanken sind eben fließend.
Infos
- Gremlin: https://github.com/tinkerpop/gremlin/wiki
- Representational state transfer: http://en.wikipedia.org/wiki/Representational_state_transfer
- ACID: http://de.wikipedia.org/wiki/ACID
- Benchmark für Graph DB: http://developers.sones.de/wiki/doku.php?id=benchmarks]
- Whitepaper für Graph DB: http://developers.sones.de/wiki/doku.php?id=whitepapers
- Lucene: http://lucene.apache.org
- Neoclipse: http://neo4j.org/download/
- Mathias Huber, “Die Simpsons in der Graphdatenbank”: https://www.linux-magazin.de/NEWS/Linuxtag-2011-Die-Simpsons-in-der-Graphdatenbank
- Tim Schürmann, “Affentheater”: Linux-Magazin 11/11, S. 38
- XPRISO: http://infogrid.org/wiki/XPRISO
- Hadoop: http://hadoop.apache.org
- Mesh World: http://infogrid.org/wiki/MeshWorld
- Net Mesh: http://netmesh.us
- Berkeley DB: http://de.wikipedia.org/wiki/BerkeleyDB
- JXTA-Protokoll: http://de.wikipedia.org/wiki/JXTA
- Tokyo Cabinet: http://fallabs.com/tokyocabinet/
- Bio4j: http://bio4j.com
- Orient DB:http://www.orientechnologies.com
- Apache Hama:http://incubator.apache.org/hama/





