
© Hiroshige Goto
Multicore-CPUs und GPUs modernster Bauart rechnen frühere Chipgenerationen in Grund und Boden – und das zum gleichen Preis und mit weniger Energie. Der folgende Blick auf aktuelle und demnächst kommende Rechenmeister macht klar: Numbercrunching verliert den Status des Reiche-Leute-Sports.
Der technische Fortschritt bei den Prozessorherstellern sorgt dafür, dass man für viele rechenintensive Aufgaben gar keinen Performance-Cluster mehr braucht. Es reicht eine Maschine mit mehreren Sockeln, in denen Multicore-CPUs neuester Bauart stecken. Wenn für Strömungs-, Physik- oder Partikelsimulation, große CAD-Projekte oder die rechenaufwändige Auswertung von Messdaten trotzdem ein Cluster nötig wird, dann reicht dank der gigantischen CPU-Leistung meist einer im Miniformat.
Den Vorreiter machten die Playstation-3-Cluster in US-Universitäten, die sich damit für kleines Geld die enorme Rechenpower der Cell-Chips erschlossen. Leider hat Sony aber Linux auf der PS3 Anfang April endgültig den Todesstoß versetzt [1], das Numbercunching-Proletariat muss sich nach anderen Optionen umsehen.
Intels aktuelle Beckton-CPUs
Kurz nach der Cebit stellte Intel seine erste Achtkern-CPU mit dem Codenamen Beckton vor, auch Nehalem EX genannt (Abbildung 2). Auch Intels erste Xeons der Core-i7-Nehalem-Generation sind Dies, die sich für Systeme mit mehr als zwei (bis zu acht) Sockeln eignen. Für Beckton hat Intel nicht nur einen neuen Chipsatz, sondern auch mit LGA 1567 einen neuen Sockel entwickelt. Ältere Xeon-MP-Systeme mit Socket 604 lassen sich damit nicht aufrüsten. Beckton verfügt je nach Ausführung über zwei bis vier QPI-Links, die 4,8 bis 6,4 Gigatransfers (ein Maß für die Übertragungsrate von Rohdaten) schnell sind.

Abbildung 2: Das Die-Foto zeigt Intels aktuellen Achtkern-Xeon Beckton.
Der gemeinsame L3-Cache ist 12 bis 24 MByte groß, auch Versionen mit sechs oder vier Kernen bietet Intel an – eine sogar ohne Hyperthreading und nur mit sechs Kernen, dafür aber mit 2,66 GHz Takt. Die Verlustleistung (TDP) liegt je nach Ausführung zwischen 95 und 130 Watt, der Takt zwischen 1,73 und 2,66 GHz. Für das Topmodell X7560 mit 2,26 GHz, 24 MByte L3-Cache und acht Kernen will Intel satte 3700 US-Dollar. Am unteren Ende der Preis- und Leistungsskala steht bei den Achtkernern der Dualsocket-X6550 mit 18 MByte L3-Cache und 2 GHz für 2460 Dollar.
Brücken bauen
Auf Intels Roadmap sind zwei Dinge für Numbercrunching interessant: Von der “Sandy Bridge”-Architektur, die die Firma wohl Anfang 2011 vorstellt, sind schon ein paar Details bekannt: Die in 32 Nanometer gefertigte CPU hat eine TDP von 150 Watt (bei acht Kernen), vier bis acht Kerne und integrierte Grafik.
Intel ändert dann abermals den Sockel und bringt gleich drei neue: LGA 2011 für Vier-Socket-Server, LGA 1356 für Entry-Server und Workstations bis zwei Sockets und LGA 1155 für Mainstream-Desktops. Jeder Kern hat 512 KByte L2-Cache, alle Kerne greifen auf 6 bis 20 MByte L3-Cache zu, der auch dem Grafikchip zur Seite steht. Die Kerne verbindet ein 256 Bit breiter Ringbus miteinander.
Software-seitig will die Sandy Bridge schon zum Start bedient sein, daher hat Intel schon Informationen zur Befehlserweiterung AVX (Advanced Vector Extensions, [2]) bekannt gegeben: Die Breite der SIMD-Wörter und damit das Rechenwerk wird von 128 Bit (XMM-Register) auf 256 Bit (YMM-Register) verbreitert. Somit verarbeiten Intels (und AMDs) künftige CPUs theoretisch doppelt so viele Daten wie bisher in einem SIMD-Befehl.
Die Änderungen, um AVX zu nutzen, sind für bestehenden SSE-optimierten Code marginal. Programme müssen die Datenstrukturen lediglich für möglichst effiziente Abarbeitung etwas umarrangieren, da sich der Prozessor nun in 32-Byte-Schritten statt in 16-Byte-Schritten durch den Datenberg arbeitet.
Ebenfalls neu in AVX: Die Befehle können nun alle mit bis zu vier Operanden arbeiten statt mit zweien, was das non-destruktive Rechnen mit Operanden erlaubt, so funktioniert neben »a=a+b« nun auch »c=a+b« – dank VEX-Präfix auch mit bekannten SSE-Befehlen.
Das 2 bis 3 Byte lange VEX-Präfix steht vor den neuen AVX- oder den alten SSE-Befehlen und definiert die Funktionsweise des folgenden Befehls. AVX sieht sogar eine spätere Erweiterung der Registerbreite auf 512 oder gar 1024 Bit vor und das Rechnen mit bis zu fünf Operanden – statt die Entwickler ständig mit neuen Befehlserweiterungen zu konfrontieren, denkt Intel hier offensichtlich weiter.
AVX braucht im Zuge der Abwärtskompatibilität explizite Unterstützung durchs Betriebssystem, ohne diese sind die neuen Befehle nicht nutzbar. Für die proprietäre Welt ist Windows 7 Pflicht, Linux ist bereits seit Kernel 2.6.30 (Juni 2009) vorbereitet. AVX-Unterstützung gibt es im GCC in Version 4.4 ab Revision 143117.
Larrabee: Schwere Geburt
Wenig bekannt ist über Intels kommenden Supercomputing-Chip Larrabee [3]. Ursprünglich sollte das 2008 angekündigte Rechenwunder primär als Grafikchip fungieren (Abbildung 1). Ende 2009 positionierte Intel den Chip aber als Applikationsbeschleuniger um und zeigte einen übertakteten Chip, der 1 Teraflops (mit einfacher Präzision) rechnete. Die für 2010 geplante Einführung ist nun auf unbestimmte Zeit verschoben. Dem Vernehmen nach scheitert Intel am Unwillen der Spiele-Entwickler, ihre Software an die GPU zupassen.
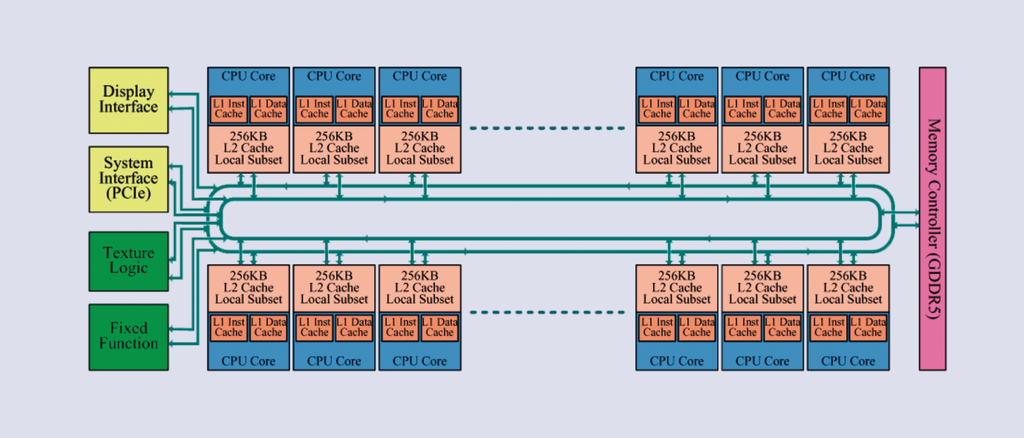
Abbildung 1: Das Blockdiagramm von Intels mehrfach verschobenem Larrabee. Der bidirektionale Ringbus ist 1024 Bit breit – 512 Bit in jeder Richtung.
Larrabee darf man als Intels Antwort auf den in der Playstation 3 und in großen Top-500-Clustern enthaltenen Cell-Chip von Sony, IBM und Toshiba verstehen: Viele einfache In-Order-Kerne mit kurzer Pipeline, 64 KByte L1- und 256 KByte L2-Cache und reichlich Vektor-Rechenpower, die über eine sehr schnelle Ringstruktur miteinander verbunden sind. Larrabees Kerne basieren auf dem P54C-Design des Pentium I, das Intel jedoch um 64-Bit-Fähigkeit sowie 512 Bit breite SIMD-Einheiten erweitert.
Einen normalen Prozessorkern wie das PPE des Cell-Chips hat Larrabee jedoch nicht, er entspricht somit eher Toshibas Cell-Derivat “Spurs Engine”. Ein Vorteil gegenüber Cell ist, dass Intel Larrabee Cache-Kohärenz über alle Kerne spendiert – bei den SPU-Kernen des Cell mit 256 KByte integriertem Arbeitsspeicher sucht man so etwas vergebens. Dank der Cache-Kohärenz adressieren alle Kerne einen linearen Speicher – eine Cell-CPU wickelt Speicherzugriffe extern über das PPE ab, das sich auch um die Kohärenz kümmern muss (Abbildung 4).
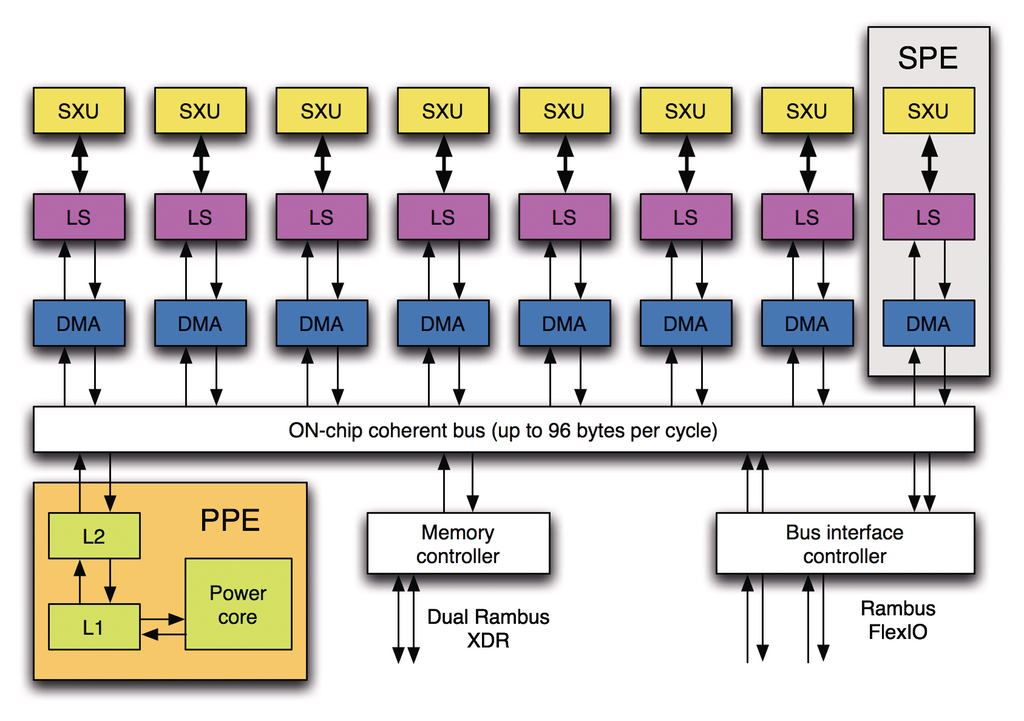
Abbildung 4: Die Cell-CPU, bekannt aus Playstation 3 und Top 500, wickelt Speicherzugriffe über das PPE ab.
Der bidirektionale Ringbus ist 1024 Bit breit – 512 Bit in jeder Richtung (Abbildung 1). Jeder Kern hat vierfaches simultanes Multithreading (SMT, das Intel Hyperthreading nennt). Intel nutzt SMT seit Pentium 4, Sun beim Niagara und IBM bei Cell, Power6 und 7.
Verwirrende Strategie
Natürlich setzt Intel bei Larrabee auf den x86-Befehlssatz – angereichert um spezielle Vektorbefehle (LRBni genannt, [4]), für welche die Firma den 3D-Grafik-Guru Michael Abrash als Berater hinzugezogen hat. Gleichwohl werden normale Programme und Betriebssysteme darauf ohne Neukompilieren nicht darauf laufen. Es stellt sich die Frage, warum Intel nicht gleich ein eigenes Instructionset für Larrabee geschaffen hat, das ohne den an Transistoren reichen x86-Befehlsdecoder auskommt.
Auf Nachfrage des Linux-Magazins erläutert Intel, dass die Ausgangsbasis für Larabee-Anpassungen meist x86-basierte Projekte seien, was den Einstieg in die Entwicklung erleichtern solle. Zurzeit warte Intel das Entwickler-Feedback ab und will dann entscheiden, wann und welche Produkte daraus werden.
AMDs Portfolio
Der Hersteller aus Sunnyvale kann Intel momentan in der Leistung pro Kern zwar nicht das Wasser reichen, schlug aber bei der Vorstellung der “Magny Cours”-Zwölfkerne dennoch Wellen im Server- und Supercomputing-Teich. Nicht nur, dass bei AMD jetzt zwölf Kerne deutlich weniger kosten als die acht Kerne bei Intels Beckton, auch die so genannte “Four Socket Tax” plant AMD abzuschaffen: Bisher waren Systeme mit vier Sockeln unverhältnismäßig teurer als zwei mit zwei Sockeln.
Doch auch Intel schläft nicht, so kostet der Xeon X7550 für Acht-Sockel-Systeme nur 270 US-Dollar mehr als der ansonsten gleich ausgestattete Dual-Socket-X6550. AMDs günstigster Dodeca-Core, der Opteron 6168 mit 1,9 GHz, steht mit gerade einmal 750 US-Dollar in der Preisliste (preislich identisch zu Intels Einstiegs-Quadcore-Beckton E6510). AMDs Top-End markiert der 2,3-GHz-6176-SE mit 1400 US-Dollar. Stromfresser sind AMDs Dutzendkerne trotz 45-Nanometer-Prozess erstaunlicherweise nicht: Außer dem Topmodell (105 Watt TDP) sind alle Magny Cours mit 80 Watt TDP spezifiziert. AMD hat auch drei niedriger getaktete “HE”-Versionen mit nur 65 Watt im Angebot. Erste Benchmarks [5] bescheinigen den zwölf AMD-Kernen eine zu Intels acht Kernen vergleichbare Leistung – nur kosten die AMD-CPUs weniger und benötigen halb so viel Strom [6].
Wie Intels Beckton eignet sich auch der Magny Cours leider nicht zum Aufrüsten älterer Systeme, er setzt statt des gängigen Sockets F den neuen Socket G34 voraus. Magny Cours hat je nach Ausführung acht oder zwölf Kerne auf zwei in einem Gehäuse untergebrachten Dies (MCM, Multi Chip Module), 512 KByte L2-Cache pro Kern sowie pro Die 6 MByte gemeinsamen L3-Cache. Vier Hypertransport-Links in Version 3.1 verbinden Chips und Außenwelt sowie die Sockel mit niedriger Latenz untereinander. Jeder Prozessor kann theoretisch über vier HT-Links maximal insgesamt 25,6 Gigatransfers oder 204,8 GByte pro Sekunde bewegen.
Bulldozer im Anmarsch
2011 soll eine völlig neue Architektur mit dem markigen Namen “Bulldozer” kommen, das im Gegensatz zur moderaten K8-Weiterentwicklung K10 ein völliges Neudesign sein soll. Zuerst kommen wohl “Valencia” genannte Chips auf den Markt, die Bulldozer-Opterons werden dann zahlreiche Befehlerweiterungen besitzen, neben allen aktuellen Intel-Sets (SSE4.1 und 4.2, AES-NI, CLMUL) auch Intels kommendes AVX.
Ursprünglich hat AMD für Bulldozer an SSE5 gewerkelt, das ein DREX genanntes Präfix ähnlich wie Intels VEX-Präfix verwendete. Um kompatibel zu bleiben, änderte AMD SSE5 in XOP, was Befehlskompatibilität mit Intels VEX-Präfix und damit AVX herstellt. Auch das geplante FMA3, eine Erweiterung für das beim Supercomputing wichtige FMA (Fused Multiply Add, Multiplikation mit Addition in einem Befehl), wird sich der Bulldozer aufladen – per VEX-Präfix implementiert. Intel integriert FMA3 als Teil von AVX, Bulldozer kennt zusätzlich auch FMA4. FMA3 kann nur mit drei Operanden rechnen (»b=b+c*d«), während FMA4 vier erlaubt (»a=b+c*d«). Da FMA4 bei Veröffentlichung der ersten AVX-Spezifikation bereits ins Bulldozer-Design integriert war, hat AMD dies beibehalten.
Es werden Zwillinge
Pro Kern gibt AMD eine Verlustleistung von 2,5 bis 25 Watt an. Jeweils zwei Kerne bilden ein Modul, das zwei Threads abarbeitet und sich den L2-Cache und die Fließkomma-Einheiten teilt. Entweder nutzt ein Kern die gesamten 256 Bit Breite oder jeder Kern 128 Bit. Dies wirkt wie AMDs Antwort auf Intels Hyperthreading, ist aber ein altbekannter Ansatz: Die erste Implementierung von 128-Bit-SSE2 in der K8-Generation löste AMD ähnlich. Bulldozer schafft somit nur halb so viele 256-Bit-Rechnungen wie Intel, was die Fließkommaleistung aller Kerne theoretisch halbiert. Da gängiger SSE-Code seine Daten allerdings mit 128 Bit adressiert, wird dies zunächst kein Nachteil sein, auf Dauer und bei HPC aber möglicherweise schon. Eventuell hat AMD ja noch ein Ass im Ärmel und schiebt Fließkommarechnungen auf den ebenfalls integrierten Grafikkern.
Wie groß der L3-Cache wird, ist noch unklar. AMD will den mit 1 MByte L2-Cache pro Modul ausgestatteten Chip mit bis zu 16 Kernen (acht Module) in 32 Nanometern fertigen. Intel will schon 2011 auf 22 Nanometer umstellen, während AMDs Fertigungspartner Global Foundries später im Jahr die Umstellung auf 28 Nanometer plant.
Vor dem Bulldozer fährt noch in diesem Jahr ein Opteron-Update namens Lisbon vor. Die als günstige Single- und Dual-Socket-Alternative zu Magny Cours gedachten 4xxx-Opterons werden vier oder sechs Kerne haben und auf dem Socket C32 sitzen. Die Socket-F-inkompatiblen Lisbon-Opterons sprechen genau wie Magny Cours nur mit DDR3-RAM.
AMD Fusion
Schon lange angekündigt soll “Fusion” Anfang 2011 kommen – die Vereinigung von CPU und GPU. Wegen der engen Verdrahtung eignet sich der Grafikchip auch gut fürs Numbercrunching – und was die Grafikkerne nicht schaffen, rechnet automatisch und latenzfrei die CPU. Wenig gibt AMD bisher dazu bekannt, aber seit der ISSCC im Februar 2010 ist klar: Der mit vier 32-Nanometer-Bulldozer-Kernen ausgeführte “Llano” (Abbildung 3) wird die erste High-Performance-Implementierung von Fusion werden, während “Ontario” als System-on-a-Chip in stromsparenden Geräten Einzug hält.
Abbildung 3: AMDs Bulldozer-Modul mit zwei Kernen einer Llano-APU.
AMD nennt die Fusion aus CPU und GPU “APU” (Accelerated Processing Unit). Während die Kerne nur 35 Millionen Transistoren brauchen, hat das gesamte Design eine Milliarde – inklusive 1 MByte Level-2-Cache und integriertem DDR3-Speichercontroller. Einen Level-3-Cache sieht AMD für Llano nicht vor. Über den integrierten Grafikkern ist nur bekannt, dass er zur HD-5xxx-Generation gehört.
Jenseits des Mainstreams
IBM hat fürs Numbercrunching mit dem neuen Power7 (Abbildung 5) die zurzeit leistungsfähigste CPU überhaupt im Programm. Preise dafür sind nicht in Erfahrung zu bringen. Das bis zu 4,1 GHz getaktete Achtkern-Monster, das dank SMT vier Threads pro Kern ausführt und über vier Fließkomma-Einheiten verfügt, ist dabei kein Stromfresser: IBM verspricht die vierfache Power6-Rechenleistung bei gleichem Stromverbrauch und sieht sich in der Disziplin Gigaflops/Watt auch klar vor der Konkurrenz.

Abbildung 5: IBM-Rack auf der Cebit 2010 mit Power7-Einschüben.
Die Big-Blaumänner erreichen das durch Einsatz von Transistoren sparendem EDRAM-L3-Cache statt des üblichen SRAM. Mit 32 MByte gemeinsamem L3-Cache und 256 KByte L2-Cache pro Kern benötigt der Power7 insgesamt “nur” 1,2 Milliarden Transistoren – Intels Achtkern-Beckton (24 MByte L3-Cache) und AMDs Zwölfkern-Magny-Cours (12 MByte L3) brauchen über zwei Milliarden. Das auf 256 Bit verbreiterte Rechenwerk liefert dabei 33 Gflops Rechenleistung pro Kern (265 Gflops insgesamt).
Speziell für Supercomputer bringt IBM ein MCM mit vier Power7 heraus, das über 1 Teraflops Rechenpower bietet – und dies ohne Vektor-SIMD, obwohl der Power7 auch ein auf doppelte Präzision erweitertes Altivec namens VSX integriert. Von In-Order beim Power6 wechselt Power7 wieder zum bewährten, ursprünglich von IBM erfundenen Out-of-Order-Design zurück.
Power6-kompilierte Software läuft auch auf Power7-CPUs. Nativ unterstützt IBM das hauseigene AIX 5.3 und 6.1, IBM i 6.1 und natürlich Linux in Form von SLES 10 SP3 und SLES 11. Auch Red Hat hat RHEL 5 für Power7 angepasst. Zum Kompilieren können Linux-User IBMs XL-Compiler [7] nehmen, den es kostenpflichtig bei Absoft gibt. IBM hat aber auch Patches in GCC eingebracht und liefert die so genannte Advance Toolchain in Version 2.1-1 mit Power7-optimiertem GCC und passenden Libraries als RPM aus. Für das Power7-Linux-Gespann betreibt IBM eine eigene FAQ-Seite [8].
Ohne Bild: GPUs und Cuda
Im Supercomputing-Bereich gewinnen die zunehmend flexibler programmierbaren GPUs an Popularität. Die Hersteller bringen daher speziell für Numbercrunching optimierte Versionen ohne Grafikanschluss und mit mehr RAM heraus: Nvidia die Tesla-Geräte [9], ATI die Firestream-Karten [10]. Mit der neuen Fermi-Generation bietet Nvidia mit 630 Gigaflops viermal so viel Fließkommaleistung in doppelter Präzision wie der Vorgänger. Neu an Fermi ist auch, dass Nvidias Compiler neben C nun auch C++ unterstützt. Extra fürs Supercomputing hat Nvidia auch Speicher-Fehlerkorrektur integriert, was bei ATI fehlt.
Der Stromverbrauch der Tesla C2070 mit 6 GByte RAM hält sich mit 130 Watt in Grenzen. Für die Tesla C2070 will Nvidia 4000 US-Dollar, für die kleinere C2050 mit 3 GByte und niedrigerem Takt 2500 Dollar. Auch 1-U-Rack-Versionen mit vier Teslas bietet Nvidia an. Die Oak Ridge National Labs [11] kündigten im Oktober 2009 an, an einem Fermi-Supercomputer zu bauen, der mit 10 Petaflops die Führung der Top 500 übernehmen soll.
ATIs Firestream scheint hingegen etwas zu lahmen, aktuell ist immer noch die dritte Generation (92×0) von 2008 auf Basis des alten RV770-Kerns. Firestream-Karten auf Basis der aktuellen Radeon HD 5xxx (“Evergreen”) sind noch nicht angekündigt. Das Top-Modell Firestream 9270 mit 2 GByte RAM liefert 1200 Gigaflops in einfacher Präzision und 240 in doppelter. Es verbraucht dabei 160 Watt und kostet 1500 US-Dollar.
Ohne Ketten: Open CL
Mit dem neuen, von Apple und anderen vorangetriebenen Open CL (Open Compute Library) gibt es endlich einen herstellerunabhängigen Standard zur GPU-Programmierung. Nvidia unterstützt parallel weiterhin ihr inzwischen recht populäres Cuda-API (siehe Artikel), wofür es dank Portland-Group nun sogar einen Fortran-Compiler gibt [12].
Da Open-CL-Code auch auf den SIMD-Einheiten normaler CPUs läuft – und sogar auf dem Cell -, ist Portierbarkeit gegeben, sodass sich niemand an einen Hersteller binden muss. Sowohl Nvidias als auch ATIs Open-CL-SDKs sind für Linux verfügbar ([13], [14]). Entwickler bescheinigen Nvidias Open-CL-Implementierung aber den ausgereifteren Status.
Damit darf man rechnen
Spannende Zeiten stehen Anwendern bevor, die viel zu rechnen haben. Neue Techniken wie GPU-Computing und Open CL machen Rechenleistung so billig und einfach verfügbar wie nie zuvor. Innerhalb weniger Jahre werden die programmierbaren Grafikchips wohl noch flexibler und zusammen mit Open CL die Top 500 der Supercomputer infiltrieren. Zu groß sind die Performance- und Leistung-pro-Watt-Vorteile im Vergleich zu CPUs (siehe Abbildung 6). (jk)
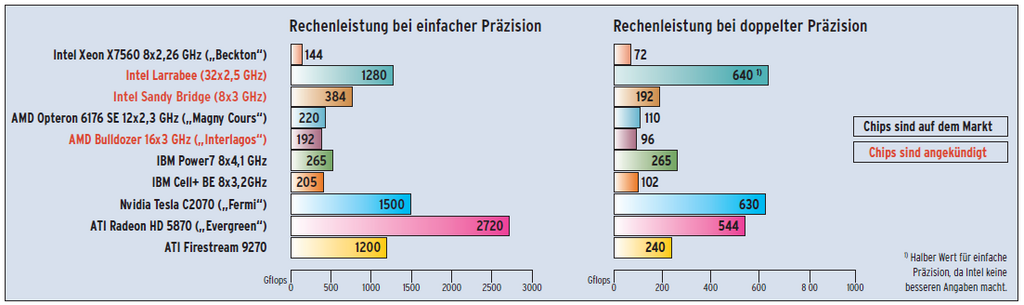
Abbildung 6: Rechnerische Gigaflop-Maximalwerte der in diesem Artikel beschriebenen Chips jeweils für einfache und doppelte Genauigkeit.





