
Die meisten Programme zur Anzeige der CPU-Auslastung wie Top und Xosview bedienen sich aus dem »/proc«-Dateisystem des Linux-Kernels. Unter bestimmten Umständen liefert diese Schnittstelle jedoch unkorrekte Werte. Das beschriebene Patch behebt das Problem.
Der Lehrstuhl für Technische Informatik der Universität Heidelberg entwickelt zurzeit Datenauslesesysteme, von denen einige aus Linux-Clustern mit bis zu 1000 Knoten bestehen werden. Geplant ist ihr Einsatz für ehrgeizige Großexperimente der Elementarteilchen- und Schwerionenphysik
In diesem Rahmen untersucht eine Arbeitsgruppe effiziente Mechanismen der Netzwerkkommunikation, um die Prozessorauslastung beim Übertragen von Daten möglichst gering zu halten. Dabei interessiert besonders der in der vorgegebenen Konstellation minimal mögliche Overhead bei Netzwerkübertragungen unter Benutzung der unmodifizierten Netzwerkkarten-Treiber.
Zu diesem Zweck haben wir, die Autoren dieses Beitrags, ein kleines Kernelmodul entwickelt, das Daten aus einem Programm ohne ein komplexes Protokoll wie TCP/IP über das Netzwerk versendet. Dieses Modul erzeugt unterschiedliche Netzwerklasten, um die CPU-Auslastung in Abhängigkeit von der Datenübertragungsrate zu messen.
Seltsame periodische Schwankungen
Im Verlauf dieser Messungen beobachteten wir jedoch auf einem Dualprozessor-System ein Phänomen: Die Last des Systems schwankte bei prinzipbedingt konstanter Datenübertragungsrate zwischen null Prozent und einem von der Übertragungsrate abhängigen Maximalwert. Das betraf sowohl den Sender als auch den Empfänger der Daten.
Diese Schwankungen traten mit einer Periode auf, die in der Größenordnung von mehreren 100 Sekunden lag. Ein Beispiel für eine derartige Messung zeigt Abbildung 1. Der uns anfänglich nicht erklärbare Effekt trat allerdings nur auf, wenn die Übertragungsrate durch Aufrufe der »usleep«-Funktion auf einen bestimmten Wert gedrosselt wurde, aber nicht bei Nutzung der vollen Netzwerkbandbreite.
Ein ähnliches Verhalten zeigt ein kleines Testprogramm, das außerhalb des Kernels Daten im Speicher per »memcpy« kopiert. Die Rate, mit der es die Daten kopiert, ist dabei ebenfalls über »usleep« auf einen bestimmten Wert geregelt. Aufrufe desselben Programms auf einem System mit einem Uniprozessor-Kernel zeigten dagegen eine kaum messbare CPU-Last (knapp über null Prozent), obwohl 80 MByte/s kopiert wurden.
Wo ist Harvey?
Dadurch angeregt kam in der Arbeitsgruppe der Verdacht auf, dass unsere Programme der Prozessüberwachung des Linux-Kernels ein Schnippchen schlagen und für diese zumindest teilweise unsichtbar sind. Zur Überprüfung des Verdachts entwickelten wir ein Programm, das in einer Endlosschleife abwechselnd rechnet und schläft.
Aufgrund seiner Fähigkeit, vor dem Prozess-Accounting des Standardkernels verborgen zu bleiben, haben wir es Harvey (nach dem Filmklassiker “Mein Freund Harvey”) genannt (siehe Listing 1). Die in Zeile 13 beginnende Endlosschleife enthält die beiden Funktionsblöcke zum Rechnen und Schlafen. Während des Rechnens bestimmt Harvey durch wiederholtes Aufrufen von »gettimeofday« die für diesen Block bereits verstrichene Zeit.
Sobald die durch »RUNTIME« festgelegte Zeit abläuft, gibt Harvey durch den Aufruf von »usleep( 0 )« den verbleibenden Rest seiner Zeitscheibe (vergleiche Kasten “Der Scheduler”) ab. Abbildung 2 zeigt einen Screenshot von Top, während Harvey läuft. Scheinbar erzeugt Harvey keine Last auf dem System und zeigt somit das gleiche Verhalten wie die anderen Programme.
Da es sehr unwahrscheinlich ist, dass ein Prozess, der 90 Prozent seiner Laufzeit in einer Schleife arbeitet, keine messbare Prozessorlast erzeugt, haben wir die Auslastung mit dem in Listing 2 gezeigten Programm CPUmeter gemessen. Die While-Endlosschleife des Programms bestimmt in der Funktion »get_iterations« die Anzahl von Schleifendurchläufen pro Sekunde. Wird es mit der niedrigsten Priorität gestartet, erhält es vom Scheduler weniger CPU-Zeit, sobald mindestens ein anderer Prozess im System lauffähig ist.
Dadurch ist die Anzahl der in jeder Sekunde abgearbeiteten Iterationen ein Maß für die tatsächliche Auslastung eines Prozessors: Je weniger Iterationen, desto größer ist die Last. Benutzt man nun CPUmeter, zeigt sich, dass Harvey auf dem System eine Last von etwa 90 Prozent erzeugt – wie man es aufgrund des Listings auch erwarten würde.
Dem Kernel auf die Finger geschaut
Die von Top & Co. benutzte Schnittstelle »/proc/stat« liefert die CPU-Last lediglich in Einheiten von Zeitscheiben. Das legt den Verdacht nahe, dass auch der Kernel mit dieser Granularität abrechnet. In den Quellen des Standardkernels ist »fs/proc/proc_misc.c« für die Ausgabe der Pseudo-Datei »/proc/stat« zuständig, wie sich mit[1] feststellen lässt.
Die dort verwendete Struktur »kstat« enthält unter anderem die gesuchten Daten über die von jeder CPU verbrauchten Zeitscheiben. Jede gehört einer der drei Kategorien »user«, »nice« und »sys« an. Der globale Zähler »jiffies« dient dazu, nicht verbrauchte Zeitscheiben ausgeben zu können, die Kernel-intern die so genannte Idle-Task verbraucht oder eben nicht verbraucht.
Gesetzt werden diese Strukturkomponenten von der Funktion »update_process_times« in der Datei »kernel/timer .c«, die Timer-Interrupt-Routinen nach Ablauf jeder Zeitscheibe aufruft. Die Funktion prüft, welcher Prozess gerade aktiv ist; falls es nicht der Idle-Prozess ist, inkrementiert sie einen der drei Zähler »user«, »nice« oder »sys«. An der gleichen Stelle entscheidet sich auch, welchem Prozess die abgelaufene Zeitscheibe zuzuschreiben ist: Eine Zeitscheibe ist immer dem zum Zeitpunkt ihres Ablaufs aktiven Prozess zugeordnet. Falls kein Prozess zu diesem Zeitpunkt aktiv ist, verbucht der Kernel die Zeitscheibe als unbenutzt.
Mit diesem Hintergrund lässt sich nun auch das bemerkenswerte Verhalten von Harvey und der anderen Programme verstehen: Das Abgeben der Zeitscheibe durch die »usleep«-Funktion führt dazu, dass kein Prozess in »update_process_ times« als aktiv markiert ist. Dementsprechend zählt die Routine die Zeitscheibe als unverbraucht, obwohl sie zum Teil genutzt wurde.
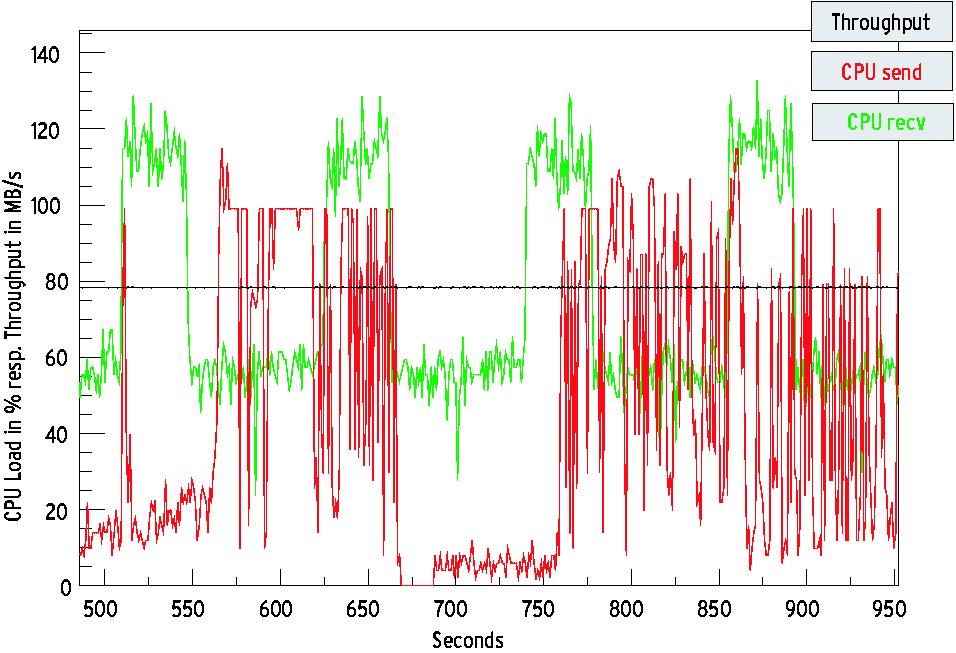
Abbildung 1: Seltsame Schwankungen bei der Prozessorauslastung und dem Durchsatz bei einem Netzwerktransfer zwischen zwei SMP-Systemen.
Phänomen wurde schon früher beobachtet
Eine Google-Suche nach entsprechenden Hinweisen lieferte uns die Erkenntnis, dass wir auf kein unbekanntes Problem gestoßen waren: Bereits Anfang 2000 hatte Jan Astalos ein entsprechendes Patch für Uniprozessor-Systeme unter Kernel 2.2.14 entwickelt[2]. Dies Patch zählt mit Hilfe des in neueren Prozessoren vorhandenen Time Stamp Counters (TSC) die von jedem Prozess verbrauchten Taktzyklen.
Auf unsere Anfrage nach einer neueren und SMP-fähigen Ausgabe schickte Jan eine Version für 2.4.0, die den Ausgangspunkt der Portierung auf den vorliegenden aktuelleren Kernel bildete. Zusätzlich erweiterten wir das Patch um die Fähigkeit, die abgelaufenen CPU-Zyklen global sowie nach CPUs aufgeteilt zu summieren und dabei die in Interrupts und Soft-IRQs verbrauchten zu berücksichtigen. Letzteres war für die am Lehrstuhl vorgesehenen Netzwerkmessungen von entscheidender Bedeutung.
|
Listing 1: |
|---|
01 #include <unistd.h>
02 #include <sys/time.h>
03
04 /* Laufzeit in Mikrosekunden */
05 #define RUNTIME 9000
06
07 int main( int argc, char** argv )
08 {
09 unsigned long n=0;
10 unsigned long t;
11 struct timeval s, e;
12
13 while ( 1 )
14 {
15
16 /* Rechnen */
17 gettimeofday( &s, NULL );
18 do
19 {
20 n++;
21 gettimeofday( &e, NULL );
22 t = (e.tv_sec-s.tv_sec)*1000000
23 +(e.tv_usec-s.tv_usec);
24 }
25 while ( t < RUNTIME );
26
27 /* Schlafen */
28 usleep( 0 );
29 }
30 }
|
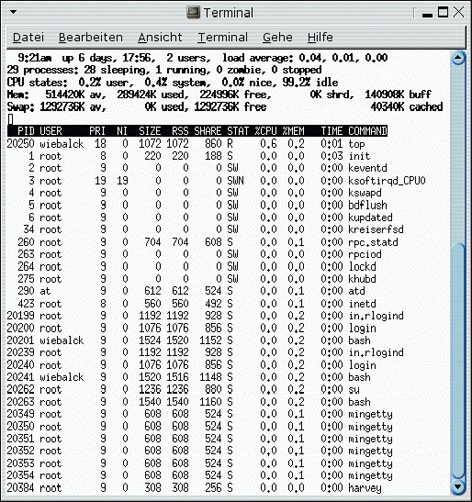
Abbildung 2: Top bei laufendem Harvey-Programm.
Einschub einer Update-Funktion
Im Gegensatz zum Prozess-Accounting des Standardkernels, das wie beschrieben nur am Ende jeder Zeitscheibe passiert, rufen wir die Funktion »update_pro- cess_cycles« (Listing 3) auf, kurz bevor der Scheduler die CPU einem neuen Prozess zuweist.
Daher erfolgt der Aufruf der Funktion ja auch in der Datei »kernel/ sched.c«. Mit den Zeilen 3 bis 5 (wieder in Listing 3) bestimmt die Funktion zunächst den noch aktuellen Prozess und die aktive CPU sowie den aktuellen Wert des TSC. Die Zeile 7 aktualisiert das der Prozess-Struktur hinzugefügte Array »cycles«. Das zu diesem Zweck benutzte »last_cycles«-Array enthält den Wert des TSC für die betreffende CPU zum Zeitpunkt des letzten Aufrufs der »update_process_cycles«-Funktion (Zeile 10).
In den Zeilen 8 und 9 wird der globale Zähler gesetzt, der die verbrauchten Taktzyklen pro CPU enthält. Das geschieht jedoch immer nur dann, wenn der aktuelle Prozess nicht der Idle-Prozess mit der Prozess-ID (PID) 0 ist. In gleicher Art und Weise verbuchen entsprechende Kernelfunktionen die zur Bearbeitung jedes Interrupts und Soft-IRQ verbrauchten CPU-Zyklen, was aber für das Verständnis der Funktion nicht von Bedeutung ist.
|
Listing 2: |
|---|
01 #include <stdio.h>
02 #include <sys/time.h>
03 #include <unistd.h>
04
05 #define TIME 1000000
06
07 unsigned long long get_iterations( unsigned long t_musec )
08 {
09 unsigned long long n = 0;
10 struct timeval s, e;
11 unsigned long tdiff;
12 gettimeofday( &s, NULL );
13 while ( 1 )
14 {
15 n++;
16 gettimeofday( &e, NULL );
17 tdiff = (e.tv_sec-s.tv_sec)*1000000+(e.tv_usec-s.tv_usec);
18 if ( tdiff >= t_musec )
19 break;
20 }
21 return n;
22 }
23
24 int main( int argc, char** argv )
25 {
26 unsigned long long cur;
27
28 while ( 1 )
29 {
30 cur = get_iterations( TIME );
31 printf( " %20Lu iter./sn", cur );
32 }
33 return 0;
34 }
|
Ausgabe per »/proc/stat«
Die Ausgabe der ermittelten Werte erfolgt wie beim normalen Prozess-Accounting ebenfalls über das »/proc«-Pseudo-Dateisystem des Kernels. »/proc /stat« listet die Anzahl der von den Prozessen, Interrupts und Soft-IRQs verbrauchten, der nicht beanspruchten sowie die Gesamtanzahl der verstrichenen Takte. Jeder Wert wird sowohl als Summe über alle CPUs als auch für jede CPU einzeln angegeben.
Die von jedem einzelnen Prozess verbrauchten Taktzyklen kann man aus »/proc/ PID/stat« erkennen – wieder sowohl pro CPU als auch summiert. Eine genauere Aufteilung der von Interrupts und Soft-IRQs verbrauchten Zyklen enthält »/proc/interrupts_cycles«. Ein Beispiel der Ausgabe dieser Pseudo-Datei zeigt Listing 4: Die Zeilen, die mit einer Zahl beginnen, enthalten die Zyklen der entsprechenden Interrupts, die letzten vier Zeilen entsprechen den vier Spielarten von Soft-IRQs.
Die mit dem gepatchten Kernel gemessenen Werte für die durch unsere Programme verursachten Systemlasten decken sich mit denen von CPUmeter – und dem gesunden Programmiererverstand. Als Beispiel zeigt Abbildung 3 einen Vergleich der von Harvey verursachten Last, wie sie der Standardkernel und der gepatchte Kernel messen. Wie man sieht, versteckt sich Harvey erfolgreich vor dem normalen Kernel, dem gepatchten Kernel dagegen entgeht seine Aktivität nicht. Auch auf SMP-Systemen zeigt der Patch-Kernel die von den Programmen verursachte Last korrekt an.
Latenzzeit steigt
Um die Auswirkungen des Patches auf die Performance des Schedulers zu ermitteln, bedienten wir uns der Benchmark-Suite LMbench[3], die wir sowohl auf einem gepatchten als auch einem ungepatchten Uniprozessor-Kernel laufen ließen. Die von diesem Benchmark gemessenen Werte für die Latenz eines Kontextwechsels sind in Tabelle 1 angegeben. Man erhält die erhöhte Genauigkeit des Accountings nur um den Preis einer um zirka zehn Prozent erhöhten Latenzzeit beim Kontextwechsel.
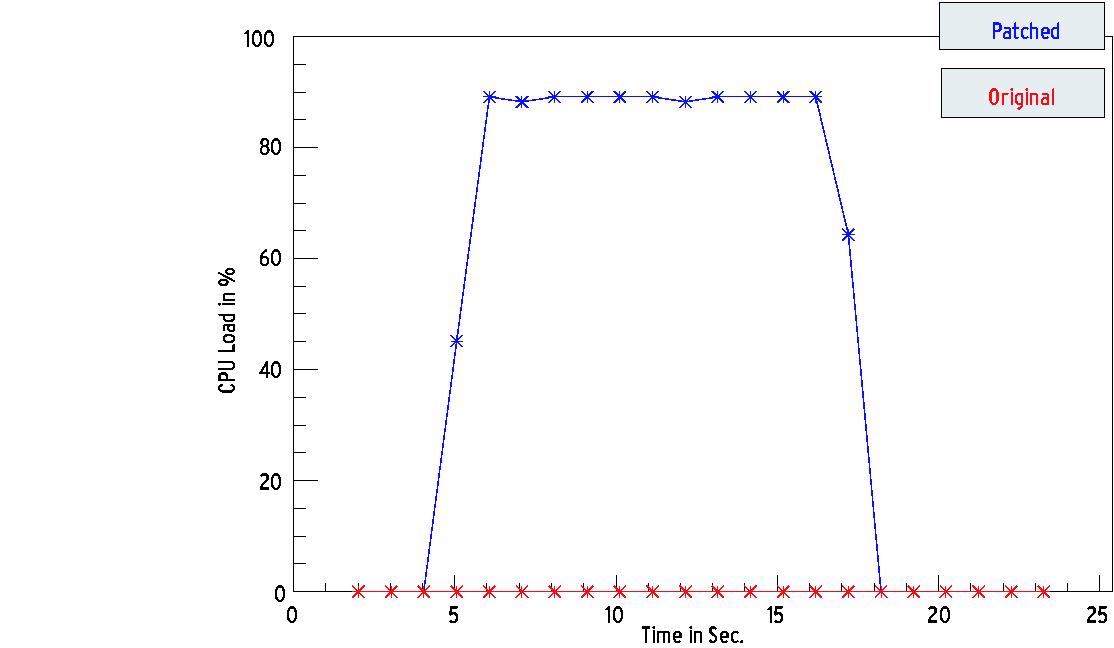
Abbildung 3: Harvey wird enttarnt – Vergleich von originalem und gepatchtem Kernel.
Fazit
Die Implementierung des Prozess-Accountings im Linux-Kernel kann unter bestimmten Bedingungen irreführende Werte für die Systemlast liefern. Ursache hierfür ist die auf Zeitscheiben basierende Granularität, mit der der Kernel verbrauchte Rechenzeit verbucht.
Anhand der zwei vorgestellten Testprogramme Harvey und CPUmeter lässt sich das Problem leicht nachvollziehen. Das im Artikel beschriebene und unter[4] zu findende Kernel-Patch implementiert eine auf den Time-Stamp-Counter-Registern der CPU basierende Methode des Prozess-Accountings, die unter den getesteten Bedingung zuverlässige Werte für die Last liefert. Die dabei im Gegenzug steigende Latenz wird meist zu verkraften sein. (jk)
|
Infos |
|---|
|
[1] Linux-Reference: [http://lxr.linux.no/] [2] 2.2.14 Precise Accounting Patch Posting: [http://www.beowulf.org/pipermail/beowulf/2000-February/008415.html] [3] LMbench-Homepage: [http://www.bitmover.com/lmbench] [4] Precise Accounting Patch: [http:// www.ti.uni-hd.de/HLT/documentation/software-and-documentation.html#kernel] |
|
Die |
|---|
|
Dipl.-Phys. Arne Wiebalck, Dipl.-Phys. Timm Steinbeck und Prof. Dr. Volker Lindenstruth arbeiten am Lehrstuhl für Technische Informatik der Universität Heidelberg an der Entwicklung von Datenauslesesystemen für Teilchenphysik-Experimente. Die dabei eingesetzten Linux-Cluster müssen aufgrund der besonderen Anforderungen auch Teilausfälle des Systems tolerieren und über effiziente Kommunikationsmechanismen verfügen. |
|
Tabelle |
||||
|---|---|---|---|---|
|
Prozessgröße |
Latenz ungepatcht |
Latenz gepatcht |
||
|
0 KByte |
0,89 |
µs |
0,97 |
µs |
|
4 KByte |
1,02 |
µs |
1,11 |
µs |
|
16 KByte |
4,31 |
µs |
4,44 |
µs |
|
Der |
|---|
|
Linux ermöglicht es, Prozesse auf einer CPU gleichzeitig laufen zu lassen, indem es die verfügbare Rechenzeit in Zeitscheiben teilt. Die Entscheidung, welcher Prozess wann eine Zeitscheibe erhält, trifft der so genannte Scheduler. Nach seinem Scheduling-Algorithmus wählt er aus der Liste einen lauffähigen Prozess und übergibt ihm die CPU eine Zeitscheibe lang. Unter Linux ist diese Zeit typischerweise 10 ms lang. Die Länge dieser Zeitscheibe ist wichtig für die Performance des Systems: Ist sie zu kurz, wächst der Overhead, der durch die Entscheidungsfindung des Schedulers und das Umschalten von einem Prozess zum nächsten (Kontextwechsel) entsteht. Ist die Zeitscheibe zu lang, scheinen die Prozesse nicht mehr gleichzeitig zu laufen. Wenn ein Prozess terminiert oder auf ein externes Ereignis warten muss, benötigt er den Rest seiner Zeitscheibe nicht mehr. Er wird sie vorzeitig freigeben, beispielsweise durch einen Aufruf der »usleep«-Funktion. In diesem Fall wird der Scheduler außer der Reihe aufgerufen, er übergibt den verbleibenden Anteil der Zeitscheibe dem regulär nächsten Prozess. Ungeachtet dessen wird der Scheduler nach Ablauf dieser Zeitscheibe normal ausgeführt. |
|
Listing 3: Auslese |
|---|
01 void update_process_cycles(void)
02 {
03 struct task_struct *p = current;
04 int cpu = smp_processor_id();
05 cycles_t t = get_cycles();
06
07 p->cycles[cpu] += t - last_cycles[cpu];
08 if ( p->pid )
09 kstat.used_cycles[cpu] += t - last_cycles[cpu];
10 last_cycles[cpu] = t;
11 }
|
|
Listing 4: |
|---|
01 CPU0 CPU1 02 0: 20242854219 16586735080 IO-APIC-edge timer 03 1: 1636655 1225320 IO-APIC-edge keyboard 04 2: 0 0 XT-PIC cascade 05 10: 0 0 IO-APIC-level usb-ohci 06 14: 251664916 263921645 IO-APIC-edge ide0 07 23: 5601393923 5431463426 IO-APIC-level eth0 08 HI_SOFTIRQ: 3924680280 3191840981 09 NET_TX_SOFTIRQ: 1115199064 1274524965 10 NET_RX_SOFTIRQ: 5157803275 4835883365 11 TASKLET_SOFTIRQ: 90516230 90298686 |





