Intels x86-Prozessoren sind SIMD-fähig seit dem Pentium MMX: SIMD (Single Instruction, Multiple Data) bedeutet, dass die CPU vier Berechnungen in einem Rutsch ausführt. Wer die passenden Optimierungstechniken kennt und nutzt, kann seine Programme erheblich beschleunigen.
Aktuelle Prozessoren der IA32-Familie sind schnell genug für wissenschaftliche Berechnungen und andere rechenintensive Aufgaben, etwa Multimedia-Anwendungen. Bis vor kurzem galt das nur für Ganzzahloperationen, bei der Gleitkommarechnung waren andere Prozessorfamilien deutlich schneller[1].
Seit dem Pentium MMX hat Intel einen neuen Weg eingeschlagen: SIMD-Erweiterungen (Single Instruction, Multiple Data) sollen Integer- und Gleitkomma-Operationen wesentlich schneller ausführen als bisherige Architekturen, da ein einzelner Befehl mehrere Berechnungen ausführt.
Befehl mit breiter Wirkung
Die besondere Stärke von SIMD-Architekturen sind Multimedia-Anwendungen. Statt vieler unterschiedlicher Informationen in den verschiedensten Datentypen muss der Prozessor hier ganze Ströme von Daten gleichen Typs mit den gleichen Befehlen verarbeitet. Ein SIMD-Befehl arbeitet daher mit mehreren Daten des gleichen Typs zur selben Zeit. Das steht im Gegensatz zur SISD-Technik (Single Instruction, Single Data) der bisherigen Prozessoren. Die Arbeitsweisen von SISD und SIMD sind in Abbildung 1 dargestellt.
Reine SIMD-Prozessoren wären jedoch zu unflexibel, um auch SISD-Aufgaben schnell und Ressourcen sparend zu bearbeiten. Kombiniert sind SISD und SIMD ideal, um sowohl einfache Aufgaben als auch größere Datensätze schnell und effektiv zu bearbeiten.
Die SIMD-Arbeitsweise ist nicht neu. Viele andere Prozessorarchitekturen, zum Beispiel MIPS und SPARC, nutzen ebenfalls diese Technik. Auch Spielekonsolen wie Sonys Playstation 2 mit ihrer Emotion Engine nutzen SIMD.
Alter Hut: SIMD in der GPU
Selbst auf normalen PCs arbeiten seit Jahren SIMD-Einheiten, und zwar in den Grafikkarten (GPU, Graphics Processing Unit). SIMD ist ideal für die Bearbeitung von Grafikdaten: Die GPU muss oft Operationen, etwa eine geometrische Transformation, auf eine größere Menge von Daten (hier: Vertices) gleichen Typs anwenden.
Es gibt verschiedenen Techniken, die die SIMD-Operationen in Hardware verwirklichen. Im Folgenden meint SIMD die Variante der neueren x86-Prozessoren, der Textkasten “SIMD-Erweiterungen der IA32-Prozessoren” gibt Erläuterungen zu den verbreiteten Techniken MMX, SSE, SSE2 und 3DNow.
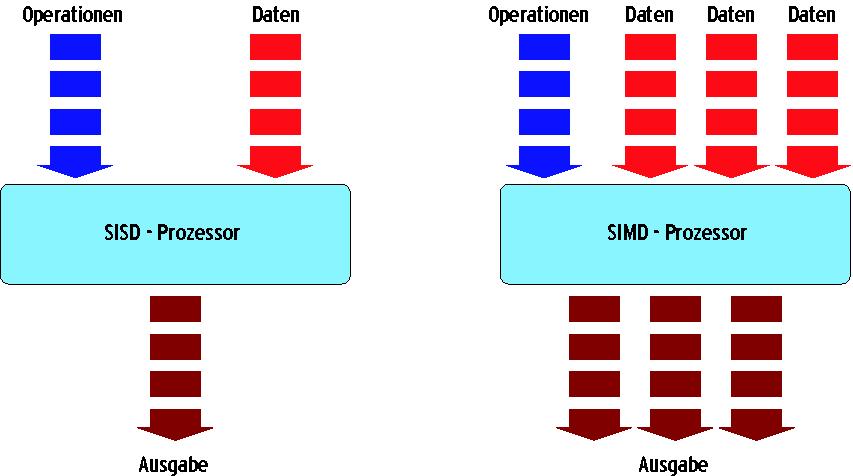
Abbildung 1: Ein SISD-Prozessor (links) arbeitet pro Befehl mit einem einzelnen Datenfeld, während ein SIMD-Prozessor (rechts) in jedem Schritt mehrere Daten gleichzeitig verarbeitet.
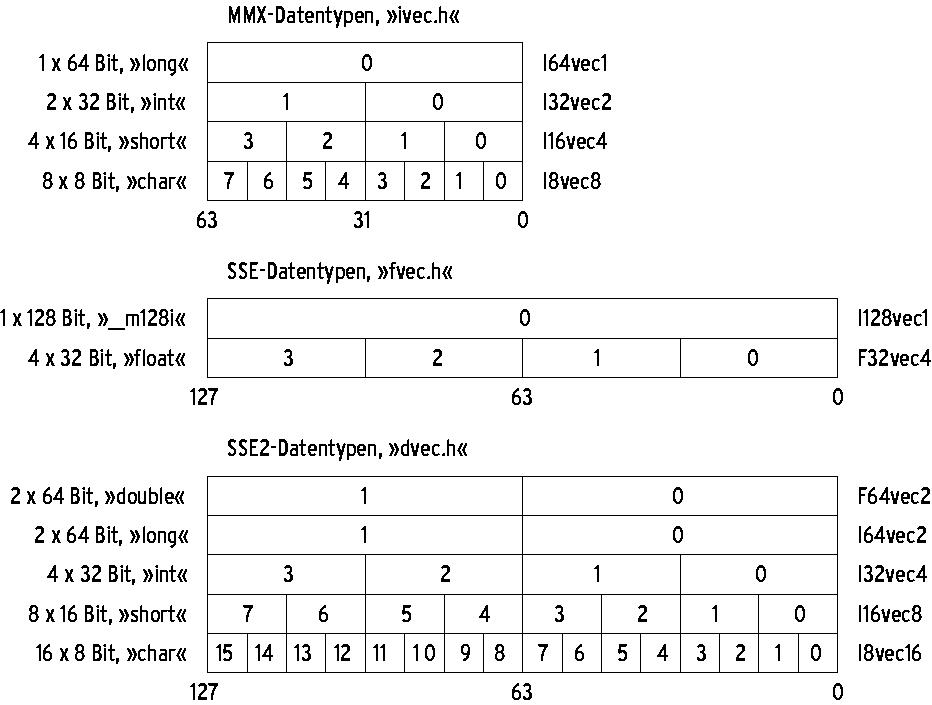
Abbildung 2: Die Datenvektoren von MMX, SSE und SSE2 arbeiten mit verschiedenen Datentypen. Links sind Anzahl, Größe und Typ der Elemente angegeben, rechts der Klassenname des Vektors innerhalb Intels Klassenbibliothek.
Moderne Erweiterungen im Prozessor
Um einen SIMD-Befehl auszuführen, lädt ein Programm die Daten nebeneinander in Register. MMX (Multimedia Extension) bedient sich dazu der FPU (Floating Point Unit): Es nutzt 64 Bit von jedem der acht FPU-Register (je 80 Bit) und gibt ihnen die Aliasbezeichnungen »mm0« bis »mm7«. Nachteil: Der Programmierer muss entscheiden, ob ein Abschnitt seiner Software FPU- oder MMX-Operationen ausführen soll.
|
Listing 1: C und |
|---|
01 // Skalarprodukt in C berechnen:
02 float skalarprodukt(float x[], float y[])
03 {
04 return x[0]*y[0] + x[1]*y[1] + x[2]*y[2] + x[3]*y[3];
05 }
06
07 // Skalarprodukt in Assembler berechnen:
08 float skalarproduktAssembler(float x[], float y[])
09 {
10 vector tmp;
11 asm(
12 "movl %1, %%esi;"
13 "movl %2, %%edi;"
14 "movaps (%%esi), %%xmm0;"
15 "mulps (%%edi), %%xmm0;"
16 "movaps %%xmm0, %0;"
17 :"=g"(tmp) /* Ausgabe */
18 :"r"(x),"r"(y) /* Eingabe */
19 );
20 return tmp.f[0] + tmp.f[1] + tmp.f[2] + tmp.f[3];
21 }
|
Intel rät explizit davon ab, FPU- und MMX-Berechnungen zu mischen. Einerseits wirken sich beide Operationsarten auf die FPU-Statusflags aus, andererseits kann das Mischen den Code stark bremsen. Pentium III umgeht dieses Problem durch acht neue Register: Sie sind 128 Bit lang (16 Byte) und mit »xmm0« bis »xmm7« gekennzeichnet. Auch Pentium 4 enthält diese SSE-Register.
Wichtig ist bei SIMD-Programmen die Organisation der Daten. Damit der Prozessor sie schnell in seine SSE2-Register laden kann, müssen die Daten nebeneinander im Speicher liegen und an 16-Byte-Grenzen starten und enden. Dies wird häufig Data Alignment genannt. Sind Daten nicht aligned, kostet es den Prozessor viel Zeit, dies zur Laufzeit zu erreichen.
|
Tabelle |
||||
|---|---|---|---|---|
|
Prozessor |
MMX |
SSE |
SSE2 |
3DNow |
|
Intel |
|
|
|
|
|
Pentium und älter |
|
|
|
|
|
Pentium MMX, Pentium II, Celeron |
x |
|
|
|
|
Pentium III, Celeron II |
x |
x |
|
|
|
Pentium 4 |
x |
x |
x |
|
|
AMD |
|
|
|
|
|
K6 |
x |
|
|
|
|
K6 II/III, Athlon, Duron |
x |
|
|
x |
|
Athlon 4, Athlon XP |
x |
x |
|
x |
Daten zu Vektoren zusammenfassen
Die Daten, die ein SIMD-Befehl in einem Schritt verarbeitet, formen einen Vektor. Die Anzahl der Elemente in diesem Vektor hängt von der Größe der Register ab: Bei MMX hat das Register 64 Bit, bei SSE und SSE2 128 Bit; so kann ein SSE2-Vektor zwei 64-Bit-Elemente enthalten oder 16 8-Bit-Werte, während in einen MMX-Vektor nur ein 64-Bit-Wert oder acht 8-Bit-Elemente passen.
Abbildung 2 zeigt die verschiedenen Vektor-Zusammensetzungen in MMX, SSE und SSE2. Auf der rechten Seite sind die von Intel benutzen Klassennamen genannt. Das Bild zeigt, dass SSE2 gegenüber MMX besonders bei Integer-Arithmetik im Vorteil ist: Es verarbeitet doppelt so viele Zahlen in einem Schritt und hält zusätzlich die x87-FPU frei für andere Aufgaben. Wenn möglich, sollte ein Programm auf MMX verzichten und besser SSE2 einsetzen.
|
SIMD-Erweiterungen |
|---|
|
MMX: Mit dem Pentium MMX lieferte Intel im Jahr 1997 die erste SIMD-Erweiterung, genannt Multimedia Extension, kurz MMX. Mit Hilfe neuer Befehle konnte diese Erweiterung zwei, vier oder sogar acht Ganzzahlbefehle parallel ausführen. Trotz einer großen Werbekampagne dauerte es allerdings einige Zeit, bis die Programmierer damit begannen, die neue Erweiterung voll ausnutzten. MMX änderte jedoch nichts an den langsamen Gleitkommaberechnungen. SSE: Mit dem Pentium III erweiterte Intel 1999 MMX um die Streaming SIMD Extension (SSE). Neben 70 neuen Befehlen erhielt der Prozessor acht zusätzliche Register, um auch Gleitkomma-Operationen (mit einfacher Genauigkeit) in SIMD-Technik auszuführen. SSE2: Ab Pentium 4 (November 2000) unterstützen Intels Prozessoren die Streaming SIMD Extension 2 (SSE2). Diese Erweiterung beschleunigt Operationen mit Integer- und Gleitkommazahlen bei doppelter Genauigkeit. 3DNow: Der Intel-Konkurrent AMD hat unter dem Namen 3DNow eine eigene SIMD-Erweiterung entwickelt[3]. 3DNow ergänzt MMX um Floating-Point-Fähigkeiten (einfache Genauigkeit), dazu sind einige neue Befehle zuständig. Der Hersteller will auch in Zukunft diesen Befehlssatz unterstützen, scheint aber auf SSE und SSE2 einzuschwenken. |
Alle Integer-Vektoren existieren in zwei Varianten: mit oder ohne Vorzeichen. Dazu erhält der C++-Klassenname nach dem ersten Buchstaben zusätzlich ein »s« oder ein »u«, aus »I64vec2« wird »Is64vec2« (signed) oder »Iu64vec2« (unsigned). Gleitkommavektoren sind immer mit Vorzeichen versehen.
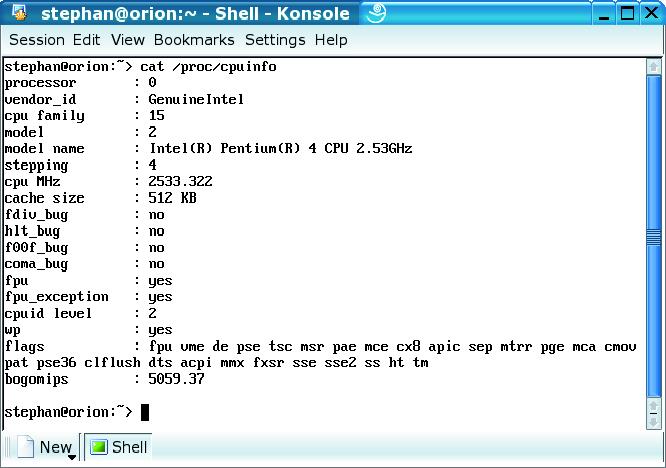
Abbildung 3: Der Befehl »cat /proc/cpuinfo« zeigt, welche Eigenschaften des Prozessors vom Kernel unterstützt werden: Laut Flags-Zeile kennt dieses Linux MMX, SSE und SSE2 (Kernel 2.4.20).
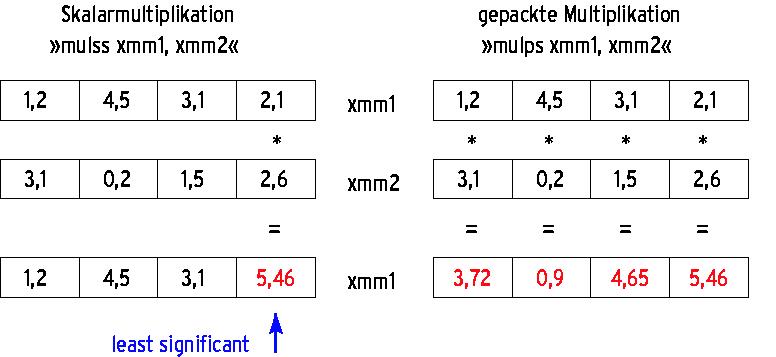
Abbildung 4: Der Unterschied zwischen skalarer und gepackter Multiplikation: Die erste multipliziert nur zwei Operanden miteinander (blauer Pfeil), die zweite betrifft jedes Element der Datenvektoren.
SSE2 unter Linux
Neue Prozessorerweiterungen müssen vom Betriebssystem und vom Compiler unterstützt werden, damit eigene Anwendungen davon profitieren können. Die Unterstützung des Betriebssystems ist wichtig, da es beim Wechsel zwischen Prozessen den Zustand aller Register speichern muss. Dazu muss es die SSE- und SSE2-Register kennen. Bei neueren Linux-Kerneln (speziell in der 2.4-Serie) ist das der Fall: »cat /proc/cpuinfo« zeigt, welche CPU-Eigenschaften das System unterstützt, siehe Abbildung 3.
Handoptimierter Code mit Inline-Assembler
Um diese CPU-Funktionen in eigenen Programmen zu nutzen, muss der Entwickler einige Hürden nehmen. Im Falle von C und C++ steht er vor dem Problem, dass die Sprachstandards keine SIMD-Funktionen enthalten. SSE2-fähiger Code ist damit stark abhängig vom benutzten Compiler und dessen Fähigkeiten. Statt sich auf die Compilerfunktionen zu verlassen, kann der Entwickler die zeitkritischen Stellen auch direkt in Assembler schreiben.
Für MMX, SSE und SSE2 sind eigene Assembler-Befehle zuständig. Dabei ist zwischen skalaren und gepackten Befehlen zu unterscheiden. Skalare Befehle ähneln den konventionellen Assembler-Befehlen, sie verändern nur das niederwertigste Element (least significant) eines Vektors. Gepackte Befehle wenden dagegen ihre Operation auf jedes Element gleichzeitig an. Ein Beispiel ist in Abbildung 4 zu sehen.
|
Tabelle |
|
|---|---|
|
Option |
Bedeutung |
|
ICC 7.1 |
|
|
-vec_report0 bis -vec_report3 |
Gibt einen Statusbericht des automatischen Vectorizers |
|
-xi, -xM, -xK, -xW |
Aktivieren den automatischen Vectorizer (i = Pentium Pro und |
|
-axi, -axM, -axK, -axW |
Aktivieren den automatischen Vectorizer, erzeugen aber auch |
|
GCC 3 |
|
|
-mfpmath= Unit |
Legt fest, welche Fließkomma-Arithmetik das Programm |
|
-mmmx, -msse, -msse2 (ab Version 3.3), -m3dnow |
Erlauben es dem Programmierer, die eingebauten SIMD-Funktionen |
|
Listing 2: |
|---|
01 // SIMD-Header einbinden
02 #ifdef __INTEL_COMPILER
03 # include <fvec.h> // enthält auch xmmintrin.h
04 #else
05 # include <xmmintrin.h>
06 #endif
07
08 typedef union{
09 __m128 m; float f[4];
10 } vector;
11
12 // Skalarprodukt mit Intrisics berechnen:
13 float skalarproduktIntrinsics(float x[], float y[])
14 {
15 __m128 *vecX = (__m128 *)x;
16 __m128 *vecY = (__m128 *)y;
17 vector tmp;
18
19 tmp.m = _mm_mul_ps(vecX[0],vecY[0]);
20
21 return tmp.f[0] + tmp.f[1] + tmp.f[2] + tmp.f[3];
22 }
23
24 // Skalarprodukt mit F32vec4 berechnen:
25 float skalarproduktSSE(float x[], float y[])
26 {
27 F32vec4 *vecX = (F32vec4 *)x;
28 F32vec4 *vecY = (F32vec4 *)y;
29 F32vec4 tmp;
30
31 tmp = vecX[0] * vecY[0];
32
33 return tmp[0] + tmp[1] + tmp[2] + tmp[3];
34 }
|
Skalarprodukt zweier Vektoren
Listing 1 zeigt zwei Funktionen, die beide das Skalarprodukt zweier Vektoren berechnen. »skalarprodukt()« ist ausschließlich in C implementiert, während »skalarproduktAssembler()« SSE-Assembler-Befehle enthält. Das Beispiel zeigt die Vor- und Nachteile von SIMD-Befehlen: Die Assembler-Variante begnügt sich mit einer Multiplikation im Vergleich zu vier im C-Code, dafür benötigt sie mehr Befehle, um das Ergebnis in eine Variable zu schreiben. Beide Lösungen berechnen vier Additionen.
Assembler-Programmierung hat den Nachteil, dass der Code schnell unübersichtlich wird und später schwer zu korrigieren ist. Wer dennoch mehr über den SSE2-Assembler-Befehlssatz des Pentium 4 erfahren möchte, findet unter[4] die passende Dokumentation.
Wer Assembler scheut, der findet bei Intel Abhilfe: Der Prozessor- und Compiler-Hersteller bietet so genannte Intrinsics an[5]. Sie fassen SIMD-Assembler- Befehle in C-ähnlichen Funktionen zusammen, die sich direkt in C und C++ benutzen lassen. Der Programmierer muss sich nicht um Register kümmern, die Intrinsics nehmen gewöhnliche Parameter entgegen.
|
Listing 3: |
|---|
01 [...]
02 // Matrix-Vektor-Multiplikation in C
03
04 // Matrix:
05 float matrix[4][4]={
06 { 2.5, 3.4, 7.9, 1.2 },
07 { 1.2, 7.7, 3.7, 0.5 },
08 { 3.1, 8.2, 7.1, 3.6 },
09 { 7.8, 0.4, 1.2, 5.2 }
10 };
11
12 // Vektor:
13 float vektor[4]={ 1.0, 1.0, 1.0, 1.0 };
14
15 // Ergebnis berechnen:
16 float ergebnis[4]={0};
17 int i,j;
18 for (i=0;i<4;i++)
19 {
20 ergebnis[i]=0;
21 for(j=0;j<4;j++)
22 {
23 ergebnis[i] += matrix[i][j] * vektor[j];
24 }
25 }
26 }
|
Übersichtlicher Code dank Intrinsics
Für die Intrinsics muss der Code eine der folgenden Headerdateien einbinden:
- »mmintrin.h« für MMX
- »xmmintrin.h« für SSE
- »emmintrin.h« für SSE2
Für SSE steht damit zum Beispiel das Kommando »__m128 _mm_mul_ps(_ _m128 a, __m128 b)« zur Verfügung. Es ruft den Assembler-Befehl »MULPS« auf, der mehrere Felder auf einmal multipliziert (»MUL«), also eine gepackte Operation ausführt (»P«, packed). Er interpretiert seine Operanden als Gleitkommawerte mit einfacher Genauigkeit (»S«, Single Precision Floating Point).
Auch mit dem GCC kann der Entwickler SIMD-Kommandos ohne Assembler programmieren[6], er muss nur den passenden Befehlssatz durch eine Compileroption aktivieren (siehe Tabelle 2). Neuere GCC-Versionen unterstützen auch die Intrinsics-Funktionen von Intel.
Automatisch optimiert
Assembler, Intrinsics und GCC-Erweiterungen haben einen entscheidenden Nachteil: Der Sourcecode eines Programms lässt sich nicht mehr auf anderen Systemen oder mit anderen Compilern übersetzt. Doch oft ist es gar nicht nötig, den Code von Hand auf SIMD zu trimmen: Viele Compiler erzeugen automatisch Maschinencode, der die besonderen SIMD-Eigenschaften des jeweiligen Prozessors nutzt (Tabelle 2).
Beim Intel-Compiler sollte der Entwickler die Option »-xkW« einsetzen, um den automatischen Vectorizer zu aktivieren, denn der wandelt selbstständig Befehle in SIMD-Anweisungen um. Allerdings eignet sich nicht jeder Code für diesen Automatismus. Der Intel-Compiler vektorisiert nur Schleifen, und dies auch nur, wenn sie nicht auf Elemente des gleichen Datenstroms zugreifen. Bei der folgenden Schleife scheitert ICC:
for(i=1;i<1000;i++) x[i] = x[i-1] + c[i];
Die Berechnung muss in jedem Schritt auf das Ergebnis des vorherigen Durchlaufs warten, der Compiler kann also nicht mehrere Schleifendurchläufe zu einem Schritt zusammenfassen. Die Option »-vec_report3« informiert den Entwickler, wie gut sich einzelne Teile seines Codes vektorisieren lassen.
Union vereinfacht den Zugriff auf SIMD-Felder
Für SIMD-Operationen ist es wichtig, dass die Daten in einem Vektor zusammengefasst sind. Ein 128-Bit-Vektor ist in den SSE-Intrinsics-Headern als Datentyp »__m128« enthalten. Dieser Typ ist immer aligned, sein Aufbau ist bekannt. Um die einzelnen Felder zu setzen, bietet sich daher eine »union« an. Im Falle von vier 32-Bit-»float«-Typen sieht das wie folgt aus:
union {
__m128 m128;
float fElement[4];
} vektor;
Damit die Programmierer ihre Vektorklassen nicht selbst definieren müssen, liefert Intel einige mit dem Compiler aus. Abbildung 2 enthält diese Typen und die zugehörigen Header.
Das Programm in Listing 2 zeigt, wie sich das Skalarprodukt von Listing 1 auch mit Intrinsics-Funktionen oder mit Intels SIMD-Klassen (C++) berechnen lässt. Die erste Funktion (Zeile 13) verwendet Intrinsics. Sie wandelt zunächst die Daten in den Typ »__m128« um. Die Typdefinition in Zeile 8 hilft ihr, die einzelnen Elemente des Zwischenergebnis-Vektors »tmp« besser zu erreichen.
|
Tabelle |
||
|---|---|---|
|
Compiler-Aufruf |
Zeit (Listing 3, reines C) |
Zeit (Listing 4, Intrinsics) |
|
g++ -O2 |
0,8 s |
– |
|
g++ -O2 -msse -mfpmath=sse |
0,82 s |
0,09 s |
|
icc -O2 |
0,05 s |
0,01 s |
|
icc -O2 -axW |
0,23 s |
0,01 s |
Die zweite Funktion (Zeile 25) nutzt die SSE-Klasse »F32vec4«, um einen Vektor für SIMD-Berechnungen zu bilden: Der Vektor hat vier Elemente (»vec4«), in denen sich jeweils eine Gleitkommazahl einfacher Genauigkeit (»F32«, Float mit 32 Bit) befindet. Besonders praktisch an den Klassen ist, dass der Programmierer für einfache Operationen keine neuen Kommandos lernen muss: C++ bietet das Überladen von Operatoren, die Multiplikation in Zeile 31 kann daher die gewohnte Notation verwenden.
Die Matrix
Die Beschleunigung durch SIMD-Erweiterungen lässt sich gut anhand einer Matrix-Vektor-Multiplikation zeigen. Der Standard-C-Code ist in Listing 3 zu sehen, Listing 4 zeigt die gleiche Berechnung mit SSE-Intrinsics. Die Intrinsics-Variante benutzt »union«-Konstrukte, um die Daten als »float«-Array oder als »__m128«-Vektor anzusprechen. Mit »_mm_add_ps« addiert der Code zwei Vektoren, »_mm_set_ps1« setzt alle vier Elemente des Vektors auf einen Wert.
Der Erfolg ist in Tabelle 3 zu bewundern: Die SSE-Implementierung (rechte Spalte) läuft um ein Vielfaches schneller als der herkömmliche Code. GCC kann leider den SSE-Code nicht ohne SSE-Optionen kompilieren, eine Messung ohne zusätzliche Optimierungen ist daher unmöglich. Bei den Werten des Intel-Compilers fällt auf, dass der normale Code mit Vectorizer deutlich langsamer läuft als ohne: Hier hat die automatische Optimierung versagt, die Handoptimierung lohnt sich damit besonders.
Gute Quellen für zusätzliche Informationen bieten die Hersteller der Prozessoren, Intel[7] und AMD[8], sowie die Dokumentation der Compiler GCC[6] und ICC. Intel veröffentlicht einige PDF-Dokumente zum Thema Code-Optimierung mit dem hauseigenen Compiler.
|
Listing 4: |
|---|
01 [...]
02 // Matrix-Vektor-Multiplikation mit SSE-Intrinsics-Code.
03
04 // Speicher für Matrix:
05 union {
06 __m128 m128[4]; // spaltenweise
07 float f[4][4];
08 } matrix;
09
10 // Speicher für Vektor und Ergebnis:
11 union {
12 __m128 m128;
13 float f[4];
14 } vektor, ergebnis;
15
16 // Matrix initialisieren:
17 matrix.m128[3] = _mm_set_ps( 2.5, 1.2, 3.1, 7.8 ); // 1. Spalte
18 matrix.m128[2] = _mm_set_ps( 3.4, 7.7, 8.2, 0.4 ); // 2. Spalte
19 matrix.m128[1] = _mm_set_ps( 7.9, 3.7, 7.1, 1.2 ); // 3. Spalte
20 matrix.m128[0] = _mm_set_ps( 1.2, 0.5, 3.6, 5.2 ); // 4. Spalte
21
22 // Vektor initialisieren:
23 vektor.m128 = _mm_set_ps(1.0,1.0,1.0,1.0);
24 ergebnis.m128 = _mm_setzero_ps();
25
26 // Multiplikation berechnen:
27 __m128 tmp_multiplikator;
28 __m128 tmp_spalte1;
29 __m128 tmp_spalte2;
30
31 tmp_multiplikator = _mm_set_ps1(vektor.f[0]);
32 tmp_spalte1 = _mm_mul_ps(matrix.m128[0], tmp_multiplikator);
33
34 tmp_multiplikator = _mm_set_ps1(vektor.f[1]);
35 tmp_spalte2 = _mm_mul_ps(matrix.m128[1], tmp_multiplikator);
36 tmp_spalte1 = _mm_add_ps(tmp_spalte1, tmp_spalte2);
37
38 tmp_multiplikator = _mm_set_ps1(vektor.f[2]);
39 tmp_spalte2 = _mm_mul_ps(matrix.m128[2], tmp_multiplikator);
40 tmp_spalte1 = _mm_add_ps(tmp_spalte1, tmp_spalte2);
41
42 tmp_multiplikator = _mm_set_ps1(vektor.f[3]);
43 tmp_spalte2 = _mm_mul_ps(matrix.m128[3], tmp_multiplikator);
44 ergebnis.m128 = _mm_add_ps(tmp_spalte1, tmp_spalte2);
45
46 ergebnis.m128 = _mm_loadr_ps(ergebnis.f);
47 }
|
Fazit und Ausblick
Modernen Compiler wie GCC und ICC bieten dem Programmierer einige Techniken, um die SIMD-Erweiterungen neuerer x86-Prozessoren zu nutzen. Die Erweiterungen können Code deutlich beschleunigen und lassen sich auch einsetzen, ohne in die Tiefe der Assembler-Programmierung hinabzusteigen.
Wer seine Programme für die Zukunft rüsten möchte, sollte sich mit den SIMD-Erweiterungen beschäftigen: Neben den hier besprochenen 32-Bit-Prozessoren enthalten auch die 64-Bit-CPUs von Intel und AMD SSE-Erweiterungen. (fjl)
|
Infos |
|---|
|
[1] Prozessor-Benchmarks: [http://www.spec.org] [2] Single Instruction, Multiple Data: [http://www.wikipedia.org/wiki/SIMD] [3] Bernhard Kuhn, “Ohne Fleiß kein Preis? 3DNow-Programmierung”: Linux-Magazin 12/99, S. 53 [4] Pentium-4-Handbuch: [http://developer.intel.com/design/Pentium4/manuals/] [5] ICC User Guide: [http://www.intel.com/software/products/compilers/techtopics/c_ug_lnx.pdf] [6] GCC-Dokumentation: [http://gcc.gnu.org/onlinedocs/] [7] Intel-Homepage: [http://www.intel.com] [8] AMD-Homepage: [http://www.amd.com] [9] Dateien zum Artikel: [ftp://ftp.linux-magazin.de/pub/listings/magazin/2003/08/] |
|
Der |
|---|
|
Dr. Stephan Siemen arbeitet als wissenschaftlicher Mitarbeiter an der Essex University (UK). Dort entwickelt er Software zur 3D-Darstellung von Wettersystemen und unterrichtet Studenten in Computergrafik und Programmierung. |





