
Ethernet-Verbünde mit Bonding betreiben, VLANs und Switches trotz Spanning Tree beherrschen und störende DHCP-Server aufstöbern: Admins halten ihre Netze meist nur dank gezielter Tricks und Kniffe unter Kontrolle. Dieser Herausforderung stellen sich unsere Profis mit Freude.
Netzwerke jenseits trivialer Fälle administrieren klappt nur mit einer guten Portion Theoriewissen und einem riesigen Erfahrungsschatz. Das Linux-Magazin wollte es genauer wissen und bat seinen Autor und Sysadmin-Guru Charly Kühnast um einschlägige Berichte aus dem Alltag. Doch der erklärte sich prompt für nicht zuständig und flüchtete auf den Flur. Zwei Türen später hielt er inne, klopfte und überredete seine Kollegen aus der Netzwerk-Abteilung dazu, Anekdoten aus ihrer täglichen Arbeit zu berichten. Da die Jungs ein recht stattliches, Niederrhein-weites Primär- und Sekundärnetz verantworten, schöpfen sie aus dem Vollen.
Der Spaß beim Vernetzen beginnt schon in den untersten Schichten: Wie viele Kabel zwischen einem Rechner und dem nächsten Switch liegen, ist gar nicht so selbstverständlich mit “eins” zu beantworten. Auch ob ein Switch die richtige Wahl ist oder doch ein Router her muss, klärt sich oft erst nach wochenlanger leidvoller Erfahrung mit der falschen Entscheidung. Selbst das altbekannte DHCP hat genügend Überraschungen in petto.
Fall 1: Bonding
Manchmal reicht ein einzelnes Ethernet-Interface nicht aus. Sei es, weil im Fehlerfall Failover-Mechanismen greifen sollen oder weil der Durchsatz bei nur einer NIC zu gering wäre (Abbildung 1). In diesen Fällen ist es sinnvoll, mehrere Karten per Bonding-Interface zusammenzufassen. Ausgangsdokumentation hierfür ist die Anleitung in »bonding.txt« für den jeweiligen Kernel. Sie steckt in den Linux-Quellen, etwa unter »/usr/src/linux-2.6.5-7.257/Documentation/networking/bonding.txt«.
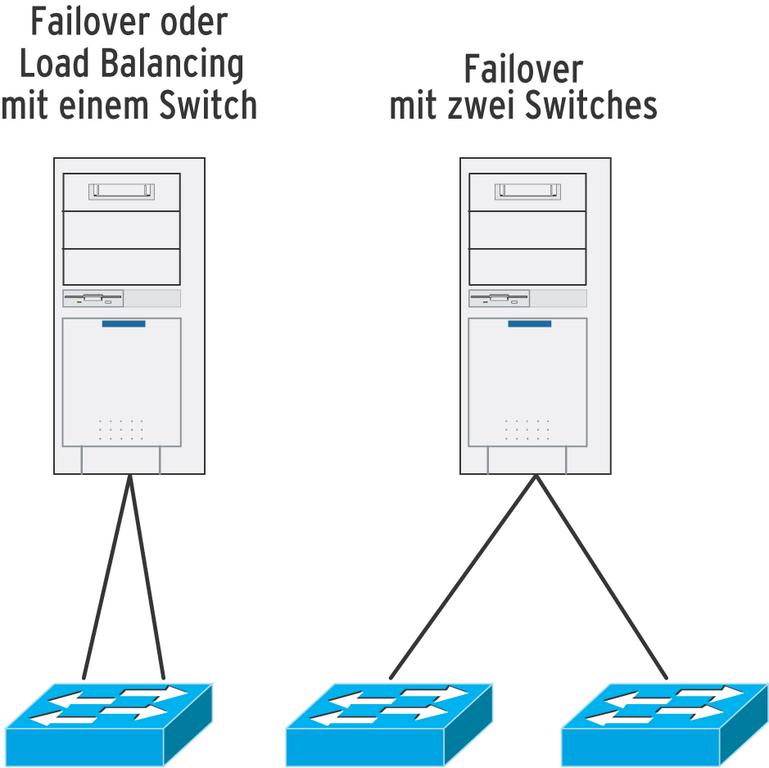
Abbildung 1: Hat ein PC zwei Netzwerkanschlüsse, gibt es zwei Verkabelungsvarianten fürs LAN: an einen Switch (links, High Availability und Load Balancing) oder an zwei getrennte (rechts, nur HA).
Nach der Konfiguration eines virtuellen Master-Interface (beginnend bei »bond0«) und der Zuordnung der physikalischen Interfaces (etwa »eth0« und »eth1«) an das Master-Interface ist das Bondingmodul mit der entsprechenden Parametrisierung zu starten: Dabei sind Modus 0 oder 2 für Load Balancing zuständig und Modus 1 für Active Backup. Modus 0 verteilt die Last im Round-Robin-Verfahren, während Modus 2 einen XOR-Algorithmus anwendet.
Aus Netzwerksicht ist Modus 2 klar zu bevorzugen, da Modus 0 zwar die Pakete gleichmäßig über alle Links verteilt, hierbei aber prinzipiell die Gefahr besteht, dass sich Pakete einer Session auf unterschiedlichen Links gegenseitig überholen. Das wäre für manche UDP-Anwendungen tödlich und selbst TCP ist in schlimmen Fällen nicht mehr in der Lage, die originale Reihenfolge zu rekonstruieren. Im ungünstigsten Fall bricht dann die Session ab. Cisco-Switches kennen Round Robin nicht einmal.
Die XOR-Variante geht intelligenter vor und bildet aus Quell- und Ziel-MAC einen Hash, der darüber entscheidet, auf welchem verfügbaren Link die Verbindung landet. Solange sich Quell- und Ziel-MAC nicht ändern, bleibt die Entscheidung gleich. Der erwünschte Effekt: Alle Pakete einer Verbindung passieren die gleiche Leitung.
Wer bin ich
Spätestens wenn mehr als zwei Interfaces vorhanden sind, wird es für das Bonding wichtig, welches physikalische Interface welchem »ethx« entspricht. Weil der Kernel selbst entscheidet, wie er die Nummern vergibt, hilft das Werkzeug »ethtool« mit dem Parameter »-p«: Es lässt die Link-Diode des angesprochenen Interface rhythmisch blinken (siehe [1] und [2]).
Das erweist sich als besonders hilfreich, wenn jemand nachträglich Netzwerkkarten einbaut (Abbildung 3). Dann nämlich würfelt das Betriebssystem die Zuordnung zwischen Physik und »ethx« neu aus. Die hässliche Folge ist, dass sich plötzlich völlig andere Interfaces in einem Bond wiederfinden. Wer dann nicht feststellen kann, welches »ethx« welchem Port entspricht, darf sich stundenlang mit Probieren vergnügen.
Beim Einrichten von zwei oder mehr Bondings über Dualport-Interface-Karten (je zwei Ports pro Karte) ist wichtig, dass sich die zu einem Bond zusammengefassten Interfaces auf unterschiedlichen Karten befinden (Abbildung 2). Nur das stellt sicher, dass beim Ausfall einer Karte noch ein Link pro Bond am Leben bleibt. Ist nur Ausfallsicherheit gefordert und kein Load Balancing, wäre es sinnvoller die Links auf verschiedene Ethernet-Switches zu verteilen (Abbildung 1). Der Ausfall eines Switch würde den Betrieb dann weniger einschränken.
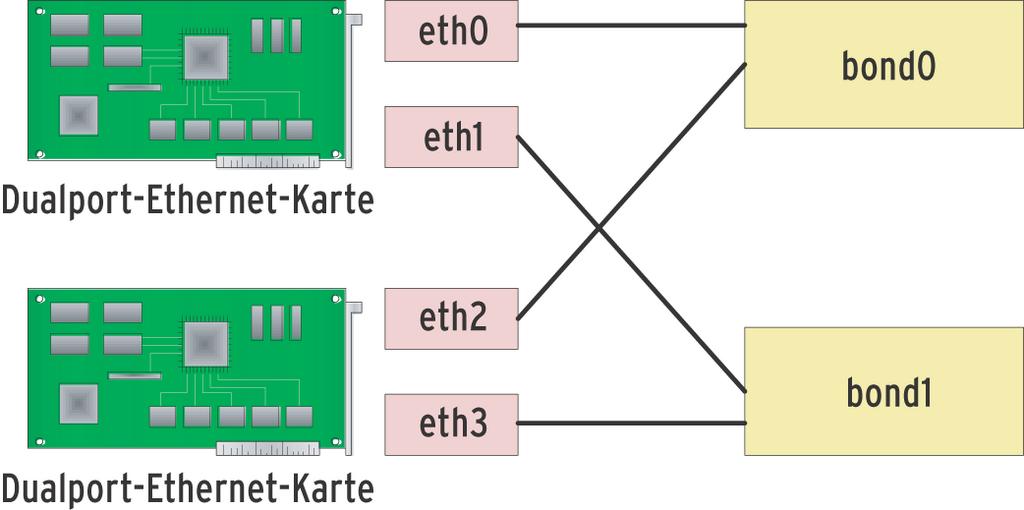
Abbildung 2: Bonding mit Dual-Port-Ethernet-Karten verwendet sinnvollerweise zwei virtuelle Master-Interfaces »bond0« und »bond1«, die über Kreuz physische Interfaces beider Karten vereinen. Fällt eine Karte aus, überleben dennoch beide Bonding-Interfaces.
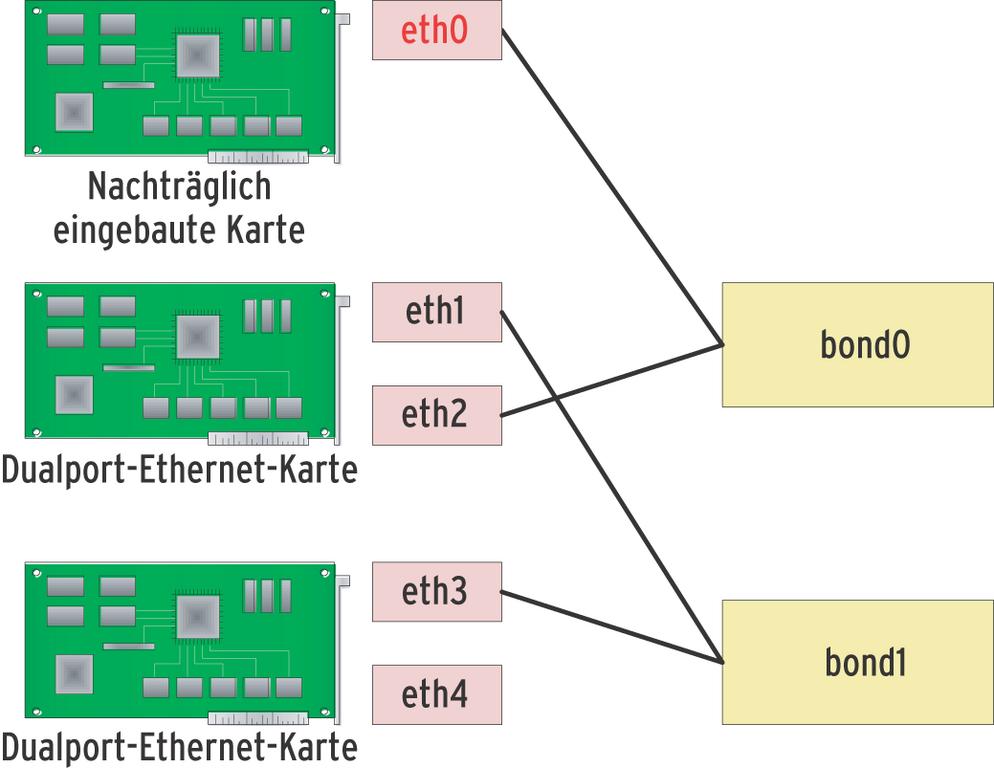
Abbildung 3: Baut der Besitzer eine zusätzliche Netzwerkkarte in seinen Rechner, tüftelt das Betriebssystem die Zuordnung von physikalischem Gerät zur logischen Interface-Nummer neu aus. Wer Pech hat, findet unter »eth0« die neue Karte wieder und alle Nummern sind neu vergeben.
Jonglieren unter Last
Dient die doppelte Anbindung an den Switch nicht als Active-Backup-Modus (also Failover), dann bleibt Load Balancing, das die Netzlast auf beide Strecken verteilt. Der angeschlossene Ethernet-Switch muss von diesem Wunsch wissen, dazu ist ein entsprechender Etherchannel zu konfigurieren. Bei Cisco-Switches lautet der »channel mode« dazu »on«. Der Switch formt dann auf jeden Fall einen Kanal und versucht nicht, über Automatismen den Status der Gegenseite festzustellen. Wer das nicht bedenkt, darf sich einer mühsamen Fehlersuche widmen.
Wie sich die Netzlast tatsächlich über die Bond-Interfaces verteilt, zeigt das Konsolenprogramm »iptraf« [3] sehr schnell. Für Langzeitstatistiken eignet sich Cacti ([4], [5]) aber viel besser. (Ludger Köhler, Werner Thal)
Fall 2: VLAN und STP
Das Konzept virtueller LANs (siehe auch den VLAN-Artikel in diesem Heftschwerpunkt) ist eigentlich einfach: VLANs verbinden physisch getrennte Ethernet-Segmente. Bei einem Switch stellt jeder Port für sich ein eigenes Segment dar. Statt jedes mit jedem zu vermitteln, ordnet das Konstrukt VLAN die Segmente in festen Gruppen. Dummerweise sorgt Cisco für Verwirrung und benutzt einige Begriffe anders als der Rest der Welt.
Ein Trunk ist in der Cisco-Nomenklatur genau das, was andere Hersteller als Tagging oder 802.1q (Dot1q) bezeichnen. Um die Verwirrung zu vergrößern, heißen Ciscos Channels beziehungsweise Etherchannels bei anderen Trunk. Linux tritt die Flucht nach vorn an und verwendet den unbelasteten Begriff Bonding.
Auch beim Spanning Tree Protocol kommen Eigenheiten von Cisco-Komponenten ins Spiel. Der Kasten “Spanning Tree Protocol” beschreibt in aller Kürze die herstellerunabhängigen Vorgänge beim STP. Cisco vertrat bisher die Ansicht, dass STP gut skaliert und auch in komplexen Strukturen für hohe Betriebssicherheit sorgt. Wer im Backbone gute Performance haben möchte, kommt an Switching und STP nicht vorbei.
|
Spanning Tree |
|---|
|
Viele Köche verderben den Brei, viele Switches verderben das Netz – auch wenn Admins sie in bester Absicht einsetzen. Ihr Ziel ist meist, die Ausfallsicherheit zu erhöhen. Durch ungeschicktes Zusammenstöpseln entsteht aber schnell ein Teilchenbeschleuniger-Ring: Eine so genannte Loop zeichnet sich dadurch aus, dass Pakete im Netzwerk endlos umherkreisen. Das könnte zum Beispiel passieren, wenn zwei oder mehr redundante Pfade im Netzwerk existieren und die Knoten die Frames an mehrere Interfaces senden. Da Ethernet-Frames keinen Hop-Count und keine Time to Live kennen, würde das Netz nichts von der Endlos-Odyssee merken und die Pakete ewig kreisen lassen. Um diesen Super-GAU zu vermeiden, haben sich schlaue Leute das Spanning Tree Protocol (STP) ausgedacht ([6], [7]). Alle Switches eines Netzwerks nehmen an einem Auswahlverfahren teil, bei dem sie einen Chef (Root-Bridge) festlegen. Gemeinsam die Root-Bridge ermittelnDer Algorithmus schaltet alle Verbindungen frei, die direkt mit der Root-Bridge verbunden sind (Abbildung 5) oder zumindest einen besseren Weg zu ihr kennen als der Rest des Netzes. Die verbleibenden redundanten Pfade mit den schlechteren Verbindungen bleiben für Netzwerkverkehr gesperrt. Um die Root-Bridge zu ermitteln, tauschen die Switches so genannte BPDUs (Bridge Protocol Data Unit) aus. Dieser Vorgang dauert typischerweise bis zu 30 Sekunden – manchmal auch länger – und beginnt jedes Mal von vorne, wenn eine redundante Verbindung ausfällt oder ein neuer Switch oder redundanter Pfad hinzukommt. Das Ziel ist dabei keinesfalls, von jeder Quelle zu jedem Ziel den optimalen Weg zu ermitteln (das schaffen nur Routingprotokolle), sondern ausschließlich, ein schleifenfreies Netz zu bilden. Hat ein Ethernet-Frame Pech, weil STP die für ihn kürzeste Anbindung sperrt, muss er einen Umweg gehen. Er kommt aber immer ans Ziel, ohne Duplikate. |
Beim Netzdesign verfolgt Cisco ein Drei-Schichten-Modell, das Netzwerke in die Bereiche Core-, Distribution- und Access-Layer gliedert (Abbildung 4). Im Core stecken schnelle Switches, die Pakete innerhalb eines VLAN möglichst flott von A nach B befördern. Der Distribution-Layer sorgt für die korrekte Verteilung der Pakete über VLAN-Grenzen hinweg und nutzt dazu klassisches Routing. Im Access-Bereich schließlich befinden sich die Endgeräte, also Workstations, Server, Drucker und mehr.
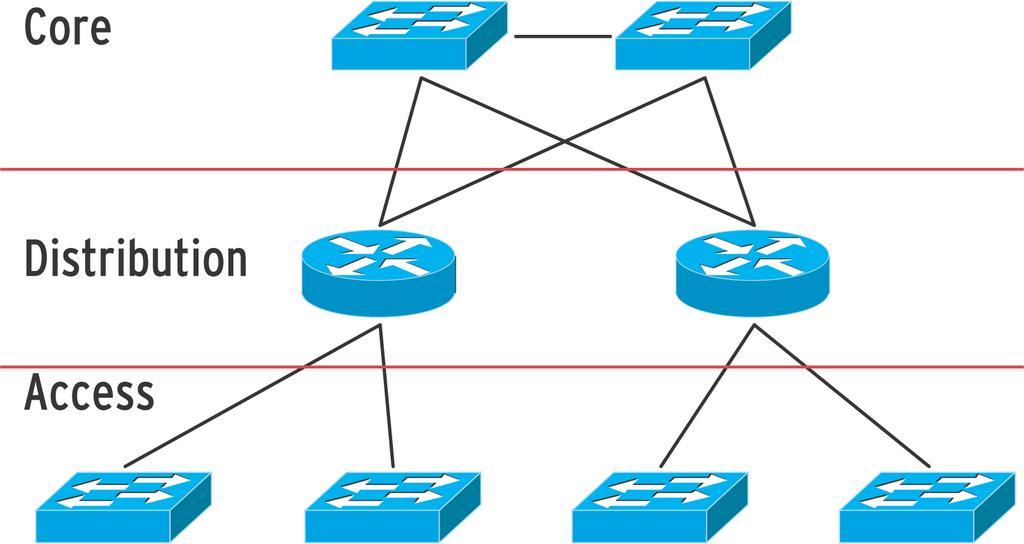
Abbildung 4: Cisco teilt größere Netzwerke in drei Layer: Im Core arbeiten Switches, im Distribution-Layer Router, in der Access-Schicht wieder Switches.

Abbildung 5: Das Spanning Tree Protocol sorgt für schleifenfreie Netze, in denen es von jedem Switch zum anderen nur einen Weg gibt.
Performance-Überraschung
Da hoch performante Routing-Hardware lange Zeit schlicht nicht verfügbar (und bezahlbar) war, galt gute Performance im Backbone als Hauptargument für besonders leistungsfähige Switches im Core-Layer. Das war auch im Netz der Autoren und einiger ihrer Kunden so eingerichtet und funktionierte lange Zeit gut – abgesehen von ungewaschenen Usern, die umherliegende Kabel einfach irgendwo in ein Büroswitch stöpselten. Das bringt Spaß bei der Fehlersuche, denn Switching und STP verursachen bei einem Fehler an einem Ende des Netzwerks gern Probleme an einer ganz anderen Stelle.
Wirklich problematisch wurde es erst nach einer Netzwerkerweiterung, die mehr Ports und zusätzliche Ausfallsicherheit erreichen sollte. Das Gegenteil war der Fall: Ab dieser Aktion führte das Hinzufügen eines Switch mit redundanter Anbindung zu Totalausfällen des Core- und Distribution-Bereichs. Weil das gleich mehrfach passierte, handelte sich Werner Thal den schmeichelhaften Spitznamen “Master of Loops” ein. Als Workaround deaktivierte er kurzerhand die redundanten Wege. Diese Verzweiflungsaktion konnte nicht der Weisheit letzter Schluss sein, da er die Redundanzen absichtlich eingefügt hatte. Bei Ausfällen sollten sie sich automatisch als Ersatz aktivierenden.
Theoretisch dürften die Redundanzen das Netz nicht beeinträchtigen und es schon gar nicht lähmen. Auch ein externer Berater fand nicht auf Anhieb die Ursache der Totalausfälle. Da Cisco auf seinen Komponenten PVST (Per-VLAN Spanning Tree) einsetzt, verringerte der Berater zuerst den Overhead, indem er auf allen Trunk-Verbindungen nur noch die dort benötigten VLANs erlaubte. Außerdem ersetzte er STP noch durch die Weiterentwicklung RSTP (Rapid Spanning Tree Protocol). Diese Variante konvergiert flotter.
Die Schritte schafften zwar erkennbar Linderung, letztlich lieferte aber erst ein Cisco-Switching-Kurs die entscheidenden Hinweise: Entgegen allen Versprechungen der Hersteller skaliert STP in der Praxis gar nicht gut.
Switch im Ausnahmezustand
Hintergrund des fatalen STP-Verhaltens ist, dass die Software des Switch fürs Generieren der BPDUs zuständig ist. Wird ein Switch, der ja deutlich mehr zu tun hat als nur BPDUs verschicken, plötzlich stark belastet, kann das zu einem Engpass bei der CPU-Leistung führen. Für das Generieren der BPDUs fehlt die Rechenzeit und der Switch schafft es nicht mehr, diese Pakete zu senden.
Die Nachbarn verstehen das Ausbleiben der BPDUs fatalerweise als Ausfall und schalten einen eventuell gesperrten Port wieder frei, um den Ausfall auszugleichen. Die dabei entstehende Schleife führt zu einem schlagartigen Anstieg der Netzwerklast, was wiederum die Switches stark beschäftigt – so stark, dass noch mehr Komponenten keine BPDUs mehr produzieren. Der Teufelskreis setzt sich fort, bis sich das komplette Netz ins Nirwana verabschiedet.
Der verblüffende Ratschlag der Switching-Kursleiter lautete: so weit wie möglich auf Switching verzichten, lieber Routing betreiben und die Layer-2-Instanzen auf maximal drei Geräte pro VLAN beschränken. Das lässt sich in der Praxis wahrscheinlich nicht immer exakt umsetzen, aber es zeigte sich schnell, dass Mikrosegmentierung auf IP-Ebene wahre Wunder bewirkt.
Performanceprobleme durch das Routing sind heute kaum mehr zu befürchten, da aktuelle Hardware mühelos mit der Bandbreite der Netze Schritt hält (Wirespeed Routing). Der Marketing-Name dafür lautet Layer-3-Switching. De facto bleibt es aber bei in Hardware gegossenem Routing optimiert durch Mechanismen wie CEF (Cisco Express Forwarding). Am Ende des Weges steht dann der Betrieb eines gut skalierbaren und stabilen, gerouteten LAN mit dem Einsatz eines entsprechenden Routingprotokolls wie OSPF (Open Shortest Path First). (Werner Thal, Charly Kühnast)
Fall 3: Störende DHCP-Server
Virtualisierungstechniken wie VMware ([8], [9]) sind sehr praktisch, um ohne großen Aufwand neue Software oder Serverdienste zu testen. Die Möglichkeiten, sich in den Fuß zu schießen, erweisen sich allerdings als ebenso vielfältig. Die Installation von VMware läuft unter Linux mit dem Skript »vmware-install.pl« halbautomatisch ab. Nach dem Prüfen gewisser Abhängigkeiten (etwa GCC und Kernelheader) fragt das Skript nach den Pfaden. Meist reicht es hier, die Vorgaben zu bestätigen.
Wenn das Testen von Serverdiensten ansteht, ist es sinnvoll, den VMware-Gast zunächst nur mit einem Loopback-Interface zu konfigurieren, alternativ mit einem privaten Subnetz, das nicht ins LAN streut. Solche Vorsicht legt leider nicht jeder Virtualisierer an den Tag und VMware verbindet sich per Default gerne schamlos mit seiner Umgebung: »Configuring a bridged network for vmnet0« lautet die Default-Option. Wer nun zu allem Überfluss noch einen Gast mit aktiviertem DHCP-Daemon in einem virtuellen Server fährt, sorgt für ungebremsten Spaß in der Netzwerk-Abteilung.
Störenfried
Ein in VMware laufender DHCP-Server antwortet selbstredend auch auf DHCP-Requests aus dem LAN, oft kommt er schneller zum Zuge als der eigentlich zuständige Firmen-DHCPD. Der offizielle Server ist meist mit weiteren Diensten beschäftigt, etwa DNS, also ungleich höher ausgelastet als der in VMware aufgesetzte Server. Der dreht die meiste Zeit Däumchen und antwortet unverzüglich auf die wenigen Fragen.
Da DHCP prinzipbedingt keine Möglichkeit kennt, erwünschte von streunenden DHCP-Quellen zu unterscheiden, würfelt der kleine Dienst das Netz gehörig durcheinander. Um den Übeltäter aufzuspüren, braucht der Admin dessen Adresse. Dazu hat er zwei Möglichkeiten. Erstens: Er opfert seinen Laptop und lässt ihn vom VMware-DHCPD versorgen. Die ARP-Tabelle des Laptops verrät, welche MAC der DHCP-Server hat (»arp -a«). Zweitens: Er nutzt eines der »dhcping«-Tools [10] auf seinem gewöhnlichen Client, um die MAC zu ermitteln.
Mit Kenntnis der gegnerischen MAC-Adresse folgt eine Fahndung auf den Access-Switches, dort steht im CAM (Content-Addressable Memory) für jeden Port, welche MAC-Adressen sich dahinter verbergen. In bester Bastard-Operator-from-Hell-Strategie hilft es am schnellsten, den Port zu deaktivieren. Danach genügt es, sich auf den Flur zu stellen und zu warten, aus welchem Büro “Hey, mein VMware ist weg!” schallt. (Mark Schier, Charly Kühnast)
Spaßbremsen
Netzwerke jeder Größe halten viel Potenzial für Überraschungen bereit. Bei Problemen größerer Tragweite ist der erfahrene Praktiker gesucht – daher tat Charly auch gut daran, sich an seine Kollegen aus dem Netzwerk-Ressort zu wenden. Auch daran beweist sich der wahre Profi. (fjl)
|
Infos |
|---|
|
[1] Charly Kühnast, “Aus dem Alltag eines Sysadmin – Ethtool”: Linux-Magazin 03/06, S. 71 [2] Gkernel (enthält Ethtool): [http://sourceforge.net/projects/gkernel/] [3] IPtraf: [http://iptraf.seul.org] [4] Achim Schrepfer, “Kurvenschau – Systemdaten grafisch überwachen mit Cacti, dem Webfrontend für RRDtool”: Linux-Magazin 09/03, S. 54 [5] Cacti, das Webfrontend für RRD-Tool: [http://www.cacti.net] [6] Cisco-Dokumentation, “Understanding Spanning-Tree Protocol”: [http://www.cisco.com/univercd/cc/td/doc/product/rtrmgmt/sw_ntman/cwsimain/cwsi2/cwsiug2/vlan2/stpapp.htm] [7] Das Elektronik-Kompendium, “Spanning Tree Protocol”: [http://www.elektronik-kompendium.de/sites/net/0907091.htm] [8] Titelthema “Virtualisierung – Geteilte Server sind besser genutzte Server”: Linux-Magazin 04/06 [9] VMware: [http://www.vmware.com] [10] Dhcping-Implementierungen: [http://www.mavetju.org/unix/general.php] und [http://dhcping.openwall.net] |





