
Die Synergistic Processing Elements (SPEs) sind die Leistungsträger der Cell Broadband Engine, bekannt als Cell-Prozessor. Die Programmierung der geselligen Arbeitstiere ist allerdings etwas trickreich. Dieser Artikel erklärt sie anhand eines einfachen Beispiels unter Linux.
Als Prozessor der seit 2007 in Europa erhältlichen Sony Playstation 3 hat die Cell-CPU (Kasten “Cell Broadband Engine Architecture”) Aufsehen erregt. Im Gegensatz zu anderen Konsolenherstellern unterstützt Sony offiziell die Installation von Linux auf der Playstation. Sie ist im Web mehrfach beschrieben [1]. Zwei Besonderheiten sind bei Linux auf der PS 3 zu beachten. Erstens gelingt kein direkter Zugriff auf die Hardware: Zum Schutz seiner proprietären Firmware hat Sony eine Virtualisierungsschicht eingezogen. Und zweitens sind von den acht Recheneinheiten des Cell-Prozessors nur sechs für Linux-Programme verfügbar.
Reagenzgläser vorbereiten
Anwendungsentwicklung für den Cell-Prozessor macht natürlich besonders denen Spaß, die Zugriff auf Cell-basierte Rechner haben. Wer mit einem Cell-Bladeserver arbeitet, entwickelt seine Anwendungen in der Regel direkt auf der Cell-Plattform. Wenn nur eine Playstation 3 zur Verfügung steht, ist ein Linux-PC als Entwicklungsplattform sinnvoll: Der Speicher der Playstation ist mit 256 MByte nicht gerade üppig dimensioniert, was sich vor allem mit einer X11-Oberfläche bemerkbar macht.
Allerdings ist reale Cell-Hardware nicht unbedingt nötig. Zunächst reicht das bei IBM kostenlos erhältliche Software Development Kit [2]. Es passt für die Plattformen x86, x86_64 und PowerPC sowie für Cell-basierte Linux-Rechner.
Die neueste Version 3.1 des Cell-SDK unterstützt Fedora 9 und Red Hat Enterprise Linux 5.2. Sie umfasst die CD-Images »Developer« und »Extras« und ein RPM-Paket mit dem Installationsskript. Bis zur Version 3.0 lieferte das Cell-SDK für Fedora einen Systemsimulator mit, um die Anwendungen auch ohne reale Cell-Hardware zu testen und zu optimieren. Ab Version 3.1 ist der Simulator separat von der IBM-Webseite zu beziehen [3]. Die gerade erhältliche Version 3.1 ist eine Betaversion, funktioniert aber reibungslos unter Fedora 9.
Als Mindestanforderungen für die Hardware nennt IBM einen Intel Pentium 4 mit 2 GHz oder einen AMD Opteron für den Sockel F. Weiter benötigt das SDK 1 GByte Hauptspeicher und 5 GByte freien Plattenplatz. Für die Installation des Cell-SDK braucht die Linux-Installation die Pakete »rsync«, »sed«, »TCL« und »wget«. Der Rechner bedarf schließlich während der Installation eines Internetzugangs, da das Installationsskript diverse Pakete vom Barcelona Supercomputer Center nachlädt [4].
Cell-Kulturen anlegen
Das RPM-Paket »cell-install-3.1.0-0.0.noarch.rpm« kreiert das Verzeichnis »/opt/cell«, in das später die Entwicklungsumgebung samt Dokumentation wandert. Das Installationsskript akzeptiert den Pfad zu den CD-Images als Option:
/opt/cell/cellsdk --isoVerzeichnispfad install
Diese Variante hat den Vorteil, dass man den Inhalt beider Images in einem Durchgang installieren kann. Sind die CD-Images des Cell-SDK auf CDs gebrannt, legt man nacheinander die Developer- und die Extras-CD ein und startet jeweils das Installationsskript separat mit »/opt/cell/cellsdk install«. Wer den Systemsimulator installiert hat, initialisiert ihn mit dem Skript »/opt/cell/cellsdk_sync_simulator«, wodurch er einige benötigte Teile des SDK nachinstalliert.
Die ISOs enthalten Bibliotheken und Werkzeuge, die größtenteils nicht quelloffen sind. Installationsdetails und Dokumentation befinden sich in »/opt/cell/sdk/docs/install«.
|
Cell Broadband Engine |
|---|
|
Sony Computer Entertainment, Toshiba und IBM entwickelten seit etwa 2001 die auf effiziente Verarbeitung von großen Datenströmen spezialisierte Cell Broadband Engine Architecture (CBEA). Große Datenströme kommen zum Beispiel in Multimedia-Anwendungen oder Computerspielen vor. Die erste Implementierung dieser Architektur ist die Cell Broadband Engine, auch Cell-Prozessor genannt, aus dem Jahr 2005 (Abbildung 1).  Abbildung 1: Die Cell-CPU ist in 90-Nanometer-Technologie gefertigt, die Transistoren auf Isoliermaterial aufbringt (Silicon on Insulator, SOI). (© Foto: IBM) Der Cell-Prozessor besteht aus einem konventionellen Prozessorkern (Power Processing Element, PPE) mit 64-bittiger IBM-Power-Architektur und acht so genannten Synergistic Processing Elements (SPE, siehe auch Abbildung 2). Jedes der acht SPEs verfügt über einen lokalen Speicher von 256 KByte und einen DMA-Controller (Memory Flow Controller, MFC). Alle neun Prozessoren sind untereinander, mit dem Hauptspeicher und mit den Peripheriegeräten durch einen Datenbus (Element Interconnect Bus, EIB) verbunden. 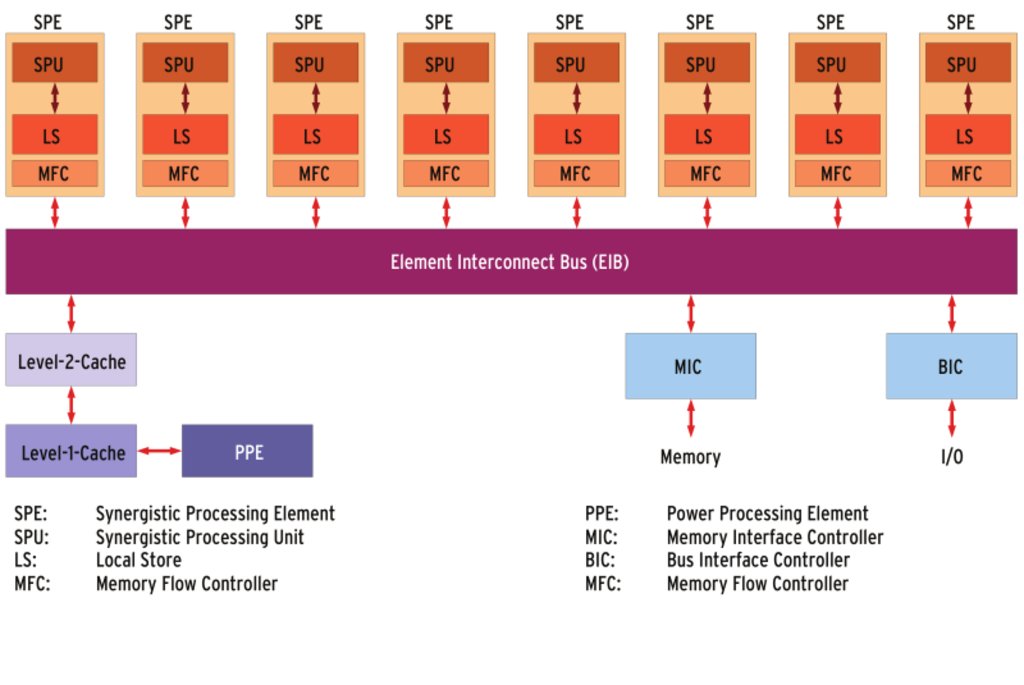 Abbildung 2: Jedes Synergistic Processing Element (SPE) hat eine Synergistic Processing Unit (SPU), einen lokalen Speicher (LS) und Speicher-Controller (Memory Flow Controller, MFC). Vor dem Hauptspeicher sitzt ein Memory Interface Controller (MIC), vor der Ein-/Ausgabe ein Bus Interface Controller (BIC). Während das Betriebssystem auf dem PPE die Systemressourcen verwaltet, spezialisieren sich die SPEs auf algebraische Operationen. Ihre 128-Bit-Register verarbeiten pro Operation entweder vier 32-Bit-Zahlen (kurze Ganzzahlen oder Fließkommazahlen mit einfacher Genauigkeit) oder zwei 64-Bit-Zahlen (lange Ganzzahlen oder Fließkommazahlen mit doppelter Genauigkeit). Diese SIMD-Architektur (Single Instruction, Multiple Data) entspricht den MMX-Erweiterungen von PC-Prozessoren. Eine Besonderheit der SPEs ist, dass sie nur mit Code und Daten arbeiten, die in ihrem lokalen Speicher liegen, also nicht auf den Hauptspeicher oder die Peripheriegeräte zugreifen. Anwendungen müssen selbst dafür sorgen, dass der richtige Code und die richtigen Daten lokal vorhanden sind. Die dazu notwendigen Datentransfers zwischen Hauptspeicher und lokalem SPE-Speicher organisiert deren DMA-Controller, ohne die SPU zu belasten. Die größte Verbreitung hat der Cell-Prozessor vermutlich in der Sony Playstation 3 gefunden (Abbildung 4). Seine spektakulärste Anwendung ist hingegen mit Sicherheit der Roadrunner (Abbildung 5), der an der Spitze der Top-500-Liste steht und über 12000 Cell-Prozessoren nutzt [5]. Drei Cell-basierte Systeme führen zurzeit die Green-500-Liste an [6], die die Rechner der Top-500-Liste nach Energieeffizienz ordnet. Auf Server-Level finden sich Cell-Blades außer bei IBM auch bei Mercury Computer Systems, die außerdem eine PCI-Express-Karte mit einem kompletten Cell-Prozessor-Rechner darauf gebaut haben. Toshiba steckt in seine Qosimo-Notebooks eine Variante des Cell-Prozessors mit nur vier SPEs und ohne PPE, den der Hauptprozessor des Notebooks steuert. |
Die PPE-Kultur
Ihre besondere Stärke zeigen Cell-Rechner bei Problemen, die einerseits viel Rechenleistung benötigen, sich andererseits aber gut in Teilaufgaben zerlegen lassen. Die einzelnen Kerne des Cell-Prozessors bearbeiten sie dann parallel und weitgehend unabhängig. Ein einfaches Beispiel ist die näherungsweise Berechnung der Kreiszahl Pi mit dem Schrotflinten-Algorithmus (siehe Kasten “Die mathematische Schrotflinte”).
Anwendungen für den Cell-Prozessor bestehen aus mindestens zwei Teilen: einem Programm, das auf dem Power-PC-Kern läuft (PPE-Programm), und wenigstens einem Programm, das die SPEs beschäftigt (SPE-Programm). Damit das PPE-Programm die SPE-Software steuern kann, muss der PPE-Quelltext die Headerdatei »libspe2.h« der Libspe2-Bibliothek einbinden. Das SPE-Programm enthält die eigentlichen Rechenroutinen. Für die Kommunikation mit dem PPE und anderen SPEs sowie für die SIMD-Rechenfunktionen muss ein SPE-Programm die Headerdateien »spu_intrinsics.h« und »spu_mfcio.h« einbinden.
Das Beispielprogramm für den Schrotflinten-Algorithmus [7] übernimmt beim Start die Zahl der zu erzeugenden Zufallszahlenpaare und die Zahl der SPEs vom Anwender. Nachdem die »main()«-Routine in »pi_libspe_ppe.c« dafür die Kommandozeile ausgewertet hat, allokiert das Programm dynamisch drei Speicherbereiche. Das erste Array speichert für jedes SPE eine Struktur mit den Parametern, die PPE und SPE austauschen. Den Typ dieser SPE-Strukturen »spe_par_t« deklariert die Headerdatei »pi_libspe.h« (Listing 1). Das zweite Array enthält für jedes SPE eine Struktur, die den so genannten SPE-Kontext speichert. Er enthält alles, was das PPE über ein Programm wissen muss, das auf einem SPE läuft. Den zugehörigen Datentyp deklariert »libspe2.h«.
|
Die mathematische |
|---|
|
Es gibt zahlreiche Möglichkeiten, numerisch einen Näherungswert für die Kreiszahl Pi zu berechnen. Bei dem so genannten Schrotflinten-Algorithmus bestimmt der Rechner Paare von Zufallszahlen zwischen 0 und 1 (Abbildung 3). Jedes Paar entspricht einem Punkt in einem Quadrat mit der Kantenlänge 1, wobei die linke untere Ecke die Koordinaten (0,0) und die rechte obere Ecke die Koordinaten (1,1) hat. Zusätzlich zählt man die Zahl der Punkte, deren Abstand von der linken unteren Ecke des Quadrats kleiner oder gleich 1 ist, die mit anderen Worten innerhalb eines Kreises mit Radius 1 um die linke untere Ecke des Quadrats liegen. 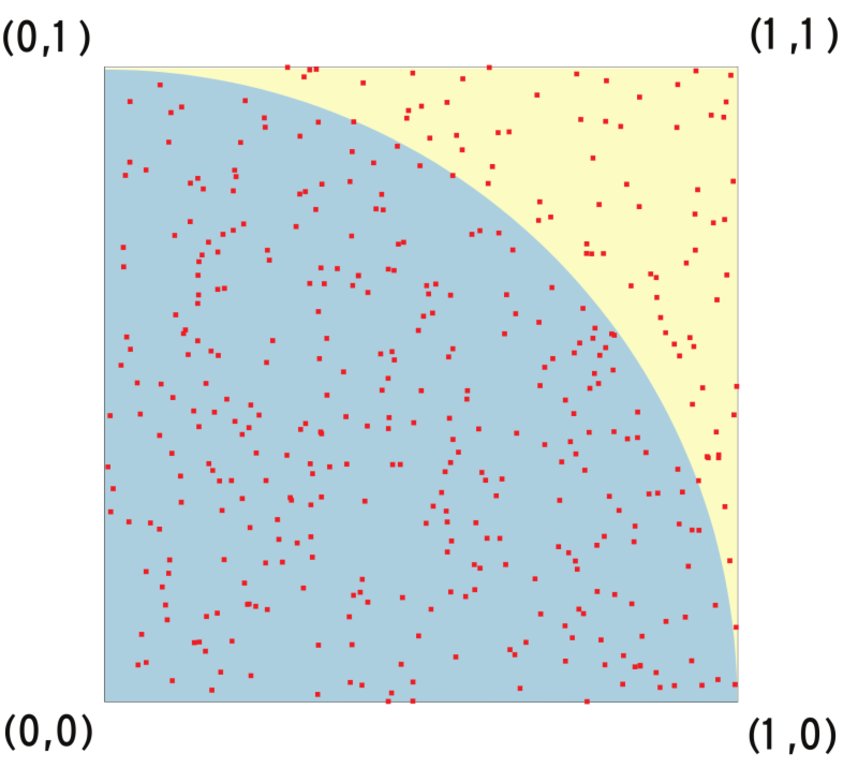 Abbildung 3: Jeder rote Punkt entspricht einem Paar von Zufallszahlen. Zählt man die Punkte auf der blauen Kreisfläche und dividiert das Ergebnis durch die Gesamtzahl der Punkte, so erhält man näherungsweise Pi/4. Unter der Annahme, dass die Punkte gleichmäßig über das Quadrat verteilt sind, ist das Verhältnis der Zahl der Punkte, die innerhalb des Einheitskreises liegen, und der Gesamtzahl der Punkte näherungsweise gleich dem Verhältnis der Flächen eines Viertelkreises mit Radius 1 und eines Quadrats mit der Kantenlänge 1, das gerade Pi/4 ist. |
|
Listing 1: Headerdatei |
|---|
01 #ifndef PI_LIBSPE_H_
02 #define PI_LIBSPE_H_
03
04 typedef struct {
05 float value;
06 uint64_t rounds;
07 uint64_t seed;
08 char reserved[4];
09 } spe_par_t;
10
11 #endif /*PI_LIBSPE_H_*/
|
Ganz oder gar nicht
Die Startadressen für Variablen, die später zwischen PPE und SPE ausgetauscht werden sollen, müssen zwingend ein ganzzahliges Vielfaches von 16 sein und für den optimalen Datentransfer sogar ein ganzzahliges Vielfaches von 128. Das erreicht der Programmierer, indem er anstelle der konventionellen »malloc()«-Funktion die Funktion »posix_memalign()« verwendet. Die Größe der einzelnen Blöcke, die später zwischen PPE und SPE übertragen werden, müssen ebenfalls ein Vielfaches von 16 sein. Treten beim Testen der Anwendung unerklärliche Busfehler auf, liegt das oft an mangelhafter Ausrichtung der Startadressen oder illegaler Größe der übertragenen Datenblöcke. Das dritte Array wird hingegen nur innerhalb des PPE-Programms benutzt und muss daher keine besonderen Anforderungen an Ausrichtung oder Größe erfüllen.
Zufallsprinzip
Das PPE-Programm enthält eine Schleife (Listing 2), die die Arbeit auf die beteiligten SPEs verteilt und einen Startwert für die Erzeugung von Pseudo-Zufallszahlen aus der aktuellen Systemzeit ermittelt. Es braucht drei Schritte, um ein Programm auf einem SPE zu starten. Erstens muss die Funktion »spe_context_create()« (Zeile 7) einen SPE-Kontext erzeugen. Zweitens muss die Funktion »spe_program_load()« (Zeile 8) das auszuführende Programm angeben, wozu der Programmierer im Kopfteil des PPE-Programms die Variable »spe_program_handle_t« deklariert. Diese Variable deklariert er auf jeden Fall extern, also außerhalb jeder Funktion. Ihr Name ist identisch mit dem Namen, den das SPE-Programm später beim Übersetzen bekommt.
|
Listing 2: For-Schleife zur |
|---|
01 for ( i = 0; i < numspe; i++ ) {
02 spe_par[i].rounds = rounds / numspe;
03 gettimeofday( &tv, NULL );
04 spe_par[i].seed = tv.tv_sec * 1000000 + tv.tv_usec;
05 spe_par[i].value = 0.0;
06
07 spe_ctx[i] = spe_context_create(0,NULL);
08 spe_program_load( spe_ctx[i], &pi_libspe_spe );
09
10 pthread_create( &spe_thread_handle[i], NULL,&spu_pthread, &spe_ctx[i] );
11
12 myaddr = (uint64_t) &spe_par[i];
13 spe_in_mbox_write( spe_ctx[i], ( unsigned int * ) &myaddr, 2, SPE_MBOX_ANY_NONBLOCKING );
14 }
|
Im dritten Schritt startet die Funktion »spe_context_run()« das auszuführende Programm. Diese Funktion würde das PPE-Programm allerdings so lange blockieren, wie das SPE-Programm läuft, und verhindern, dass es weitere SPE-Programme parallel startet. Zur Abhilfe tritt ein Posix-Thread auf den Plan. Er führt die Funktion »spu_pthread()« aus (Zeile 10), die wiederum ein SPE-Programm startet, ohne den weiteren Ablauf des PPE-Programms zu stören.
Das gestartete SPE-Programm muss nun erfahren, wo die Parameter für die anstehenden Berechnungen zu finden sind. Jedes SPE hat eine Mailbox für eingehende Nachrichten (vier 32-Bit-Worte) und eine Mailbox für ausgehende Nachrichten (ein 32-Bit-Wort). Eine weitere Mailbox löst einen Software-Interrupt aus, wenn Daten anliegen. Im vorliegenden Fall übermittelt das PPE-Programm mit »spe_in_mbox_write()« (Zeile 13) die Startadresse der Struktur, in der die Parameter für die Berechnung gespeichert sind. An welches SPE die Nachricht geht, bestimmt der SPE-Kontext, dessen Startadresse das erste Argument der Funktion ist.
Wenn alle SPE-Programme beendet sind, gibt das PPE-programm den Speicherplatz für den betreffenden SPE-Kontext frei. Zum Abschluss schreibt das PPE-Programm die Ergebnisse der SPEs auf die Konsole.
Die SPE-Kultur
Die eigentliche Arbeit auf den SPEs geschieht in der Funktion »compute_pi()« (Listing 3). Sie benötigt den Startwert für die Berechnung von Pseudo-Zufallszahlen und die Zahl der Zahlenpaare, die sie erzeugt, als Argumente. Zurück gibt sie einen Näherungswert für Pi als Funktionswert. Die »main()«-Funktion (Listing 4) liest dafür die Hauptspeicher-Adresse, an der die Struktur mit den Parametern für das aktuelle SPE-Programm zu finden ist, aus der Mailbox. Diese Adresse heißt auch effektive Adresse.
|
Listing 3: Funktion |
|---|
01 float compute_pi( long int seed, uint64_t rounds )
02 {
03 uint64_t i;
04 uint64_t in = 0;
05 float x, y;
06 unsigned long int h;
07
08 srand48( seed );
09
10 for ( i = 0; i < rounds; i++ ) {
11 x = (float) lrand48()/RAND_MAX;
12 y = (float) lrand48()/RAND_MAX;
13
14 if (( x * x + y * y ) < 1.0 ) {
15 in++;
16 }
17 }
18
19 return ( float ) 4.0 * in / rounds;
20 }
|
|
Listing 4: Hauptfunktion des |
|---|
01 int main ()
02 {
03 uint32_t ea_block_h, ea_block_l;
04 uint32_t tag_id;
05 spe_par_t spe_par __attribute__ ((aligned(16)));
06
07 ea_block_h = spu_read_in_mbox();
08 ea_block_l = spu_read_in_mbox();
09
10 tag_id = mfc_tag_reserve();
11
12 spu_mfcdma64( &spe_par, ea_block_h, ea_block_l, sizeof( spe_par_t ), tag_id, MFC_GET_CMD );
13 mfc_write_tag_mask( 1 << tag_id );
14 mfc_read_tag_status_all();
15
16 spe_par.value = compute_pi( spe_par.seed, spe_par.rounds );
17
18 spu_mfcdma64( &spe_par, ea_block_h, ea_block_l, sizeof( spe_par_t ), tag_id, MFC_PUT_CMD );
19 mfc_write_tag_mask( 1 << tag_id );
20 mfc_read_tag_status_all();
21
22 mfc_tag_release( tag_id );
23
24 return 0;
25 }
|
Da die Funktion »spu_read_in_mbox()« nur einzelne 32-Bit-Worte lesen kann, muss sie zweimal laufen, um die vollständige 64-Bit-Adresse zu empfangen (Zeilen 7 und 8). Die Variablen, die innerhalb des SPE-Programms deklariert sind, liegen alle im lokalen Speicher des jeweiligen SPE. Pointer zeigen ebenfalls auf Speicheradressen im lokalen Speicher. Da der Cell-Prozessor eine Big-Endian-Architektur hat, enthält das erste Wort die höherwertigen und das zweite die niederwertigeren Bits.
Im nächsten Schritt reserviert das SPE-Programm eine Tag-ID, um DMA-Datentransfers zwischen Hauptspeicher und lokalem Speicher zu unterscheiden (Zeile 10). Ein SPE kann bis zu 32 Tag-IDs verwalten. Anschließend überträgt die Funktion »spu_mfcdma64()« den Parameterblock, auf den die vorher aus der Mailbox gelesene Adresse im Hauptspeicher zeigt, in die Variable »spe_par« im lokalen Speicher (Zeile 12). Diese Funktion beherrscht sowohl lesende als auch schreibende DMA-Transfers. Das sechste Argument bestimmt die Richtung, wie der Vergleich mit Zeile 18 zeigt.
Die Funktion »spu_mfcdma64()« wartet nicht, bis der Speicher-Transfer beendet ist. Um die Vollständigkeit der Daten sicherzustellen, muss das SPE-Programm anhalten, bis der DMA-Controller (Memory Flow Controller, MFC) fertig ist. Dazu dient die Funktion »mfc_read_tag_status_all()« (Zeile 14). Auf welche der 32 möglichen parallelen DMA-Transfers sie wartet, verrät die Funktion »mfc_write_tag_mask()« (Zeilen 19 und 20). Jetzt beginnt die eigentliche Berechnung. Das Ergebnis, das nun auch in der Struktur »spe_par« gespeichert ist, wandert wieder in den Hauptspeicher. Ganz zum Schluss gibt Zeile 22 die Tag-ID wieder frei.

Abbildung 4: Der bekannteste Anwendungsfall für den Cell-Prozessor ist die Playstation 3 von Sony … (Bild: © Foto: Sony Computer Entertainment)
Leben einhauchen
Nun geht es an das Erstellen der Objektdateien. Das Steuerungselement PPE und das Rechenelement SPE verwenden unterschiedliche Befehlssätze. Daher kommen beim Übersetzen zwei verschiedene Compiler zum Einsatz:
/opt/cell/toolchain/bin/spu-gcc -o pi_libspe_spe.spuo pi_libspe_spe.c /opt/cell/toolchain/bin/ppu-gcc -c pi_libspe_ppe.c
Die Endung ».spuo« verdeutlicht, dass die Objektdatei auf dem Befehlssatz des SPE basiert. Um zu einer einzigen ausführbaren Datei zu kommen, bringt das Tool »ppu-embedspu« den Objektcode des SPE-Programms in eine für das PPE lesbare Form:
/opt/cell/toolchain/bin/ppu-embedspu pi_libspe_spe pi_libspe_spe.spuo pi_libspe_spe.o
Der erste Parameter ist der Name, unter dem das PPE das SPE-Programm anspricht. Er ist identisch mit dem Namen der Variablen vom Typ »spe_program_handle_t«, die die Datei »pi_libspe_ppe.c« deklariert. Der zweite Parameter ist der Name der Datei, die den SPE-Objektcode enthält, und der dritte benennt die Datei, in die »ppu-embedspu« den PPE-lesbaren Objektcode schreiben soll. Als Letztes muss der Entwickler die Objektdateien für das PPE- und das SPE-Programm zu einer ausführbaren Datei zusammenfassen und mit der »libspe2«-Bibliothek verlinken:
/opt/cell/toolchain/bin/ppu-gcc -o pi_libspe pi_libspe_ppe.o pi_libspe_spe.o -lspe2
Wer einen Rechner mit Cell-Hardware greifbar hat, muss jetzt nur noch die ausführbare Datei »pi_libspe« dorthin kopieren und ausführen. Verwendet man den Simulator, ist ein kleiner Umweg nötig.
Existenz simulieren
Bevor sich der Cell Full System Simulator starten lässt, muss die Umgebungsvariable »SYSTEMSIM_TOP« den Pfad seines Installationsorts enthalten. Standardmäßig ist das »/opt/ibm/systemsim-cell«. Den Simulator selbst erweckt zum Leben das Kommando:
/opt/ibm/systemsim-cell/bin/systemsim -g
Die Option »-g« startet eine Tcl/Tk-basierte grafische Oberfläche (Abbildung 6). Der Simulator beherrscht verschiedene Modi (Schaltfläche »Mode«). Für einen einfachen Funktionstest ist der »Fast Mode« am günstigsten (gleichnamige Schaltfläche). Ein Klick auf »Go« startet den Simulator. Das Konsolenfenster zeigt nun den Bootvorgang des Betriebssystems des simulierten Cell-Rechners.
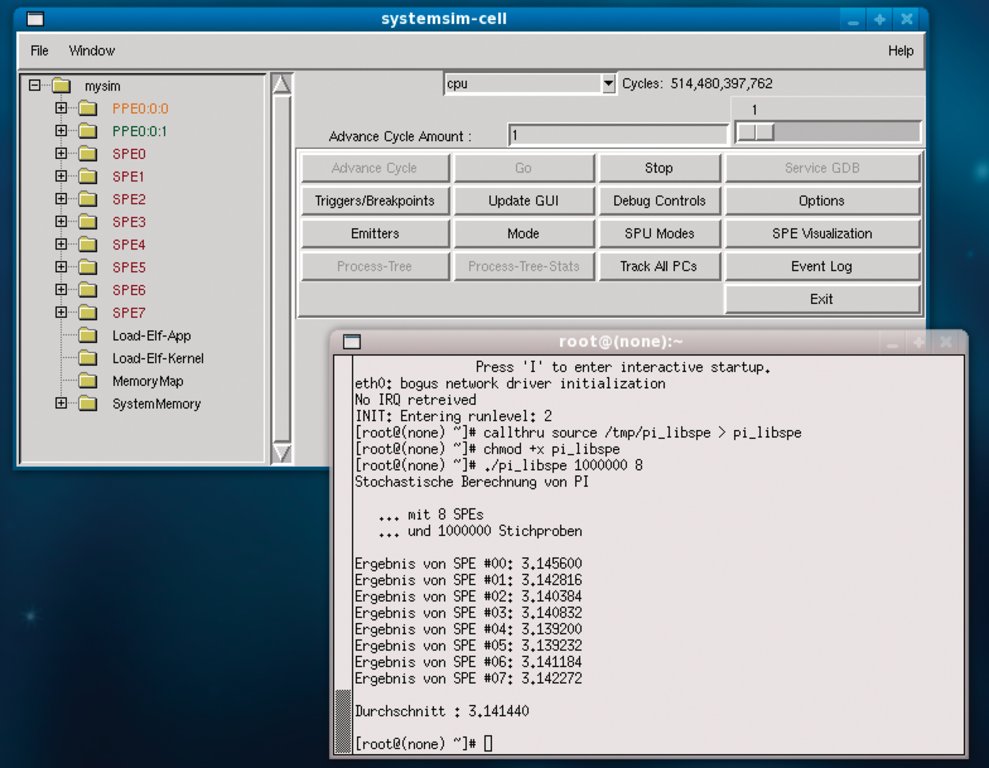
Abbildung 6: Der Cell Full System Simulator von IBM macht reale Cell-Hardware fürs Erste unnötig.
Das zu testende Programm in den Simulator zu laden, ist Aufgabe des Kommandos »callthru«. Ohne Parameter aufgerufen, erzeugt das Kommando einen Hilfetext. Eine ausführbare Datei, die auf dem physikalischen Rechner mit dem Pfad »/tmp/pi_libspe« gespeichert ist, importiert das Kommando:
callthru source /tmp/pi_libspe > pi_libspe
Nach Änderung der Zugriffsrechte, etwa mit »chmod u+x pi_libspe«, kann man endlich das Programm starten:
./pi_libspe 1000000 8
Das Programm veranlasst den simulierten Rechner dazu, eine Million Paare von Zufallszahlen zu erzeugen und dafür acht SPEs zu verwenden. Wie genau das Ergebnis dem vertrauten Wert von Pi entspricht (3,1415926…), hängt von der Qualität der Pseudo-Zufallszahlen ab, ist aber auch durch die Zahl der Versuche begrenzt. Der statistische Fehler ist ungefähr gleich dem Kehrwert der Quadratwurzel aus der Zahl der Versuche. Bei einer Million Versuchen ist die Abweichung des errechneten genäherten Wertes vom tatsächlichen Wert für Pi ungefähr ein Tausendstel, also etwa 0,003.
Offene Quellen
Ein weiteres Programmiermodell neben der »libspe2«-Bibliothek ist die Bibliothek Data Communication and Synchronization (Dacs). Sie kapselt einige der Hardware-Besonderheiten des Cell und ließe sich so prinzipiell auch auf andere Beschleuniger-Architekturen portieren. Das Accelerator Library Framework (ALF) realisiert dagegen ein Programmiermodell, das einzelne Funktionen auf die SPEs auslagert. Dacs und ALF sind in der IBM-Entwicklungsumgebung enthalten.
Das Multicore Application Runtime System (Mars) hingegen ist eine von Sony getriebene Open-Source-Entwicklung [8]. Mars installiert auf den SPEs kleine Kernel, die autonom die Ausführung von Programmen auf “ihrem” SPE steuern. Die neueste Version 1.0.1 datiert von Mitte November 2008 und liegt als RPM-Paket und Tar-Archiv vor. (ake)
|
Infos |
|---|
|
[1] Linux auf der PS 3: [http://en.wikipedia.org/wiki/Linux_for_PlayStation_3] [2] Cell-SDK: [http://www.ibm.com/developerworks/power/cell] [3] Cell-Systemsimulator: [http://www.alphaworks.ibm.com/tech/cellsystemsim] [4] Barcelona Supercomputer Center:[http://www.bsc.es] [5] Top 500: [http://www.top500.org] [6] Green 500: [http://www.green500.org] [7] Listings zu diesem Artikel:[ftp://www.linux-magazin.de/pub/listings/magazin/2009/01/cell-prozessor] [8] Mars-Software und Dokumentation: [ftp://ftp.infradead.org/pub/Sony-PS3/mars] |
|
Der Autor |
|---|
|
|






