
© jamestohart / 123rf.com
Wer Prometheus als Zeitreihendatenbank nutzt, kennt das Problem: Je mehr Daten es speichert, desto behäbiger wird es. Thanos, Cortex, Mimir und M3db wollen Abhilfe schaffen – auf ganz unterschiedliche Art und Weise. Wo liegen die Stärken und die Schwächen der Kandidaten?
Ein zentraler Unterschied gegenwärtiger IT-Setups zu jenen der Vergangenheit besteht darin, dass sie meist auf Skalierbarkeit ausgelegt sind. Rechenpower, RAM, Plattenplatz – all das lässt sich heute idealerweise dynamisch hinzufügen oder entfernen. Für den laufenden Betrieb ergeben sich daraus ein paar Herausforderungen, mit denen Administratoren bis zum Aufkommen von OpenStack, Ceph, Kubernetes & Co. kaum konfrontiert waren. Dazu gehört zum Beispiel die Notwendigkeit zu wissen, wann ein guter Moment für das Hinzufügen zusätzlicher Ressourcen ist. “Wenn sie nötig sind”, ist leicht gesagt, denn das führt direkt zur Frage: “Wann sind neue Ressourcen nötig?” Und wie umschifft der Administrator Engpässe und Verzögerungen bei der Lieferung neuer Gerätschaften?
Software für das Trending hilft dabei, eben diese Fragen so früh zu beantworten, dass Admins in Ruhe planen und abends gut schlafen können. Unter der Haube werkelt dabei oft eine Zeitreihendatenbank. Sie sammelt Metrikdaten von allen Instanzen des gesamten Setups in regelmäßigen Abständen ein, speichert sie, korreliert sie und schlägt Alarm, wenn vom Admin gesetzte Grenzwerte überschritten werden.
Prometheus dürfte der im Augenblick am weitesten verbreitete Vertreter dieser Gattung sein. Ursprünglich bei SoundCloud entstanden, findet sich Prometheus inzwischen weltweit in skalierbaren Umgebungen. Hinter Prometheus selbst steckt eine klassische Zeitreihendatenbank. Ihr zur Seite steht ein Alert Manager, der das Auswerten von Metrikdaten samt Alarmfunktion übernimmt. Überdies kommt Prometheus zumeist im Gespann mit Grafana daher, das die Metrikdaten aus Prometheus ausliest und daraus ansehnliche, vor allem aber gut verständliche Graphen zaubert (Abbildung 1). Alles super also, möchte man meinen.
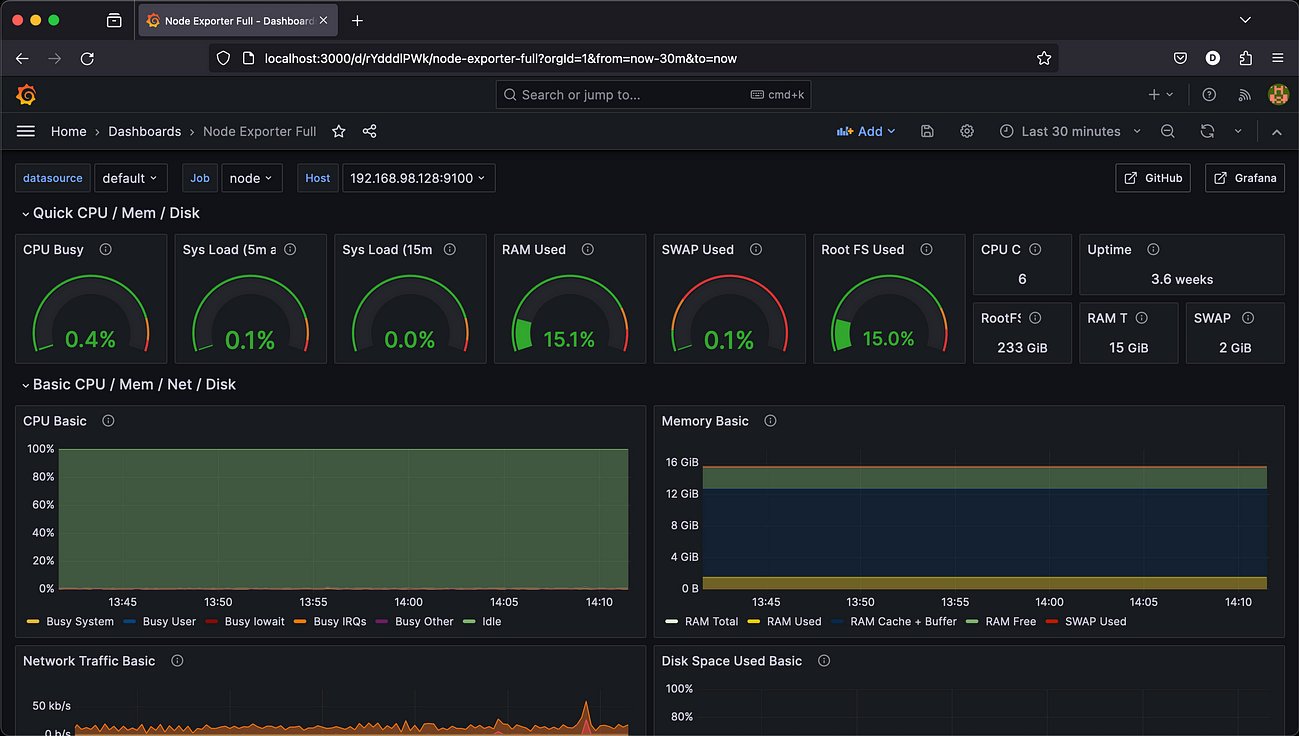
Abbildung 1: Grafana gilt als eierlegende Wollmilchsau in Sachen Datenvisualisierung und kommt oft im Gespann mit Prometheus zum Einsatz. Wer Prometheus skalieren oder Daten darin langfristig ablegen möchte, braucht für die Zeitreihendatenbank aber einen Sparringspartner. Quelle: Grafana Labs
Der schlachterfahrene Prometheus-Admin möchte an dieser Stelle vermutlich widersprechen. Denn so gut Prometheus sich auch dafür eignet, grundlegende Daten für das Trending zu sammeln und nebenbei noch Monitoring auf Basis einzelner Ereignisse zu erlauben, wird die Arbeit doch bald mühsam – immerhin geht es darum, historische Metrikdaten wirklich lange aufzubewahren, um Trends über längere Zeiträume zu erkennen. Quasi als ewiges Problem gilt im Prometheus-Kontext nämlich die Tatsache, dass er immer langsamer wird, je mehr historische Daten er in seinem Depot hält. Mittlerweile sieht die Situation zwar deutlich besser aus als vor ein paar Jahren, aber wer Prometheus mit historischen Metrikdaten eines großen Setups über mehrere Jahre zukleistert, wird mit der Lösung aller Voraussicht nach trotzdem nur wenig Spaß haben. Hier spielen problematische Architekturentscheidungen eine große Rolle, die noch aus der Anfangszeit der Anwendung stammen und sich im Nachhinein schwer oder gar nicht mehr korrigieren lassen.
Wider die Trägheit
“Gar kein Problem”, sagt die Open-Source-Gemeinde und versucht gleich mit mehreren Ansätzen, Prometheus Beine zu machen. Vier stechen aus der Masse hervor: Thanos (Abbildung 2) ist eine Cluster-Lösung mit einem eingebauten Langzeitspeicher [2]. Mit Cortex stellen Sie Prometheus problemlos eine echte Langzeitspeicher-Engine zur Seite. Hinter Mimir wiederum verbirgt sich ein Cortex-Fork, der sich von seinem Urahn mittlerweile aber deutlich unterscheidet und mit eigenen Funktionen aufwartet. Und M3db entspricht einem Wandler zwischen den Welten, der zentrale Designelemente von Thanos mit zentralen Designelementen von Cortex verknüpft.
Admins müssen also eine Entscheidung treffen. Dabei ergibt es Sinn, sich zunächst mit drei Fragen zu beschäftigen: Welche Lösung eignet sich optimal für welchen Einsatzzweck? Wo liegen die individuellen Stärken und Schwächen der Werkzeuge, und was ist im Alltag am einfachsten zu administrieren? Das Linux-Magazin nimmt die vier Probanden unter die Lupe und zeigt, womit Administratoren rechnen dürfen und müssen.
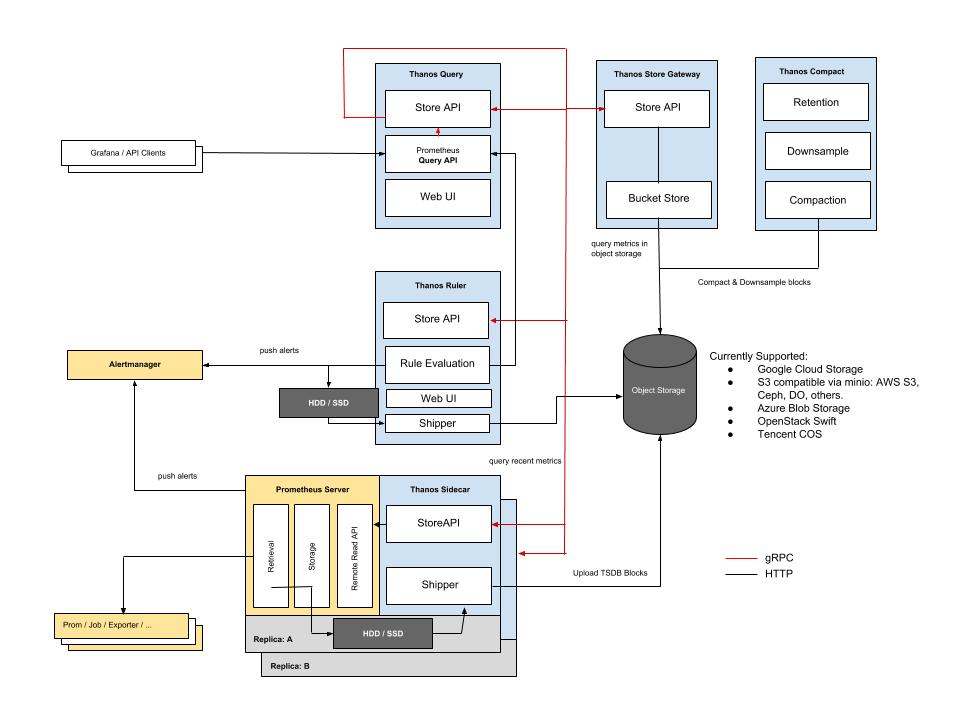
Abbildung 2: Thanos gehört zu den ältesten Skalierbarkeitslösungen für Prometheus und verspricht einen globalen View über alle Daten und flotte Langzeitspeicherung von Daten. Quelle: Thanos
Thanos
Den Anfang beim Schaulaufen macht Thanos. Die Software gehört zu den ältesten, die für Prometheus eine Cluster-Schicht schafft. Damit deckt sie nicht nur den Aspekt des Speicherns von Daten über einen langen Zeitraum ab, sondern will Prometheus effektiv auch HA-fähig machen. Ab Werk ist die Zeitreihendatenbank in dieser Hinsicht eher blank: Die Prometheus-Entwickler gehen einfach davon aus, dass Nutzer bei notwendiger Redundanz einfach mehrere Prometheus-Instanzen gleichzeitig ausrollen können. Weil Prometheus dem Pull-Prinzip folgt und seine Metrikdaten von definierten Zielen selbst einsammelt, könnten die laufenden Prometheus-Instanzen dann ganz simpel parallel permanent alles abgrasen. Das würde allerdings einerseits die Last auf den Datenquellen erhöhen, andererseits führte es dazu, dass es keinen globalen, einheitlichen Query-View für Metrikdaten aus Prometheus gäbe. Diese rüstet Thanos ebenfalls nach: Es sammelt Metrikdaten von unterschiedlichen Prometheus-Instanzen (oder Prometheus-Instanzpaaren), dedupliziert sie und speichert sie schließlich dauerhaft.
Dazu enthält Thanos etliche verschiedene Komponenten. Jeder Prometheus-Instanz stellt die Anwendung erst einmal ein Sidecar zur Seite, also einen Dienst, der sich mit Prometheus verbindet und aus diesem eingehende Daten absaugt. Die schickt das Sidecar an einen Objektspeicher, im Regelfall kommt dazu S3 zum Einsatz. Das muss selbstredend nicht das echte S3 sein, ein lokaler Nachbau etwa auf Basis von MinIO oder RADOS Gateway funktioniert genauso. Die Datenbank unterstützt eine Compactor-Komponente. Sie liest die hinterlegten Metrikdaten regelmäßig aus, führt anhand festgelegter Regeln ein Downsampling aus und legt die Daten dann wieder im Objektspeicher ab. Für die Abfragen von außen steht eine Query-Komponente zur Verfügung. Hier ist der Global View implementiert: Bei der Abfrage von Metrikdaten via Thanos Query stöbert der Admin stets im gesamten Datenbestand.
Praktisch: Alle Komponenten von Thanos lassen sich in die Breite skalieren. Darüber hinaus kann es beliebig viele Query-Instanzen geben, denen Sie dann allerdings einen Loadbalancer voranstellen müssen. Last but not least enthält Thanos eine Komponente namens Ruler. Die kommuniziert vor allem mit dem Alert Manager von Prometheus, oder eher: mit den jeweiligen Alert Managern von mehreren Prometheus-Instanzen oder Prometheus-HA-Pärchen. Auf diese Weise implementiert Thanos eine globale Alarmansicht über sämtliche Prometheus-Instanzen hinweg, Deduplikation inbegriffen.
Datenbankabfragen lassen sich per Thanos Query mit derselben Syntax ausführen, die Prometheus selbst benutzt. Als Query-Sprache dient also PromQL. Daraus ergibt sich außerdem die aus Sicht des Administrators hilfreiche Option, Thanos statt Prometheus als Datenquelle in Grafana zu hinterlegen. Das vereinfacht das Handling in Grafana: Statt mehrere Prometheus-Instanzen nach Daten abzugrasen und sie dann in einem Dashboard zusammenzufügen, holt sich Grafana schlicht die Metrikdaten von Thanos ab, das zuvor bereits eine globale Ansicht hergestellt hat. Hinzu kommt, dass Thanos der Erfahrung der Community nach in kleinen, mittelgroßen und großen Setups wieselflink ans Werk geht und eine hohe Performance liefert.
Schwierige Installation
Die Kehrseite der Medaille bei Thanos ist, dass sich das Deployment des Werkzeugs als deutlich komplizierter herausstellt, als das heute der Fall sein sollte. Wer Thanos etwa zusammen mit Prometheus in Kubernetes ausrollen möchte, findet im Prometheus-Kubernetes-Operator zwar einen Schalter, um Prometheus zusammen mit dem Thanos Sidecar auszurollen. Die Thanos-Dienste selbst muss der Administrator aber mehr oder minder zu Fuß aufsetzen, weil dafür weder fertige Helm-Charts der Autoren noch Anleitungen existieren.
In dieser Hinsicht befindet sich die Lösung nicht auf der Höhe der Zeit, das ginge deutlich besser. Doch hat sich der Administrator sein Thanos erst einmal so zusammengebaut, wie es den eigenen Bedürfnissen entspricht, erhält er damit eine leistungsstarke und sehr zuverlässige Methode für geclustertes Prometheus sowie eine globale Datenansicht über mehrere Instanzen der Zeitreihendatenbank hinweg.
M3db
Wie sehr selbst Enterprise-IT mittlerweile ubiquitär geworden ist, zeigt sich gut am Beispiel von M3 (Abbildung 3). M3 entstammt der Feder von Uber, einem Vermittler von Taxi- und Mietwagenfahrten, und zielte dort von Anfang darauf ab, die mangelnde Skalierbarkeit von Prometheus in die Breite zu umschiffen und Long-Term-Storage von Daten effizient zu erlauben [2]. Die Begrifflichkeiten sorgen an dieser Stelle möglicherweise für Verwirrung – die gesamte Lösung firmiert im Netz sowohl unter dem Namen M3 als auch unter M3db. Hinter letzterem steckt jedoch de facto nur eine Komponente von M3.
Die M3db ist eine klassische Zeitreihendatenbank: Sie besteht aus Storage- und Seed-Nodes, letztere sind im Grunde Storage-Nodes, erledigen aber nebenbei das Cluster-Management für die M3db und erzwingen ein Quorum. Aus der Perspektive der anderen M3-Komponenten wirkt eine M3db allerdings ohnehin wie eine Einzelkomponente, zumal Daten ihren Weg in die M3db gar nicht direkt finden. Dafür gibt es zusätzlich den M3-Coordinator. Aus Sicht des Administrators ist hier vor allem wichtig, dass M3db eine vollständig eigene Datenbank mit eigener Datenhaltung ist. Hier zeigt sich ein zentraler Unterschied zum Thanos-Design, das keine eigene Zeitreihendatenbank mitbringt, sondern die Daten eben als Blob in einem Objektspeicher ablegt.
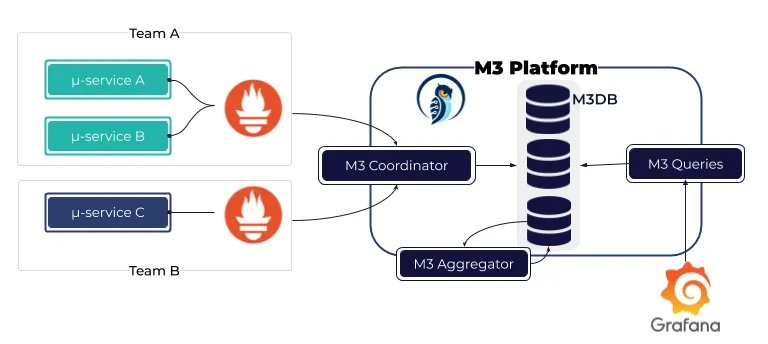
Abbildung 3: M3 kommt von Uber und gleicht in seiner Architektur sowohl Cortex als auch Thanos in Teilen. Die Lösung ist gut in Kubernetes integriert, insgesamt aber recht wenig bekannt. Quelle: Uber
Im Prinzip handelt es sich beim Coordinator um eine Art Sidecar, das jeder Prometheus-Instanz zur Seite gestellt ist und dort Daten mitschneidet, um sie parallel an die M3db zu senden. Damit ähnelt er dem Thanos-Sidecar stark. Analog zum Sidecar in Thanos müssen Sie den M3-Coordinator so ausrollen, dass er einerseits Metrikdaten direkt per Read-API von Prometheus aus dessen Fundus ausliest und sie andererseits weitergibt. Freilich lässt sich auch der M3-Coordinator horizontal skalieren – so vermeiden seine Autoren das Entstehen von Engpässen.
Allerdings gestaltet sich das Deployment des Systems in K8s kaum weniger aufwendig als jenes mit Thanos. Zwar existieren für M3 Helm-Charts, aber im offiziellen Prometheus-Operator für Kubernetes fehlt der Schalter, um das M3-Sidecar in Form des Coordinators gleich zusammen mit Prometheus auszurollen. Im Gegenzug fällt eben wegen des existierenden Operators samt Helm-Chart das Deployment von M3 in Kubernetes deutlich leichter. Die Situation bei M3 gilt aber ebenso wenig als ideal wie bei Thanos.
Zwei weitere Komponenten gehören zu M3, nämlich der Aggregator sowie eine Query-Komponente. Der Aggregator durchforstet auf Grundlage von Regeln des Admins regelmäßig den Datenbestand und wirft nicht mehr benötigte Daten weg. Er dedupliziert auch Datensätze, etwa wenn diese von HA-Setups aus mehreren Prometheus-Knoten stammen, die allesamt dieselben Targets überwachen. Der Query-Dienst schließlich tut genau das, was der Name vermuten lässt: Er bietet die Möglichkeit zur zentralen Abfrage der in M3db hinterlegten Daten per PromQL-Syntax und implementiert so die globale Ansicht, die Prometheus ab Werk fehlt.
Wie Thanos lässt M3 sich dementsprechend hervorragend verwenden, um Prometheus horizontal skaliert zu betreiben, ohne dabei etliche verschiedene Endpunkte für Nutzung und Administration des Monitoring-Systems zu erzeugen. Leichte Schwächen beim Deployment zeigen sich bei M3 ebenso wie bei Thanos, insbesondere im Kubernetes-Kontext. Quasi einen Totalausfall verzeichnet M3 in Sachen Alert-Management: Den Alert Manager von Prometheus lässt das Werkzeug weitgehend außer Acht. Wer Alarme in HA-Setups aus Prometheus deduplizieren und entsprechend versenden möchte, muss das also mit den Bordmitteln des Alert Managers von Prometheus tun. Das klappt zwar, verspricht aber deutlich weniger Komfort und Funktionen.
Cortex
Wenig überraschend kam nicht nur der Fahrdienstleister Uber auf den Trichter, dass Prometheus zwar als Lösung attraktiv ist, aber nicht gut skaliert. Kurz nach Thanos entstand Cortex (Abbildung 4), das dasselbe Problem lösen, sich ihm jedoch aus einer anderen Richtung nähern wollte. Die Stärken von Cortex [3] liegen beim Cloud-native-first-Prinzip und der sich daraus ergebenden praktisch nahtlosen Integration in Kubernetes. Doch der Reihe nach.
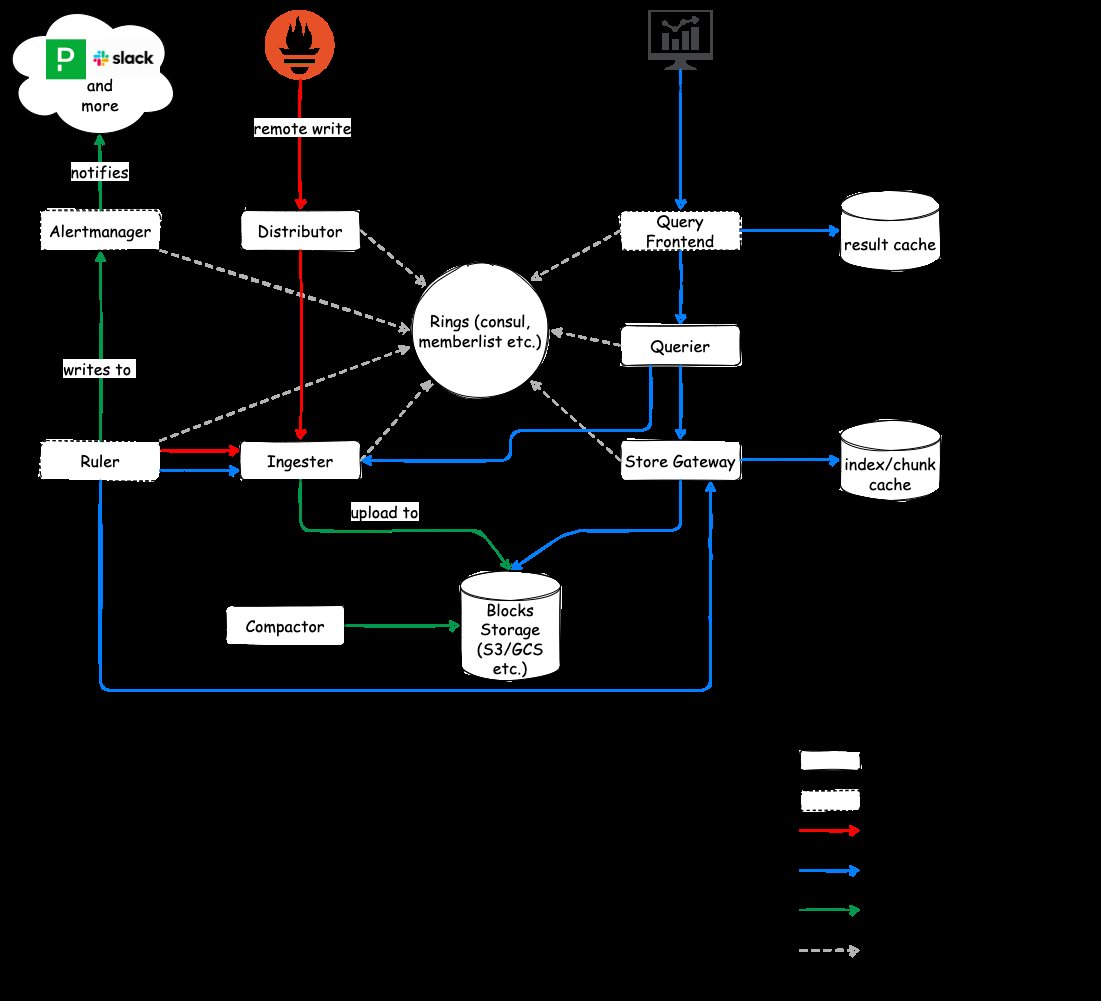
Abbildung 4: Cortex ist eine Art Zwitter aus Thanos und M3, zumindest was die Architektur angeht. Denn ein Sidecar für Prometheus braucht Cortex nicht. Stattdessen fungiert es als Write Engine im Hintergrund. Quelle: Cortex
Unter der Haube weist die Cortex-Architektur deutliche Gemeinsamkeiten mit jener von M3 auf. Auch Cortex selbst ist zunächst eine Zeitreihendatenbank und enthält alle für eine verteilte Datenbank nötigen Komponenten. Interessant ist bei Cortex allerdings die Art und Weise, wie die Daten im Hintergrund gespeichert werden – hinsichtlich dessen entspricht Cortex eher Thanos. Einen echten Datenbankdienst als solchen gibt es nicht, die Daten liegen im Backend stattdessen auf dem Objektspeicher. Das wiederum verschafft Vorteile für Setups, die ohnehin über einen S3-kompatiblen Speicher wie MinIO oder das RADOS Gateway verfügen. Bis Daten in diesem Speicher landen, durchlaufen sie bei Cortex mehrere Stationen.
Bemerkenswert ist bei Cortex zudem, wie das Tool an seine Daten herankommt. Denn anders als Thanos oder M3 dockt Cortex nicht als Client an Prometheus an. Stattdessen konfiguriert der Administrator in seinem Prometheus eine Art internen Cortex-Loadbalancer namens Distributor als Remote-Storage-Ziel. Prometheus bietet seit einiger Zeit die Option, die selbst eingesammelten Daten auch an andere Stellen durchzureichen – genau davon macht Cortex ausgiebig Gebrauch. Der Distributor werkelt im Zusammenspiel mit dem Cortex Ruler, der festlegt, welche der eingehenden Daten wie und wie lange zu speichern sind. Danach gehen die Daten durch eine Komponente namens Ingester hindurch auf den konfigurierten Objektspeicher im Hintergrund.
Der Ingester ist ebenfalls mit der Ruler-Komponente verdrahtet und filtert bereits einen Teil der eingehenden Daten heraus. Der Cortex Compactor erfüllt eine ähnliche Aufgabe wie der M3-Aggregator: Er säubert die hinterlegten Daten auf Grundlage der Regeln in der Ruler-Komponente, dedupliziert sie und schreibt sie am Ende bereinigt wieder auf den Speicher zurück.
Besonderes Augenmerk liegt bei Cortex weiterhin auf den Möglichkeiten zur Abfrage der gespeicherten Daten. Nicht weniger als vier Komponenten bilden den Query Stack der Lösung: Eine API exponiert den Dienst mit PromQL-Schnittstelle zur Außenwelt hin. Im Cortex-Sprech heißt sie Query Frontend. Das Frontend führt einen eigenen Cache, der Abfragen derselben Daten in kurzer Zeit erheblich beschleunigt. Von den Frontends aus gehen die Anfragen bei der Query-Komponente ein. Die kommuniziert mit dem Ruler, um sich von dort zusätzliche Informationen zu den hinterlegten Daten zu holen, leitet die Anfrage ansonsten aber an das Store-Gateway weiter. Das sucht die gewünschten Daten aus dem Objektspeicher im Backend und liefert sie schließlich aus.
Auch das Store Gateway verfügt über einen eigenen Cache und macht so Abfragen Beine. Selbstredend ist jede einzelne Komponente in Cortex implizit redundant und skalierbar. Vom Query-Frontend, das zusätzlich als Endpunkt für die Kommunikation mit Visualisierern wie Grafana dient, können ebenso mehrere Instanzen laufen wie vom Ruler, von den Queriern oder den Store-Gateways. Selbstverständlich besitzt auch Cortex einen Global View, also die Abfrage von Metrikdaten über die Grenzen einzelner Prometheus-Instanzen oder lokaler HA-Setups aus mehreren Prometheus-Knoten hinweg.
Anders als die M3-Entwickler haben die Cortex-Entwickler den Prometheus-Alert-Manager nicht vergessen. Er lässt sich direkt an die Ruler-Komponente anbinden, die eingehende Alarme dedupliziert und daraufhin auf unterschiedliche Arten und Weisen in die Welt posaunen kann. Native Integrationen mit Diensten wie Slack oder PagerDuty und viele weitere stehen zur Verfügung.
Ebenso gut gelöst ist bei Cortex die Integration in Kubernetes. Zwar fehlt eine Anbindung beispielsweise im Prometheus-Operator. Doch das wirkt sich hier nicht allzu kritisch aus, eben weil sich Cortex als Speicherziel über die Prometheus-Konfiguration anbinden lässt. Dafür hält der Prometheus-Operator durchaus die nötigen Schalter und Hebel bereit. Für Cortex selbst existiert eine lückenlose K8s-Anbindung in Form vorgefertigter Helm-Charts. Der gesamte Dienst lässt sich mithin mit relativ wenig Aufwand ausrollen. Wer skalierbaren, flotten Langzeitspeicher für Prometheus schnell am Start in Kubernetes haben möchte, ist mit Cortex bestens bedient.
Mimir
Der letzte Proband im Test ist Mimir (Abbildung 5). Allzu ausführlich muss die technische Betrachtung von Mimir [1] nicht ausfallen – Mimir und Cortex gleichen sich in weiten Teilen, und das ist alles andere als ein Zufall. Historisch stammen beide Produkte von Grafana Labs: Grafana begann erst mit der Arbeit an Cortex und führte sie über mehrere Jahre fort, spaltete dann jedoch das Projekt Mimir ab. Nicht immer geht es in der Open-Source-Szene reibungslos zu, und die Spaltung von Cortex in Cortex und Mimir eignet sich als Beispiel. Ausschlaggebend war seinerzeit vorrangig die Tatsache, dass die Cortex-Entwicklung zwischenzeitlich weitgehend von AWS-Entwicklern und ihren ganz eigenen Vorstellungen davon dominiert war, wie ein skalierbares Prometheus aussehen könne oder müsse.
Wie so oft in der Community stritt man irgendwann über kleinste Details bis auf die Ebene einzelner Commits hinunter. Letztlich zerbrach die ehemalige Cortex-Community in zwei Teile. Aus Sicht eines Administrators ist das nicht unwichtig. Denn bis heute treibt die Entwicklung von Cortex vor allem AWS voran, die von Mimir dagegen vorrangig Grafana Labs.
Die allermeisten Admins würden das intuitiv für einen Vorteil halten: Bei einem Unternehmen wie AWS ist nicht davon auszugehen, dass es pleite geht oder durch Aufkauf einfach vom Markt verschwindet. Der Schein mag an dieser Stelle aber trügen. Zahllose Male haben Großkonzerne wie Google, Microsoft oder AWS in der Vergangenheit bewiesen, dass sie keinerlei Skrupel haben, einzelnen Werkzeugen oder ganzen Abteilungen per Federstrich den Garaus zu machen, sollten die Zahlen nicht stimmen. Käme man bei AWS auf die Idee, das Teamzur Disposition zu stellen, das an Cortex arbeitet, würde das Werkzeug von heute auf morgen das Gros seiner aktiven Entwickler verlieren.
Abbildung 5: Grafana Labs hat laut eigener Aussage bei der gehosteten Variante von Mimir mittlerweile über eine Milliarde aktive Datenserien im Zugriff – und Mimir meistert das ohne Probleme. Quelle: Grafana Labs
Bei Mimir sieht das anders aus: Verglichen mit dem riesigen Tanker AWS ist Grafana eine Nussschale, für die kein riesiger Zoo von Werkzeugen zu verwalten und zu entwickeln ist. Mimir ist für Grafana von strategischer Bedeutung, das Unternehmen bietet den Dienst selbst auch gehostet an. Zugleich ist Grafana mittlerweile zu groß, um in absehbarer Zeit ernsthaft in finanzielle Schwierigkeiten zu geraten. Dass Mimir die Triebfeder der Entwicklung abhanden kommt, gilt vorerst als unwahrscheinlich und mag manchen Administrator eher zu Mimir als zu Cortex neigen lassen.
Technisch sind die Unterscheide marginal. Mimir funktioniert architektonisch wie Cortex; es ist über Helm-Charts hervorragend in Kubernetes integriert und lässt sich einfach und flugs in Betrieb nehmen. Das rührt nicht zuletzt daher, dass Grafana Mimir ordentlich entschlackt hat: Weite Teile der Legacy Codebase von Cortex sind in Mimir nicht mehr enthalten, schlicht weil sie bei gegenwärtigen Setups nicht obsolet sind. Anders als Cortex kommt Mimir als einzelnes Binary, das alle nötigen Funktionen enthält und anbieten kann.
Für spezielle Datenarten wie dem Handling von Kardinalität versprechen die Mimir-Entwickler zudem mehr Performance und eine einfachere Handhabung als bei Cortex. Das ist allerdings ein Nischeneinsatzzweck, der die meisten Admins nicht für Mimir begeistern wird. Schwerer ins Gewicht fällt die Tatsache, dass Mimir die Query-Komponente um eine native Scheduling-Komponente erweitert hat. Sie wählt im Bedarfsfall die passende Instanz zum Abfragen aus. Das macht sich jedoch erst bei sehr großen Setups bemerkbar. Wer sich auf das grundlegende Funktionsprinzip von Cortex oder Mimir festgelegt hat und Thanos oder M3 ausschließt, sollte beide Lösungen ausgiebig evaluieren. Dabei liegt das Hauptaugenmerk idealerweise auf den Eigenheiten der Lösungen im Kontext des jeweiligen Deployment-Szenarios.
Fazit
Die gute Nachricht aus Admin-Perspektive: Ein skalierbares, verteiltes Prometheus ist heute möglich, es funktioniert gut und zuverlässig. Alle vier Probanden im Vergleich liefern überzeugende Ergebnisse, wenn auch auf Grundlage zum Teil völlig unterschiedlicher Architekturen. Als Veteran der Szene punktet Thanos durch Vielseitigkeit, macht aber Abstriche bei der Integration in Prometheus und Kubernetes. M3 bietet eine gute Kubernetes-Integration und ist flott. Allerdings müssen Sie es in einem K8s-Cluster als separaten Dienst zusätzlich zu Prometheus mühsam händisch aufsetzen.
Cortex und Mimir sind eng verwandt miteinander, und die Entscheidung für oder gegen eine der beiden Lösungen ist eher eine philosophisch-strategische als eine technische. Beide Werkzeuge lassen sich exzellent in Kubernetes integrieren und bieten wie Thanos und M3 eine echte globale Ansicht auf alle gespeicherten Metrikdaten inklusive der flotten, langfristigen Speicherung von Daten. Mimir kommt jedoch mit der moderneren und deutlich abgespeckteren Codebasis daher und hat das Momentum innerhalb der Community zumindest im Augenblick bei sich.
Ganz gleich, für welchen der vier Ansätze Admins sich nach entsprechenden Tests entscheiden: Schlecht fahren sie mit keinem der vier Vertreter. Die Open-Source-Community zeigt hier einmal mehr äußerst eindrucksvoll, dass sie auch für die Schaffung von Enterprise-Software und Enterprise-Setups bestens aufgestellt ist. (jcb)
Infos
- Thanos: https://thanos.io
- M3: https://www.uber.com/en-DE/blog/m3
- Cortex: https://www.cortex.io
- Mimir: https://grafana.com/oss/mimir





