
Datenbanken sprechen die gemeinsame Muttersprache SQL – aber in vielen herstellerspezifischen Dialekten. Ein neuer Konverter verspricht zwischen dreizehn Mundarten zu dolmetschen.
Süddeutsche, die nördlich des Weißwurstäquators ein Fleischpflanzl bestellen, werden in der Regel den Hackfleischkloß näher umschreiben müssen, bevor sie – je nach Landstrich – eine Bulette, eine Frikadelle oder gar ein deutsches Beefsteak serviert bekommen. Auf ähnliche, dialektbedingte Verwirrung trifft man selbst in technischen Sprachen: Jener SQL-Datentyp, der eine große Menge Text aufzunehmen vermag, nennt sich in einer Oracle-Datenbank Long, in MS Access Memo, in PostgreSQL Text oder in MySQL Longtext.
Babylon der Datenbanken
Dabei sollte SQL (Structured Query Language) als Datenbank-Esperanto Verständigungsprobleme ausschließen. So gut wie alle Hersteller unterstützen diese Sprache, allerdings jeweils nur auf einer bestimmten historischen Entwicklungsstufe (SQL 89, SQL 92, SQL 99, SQL 2003) bis zu einem gewissen Grad. Daneben pflegen sie weiter eigene Mundarten. Der SQL-Standard wurde extra modularisiert, da 1999 bei der Premiere der dritten Generation bereits keine einzige Datenbank existierte, die auch nur den mittleren der drei Kompatibilitäts-Le- vels des sieben Jahre zuvor in Kraft getretenen Vorgängers vollständig umsetzen konnte.
Seitdem handelt SQL-konform, wer ein Paket aus Kern-Features implementiert und sich aus dem Rest nach Lust und Laune bedient. Hinzu kommen versionsspezifische Unterschiede sowie Eigenheiten der Treiber, bei denen allein der JDBC-Standard schon drei Generationen und vier Typklassen kennt[1].
Das kümmert den Anwender so lange nicht, wie er bei einem System bleibt. Entwickelt er aber für mehrere Plattformen oder möchte die mit MySQL bestückten Laptops seiner Außendienstler mit Auszügen aus der zentralen Oracle-DB versorgen oder plant umgekehrt die Konsolidierung einer breiten Palette vorhandener Datenbanken in einem zentralen System, dann stößt er unweigerlich auf die Sprachbarriere. Für solche Überführungstätigkeiten zwischen unterschiedlichen Datenbanken ist ein guter Dolmetscher gefragt.
Genau für diese Rolle bietet sich der soeben erschienene Eva/3 Universal Database Converter (UDC) der Firma Optadata[2] an. Er spricht 13 SQL-Dialekte von DB 2 über Sybase bis MySQL. Zwischen diesen Idiomen kann er nach Angaben des Herstellers Daten auf Knopfdruck portieren oder konvertieren. Das Linux-Magazin hat mit drei verbreiteten Datenbanken – Oracle 10g, PostgreSQL 8 und MySQL 4.0.18 – getestet, wie nützlich der Sprachmittler für den Datenbank-Admin ist.
Anlaufschwierigkeiten
Die Installation des 30 Euro teuren Tools auf einem Suse Linux Enterprise Server (SLES 9) verlief nicht ganz ohne Schwierigkeiten. Erstes Problem war die von Suse mitgebrachte Java-Version von IBM, unter der es dem Installer nicht gelang, eine bestimmte Krypto-Library zu lokalisieren. Dies funktionierte erst nach einem Umstieg auf Suns SDK 1.4.2, das dafür freilich erst noch nachinstalliert werden musste.
Damit erreicht das Setup-Tool über einen Eröffnungsbildschirm und die obligatorische Einverständniserklärung zu den Lizenzbestimmungen eine Ansicht, die Voreinstellungen wie Installationstyp und -pfad zusammenfasst. Einfluss auf die präsentierte Auswahl hat der Benutzer allerdings nicht und auch der Back-Button verhilft ihm – entgegen den Versprechungen vor seinen Augen – nicht zu einer Mitsprachemöglichkeit.
Fügt sich der Installateur in das Schicksal vorgegebener Pfade und Einstellungen, ist das Programm binnen weniger Minuten eingespielt und einsatzbereit. Nach dem ersten Start muss er dann zunächst die nötigen JDBC-Treiber zur Hand haben, um die Verbindungen zu seinen Datenbanken einrichten zu können. Die Onlinehilfe nennt im Bedarfsfall Adressen von Websites, von denen man die Treiber downloaden kann. Der Dialog für die Datenbankparameter ist selbsterklärend und schnell ausgefüllt. Danach kann es losgehen.
Alle Datenbanken versammeln sich zusammen mit einer Auswahl zugehöriger Objekte in einer aufklappbaren Liste im Hauptfenster der Applikation. Das wird allerdings schnell unübersichtlich, besonders dann, wenn eine größere Anzahl Tabellen und Indizes in unterschiedlichen Datenbanken zu extensivem Scrollen zwingt.
Ungefiltert
Hier wäre ein Fenster pro Datenbank wünschenswert sowie eine Möglichkeit, die angezeigten Objekte zu filtern. Letzteres umso dringlicher, als der Konverter jede Tabelle anzeigt, darunter beispielsweise auch bereits gelöschte, die sich in Oracles Papierkorb befinden und bestimmt nicht konvertiert werden sollen (siehe Abbildung 1). In dieser Liste tauchen neben Tabellen, Schlüsseln und Indizes auch Views auf.
Wer daraus schließt, auch solche Views seien zwischen den Datenbanken übertragbar, sieht sich allerdings getäuscht. Weder per Drag&Drop noch in Verbindung mit den verwendeten Tabellen gelingt eine Übernahme. Weshalb sie dann überhaupt präsentiert werden, bleibt unklar. In der Onlinehilfe kommen die Stichwörter View oder Sicht jedenfalls an keiner Stelle vor.
Einfaches gelingt schnell
In einem ersten Test musste UDC eine umfangreiche, aber einfach aufgebaute Messwertetabelle von MySQL nach Oracle und PostgreSQL konvertieren, die mehr als zehntausend Datensätze enthält. Das gelang problemlos, schnell und korrekt. Auch die vorhandenen Indizes und Primärschlüssel wurden auf dem Zielsystem wieder angelegt (Constraints gehen im Gegensatz dazu verloren). Dafür reichte es bereits aus, die Tabelle aus der Liste der Quelldatenbank in den entsprechenden Abschnitt der Zieldatenbank zu ziehen.
Sieht der Konverter kein Übersetzungsproblem, transferiert er die Daten ohne Nachfrage. Andernfalls bietet er einen Dialog für das Matching der Datentypen an, in den er auf Wunsch nur solche Optionen einschließt, die ihm sinnvoll erscheinen. Allerdings hinkt die Logik an dieser Stelle ein wenig, denn der Administrator kann zwar die Beschränkung auf empfohlene Datentypen aufheben und den Zieltyp selbst vorgeben, doch darf er dann in vielen Fällen offenbar nicht mehr erwarten, dass der Konverter selbst weiß, wie damit umzugehen ist.
Intelligenter Workaround
Als überraschend findiger Kopf erwies sich der Dolmetscher beim Übersetzen einer PostgreSQL-Tabelle, die eine Spalte vom Serial-Typ enthielt. Oracle etwa kennt keine derartigen Felder, die sich selbst weiterzählen (Auto-Inkrement). Deshalb wurden auf Oracle-Seite ersatzweise eine Sequenz und ein Trigger eingerichtet, die diese Funktionalität nachbildeten – sehr gut.
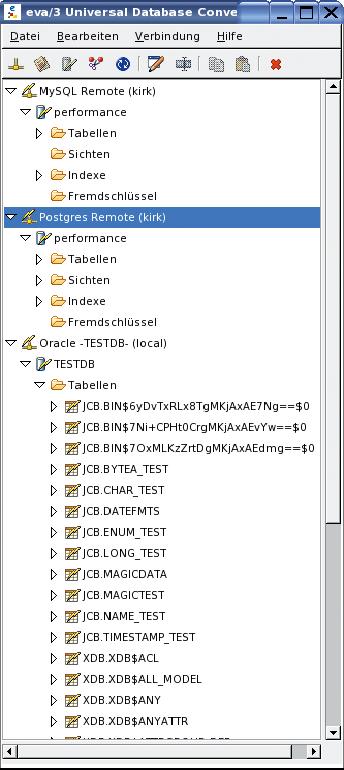
Abbildung 1: Das Hauptfenster des Konverters listet unterschiedslos alle Objekte einer bestimmten Kategorie auf, darunter auch längst gelöschte oder offenbar nicht konvertierbare Sichten.
Noch besser wäre es freilich gewesen, wenn der Admin davon unterrichtet worden wäre und damit eine Chance erhalten hätte, die neuen Objekte später zu pflegen oder bei Bedarf zu entfernen. Außerdem ergab sich so der Seiteneffekt, dass ein mehrmaliges Konvertieren derselben Tabelle – auch wenn sie zuvor gelöscht wurde – an der Fehlermeldung scheiterte, anzulegende Objekte seien bereits vorhanden. Durch diesen Fehler kam übrigens der beschriebene Trick ans Licht, der es doch gar nicht nötig hat, sich zu verstecken.
Falsche Freunde
Schrittweise steigerte sich anschließend der Schwierigkeitsgrad – und prompt ließ sich der Übersetzer aufs Glatteis führen und stolperte über ein Problem, das sonst eher Sprachschülern Kopfzerbrechen macht: die falschen Freunde. Eventually heißt bekanntlich genauso wenig eventuell, wie actually aktuell bedeutet – obwohl sie ähnlich klingen. Und Oracles Char ist trotz Namensgleichheit auch nicht das Gleiche wie MySQLs Char, das lediglich 255 Zeichen aufzunehmen vermag.
Versucht der Anwender eine Tabelle mit einer Char(2000)-Spalte aus Oracle nach MySQL zu übernehmen, wird der Konverter nicht stutzig, sondern macht weiter, bis ihm die Zieldatenbank die Quittung präsentiert: »Too big column length for column \’CHARACTRES\’ (max=255). Use BLOB instead«. Dem guten Rat kann man aber leider nicht folgen, weil UDC die manuelle Auswahl des Zieldatentyps wegen der vermeintlich eindeutigen Zuordnung erst gar nicht anbietet.
Als Gegenstück zum Typ Text in PostgreSQL schlägt der UDC auf Oracle-Seite Varchar2 vor, obwohl dieser Typ im Unterschied zur PostgreSQL-Version (ab 7.1.) auf 4000 Zeichen limitiert ist, also unter Umständen überläuft. Konvertiert man die Text-Spalte nach MySQL, verwendet der Konverter dort den gleichnamigen, hier auf 64 KByte begrenzten Typ und greift damit immer noch zu kurz, wenn ein Konflikt auch weniger wahrscheinlich ist.
Dafür verkünstelt er sich aber zusätzlich bei der SQL-Syntax so, dass die Datenbank nur noch Bahnhof versteht: »CREATE TABLE \’text_test\’ (\’text\’ text(-1) NULL)« führt zu einem Syntaxfehler, »CREATE TABLE text_test (text text)« hätte gereicht und funktioniert.
Ein ähnliches Problem wie mit der unterschiedlichen Kapazität gleichnamiger Datentypen resultiert aus ihrer zuweilen unterschiedlichen Genauigkeit. MySQL etwa löst »TIMESTAMP« nur in ganze Sekunden auf, während sich PostgreSQL oder Oracle im gleichen Datentyp auch Sekundenbruchteile merken. Die fallen bei einer Konvertierung mit Eva/3 UDC unter den Tisch – das ist als Kompromiss akzeptabel, doch einen Hinweis auf den Informationsverlust wäre sicherlich dennoch zu wünschen.
Umgang mit Doppelnamen
Einem weiteren potenziellen Stolperstein – Namenskonflikte durch unterschiedlich reservierte Wörter und bereits vorhandene Objekte – geht der Konverter erfolgreich aus dem Weg. Stößt er auf namensgleiche Tabellen, bietet er an, die Zieltabelle zu überschreiben oder das Objekt umzubenennen. Probleme mit reservierten Wörtern entschärft er durch konsequentes Quoting.
Dabei schießt der Übersetzer jedoch gelegentlich über das Ziel hinaus. So kam es im Test vor, dass beispielsweise Inhalte von Oracle-Tabellen nicht angezeigt werden konnten, weil das entsprechenden Select auch den dem Tabellennamen vorangestellten Namen des Schemas in doppelte Anführungen setzte, woraufhin die Datenbank das Objekt nicht mehr fand.
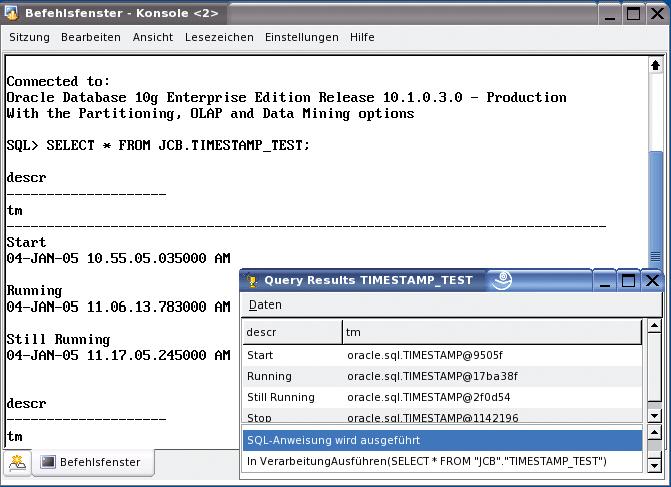
Abbildung 2: Eine Oracle-Tabelle mit Timestamps: In SQLPlus wird der Inhalt korrekt wiedergegeben, die Tabellenansicht des Konverters serviert stattdessen Java-Fragmente.
Überhaupt sind Fehler bei Tabellenabfragen unnötig schwer zu identifizieren, weil der Statusbereich am unteren Rand des Ergebnisfensters die Meldungen so sortiert, dass stets die älteste sichtbar bleibt. Es steht dort also immer die erste, in jedem Fall überholte Nachricht. Um neue Fehlermeldungen zu Gesicht zu bekommen, muss der Benutzer zurückblättern – unpraktisch.
Nicht übersetzbar
Eine ganze Reihe von Datentypen lässt sich überhaupt nicht konvertieren. Das betrifft zum einen verständlicherweise die proprietären Spezialkonstruktionen wie etwa die geometrischen Typen in PostgreSQL. Hier hebt der Konverter rechtzeitig die Hände und meldet »Angegebener Datentyp wird von der Datenbank nicht unterstützt«. Für die speziellen Aufzählungstypen von MySQL (SET, ENUM) werden in PostgreSQL und Oracle Charakter-Typen angeboten – akzeptabel, aber leider fehlt wieder ein Hinweis auf die drohenden Einbußen an Funktionalität.
Ganz aus dem Spiel sind alle benutzerdefinierten Datentypen. Außerdem bleiben offenbar die Binär-Container außen vor. Für einen Oracle-BLOB war bei einer Stichprobe in PostgreSQL jedenfalls zunächst kein empfehlenswerter Zieltyp zu finden und auch mit dem expliziten Hinweis auf »bytea« kam der Konverter nicht weiter als bis zu »Keine Klasse für Typ oracle.sql.BLOB gefunden«.
Fazit
Der Datenbank-Dolmetscher Eva/3 UDC setzt ein interessantes Konzept in Software um – beim gegenwärtigen Entwicklungsstand aber erst auf dem Niveau eines Touristen-Sprachführers. Mit einem besseren Benutzerinterface, auskurierten Kinderkrankheiten und noch mehr Lösungen, die so viel eigene Intelligenz verraten wie die Serial-Emulation, könnte aus ihm aber ein wertvolles Tool für alle Anwender werden, die häufiger Inhalte verschiedener Datenbanken zu konvertieren haben. Zurzeit eignet er sich vor allem für einfache Tabellen, die im Wesentlichen kurze Strings und numerische Werte enthalten, etwa Adressen, Preislisten, Personaldaten und Ähnliches mehr.
Binärdaten, große Textmengen, benutzerdefinierte oder proprietäre Datentypen sind dagegen potenzielle Problemquellen. Der Anwender sollte dem Konverter nicht blind vertrauen, sondern das Ergebnis verifizieren, dann spart er in vielen Fällen zumindest lästige Handarbeit. Die verlangten 29,90 Euro erscheinen als fairer Preis. Einige der Bugs sollen außerdem, wie die Herstellerfirma Optadata mitteilt, bereits behoben sein oder mit dem nächsten kostenlosen Update verschwinden.
Von einem sehr guten Konverter bis zur vollständigen Datenbank-Portierung – bei der neben den Tabellendaten und Indizes auch die Benutzer, Rollen, Rechte, Trigger, Prozeduren, Views und so weiter übernommen werden müssten – wäre es dann aber immer noch ein recht weiter Weg.
|
Infos |
|---|
|
[1] Dokumentation des JDBC-Standards: [http://java.sun.com/products/jdbc/] [2] Datenbank-Konverter Eva/3 UDC: [http://www.optadata.com/de/Eva3_udc.htm] |





