
Geschickte Konfiguration und Geschwindigkeits-optimierte SQL-Selects verbessern die Performance einer Datenbankanwendung ganz ohne zusätzliche teure Hardware merklich – demonstriert am Beispiel von Oracle-Datenbanken unter Linux.
Oracle V2, die erste kommerzielle relationale Datenbank mit SQL als Abfragesprache, erschien 1979 auf dem Markt. Im Jahr zuvor hatte der Stammvater einer späteren CPU-Dynastie das Licht der Welt erblickt, der 8086. Dieser Chip enthielt 29000 Transistoren und wurde mit 8 MHz getaktet. Sein heutiger Nachfahr, der Pentium 4, bringt es auf mehr als 125 Millionen Transistoren, die Taktrate stieg auf über 3 GHz. Selbst wer die Transistorenzahl nicht direkt in Leistung umrechnen mag, kommt auf einen Geschwindigkeitsgewinn von mehreren tausend Prozent. Mit einer solchen CPU sollte Performance für die Anwender der aktuellen zehnten Oracle-Generation kein Thema mehr sein.
Ist es aber. Denn so, wie sich die Anzahl der Transistoren im Anderthalb-Jahres-Rhythmus verdoppelt (Mooresches Gesetz), steigt auch die Komplexität der Anwendungen, wächst der Ressourcenbedarf der Applikationen und nehmen die Erwartungen der Benutzer zu. Im Ergebnis ist das Thema Tuning für Datenbank-Entwickler, -Programmierer und -Administratoren nach wie vor aktuell.
Tägliches Tuning
Für die Datenbank-Beschleunigung gibt es eine Reihe Erfolg versprechender Strategien mit unterschiedlichen Ausgangspunkten. Eine erschöpfende Erörterung füllt Bücher. Dieser Beitrag wird sich auf solche Aspekte konzentrieren, die leicht in der täglichen Praxis anwendbar sind und weder umfangreiches Spezialwissen noch zusätzliche Hard- oder Software erfordern. Er enthält Hintergrundwissen und Tipps, die jedem Datenbank-Administrator dabei helfen
- performante Indizes aufzubauen,
- SQL-Anweisungen effizienter zu formulieren,
- große Tabellen geschickt zu verwalten und
- die User-Connections Ressourcen-schonend zu managen.
Die Performance einer Datenbank hängt von vielen weiteren Faktoren ab. Darunter von der Hardware und vom Betriebssystem des Datenbank-Servers. Die erste goldene Regel für den Linux-Host heißt: Konzentration auf das Wesentliche, unnötige Dienste abschalten, unnötige Kernelmodule nicht statisch laden.
Index – Turbo oder Bremse?
Der Index, das Datenbank-Element, das speziell für die Beschleunigung entwickelt wurde, spielt eine besondere Rolle bei der Performance. Allerdings senkt lange nicht jeder Index die Antwortzeiten, falsch verwendet kann er sich sogar als Bremse erweisen. Neben allgemeinen Regeln für den Index-Aufbau gilt es auch, eine Reihe Oracle-spezifischer Richtlinien zu beachten.
Das betrifft zuerst die Index-Typen, die Oracle anbietet. Neben BTree- kennt es Domain-Indizes (geeignet für Volltextsuche, siehe[5]) und den Bitmap-Index-Typ. Bitmap-Indizes bieten Vorteile für Tabellen, deren Spalten nur wenige Werte annehmen oder die sich auf keine oder nur wenige andere Spalten beziehen. Außerdem haben sie Vorteile bei Abfragen, deren »WHERE«-Klausel Aggregatfunktionen wie »COUNT« oder »SUM« enthält[1]. In diesen Fällen ist der per Default benutzte BTree-Index nicht optimal.
Bitmap-Indizes sind dagegen für Spalten ungeeignet, die regelmäßig aktualisiert werden. In diesem Fall können sie im Gegenteil sogar zur Steigerung der Kosten und zu Performanceverlusten führen. Deshalb empfehlen sie sich auch nicht für OLTP-Anwendungen (Online Transaction Processing).
Den Gewinn, der durch die richtige Wahl des Index-Typs zu erzielen ist, illustriert ein Beispiel: Eine Kundentabelle mit zwei Millionen Zeilen enthält eine Spalte »Geschlecht«. Diese Spalte wird naturgemäß selten upgedatet und kann nur zwei Werte annehmen. In diesem Fall wäre ein BTree-Index 29696 KByte groß, ein Bitmap-Index jedoch nur 753 KByte. Auf einem Testsystem benötigte ein »COUNT« auf diese Spalte mit BTree-Index 1,01 Sekunden, mit Bitmap-Index dagegen nur 0,03 Sekunden.
Schneller ohne Index
Ein Index soll es der Datenbank ersparen, jede Zeile mit der Abfrage zu vergleichen. Liefert sie aber mehr als zehn Prozent der Tabellenzeilen zurück, kann ein Full Table Scan schneller als der Einsatz des Index sein. Wenn möglich, sollte man den Index für solche Spalten löschen. Wird er aber unbedingt gebraucht, lässt sich in einem Select, das ihn nicht verwenden soll, mit dem Hint »FULL« ein Full Table Scan erzwingen. Beispiel: »SELECT /*+ FULL ( Tabellenname) */…«. Oracle versteht den Hinweis allerdings nur, wenn der Optimizer entsprechend konfiguriert ist.
Tabellen, die nur wenige Zeilen enthalten, sollten am besten nicht indiziert werden, weil auch hier ein Table Scan schneller als ein Zugriff über den Index ist. Will der Anwender allerdings mit einem Primärschlüssel Eindeutigkeit erreichen, muss er die eventuell schlechtere Performance in Kauf nehmen.
Unterscheiden sich die Datentypen in einer indizierten Spalte und in der darauf bezogenen »WHERE«-Klausel der Abfrage, wird der Index von Oracle nicht verwendet. Enthält eine Kundentabelle etwa eine Spalte »Kundentyp VARCHAR2«, auf die die Abfrage »WHERE Kundentyp = 324« anzuwenden ist, entspricht der Typ »NUMBER« nicht dem Typ »VARCHAR2« in der Tabelle. Oracle konvertiert dann den Spaltentyp mit »WHERE TO_NUMBER(Kundentyp) = 324« und liest die Tabelle sequenziell, ohne den Index zu Hilfe zu nehmen.
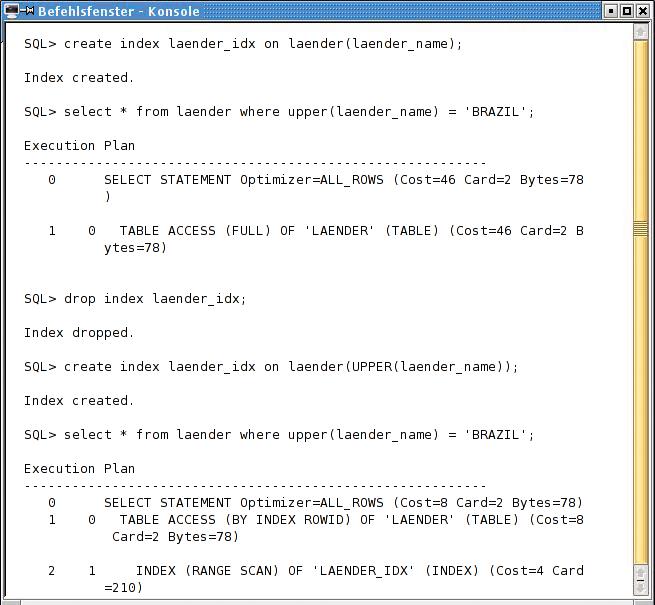
Abbildung 1: Abfragen, die Funktionen enthalten, profitieren nur von Indizes, die auf der Grundlage derselben Funktion aufgebaut sind.
Funktionsträger
Verwendet eine »WHERE«-Klausel Funktionen wie »SUBSTR«, »!=« (ungleich), »NOT«, »TRUNC«, »LOWER«, »UPPER« oder einen der arithmetischen Operatoren, wird ein gewöhnlicher Index für Oracle wertlos. Die Datenbank könnte allerdings einen Index zu Rate ziehen, der auf der Grundlage derselben Funktion aufgebaut wurde. Für einen solchen funktionsbasierten Index ist der Parameter »QUERY_REWRITE_ENABLED« in »init.ora« auf »true« zu setzen und der kostenbasierten Optimizer zu verwenden (mehr dazu weiter unten).
Abbildung 1 demonstriert die Performance einer SQL-Abfrage, die in ihrer »WHERE«-Klausel die SQL-Funktion »UPPER« benutzt. Beim ersten Test ist die Spalte, auf die »UPPER« angewendet wird, zwar indiziert, aber nicht funktionsbasiert. Der Optimizer ignoriert diesen Index völlig. (»TABLE ACCESS (FULL)« ). Die zweite Abfrage erfolgte nach dem Neuaufbau des Index dieser Spalte auf der Grundlage der Funktion »UPPER«. Nun akzeptiert der Optimizer den Index (»INDEX (RANGE SCAN)«).
Mit Indizes sparen
Oracles Optimizer verwendet nur nützliche Indizes. Aber die SQL-Engine behält alle Indizes, die für eine Tabelle definiert sind – unabhängig davon, ob sie bei der Ausführung eines SQL-Statements zum Einsatz kommen oder nicht. Das kostet I/O-Ressourcen und belastet nicht nur den Speicher, sondern auch die CPU, weil der Index bei jedem Insert, Update oder Delete reorganisiert werden muss. Deshalb ist es empfehlenswert, nicht benutzte Indizes zu löschen[1]. Ob ein Index in Gebrauch ist oder nicht, ist mit »ALTER INDEX Indexname MONITORING USAGE;« zu erfahren. Listing 1 zeigt ein SQL-Skript namens »startmi .sql«, das alle Indizes eines Schemas unter Beobachtung stellt.
In der View »V stehen nach Ausführung des Skripts entsprechende Informationen. Über die Spalte »MON« dieser View ist feststellbar, ob der Index momentan beobachtet wird. Die Spalten »START_MONITORING« und »STOP_MONITORING« geben den Beobachtungszeitraum an, die Spalte »USE« sagt, ob der Index verwendet wurde. Trifft dies nicht zu, lässt sich daraus natürlich nicht automatisch schließen, dass der Index überflüssig ist. Es könnte ja auch sein, dass er selten benötigt wird. »ALTER INDEX Indexname NOMONITORING USAGE« unterbricht die Beobachtung.
|
Listing 1: |
|---|
01 SET PAGESIZE 0
02 SET FEEDBACK OFF
03 SET VERIFY OFF
04 ACCEPT v_value CHAR PROMPT 'index_name oder "alle" eingeben um das Monitoring durchzufuehren: '
05 SPOOL start_monitoring_idx.sql
06 SELECT 'ALTER INDEX ' || lower(index_name) || ' MONITORING USAGE;'
07 FROM user_indexes
08 WHERE index_type = 'NORMAL' AND index_name LIKE decode(UPPER('&v_value'), 'ALLE', '%', UPPER('&v_value'));
09 SPOOL OFF
10 @START_MONITORING_IDX.SQL;
11 SET FEEDBACK ON
12 SET VERIFY ON
13 SET PAGESIZE 24
|
Fragmentierung kontrollieren
BTree-Indizes können mit der Zeit durch Updates oder Inserts fragmentiert werden. Dem kann der Admin beim Aufbau eines Index (und nur dann, nicht nachträglich) entgegenwirken, indem er mit dem Parameter »PCTFREE« zusätzlichen freien Platz für künftige Updates reserviert. Der Defaultwert dafür sind zehn Prozent der Größe eines Blocks.
Den aktuellen Fragmentierungsgrad ermittelt »ANALYZE INDEX Indexname VALIDATE STRUCTURE;«. Dieses Kommando sammelt für die aktuelle Sitzung Informationen über den angegebenen Index und speichert sie in der Tabelle »INDEX_STATS«. Nach Ende der Sitzung werden diese Informationen gelöscht. Wer sie aufheben möchte, kopiert sie vorher in eine andere Tabelle. Die Resultate findet folgendes Select:
SELECT name, del_lf_rows, lf_rows,U del_lf_rows lf_rows_used,
TO_CHAR(del_lf_rows / (lf_rows)*100,
'999.99999') ratio
FROM index_stats
WHERE name = UPPER('Indexname');
Beträgt der Wert in der Spalte »DEL_LF_ROWS« mehr als 15 bis 20 Prozent des Werts in der »LF_ROWS_USED«-Spalte, ist ein Wiederaufbau des Index notwendig. Wenn eine größere Menge von Datensätzen aus einer Tabelle eines Produktionssystem zu löschen ist, dann empfiehlt es sich, zuerst den Index zu droppen, danach den Löschvorgang zu starten und anschließend den Index neu aufzubauen. Andernfalls würde nach jedem gelöschten Datensatz der Index aktualisiert.
|
Listing 2: Eine |
|---|
01 CREATE TABLE test_par (
02 name VARCHAR2(80),
03 alt NUMBER(3)
04 )
05 PARTITION BY RANGE(name)
06 (PARTITION part1 VALUES LESS THAN('M')
07 TABLESPACE ts0,
08 PARTITION part2 VALUES LESS THAN('Z')
09 TABLESPACE ts1)
10 ;
11 CREATE INDEX test_par_idx ON test_par(name) LOCAL
12 ( PARTITION part1
13 TABLESPACE ts0,
14 PARTITION part2
15 TABLESPACE ts1);
|
Oracle-Indizes sind immer durch Parameter beeinflussbar. Manche haben große Wirkung auf die Performance. Diese Parameter lassen sich nachträglich mit dem Kommando »ALTER INDEX Indexname REBUILD ONLINE;« ändern. Der Index bleibt dabei so lange erhalten, bis eine Kopie erstellt wurde. Das hat den Vorteil, dass der Benutzer die Basistabelle weiter abfragen oder updaten kann. Die Kopie kostet jedoch CPU-Ressourcen und ist nicht empfehlenswert, wenn man gleichzeitig Daten von zirka 20 bis 30 Prozent der gesamten Tabelle laden muss.
Aufbau beschleunigen
Die Index-Parameter mit Einfluss auf die Performance sind:
- »PARALLEL n« erlaubt parallele Zugriffe auf eine
Tabelle. Wenn ein Index erzeugt wird, scannt Oracle die betroffene
Tabelle komplett, um die ROWIDs aller Datensätze
zusammenzustellen. Der Parameter »n« soll dabei der
Anzahl der CPUs minus 1 entsprechen. Damit ergäbe sich zum
Beispiel für eine Maschine mit vier CPUs das folgende
»CREATE INDEX«-Statement:
CREATE INDEX index_name ON table_name(column_name) PARALLEL 3;
- »NOLOGGING« verhindert das Schreiben ins Redo-Log
und erhöht die Geschwindigkeit bis zu 30 Prozent. Fällt
allerdings der Server aus, während der Index erzeugt wird,
muss man den Prozess neu starten. Beispiel:
CREATE INDEX Indexname ON table_name(Columnname) PARALLEL 3 NOLOGGING;
Seit Oracle 8 und 8i lässt sich eine Tabelle in mehrere Zeilenblöcke aufteilen. Die kleineren Einheiten, die dabei entstehen, bezeichnet man als Partitionen der Tabelle. Auch der Index teilt sich dadurch entsprechend. Gerade bei großen Tabellen kann das sehr performant sein. Denn jetzt muss die Datenbank für eine Abfrage meist nicht die gesamte Tabelle, sondern nur die betreffende Partition durchsuchen.
Tunen durch teilen
Es gibt vier Methoden der Partitionierung: Die erste Möglichkeit ist die Bereichspartition. Hier dient eine Spalte der Tabelle als Partitionsschlüssel. Die Werte dieser Spalte werden in Bereiche geteilt und den einzelnen Partitionen zugeordnet. Listing 2 zeigt ein Beispiel. Dieser Partitionstyp ist dann sinnvoll, wenn der Wertebereich des Schlüssels stetig ist, die Daten logisch unterteilbar und etwa gleich verteilt sind (sodass auch die Partitionen ungefähr gleich groß werden).
Wenn es keinen für eine solche Range-Partition passenden Schlüssel gibt, bietet sich die Hash-Partitionierung als eine Alternative an. Bei ihr liegen die aufeinander folgenden Werte nicht unbedingt in derselben Partition. Stattdessen verteilt eine Hashfunktion die Tabellenzeilen gleichmäßig.
Die dritte, relativ neue »LIST«-Methode (seit Oracle 9i) gestattet es dem Administrator, genau zu kontrollieren, welche Daten in welcher Partition abgelegt werden. Diese Methode eignet sich für diskrete Schlüssel wie beispielsweise Produkt- oder Ländernamen.
Die List-Partitionierung benötigt unbedingt eine Default-Partition, die unbekannte Schlüssel (wie ein neues Produkt) aufnimmt. Beispiel:
CREATE TABLE test_par_laender(
...
laender VARCHAR2(100),
...)
PARTITION BY LIST (laender) (
PARTITION EU VALUES ('DEUTSCHLAND',
'FRANKREICH'),
PARTITION NAH_OST VALUES ('PALAESTINA',
'LIBANON'),
PARTITION FERN_OST VALUES ('JAPAN',
'CHINA'),
PARTITION andere VALUES (DEFAULT));
Sind die Datenmengen sehr groß, lassen sich schließlich mit der »COMPOSITE«-Methode Range-Partitionen in Subpartitionen unterteilen. Dabei wird jede Range-Partition noch einmal geteilt (mit Hilfe der Range- oder List-Methode.)
Oracle cachet SQL-Abfrage im so genannten Shared Pool. Bei jeder neuen Abfrage prüft es zuerst, ob ein identisches Select bereits im Cache vorhanden ist – in diesem Fall könnte sich die Datenbank das wiederholte Parsen (Hard Parse) sparen. Sie muss allerdings das neue Statement auch dann neu analysieren, wenn es sich nur in einem Teilausdruck von einem schon gemerkten unterscheidet.
Beispielsweise würden sehr viele Abfragen nach dem Muster »SELECT * FROM mitarbeiter WHERE name = “Name”«, die sich nur im Namen unterscheiden, jeweils separat abgearbeitet und gespeichert. Auf diese Weise wird der Cache natürlich wenig effizient genutzt und außerdem Platz verschwendet.
SQL mit Nachbrenner
Solche Probleme lassen sich wesentlich Ressourcen-sparender und performanter lösen, wenn die Abfrage eine Variable für den veränderlichen Teil verwendet (im Beispiel anstelle des Namens). Mit dieser Bind-SQL-Technik sähe das Select so aus: »SELECT * FROM mitarbeiter WHERE Name =:VAL;«. In dieser Form würde es gecachet und für alle Abfragen nach diesem Muster benutzt.
Wer diese Abfrage in SQLPlus ausführen möchte, sollte zuerst die Variable definieren und ihr anschließend einen Wert zuweisen:
VAR name VARCHAR2(20) Exec :name := 'Farwati' . SELECT * FROM mitarbeiter WHERE name = :name;
Einige Skriptsprachen haben Funktionen für die Oracle-Schnittstelle implementiert, über die man Bind-Variablen definieren kann. PHP zum Beispiel stellt die Funktion »OCIBindByName()« zur Verfügung[2]. Ein Beispiel:
<?
$db=OCIPLogin('userid', 'password','mydb');
$stmt = OCIParse($db, 'SELECT * FROM
mitarbeiter WHERE name = :name');
$name = 'Farwati';
OCIBindByName($stmt, ':name', $name, -1);
OCIExecute($stmt);
?>
In PL/SQL ist das Ganze sehr einfach, denn sie verwendet grundsätzlich nur Bind-Variablen. Beispiel:
CREATE OR REPLACE PROCEDURE
hole_mitarbeiter(p_name in VARCHAR2())
AS
BEGIN
SELECT * FROM mitarbeiter WHERE name = p_name;
END;
Das funktioniert, weil jede Referenz in PL/SQL bereits eine Bind-Variable ist. Selbst wenn literale Werte wie zum Beispiel in »SELECT * FROM mitarbeiter WHERE name = “Farwati”;« anstelle von Variablen in PL/SQL-Code zum Einsatz kommen, wird automatisch eine Bind-Variable benutzt.
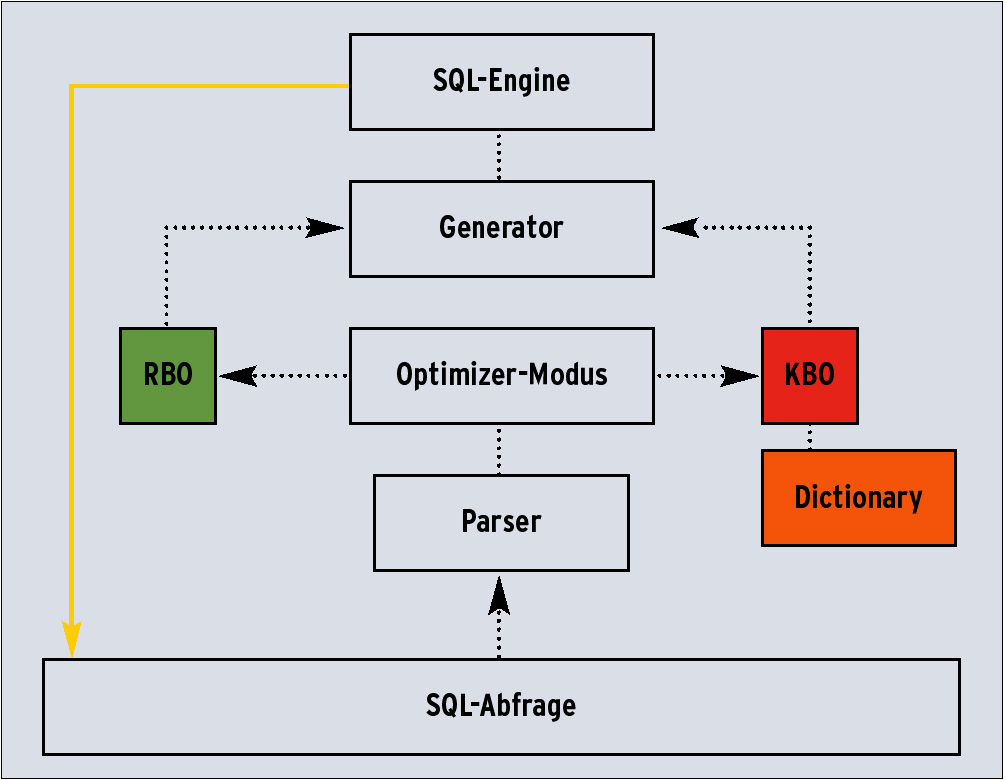
Abbildung 2: Jedes SQL-Statement wird geprüft, optimiert und geplant, bevor es am Ende der Verarbeitungskette ausführbar ist.
Kosten senken
Jedes SQL-Statement wird zuerst vom SQL-Parser analysiert, anschließend vom Optimizer bearbeitet, der einen Plan an den Generator weitergibt. Die SQL-Engine führt den Plan dann schließlich aus (siehe Abbildung 2). Dem Optimizer (bis Oracle 9i) stehen grundsätzlich zwei Methoden zur Verfügung: die regelbasierte RBO- und die kostenbasierte KBO-Methode.
Der regelbasierte Optimizer verwendet 15 vordefinierte Prioritätsregeln[3]. Die kostenbasierte Methode verfolgt dagegen keine festgeschriebenen Regeln, sondern ermittelt den bestmöglichen Zugriffspfad anhand von Statistiken, die der Anwender explizit erzeugen muss. Sind für eine Tabelle keine Statistiken vorhanden und hat der Optimizer daher keine gute Entscheidungsgrundlage, kann die Performance einer Abfrage sehr schlecht sein.
Statistisch gesichert
Ein Beispiel: Eine Tabelle »bestellungen« enthält eine indizierte Spalte »bearbeitet«, die nur zwei Werte annehmen kann: »erledigt« und »in_bearbeitung«. Die Tabelle speichert die Bestellungen eines Monats, sie hat über eine Million Zeilen. Die Bestellungen werden üblicherweise innerhalb weniger Stunden bearbeitet, deshalb gibt es durchschnittlich nicht mehr als 100 offene Bestellungen. Für eine Abfrage, die alle offenen Bestellungen finden soll, wird der KBO einen von zwei möglichen Ausführungspfaden wählen, je nachdem, ob eine Statistik zum Index der Spalte »bearbeitet« existiert oder nicht.
Der KBO weiß, dass es für diese Spalte nur zwei Werte gibt. Wenn er keine Statistik hat, nimmt er an, dass die Werte in etwa gleich verteilt sind, und benutzt daher den Index, obwohl in diesem Fall ein Full Table Scan viel schneller wäre. Kennt der KBO jedoch aufgrund einer zuvor berechneten Statistik die Werteverteilung (1:10000), ist ihm klar, dass der Index langsamer ist.
Welche Methode der Optimizer verwenden soll, kann der Anwender Oracle (bis 9i) in der Datei »init.ora« mitteilen: Oracle benutzt den RBO, wenn dort »OPTIMIZER_MODE = RULE« eingetragen ist. Steht die Variable jedoch auf dem Wert »CHOOSE«, hängt die Wahl der Methode von mehreren Faktoren ab: Gibt es keine Statistiken, verwendet Oracle den RBO, sind Statistiken vorhanden, benutzt Oracle den KBO.
Zudem kann der Admin auf Applikationsebene über Hints die Methode des Optimizers festlegen (etwa »SELECT /*+ RULE */ «….). Die Version 10g unerstützt den RBO nicht mehr, »OPTIMIZER_MODE« ist nicht mehr nötig. Applikationen, die eine regelbasierte Optimierung verwenden, sind umzuschreiben. E
Der KBO kannte bis vor Oracle 9i nur die Varianten »ALL_ROWS« und »FIRST_ROWS«-Optimierung. Bei »ALL_ROWS« versucht der Optimizer kostenbasiert, also mit minimalen Ressourcen, die beste Durchsatzrate für ein gesamtes SQL-Statement zu finden. Mit »FIRST_ROWS« verwendet er eine Mischung aus kostenbasierter und heuristischer Methode mit dem Ziel, die ersten paar Zeilen möglichst schnell zu ermitteln. Die heuristische Methode führt aber in manchen Fällen dazu, dass der Execution Plan wesentlich kostenintensiver wird.

Abbildung 3: Diese SQL-Anweisung kann durch die ungünstige Formulierung der Abfrage keinen Index verwenden und braucht daher relativ viel Zeit.
Schnellstart
Deshalb gibt es seit Oracle 9i die Anweisung »FIRST_ROWS_ n«, wobei » n« einen der Werte 1, 10, 100 oder 1000 annehmen kann. Dieser Parameter verwendet – ungeachtet der Statistiken – eine kostenbasierte Methode, die die Rückgabe der 1, 10, 100 oder 1000 ersten Zeilen optimiert.
|
Listing 3: Lange laufende |
|---|
01 SELECT sql_text , executions , 02 disk_reads / decode(executions, 0, 1, executions) / 300 "Antwort" 03 FROM v$sql 04 WHERE disk_reads / decode(executions,0,1,executions)/300 >15 05 AND executions > 0 06 ORDER BY hash_value, child_number; 07 08 SELECT sql_text , executions , 09 buffer_gets / decode(executions, 0, 1, executions) / 4000 "Antwort" 10 FROM v$sql 11 WHERE buffer_gets / decode(executions,0,1,executions) / 4000 >15 12 AND executions > 0 13 ORDER BY hash_value, child_number; |
Mit dem Kommando: »ANALYZE TABLE Tabellenname ESTIMATE/COMPUTE STATISTICS« stellt Oracle Statistiken über die Tabelle und alle ihre Indizes zusammen. Das Schlüsselwort »COMPUTE« in diesem Kommando bewirkt, dass die Datenbank alle Zeilen der Tabelle einbezieht. Ist eine Tabelle groß, kann die Analyse sehr lange dauern. Deshalb ist mit »ESTIMATE« bestimmbar, dass sie sich auf einen Teil der Tabelle beschränken soll.
Die Statistiken muss man regelmäßig berechnen. Insbesondere nach dem Aufbau eines neuen Index oder sobald sich das Datenvolumen oder die Struktur eines Objekts verändert hat. Das Package »DBMS_STATS« erstellt eine Sicherheitskopie der letzten Statistik. So stehen dem KBO zumindest noch alte Daten zur Verfügung, falls bei der Neuberechnung etwas schief laufen sollte. Das letzte Analysedatum für alle Tabellen eines Schemas findet das Kommando:
SQL> SELECT table_name, num_rows, SQL> last_analyzed FROM user_tables;
Abkürzungen
SQL ist eine sehr flexible Sprache, sodass unterschiedlich aufgebaute Statements zu gleichen Resultaten führen können. Allerdings variieren die Ausführungszeiten manchmal stark:
SELECT titel, autor, verlag FROM titel, verlage WHERE autor ='XXX' AND verlag ='YYY';
Diese simple Abfrage zwingt die Datenbank dazu, die Spalten selbst den richtigen Tabellen zuzuordnen. Verwendet der Admin jedoch explizit Aliases, spart das Zeit:
SELECT t.titel, t.autor, v.verlag FROM titel t, verlage v WHERE t.autor ='XXX' AND v.verlag ='YYY';
In Abbildung 3 wird auf beide Tabellen ein »TABLE ACCESS (FULL)« durchgeführt. Abbildung 4 zeigt das gleiche Resultat, aber als Ergebnis einer anderen Abfrage. Hier kann der Index »REGIONEN_REGION_ID_IDX« genutzt werden.
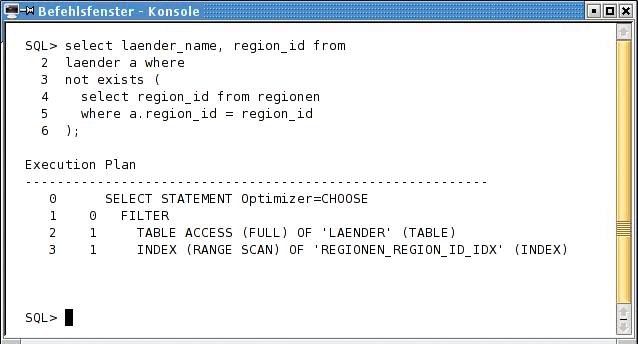
Abbildung 4: Dasselbe SQL-Select wie in Abbildung 3 kann – wie hier formuliert – den Index verwenden und gewinnt erheblich an Geschwindigkeit.
Erläuterte Pläne
Mit Hilfe des Kommandos »EXPLAIN PLAN« lässt sich der Anwender anzeigen, wie der SQL-Optimizer die Ausführung eines Selects plant. In SQLPlus steht der Parameter »AUTOTRACE« zur Verfügung, der solche Reports automatisch erzeugt: »SET AUTOTRACE« mit den Optionen »ON«, »OFF«, »TRACEONLY«. Mit »TRACEONLY« aktiviert der Admin die Herstellung des Reports, das Resultat und der Ausführungsplan werden aber nicht ausgegeben. Dafür muss er die Rolle »PLUSTRACE« anlegen und dem ausführenden User zuweisen.
Conn / as sysdba GRANT PLUSTRACE TO Username;
Anschließend erzeugt er die »PLAN«-Tabelle mit Hilfe des Skripts »utlxplan.sql«, das sich im Verzeichnis »/rdbms/admin« findet. Danach lässt sich der User Statistiken und Ausführungspfad für bestimmte Abfragen anzeigen.
»SET AUTOTRACE TRACEONLY STATISTICS« erzeugt Statistiken über zwei wichtige Aspekte der Performance: Disk Reads und Buffer Gets. Zeigen sich hier relativ hohe Kosten für das geplante Statement, ist eine Optimierung notwendig. Diese Werte hängen von vielen Parametern ab, einen allgemeinen Richtwert gibt es nicht. Relativ hoch wären die Kosten zum Beispiel, wenn ein Statement 1000 Zeilen zurückliefert und dafür 1000000 »consistent gets« und 10000 »physical reads« benötigt (siehe Abbildung 5).
Unter solchen Gesichtspunkten kann man verschiedene Varianten einer Abfrage untersuchen und sich für die optimale entscheiden. Listing 3 hilft dabei, schlechte SQL-Anweisungen, die mehr als 15 Sekunden dauern, zu identifizieren (im Beispiel für einen Server, der 300 Disk-I/Os und 4000 Buffer Gets in der Sekunden ausführen kann).

Abbildung 5: Statistik einer SQL-Anweisung.
Gute Verbindungen
Oracle startet auf einem Dedicated Server einen Prozess für jede User-Connection. Wenn zum Beispiel 30 Mitarbeiter eingeloggt sind, die die Datenbank pflegen, und 300 Webuser als Kunden gerade ihre Bestellungen über das Webfrontend der Datenbank tätigen, dann laufen 330 Oracle-Prozesse, wenn es sich um persistente Verbindungen handelt – ob sie gerade etwas zu tun haben oder nicht.
Das kostet Ressourcen. Oracle bietet daher eine Shared-Server-Lösung (Nachfolger des Multi-Threaded Servers), die die Anzahl der Prozesse viel niedriger hält und Verbindungen und Abfragen wie in einem großen Pool verwaltet. Das schont die Ressourcen vor allem bei OLTP-Systemen.
Speicher justieren
Als Faustregel gilt: Je größer die SGA (System Global Area), desto besser ist die Performance – aber unter der Voraussetzung, dass dabei auch für andere Prozesse genügend Platz im Arbeitsspeicher bleibt und die SGA nie geswappt werden muss.
Die SGA beherbergt auch den Shared Pool, einen Speicherbereich, den alle Oracle-User gemeinsam benutzten. Er besteht aus drei Teilen: dem Library Cache, der alle Abfragen für eine eventuelle Wiederverwertung zwischenlagert, dem Dictionary Cache sowie dem Large Pool, den der Shared Server, parallele Abfragen und der Recovery Manager nutzen. Durch eine optimale Dimensionierung dieser Speicherbereiche erreicht der Admin, dass häufig ausgeführte SQL-Statements im Library Cache bleiben, ohne darin allzu viel Speicherplatz zu belegen.
Abbildung 6: Der Enterprise-Manager der jüngsten Oracle-Version bietet bereits verschiedene Ressourcen-Monitore, in denen sich Performance-relevante Messgrößen ablesen lassen.
Hilfreich bei der Justierung ist die View »V. Die »PINS«-Spalte dieser Sicht gibt die Anzahl der Requests pro Namspace wieder. »PINHITS« sind Anfragen, die im Library Cache zu finden sind. Aus der »RELOADS«-Spalte kann man ablesen, wie oft ein aus dem Cache bereits entferntes SQL-Statement erneut geladen wurde. Bei einer optimalen Shared-Pool-Größe sollte die Anzahl der Reloads gegen null gehen.
Die »INVALIDATIONS«-Spalte zeigt, wie oft die Daten im Library Cache ungültig geworden sind und neu geparst werden mussten. Auch diese Größe sollte gegen null gehen:
SELECT namespace, pins, pinhits, reloads, invalidations FROM V$LIBRARYCACHE ORDER BY namespace;
|
Listing 4: Trefferquoten in den |
|---|
01 SET SERVEROUTPUT ON
02 SET LINESIZE 1000
03 SET FEEDBACK OFF
04 SELECT name, created, log_mode, open_mode
05 FROM v$database;
06 prompt
07 prompt ##################################
08 prompt
09 DECLARE
10 v_value NUMBER;
11 BEGIN
12
13 -- Dictionary Cache Hit Ratio
14
15 SELECT round(sum(getmisses) / (sum(gets)+0.00000000001) * 100,2)
16 INTO v_value
17 FROM v$rowcache;
18
19
20 DBMS_Output.Put('Dictionary Cache Hit Ratio: ' || v_value || ' % ');
21 IF v_value > 10 THEN
22 DBMS_Output.Put_Line('Vergroessern des SHARED_POOL_SIZE parameters
23 um eine Hit Ratio unter 10% zu erreichen');
24 ELSE
25 DBMS_Output.Put_Line('Wert ist OK.');
26 END IF;
27
28 -- Library Cache Hit Ratio
29
30 SELECT round(sum(RELOADS)/sum(pins) *100,2)
31 -- (1 -(Sum(reloads)/(Sum(pins) + Sum(reloads)))) * 100
32 --SELECT sum(pinhits) / sum(pins)
33 INTO v_value
34 FROM v$librarycache;
35
36
37 DBMS_Output.Put('Library Cache Hit Ratio: ' || v_value || ' % ');
38 IF v_value > 1 THEN
39 DBMS_Output.Put_Line('Vergroessern des SHARED_POOL_SIZE parameters
40 um eine Hit Ratio unter 1% zu erreichen');
41 ELSE
42 DBMS_Output.Put_Line('Wert ist OK.');
43 END IF;
44
45 -- Dispatcher Workload
46
47 SELECT (Sum(busy) / (Sum(busy) + Sum(idle))) * 100
48 INTO v_value
49 FROM v$dispatcher;
50
51
52 DBMS_Output.Put('Dispatcher Workload : ' || round(v_value) || ' % ');
53 IF v_value > 50 THEN
54 DBMS_Output.Put_Line('Erhoehung die Anzahl der MTS_DISPATCHER
55 bringt Performa');
56 ELSE
57 DBMS_Output.Put_Line('Wert ist OK.');
58 END IF;
59
60 END;
61 /
|
Pools perfektionieren
Als Resultat dieser Abfrage ergaben sich folgende Werte: 230 Reloads und zwei ungültige SQL-Statements. Das Verhältnis von »RELOADS« zu »PINS«, die so genannte »HIT RATIO«, ist eine gute Maßzahl für die Performance des Library Cache. Die Reloads sollten nicht mehr als ein Prozent der »PINS« ausmachen. Listing 4 zeigt ein Skript, das die Trefferquote einer Instanz im Dictionary Cache, Library Cache und Dispatcher Workload untersucht.
Eine andere Schlüsselzahl ist der freie Speicherplatz im Shared Pool bei Spitzenbelastungen. »V kann diesen Wert abfragen. Optimal ist es, wenn so wenig wie möglich Speicher frei bleibt und es dennoch nicht zu Reloads kommt. Das passende Select ist:
SELECT * FROM V$SGASTAT WHERE name = 'free memory' AND pool ='shared pool';
Large Pool
Mit dem Parameter »SHARED_POOL_SIZE« in »init.ora« wird die Größe dieses Pools (in Bytes) kontrolliert. Den Wert sollte man jedoch erst nach genügend langer Beobachtung ändern.
Parallele Abfragen, Recovery Manager (RMAN) und Shared Server verwenden den Large Pool. Wer einen der Dienste einsetzt, muss den entsprechenden Pool konfigurieren. Er ist über den Parameter »LARGE_POOL_SIZE« in »init .ora« einstellbar. Die Formel für die Berechnung seiner Größe lautet: UGA * Anzahl der User = Large Pool
Benutzer-Memory
Die UGA (User Global Area) selbst berechnet sich aus dem Memory-Bedarf der Sessions und dem des Cursors. Die Berechnung erfolgt über folgende Abfrage :
SELECT SUM(value) groesse , name From V$SESSTAT, V$STATNAME WHERE NAME LIKE 'session uga memory%' AND V$SESSTAT.statistic# = V$STATNAME.statistic# group by name;
Der richtige Wert für den Parameter »LARGE_POOL_SIZE« ermittelt sich aus dem Durchschnitt aus »session uga memory« für alle Sessions und »session uga memory max« für alle Sessions während einer Spitzenbelastung.
Fazit
Die Geschwindigkeit eines Datenbankservers hängt sicherlich von der Leistungsfähigkeit der CPU, des Plattensystems und der Netzwerkverbindungen ab. Darüber hinaus aber beeinflussen auch viele weiche Faktoren die Datenbank-Performance.
Neben einer optimalen Dimensionierung des SGA lässt sich die Geschwindigkeit vor allem durch die Auswahl eines maßgeschneiderten Index steigern. Optimierte SQL-Statements versprechen auch messbaren Performancegewinn. Aktuelle Statistiken unterstützen den Optimizer bei der Wahl eines schnellen Ausführungspfads. Zudem entscheidet das Management der User-Connections über den effektiven Einsatz der Ressourcen. (jcb)
|
Infos |
|---|
|
[1] Produkt-Dokumentation: Database Performance Tuning Guide and Reference Release 2 (9.2), October 2002 [2] Referenz der Funktion Ocibindbyname: [http://at.php.net/manual/en/function.ocibindbyname.php] [3] Rule Based Optimizer: [http://download-west.oracle.com/docs/cd/B10501_01/server.920/a96533/rbo.htm#39350] [4] Managing Oracle Processes: [http://www.cs.umb.edu/cs634/ora9idocs/server.920/a96521/manproc.htm] [5] B. Farwati, “Volltextsuche mit Oracle”: Linux-Magazin 10/04, S. 70 |
|
Der Autor |
|---|
|
Mag. Badran Farwati arbeitet als Datenbankadministrator und -Programmierer an der Österreichischen Nationalbibliothek. |





