
© Supattra Suparit / 123RF.com
Die Kombination vieler Technologien macht Linux-Systeme immer komplexer. Kein Problem, versprechen die großen Hersteller: Wir bieten ja auch Support. In der Praxis verzweifeln viele Admins allerdings an Wissenslücken der Supporter, Salamitaktik und zum Teil absurden Ausschlussgründen.
Selbst die treuesten Befürworter althergebrachter Wege und Methoden können sich dem Trend zu Virtualisierung und zur Cloud heute kaum noch entziehen. Sogar, wer sich nicht bei einem der großen Anbieter einmietet, bekommt die Auswüchse von Cloud first und Container first zu spüren: Dienste in Containern statt auf dem blanken Blech auszurollen, gilt inzwischen fast schon als Standardprozedur. Weil dieser Weg nicht zuletzt erhebliche Einsparungen an Aufwand und Personal bei den großen Herstellern ermöglicht, drücken die ihre Nutzer massiv in diese Richtung.
Von Red Hat Enterprise Linux (RHEL [1]) gibt es längst eine Mini-Version, die im Wesentlichen nur noch Container abspielen kann. Suse entwickelt sich mit seiner Adaptable Linux Platform (ALP [2]) in dieselbe Richtung. Canonical geht mit seinem auf Snap basierenden Modell zwar einen Sonderweg, verfolgt letztlich aber exakt dasselbe Ziel. Für Administratoren bringt das nicht nur Vorteile, denn es gilt, die Container-Schicht zwischen Admin und eigentlicher Anwendung etwa beim Debugging oder bei der Konzeption ganzer Umgebungen gesondert zu beachten. Docker und Podman, zwei Laufzeitumgebungen für Container unter Linux, sind schließlich eigene Technologien, die auch separat kaputtgehen können und dadurch Schwierigkeiten an ganz anderer Stelle verursachen.
Das sei jedoch gar kein Problem, beschwichtigen die Hersteller gleich. Wer bei den großen Anbietern eine Subskription erwirbt, bekommt schließlich immer Support dazu, hat also den Hersteller im Rücken. Und damit weiß der Admin auch, an wen er sich wenden kann, falls etwas schiefläuft – zumindest lautet so das Versprechen, mit dem Red Hat, Suse, Canonical & Co. künftige Kunden für sich begeistern wollen. In der Praxis bleibt von den hehren Support-Versprechungen allerdings oft nicht viel mehr übrig als heiße Luft.
Dieser Artikel geht den Ursachen dafür auf den Grund und zeigt anhand mehrerer Beispiele, warum Administratoren oft genug eben doch davon ausgehen müssen, auf sich allein gestellt zu sein. Er zeigt zum einen, mit welchen Tricks die großen Anbieter arbeiten, um den Umfang ihres Supports bereits im Vorfeld so gut wie möglich zu begrenzen. Zum anderen beleuchtet er, was Kunden tun können, wenn sie doch mal in der Patsche sitzen und der Anbieter ihrer Wahl entweder nicht weiß, was zu tun ist oder mit Hinhaltetaktiken arbeitet. Das Gros der beschriebenen Ereignisse fußt dabei auf der eigenen Erfahrung des Autors.
Früher war es leichter
Wer sich mit den Support-Praktiken der großen Anbieter beschäftigt und sich die Frage stellt, wieso diese zumindest dem subjektiven Eindruck nach immer schlechter werden, tut gut daran, sich detailliert mit der gestiegenen Komplexität der Setups in den vergangenen Jahren zu befassen (Abbildung 1).
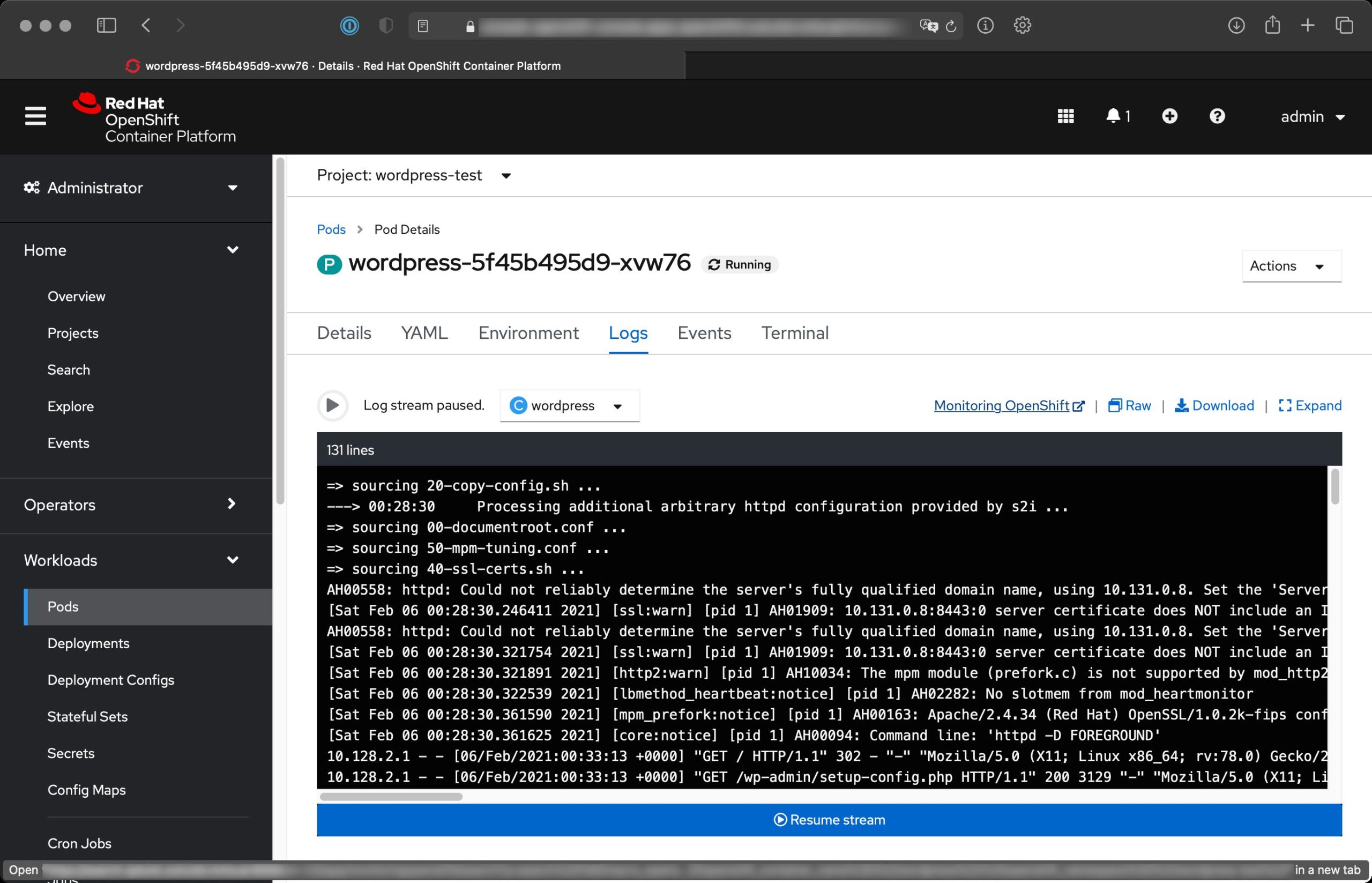
Abbildung 1: Kubernetes (hier auf Basis von Red Hat OpenShift) fügt einem Setup mehrere Layer an Komplexität hinzu, die kommerziellen Support erheblich komplizierter machen.
Eingangs ist es ja schon angeklungen: Die verteilten Systeme heute fallen viel komplexer aus als ein klassisches Linux-System mit einem monolithischen Dienst früher. Ein kurzer Vergleich macht das am Beispiel einer klassischen Webanwendung schnell deutlich. Vor zehn Jahren hätte man die im Regelfall wohl noch mit PHP gebaut, zum Einsatz wäre also der klassische LAMP-Stack gekommen, bestehend aus Linux selbst, Apache, MySQL und PHP. Zwar sind alle vier beteiligten Komponenten in sich komplex, doch weil sie schon so lange etabliert sind, haben sich über die Jahre robuste Best Practices etabliert. Die meisten Fehler im Hinblick auf die Nutzung der Dienste oder ihre Konfiguration hat das Gros der Admins schon mal gemacht oder über Bande mitbekommen. Obendrein sind Setups dieser (alten) Art nicht sonderlich dynamisch.
Das Netzwerk war im Normalfall ein klassisches Layer-2-Netz ohne viel Schnickschnack, Overlay-Technologien wie VXLAN und die damit assoziierten Netzwerktechniken wie Ethernet-VPN (EVPN) spielten keine Rolle. Auch Offloading war seinerzeit ein eher untergeordnetes Thema. Man achtete beim Kauf eines Servers darauf, dass der eine Netzwerkkarte mit hinreichend leistungsfähigem Prozessor für die vorgesehenen Aufgaben mitbrachte, und verließ sich darauf.
Heute stellen selbst Komponenten wie Load Balancer Admins nicht mehr vor größere Herausforderungen. Ganz gleich, ob der Load Balancer mit HA-Proxy auf einem Linux-System implementiert ist oder als fertige Appliance mit eigenem Support des Anbieters daherkommt: Ein verteiltes Webserver-Setup lockt heute keinen arrivierten Administrator mehr aus der Reserve. Ähnliches gilt für das Thema Speicher. Wer zentralen Speicher haben wollte, griff entweder zur NAS- oder SAN-Appliance eines etablierten Herstellers oder baute auf Grundlage von Tools wie DRBD eine eigene, passgenaue Lösung.
All diese technischen Details haben gemein, dass sie von vorneherein so konzipiert waren, dass das Setup im Laufe seines Lebens nicht mehr nennenswert wächst. Wer einen Load Balancer mit Webservern nutzte, musste höchstens damit rechnen, ein paar Anwendungsserver zusätzlich zum ursprünglichen Setup installieren zu müssen. Nahtloses Skalieren in die Breite war aber keine Anforderung. Wer skalieren musste, skalierte eher noch in die Höhe und stattete das bereits vorhandene SAN mit mehr Festplatten aus oder zog die interne Datenbank auf einen Server mit leistungsfähigerer CPU um.
Weil auch für diese Aufgaben etablierte Prozesse existieren und brauchbare Werkzeuge nur auf ihre Verwendung warteten, entstanden im Alltag nicht sonderlich viele Anlässe, den Support des Anbieters in Anspruch zu nehmen. Support war für viele Admins lange gleichbedeutend damit, vom Hersteller zuverlässig über einen definierten Zeitraum hinweg Updates und Korrekturen für Sicherheitsprobleme zu erhalten.
Überbordende Komplexität
Vergleicht man ein skalierbares Setup der Gegenwart mit dieser vermeintlich heilen Welt, wirkt das, als träten Steinzeit und Moderne mit ihren jeweiligen Werkzeugen gegeneinander an. Ein zentraler Aspekt des Cloud Computings ist ja gerade die Tatsache, dass sich Setups im kleinen Maßstab planen und danach beliebig in die Breite skalieren lassen. Nur so lässt sich das Versprechen der Hyperscaler überhaupt verkaufen. Die Kostenreduktion, die AWS, Azure und Google gern für sich reklamieren, fußen ja vorrangig auf dem On-Demand-Prinzip der jeweiligen Plattformen. Genutzt werden nur die Ressourcen, die zum jeweiligen Zeitpunkt tatsächlich nötig sind, um einen stabilen Betrieb zu gewährleisten. Was an Diensten überflüssig ist, erhält die Cloud zurück, und der Anwender muss nicht länger dafür bezahlen.
In der Theorie hätten die alte Welt und die neue Welt problemlos nebeneinander existieren können, aber so funktioniert die Branche eben nicht: Bald schickten sich Suse, Red Hat & Co. an, Admins auch für lokale Systeme in Rechenzentren etwa die Vorteile der Container-Virtualisierung schmackhaft zu machen. Die finden die Anbieter deshalb toll, weil sie das Handling von Anwendungen erleichtert und damit die Pflege von Paketen eines Diensts in verschiedenen Versionen für verschiedene Distributionen überflüssig macht.
Davon soll auch der Administrator profitieren, so das Versprechen: Das Update einer MySQL-Datenbank etwa ließe sich mit Containern einfach dadurch abwickeln, dass man die laufende Datenbank anhält, den zu ihr gehörenden Container austauscht, dem neuen Container dasselbe Volume mit den Daten unterschiebt und diesen startet. Was an Migrationsarbeit zu leisten ist, muss die Anwendung selbst erledigen. Für den Administrator ergibt sich nur eine kurze Downtime, wenn überhaupt.
In der Praxis bedeutet alleine der großflächige Ersatz von Paketen durch Container aber eben auch, dass der Admin mehrere Schichten zusätzlicher Komplexität beherrschen muss: Namespaces, Cgroups, die genutzte Laufzeitumgebung für Container, ein Mini-SDN, das Podman & Co. nutzen, um Ports aus per Namespace abgetrennten Containern mit der Außenwelt zu verbinden und so weiter. Hinzu kommt eine Verwaltung von Storage-Volumes, die im Regelfall an einen skalierbaren Speicher andockt (Abbildung 2).
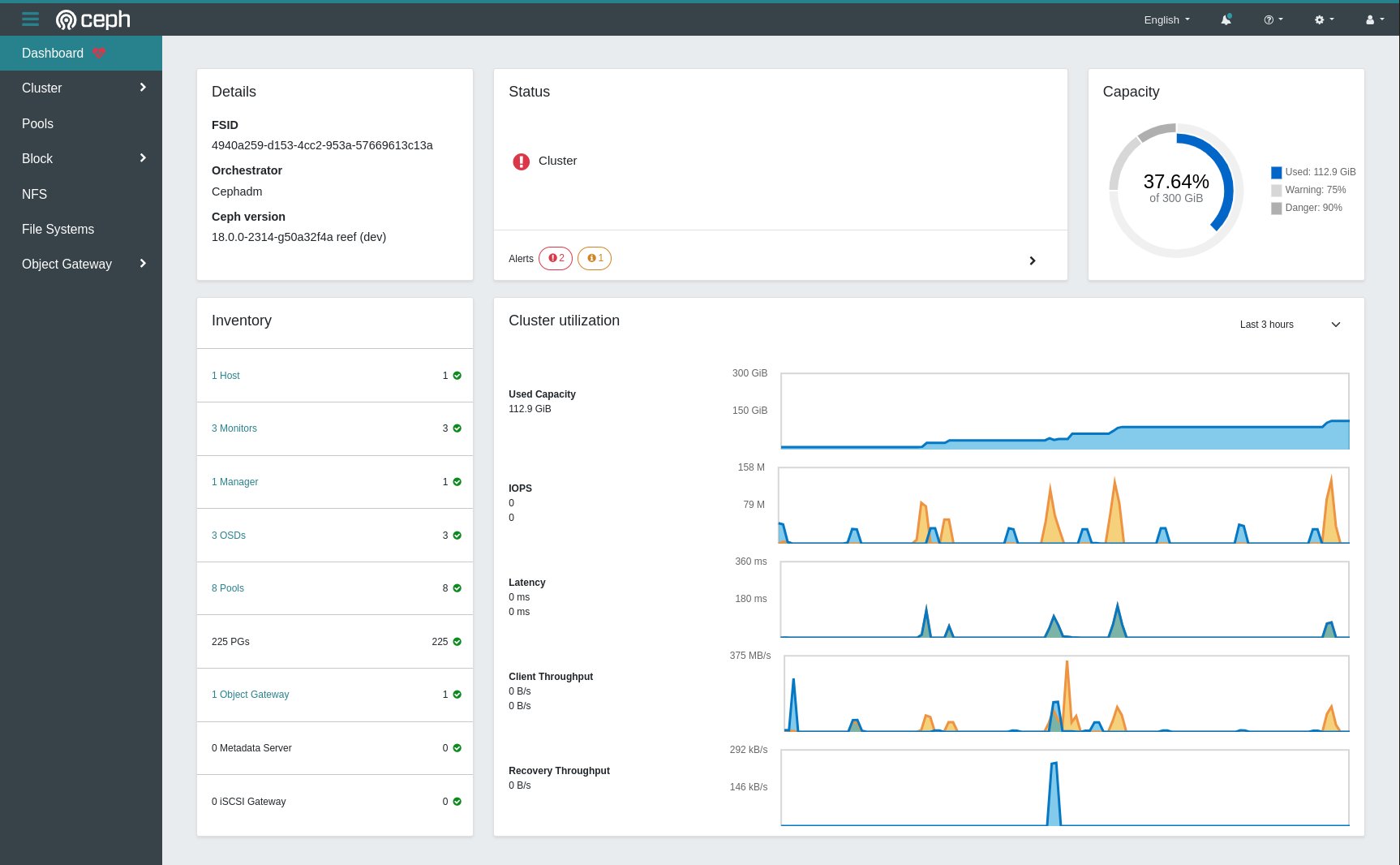
Abbildung 2: Auch verteilter Speicher wie hier auf Grundlage von Ceph führt dazu, dass ein Setup deutlich schwieriger zu debuggen und zu unterstützen ist. Quelle: Ceph / Red Hat
Wer es – auch lokal – ernst mit Containern meint, ergänzt sie um einen Orchestrierer, typischerweise Kubernetes. Dann aber kommen im Regelfall auch dynamische Verbindungslösungen wie Istio ins Boot, die ihrerseits mit einer SDN-Lösung der Container-Umgebung verzahnt sein müssen, um zu funktionieren (Abbildung 3). Wer das letzte Quäntchen Speed aus seiner Umgebung herausholen will, braucht obendrein Offloading jener Komponenten, die in verteilten Umgebungen nötig sind und die es vorher noch nicht gab.
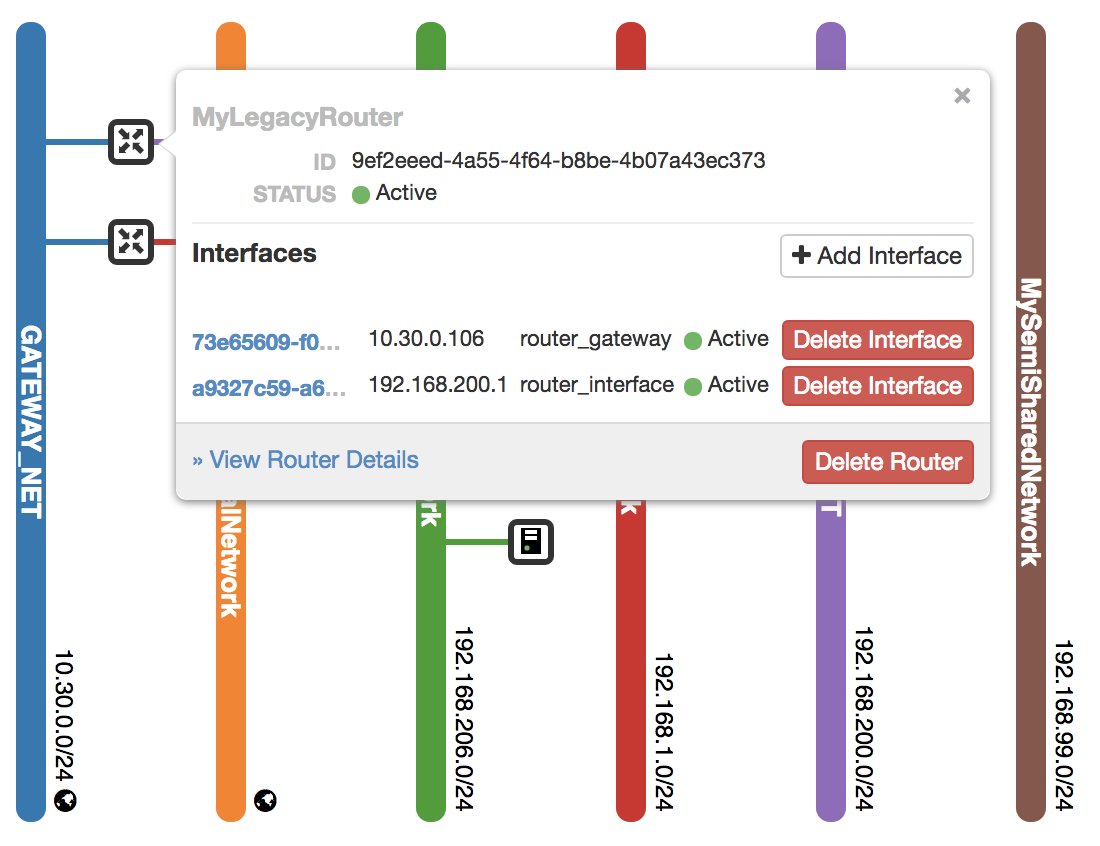
Abbildung 3: OpenStack bietet eine private Cloud-Umgebung, hat neben Software Defined Storage aber auch Software Defined Networking mit an Bord – eine Lösung, für die guter Hersteller-Support überlebensnotwendig ist. Im Alltag erleben Admins hier oft große Enttäuschungen.
VXLAN [3] etwa ist eine Verkapselungsmethode für SDN-Umgebungen, die ähnlich wie VLAN arbeitet und sich um die Separierung von Traffic beispielsweise in Kubernetes kümmert. Die Performance-Einbußen, die VXLAN mit sich bringt, federn Hersteller wie Nvidia dadurch ab, dass sie ihre Netzwerk-Chips VXLAN-fähig machen (Abbildung 4). Damit Container oder VMs das dann nutzen können, brauchen sie aber eine entsprechend komplexe Treiberkonfiguration mit allen Schikanen. Wer eigentlich nur eine Webumgebung mit einer Datenbank im Hintergrund starten möchte, fühlt sich bei so vielen Komponenten bald überfordert.

Abbildung 4: ConnectX-6-Karten von Nvidia (ehemals Mellanox) heißen “SmartNIC”, weil sie diverse Offloading-Features beherrscht. Die dafür oft nötige Software ist von Standard-Support-Verträgen für Linux oft aber gar nicht abgedeckt, sodass es zum Support-Ausschluss kommt. Quelle: Nvidia
Achselzucken
Fest steht, dass es selbst einem passionierten Administrator kaum möglich ist, beim Umstieg von einer konventionellen auf eine skalierbare Umgebung alle Details im ersten Versuch richtig umzusetzen. Gerade an dieser Stelle wäre es umso wichtiger, dass die Hersteller mit ihren Support-Angeboten zuverlässig zur Verfügung stehen. Dumm nur, dass der Layer-Kuchen, den die Support-Abteilungen der etablierten Hersteller ihren Kunden kredenzen, offenbar so komplex ausfällt, dass sie selbst kaum noch hinterherkommen. Genau das wird bei immer mehr Gelegenheiten deutlich.
Wohlgemerkt: Es steht erst einmal nicht in Abrede, dass die Support-Abteilungen der Anbieter ihren Kunden wirklich und ehrlich helfen möchten. Die Probleme gehen aber schon los, wenn der Support in Erfahrung zu bringen versucht, was genau beim Kunden nicht stimmt. Wer etwa schon einmal versucht hat, ein OpenStack-Setup aus der Ferne zu debuggen, kennt das Problem: Hier greifen so viele verschiedene Dienste auf verschiedenen Systemen ineinander, dass eine Fehlermeldung von Dienst A auf System 1 auch durch eine Fehlfunktion einer anderen Instanz desselben Dienstes auf System 14 bedingt sein kann. In den allermeisten Fällen hat der Hersteller selbst aber auf die betroffenen Systeme gar keinen Zugriff, und üblicherweise will er ihn auch gar nicht.
Das führt beim Debugging von Problemen zu einem bizarren Schauspiel: Praktisch immer fordern die Support-Abteilungen der Anbieter heute nämlich zuerst Log-Dateien en masse an, um das Problem genauer zu durchleuchten. Das gilt ganz unabhängig davon, wie detailliert man dem Support das aufgetretene Problem beschreibt und wie viel Vorarbeit beim Untersuchen bereits geleistet wurde. Schritt 1 besteht stets darin, dem Anbieter Log-Dateien zu schicken, deren Umfang bisweilen mehrere 100 Megabyte beträgt – und zwar pro betroffenem Server.
Damit der Hilfesuchende nicht die falschen Logs einsammelt, stellen die Anbieter eigene Werkzeuge dafür zur Verfügung, die ihrerseits oft ein Problem darstellen. Red Hat etwa musste »sosreport« vor ein paar Monaten offiziell aktualisieren, weil es etwas zu neugierig auf den Zielsystemen unterwegs war. Mittlerweile hat der Anbieter das Werkzeug gleich durch ein neues ersetzt, das absehbar allerdings mit ähnlichen Problemen zu tun haben könnte: Die Aufgabe, von einem System in einem komplexen, verteilten Setup alle nötigen Daten einzusammeln und dabei keine zentralen Dateien wie etwa die privaten Schlüssel von SSL-CAs mitzunehmen, ist alles andere als trivial.
Wer sich als Administrator allerdings den Schweiß von der Stirn wischt, nachdem er ein paar Gigabyte an Log-Dateien in das Support-System eines Herstellers geladen hat, und nun erwartet, zügig Hilfe zu bekommen, den erwartet eine Enttäuschung. Damit die großen Anbieter ein Problem überhaupt als kritisch betrachten, muss es bestimmte Kriterien erfüllen.
So gilt es beispielsweise als kritisch, wenn ein Fehler die produktive Umgebung eines Kunden außer Gefecht sitzt. Funktionieren hingegen nur einzelne Features nicht, reiht einen der Support in Sachen Dringlichkeit üblicherweise bei “normal” oder sogar “low” ein, ganz gleich, wie lästig die jeweilige Fehlfunktion vor Ort auch sein mag. Dann heißt es warten, bis sich beim Hersteller jemand durch die Log-Dateien gewühlt hat und vielleicht eine Lösung anbietet.
Viel häufiger kommt es aber vor, dass der Anbieter entweder noch mehr Dateien anfordert oder sein Wissen für erschöpft erklärt und die Angelegenheit zum Second Level durchreicht. Nicht selten beginnt das gesamte Schauspiel dort von vorn. Bei diversen Gelegenheiten jedenfalls drängte sich dem Autor der Eindruck auf, der Second Level habe die bereits gesammelten Dateien des First Levels keines Blickes gewürdigt.
Gelöst wird das Problem dann oft eine ganze Weile später im Rahmen eines echten Kraftakts – dann nämlich, wenn der Anbieter irgendwo intern eine kundige Person ausgemacht hat, die in einem Telefonat mit dem ausführenden Admin und per Remote-Desktop-Software direkt auf die Systeme zugreift und die Situation analysiert. Das sind dann aber regelmäßig gar nicht Leute, die der Support-Organisation des jeweiligen Herstellers angehören, sondern höhere höheren Chargen aus Training und Consulting. Offensichtlich ist die implizite Komplexität eines modernen Linux-Systems mit allen Komponenten in einer skalierbaren Umgebung so hoch, dass dies die Erfahrung und das Wissen von klassischen 1st- und 2nd-Level-Abteilungen überfordert.
Bsa hierher
Goldene Himbeere
Dabei ist die Aussicht, ein vorhandenes Problem letztlich im Gespräch mit einem Consultant oder Trainer zu lösen, auch nur ein Ausgang von mehreren möglichen. Ebenso oft nutzt der Anbieter die eingesandten Log-Dateien nämlich der Erfahrung nach, um erst einmal Gründe dafür zu finden, dass das jeweilige Setup sowieso in dieser Form gar nicht den Support-Vorgaben entspricht und Support deshalb unmöglich ist.
Die Gründe dafür können vielfältig sein: Praktisch alle großen Anbieter passen zum Beispiel in Sachen Support, sobald ein Kunde Treiber in den Kernel lädt, die nicht zur jeweiligen Distribution gehören. Genau das ist in vielen verteilten Umgebungen aber häufig nötig, weil Funktionen wie das zuvor beschriebene Offloading sonst nicht zur Verfügung stehen. Ein Offloading setzt das Data Plane Development Kit (DPDK) und andere Kernel-Techniken voraus. Die aber versuchen die Supporter so weit wie möglich zu umgehen – auch, weil die Hersteller der entsprechenden Hardware oft nicht bereit sind, viel Geld für Rahmenabkommen mit den jeweiligen Linux-Distributoren zu zahlen. Hier muss aus Sicht des Administrators schon im Vorfeld eine sehr gründliche Recherche erfolgen, um ein Gespann aus Linux-Distribution und Hardware mit offiziellem Support zu finden. Im Zweifelsfall steht man sonst nämlich im Regen und bekommt Hilfe weder vom Linux-Anbieter noch vom Hardwarehersteller, und das selbst dann, wenn man laufende Support-Verträge mit beiden Lieferanten hat.
Freilich spielt hier Geld eine große Rolle. Eine neue Variante des Spiels läuft darauf hinaus, dass die Anbieter zwar auch Setups unter ihre Fittiche nehmen, die den sehr eng gefassten Standardregeln nicht entsprechen. Dann wittern die Sales-Abteilungen aber Morgenluft: Bei solch komplexen Setups, heißt es dann oft, sei mindestens eine Art Kundenbetreuer beim Anbieter nötig (manchmal Technical Account Manager oder ähnlich genannt), der das Setup des jeweiligen Kunden kennt und für diesen intern eine Art Lobbying betreibt.
Die Versprechungen lesen sich rosig: Tickets etwa würden unter der Obhut eines solchen Managers deutlich schneller bearbeitet, Lösungen für Probleme seien schneller zu erreichen. Praktisch heißt das aber eben auch, dass pro Jahr ein pauschaler Betrag in Höhe von 100 000 Euro und mehr an den Anbieter zu überweisen ist – wohlgemerkt zusätzlich zu den Beträgen, die für den Support ohnehin schon anfallen. Und das, obwohl ein solcher Manager bei den Anbietern nur sehr selten tatsächlich einem Kunden exklusiv zur Verfügung steht. Diverse Erfahrungsberichte im Netz legen obendrein nahe, dass die tatsächlichen Einflussmöglichkeiten der Technical Account Manager innerhalb der Unternehmen eher begrenzt sind – außer Spesen wenig gewesen also.
Stöbert man in den einschlägigen Foren im Netz wie Reddit oder Stack Overflow, merkt man schnell, dass nur wenige Admins mit dem Support ihres jeweiligen Anbieters wirklich zufrieden sind. Das Ganze ist mit Vorsicht zu genießen, denn wie bei jeder Art der Bewertung neigen vorrangig die unzufriedenen Kunden dazu, sich online über ihren Dienstleister auszulassen. Ein Muster lässt sich aber dennoch erkennen, und bei dem kommt praktisch kein Anbieter gut weg (Abbildung 5).
Abbildung 5: Wenn der Kernel stirbt, steigen beim Admin der Blutdruck und der Wunsch nach schneller Hilfe durch den ja bereits bezahlten Dienstleister. Die aber bleibt in immer mehr Fällen aus oder kommt nur schleppend daher.
Horrorgeschichten über unzureichenden, langsamen oder schlicht inkompetenten Support finden sich von praktisch jedem auch nur irgendwie bedeutsamen Anbieter für Linux-Distributionen ebenso wie von praktisch jedem relevanten Hardwarehersteller. Das Fass Hardware kann der Artikel an dieser Stelle dabei gar nicht richtig öffnen: Was an Geschichten über Dell, HP & Co. kursiert, obwohl die Kunden ihre Hardware mit zum Teil exorbitant teuren Enterprise-Support-Verträgen kaufen, würde den Rahmen bei Weitem sprengen.
Zur Hilfe
Aus Sicht des Administrators ist eine mehrgleisige Strategie nötig, um sich vor Ungemach in Sachen Support so weit wie möglich zu schützen. Eine zentrale Rolle spielt schon das Setup eines Systems. Hier tun Admins gut daran, die Anzahl der involvierten Komponenten auf ein Minimum zu reduzieren. Ist Kubernetes wirklich nötig, oder reicht möglicherweise auch Nomad als Orchestrierungslösung im kleinen Maßstab? Muss innerhalb der Container-Umgebung wirklich Istio ran, oder ist die genutzte Anwendung nicht eigentlich viel zu simpel gestrickt, um ein komplettes Service-Mesh zu rechtfertigen?
Weniger ist mehr, gilt an dieser Stelle, und entgegen der Slogans aus den Hochglanzprospekten der Anbieter ist ein möglichst vielschichtiger Kuchen aus Hard- und Softwareebenen kein erstrebenswerter Selbstzweck. Wer sein Setup auch in der Gegenwart so einfach wie möglich konzipiert und den Versuchungen der hippen Cloud-Welt möglichst widersteht, umgeht von vornherein viel Ärger. Das gilt auch für Soft- und Hardware im Gespann. Wer VXLAN nicht braucht, muss sich über dessen Offloading auch keine Gedanken machen und kann Treiber benutzen, die jeder zeitgenössischen Linux-Distribution beiliegen.
Alle klugen Ratschläge helfen im Nachhinein aber freilich nicht mehr, wenn der Administrator es bereits mit einem handfesten Problem zu tun hat und im Dickicht des Anbieter-Supports festhängt. Auch hier hat sich eine Strategie bewährt, die auf mehreren Pfeilern ruht.
Je nach eingesetzter Software schadet es nicht, nicht nur den jeweiligen Hersteller-Support in der Hinterhand zu haben, sondern auch einen externen (und damit neutralen) Dienstleister, der die Materie möglicherweise besser kennt als man selbst. Hier greifen gleich mehrere Vorteile. So sind die Kommunikationswege kurz, weil ein kleinerer Dienstleister im Normalfall keine fünf verschiedenen Support-Systeme zwischen sich und seine Kunden schaltet. Oft kennen Dienstleister und Kunde sich persönlich, weil sie schon länger kooperieren. Auf jeden Fall kann man sich einen externen Dienstleister spezifisch nach einem bestimmten Themengebiet aussuchen, statt darauf zu vertrauen, dass der jeweilige Linux-Anbieter intern die passende Person für ein vorliegendes Problem auftreibt.
Fazit
Sonderlich erfreulich stellt sich die Performance der Support-Abteilungen der großen Anbieter 2024 nicht dar. Zu oft gelangt man zu dem Eindruck, die Hersteller seien selbst nicht mehr in der Lage, das von ihnen konzipierte Dickicht aus multiplen Lösungen und Layern zu durchblicken.
Darauf reagieren sie aber nicht etwa, indem sie zusätzliche Support-Kapazitäten aufbauen. Stattdessen steht vielerorts erkennbar der Ansatz im Fokus, durch möglichst umfassende Ausschlüsse schon im Vorfeld ein Setup für nicht unterstützt zu erklären. Dann lassen sich im nächsten Schritt horrende Zusatzgebühren für Support Exceptions kassieren, also formale Unterstützung für Setups, die nicht den vom Anbieter selbst definierten Regeln entsprechen. Gerade bei größeren Anbietern ist zudem der starke Drang erkennbar, gleich ganze Support-Zusatzpakete etwa in Form des erwähnten eigens abgestellten Managers zu verkaufen, die ordentlich Geld in die Kasse des Distributors spülen. Auf Kundenseite führt das meist aber nicht zur erhofften Wunschlos-glücklich-Erfahrung in Sachen Enterprise-Unterstützung.
Die Anbieter arbeiten indes daran, sich noch mehr Support-Aufwand vom Hals zu schaffen: Die eingangs erwähnte Tendenz, aus der eigenen Enterprise-Distribution vorrangig einen Container-Abspieler zu machen, ist nur der erste Schritt. Es lässt sich absehen, dass die größeren Anbieter heute noch als zentral geltende Komponenten wie MySQL oder Nginx in absehbarer Zeit gar nicht mehr unterstützen. Wenn nur noch Container zum Einsatz kommen, ist das technisch ja einigermaßen simpel umzusetzen: Wer MySQL-Support will, muss dann halt den offiziellen Container von Oracle nutzen und sich dort separat mit Support versorgen. Auch das Alles-aus-einer-Hand-Argument, mit dem die Linux-Anbieter noch werben, wäre dann Geschichte. Für den geplagten Admin, der eigentlich nur einen Dienst unterstützt betreiben möchte, wäre die Welt damit ein weiteres, gehöriges Stück komplizierter geworden.
Freilich: Über ihr Support-Geschäft generieren die großen Anbieter einen großen Teil ihrer Umsätze. Unbestritten ist es völlig legitim, Geld dafür zu verlangen, dass man im Zweifelsfall die Instanz ist, auf die andere mit dem Finger zeigen und von der sie gleichzeitig die Lösung für ein Problem fordern können. Anspruch und Wirklichkeit in Sachen Linux-Support stehen aber oft in einem krassen Missverhältnis. Die Aussichten, dass sich das wieder ändert, erscheinen nicht gerade rosig. Die großen Anbieter sind längst nur noch Mosaiksteinchen in riesigen Corporate-Konstrukten, die auf Kosteneffizienz und Rendite getunt werden, nicht unbedingt aber auf eine befriedigende Endkundenerfahrung.





