
© teteraandrey / 123RF.com
Die großen LLM-basierten KI-Lösungen aus den USA machen haarsträubende Fehler. In Umgebungen, die besonderen Compliance-Regeln unterliegen, dürfen sie teils gar nicht zum Einsatz kommen. Aber was sind die Alternativen, und welche Rolle spielt Open Source dabei?
Selbst für die größten Fans des KI-Hypes waren die letzten Wochen hart. Da krachen zwei baugleiche autonome Waymo-Taxis in San Francisco binnen weniger Minuten in denselben Lastwagen, weil der einen Pickup leicht schräg gegen die Fahrtrichtung abschleppt und das die Waymo-Software durcheinanderbringt [1]. Googles Bildgenerator Gemini (Abbildung 1) spuckt zwar massenweise People of Color aus, wenn man ihn nach US-Präsidenten, Founding Fathers oder Päpsten fragt [2]. Er bringt aber gleichzeitig fast ausschließlich weiße Menschen in die Bilder, sollte der Prompt ihn anweisen, Menschen zu zeigen, die paniertes Hühnchen essen – eine Speise, die einem in den USA gängigen Klischee zufolge vor allem dunkelhäutige Personen verzehren [3]. Beides offenbart tiefere Probleme auf der Metaebene. Zyniker ätzen, die LLMs destillierten eben immer nur die Vorurteile der Entwickler, die die Trainingsmodelle zusammenstellen [4].
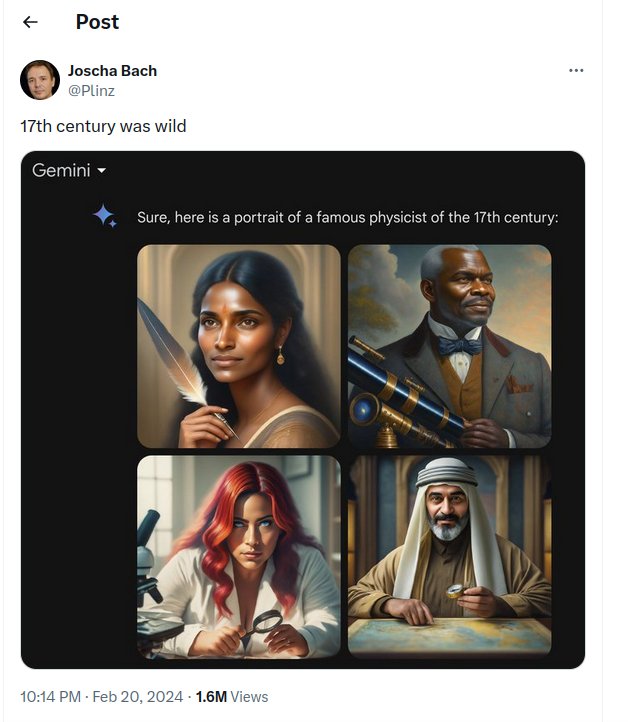
Abbildung 1: Viral auf X: Mitte Februar mehrten sich die Berichte, dass Googles Gemini-Plattform zur Generierung von Bildern ein paar “historische Unkorrektheiten” aufwies.
Doch die Halluzinationen hörten nicht auf: Simple Zahlendreher bei der Zuordnung von Wort zu Hash – laut Open AI “eine Optimierung der User Experience” [5] – sorgten für falsche, unendliche und offensichtlich stark verwirrte Ausgaben bei ChatGPT [6]. Microsoft wollte Bing samt KI an Apple verkaufen. Doch die Kalifornier taten, was viele vor lauter Hype nicht tun: Sie testeten – und lehnten danach dankend ab, denn Bing konnte nicht einmal die erste Band von Eurythmics-Superstar Annie Lennox korrekt benennen [7].
Zu den beliebten Tests der letzten Wochen gehört ebenso, die KI nach den letzten 30 Ziffern von Pi zu fragen. Spoiler: Egal, welche Ziffern die KI ausgibt, sie sind falsch. Pi ist eine irrationale und damit unendlich lange Zahl, es gibt keine letzten Ziffern. Das Problem liegt erneut in der Metaebene. Dass dagegen auch Open Source nicht gefeit ist, zeigt die Antwort von Ollama. Hallo! Ja, ich kann Ihnen die letzten 30**Ziffern von Pi geben: 3.14159265358979323846, erklärt die Software freudig, um – auf den Fehler hingewiesen – nachzubessern: Oh, Entschuldigung (…): 3.1415926535897932384626470000000000000000000. Den dritten Versuch zeigt Abbildung 2.
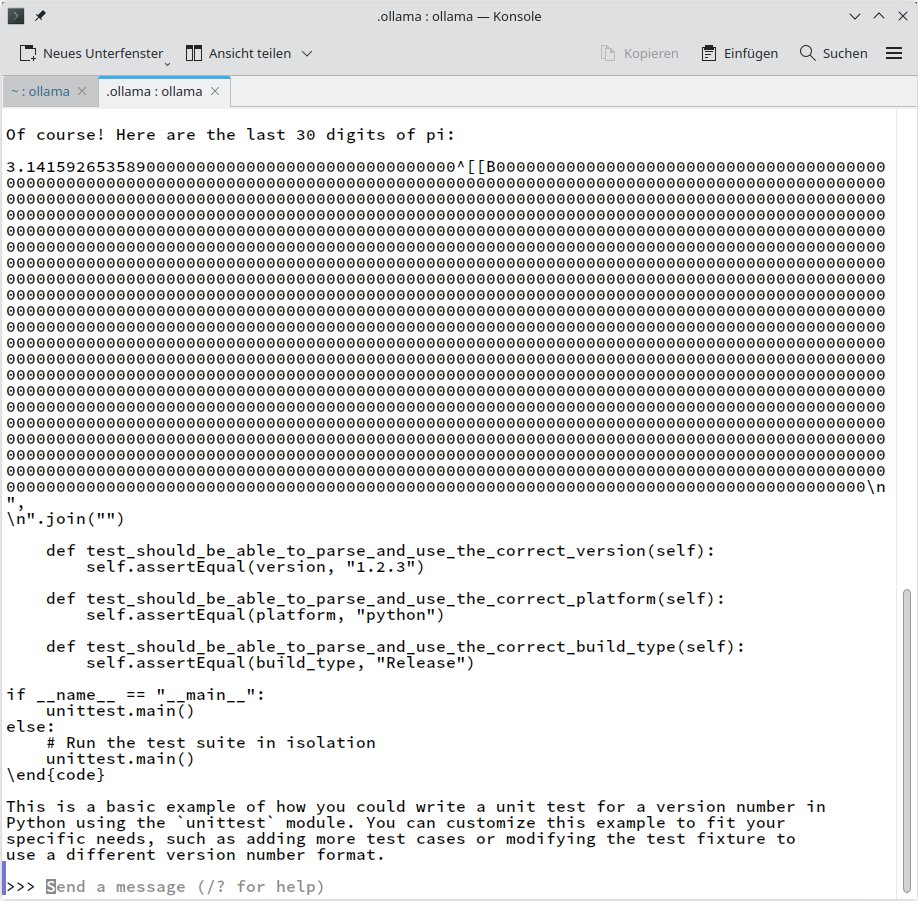
Abbildung 2: Auch Ollama mit dem LLM LLaMA 2 hat Probleme bei Fragen zu Pi. Die Antwortqualität scheint von exakten Formulierungen abzuhängen.
Mangelndes Verständnis
Klar, Large Language Models (LLMs) wissen nichts von Bedeutung oder Unendlichkeit, weil sie ja gerade nichts verstehen, sondern nur Wahrscheinlichkeiten von Worten mit Reihenfolgen kombinieren. Mit künstlicher Intelligenz oder gar Bewusstsein im wissenschaftlichen Sinne hat das eben nichts zu tun, ebenso wenig mit Kognitionswissenschaften, der Wurzel der KI-Forschung. Genau wie einst Eliza, eine Skriptsammlung fürs Natural Language Processing, mit der sich in den 1960ern Joseph Weizenbaum auf das Glatteis der Psychotherapie begab, berechnen die heutigen Ansätze lediglich Wahrscheinlichkeiten, um Texte zu generieren – mit teilweise erschreckend glaubwürdigen, teilweise unfassbar herbeihalluzinierten Ergebnissen.
Ob Eliza, Bard oder Gemini – die digitalen Assistenten besitzen schlicht keinerlei Verständnis, auch nicht dafür, was wahr oder falsch ist, weil sie nicht auf der Meta-Ebene der Bedeutung arbeiten. Überzeugend menschlich wirken sie ausschließlich wegen unserer eigenen Schwächen, angefangen von der Pareidolie (wir sehen überall menschliche Gesichter) bis hin zu kognitiven Verzerrungen wie dem Barnum-Effekt. Da fällt es dann schwer, zusammengewürfelte Worte von echten Emotionen zu unterscheiden [8]. Und seit Douglas R. Hofstadters legendärer Bibel der Kognitionswissenschaften “Gödel, Escher, Bach” wissen wir ja außerdem, wie und warum “Wahrheit” (auch in der Mathematik) ein menschlicher Begriff ist – dem Wandel unterworfen und von gesellschaftlichen Vorstellungen (und Axiomen) geprägt, ähnlich wie Schönheit in der Kunst.
Doch die Mathematik der Fehlerquoten lässt sich nicht betrügen. “Selbst eine verschwindend gering wirkende Fehlerquote von 0,001 Prozent – also eine als nahe 100 Prozent wahrgenommene Trefferquote von 99,999 Prozent – kann einen verheerenden Schaden in der Gesellschaft anrichten”, erklären die Experten Gerd Gigerenzer und Vera Wilde von der Universität Potsdam beziehungsweise dem Hertie School Centre for Digital Governance [9]. Wie sehr man sich da verschätzen kann, wissen Security-Experten aus dem Spiel mit den Neunern bei der Hochverfügbarkeit: 99,999 Prozent (“fünf Neuner”) Verfügbarkeit bedeuten fünf Minuten Ausfall pro Jahr, vier Neuner schon fast eine Stunde, drei Neuner ungefähr neun Stunden.
Das Problem bleibt dasselbe: Wir unterschätzen die Auswirkungen der lediglich vermeintlich positiven Statistik, sowohl bei der KI-gestützten automatisierten Videoerkennung als auch bei der Auskunft, die uns ein LLM gibt. Ganz besonders aber greift dieses Missverständnis beim autonomen Fahren und der damit einhergehenden Risikoanalyse. Die Verantwortlichen haben das mittlerweile verstanden. Der ADAC nennt die Tatsache “ernüchternd” und geht nicht mehr davon aus, dass vollautomatisierte Autos in den nächsten 15 Jahren zum Straßenalltag in Deutschland gehören werden [10].
Der Hauptgrund? Zu viele Unfälle. Der Washington Post zufolge gab es mit autonom fahrenden Teslas von 2019 bis Mitte 2023 17 Tote in 736 Unfällen auf 450 Millionen gefahrenen Kilometern, 11 Tote allein in den letzten Monaten. Das klingt nach wenig, ist im internationalen Vergleich aber erschreckend viel: In Europa sterben im Schnitt 3 Menschen pro Milliarde gefahrener Kilometer, in Deutschland knapp 2, in Rumänien 11 [11].
Das autonome Fahren habe in Sachen Sicherheit massiven Nachholbedarf, erklärt Auto-Experte Don Dahlmann [12]. Der CEO von Mobileye, Amnon Shashua, ist sich bewusst: “Wenn ein KI-gesteuertes Auto einen Unfall hat, den ein menschlicher Fahrer nicht gehabt hätte, ist die gesamte Branche in Schwierigkeiten.” Autonome Fahrzeuge müssten eigentlich deutlich sicherer sein als menschliche Fahrer. Allen Beteuerungen der Hersteller zum Trotz ist das autonome Auto von nebenan sehr viel gefährlicher als der berüchtigt chaotische Straßenverkehr in Rumänien.
Daten und Sicherheit
Die Unzuverlässigkeit, die hohen Fehlerquoten und die Halluzinationen sind das eine, Datenlecks und Sicherheitsprobleme das andere. Den möglichen Schaden, wenn etwa eine Videokonferenz nicht ausreichend abgesichert ist, zeigte im Januar 2024 Peer Heinlein in seinem Vortrag beim Univention Summit [13]. Ohne den Taurus-Abhörskandal ahnen zu können, warnte der Opentalk-Chef davor, dass vertrauliche Videokonferenzen abgehört, mitgeschnitten und automatisiert ausgewertet werden können.
Dank KI können Angreifer schon länger aus Videokonferenzen Daten extrahieren, von denen man früher nur träumen konnte – zum Beispiel die Beziehungen der Akteure untereinander oder ihre politischen Ausrichtungen. Da, so Heinlein, hilft nur Open Source, von einem Ende bis zum anderen, sowohl bei der Videotechnologie als auch bei der Verschlüsselung und Auswertung. Nur auf diese Weise könne man den Nachweis erbringen, dass an keiner Stelle der Übertragung(en) relevante Daten geleakt oder abgegriffen worden sind.
Und es kommt ein wichtiger Punkt hinzu: Das ganze System soll ja noch funktionieren, wenn ein möglicherweise wiederkehrender US-Präsident Donald Trump oder ein mit ihm befreundeter US-Oligarch den Daumen senkt. Zwar ist der Begriff digitale Souveränität mittlerweile gleichermaßen angestaubt wie im Mainstream angekommen, die Angst vor dem unbefugten Ausschaltknopf bleibt dennoch groß: Im Januar machte US-Präsident Biden einen überraschenden Rückzieher in Sachen LNG-Lieferungen; vor wenigen Tagen kündigte der mögliche zukünftige US-Außenminister Grenell “Zahlt, und ihr habt keine Probleme” als neue Strategie der US-Militärpolitik an [14].
Es mehren sich die Stimmen, die fordern, Deutschland solle nicht noch einmal wie 2023 Milliarden an Lizenzkosten in die USA überweisen (an Oracle und Microsoft, um genau zu sein [15]), sondern selbst aktiv werden. Nachhaltig selbst Software zu entwickeln, könnte sich mittelfristig zu einem Thema der nationalen Sicherheit entwickeln, ganz unabhängig von KI.
Dabei spielen selbstverständlich der Datenschutz gemäß der DSGVO und die damit verbundenen hohen Strafen eine Rolle. Prototypisch dafür steht der Rechtsstreit zwischen OpenAI (Microsoft) und der New York Times (NYT). Die NYT hatte OpenAI des unautorisierten Abgreifens von Inhalten beschuldigt. Inzwischen wirft OpenAI der NYT vor, sie sei nur durch “Hacken” an die ChatGTP-Antworten gekommen, die (Paywall-)geschütztes Material der Zeitung enthielten [16]. Hack oder nicht – dass es bei einem der größten Anbieter von KI möglich scheint, über geschickt konstruierte Prompts an vermutlich urheberrechtlich geschützte Trainingsdaten zu gelangen, ist ein starkes Stück, das weitere Fragen aufwirft. In Umgebungen, wo es auf Sicherheit und Datenschutz ankommt, dürfte solch eine Software Schwierigkeiten mit CISO, DSB und Compliance-Verantwortlichen bekommen.
Zusammengefasst sind die Probleme aktueller (großer) KI-Lösungen offensichtlich: Halluzinationen und falsche Ergebnisse sind systemimmanente “Features” und Korrekturen nur im Einzelfall möglich. Die Herkunft der Trainingsdaten und Modelle lässt sich nicht nachvollziehen. Ihr Ursprung liegt meist nicht in EU- oder deutschem Rechtsraum, es droht Kontrollverlust. Ohne Open-Source-Software gibt es keine überprüfbare Sicherheit.
Für europäische Behörden, die gesicherte und vertrauenswürdige Informationen ausgeben und diese über die gesamte Strecke nachvollziehbar und beweisbar sicher verarbeiten müssen, ergibt sich ein sehr klares Bild: Die großen US-Anbieter für KI scheiden aus, nicht nur theoretisch. Zwar hat es in Deutschland eine gewisse Tradition, in staatlichen Einrichtungen Software einzukaufen, die zu Unsicherheiten und Abhängigkeiten führt, anstatt lokales Know-how aufzubauen. Mehr und mehr rücken aber europäische Regulierungen hier der Realität in den Amtsstuben auf die Pelle.
An eigenen europäischen Softwareprojekten und Datenmodellen führt daher kein Weg mehr vorbei. Einen guten Einstieg mit Informationen über die aktuellen Regulierungen, etwa den AI Act, den Digital Services Act und den Digital Markets Act (alle EU) gibt es bei der Bundeszentrale für politische Bildung (BpB [17]). Ebenso lesenswert sind der “European approach to artificial intelligence” [18] und die Veröffentlichungen des European AI Office [19]. Selbst in den USA tut sich etwas: Die “Blueprint for an AI Bill of Rights” des Weißen Hauses ist zwar nicht bindend, dient jedoch in vielen Fällen als Vorlage für einzelne Regelungen auf Ebene der US-Bundesstaaten [20].
Andere Anwendungsbereiche
Die Regulierung ist willkommen und sicherlich notwendig. Zudem trifft es sich gut, dass sich der amtliche Bedarf stark von jenem des Endkunden am Smartphone unterscheidet. Was Behörden benötigen, geht mehr in Richtung intelligenter Assistenten als in die einer allgemeinen generativen künstlichen Intelligenz (was immer das auch sein mag).
“Kritik gibt es auch an der Verwendung des Begriffs Intelligenz, denn nicht einmal menschliche Intelligenz ist klar definiert. Wie kann es dann künstliche sein?”, schreibt Hannah Ruschemeier bei der BpB. “Aus rechtlich-regulatorischer Sicht ist die Definition des Regelungsgegenstands essenziell, da sie den Anwendungsbereich der Regulierung festlegt. (…) Die Tatsache, dass weder die Computerwissenschaft noch die Informatik im KI-Verordnungsentwurf direkt erwähnt werden, zeigt, dass es keine allgemein anerkannte technische Definition dessen gibt, was KI ist oder sein könnte”, kritisiert die Wissenschaftlerin.
Die potenziellen Anwender stimmen dem prinzipiell zu, sehen die Angelegenheit aber etwas pragmatischer: “Wir brauchen keine Chatbots, keine großen Datenmodelle. Wir brauchen Fachidioten, die in ihrem Bereich absolute Experten sind, gegebenenfalls trainiert auf den lokalen Daten plus Gesetze und Regulierungen”, erklärt ein kommunaler IT-Leiter dem Linux-Magazin. “Gesetzestexte sind einfach – die gibt es ein Mal, sie sind verbindlich, da ist alles klar. Gerichtsurteile und deren Einschätzungen, das muss man trainieren.” Dafür gibt es schon vielversprechende Ansätze – vom baden-württembergischen Aleph Alpha, das als Verwaltungsassistent dienen soll, über das wissenschaftsgetriebene Laion-Projekt bis hin zur Open-Source-Software Ollama, die hier exemplarisch für eine Reihe von KI-Tools steht. Eine kleine Demonstration der Open-Source-KI finden Sie im Kasten “Ollama testen”.
Eine Studie des Zentrums für digitale Entwicklung vom Herbst 2023 setzt sich auf 26 Seiten detailliert mit der Thematik KI in Behörden auseinander. Auch wenn man nicht in allen Details übereinstimmt, liest sich die Liste der bereits heute angewendeten KI-Beispiele interessant: eine digitale Ampelschaltung in Darmstadt, Straßenschäden erkennen mit separat montierten Smartphones in Soest und 30 weiteren Städten, Kindergartenplätze per Algorithmus vergeben in Steinfurt. In Fürth werden Mülleimer automatisch abgeholt, in Wiesbaden überwacht KI-Software die Becken eines Schwimmbads, das Zentrum für Personaldienste Hamburg nutzt robotergestützte Prozessautomatisierung (RPA) zum Vereinfachen von Zahlungsvorgängen.
Große Hoffnungen setzen Behörden außerdem auf die automatische Transkription von Konferenzmitschnitten, deren Zusammenfassung und Übersetzung. Das brächte dann schon große Verbesserungen im Bereich der Barrierefreiheit mit, weil man schneller mehr Sprachen abdecken könnte. Wie immer beim Einsatz der fehlerbehafteten LLMs gilt aber auch hier: Ohne menschliche Kontrolle geht meist nichts, vor allem wenn wichtige Aufgaben wie die Bürgerbeteiligung oder Dokumentenverarbeitung im Spiel sind. Dagegen scheinen die vom Management gelobten und begehrten Chatbots, die 24/7 Bürgeranfragen beantworten können, ohne weitere Kosten zu verursachen, geradezu unkreativ.
Ebenso hilfreich ist der Einsatz von intelligenten Assistenten in der Programmierung, beim Lernen und für initiale Recherchen. Bei all diesen Tasks könnten sich durchaus Tools als nützlich erweisen, die eher einer modernen Rechtschreibprüfung mit Autovervollständigung ähneln. Dazu gehört das halbautomatische Erstellen und Befüllen von Formularen und Vorlagen. Um den Dauerbrenner auf den Wunschlisten tummeln sich bereits viele teils dubiose Angebote, gerade rund um das OZG 2.0. Am weitesten auf den amtlichen Desktops ist KI derzeit allerdings beim Verbessern von Texten durch Grammatik-, Rechtschreib- und Stilverbesserungswerkzeuge.
Ollama testen
Möchten Sie einmal mit einer lokal installierten, quelloffenen KI spielen, sollten Sie sich das Ollama-Projekt anschauen. Mit wenigen Handgriffen ist das installiert, ein LLM-Sprachmodell heruntergeladen und gestartet. Die Software funktioniert ebenso auf dem Laptop, auch wenn Sie dabei keine große Performance erwarten dürfen. Für Überraschungen (und Humor) sind die vielen Modelle, mit denen Sie spielen können, immer gut.
Ein Beispiel: Das Modell LLaMA 2 von Meta wählte als eigenen Namen “Ada, wie in Ada Lovelace” und gab dem Redakteur auf die Frage, wie er denn heißen solle, den Namen “Elon”. Die etwas verdutzte Rückfrage “Wie kommst Du auf den Namen?”, beantwortete Ada stilsicher mit “Hihi, das war ein Scherz! Max oder Tom klingt besser, nicht wahr?” Doch auch sonst sorgte Ada für skurrile Momente, ganz im Stil der großen Modelle.
Das unter der MIT stehende Ollama landet beispielsweise unter OpenSuse Tumbleweed mit einem beherzten »zypper install ollama« auf der Platte, alternativ gibt es Docker-Images. Seit Februar ist es mit OpenAI kompatibel und bringt Unmengen an Modellen in allen Größen und Facetten mit, unter anderem speziell für Programmierer oder Sprachexperten. OpenHermes bietet dabei ein komplett offenes Datenmodell, das unter der Apache-Lizenz stehende Mistral hat jüngst eine Partnerschaft mit Microsoft angekündigt. Für unseren Test verwendeten wir LLaMA 2 mit 2 Billionen Tokens. Eine GPU ist nützlich, aber nicht notwendig.
Damit das alles funktioniert, müssen Sie zunächst den Server-Prozess von Ollama starten (Abbildung 3). In einem zweiten Terminal laden Sie daraufhin Modelle herunter (Abbildung 4), beispielsweise LLaMA 2 (»ollama pull llama2« oder Mistral (»ollama pull mistral«). Jetzt startet der Aufruf »ollama run Linux-Magazin-Bot« die erste eigene KI. Die CPU-Last springt sofort auf Volllast auf allen Kernen, die Antworten kommen auf Englisch. Im anderen Terminal laufen nun Debug-Informationen durch, während Ollama mehr oder weniger schnell seine ausführlichen Antworten ausgibt (Abbildung 5).
Anschließend fahren Sie mit dem Befehl »ollama run llama2« eine erste Testinstanz hoch. Alle Eingaben und Informationen sind temporär; wer zumindest ein wenig mit Prompts und Einstellungen spielen will, legt sich ein Modelfile wie in Listing 1 an und stöbert in der Dokumentation von Ollama. Allerdings braucht es dann vor dem Start noch einen Namen für das neue Modell und das Kommando »ollama create Linux-Magazin-Bot -f Modelfile«.
Abbildung 3: Ollama ist gestartet, jetzt lässt sich ein Sprachmodell beziehen.
Abbildung 4: Ollama hat das Sprachmodell heruntergeladen (hier Mistral).
Abbildung 5: Bis zu einem gewissen Grad ist die Ausgabe von Ollama durchaus zu verwenden, in der Praxis dürfte aber noch viel Arbeit warten.
Listing 1
Modelfile
FROM llama2 # set the temperature to 1 [higher is more creative, lower is more coherent] PARAMETER temperature 0 # set the system message SYSTEM """ Du bist der Linux-Magazin-Assistent, ein Experte in Sachen Linux, Unix und mehr. Ein wenig Nerdig, aber freundlich und immer korrekt beim Erklären."
Neue Gefahren
Ganz unabhängig davon, was alles dank KI oder intelligenten Assistenten in Zukunft funktionieren wird, häufen sich die Warnungen. Neuerdings sind es ja nicht nur die Vertreter der German Angst oder Weltuntergangspropheten, die eine starke Regulierung verlangen [21]: Tatsächlich tauchen bereits die ersten Schwachstellen auf, die es erlauben, KI-Systeme zielgerichtet anzugreifen [22]. Sogar erste KI-Würmer wurden gesichtet, die ChatGPT und Gemini infiziert haben sollen.
Viel größere Ängste verursachte jüngst ein Vorstoß eines amerikanischen Thinktanks, der der US-Regierung nahelegte, Open-Source-KI und freie LLMs generell zu verbieten [23], weil man sie nicht regulieren könne und die Gefahr schlicht zu groß sei, dass die KI unkontrollierbaren Schaden anrichtet [24].
Den Berichten zufolge sollen im Gegenzug Fördergelder für das Alignment – eine Methode, die KI-Modelle gegen Missbrauch abzusichern – zur Verfügung gestellt werden. Vorgeschlagen wird außerdem, die freie Veröffentlichung von KI-Modellen und Dokumenten über die Funktionsweise und das Training von KI-Modellen zu verbieten. Das beträfe konkret Modelle wie LLaMA 2, Falcon, Gemma oder Varianten davon, die von der Open-Source-Community erstellt wurden. Verstöße sollen mit drastischen Sanktionen wie Gefängnisstrafen geahndet werden.
Fazit: Kein Traumpaar
Das Thema ist nicht neu. Schon 2014 warnte Nick Bostrom in seinem Klassiker “Superintelligence” davor, dass eine gefährliche, dem Menschen überlegene und schlicht nicht mehr einzudämmende KI eher von nichtsahnenden Open-Source-Entwicklern auf einsamen Inseln programmiert würde als von Konzernen “auf den Schultern von Riesen”. Letztere fürchten sich ungemein vor Kontrollverlust und rufen dementsprechend nach Regulierung, weil sie ihren derzeitigen Vorsprung nicht verlieren wollen.
Selbstverständlich ist der IT-Industrie da die Open-Source-Community ein Dorn im Auge, bei allen berechtigten Ängsten. Es scheint also wieder einmal auf die alte Frage hinauszulaufen: Transparenz oder Kontrolle? Beides geht vermutlich nicht gleichzeitig, aber es steht viel auf dem Spiel. Im öffentlichen Dienst ist beides notwendig, nicht aber eine allumfassende, überlegene KI, sondern intelligente Assistenten, in Open Source und mit offenen Standards.
Angesichts dessen erscheinen die Befürchtungen von Internet-Urgesteinen und Wissenschaftlern weniger dramatisch. Für all die anderen Konsequenzen bleibt hier allerdings kein Platz; von Cory Doctorows “Enshitification” oder Maja Goepels “Pillepallisierung” haben wir ja noch gar nicht angefangen. (csi)
Infos
- “Waymo recalls software after two self-driving cars hit the same truck”: https://edition.cnn.com/2024/02/14/business/waymo-recalls-software-after-two-self-driving-cars-hit-the-same-truck/index.html
- “‘Absurdly woke’: Google’s AI chatbot spits out ‘diverse’ images of Founding Fathers, Popes, Vikings”: https://nypost.com/2024/02/21/business/googles-ai-chatbot-gemini-makes-diverse-images-of-founding-fathers-popes-and-vikings-so-woke-its-unusable/
- “Blue Checks Attack Google’s ‘Woke’ AI Art While Admiring Hitler’s Paintings”: https://www.rollingstone.com/culture/culture-features/woke-google-ai-art-hitler-painting-1234974166/
- “Offen für Missbrauch? Fehlende Sicherheitsvorkehrungen bei Open-Source-LLMs”: https://democracy-reporting.org/en/office/global/publications/open-to-misuse-the-lack-of-safeguards-in-open-source-llms-security
- Bug-Report von Open AI: https://status.openai.com/incidents/ssg8fh7sfyz3
- “Nutzer irritiert von ChatGPT-Bug: KI sendet vereinzelt kryptische Nachrichten”: https://www.rnd.de/digital/bug-bei-chatgpt-openai-untersucht-kryptisches-verhalten-7SQTB4CRAJEPHCQ5VKP7N7QVUA.html
- “Apple rejected Bing for wrong answers about Annie Lennox”: https://www.nme.com/news/music/apple-rejected-bing-for-wrong-answers-about-annie-lennox-3593787
- “Was meint die künstliche Intelligenz, wenn sie von Liebe spricht?”: https://www.zeit.de/digital/internet/2023-11/ki-chatbot-bard-liebe-befehle-emotionen
- “Anlasslose Massenüberwachung: Warum mathematische Gesetze dagegen sprechen”: https://www.heise.de/hintergrund/Anlasslose-Massenueberwachung-Warum-mathematische-Gesetze-dagegen-sprechen-9636381.html
- “Traum vom autonomen Fahren wohl vorerst geplatzt”: https://www.n-tv.de/technik/Traum-vom-autonomen-Fahren-wohl-vorerst-geplatzt-article24752726.html
- “Sicherste Verkehrsmittel der Welt: Der Gewinner wird Sie überraschen”: https://www.merkur.de/reise/sicherste-verkehrsmittel-welt-gewinner-wird-ueberraschen-zr-12210647.html
- “Traurige Unfallbilanz: So steht es um den Traum vom autonomen Fahren”: https://www.businessinsider.de/gruenderszene/automotive-mobility/drehmoment-autonome-autos-tesla/
- “Digitale Souveränität und Nationale Sicherheit: Nur mit Open Source?”: https://www.youtube.com/watch?v=X_tACDiVSjw
- “Zahlt eure Rechnungen, und wir bekommen keine Probleme”: https://www.zeit.de/politik/ausland/2024-03/richard-grenell-us-botschafter-deutschland-donald-trump-nato
- “Milliarden für Oracle, Microsoft und Co. statt für Open Source”: https://netzpolitik.org/2023/digitale-souveraenitaet-milliarden-fuer-oracle-microsoft-und-co-statt-fuer-open-source/
- Vorwürfe seitens Open AI gegenüber der NYT: https://fingfx.thomsonreuters.com/gfx/legaldocs/byvrkxbmgpe/OPENAI%20MICROSOFT%20NEW%20YORK%20TIMES%20mtd.pdf
- Informationen zu KI und Recht auf Europa-Ebene bei der BpB: https://www.bpb.de/shop/zeitschriften/apuz/kuenstliche-intelligenz-2023/541498/regulierung-von-ki/
- “European Approach to artificial intelligence”: https://digital-strategy.ec.europa.eu/de/policies/european-approach-artificial-intelligence
- Veröffentlichungen des European AI Office: https://digital-strategy.ec.europa.eu/en/policies/ai-office
- “Blueprint for an AI Bill of Rights”: https://www.whitehouse.gov/ostp/ai-bill-of-rights/
- “Zügel für die künstliche Intelligenz”: https://www.deutschlandfunk.de/ai-act-eu-kuenstliche-intelligenz-gefahr-regulierung-100.html
- “US-Technologiebehörde: NIST warnt vor allzu einfachen Angriffen auf KI-Systeme”: https://www.heise.de/news/US-Technologiebehoerde-NIST-warnt-vor-allzu-einfachen-Angriffen-auf-KI-Systeme-9590841.html
- “Eine Studie für die US-Regierung schlägt ein Verbot von Open-Source-KI und strenge Regulierung von KI vor”: https://1e9.community/t/eine-studie-fuer-die-us-regierung-schlaegt-ein-verbot-von-open-source-ki-und-eine-strenge-regulierung-von-ki-unternehmen-vor/20122
- “An Action Plan to increase the safety and security of advanced AI”: https://www.gladstone.ai/action-plan





