
© sportgraphic / 123RF.com
Die Mannschaftsaufstellung ist eigentlich Aufgabe des Trainers. In Mike Schillis Hobbykickertruppe wählt stattdessen ein Algorithmus die Mitspieler anhand ihrer Stärken aus.
Beim wöchentlichen Fußballspiel der Hobbymannschaft in meiner Wahlheimat San Francisco stellt sich bei 16 eingetragenen Teilnehmern und einem Spiel 8 gegen 8 immer die Frage, wer nun am Spieltag gegen wen antritt. Die Erstellung des sogenannten Team Sheets nehmen normalerweise erfahrene Spieler in die Hand, doch das ist zeitaufwendig und führt zu Diskussionen darüber, ob die acht Spieler der einen Equipe dem anderen Achter nicht haushoch überlegen sind. Ein Computerprogramm schafft da Abhilfe und erlaubt einen interessanten Ausflug in die Kombinatorik und die Entwicklung geeigneter Algorithmen.
Wie viele Möglichkeiten gibt es, 16 Teilnehmer in zwei Mannschaften zu je 8 Spielern einzuteilen? Steht eine Elf fest, ergibt sich das gegnerische automatisch aus den verbliebenen Teilnehmern, also schreibt sich das Ergebnis kombinatorisch als 8 über 16, was sich als (16*15*…*10*9) / (8*7*…*2*1) errechnet, also 12 870 ergibt. Das kann jeder Heimcomputer mit vertretbarem Aufwand bearbeiten. Selbst das Aufteilen von 22 Spielern in zwei Teams zu je 11 Kickern liegt mit 705 432 Möglichkeiten in derselben Liga.
Brute Force
In derart kleinen Ereignisräumen kann man durchaus einfach alle Möglichkeiten durchprobieren, bei jedem Durchgang eine Bewertungsfunktion aufrufen, sich die besten Ergebnisse merken und sie am Ende ausgeben. Diese Brute-Force-Methode grast also auf Biegen und Brechen schlicht alles ab. Bei einem ausgedehnteren Ereignisraum wäre es hingegen sinnvoll, zunächst eine halbwegs brauchbare Lösung als Ausgangspunkt zu wählen, sie in kleinen Schritten zu verändern und zu sehen, ob sich das Ergebnis verschlechtert oder verbessert. Simulated Annealing nennt man diesen Prozess in der Fachsprache [2].
Doch bevor es daran geht, Aufstellungen schrittweise zu verbessern, muss zunächst eine Messfunktion her, die die Qualität einer Mannschaft bestimmt. Damit lassen sich dann verschiedene Konstellationen miteinander vergleichen und die besten auswählen. Wie heißt es so schön im Mantra aller Managementkurse: “You can’t manage what you can’t measure.” Bevor es überhaupt ans Probieren oder schrittweise Verbessern geht, muss ein Fachmann die einzelnen Kicker in einigen Kategorien bewerten und es dann dem Kollegen Computer überlassen, die Mitspieler in zwei ebenbürtige Mannschaften einzuteilen. Deren Stärke ergibt sich aus den kumulierten Spielerbewertungen.
Punkte sammeln
Die Einzelbewertungen der Spieler zeigt die YAML-Datei in Listing 1, zu Illustrationszwecken in einem auf 6 Kicker beschränkten Modell. Jeder Eintrag unter »players« identifiziert einen Spieler mit Namen und legt dessen Bewertung in drei Kategorien mit Werten von 0 bis 9 fest: »offense« (Sturm), »defense« (Verteidigung) und »goalie«, also die Eignung zum Torwart. Fehlt übrigens für einen Spieler die Bewertung in einer Kategorie, soll der Algorithmus einfach 0 annehmen.
Listing 1
teams.yaml
players:
- name: joe
skills:
offense: 3
- name: tony
skills:
defense: 2
goalie: 3
- name: fred
skills:
defense: 2
- name: mike
skills:
offense: 9
- name: manuel
skills:
goalie: 9
- name: mark
skills:
defense: 9
Listing 1 weist zum Beispiel dem Spieler »tony« eine 3 in Sachen Torwartqualität zu, und der Spieler »manuel« hat einen »goalie«-Wert von 9. Übereinstimmungen mit den Namen real existierender Torhüter wären rein zufällig. Da jede Elf einen Torwart braucht und niemand sonst Torwartqualitäten aufweist, sollte der Algorithmus später also »tony« und »manuel« nicht miteinander, sondern gegeneinander spielen lassen. Außerdem sollte der Algorithmus darauf achten, dass in beiden Mannschaften in etwa gleichwertige Offensiv- und Defensivspieler kicken, damit das Match spannend und offen bleibt.
Das Einlesen der YAML-Daten und die Datenhaltung des später mannschaftsbildenden Go-Binaries implementiert Listing 2. Das Rahmenprogramm mit der Hauptfunktion »main()« definiert Listing 3. Zum Warmwerden zeigt Listing 4 einen simplen Algorithmus, der die Mitspieler nach dem Zufallsprinzip auf zwei Mannschaften verteilt. Die Ausgabe des Programms sehen Sie in Abbildung 1. Das Ganze ist offensichtlich noch nicht optimal, aber Verbesserungen kommen noch.

Abbildung 1: Zufällig erstellte Teams weisen meist erhebliche Leistungsunterschiede auf.
Strenge Typen
Damit das Go-Programm später die YAML-Daten versteht, muss es wegen der strengen Typprüfung in Go in Listing 2 erst einmal gleichartige Datenstrukturen definieren. Die gesamte YAML-Struktur in Listing 1 besteht aus einem Dictionary mit dem Eintrag »players«, unter dem ein Array von Spielern liegt. Deren Einträge enthalten jeweils den Namen (»name«) und listen die Talente (»skills«) mit numerischen Bewertungen von 0 bis 9 auf.
Listing 2
data.go
package main
import (
"gopkg.in/yaml.v2"
"io/ioutil"
)
type Skills struct {
Goalie int `yaml:goalie`
Offense int `yaml:offense`
Defense int `yaml:defense`
}
type Player struct {
Name string `yaml:name`
Skills Skills `yaml:skills`
}
type Config struct {
Players []Player `yaml:players`
}
func yamlParse() ([]Player, error) {
config := Config{}
text, err := ioutil.ReadFile("teams-real.yaml")
if err != nil {
return config.Players, err
}
err = yaml.Unmarshal([]byte(text), &config)
if err != nil {
return config.Players, err
}
return config.Players, nil
}
Folglich definiert der Go-Code in Listing 2 in Zeile 15 die Struktur »Config« mit einem Feld »Players«, dessen Wert ein Array-Slice mit Elementen vom Typ »Player« ist. Dieser in Zeile 11 definierte Typ enthält wiederum das Feld »Name« für den Namen des Spielers und ein Feld »Skills« vom gleichnamigen Typ. Der wird ab Zeile 6 definiert und gibt mit den Feldern »Goalie«, »Offense« und »Defense« die Stärke des Spielers in Werten vom Typ »int« an.
Da Go von YAML-Daten von Haus aus verarbeiten kann, darf der Code hinter den Feldnamen und -typen jeweils in Backticks nützliche Hinweise geben, falls der in YAML verwendete Feldname vom im Typ genutzten abweicht. Im vorliegenden Fall sind die Feldnamen jeweils groß geschrieben (die YAML-Library will es so), die YAML-Felder in der Konfiguration aber klein. So definiert zum Beispiel Zeile 7 mit »Goalie int ‘yaml:goalie’« das Feld »Goalie« als vom Typ »int«, dessen Pendant in den YAML-Daten »goalie« heißt.
Mehr braucht der YAML-Evaluierer »yaml.Unmarshal()« in Zeile 24 nicht. Er frisst sich in einem Rutsch durch alle Elemente des YAML-Arrays der Konfiguration, füllt die programminternen Go-Strukturen damit und sorgt auch noch für das Allozieren des benötigten Speichers – ein wahres Wunderwerk. Will der Code später zum Beispiel auf die Sturmeigenschaften des dritten Spielers von oben zugreifen, bekommt er mit »config.Players[2].Offense« den zugehörigen Integer-Wert geliefert.
Einfach planlos
Listing 3 definiert das Hauptprogramm »main()«, das als Erstes mit »yamlParse()« die YAML-Daten aus Listing 2 einliest. Zeile 12 ruft dann das später definierte »mkTeams()« zum Aufstellen der beiden Teams auf. Zurück kommt ein Array-Slice »teams« mit den Teams. Dessen Elemente bestehen wiederum aus Array-Slices von Spielern des Typs »Player«. Die For-Schleife ab Zeile 15 iteriert über beide Mannschaften, die innere For-Schleife ab Zeile 17 dann über die einzelnen Spieler. »Printf()« druckt den Namen jedes Spielers einer Equipe sowie eine Zusammenfassung der Bewertung des Kickers nach den drei vordefinierten Kriterien.
Listing 3
teams.go
package main
import (
"fmt"
)
func main() {
players, err := yamlParse()
if err != nil {
panic(err)
}
teams := mkTeams(players)
if err != nil {
panic(err)
}
teamNames := []string{"A", "B"}
for tIdx, team := range teams {
fmt.Printf("Team %s\n", teamNames[tIdx])
for pIdx, player := range team {
fmt.Printf("%d. %8s [off:%d def:%d goa:%d]\n",
pIdx+1, player.Name, player.Skills.Offense,
player.Skills.Defense, player.Skills.Goalie)
}
fmt.Print("\n")
}
}
Zum Aufwärmen soll nun ein simpler Algorithmus die Mannschaften zufällig zusammenwürfeln. Die Implementierung von »mkTeams()« aus Listing 4 initialisiert zunächst anhand eines Seeds mit der aktuellen Uhrzeit einen Zufallsgenerator aus dem Standardpaket math/rand, damit Aufrufe des virtuellen Trainers stets unterschiedliche Mannschaften liefern. Die Funktion »rand.Shuffle()« wirbelt dann ab Zeile 8 die Elemente des Array-Slices mit den 16 Spielern durcheinander. Die »return«-Anweisung ab Zeile 14 gibt die beiden Hälften des Slices an den Aufrufer zurück. Fertig ist die Mannschaftsaufstellung.
Listing 4
random.go
package main
import (
"math/rand"
"time"
)
func mkTeams(players []Player) [][]Player {
rand.Seed(time.Now().UnixNano())
rand.Shuffle(len(players), func(i, j int) {
players[i], players[j] = players[j], players[i]
})
if len(players) < 2 || len(players)%2 != 0 {
panic("Needs even number of players")
}
return [][]Player{
players[0 : len(players)/2],
players[len(players)/2:],
}
}
Vor dem eigentlichen Befehl zum Erzeugen des Binaries muss der Compiler erst noch das in Listing 2 verwendete YAML-Paket von Github abholen und übersetzen (Listing 5, erste zwei Zeilen). Anschließend bindet der Aufruf aus der letzten Zeile von Listing 5 alles zum Binary »random« zusammen, dessen Aufruf auf der Kommandozeile Abbildung 1 mitsamt der generierten Ausgabe zeigt.
Listing 5
Kompilieren
$ go mod init teams $ go mod tidy $ go build random.go teams.go data.go
Besser mit System
Doch dieser Algorithmus ist noch nicht das Gelbe vom Ei. Wie Abbildung 1 zeigt, hat der Zufallsgenerator die beiden einzigen Spieler mit Torwartqualitäten demselben Team zugewiesen, obwohl jedes Team mindestens einen Torwart braucht. Auch die Angriffs- und Verteidigungskapazitäten fallen ungleich aus. Daher sollte die nächste Stufe im Algorithmus-Design die Spieler entsprechend ihrer individuellen Stärken in zwei ebenbürtige Mannschaften aufteilen.
Wie eingangs erwähnt, ist es wegen des kleinen Ereignisraums ein Klacks, alle Möglichkeiten durchzuspielen und die Tauglichkeit einzelner Lösungen zu ermitteln und miteinander zu vergleichen. Dazu bietet Listing 6 eine Tauglichkeitsfunktion »diff()«, die eine Begegnung zweier Mannschaften »teamA« und »teamB« mit einem Score bewertet. Liegt diese Ganzzahl nahe 0, ist die Begegnung ausgeglichen, und je größer ihr Wert, desto schieflastiger wird das Match voraussichtlich.
Zum Ermitteln des Scores addiert die Funktion die absoluten Differenzen der Mannschaften in Sachen Angriff, Verteidigung und Torwartverfügbarkeit. Sie gewichtet die Angriffsfähigkeiten mit dem Faktor 2 und setzt für den Torwart den Faktor 10 an, denn fehlt der Keeper, ist das Spiel schon verloren.
Listing 6
diff.go
package main
func diff(teamA []Player, teamB []Player) int {
d := 0
for idx, player := range teamA {
s1 := player.Skills
s2 := teamB[idx].Skills
d += 2 * absDiff(s1.Offense, s2.Offense)
d += absDiff(s1.Defense, s2.Defense)
d += 10 * absDiff(s1.Goalie, s2.Goalie)
}
return d
}
func absDiff(x, y int) int {
d := x - y
if d < 0 {
return -d
}
return d
}
Schrulliges Go
Man sollte meinen, dass eine Programmiersprache von Haus aus eine Funktion zum Ermitteln des absoluten Werts einer Ganzzahl bereitstellt, aber Gos schrullige Entwickler haben sich dagegen entschieden. Das math-Paket bietet zwar eine Funktion »Abs()« für Floats, aber deren Verwendung mit Integern erfordert jede Menge Konvertierungsoperationen. Deshalb implementiert Listing 6 ab Zeile 13 lieber gleich eine Funktion »absDiff« zur Subtraktion zweier Werte, die das Ergebnis auch noch positiv macht.
Damit kann nun Listing 7 als Alternative zur Zufallsproduktion aus Listing 4 eine neue Version der Funktion »mkTeams()« präsentieren. Sie spielt mit »perm()« alle Möglichkeiten durch, bewertet die entstehenden Gruppierungen mit »diff()« und speichert die beste Konstellation mit dem niedrigsten Wert in »bestTeams« und »bestDiff«.
Listing 7
brute.go
package main
func mkTeams(players []Player) [][]Player {
bestTeams := make([][]Player, 2)
bestDiff := -1
perm(players, func(t1 []Player, t2 []Player) {
d := diff(t1, t2)
if bestDiff < 0 || d < bestDiff {
bestDiff = d
t1c := make([]Player, len(t1))
copy(t1c, t1)
t2c := make([]Player, len(t2))
copy(t2c, t2)
bestTeams = [][]Player{t1c, t2c}
}
})
return bestTeams
}
Beim Merken des besten Ergebnisses gilt es allerdings, eine nicht gerade offensichtliche Stolperfalle zu umgehen: Wer dachte, man könne einfach die Werte der Variablen »t1« und »t2« mit den Teams an einem sicheren Ort aufbewahren, sieht sich getäuscht: Dadurch, dass die Go-Runtime die von »t1« und »t2« referenzierten Mannschaften in dem darunterliegenden Array modifiziert, entstehen absurde Spielbegegnungen. Ein Array-Slice in Go ist ja immer nur ein Pointer auf ein echtes Array (Abbildung 2), und wer nur den Pointer speichert, bekommt hinterher etwaige Änderungen am darunterliegenden Array aufgetischt.
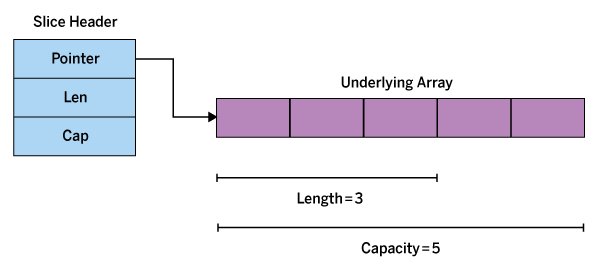
Abbildung 2: Ein Array-Slice in Go referenziert nur ein reales Array.
Die Zeilen 9 bis 12 umgehen diese Falle, indem sie einmal gefundene Mannschaften mit der in Go eingebauten Funktion »copy()« duplizieren. Zudem gilt es darauf zu achten, dass das Ziel-Array-Slice (erstes Argument von »copy()«) dieselbe Länge aufweist wie das zu kopierende Original. Hätte ersteres die Länge 0, würde »copy()« einfach 0 Bytes kopieren und der Benutzer sich die Haare raufen.
Wie nun findet Listing 7 alle möglichen Konstellation von Mannschaften? Dazu ruft es in Zeile 5 die Funktion »perm()« aus Listing 8 auf, die ein Array-Slice mit verfügbaren Spielern entgegennimmt sowie eine Callback-Funktion, die es für alle gefundenen Kombinationen einmal anspringt. Dort kann dann der User, wie in Listing 7 ab Zeile 6, Aktionen auf die beiden Mannschaften loslassen, wie zum Beispiel deren Bewertung vorzunehmen und das beste bislang gefundene Ergebnis zu behalten.
Listing 8
perm.go
package main
func perm(players []Player, f func([]Player, []Player)) {
_perm(players, 0, []Player{}, []Player{}, f)
}
func _perm(players []Player, idx int,
subset1 []Player, subset2 []Player,
f func([]Player, []Player)) {
if len(subset1) == len(players)/2 && len(subset2) == len(players)/2 {
f(subset1, subset2)
return
}
if idx == len(players) {
return
}
_perm(players, idx+1, append(subset1, players[idx]), subset2, f)
_perm(players, idx+1, subset1, append(subset2, players[idx]), f)
}
ChatGPT, hilf!
Beim Code aus Listing 8 ließ ich mir von dem Elektronengehirn hinter ChatGPT helfen. Ich befragte es nach einem Verfahren, das ein Array mit N Spielern in alle möglichen Kombinationen von zwei Mannschaften aufteilen kann. Innerhalb von zehn Sekunden hatte es eine Lösung parat (Abbildung 3). Was für eine Arbeitserleichterung für übermüdete Programmierer!
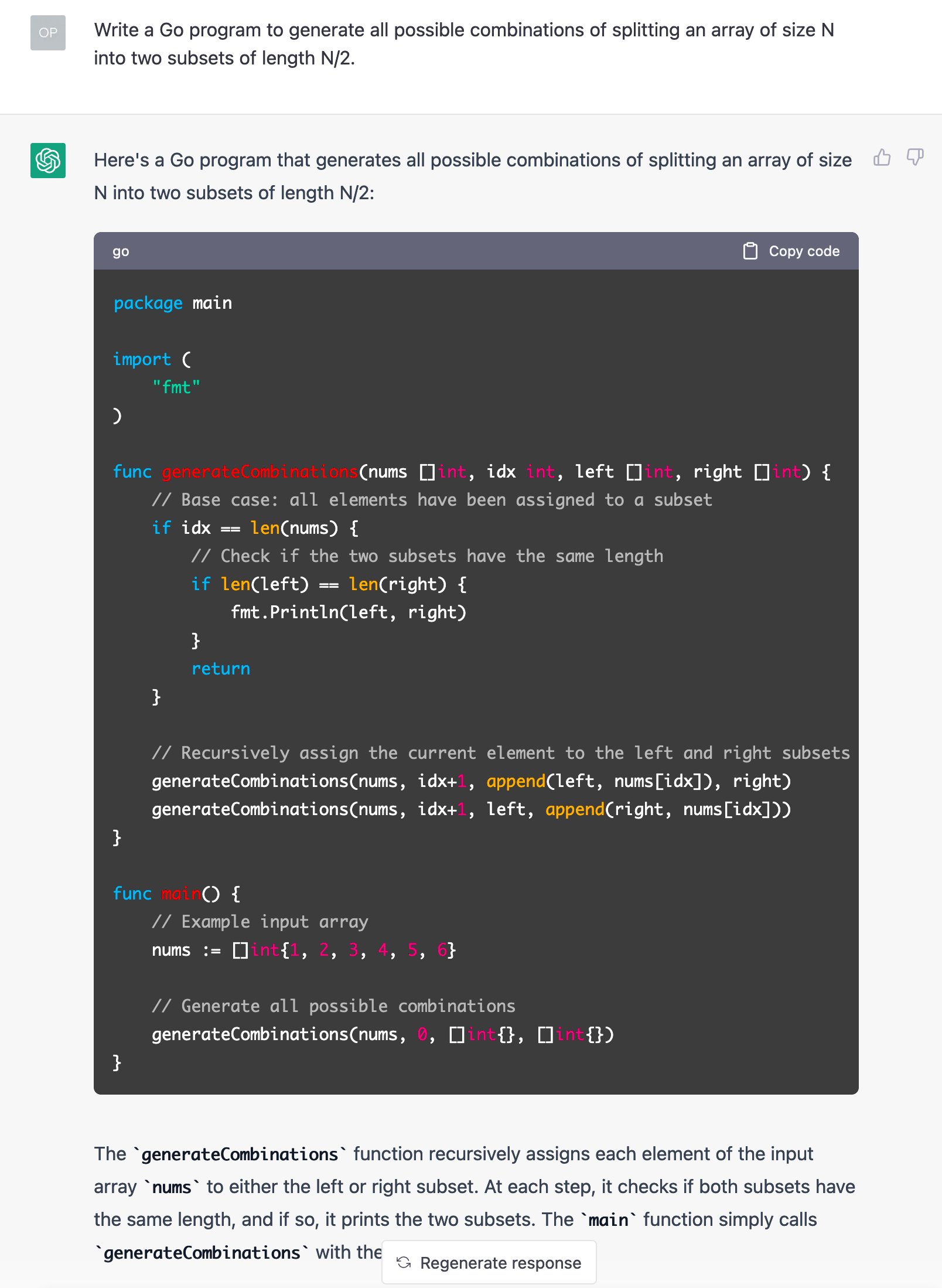
Abbildung 3: ChatGPT schreibt Teile des Go-Codes für diese Kolumne.
Zu tun blieb lediglich, den Code an die für die Mannschaften verwendete »Player«-Datenstruktur der Array-Elemente anzupassen, und schon war Listing 8 fertig. So macht das Programmieren Spaß! Es sei allerdings angemerkt, dass die Lösungen, die ChatGPT präsentiert, oft nicht hundertprozentig korrekt sind. Weist man die AI aber in einer Nachfrage auf etwaige Fehler hin, entschuldigt sie sich artig und präsentiert prompt eine bessere Lösung.
Der von ChatGPT entworfene Algorithmus basiert auf Rekursion. Er ruft die Funktion »perm()« zwei Mal mit zwei anfangs leeren Team-Slices »subset1« und »subset2« auf. Die exportierte Funktion »perm()« startet hierzu in Zeile 3 von Listing 8 die mit einem Unterstrich versteckte Funktion »_perm()«, wobei sie die beiden Subset-Parameter sowie den Index des gerade bearbeiteten Elements einfüllt. Mit einem anfangs auf 0 gesetzten »idx« merkt sich die Funktion, wo im Array-Slice der verfügbaren Spieler »players« sie sich gerade befindet, und ruft sich selbst dann zwei Mal mit zwei neuen Teamversuchen auf: Einmal hängt sie das aktuelle per »idx« referenzierte Element an »subset1« an, das andere Mal an »subset2« (Zeilen 15 und 16).
So entstehen rekursiv alle möglichen Konstellationen, die die Array-Elemente in zwei Untergruppen aufteilen. Allerdings achtet die Funktion nicht darauf, ob die Teams auch alle für die Mannschaftsbildung notwendigen Spieler enthalten. In der Tat lässt sie die Subsets sogar teilweise leer (Abbildung 4).
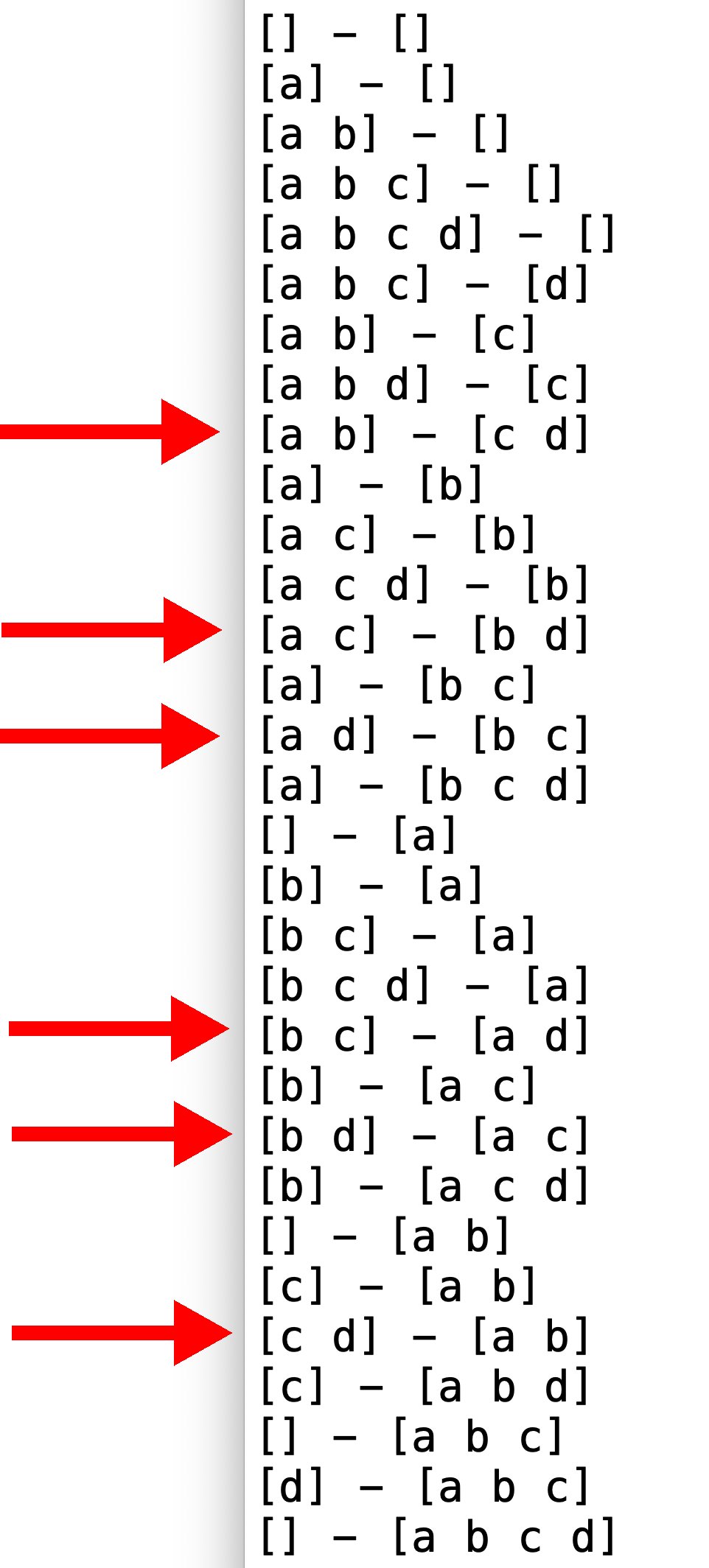
Abbildung 4: Gültige Zwei-mal-zwei-Aufstellungen für vier Spieler.
Das ist aber kein Beinbruch: Der Code in Listing 8 prüft ab Zeile 8, ob die generierten Gruppen die erforderliche Spielerzahl haben, und ignoriert alle Lösungen, die diesem Kriterium nicht genügen. Nur für zahlenmäßig passende Konstellationen – in Abbildung 4 durch rote Pfeile markiert – ruft Zeile 7 den Callback »f« mit den beiden gefundenen Mannschaften auf. Den nutzt der Aufrufer dann, um die Konstellation zu bewerten und das beste Ergebnis einzukreisen.
Dieses kompakt zu implementierende Verfahren erzeugt, wie Abbildung 5 zeigt, alle möglichen Begegnungen (zu Illustrationszwecken auf sechs Spieler reduziert). Es ist allerdings nicht optimal, da es auch symmetrische Begegnungen (Team A gegen Team B und umgekehrt) als neu bewertet. Wegen des kleinen Ereignisraums ist das aber nicht so schlimm.

Abbildung 5: Alle Permutationen von sechs Spielern zu Dreiermannschaften.
Das mittels »go build brute.go teams.go diff.go perm.go data.go« erzeugte Binary »brute« wirft sich auf die YAML-Datei »teams.yaml«, nudelt alle möglichen Teamkonstellationen durch und gibt die nach der Bewertungsfunktion ermittelten Bestwerte aus. Abbildung 6 und Abbildung 7 zeigen zwei Beispiele von brauchbaren Aufstellungen, einmal für die eingangs gestellte Aufgabe mit einem Pool von sechs Spielern und dann für ein Spiel von zwei Achterteams.
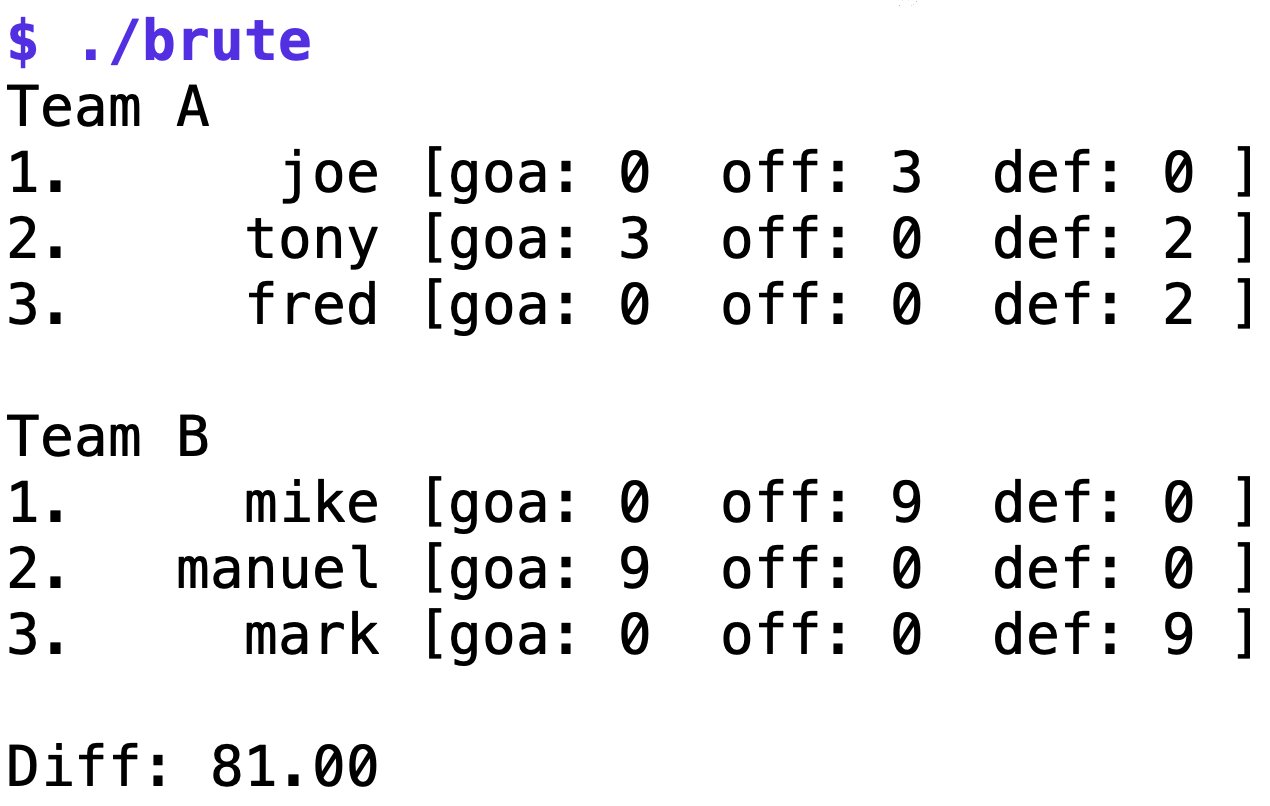
Abbildung 6: Eine nach der Brute-Force-Methode ermittelte Verteilung.
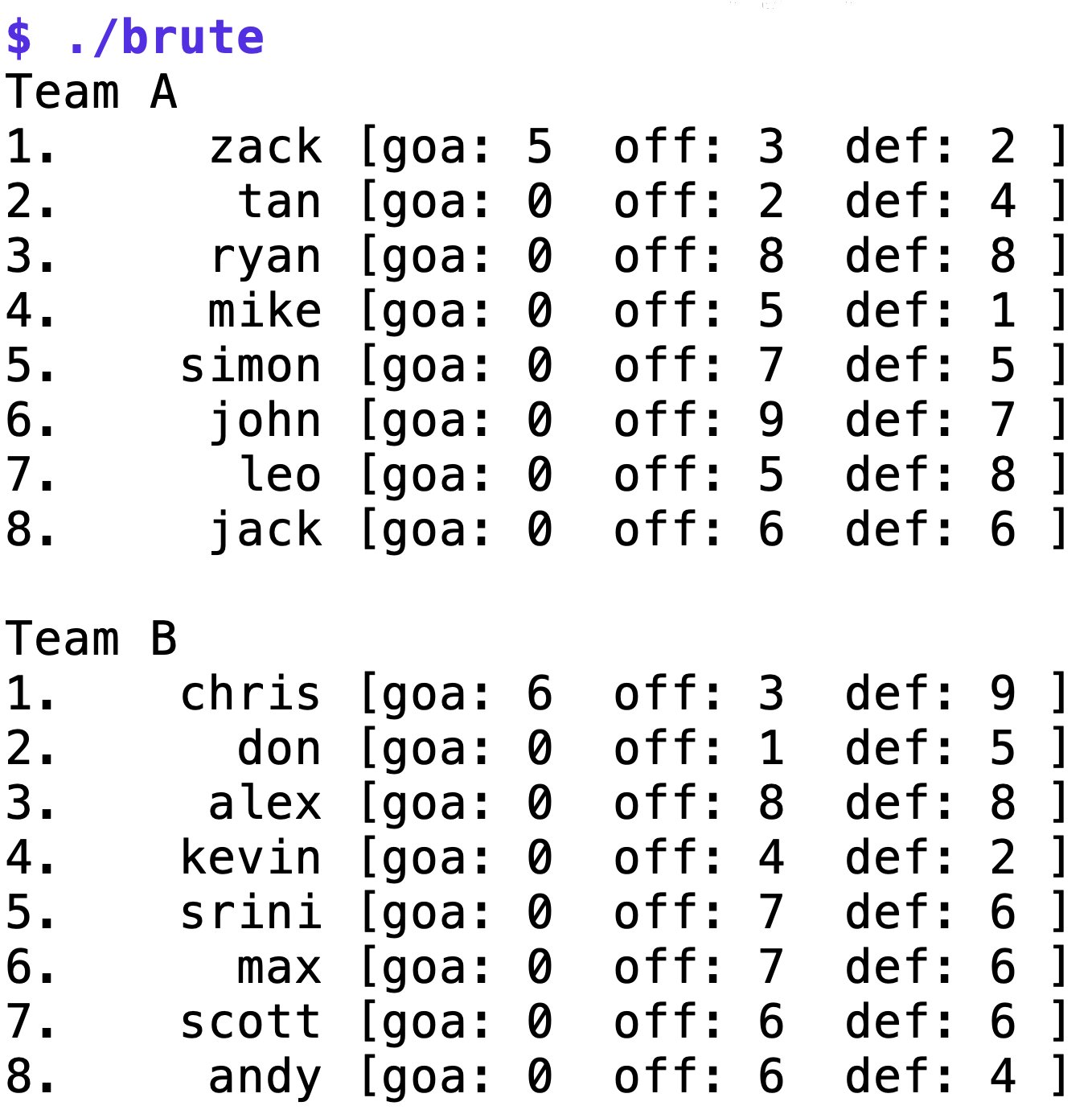
Abbildung 7: Auch bei zwei Teams zu je acht Spielern macht der Algorithmus eine gute Figur.
Bei beiden Lösungen hat der Algorithmus Verteilungen gefunden, bei denen jede Mannschaft einen Torwart hat und die Spielerwerte für Angriff und Verteidigung in etwa ausgewogen sind. So bleibt die Begegnung spannend bis zur letzten Minute, und alle Spieler geben 110 Prozent, wie es im Fußballerdeutsch so schön heißt. (uba)
Der Autor
Michael Schilli arbeitet als Software Engineer in der San Francisco Bay Area in Kalifornien. In seiner Kolumne forscht er seit 1997 jeden Monat nach praktischen Anwendungen verschiedener Programmiersprachen. Unter mailto:mschilli@perlmeister.com beantwortet er gern Ihre Fragen.
Infos
- Perl-Snapshot: Mike Schilli, “Schaut auf diese Stadt”, LM 12/2016, S. 104, https://www.lm-online.de/37665
- “How to Solve It: Modern Heuristics”: https://link.springer.com/book/10.1007/978-3-662-07807-5





