
© lassedesignen, 123RF
Der Umgang mit Datentypen und deren Werten will gelernt sein. Wer sein Einmaleins nicht beherrscht, den bestraft im besten Fall der Compiler, im schlechtesten ein undefiniertes Programmverhalten.
Gut geschriebenen Code versteht jeder Entwickler; guten Code zu schreiben, ist jedoch nicht immer ganz trivial. Das gilt auch für Code, der die Regeln zur Priorität und Auswertungsreihenfolge von Ausdrücken erfüllen will, wie sie die C++ Core Guidelines definieren. Die Regeln klingen einfach – sie umzusetzen, entpuppt sich in der Praxis häufig als komplex.
Zu kompliziert
Zum Beispiel erscheint die Regel ES.40 [1] zunächst klar und verständlich: “Vermeide komplizierte Ausdrücke.” Weniger klar und verständlich ist Listing 1.
Listing 1
Zu komplizierte Ausdrücke
while ((c = getc()) != -1) while ((cin >> c1, cin >> c2), c1 == c2) for (char c1, c2; cin >> c1 >> c2 && c1 == c2;) x = a + (b = f()) + (c = g()) * 7; x = a & b + c * d && e ^ f == 7; int x = ++i + ++j; v[i] = v[j] + v[k]; x = x++ + x++ + ++x;
Die Ausdrücke in den Zeilen 1 bis 5 zeugen von schlechtem Stil und sollten ein Code-Review nicht überstehen. Denn: Was genau passiert in dem Ausdruck aus Zeile 5? Damit die Ausdrücke in den Zeilen 7 und 8 zutreffen, müssen ein paar Bedingungen gelten: »i« und »j« müssen verschieden sein, dasselbe gilt paarweise für die Indizes »i«, »j« sowie »i«, »k«.
Gilt das nicht, besitzen die Ausdrücke kein definiertes Verhalten. Es lassen sich also keine verlässlichen Aussagen zu den Ausgaben des Programms machen. Dasselbe gilt für den Ausdruck in Zeile 10: Es gibt keine Garantie dafür, in welcher Reihenfolge das Programm die Variable »x« auswertet.
Wo wir gerade von undefiniertem Verhalten sprechen: Die Regel ES.44 (“Hänge nicht von der Auswertungsreihenfolge von Funktionsargumenten ab.” [2]) schlägt in dieselbe Kerbe. Viele Programmierer nehmen irrtümlich an, dass C++ die Argumente einer Funktion von links nach rechts auswertet. Falsch! In Code, wie ihn Listing 2 zeigt, gibt es keine Zusicherungen.
Listing 2
Reihenfolge unklar
// Undefinierte Reihenfolge beim
// Auswerten der Funktionsargumente
#include <iostream>
void func(int fir, int sec){
std::cout << "(" << fir << "," << sec << ")" << std::endl;
}
int main(){
int i = 0;
func(i++, i++);
}
Der Postinkrement-Operator »i++« gibt den alten Wert zurück, bevor er den Wert erhöht. Die Ausgabe des Programms in Abbildung 1 zeigt schön, dass der Compiler GCC zuerst das zweite Funktionsargument auswertet und dann das erste. Clang hingegen verwendet die umgekehrte Reihenfolge.
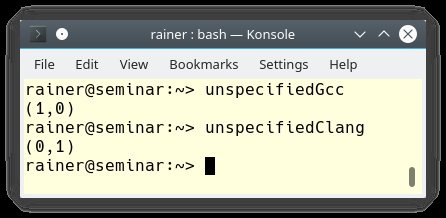
Abbildung 1: C++ folgt beim Auswerten der Funktionsargumente keiner festen Reihenfolge.
Ich weiß es besser
Explizites Casten von Datentypen ist ein Zeichen von Code Smell [3]. Wie die Schwaben zu sagen pflegen: Der Code hat ein Geschmäckle.
Der Compiler weiß automatisch, welchen Datentyp ein Wert besitzt. Jeder Eingriff in seine Domäne (ES.48: “Vermeide Typumwandlungen.” [4]) endet allzu schnell in undefiniertem Verhalten (Listing 3).
Listing 3
Verkehrtes Typsystem
#include <iostream>
int main(){
double d = 2;
auto p = (long*)&d;
auto q = (long long*)&d;
std::cout << d << ' ' << *p << ' ' << *q << '\n';
}
Die Abbildungen 2 und 3 bringen zwei Beobachtungen schön auf den Punkt: Weder kommt hinten automatisch »2« heraus, wenn der Entwickler vorn »2« hineinsteckt, noch ist die Ausgabe des Visual Studio Compilers (Abbildung 2) identisch mit der von GCC und Clang (Abbildung 3).
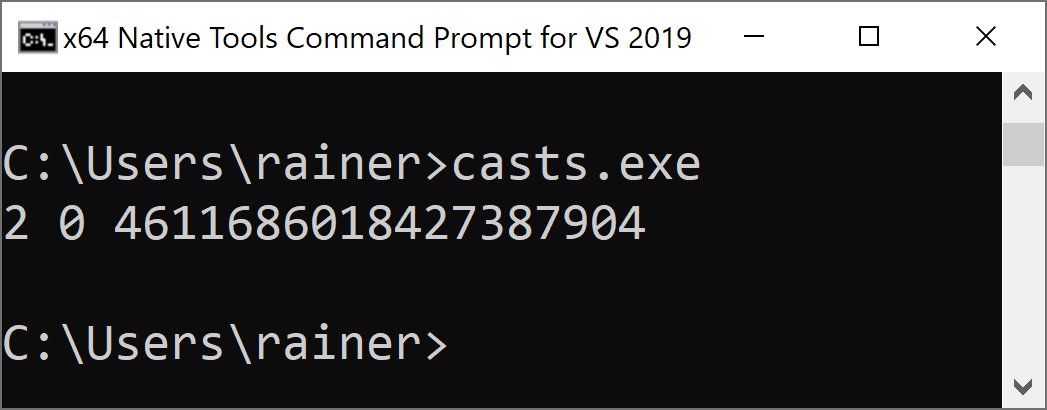
Abbildung 2: Die Ausgabe von Listing 3 beim Übersetzen mit dem Visual Studio Compiler.
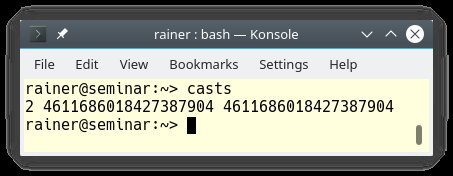
Abbildung 3: Zum Vergleich die Ausgabe von Listing 3 beim Kompilieren mit GCC und Clang.
Eine sehr beliebte, aber deswegen nicht weniger gefährliche Praxis besteht darin, einer Konstanten (»const«) die Konstanz zu entziehen, um sie wieder ändern zu dürfen. Das führt zu undefiniertem Verhalten, falls der Entwickler das Objekt wie »constInt« in Listing 4 konstant angelegt hat.
Listing 4
Typ entziehen
// Das Wegcasten von <c>const<c> // erzeugt undefiniertes Verhalten const int constInt = 10; const int* pToConstInt = &constInt; int* pToInt = const_cast<int*>(pToConstInt); *pToInt = 12; // Undefiniertes Verhalten
Der C-Standard (ISO/IEC 9899:2011), der auch Relevanz für den C++-Standard besitzt, bringt es in Klausel 6.7.3, Absatz 4 unmissverständlich auf den Punkt: “The implementation may place a const object that is not volatile in a read-only region of storage. Moreover, the implementation need not allocate storage for such an object if its address is never used.” Vereinfacht ausgedrückt bedeutet das, dass der Compiler den Versuch ignoriert, eine Konstante wie »constInt« zu verändern.
Alles ist vergänglich
Die Regel ES.84 [5] lautet: “Versuche nicht, eine lokale Variable ohne Namen zu deklarieren.” Das klingt erst einmal unschuldig, doch ein Verletzen dieser Regel birgt beträchtliches Unheilspotenzial. Das musste der Schreiber dieser Zeilen dies bereits am eigenen Code erfahren (Listing 5).
Listing 5
A Lock with no name?
#include <mutex>
#include <iostream>
template <typename T>
class MyGuard {
public:
explicit MyGuard(T& m): myMutex(m) {
std::cout << "lock" << '\n';
myMutex.lock();
}
~MyGuard() {
myMutex.unlock();
std::cout << "unlock" << '\n';
}
private:
T& myMutex;
};
int main() {
std::cout << '\n';
std::mutex m;
MyGuard<std::mutex> {m};
std::cout << "Kritischer Bereich" << '\n';
std::cout << '\n';
}
Der entscheidende Punkt in Listing 5: »MyGuard« in Zeile 22 trägt keinen Namen. Das bedeutet, dass das Programm in dieser Zeile den Konstruktor und Destruktor von »MyGuard« aufruft. Konsequenterweise aktiviert Zeile 22 auch »myMutex.lock()« und »myMutex.unlock()«. Damit verwendet das Programm den angedeutet kritischen Bereich in Zeile 23 unsynchronisiert.
Die Idee hinter »MyGuard«: Es verliert seine Gültigkeit am Ende der »main()«-Funktion und ruft erst dann »myMutex.unlock()« (Zeile 12) auf. Abbildung 4 zeigt das fatale Verhalten des Programms.
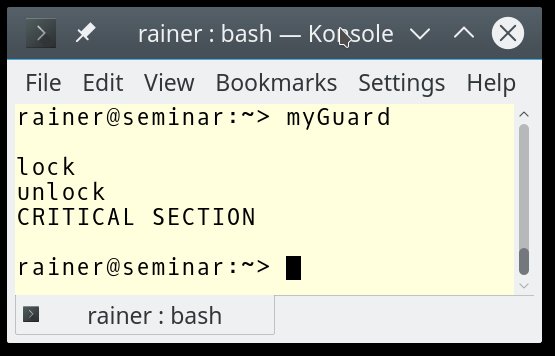
Abbildung 4: Aufgrund einer vergessenen Deklaration führt das Programm den kritischen Bereich ungeschützt aus.
1 + 1 = ?
Die Regeln zur Arithmetik sollten den Entwickler eigentlich wieder auf sicheres Terrain zurückführen. Die Regel ES.100 spricht jedoch eine andere Sprache [6]: “Vermische keine Arithmetik mit und ohne Vorzeichen miteinander.” Was passiert, wenn der Programmierer vorzeichenbehaftete (signed) und vorzeichenlose (unsigned) Arithmetik vermischt? Das Resultat des Codes aus Listing 6 entspricht jedenfalls nicht der Erwartung.
Listing 6
Vorzeichen-Mischmasch
// Vermischen von vorzeichenbehafteter
// und vorzeichenloser Arithmetik
#include <iostream>
int main() {
int x = -3;
unsigned int y = 7;
std::cout << x - y << '\n'; // 4294967286
std::cout << x + y << '\n'; // 4
std::cout << x * y << '\n'; // 4294967275
std::cout << x / y << '\n'; // 613566756
}
Am Ende produzieren die großen drei Compiler (GCC, Clang und Microsofts Compiler) dasselbe Ergebnis. Allerdings ist es auch nicht besser, wenn der Entwickler vorzeichenlose (unsigned) Datentypen für die Arithmetik verwendet. Das bekräftigt auch die Regel ES.102 [7]: “Verwende vorzeichenbehaftete Typen für Arithmetik.” Was andernfalls passieren kann, zeigt Listing 7.
Listing 7
Arithmetik ohne Vorzeichen
#include <iostream>
template<typename T, typename T2>
T subtract(T x, T2 y) {
return x - y;
}
int main() {
int s = 5;
unsigned int us = 5;
std::cout << subtract(s, 7) << '\n'; // -2
std::cout << subtract(us, 7u) << '\n'; //4294967294
std::cout << subtract(s, 7u) << '\n'; // -2
std::cout << subtract(us, 7) << '\n'; //4294967294
std::cout << subtract(s, us + 2) << '\n'; // -2
std::cout << subtract(us, s + 2) << '\n'; //4294967294
}
Wie bei Listing 6 sind sich auch hier die großen Drei (GCC, Clang und Microsofts Compiler) wieder einig, wenn es um das Ergebnis des Programms geht.
Unheil droht aber auch all jenen, die auf die Regeln ES.103 und ES.104 pfeifen: “Don’t overflow.” [8] und “Don’t underflow.” [9] Der Effekt eines Speicherüber- oder -unterlaufs ist derselbe: Speicherkorruption und undefiniertes Verhalten.
Wie lange läuft zum Beispiel das Programm aus Listing 8, das jenseits der Array-Grenzen liest und schreibt? Spoiler-Alarm: beunruhigend lange. Das Programm schreibt jeden hundertsten Array-Wert auf »std::cout« (Abbildung 5).
Listing 8
Overflow und Underflow in Aktion
#include <cstddef>
#include <iostream>
int main() {
int a[0];
int n = 0;
while (true){
if (!(n % 100)){
std::cout << "a[" << n << "] = " << a[n] << ", a[" << -n << "] = " << a[-n] << '\n';
}
a[n] = n;
a[-n] = -n;
++n;
}
}
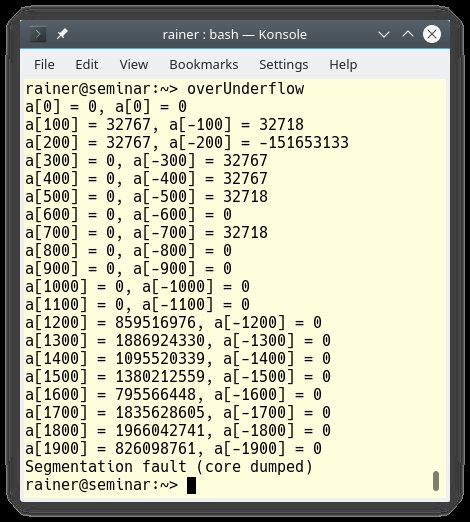
Abbildung 5: Über die Grenzen des Arrays hinaus zu lesen und zu schreiben, führt zu undefiniertem Verhalten und ist daher eine schlechte Idee.
Zum Ende des Artikels noch ein grundsätzlicher Hinweis: In Sachen Überlauf unterscheidet es sich in der Arithmetik elementar, ob ein vorzeichenloser oder ein vorzeichenbehafteter Datentyp zum Einsatz kommt. Am einfachsten zeigt sich der Unterschied im Quellcode. Mit dem Programm in Listing 9 beginnt der Vergleich.
Listing 9
Arithmetik – Unsigned Type
// Addition bei Überlauf eines
// vorzeichenlosen Datentyps
#include <cstddef>
#include <iostream>
int main(){
std::cout << '\n';
unsigned int max{100000};
unsigned short x{0};
std::size_t count{0};
while (x < max && count < 20) {
std::cout << x << " ";
x += 10000;
++count;
}
std::cout << "\n\n";
}
Der entscheidende Punkt am Programm ist, dass die fortwährende Addition auf »x« in Zeile 13 keinen Überlauf erzeugt. Sie erzeugt vielmehr eine Modulo-Operation, wenn der Wertebereich von »x« endet. Der Grund: Bei »x« handelt es sich um eine vorzeichenlose »unsigned short« (Zeile 9).
Listing 10
Arithmetik – Signed Type
// Addition bei Überlauf eines
// vorzeichenbehafteten Datentyps
#include <cstddef>
#include <iostream>
int main() {
std::cout << '\n';
int max{100000};
short x{0};
std::size_t count{0};
while (x < max && count < 20) {
std::cout << x << " ";
x += 10000;
++count;
}
std::cout << "\n\n";
}
Die Zeile 9 von Listing 10 definiert »x« dagegen als vorzeichenbehaftete Variable. Diese kleine Modifikation hat weitreichende Konsequenzen, denn es kommt nun zu einen Überlauf. Abbildung 6 zeigt beide Programme in Aktion: Zuerst kommt die Arithmetik mit der vorzeichenlosen Summationsvariablen zum Einsatz, dann die mit der vorzeichenbehafteten. Die entscheidenden Stellen der Ausgabe sind rot markiert.
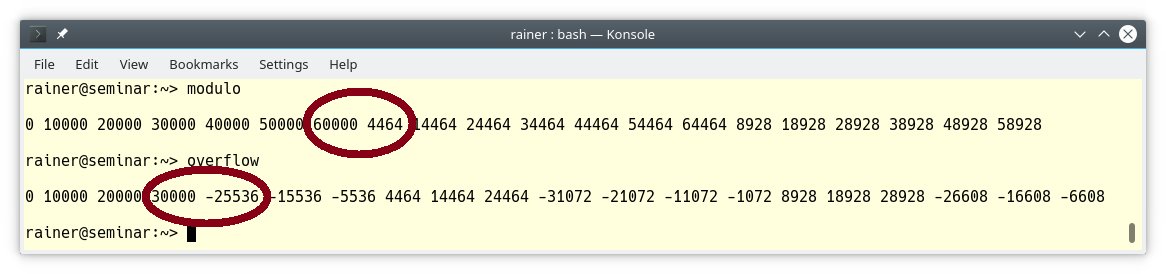
Abbildung 6: Überlauf bei einer vorzeichenlosen und einer vorzeichenbehafteten Variablen.
Jetzt gilt es noch, eine brennende Frage zu beantworten: Wie erkennt ein Programmierer den Überlauf? Ersetzt er den Ausdruck »x += 1000« durch einen Ausdruck mit geschweiften Klammern (»x = {x + 1000}«), dann prüft der Compiler, ob eine verengende Konvertierung (Narrowing Conversion) vorliegt. Dabei erfolgt eine Konvertierung unter Verlust der Datengenauigkeit. Abbildung 7 zeigt, dass GCC die verengende Konvertierung direkt zur Sprache bringt.

Abbildung 7: GCC erkennt an dieser Stelle verengende Konvertierungen.
Die Ausdrücke »x += 1000« und »x = {x + 1000}« erscheinen aus der Performance-Perspektive unterschiedlich: Der zweite Ausdruck kann einen temporären Wert für »x + 1000« erzeugen. Im konkreten Fall zeigt der Compiler Explorer [10] aber, dass beide Ausdrücke denselben Code erzeugen.
Wie geht es weiter?
Der nächste Artikel dieser Serie zu den C++ Core Guidelines beschäftigt sich mit der ureigensten Domäne von C++: Performance. (kki/jlu)
Infos
-
Regel ES.40: http://isocpp.github.io/CppCoreGuidelines/CppCoreGuidelines#Res-complicated
-
Regel ES.44: http://isocpp.github.io/CppCoreGuidelines/CppCoreGuidelines#Res-order-fct
-
Code Smell: https://en.wikipedia.org/wiki/Code_smell
-
Regel ES.48: https://isocpp.github.io/CppCoreGuidelines/CppCoreGuidelines#Res-casts
-
Regel ES.84: http://isocpp.github.io/CppCoreGuidelines/CppCoreGuidelines#Res-noname
-
Regel ES.100: http://isocpp.github.io/CppCoreGuidelines/CppCoreGuidelines#Res-mix
-
Regel ES.102:http://isocpp.github.io/CppCoreGuidelines/CppCoreGuidelines#Res-signed
-
Regel ES.103: http://isocpp.github.io/CppCoreGuidelines/CppCoreGuidelines#Res-overflow
-
Regel ES.104: http://isocpp.github.io/CppCoreGuidelines/CppCoreGuidelines#Res-underflow
-
Compiler Explorer: https://godbolt.org





