
© Robelio, Pixelio.de
Die perfekten Einstellungen für jede Datenbank gibt es nicht – umso wichtiger, im Einzelfall die richtigen zu finden. Zum Erfolg führen Zielstrebigkeit, Geduld, Know-how und Messungen.
Selbst beim Auto hilft es nicht, den Motor einfach aufzubohren. Wahrscheinlich braucht man andere Kolben und Ventile, eine neue Nockenwelle, eine neue Abstimmung der Motorelektronik, von der Zulassung nicht zu reden – fraglich, ob sich das lohnt. Das steht bei einer Datenbank außer Frage: Im besten Fall entwickelt sie gratis ein vielfaches Drehmoment, nur durch geschickte Konfiguration der vorhandenen Hardware und passende Serversettings.
Weil aber auch die Datenbank ein komplexes System darstellt, gelingt das nur mit guter Planung, genügend Know-how und einer fundierten Strategie. Das Linux-Magazin hat den Weg am Beispiel einer OLTP-Datenbank (Online Transaction Processing) im Folgenden mit MySQL durchexerziert.
Manches Ergebnis war spontan vielleicht so nicht zu erwarten. Zum Beispiel: Wer speziell im I/O-System einzelne Komponenten misst und optimiert, der kann nicht davon ausgehen, dass die jeweils schnellsten Einzelspieler im Verbund auch die beste Mannschaft ergeben. Der Grund liegt in der Komplexität des I/O-Systems. Ein Request durchläuft auf dem Weg von der Applikation über das Filesystem, den Linux-I/O-Scheduler, den Bus, den Plattencontroller bis zur Platte zahlreiche Stationen, die aufeinander ein- und rückwirken. Selten sind ihre Aktionen koordiniert, leicht kommt es dazu, dass mehrere Beteiligte die Daten zwischenspeichern und umsortieren, was die Performance drückt.
Wer nun beispielsweise den Workload und den I/O-Scheduler konstant hält und das Filesystem und/oder das Disk-Layout ändert, kann ungewollt ganz neue Wahrscheinlichkeiten für unerwünschte Nebenwirkungen im Zusammenspiel von Komponenten hervorrufen.
Daraus ergeben sich zwei Konsequenzen: Erstens ist eine bestimmte Konfiguration als Einheit zu betrachten, die unter einem definierten Workload eine bestimmte Leistung erreicht. Den Datenbank-Scheduler oder das Datenbank-Filesystem schlechthin, die immer und in jedem Fall die optimale Wahl darstellen, gibt es nicht. Das führt, zweitens, zwanglos zu der Frage, was ein Datenbank-Benchmark überhaupt leisten kann, wenn man ihn doch nur als Einzelfall-Aussage betrachten darf?
Auch die Antwort ist zweigeteilt: Zum einen ist eine vorsichtige Verallgemeinerung auf vergleichbare Szenarien sicher statthaft, zum anderen kann sich der Admin im besten Fall von dem Benchmark eine Systematik abschauen, mit der er selber seine individuelle Situation messen und beurteilen kann.
Der Workload
Für die Versuche in diesem Beitrag verwendeten die Tester den Datenbank-Benchmark DBT-2 [1], den das Open Source Development Lab (OSDL) ab 2002 in Anlehnung an den TPC-Benchmark entwickelte, der als Industriestandard gilt. Leider verlief das Projekt bereits im Jahr 2004 bei Versionsstand 0.40 wieder im Sand. Der ursprüngliche Entwickler teilte auf Befragen der Redaktion mit, dass er inzwischen anderswo mit anderen Vorhaben beschäftigt sei. Mit etwas sportlichem Ehrgeiz ist die Benchmark-Suite aber wieder nutzbar zu machen, größtes Hindernis ist die fehlende Dokumentation, die häufig dazu zwingt, den Quelltext zu konsultieren.
DBT-2 simuliert das Warenwirtschaftssystem eines Großhändlers mit einer Anzahl Lager (Warehouses), das Bestellungen, Auslieferungen und Warenzugänge verbucht. Jedes Lager enthält 100000 Artikel und beliefert zehn Verkaufsbezirke. Zu jedem Verkaufsbezirk gehören 3000 Kunden. Für jedes Lager simuliert die Software im vorliegenden Fall 15 Terminals, die unterschiedlich komplexe Zugriffe auslösen, wobei es sich immer um eine von fünf Aktionen handelt. Sie
- platzieren eine Bestellung,
- veranlassen eine Lieferung,
- kontrollieren die Zahlungen,
- überprüfen den Bestellstatus oder
- checken den Lagerbestand.
Die häufigste Aktion (45 Prozent) ist eine neue Bestellung. Dabei sorgt das Testprogramm dafür, dass in 10 Prozent der Fälle das angefragte Lager nicht liefern kann und die Bestellung weiterreichen muss. An zweiter Stelle der Häufigkeitsliste (44 Prozent) rangiert die Verfolgung des Zahlungsverkehrs. Alle anderen Transaktionen kommen viel seltener vor.
Die größte Tabelle »order_line« fasst mehr als 4 GByte, die gesamte Datenbank bringt es auf rund 5,7 GByte. Die Performance des kompletten Mix repräsentiert schließlich eine einzelne Kenngröße, die Anzahl der New-Order-Transactions pro Minute, die das System insgesamt zu bewältigen vermochte.
Läuft der Benchmark, produziert er nach einer gewissen Einschwingzeit, die er nicht auswertet, einen typischen OLTP-Workload, der sich über die Anzahl der involvierten Warehouses skalieren lässt. Die Benchmarks für diesen Artikel berechneten Szenarien mit ein bis 20 Warehouses, die jeweils für eine bestimmte Konfiguration rund sieben Stunden Rechenzeit benötigten. Am Ende standen weit mehr als 200 Stunden Gesamtlaufzeit der Tests in den Büchern. Dabei kamen aus Sicht von MySQLs Inno-DB-Statistik permanent um die 2500 Lese- und 650 Schreiboperationen pro Sekunde zusammen. Der Load Average des 8-Kern-Servers pegelte sich auf etwa 6,5 ein. Zur Laufzeit ließ sich – dank der großzügigen Ausstattung mit 16 GByte RAM – kaum Paging und kein Swapping beobachten.
Nun kommt es also darauf an, das System für diesen Workload so einzustellen, dass sich die bestmögliche Performance ergibt. Ein erster und offensichtlicher Ansatzpunkt ist die Hardware und ihre Konfiguration. In der Praxis sind hier die Freiheitsgrade oft beschränkt. Trotzdem lohnt sich ein Blick auf die Optionen: Womöglich stecken in der Konfiguration noch Reserven, vielleicht erweist sich aber auch, dass die Beschaffung neuer Technik unumgänglich ist. Auch die Linux-Magazin-Tester hatten sich für ein Setup entschieden (siehe Kasten “So haben wir getestet”), das allerdings war frei konfigurierbar.
|
So haben wir |
|---|
 Abbildung 1: Die Hardware für die Benchmark-Tests. Oben der Server unten das Raid. Als Datenbankserver für diesen MySQL-Benchmark stand das Modell Proserv II der Firma Exus Data zur Verfügung (Abbildung 1, oben), bestückt mit zwei Quad-Core Xeon 5460 (64 Bit, 3,16 GHz) und 16 GByte RAM sowie Gigabit-Ethernet. Die Platten dieser Testkonfiguration befanden sich in einem Transtec-Raid 6100 SATA Premium (Abbildung 1, unten), ausgestattet mit 12 Serial-ATA-Disks, einem UW-320-SCSI-Controller für die Anbindung des Hosts und 512 MByte Cache. Hier konfigurierten die Tester die im Text erläuterten Volumes und mounteten eine jeweils 100 GByte große Partition für die Datenbank-Daten. Als Betriebssystem kam auf dem Datenbank-Server die Server-Edition von Ubuntu 8.04.1 (64 Bit) mit einem Kernel 2.6.24-19 zum Einsatz. |
Disklayout
Datenbanken, zumal im OLTP-Betrieb, sind I/O-gebunden, also muss ein Hauptaugenmerk dem Storage gelten. Konfigurationsmöglichkeiten ergeben sich auf dem Server und auf dem – meist externen – Storage-System. Bei diesem gilt es, einen Kompromiss zwischen Kosten, Verfügbarkeit und Performance zu finden, denn diese Parameter widersprechen sich in der Regel.
Grundbaustein der Verfügbarkeit ist Redundanz, die aber kostet Zeit und Geld. Wer nur auf die Performance blicken würde, der müsste sich für ein möglichst großes Stripeset entscheiden: Hier verteilen sich Lese- und Schreibzugriffe auf möglichst viele Spindeln, was die Geschwindigkeit steigert, gleichzeitig nutzt diese Konfiguration die Kapazität maximal aus. Allerdings multipliziert sich mit jeder Platte das Risiko eines Daten-Totalverlusts. Dafür sorgt bereits der Ausfall irgendeiner einzelnen Platte aus dem Verbund.
Deswegen kommen praktisch nur Raid-Level mit Redundanz wie Raid 1, 5, 6, oder 10 in Frage. Raid 1 (die Spiegelung) erkämpfte sich bei den hier beschriebenen Versuchen (Abbildung 2) einen kleinen Vorsprung, hat aber das Handicap, auf zwei physische Devices beschränkt zu sein. Wo deren Kapazität nicht reicht oder wo – wie beim vorliegenden leselastigen Workload – eine höhere Lese-Performance gefragt ist, scheidet es aus. Raid 6, das den Ausfall von zwei Platten des Verbunds kompensiert, bot die eingesetzte Hardware nicht an.
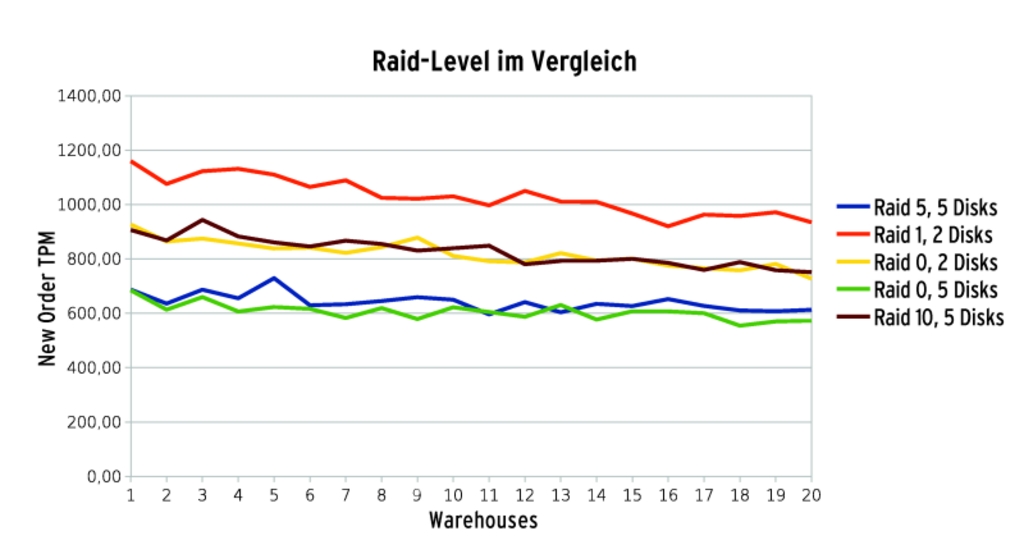
Abbildung 2: Wer größere Kapazitäten benötigt, für den kommen hier praktisch nur die Optionen Raid 5 oder 10 in Frage. Beide bedingen einen Kompromiss.
Bleiben Raid 5 oder 10, das Stripeset aus Spiegeln. Raid 5 nutzt die Kapazität besser (von der Gesamtkapazität ist nur der Gegenwert einer Platte zu subtrahieren), hinkt aber beim Schreiben hinterher, weil es dabei Checksummen berechnen muss. Raid 10 ist schneller, auch in diesem Test, opfert aber die Hälfte der Gesamtkapazität der Redundanz.
Scheduler
Auf halbem Weg zwischen Datenbank und Platte versucht der I/O-Scheduler von Linux etwas für die Performance zu tun, indem er die Schreib- und Leseanforderungen zwischenspeichert und in einer nach seiner Vorstellung optimalen Reihenfolge umsortiert und zusammenfasst. Verschiedene Scheduler kennen dafür verschiedene Strategien, aber alle kämpfen mit demselben Problem: Je größer die Intelligenz der Plattencontroller in ihrem Rücken, die Ähnliches versuchen und dabei das Ohr an der Hardware haben, desto eher durchkreuzen deren Entscheidungen die Pläne des Schedulers.
Der Controller sortiert sich die Lese- und Schreiboperationen dann neu, wobei er beispielsweise auch die momentanen Kopfpositionen berücksichtigen kann, die der Scheduler nicht kennt. Dessen Mühe war dann umsonst, es ergibt sich unter Umständen durch die Doppelarbeit sogar der gegenteilige Effekt und die I/O-Performance sinkt.
Die Testergebnisse rechtfertigen jedoch den Aufwand, den die Scheduler treiben: Der NOOP-Scheduler, der alle Requests einfach durchwinkt, schneidet am schlechtesten ab (Abbildung 3). Zu kompliziert darf es aber offenbar auch nicht sein. Der Anticipatory Scheduler, der vorauszuahnen versucht, an welchen Stellen eine Applikation wohl demnächst lesen oder schreiben will, platziert sich am zweitschlechtesten. Und das, obwohl die Benchmarks auf einem dedizierten Datenbankserver liefen, bei dem keine anderen Anwendungen parallel zur Datenbank ganz andere Daten lesen oder schreiben wollten.
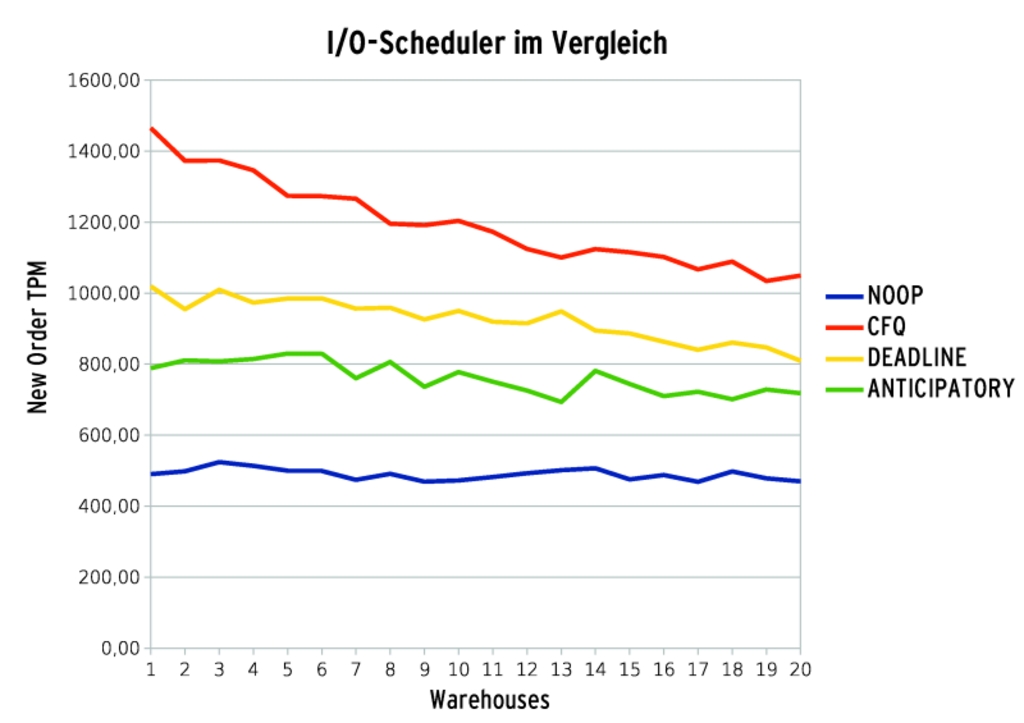
Abbildung 3: Ganz ohne geht es schlecht: Schlusslicht ist der Pseudo-Scheduler NOOP. Aber zu kompliziert darf es auch nicht sein, ein guter Kompromiss ist der Completely-Fair-Scheduler.
Einen guten Kompromiss scheint der relativ junge Completely-Fair-Scheduler (CFQ) zu liefern, der mit prozessbezogenen I/O-Queues arbeitet und sich darum bemüht, die verfügbare Bandbreite möglichst gerecht zu verteilen. Auch der Deadline-Scheduler, der eher bestrebt ist die Latenz zu minimieren, konnte da nicht mithalten. Die Tester behielten von nun an den CFQ-Scheduler bei, den übrigens viele Distributionen von vornherein als Default vorsehen.
Filesysteme
Hat man sich für ein Disklayout entschieden – hier ist es Raid 10 – und einen Scheduler gewählt, geht es um das Filesystem. Dass das Universal-Filesystem Ext 3 sich nicht die Pole Position erkämpft, war zu vermuten. Bei Reiser-FS ist die Zukunft unsicher, da sein straffälliger Erfinder eine lange Haft verbüßt. Eine ganze Reihe vielversprechender Filesysteme wie Ext 4 oder BTRFS befinden sich derzeit in Entwicklung, sie sind aber für den Produktivbetrieb noch nicht ausgereift, geschweige denn zertifiziert.
Theoretisch kommen auch Raw Devices in Betracht, zumindest kann MySQL die Verwaltung des Plattenplatzes in die eigenen Hände nehmen. Dabei darf der Admin auf einen Performancegewinn von 2 bis 5 Prozent hoffen. Allerdings erkauft er sich diesen relativ bescheidenen Vorteil mit deutlichen Nachteilen. Beispielsweise darf er für das Backup oder für das Monitoring der Plattenkapazität nicht mehr auf Methoden zurückgreifen, die sich auf Filesysteme beziehen, und auch keine entsprechenden Tools mehr verwenden. Auch ein Desaster Recovery wird sehr viel schwieriger, weil sich auf die Daten kaum mehr unabhängig von dem laufenden Server zugreifen lässt.
Bleiben XFS und JFS als ernsthafte Bewerber. Beide gehören zu den ältesten Journaling-Filesystemen unter Linux, sind entsprechend stabil und ausgereift und ermöglichen sehr große Dateien und Filesysteme. In diesem Vergleich (Abbildung 4) kann sich JFS leicht absetzen und kommt fortan zum Zuge.
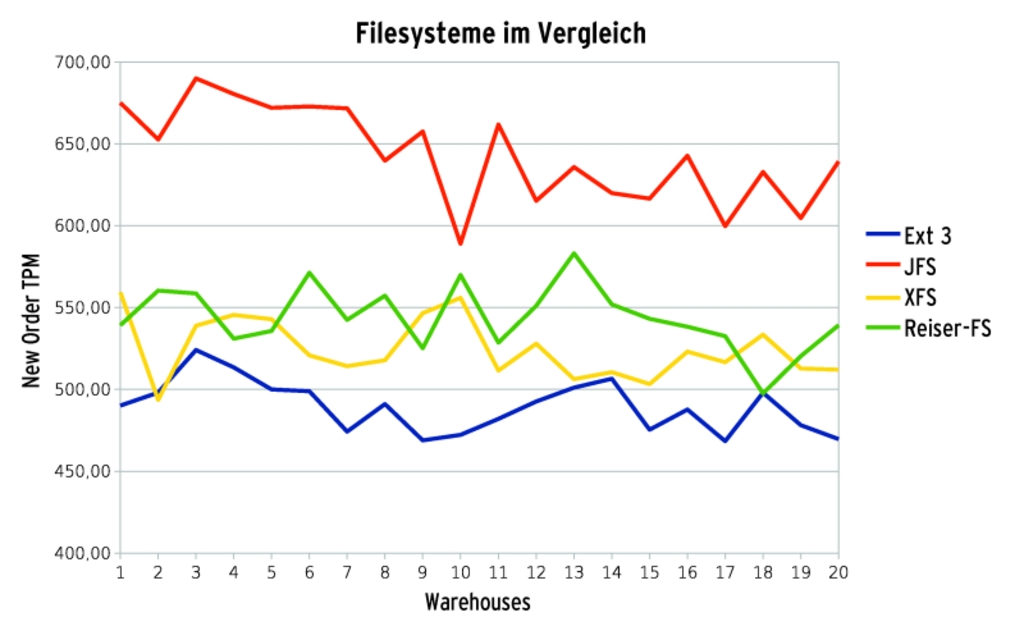
Abbildung 4: Leichter Vorsprung für JFS, das übrige Feld ist eng beisammen. Sehr große Unterschiede sind von der Filesystem-Auswahl offenbar nicht zu erwarten.
Prozessoren
MySQL profitiert tendenziell eher von schnellen als von vielen CPUs, weil es eine Query nicht parallelisieren kann, sodass mehrere CPUs (oder Kerne) gleichzeitig daran rechnen. Entsprechend beeinflusst die Menge der CPUs kaum die Latenz einer Abfrage. Trotzdem kann MySQL im Bedarfsfall mehrere Abfragen auf verschiedenen CPUs gleichzeitig bearbeiten – vorausgesetzt die Applikation ist in der Lage, solche konkurrierenden Queries zu erzeugen. Auch dürfen parallel zu einer Abfrage auf anderen Prozessoren Hintergrundtasks laufen.
Schließlich benötigen auch das Betriebssystem und eventuelle andere Applikationen Rechenzeit, was ein Motiv für das Verfahren ergibt, eine Anzahl von CPUs oder Kernen für die Datenbank zu reservieren. Unter Linux bewerkstelligt dies »taskset«.
Am ehesten profitieren OLTP-Workloads von vielen CPUs, weil hier oft viele kurze Operationen anfallen, die aus verschiedenen Verbindungen stammen und daher gleichzeitig laufen. Reicht diese Parallelität aber nicht aus, dann gibt es nicht selten den gegenteiligen Effekt: Mehr CPUs sind dann langsamer. Es entsteht Overhead für die Koordination, doch dem steht kaum Gewinn gegenüber. Genau das passierte auch bei diesem Benchmark (Abbildung 5).
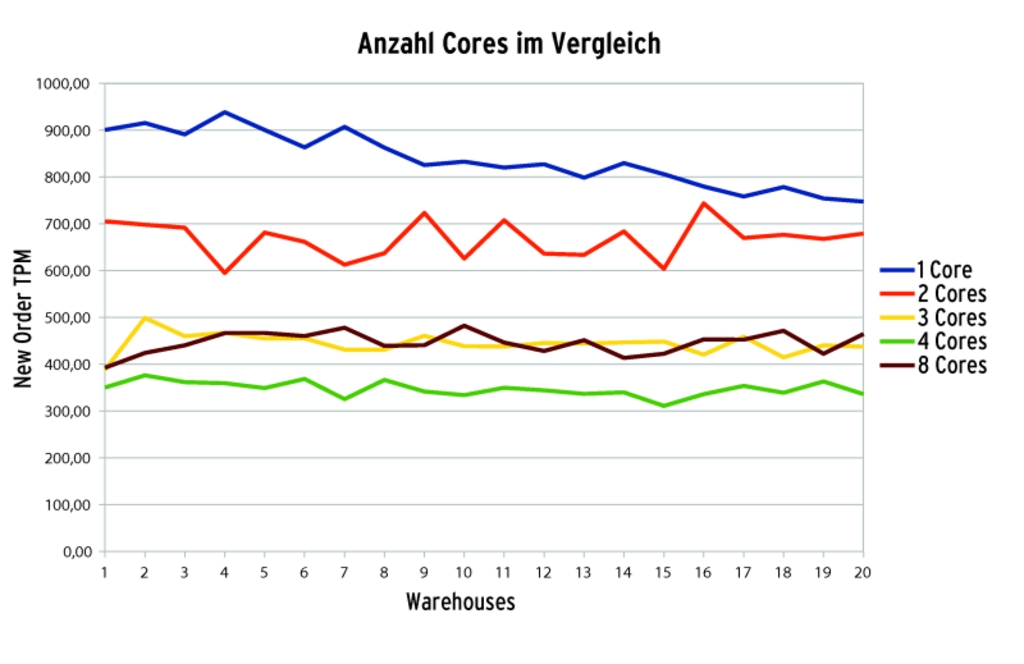
Abbildung 5: Auf den ersten Blick paradox – weniger ist mehr. MySQL wird mit vielen CPU-Kernen unter Umständen langsamer. Die verursachen nämlich Overhead, bringen aber nicht genügend Nutzen.
Memory
Nachdem die wesentlichen Parameter der Hardware justiert sind, soll es um Datenbankparameter gehen, die sich zugunsten einer guten Performance beeinflussen lassen. Eigentlich müsste man freilich noch früher ansetzen – die größten Tuning-Potenziale bieten sich beim Datenbankdesign und beim Entwurf der Queries. Allerdings hat der Admin darauf nicht immer Einfluss.
Anders beim Datenbankserver. Hier sind alle Stellschrauben erreichbar. Wer an ihnen dreht, sollte im Auge behalten, dass viele Parameter über nicht immer offensichtliche Mechanismen miteinander gekoppelt sind. Aus demselben Grund verbietet es sich, mehrere Variablen gleichzeitig zu ändern, denn das macht den Effekt völlig undurchschaubar. Wer das beherzigt, dem stehen viele Eingriffsmöglichkeiten offen. Aber eine einzelne hat den mit Abstand größten Effekt: das Memory, sprich: die Caches.
I/O-Prozesse laufen im Speicher nun mal etliche Größenordnungen schneller als auf der Festplatte ab. Je mehr der Admin also von der Platte ins RAM verfrachten kann, desto schneller wird die Datenbank sein. Wer jetzt aber in einer Kurzschlusshandlung alles RAM der Datenbank zuordnet, schneidet sich ins eigene Fleisch, weil er das Betriebssystem in zeitfressendes Swapping zwingt.
Ein praktikabler Anhaltspunkt ist stattdessen die Größe der Datenbank. Kennt man die nicht, hilft unter MySQL etwa »SHOW TABLE STATUS FROM DB-Name« weiter. Die Benchmark-Datenbank verwendet die Inno-DB-Speicherengine, bei der als zentraler Parameter »innodb_buffer_pool_size« die Größe jenes Puffers reguliert, der nicht allein die Speicherseiten mit den Tabellendaten, sondern auch den Insert-Puffer oder Locks und zwischengespeicherte Write-Requests aufnimmt.
Der Inno-DB-Buffer soll sich in der Größenordnung Datenbankgröße plus 10 Prozent bewegen. Wer nicht so viel RAM zur Verfügung hat, kann alles, was anderweitig nicht dringend nötig ist, diesem Puffer zuschlagen. So oder so setzt das übrigens oft ein 64-Bit-Betriebssystem (und passende CPUs) voraus und ist ein wesentlicher Grund, weshalb man heute einen Datenbankserver niemals mit der 32-Bit-Version einrichten sollte, die nur rund 2,5 GByte RAM adressiert.
MySQLs Defaultwerte sind sehr zurückhaltend dimensioniert. Deshalb ist der voreingestellte Wert für den Inno-DB-Buffer (8 MByte) für die 6 GByte große Datenbank viel zu klein. Einen guten Anhaltspunkt für die richtige Größe liefert die Buffer Pool Hit Rate, die »SHOW INNODB STATUS« ausgibt.
Fazit
Tuning ist oft eine Geduldsprobe. Beharrlich sind alle Optionen zu prüfen, oft zwingen die Ergebnisse den Tester zu einem Schritt rückwärts. Als Lohn winken aber durchaus handfeste Performancegewinne, die in vielen Fällen nur mit etwas Tüfteln zu bezahlen sind.
|
Infos |
|---|
|
[1] DBT-Benchmark-Suite: [http://sourceforge.net/projects/osdldbt] |





