
© Paul Gibbings, 123RF
Der dritte Teil des Datafari-Workshops behandelt Magazine, die ihre Artikel im PDF-Format veröffentlichen, sowie das Verbessern von Metadaten bereits indexierter Artikel.
In der Prä-Internet-Epoche waren Fachzeitschriften nicht nur eine geschätzte, sondern häufig auch die einzige Quelle für aktuelles Fachwissen. Artikelarchive gängiger Fachzeitschriften kann man auch heute noch bei den Verlagen auf Datenträgern oder als Downloads beziehen. Häufig müssen Leser dafür kein Abo abschließen, sondern erhalten zurückliegende Ausgaben kostenlos oder gegen kleines Geld.
Ein digitales Fachartikelarchiv hat auch im Zeitalter des Internets mit seiner Informationsüberflutung durchaus seine Daseinsberechtigung, lässt sich allerdings nur mithilfe einer vernünftigen Volltextsuche sinnvoll nutzen. Bislang beschäftigte sich diese Serie [1] ausschließlich damit, solch eine Suche für Linux-Fachzeitschriften zu zimmern, die im HTML-Format vorliegen [2]. In diesem Teil kommen PDF-Dateien hinzu.
Als Fundament diente stets Datafari [3], ein Open-Source-Suchserver auf Basis von Solr [4] und anderen Apache-Komponenten. Im so erzeugten verlagsübergreifenden Gesamtarchiv blättert der Autor nun bereits durch zahlreiche Ausgaben nicht nur von Linux-Magazin und LinuxUser, sondern auch von englischsprachigen Publikationen wie Linux Magazine, Admin Magazine, Ubuntu User, Linux Journal, Linux Voice und Linux Gazette. Nun folgen iX, c’t, LinuxWelt und AndroidWelt nebst Sonderheften.
Dabei sollten die Nutzer stets den rechtlichen Rahmen beachten: Einige Publikationen verbieten in ihren Nutzungsbedingungen, die Originaldateien zu verändern oder im Netzwerk zu speichern. Eine Aufnahme in den Index darf daher nicht über einen Proof of Concept hinausgehen. Interessierte finden alle Konfigurationsdateien, Skripte und sonstige Zutaten auf dem Listing-Server des Verlags [5].
Magazine im PDF-Format
Bei strukturierten HTML-Dokumenten fällt das Extrahieren der Texte und Metadaten noch relativ leicht, da die Informationen in der Regel bestimmte Tags tragen (zum Beispiel Titel, Überschriften und Textkörper). Sehr beliebt bei Verlagen sind aber auch Archiv-DVDs mit Magazinausgaben im PDF-Format. Es gibt hier zwei gebräuchliche Varianten, nämlich eine PDF-Datei pro Artikel und eine PDF-Datei pro Heft.
Die frühen Jahrgänge 2000 bis 2004 des englischsprachigen Linux Magazine gehören zur ersten Gruppe und sollen nun das Artikelarchiv vervollständigen. Zwar fehlt diesen PDFs jeder Hinweis auf Magazinnamen, Titel, Jahrgang und Ausgabennummer, aber auf einem Umweg lassen sich die fehlenden Informationen beschaffen.
Die Textextraktion basiert wegen des Dateiformats auf dem bereits aus dem zweiten Teil des Workshops bekannten Tika Transformer in Manifold CF (MCF [6]). Auch für das Linux Magazine im PDF-Format gibt es einen eigenen MCF-Job namens »Tika LM_en« (Tabelle 1). Die Indexdateien jedes Jahrgangs dienen als Einstiegspunkte für den MCF Crawler (Seed-URLs). Der Admin passt diese Seed-URLs an die lokale Ablage auf dem Webserver an und ersetzt dessen Adresse (Host oder IP), wobei ihm das Admin-UI von MCF hilft.
|
Magazin |
Typ |
Jahrgang |
Sprache |
Job |
Verfahren |
|---|---|---|---|---|---|
|
Linux Magazine |
Jahrgang |
2000 bis 2004 |
EN |
»Tika LM_en« |
Tika Extractor |
|
Linux Magazine |
Metadaten |
2000 bis 2004 |
EN |
»AddMeta LM_en« |
XML Handler |
|
LinuxWelt |
Jahrgang |
ab 2011 |
DE |
»Tika_pdf LW_de« |
Tika Extractor |
|
AndroidWelt |
Jahrgang |
ab 2012 |
DE |
»Tika_pdf AW_de« |
Tika Extractor |
|
iX |
Jahrgang |
1988 bis 1993, ab 2008 |
DE |
»Tika_pdf IX_de« |
Tika Extractor |
|
iX |
Jahrgang |
1994 bis 2007 |
DE |
»SolrCell IX_de« |
HTML Extractor |
|
c’t |
Jahrgang |
1983 bis 1989, ab 2008 |
DE |
»Tika_pdf CT_de« |
Tika Extractor |
|
c’t |
Jahrgang |
1990 bis 2007 |
DE |
»SolrCell CT_de« |
HTML Extractor |
Ist der Job erledigt, fehlen in den Suchergebnissen aus dieser Quelle erwartungsgemäß sämtliche Metadaten inklusive Titel. Das sieht nicht nur beim Präsentieren auf dem Bildschirm schlecht aus, sondern verhindert auch eine vernünftige Quellenangabe. Die fehlenden Informationen sind glücklicherweise da, verstecken sich aber in den digitalen Inhaltsverzeichnissen (»index.html«) der Heftausgaben, die die Artikel mitsamt Themenbereich, Titel und klickbarem Link zur Artikeldatei zusammenfassen (Abbildung 1).
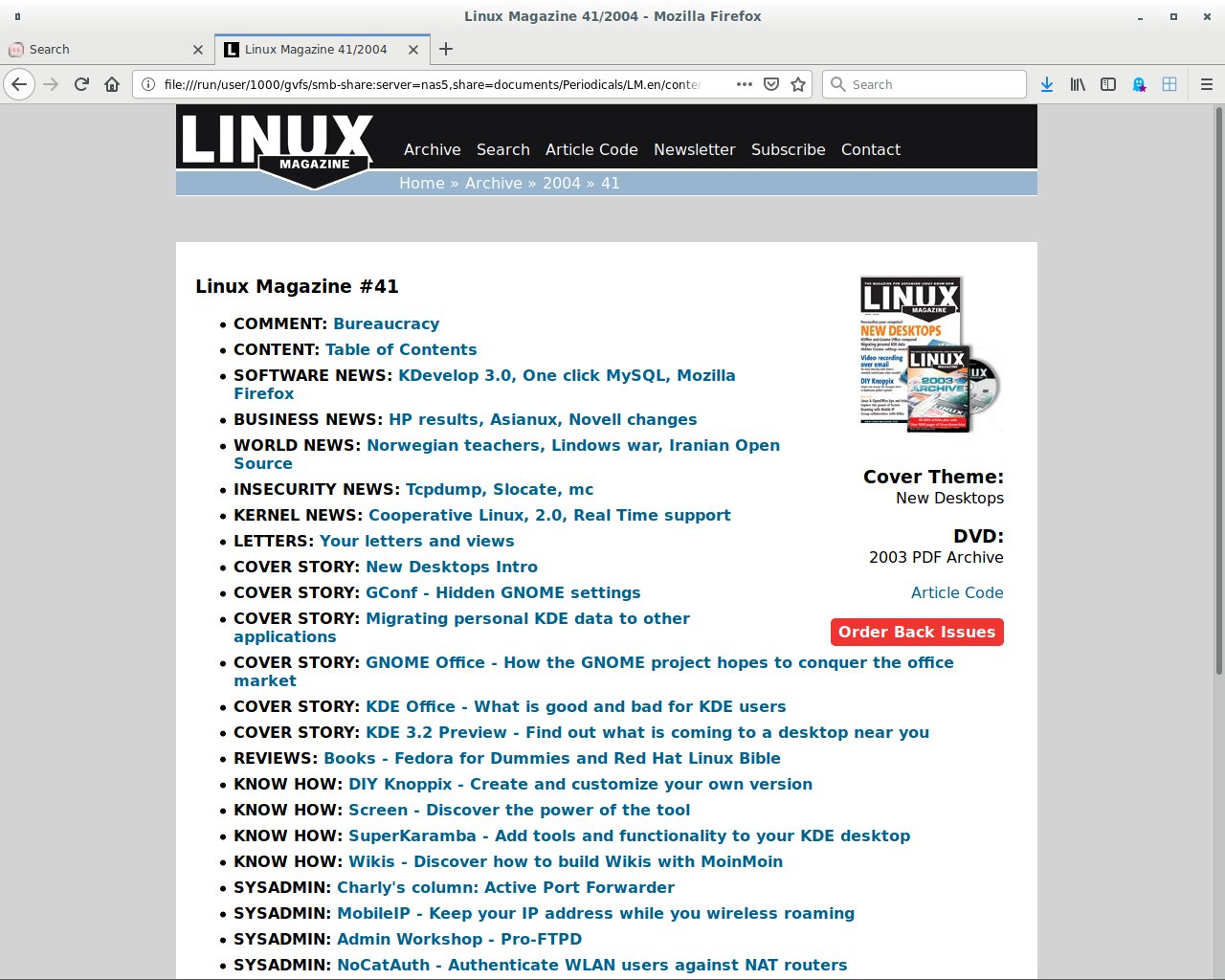
Abbildung 1: Die Index-Datei mit der Heftübersicht liefert Informationen, die den PDFs fehlen.
Metadaten dazu
Mit einem geeigneten Werkzeug gräbt der Suchende nun die vermissten Daten aus. Hier schlägt die Stunde von Xidel [7], einem ausgezeichneten Tool zum Zerlegen von XML- und HTML-Dateien. Diesen steuern ein übergeordnetes Shellskript namens »upd_docs_lmen.sh« sowie das kleine XQuery-Programm aus Listing 1 (»meta_lmen.xq«). Am Ende liefert das Tool eine XML-Datei mit den vermissten Metadaten pro Jahrgang.
Listing 1
Metadaten generieren mit XQuery-Script
declare variable $wl := doc("file://whites.xml")//url;
[...]
let $rem := "metadata added"
for $li in //ul[@class="articles"]/li
let $title := $li/h2/a/text()
let $headline := $li/p/text()
let $s := lower-case(substring-before($li/h2/string(),":"))
let $words := subsequence(tokenize($s, " "),1,2)
let $section := string-join((for $w in $words
return capitalize-first($w)), " ")
let $href := $li/h2/a/@href
let $link := concat($base,"/",$issue,"/",$href)
let $pageno := if (matches($href,"^\d{3}"))
then substring($href,1,3) else ""
let $pagend := if (matches($href,"^\d{3}-\d{3}"))
then substring($href,5,3) else ""
let $section := clean_section($section)
where exists(index-of($wl, $link))
return
<doc>{
<field name="id">{$link}</field>,
<field name="issue" update="set">{$issue}</field>,
<field name="year" update="set">{$year}</field>,
<field name="title" update="set">{$title}</field>,
<field name="headline" update="set">{$headline}</field>,
<field name="section" update="set">{$section}</field>,
<field name="pageno" update="set">{$pageno}</field>,
<field name="pagend" update="set">{$pagend}</field>,
<field name="comments" update="set">{$rem}</field>
}</doc>
Search-API
Das Shellskript ermittelt über das Solr-Interface zur Suche zunächst eine Liste mit URLs derjenigen Dokumente im Index, die eine Nachbehandlung benötigen – in diesem Fall alle Artikel des Linux Magazine im PDF-Format.
Der Archivar muss an dieser Stelle beachten, dass die Datafari-Entwickler einen minimalen Schutz der Solr-Instanz eingebaut haben: Die Tomcat-Konfiguration erlaubt Zugriffe auf den Solr-Standard-Port 8983 nur über das lokale Loopback-Interface der Maschine. Das soll den Index vor fatalen Update-Anweisungen schützen wie etwa:
<delete><query>*:*</query></delete>
Die enthalten im Zweifelsfall neben der hier gezeigten globalen Löschanfrage noch andere Gemeinheiten. Der Schutz hilft allerdings nur, solange sich der Bösewicht nicht auf dem Solr-Server anmelden kann. Andere Maschinen müssen Solr-Suchanfragen über ein restriktives Proxy-Interface von Datafari [8] und via Port 8080 absetzen (siehe Kasten “Umwege”). Die lokale Adresse des Servlets lautet daher:
http://localhost:8983/solr/FileShare/select
Umwege
Jeder Benutzer, der sich auf der entfernten Solr-Maschine anmelden darf, kann den Standard-Port 8983 der Solr-Instanz via SSH-Tunnel auch auf die lokale Maschine weiterleiten, um dort wie gezeigt den Port 8984 anzusprechen. Das bewirkt der Befehl »ssh -L localhost:8984:127.0.0.1:8983 Datafari-Proxy-IP -N«.
Wer zur Proxy-URL greift, der verwendet stattdessen die IP-Adresse des Datafari-Proxys als Server-Adresse:
http://Datafari-Proxy-IP:8080/Datafari/SearchProxy/select
Der Search Handler beantwortet eine Suchanfrage implementierungsbedingt im JSON-Format. Glücklicherweise versteht der Xidel-Parser auch JSON und erzeugt mit einer Pipeline die gewünschte Liste aller URLs bereits indexierter PDF-Ausgaben des Linux Magazine (Listing 2). Die erzeugte XML-Liste sieht wie in Listing 3 gezeigt aus.
Listing 2
Eine URL-Liste abrufen
$ curl -s http://Datafari-Proxy-IP:8080/Datafari/SearchProxy/select?q="%2Bpublication:Linux?Magazine%20%2Bextension:pdf"\&wt=json\&hl=false\&rows=99999\&fl=url\&json.wrf=lmen | && sed s/^lmen\(// | sed s/\)$// | && xidel --data=- --input-format=json --output-format=xml-wrapped -e "$json(response/docs)" | && xidel --data=- --xml -e "//url"
Listing 3
Von Listing 2 generierte Liste
<?xml version="1.0" encoding="UTF-8"?> <xml> <url>URL1</url> <url>URL2</url> <url>URL3</url> [...] </xml>
Das XQuery-Skript prüft, ob die gerade bearbeitete URL in der Liste auftaucht. Tut sie es nicht, verwirft es den ganzen Datensatz. Dieser Schritt verhindert, dass ein neues Phantom-Dokument mit Metadaten, aber ohne Text im Index landet, was nicht im Sinne des Erfinders wäre. Bei einem Quellarchiv im einwandfreien Zustand ohne kaputte Links in den Indexdateien sollte dieser Fall nicht eintreten. Die Praxis zeigt aber, dass schon mal der ein oder andere kleine Patzer in den Verweisen lauert.
Listing 4 zeigt einen Ausschnitt der generierten Update-Anweisungen. Die Datei nimmt die Metadaten eines ganzen Jahrgangs auf, wobei sie jeden Artikel als Solr-Dokument mit dessen URL zur eindeutigen Identifikation (»id«) repräsentiert. Fiese Delete-Anweisungen lassen sich jedoch auch in die Solr-Anweisungsdateien einbauen. Es versteht sich daher von selbst, dass nur ausgesuchte Nutzer Schreibzugriff auf das Ablageverzeichnis haben sollten.
Listing 4
Solr-Anweisungsdatei (URLs gekürzt)
<add>
<doc>
<field name="id">http://Pfad/2003/32/Comment.pdf</field>
<field name="issue" update="set">32</field>
<field name="year" update="set">2003</field>
<field name="title" update="set">Dark art defenses</field>
<field name="headline" update="set"/>
<field name="section" update="set">Comment</field>
<field name="pageno" update="set"/>
<field name="pagend" update="set"/>
<field name="comments" update="set">metadata added</field>
</doc>
[...]
<doc>
<field name="id">http://Pfad/2003/32/Preview.pdf</field>
<field name="issue" update="set">32</field>
<field name="year" update="set">2003</field>
<field name="title" update="set">Preview of the next issue</field>
[...]
</doc>
</add>
XML Request Handler
Dateien in diesem XML-Format verarbeitet Solr direkt über den passenden XML Request Handler. Dazu muss man neben einem neuen Job (»AddMeta LM_en«) lediglich zwei weitere MCF-Konnektoren definieren. Sie greifen einerseits auf das Dateisystem als Ablagedepot zu (Typ: Repository Connector) und füttern andererseits Solr über den passenden Update Handler (»/update«) mit den Informationen (Typ: Output Connector). Der Repository Connector definiert als Repository-Pfad das Verzeichnis »/var/datafari/metadata/lmen/«. Hierhin gehören die XML-Dateien, die für den User datafari lesbar sein müssen.
Der Trick besteht nun darin, die URL für das eindeutige Identifizieren des vorhandenen Dokuments und des zugehörigen Metadatensatzes (Attribut »id«) gleichermaßen zu verwenden. Solr bildet dann während der Indexaktualisierung ein Gesamtdokument mit den Informationen beider Teilkomponenten. Diese Aktualisierung auf Dokumentenebene heißt auch Atomic Update oder Partial Update [9].
Der Admin stößt sie an, indem er die XML-Datei mit besonderen Attributen (»update=”set”«) garniert. Im Endeffekt erhält das ursprüngliche Dokument aktualisierte Feldwerte für den Titel und die übrigen Metadaten. Die Metadaten generiert folgender Befehl:
$ upd_docs_lmen.sh URL-Jahresindex [<Host:Port>]
Das Argument »URL-Jahresindex« gibt die URL der Indexdatei des Jahrgangs an. Die Solr-Server-Adresse »Host:Port« ist optional, mit der lokalen Serveradresse als Standardvorgabe. Das Skript schreibt die Ausgabedatei in das aktuelle Verzeichnis, der MCF-Job arbeitet sie ab. Nach Jobende kennt Solr endlich auch die zusätzlichen Metadaten der frühen Linux-Magazine-Artikel im PDF-Format (Abbildung 2).
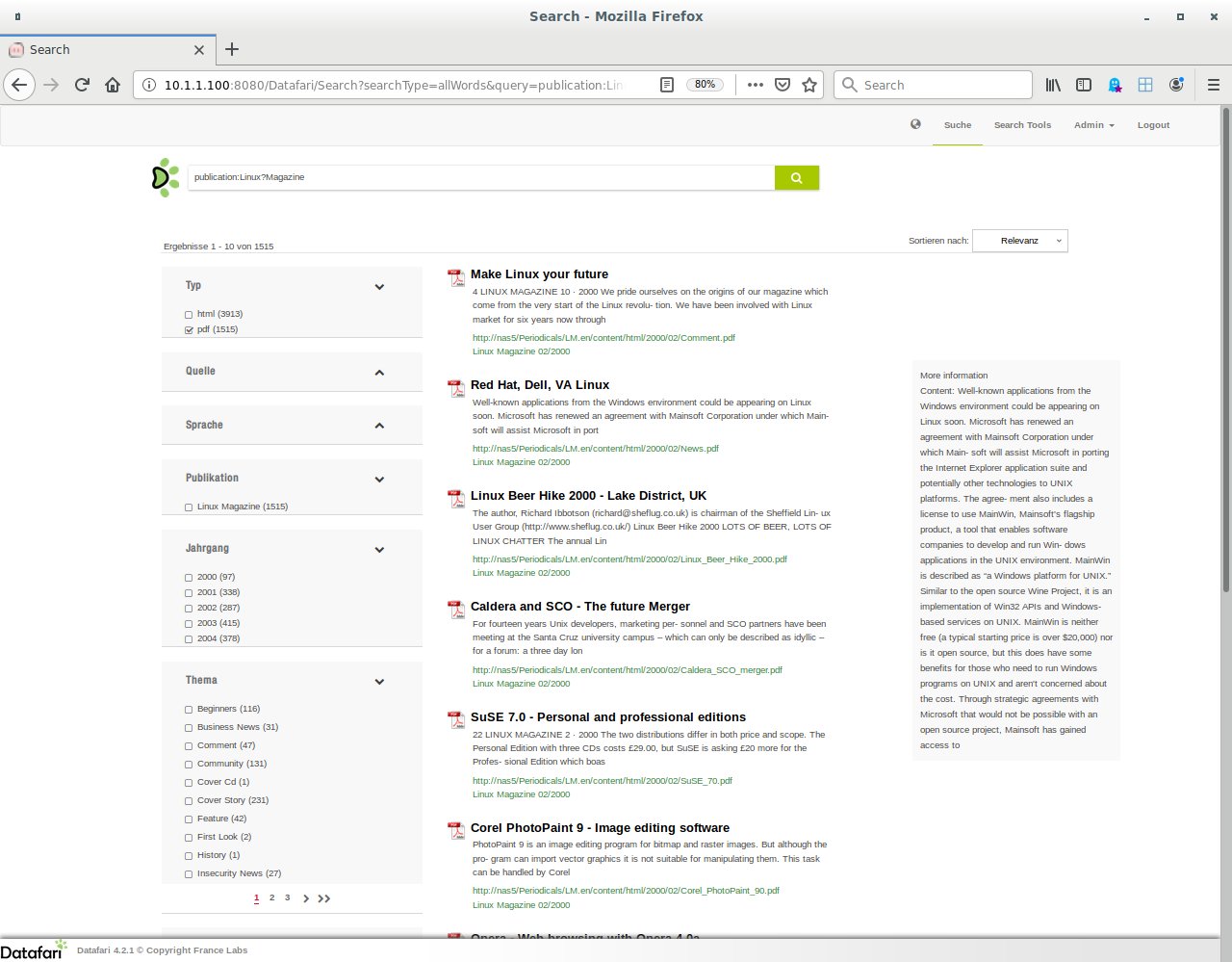
Abbildung 2: Dank eines Features namens Atomic Updates und über eine gemeinsame »id« führt Solr die Artikel im Linux Magazine mit zusätzlichen Metadaten zusammen.
Dank des Zugangs zum Solr Update Handler kann auch Curl die XML-Datei mit Solr-Anweisungen direkt ohne Umwege ausliefern. Das macht bei genauerer Betrachtung MCF für diese Art der Indexierung überflüssig: Das Skript nimmt für das Sammeln der Metadaten dieselben Wege durch die Indexdateien wie der eingebaute MCF-Webcrawler.
Außerdem hat die beschriebene Vorgehensweise auch den Nachteil, dass sie einen zweiten Indexierungslauf benötigt, um die Metadaten zu ergänzen. Der vierte Teil dieser Serie stellt dann eine Variante mit nur einem Durchlauf für Dokumententext und Metadaten vor, basierend auf dem Solr Data Import Handler.
Dicke Brocken
Die bisherigen Indexierungsmethoden würden allerdings bei PDFs mit mehreren Artikeln pro Datei durchfallen. Ein Einzelartikel mit der Fundstelle ließe sich innerhalb der fugenlosen Heftdatei nur finden, indem der Archivar noch eine umständliche untergeordnete Suche im Browser startet.
Der Betrachter erwartet aber mit Recht eine separate Präsentation passender Artikel und keine Anzeige der gesamten PDF-Datei. Daher muss die Indexierung auf Artikelgrenzen Rücksicht nehmen. Lägen die Artikel getrennt in einzelnen PDF-Dateien vor, wäre das Problem gelöst: Der Benutzer würde auf den Link eines Suchergebnisses klicken und der Browser nur den passenden Artikel anzeigen.
Die Forderung lässt sich für PDF-Dateien mit mehreren Artikeln pro Ausgabe nicht ohne Weiteres realisieren. Zum Glück bringen diese PDFs in den meisten Fällen Inhaltsverzeichnisse beziehungsweise Bookmarks mit. Mit etwas Zusatzaufwand und den geeigneten Tools ermittelt der Admin die Artikelgrenzen auf Basis der Seitenzahlen.
In der Regel besitzen die Inhaltsverzeichnisse drei Ebenen, wobei der Titel die letzte und der gliedernde Heftbereich (Hauptthema) die vorletzte belegen. Das Hauptthema (zum Beispiel “Grundlagen” oder “Programmierung”) eignet sich hervorragend als Facette für das Gruppieren der Suchergebnisse und damit als Navigationshilfe.
Das Shellskript »split_pdf.sh« ermittelt mit Awk und dem PDF-Toolkit Pdftk [10] Basisinformationen wie Publikation, Jahrgang, Ausgabe, Titel, Themenbereich und die Seiteninformationen, wie der Ausschnitt in Listing 5 zeigt. Der Admin stößt den gesamten Vorgang für eine PDF-Datei mit dem Argument »split_pdf.sh PDF-Datei« an.
Listing 5
Beispiel für extrahierte Informationen
lwde|003|2016|LinuxWelt|003|003|Editorial||000|Editorial lwde|003|2016|LinuxWelt|007|007|Grundlagen||000|Raspberry Pi 3 lwde|003|2016|LinuxWelt|008|009|Grundlagen||000|Linux-News lwde|003|2016|LinuxWelt|010|011|Grundlagen||000|Linux im Reagenzglas
Das Skript kennt die PDF-Strukturen verschiedener Verlage und berücksichtigt auch die eine oder andere im Laufe der Jahre eingeflossene Modifikation. Trotzdem ist beim Zerlegen des Inhaltsverzeichnisses Toleranz gefragt: Nur in den wenigsten Fällen hat das Verzeichnis die erhoffte Struktur und sind die Artikelverweise nach Seitenzahlen aufsteigend sortiert. Nur so lässt sich das Ende des Artikels, also seine letzte Seite, im Heft ermitteln. Es gilt also, vagabundierende Seitenverweise einzufangen, die bei der Heftgestaltung aus praktischen oder ästhetischen Gründen die fortlaufende Reihenfolge der Seitenzahlen unterbrechen. Zudem muss der Admin kompliziertere Strukturen mit mehreren Ebenen auf das einfache Modell aus Themenbereich und Artikelüberschrift abbilden.
Drei Hilfsskripte holen die PDFs vom Webserver. Dann startet die Teilungsprozedur, die die Jahresinhaltsverzeichnisse parst. Die Skripte eignen sich für die c’t, für die iX und für den Rest der Welt (»split_ct.sh«, »split_ix.sh«, »split_all.sh«). Die Skripte verweisen auf Indexdateien, der Admin muss sie aber noch an seine lokalen Gegebenheiten anpassen.
Eine behutsame Zusammenfassung der Themenbereiche ist wegen der Authentizität zwar fragwürdig, aber dennoch unerlässlich, weil sonst die reine Anzahl der Begriffe die sinnvolle Darstellung als Facette verhindern würde. Nebenbei versieht das Skript zum Beispiel »Tips« streng nach Duden mit einem modernen, zweiten »p« und bügelt grobe Schreibfehler aus. Das Ganze realisiert eine Kaskade von Awk-Aufrufen, wobei mehrere Skripte für das Zerlegen der Bookmark-Informationen, das Ermitteln von Artikeldaten inklusive Seitenzahlen und das Aufbereiten der Themenbereiche zuständig sind.
Splittergruppe
Mit den nun vorliegenden Seiteninformationen lässt sich die PDF-Datei mit der Cat-Funktion von Pdftk im Skript »split_pdf.sh« in einzelne Artikel zerlegen:
pdftk "$pdf" cat $pageno-$lastno output "$dst"
Das Skript legt die PDF-Schnipsel im aktuellen Verzeichnis ab. Die Argumente »pageno« und »lastno« geben die den Bookmarks entnommene beziehungsweise errechnete erste und letzte Seite des Artikels an.
Indem der Admin bestimmte Heftbestandteile filtert, bleiben das Heft-Cover und andere Kleinigkeiten, die keinen Text enthalten, außen vor. Wo nichts ist, kann Solr schließlich auch nichts finden. Danach liest Pdftk mit der Funktion »dump_data_utf8()« zunächst die vorhandenen Metadaten der vom Webserver geholten Ursprungsdatei, ergänzt sie via »update_info_utf8()« um die inzwischen hinzugewonnenen Metadaten und kombiniert sie mit dem neu entstandenen PDF des Artikels (Listing 6).
Listing 6
PDF-Metadaten
[...] printf 'InfoBegin\nInfoKey: Title\nInfoValue: %s\n' "$title" > metadata.txt printf 'InfoBegin\nInfoKey: Publication\nInfoValue: %s\n' "$publication" >> metadata.txt printf 'InfoBegin\nInfoKey: Issue\nInfoValue: %s\n' "$issue" >> metadata.txt [...] pdftk "$dst" dump_data_utf8 >> metadata.txt pdftk "$dst" update_info_utf8 ./metadata.txt output "$dst.upd" mv "$dst.upd" "$dst"
In der Praxis ist es üblich, mehrere kleine Artikel platzsparend auf einer Seite anzuordnen. Bislang setzte dieses Projekt stillschweigend voraus, dass Artikel an Seitengrenzen beginnen und enden. Auf der gleichen Seite befindliche Artikel lassen sich ärgerlicherweise nicht weiter separieren, aber zumindest durchnummerieren. Indem das Skript die Nummer im Dateinamen verwendet, existieren dann mehrere Dateikopien. Nach außen sieht das Ganze nach mehreren Artikeln aus, im Inneren befinden sich jedoch alle Artikel der fraglichen Seite.
Damit ist die Aufgabe auch schon erledigt. Der Admin kopiert die mit Metadaten gespickten Einzeldateien nur noch auf den Webserver, wo er sie dann für den MCF Crawler bei passender Seed-URL zugänglich macht. Für das Indexieren wartet je nach Magazin ein eigener MCF-Job auf den Einsatz.
Das schon vorgestellte Verfahren, die Metadaten nachträglich mit einem zweiten Indexierungslauf zu ergänzen, ist hier überflüssig: Der Admin musste die Artikeldatei wegen der Zerlegung ohnehin neu erstellen und konnte die Metadaten dabei gleich ergänzen. Zwei Jobs sammeln schließlich auch noch auf bekannte Weise die HTML-Ausgaben von c’t (1990 bis 2007) und iX (1994 bis 2007) ein (Abbildung 3). Die in diesem Teil eingeführten MCF-Jobs fasst Tabelle 1 zusammen.
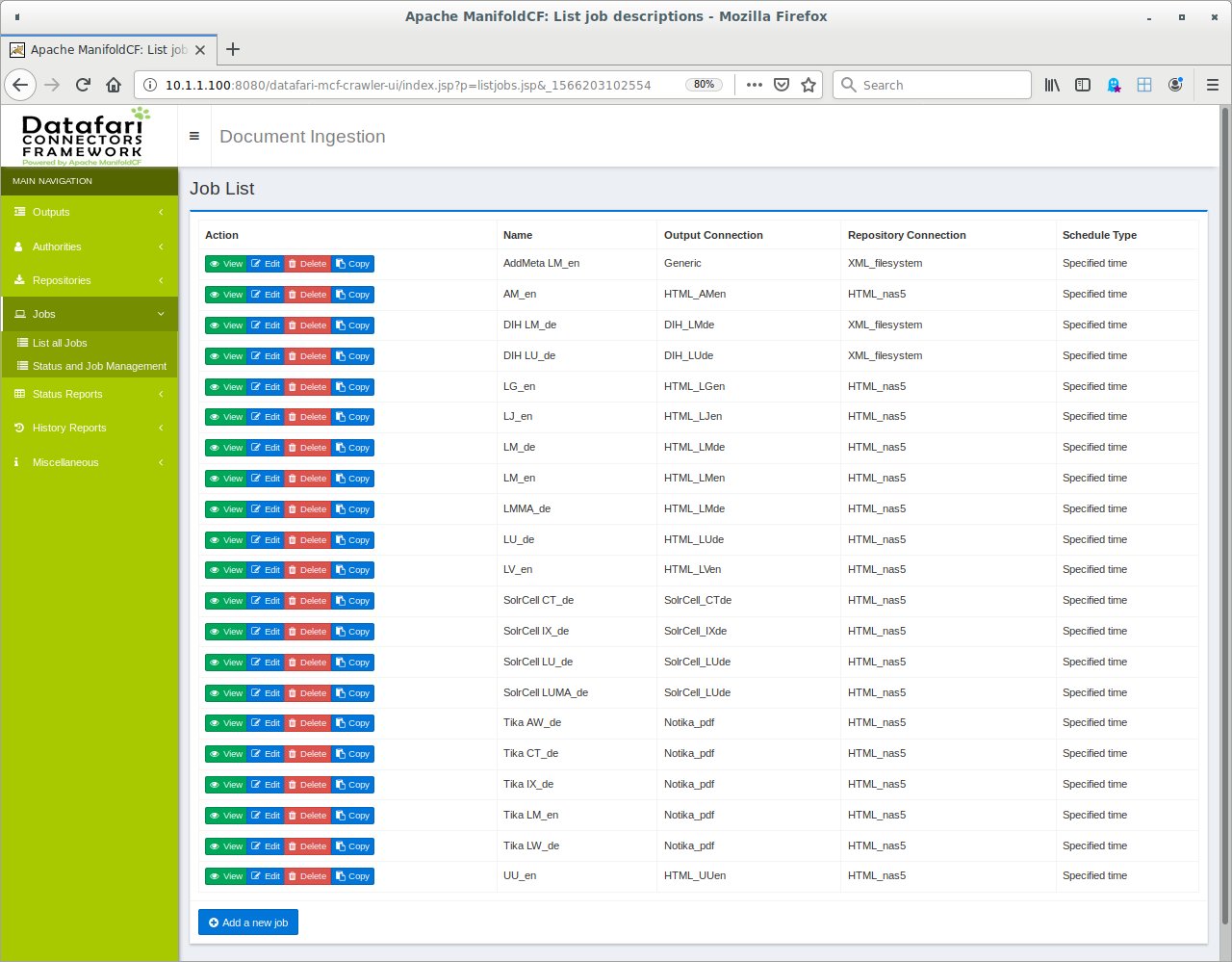
Abbildung 3: Die Job-Liste versammelt die Jobs für verschiedene Zeitschriften.
Fazit
Dieses Projekt will lediglich einige überschaubare Grundfunktionen zur Indexierung der Fachtexte vorstellen. Ausgefeilte Journalsysteme wie PKP [11] oder Open Journal Systems [12] sowie etablierte Bibliothekssysteme [13] und -kataloge [14] mit ihren standardisierten Schnittstellen bieten wesentlich mehr Komfort.
MCF und Solr fehlt jedoch eine einheitliche und modular zusammengesetzte Document Processing Pipeline. Der MCF Transformer oder die Solr Update Chain lösen zwar viele Aufgaben, allerdings überzeugt dieses Konzept nicht so recht: Die Update Chain wächst schnell zu einer unübersichtlichen XML-basierten Update-Wurst. Zudem sind die Strukturierungsmöglichkeiten beschränkt und die Transformationsregeln mit den Prozessorketten sehr geschwätzig.
Das Verfahren eignet sich jedoch grundsätzlich für zahlreiche Fachzeitschriften im PDF-Format mit durchsuchbaren Texten. Einzige Bedingung, um die Heftartikel einzeln darzustellen, ist die Existenz eines Inhaltsverzeichnisses in Form von Bookmarks. (kki)
Infos
- Datafari (Teil 1): Michael Brandenburg, “Suchtrupp”, LM 11/2019, S. 62, https://www.linux-magazin.de/43403
- Datafari (Teil 2): Michael Brandenburg, “Suchauftrag”, LM 12/2019, S. 64, https://www.linux-magazin.de/43520
- Datafari: https://www.datafari.com
- Apache Solr Reference Guide: https://lucene.apache.org/solr/guide/7_4/index.html
- Alle Dateien zum Artikel: http://www.linux-magazin.de/static/listings/magazin/2020/01/datafari/
- Manifold CF: https://manifoldcf.apache.org
- Xidel: http://www.videlibri.de/xidel.html
- Datafari-Wiki: https://datafari.atlassian.net/wiki/spaces/DATAFARI/overview
- Solr Partial Update: https://lucene.apache.org/solr/guide/7_4/updating-parts-of-documents.html
- PDF Toolkit: https://www.pdflabs.com/tools/pdftk-the-pdf-toolkit
- Public Knowledge Project: https://pkp.sfu.ca
- Open Journal Systems: https://de.wikipedia.org/wiki/Open_Journal_Systems
- Bibliothekssysteme: https://de.wikipedia.org/wiki/Bibliothekssystem
- Bibliothekskataloge: https://de.wikipedia.org/wiki/Bibliothekskatalog





