
© Elnur Amikishiyev, 123RF
Geht einem Linux-System der Arbeitsspeicher aus, eilt ihm ein spezieller Agent zu Hilfe, der Out-of-Memory-Killer. Facebook stellt nun einen eigenen OOM-Killer vor. Was macht der anders als sein Kollege im Kernel? Und wie funktioniert ein OOM-Killer eigentlich überhaupt?
Wer schon länger keinen großen Server mehr bestellt hat, reibt sich vermutlich verwundert die Augen, wenn er dieser Tage ein neues Gerät bestellt: Konfigurationen mit Terabytes statt Gigabytes RAM sind völlig problemlos zu bekommen und bedingen auch nicht mehr unbedingt einen vorherigen Sechser im Lotto. Vorbei die Zeiten, in denen man stolz auf jedes einzelne Gigabyte war (Abbildung 1). Heute haben viele Admins den RAM gar nicht mehr als möglicherweise limitierenden Faktor im Kopf.

Abbildung 1: RAM gehört nicht mehr unbedingt zu den allerknappsten Ressourcen im Server, doch kein System ist davor gefeit, in eine Out-of-Memory-Situation zu geraten.
Das ist freilich eine etwas zu optimistische Darstellung, denn auch auf modernen Systemen kommt es durchaus vor, dass nicht genügend RAM für anstehende Aufgaben verfügbar ist. Was im schlimmsten Fall dramatische Konsequenzen hat: Braucht eine Komponente wie Systemd RAM und kann ihn nicht allozieren, funktioniert das System falsch oder gar nicht mehr. Damit RAM-Mangel Rechner nicht in die Knie zwingt, hat der Linux-Kernel einen Wachhund eigens für diese Aufgabe an Bord, nämlich den Out-of-Memory-Killer, kurz OOM-Killer. Der soll im Notfall durch das gezielte Abschießen von Prozessen Speicher freigeben, der dann anderen, vermeintlich oder tatsächlich wichtigeren Zwecken zur Verfügung steht.
Viele Legenden und Horrorgeschichten ranken sich um den OOM-Killer, und bei Admins hält sich die Freude meist in engen Grenzen, wenn sie im Log an den Kernelmeldungen sehen, dass er zugeschlagen hat (Abbildung 2). Denn gerade große Anwendungen sind es, die ihm zum Opfer fallen, also etwa Java.

Abbildung 2: Der OOM-Killer im Linux-Kernel schießt wahlweise einzelne Prozesse ab oder schickt den Server in einen Reboot, wenn der Kernel so konfiguriert ist.
Java steht von Haus aus nicht unter dem Verdacht, sehr sparsam mit Ressourcen umzugehen – betreibt in aller Regel aber eben auch die Applikation, derentwegen der Server überhaupt existiert. Schießt der OOM-Killer auf einem Tomcat-System Java ab, fängt ein Load Balancer das Problem zwar üblicherweise ab, doch fehlt der so aus dem Rennen genommene Server am Ende trotzdem.
Dieser Artikel stellt die aktuelle OOM-Implementierung in Linux vor und erklärt, wie sie funktioniert. Anschließend vergleicht er den von Facebook gewählten Ansatz mit der OOM-Variante im Kernel und beschreibt, worin die Gemeinsamkeiten und Unterschiede liegen.
Wie es zu OOM-Situationen kommt
Selbst Server mit riesigen Mengen RAM können in Situationen geraten, in denen der verfügbare Arbeitsspeicher des Systems nicht ausreicht. Das liegt daran, dass der Linux-Kernel bestimmte Mittel und Wege nutzt, um die Zuweisung von Arbeitsspeicher möglichst effizient zu erledigen. Wer schon mal Top aufgerufen und sich dort die RAM-Statistiken angeschaut hat, der weiß: Selbst auf Systemen mit sehr viel RAM und wenig Last ist die Anzeige für genutzten RAM oft nahe der 100-Prozent-Grenze, und das selbst dann, wenn das System nichts zu tun hat (Abbildung 3).

Abbildung 3: Selbst auf Systemen, auf denen viel RAM und wenig Last vorhanden sind, sieht es oft so aus, als sei der gesamte RAM zugewiesen – das liegt am Memory Paging des Kernels.
Der Linux-Kernel ist die Schnittstelle zwischen der Hardware auf der einen und den Programmen auf der anderen Seite. Möchte ein Programm Speicher, fragt es dafür mittels eines Systemaufrufs (Syscall) wie »malloc()« beim Kernel nach. Es dauert jedoch zu lange, wenn der Kernel nun erst freien Arbeitsspeicher suchen und ihn dann in der beantragten Menge zur Verfügung stellen würde.
Stattdessen handelt der Kernel vorauseilend: Den gesamten verfügbaren Speicher teilt er in Segmente auf, die Memory Pages. Zudem merkt der Kernel sich, welche Pages den laufenden Programmen schon zugewiesen und welche im Umkehrschluss noch verfügbar sind. Kommt nun ein Programm und beansprucht RAM, weist der Kernel ihm einfach eine Memory Page aus der Liste der freien Pages zu. Weil die Memory Pages nicht alle gleich groß sind, hat der Kernel hier auch eine gewisse Flexibilität und kann dafür sorgen, dass nicht zu viel Verschnitt entsteht.
Verschnitt ist schlecht
Denn eben jenen Verschnitt gilt es so gut wie möglich zu vermeiden. Selbst wer beliebig viel RAM sein Eigen nennt, möchte ihn möglichst gut und effizient nutzen. Der Linux-Kernel unterstützt deshalb seit vielen Jahren eine Funktion, die für viele Sysadmins dem Öffnen der sprichwörtlichen Büchse der Pandora gleichkommt – das Überbuchen von RAM.
Grob funktioniert das so: Der Kernel weist anfragenden Programmen wie gehabt Memory Pages zu, in Summe aber mehr, als durch den physisch vorhandenen Arbeitsspeicher eigentlich verfügbar wären. Das erzeugt zwar nicht direkt OOM-Probleme, denn verursacht werden die ja bekanntlich durch Programme, die zu viel RAM anfordern.
Allerdings vergrößert das RAM-Overcommitment die Gefahr von OOM-Situationen, weil der Kernel etwaige Schwierigkeiten im Vorfeld nicht rigoros abfängt. Ließe Linux es gar nicht erst zu, dass Anwendungen in Summe mehr Speicher allozieren als tatsächlich vorhanden, wäre ein Absturz aus Speichermangel gar nicht denkbar. Denn dann würden Anwendungen ganz einfach eine Fehlermeldung erhalten, wenn sie versuchen, mehr Speicher als verfügbar für sich zu beanspruchen.
Der Linux-Ansatz ist anders. Der Kernel spekuliert quasi darauf, dass zugewiesener Speicher nie vollständig genutzt wird. Die Sysctl-Variable »vm.overcommit_memory=« regelt alles Weitere: Steht sie auf »0«, was übrigens dem Standardwert entspricht, kalkuliert der Kernel auf Basis eines heuristischen Ansatzes, wie viel RAM tatsächlich frei ist. Das setzt er dann in Relation zum Speicher, den eine anfragende Applikation haben will. Fällt die Kalkulation positiv aus, bekommt das Programm den Speicher, auch wenn die Menge des zugewiesenen Speichers dadurch größer wird als die tatsächlich im System vorhandene.
Noch radikaler geht der Kernel bei »vm.overcommit_memory=1« zu Werke: Hier überspringt der Kernel die heuristische Analyse und bescheidet jeden Request für RAM positiv. Setzt man den Wert hingegen auf »2«, schaltet das die Überbuchung des RAM ab.
Was wirklich hilft
Wer auf Basis der bisherigen Erklärungen allerdings glaubt, dass es genügt, die RAM-Überbuchung zu deaktivieren, der irrt sich. Die OOM-Problematik entsteht ja gerade nicht durch das Überbuchen des RAM, sondern durch Programme, die kontinuierlich zu viel RAM allozieren wollen. Und leider tun sie das in aller Regel unvorhersagbar und aus verschiedenen Gründen. Häufig ist des Übels Wurzel schlicht ein Programmierfehler, der dazu führt, dass das betroffene Programm RAM im Übermaß beansprucht. Gelegentlich kommt es tatsächlich vor, dass ein System für die Bearbeitung der eingehenden Anfragen mehr RAM braucht als zur Verfügung steht. Java & Co. lassen grüßen.
Wer sich mit OOM-Situationen konfrontiert sieht, sollte also zunächst sehr sorgfältig versuchen, die Ursache ausfindig zu machen. Beruht der Notstand nicht auf einem Programmierfehler und treten die OOM-Situationen regelmäßig und reproduzierbar auf, kann die Lösung langfristig nur “mehr Hardware” lauten. Das kann bedeuten, in die betroffenen Server mehr RAM zu stecken oder das Setup in die Breite zu skalieren.
Wer es hingegen mit einem Programmierfehler zu tun hat, tut gut daran, ihn zu finden und gegebenenfalls im Tandem mit den Entwicklern zu reparieren. Die Fehlersuche in solchen Fällen kann zäh und langwierig sein. Wenn aber OOM-Probleme nach einem Update verstärkt auftreten, wo vorher keine waren, ist ein Bug höchstwahrscheinlich der Auslöser.
Der missliebige OOM-Killer
Der OOM-Killer des Kernels ist in jedem Fall eine Hilfskonstruktion. Er erfüllt allerdings eine wichtige Aufgabe, wenn es das primäre Ziel ist, den Absturz des Systems zu verhindern: Er sorgt im Falle eines Falles dafür, dass Programme sterben, die andernfalls das System durch die Über-Allokation von RAM mit hoher Wahrscheinlichkeit zum Absturz brächten. Vereinfacht gesagt ist die Aufgabe des OOM-Killers also, dem Admin etwas Zeit zu verschaffen, um sich im Detail mit dem eigentlichen Problem zu befassen, ohne dass ihm gleich seine gesamte Umgebung um die Ohren fliegt.
Als Krückenkonstrukt dieser Art funktioniert der Kernel-interne OOM-Killer jedoch mehr schlecht als recht – glaubt man Facebook. Um die Kritik zu verstehen, die im Valley an der Kernel-Lösung erklingt, lohnt sich zuerst ein Blick auf die Funktionsweise des aktuellen OOM-Killers in Linux und seine Geschichte.
Holistik statt Heuristik
Die Art und Weise, wie der OOM-Killer seine potenziellen Opfer aus dem laufenden System heraus identifiziert, hat sich in den vergangenen Jahren stark verändert. Die erste OOM-Implementation in Linux, die viele Jahre in Verwendung war, basierte im Wesentlichen auf Heuristik: Anhand vieler Parameter versuchte der Kernel herauszufinden, welche Programme wichtig für die Bereitstellung der elementaren Funktionen sind und welche auch mal den Weg in die ewigen Jagdgründe antreten dürfen.
Die Funktion, die dafür in der Speicherverwaltung des Kernels verantwortlich ist, heißt bis heute passenderweise »badness()« – sie berechnet, welcher Prozess des laufenden Systems die höchste Bösartigkeit hat, und erstellt so eine Liste in absteigender Reihenfolge.
Sonderlich gut nachvollziehbar war die genutzte Heuristik allerdings nicht, und so war es Google in Person von David Rientjes, das 2010 eine völlig neue Implementation des OOM-Killers in Linux etablierte. Die Funktion, die sich um das Identifizieren der problematischen Prozesse kümmert, heißt zwar nach wie vor Badness, darüber hinaus ist aber nicht viel gleich geblieben.
Denn Badness verfolgt nun einen eher einfachen Ansatz: Es interessiert sich beinahe ausschließlich für den Speicherverbrauch einzelner Prozesse, wirft alle Prozesse des Systems in eine Waagschale und stellt dann die Frage, wie es durch das Abschalten möglichst weniger Prozesse möglichst viel Speicher wieder verfügbar macht.
Für jeden Prozess berechnet der Kernel dabei den OOM-Score, der übrigens über das »/proc«-Dateisystem auch per »cat« auslesbar ist (»/proc/PID/oom_score«). Ergibt sich eine OOM-Situation, beginnt der OOM-Killer damit, der Reihe nach die Prozesse mit den höchsten OOM-Punktwerten zu beenden.
Wie genau sich der OOM-Score berechnet, ist seit den Patches von David Rientjes deutlich leichter zu beantworten als zuvor: Der Kernel bewertet pro Prozess, wie viel Speicher dieser wirklich nutzt. Speicher definiert sich dabei aus der Summe des Arbeitsspeichers und des Swap-Speichers, wobei letzterer gerade auf modernen Systemen ja immer seltener anzutreffen ist. Die Faustregel ist: Je mehr Speicher ein Prozess im Augenblick der OOM-Bewertung nutzt, desto höher rutscht er auf der Abschussliste.
Ausnahmen bestätigen die Regel
Wobei David Rientjes ein paar Ausnahmen eingebaut hat, um lästige Effekte zu vermeiden. Grundsätzlich zieht der Kernel bei Prozessen von Root vom OOM-Score immer 30 Punkte ab, weil die Prozesse des Systemadministrators potenziell wichtiger sind als die im Userspace. Hinzu kommt, dass der Admin auch selbst auf den Punktwert Einfluss nehmen kann: Für diesen Zweck existiert im »/proc«-Dateisystem das File »oom_score_adj«, über das sich der Wert pro Prozess anpassen lässt. Werte von -1000 bis +1000 sind möglich.
Gibt der Admin einem Prozess »-1000«, wird der OOM-Killer diesen Prozess nicht beenden. Setzt er den Wert hingegen auf »+1000«, malt er dem Prozess ein großes Zielkreuz auf den Bauch und es steigt die Wahrscheinlichkeit, dass eben jener Prozess als Erster einen OOM-Tod stirbt.
Facebook regt sich auf
Verglichen mit der scheinbaren Magie, mit der die »badness()«-Funktion bis 2010 noch zu Werke ging, wirkt die aktuelle OOM-Implementierung leicht verständlich und sinnvoll konzipiert. Das sehen aber nicht alle Unternehmen so, die Linux in großem Maßstab einsetzen.
Ein sehr prominenter Kritiker der aktuellen OOM-Implementation ist Facebook: Das Unternehmen setzt in seinen Rechenzentren bekanntermaßen auf das freie Betriebssystem, wenn auch in stark modifizierter Form. Eine Komponente des Vanilla-Kernels, der es nun im Hause Facebook an den Kragen ging, ist der OOM-Killer, denn mit dem waren die Zuckerberg-Angestellten offensichtlich überhaupt nicht einverstanden.
Ihre Probleme mit dem Kernel-eigenen OOM-Killer fassen die Entwickler im Netz zusammen: Der OOM-Killer reagiere unberechenbar. Die Möglichkeiten, auf seine Funktion Einfluss zu nehmen, seien zu stark beschränkt und die Konfigurationsoptionen in Summe auch unzureichend. Weil der OOM-Killer im Kernel residiere, sei er zudem ausgesprochen träge: Zwischen dem Moment, in dem der Kernel bemerkt, dass es möglicherweise ein Speicherproblem gibt, und dem Moment, in dem er zu Werke geht und Speicher freigibt, vergehe gerne mal eine ganze Weile (Abbildung 4).
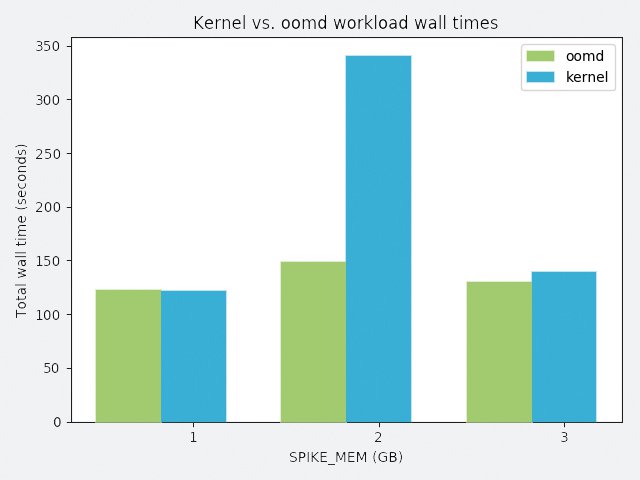
Abbildung 4: Zeitersparnis ohne Ende: Während der OOM-Killer ein System beim OOM-Szenario für fast sechs Minuten im Würgegriff hält, braucht der OOMd nur knapp drei Minuten.
Denn der Kernel tötet die Prozesse nacheinander, bewertet die Situation neu, muss zwischenzeitlich auch den Pagecache leerräumen und schaut erst danach den nächsten Prozess an – das Spiel beginnt so lange immer wieder von vorn, bis das System stabil läuft.
Im schlimmsten Falle komme es zu Livelock-Situationen von mehr als 30 Minuten, so Facebook. Zur Erinnerung: Als Deadlock bezeichnen Informatiker üblicherweise eine Situation, in der alle Komponenten eines Systems auf eine andere Komponente desselben Systems warten. Livelocks funktionieren ebenso, allerdings verändern sich die Rollen der wartenden Komponenten zueinander in regelmäßigen Abständen. Wartet also in einem Augenblick der Kernel darauf, dass die Überreste eines Programms aus dem Pagecache verschwinden, wartet er im nächsten Moment vielleicht wieder auf die OOM-Score-Kalkulation für einen bestimmten Prozess.
Aus Facebook-Sicht ist der Unmut indes nachvollziehbar: Während der 30 Minuten, die eine solche Situation angeblich verschlingt, ist das System praktisch nicht benutzbar. Lediglich ein harter Reboot wäre eine probate Maßnahme, aber genau das ist ja eigentlich zu verhindern.
OOM als holistische Maßnahme
Der OOMd [1], den Facebook im August 2018 vorgestellt hat, schneidet alte Zöpfe ab und geht für manchen Sysadmin sicherlich sehr forsch an das Thema OOM heran. Der größte Unterschied zur vorhandenen OOM-Implementation in Linux ist wohl die Tatsache, dass Facebooks OOM-Killer nicht im Kernelspace läuft, sondern als normale Applikation im Userspace. OOMd ist damit ein echtes Novum, denn bisher war OOM unangefochtene Kernel-Domäne.
Große technische Nachteile entstehen dem OOMd dadurch allerdings nicht – letztlich kann er, wenn er mit den Rechten des Sysadmin läuft, einen Prozess einfach per »SIGKILL« töten. Etwas großartig anderes tut der OOM-Killer im Kernel am Ende auch nicht.
Im Gegenzug liegen die Vorteile der Userspace-Implementierung klar auf der Hand: Insbesondere ist OOMd deutlich flexibler, als die Kernel-Implementierung es jemals sein könnte. Wie funktioniert das Konstrukt allerdings im Detail?
Ganz ohne Kernel geht es doch nicht
Wer nach der Lektüre dieses Artikels den OOMd gleich ausprobieren möchte, der sei gewarnt: Ganz ohne Kernel geht es auch hier nicht. Zwar liegen beim OOMd nicht Funktionen des Killers selbst im Kernel. Stattdessen ist der OOMd im Userspace aber darauf angewiesen, vom Betriebssystemkernel möglichst viele möglichst genaue Informationen über den aktuellen Zustand des Systems zu erhalten. Eine geeignete Schnittstelle gibt es mit Linux-PSI [2] bereits, doch steckt dieses Framework noch nicht im Kernel. Wer OOMd nutzen möchte, muss sich PSI also selbst in den Kernel holen – was als Modul aber kein Problem ist.
Stets auf der Hut
Modular geht es auch beim OOMd selbst zu. Neben PSI setzt der Dienst unter der Haube auf die Cgroupsv2, die eine im Kernel verankerte Funktion für die Begrenzung und Zuweisung von Ressourcen und Berechtigungen darstellen. Doch erzwingt der OOMd nicht die Umsetzung von Cgroups, sondern er nutzt Cgroupsv2 nur als eine zweite Datenquelle für sein eigenes Monitoring des Systems mit Fokus auf den RAM.
Das setzt freilich voraus, dass der Admin Cgroups einsetzt und auch nutzt. Wer auf seinen Systemen bisher Cgroups nicht verwendet, fällt effektiv also auf PSI als einzige Datenquelle zurück. Freilich darf man bei Facebook davon ausgehen, dass neue Systeme vollständig automatisch provisioniert werden und im Rahmen dessen gleich auch die passende Cgroups-Konfiguration abbekommen. Das nachträgliche Einführen von Cgroups ist komplexer, sollte dem Admin aber im Falle eines Falles die Mühe wert sein, wenn er OOMd nutzen möchte.
Das oberste Funktionsprinzip von OOMd ist, dass Vorsicht viel besser als Nachsicht ist. Deshalb spielt das Thema Monitoring eine große Rolle: Anders als die Kernel-Implementation des Memory-Killers soll der OOMd schon aktiv werden, bevor eine systemweite OOM-Situation eintritt. Dafür scannt der Dienst kontinuierlich seine Hauptdatenquellen – Cgroups und PSI – und legt im Falle eines Falles selbsttätig Hand an, bevor eine echte Out-of-Memory-Situation überhaupt zustande kommt – also der Fall eintritt, bei dem ein »malloc()«-Aufruf nicht mehr erfolgreich ist.
Weil der OOMd im Userspace und nicht im Kernelspace beheimatet ist, profitiert er von einer deutlich größeren Flexibilität, besonders mit Blick auf Erweiterungen. Da verwundert es nicht, dass Facebook dem OOMd gleich eine Plugin-Schnittstelle spendiert, über die sich externe Funktionalität nachladen lässt. Die Plugins sind unmittelbar in die Arbeitsabläufe des OOMd eingebunden – das einzige Plugin, das dem OOMd ab Werk beiliegt, ist allerdings jenes für das Töten von Prozessen. Denkbar sind hier aber viele Optionen, etwa auch, dass sich vor dem Töten eines Prozesses verschiedene andere Arbeitsschritte auf einem System durchführen lassen.
Simple Konfiguration
Der OOMd ist in der Sprache C++ verfasst und nutzt als Format seiner Konfiguration die Json-Notation. Das Ergebnis ist sehr übersichtlich: Per Cgroups-Direktive sind verschiedene Vorgehensweisen für einzelne Cgroups definierbar, wobei »target« die Zielgruppe angibt, auf die sich der jeweilige Eintrag bezieht. Die übrigen Einträge pro Cgroup-Direktive legen unter anderem fest, welche Handler und Aktionen bei OOM-Events zur Anwendung kommen. Die Abbildung 5 enthält ein entsprechendes Beispiel, das recht deutlich macht, wie flexibel OOMd in der Praxis ist.
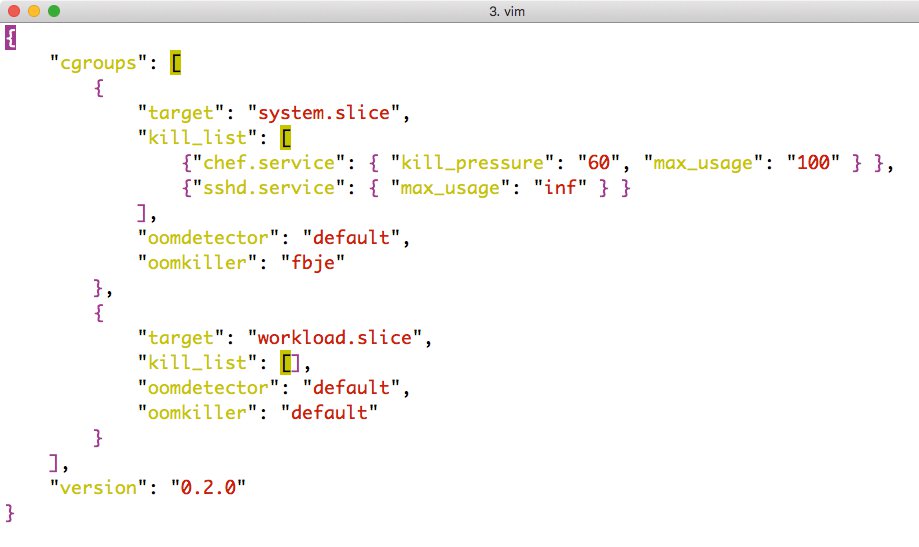
Abbildung 5: Die Konfigurationsdatei von OOMd ist übersichtlich und bietet im Json-Format Hebel und Schalter für alle wichtigen Parameter.
Das Beispiel legt fest, dass beim Eintreten einer OOM-Situation zunächst der Dienst »chef« beendet werden soll, falls dieser mehr als 60 Prozent der gesamten RAM-Last ausmacht oder mehr als 100 MByte RAM für sich alleine alloziert hat. Dem Daemon SSHd sprechen die Entwickler hingegen eine Überlebensgarantie aus, der Eintrag »max_usage: inf« legt fest, dass OOMd den Dienst niemals und unter überhaupt keinen Umständen abschießen darf.
Das ist auch ausgesprochen sinnvoll, denn ohne SSHd bliebe für den Remote-Login nur noch eine VNC- oder KVM-Konsole, und im Falle des Kernel-OOM ist es durchaus denkbar, dass der SSH-Daemon als einer der Speichernutzer in die Schusslinie gerät. Wer OOMd verwendet, kann das hingegen völlig ausschließen.
Die Facebook-Entwickler sparen übrigens nicht mit Lob für ihre eigene Lösung. In der Dokumentation auf Gitlab halten sie fest, dass der neue OOMd die zuvor beschriebenen Livelock-Situationen mit ihren Wartezeiten von bis zu 30 Minuten und mehr komplett eliminiert haben soll.
Fazit
In die OOM-Debatte bringt Facebook mit seiner Lösung dringend benötigten sowie wohltuend frischen Wind: Klar wird jetzt immerhin, dass OOM keine Aufgabe ist, die unter allen Umständen der Kernel erledigen muss. Und klar ist auch, dass sich im Userspace Funktionalität und Flexibilität erreichen lassen, die im Kernelspace undenkbar wären. Der von Facebook veröffentlichte OOM-Killer für den Userspace ist insofern interessant und erlebt hoffentlich noch eine rasante Entwicklung.
Denn die ist notwendig: Aktuell beschränkt sich die Funktionalität des OOMd auf wenig mehr als das, was der im Kernel existierende OOM-Killer auch kann. Trotzdem erklärt Facebook, dass das Werkzeug im Alltag deutlich besser funktioniert als die ursprüngliche Linux-Lösung. Kaum absehbar ist daher, was passiert, wenn der OOMd eine größere Fangemeinde bekommt und für die gängigen Distributionen in paketierter Form einfach verfügbar ist. Sehr gut möglich, dass Facebook hier ein echter Coup gelungen ist. Sicher ist: Der aktuelle Stand der Dinge in Sachen Auftragskiller macht Lust auf mehr.
Infos





