
Ein Jahr nach Version 3.4 erscheint GCC 4.0 mit einer neuen internen Struktur, die künftige Verbesserungen vorbereitet, aber jetzt schon Ergebnisse zeigt: Der Compiler vektorisiert C-Code automatisch und übersetzt C++-Programme schneller als sein Vorgänger.
Lange erwartet – jetzt ist es endlich so weit: Die GNU Compiler Collection [1] bricht in eine neue Ära auf und liegt nun in Version 4.0 vor. Wichtigstes neues Feature ist zweifellos die Optimierungsinfrastruktur der Static Single Assignment Trees (Tree-SSA, [2]). Dieses Modell zur internen Code-Repräsentation hat den Aufbau der GCC stark beeinflusst. Deshalb entschlossen sich die Entwickler, dies auch in der Version auszudrücken, und sprangen gleich zur 4.0, ursprünglich war die Release noch als 3.5 geplant. Eine Übersicht der Änderungen gibt das Changes-Dokument [3].
Einfachere Struktur durch Single Assignments
Frühere GCC-Versionen wandten die Optimierungsschritte hauptsächlich auf die interne Abstraktion der Maschinensprache an, also auf die RTL-Repräsentation (Register Transfer Language), eine Zwischenstufe der Kompilierung. Allerdings sind zu diesem Übersetzungszeitpunkt schon viele Informationen der Hochsprache verloren. In der aktuellen GCC-Version stehen sie durch die Tree-SSA-Darstellung für die Optimierung zur Verfügung. Dazu baut der Compiler intern einen Graphen auf, dessen Knoten nur eine einzige Zuweisung enthalten (Single Assignment). So entsteht aus »a = b + c – d« Compiler-intern:
tmp = b + c a = tmp - d
Dadurch werden die Ausdrücke einfacher und sind algorithmisch besser zu verarbeiten. Da die Tree-SSA-Repräsentation wesentlich mehr Informationen enthält als die RTL-Variante vorheriger Versionen, können die GCC-Entwickler damit neue, moderne Optimierungstechniken implementieren.
Einige der Optimierungen in 4.0 setzen direkt auf der SSA-Ebene an. Erst dadurch wurde die Vektorisierung von Schleifen möglich (siehe Kasten “Automatische Vektorisierung”). Vor allem C++-Programmen soll der Compiler damit in Zukunft deutlich beschleunigen. GCC 4.0 bildet in erster Linie die Basis für künftige Verbesserungen, die in Version 4.1 folgen sollen.
Parallel rechnen
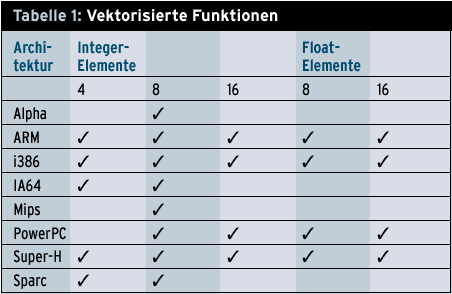
Unter Vektorisierung ist bei der GCC die Verwendung der SIMD-Instruktionen (Single Instruction Multiple Data) moderner CPUs zu verstehen. In der x86-Welt sind dies MMX [4], 3DNow [5] und SSE [6] mit den Revisionen 2 und 3 [7]. Jenseits des Mainstream finden sich bei PowerPC der Altivec-Mechanismus [8] und bei Sparc-Prozessoren das Sun-eigene VIS (Visual Instruction Set) [9]. Auch bei den ARM- [10] und Super-H-Prozessoren [11] sind solche Befehle zu finden, die teilweise sogar schon von der GCC-Version 4.0 genutzt werden.
Welche Arten für die jeweilige Architektur implementiert sind, zeigt Tabelle 1. Die einzelnen Spalten geben an, welche Vektoroperationen für wie viele Elemente (4 bis 16) eines Typs (Integer oder Float) realisiert sind.
Als weitere Neuerung integriert GCC 4.0 das Frontend für die Sprache Fortran 95, die das etwas angegraute Fortran 77 ablöst. Im wissenschaftlichen Bereich ist Fortran noch häufig im Einsatz, auch die Spec-Benchmarks enthalten einige Fortran-95-Tests, die GCC bisher nicht übersetzen konnte.
Nicht mehr in die neue Release 4.0 hat es der Dialekt Objective-C++ geschafft. Dabei handelt es sich um eine Mischung von C++ mit dem von Apple verwendeten Objective-C.
Für C++-Entwickler dürfte interessant sein, dass der neue Compiler ohne Optimierungen (»-O0«) deutlich schneller arbeitet als alle vorherigen Versionen. Das kann den Editier-Compile-Zyklus deutlich beschleunigen, dessen Dauer die C++-Entwicklung mit der GCC bisher eher mühsam gestaltete.
Die C++-Bibliothek bringt auch schon einige Features aus der kommenden Überarbeitung des C++-Standards mit. Der Namensbereich »TR1« enthält bereits »hashtable«, »tuple«, »type_traits«, »shared_ptr« und einiges mehr. Entwickler können sich so mit den Erweiterungen beschäftigen, bevor sie im nächsten C++-Standard erscheinen.
Das Debugging erleichtern die neuen Location Lists, die der neue GCC-Compiler in die Objektdateien einfügen kann. Diese führen über den Ort der verwendeten Variablen Buch und helfen damit dem GNU-Debugger dabei, auch bei optimiertem Code die passende Zeile im Quellcode wiederzufinden. Bisher war das nicht möglich, sodass man zum Debuggen weniger optimierten Code generieren musste,siehe [12]. Abschalten lässt sich dieses Verhalten mit dem Parameter »-no-var-tracking«.
Schneller bei C++
Die neue GCC-Version hilft die Startzeit von Programmen zu reduzieren: Sie markiert beim ELF-Bibliotheksformat [13] Funktionen, die sie in den Aufrufer einbetten (inlinen) kann, als unsichtbar. Damit wandern die entsprechenden Funktionssymbole nicht in das ausführbare Binary. Der Schalter »-fvisibility-inlines-hidden« aktiviert dieses Verhalten. Bei modernem C++-Code entfernt der Compiler ungefähr 40 Prozent der Symbole und verkleinert Programme damit um bis zu zehn Prozent. So muss der dynamische Linker beim Laden des Programms deutlich weniger Symbole relokieren, was den Start spürbar beschleunigt. In Form von Attributen und weiteren Optionen erlaubt die GCC dem Programmierer dabei weitgehende Kontrolle über die Sichtbarkeit [14].
Ähnlich arbeitet auch »–as-needed«, eine neue Option des GNU-Linkers aus dem Binutils-Pakets. Sie bewirkt, dass der Linker nicht alle auf der Kommandozeile übergebenen Bibliotheken in den ELF-Header einträgt, sondern lediglich die durch referenzierte Symbole direkt verwendeten.
Das reduziert zwar die Anzahl direkt verwendeter Bibliotheken, beispielsweise von Gnome- und KDE-Programmen. Ein eindeutiger Performance-Unterschied war im Test aber nicht festzustellen – vermutlich weil das Programm beim Start auch alle indirekten Bibliotheken laden muss. Beim Aufruf von »gcc« zum Linken lautet die entsprechende Option »-Wl,–as-needed«.
Beim so genannten Scalar Replacement of Aggregates teilt der Compiler komplexe Objekte wie Structs oder Unions, deren Adresse noch nicht verwendet wurde, in kleine Stücke auf. Das spart Speicherzugriffe, denn im Optimalfall lassen sich die Daten auf die Prozessorregister verteilen.
|
Automatische |
|---|
|
Für die Vektorisierung mittels SIMD-Instruktionen kommen Schleifen in Frage, die in einer Iteration auf mehrere Elemente zugreifen oder nach Loop Unrolling zugreifen könnten. Einzelne Elemente der Berechnung dürfen dabei nicht voneinander abhängen. Die folgenden Beispiele zeigen nur den generierten Assembler-Code der Schleife. Die Vektoroperationen sind durch Großbuchstaben hervorgehoben und teils kommentiert. Das einfachste Beispiel ist eine Schleife, die eine ähnliche Kopierfunktionalität wie »memcpy()« realisiert:
int *p, *q;
while (n--) {
*p++ = *q++;
}
Die GCC 4 kann für diese Schleife Code erzeugen, der die Instruktionen »MOVDQA« (Move Aligned Double Quadword) und »MOVAPS« (Move Aligned Packed Single-Precision FP Values) verwendet, um vier Wörter (16 Bytes) in einem Schleifendurchlauf zu kopieren: .L23: incl %ecx // Schleifenzähler // erhöhen MOVDQA (%edx), %xmm0 // 128 Bits von *q // in %xmm0 laden addl $16, %edx // erhöhen von q MOVAPS %xmm0, (%eax) // 128 Bit nach p // schreiben addl $16, %eax // erhöhen von p cmpl %ecx, %edi // Schleifenende? ja .L23 Kommt die obige Schleife aber in einer Funktion vor, die beide Pointer als Parameter enthält, gerät die Vektorisierung ins Stocken. Der Compiler nimmt dann an, dass die Pointer auch auf denselben Speicherbereich zeigen können, und generiert deshalb keine Vektoroperationen. Das Ansi-C-Schlüsselwort »__restrict« legt fest, dass die Zeiger auf nicht überlappende Speicherbereiche verweisen: void foo (int n, int* __restrict p, int* __restrict q); Auch die Addition einer Konstanten innerhalb einer Schleife ist ein möglicher Kandidat für eine Paralleloptimierung:
while (n--) {
*p++ = *q++ + 5;
}
Diesen Programmabschnitt vektorisiert der Compiler analog zum obigen Beispiel mit »PADDD« (Packed Addition Double):
.LC0: // 5en im Datensegment
.long 5 // für die Addition
.long 5
.long 5
.long 5
MOVDQA .LC0, %xmm1 // laden von '5555' // in %xmm1
.L36:
incl %ecx
MOVDAQ (%edx), %xmm0
PADDD %xmm1, %xmm0 // viermal 32bit- // Addition mit je 5
addl $16, %edx
MOVAPS %xmm0, (%eax)
addl $16, %eax
cmpl %ecx, %edi
ja .L36
Abschließend sei noch ein Beispiel dafür aufgeführt, dass auch dynamische Berechnungen automatisch vektorisiert werden. Dabei sollen in der Schleife Fließkommazahlen multipliziert werden:
float *p, *q;
while (n--) {
*p = *p++ * *q++;
}
Bei der Vektorisierung verwendet der GNU-Compiler die beiden Instruktionen »MOVHPS« (Move High Packed Single-Precision FP) und »MOVLPS« (Move Low Packed Single-Precision FP), um die Operanden zu laden. Die Multiplikation führt »MULPS« (Packed Single-FP Multiply) durch:
.L11:
MOVLPS (%edx), %xmm1 // niederwertige // Bytes laden
MOVLPS (%eax), %xmm0
incl %edi
MOVHPS 8(%edx), %xmm1 // höherwertige // Bytes laden
MOVHPS 8(%eax), %xmm0
addl $16, %edx
addl $16, %eax
MULPS %xmm0, %xmm1 // vier 32bit- // Multiplikationen
MOVAPS %xmm1, (%ebx)
addl $16, %ebx
cmpl %edi, -24(%ebp)
ja .L11
Die abgebildeten Assembler-Fragmente stellen nur die Schleifenkerne dar. Vor den Schleifen multiplizieren Code-Abschnitte einzeln die Werte zu einer an einem Mehrfachen von 4 ausgerichteten Adresse. Nach den Schleifen kopieren weitere Code-Abschnitte die eventuell verbleibenden, nicht durch 4 teilbaren Reste der Daten. |
Pointer überprüfen
Für C-Programmierer bringt die GCC eine neue Möglichkeit, Problemen mit Zeigern auf die Spur zu kommen: Mudflap [15] instrumentiert kompilierten Code, um Array- und Pointerzugriffe zu überprüfen. Die neue Technik soll die Zugriffe auf bereits freigegebenen Speicher, die Überschreitung von Feldgrenzen sowie das Dereferenzieren von Null-Pointern und zudem sogar zufällig überschriebene Pointer erkennen.
Da die Überprüfung zu Performance-Einbußen führt, eignet sich Mudflap vor allem für die Entwicklungsphase von Software. Schon länger kennt GCC die Option »-ftracer«. Dabei dupliziert der Compiler Code-Abschnitte nach einer Verzweigung, um den Kontrollfluss zu vereinfachen und damit größeren Spielraum zur Optimierung zu schaffen.
Trotz aller Fortschritte gibt es bei der neuen GCC-Version auch einige Wermutstropfen. Die weggefallenen GNU-Erweiterungen, aber auch die neuen Optimierungsoptionen machen an so manchem Quellcode Änderungen nötig. So lässt sich der Linux-Kernel nur mit den neuesten Patch-Sets kompilieren. Die aktuelle Glibc 2.3.5 ist noch nicht auf die neueste Compilerversion abgestimmt. Interessierte müssen deshalb auf die angekündigte Version 2.3.6 warten oder eine CVS-Version verwenden.
Da schon der letzte Artikel zur GCC [16] die Unterschiede zwischen verschiedenen Versionen untersucht hat, konzentriert sich dieser auf die Analyse der Optimierungsoptionen. Dabei geht es nicht nur um die Hauptparameter »-O2«, »-O3«, und »-Os«, sondern auch um die Feinsteuerung über »-funroll-loops« oder »-lu«, »-ftree-vectorize«, »-ftracer«, »-funit-at-a-time« oder »-uaat« sowie eine Kombination aller zuzüglich »-fpeel-loops« und »-funswitch-loop«/»-x«.
Benchmarks
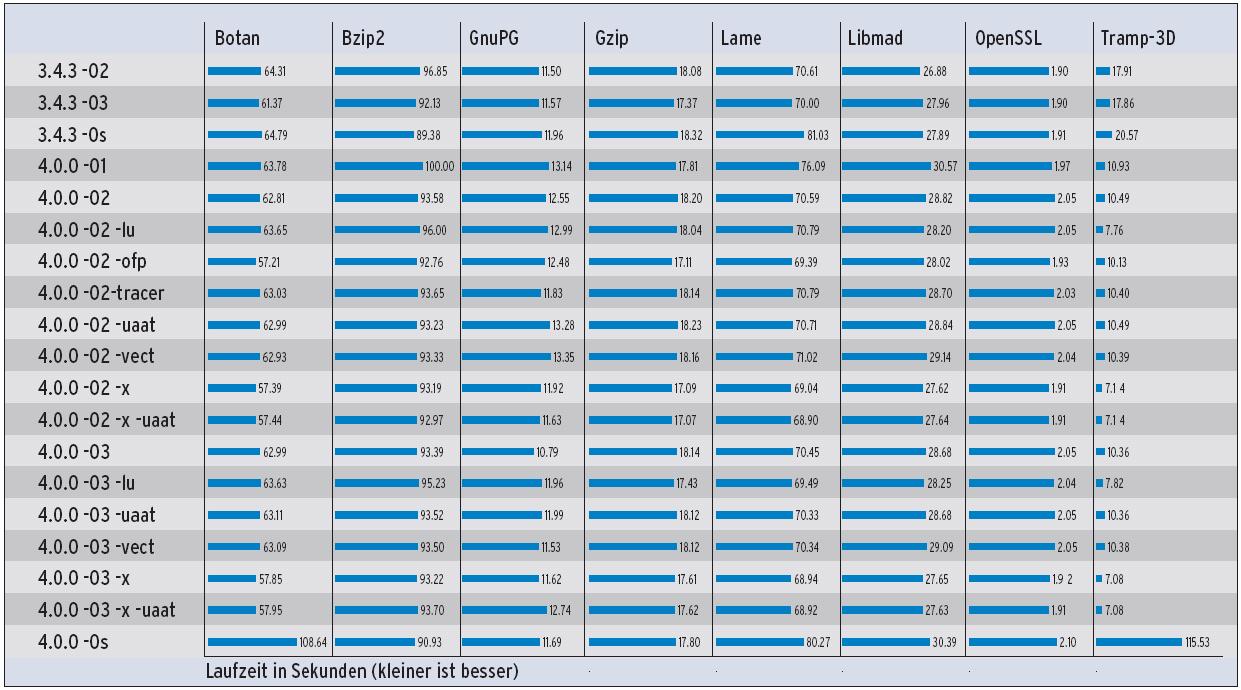
Die Ergebnisse sind recht breit gestreut (Abbildung 1). Wenn es um modernen, Template-lastigen C++-Code wie in Tramp-3D geht, liegt der neue G++ weit vorne. Hier erzeugt er teils bis zu 100 Prozent schnelleren Code als die vorherige GCC-Generation.
|
Tabelle 2: |
|
|---|---|
|
Benchmark |
Anzahl |
|
Botan |
2 |
|
Bzip2 |
6 |
|
Gnupg |
22 |
|
Gzip |
2 |
|
Lame |
22 |
|
Libmad |
4 |
|
OpenSSL |
30 |
|
Tramp-3D |
2 |
Bei vielen C-Tests hat die GCC 4.0 jedoch Schwierigkeiten, mit 3.4 mitzuhalten. Das betrifft vor allem OpenSSL, Libmad und GnuPG. Bei Bzip2 und Lame generiert die neue Version schnelleren Code.Im Vergleich zum Vorgänger liefert die neue GCC-Version bei der Optimierung mit »-Os« (s steht für Size, Größe) schlechtere Ergebnisse. Bisher waren mit dieser Option optimierte Programme so schnell wie mit »-O2« kompilierte.
Die Ergebnisse der automatischen Vektorisierung konnten in den Benchmarks nicht überzeugen, obwohl der Compiler tatsächlich einige Schleifen vektorisiert hat. Deren Anzahl pro Benchmark zeigt Tabelle 2. Die Übersetzungszeiten haben sich mit der neuen GCC-Version im Vergleich zum Vorgänger nicht verschlechtert (siehe Abbildung 2). C++-Code übersetzt der neue Compiler teilweise sogar schneller, zum Beispiel den Botan-Benchmark.
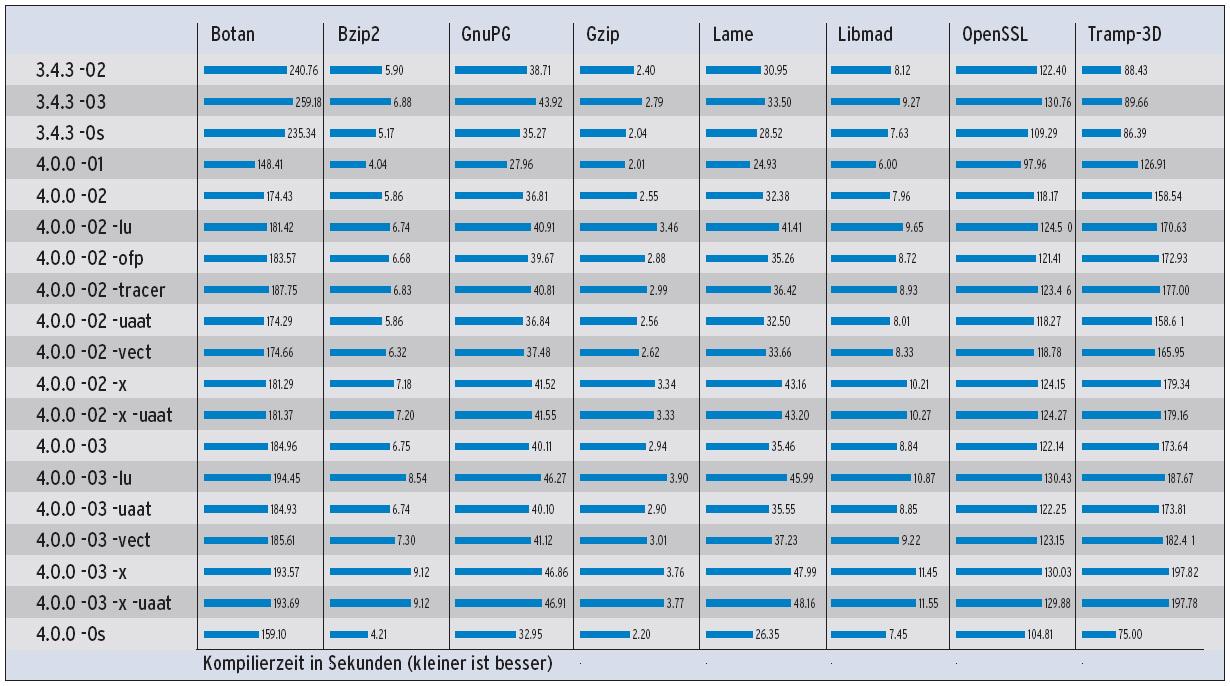
Abbildung 2: GCC 4.0 übersetzt Programme nun schneller. Auch das macht sich vor allem bei der Sprache C++ bemerkbar.
Ausblick
In der GCC-Version 4.1 wird der in 3.4 eingeführte, von Hand geschriebene C++-Parser auch C- und Objective-C-Quellcode lesen. Das soll nicht nur die Wartung des Parser-Code erleichtern, sondern auch den Übersetzungsvorgang für diese Sprachen weiter beschleunigen – und damit die Tür für weitere Optimierungen öffnen, die auch der neu unterstützen Sprache Objective-C++ zugute kommen. Mehr Details zur kommenden GCC-Version gibt [17]. (ofr)
|
Der Autor |
|---|
|
René Rebe studiert Technische Informatik an der TFH-Berlin und kennt Linux leider erst seit 1997. Er ist einer der Hauptentwickler des Distributionsbaukastens T2 und arbeitet bei vielen anderen Projekten mit. |





