
© Tomas Griger, 123RF
Wer auf der Suche nach Monitoring, Alerting und Trending für große Landschaften ist, findet im TICK-Stack alle Komponenten, die er braucht. Dieser Artikel erklärt, warum TICK selbst Prometheus überlegen ist.
Wer große IT-Setups, etwa eine Cloud, überwachen muss, steht vor einer Herausforderung: Knoten kommen und gehen, nicht jeder Wegfall ist ein Ausfall und muss zwingend zur Alarmierung führen. Neben Monitoring und Alerting ist vielerorts auch Trending nötig, denn nur so weiß der Admin, wann er Hardware nachrüsten muss, um eine gestiegene Grundlast auszugleichen.
Bald wird klar: Typische Monitoring-Lösungen wie Nagios oder Zabbix sind damit überfordert. Wer sich mit dem Thema beschäftigt, landet schnell bei Zeitreihendatenbanken. Der prominenteste Vertreter dieser Gattung ist wohl Prometheus [1]. Einst als internes Werkzeug von Soundcloud gestartet, ist das Programm samt der an ihm hängenden Zusatzkomponenten heute allseits beliebt. Poweruser jedoch klagen: An vielen Stellen nervt Prometheus mit fehlenden Funktionen und Designentscheidungen, die nicht zu jedem Setup gut passen.
Defizite und Alternativen
Ein Beispiel dafür ist der Prometheus Node Exporter, der auf den Systemen der Umgebung Messwerte einsammeln soll – und dabei oft nicht das tut, was der Administrator sich wünscht (siehe dazu den Beitrag “Schönheitskur” in dieser Ausgabe). Auch ist es mit dem Prometheus-Server nicht möglich, Messdaten redundant und in einem verteilten Speichersystem abzulegen.
Wird das eigene Setup also zu groß für eine einzelne Prometheus-Instanz, muss der Admin es aufteilen, wodurch unter Umständen einer der größten Vorzüge eines Systems für Monitoring, Alerting und Trending (MAT) wegfällt, nämlich der Single Point of Administration.
Hinzu kommt, dass Prometheus mit zunehmender Datenmenge langsamer wird. Das Programm eignet sich für Short- und Mid-Term-Trending, doch wer Trending-Daten über Jahre hinweg sicher verwahren möchte, der stößt schnell an Grenzen, denn Prometheus verliert dabei deutlich an Geschwindigkeit.
Das ist eingedenk der Tatsache, dass die Software tatsächlich nur Ziffern als Repräsentation von Messwerten speichert, erstaunlich. Andere Lösungen, die sogar Logmeldungen als Strings in der Datenbank ablegen, kommen mit viel größeren Datenmengen klar. Lange Rede, kurzer Sinn: Es gibt gute Gründe, seine Plattform für Monitoring, Alerting und Trending nicht auf Basis des momentanen Platzhirschs Prometheus zu bauen.
Wer auf der Suche nach einer Alternative ist, wird möglicherweise bei Influx DB fündig. Influx DB tritt auf Basis des TICK-Stack [2] als Alternative zu Prometheus an. TICK steht für Telegraf, Influx DB, Chronograf und Kapacitor, also die vier Komponenten, die den Kern der Lösung darstellen. Dieser Artikel stellt TICK-Stack und seine Komponenten vor und erläutert im Detail deren jeweilige Stärken. Dass Prometheus und der TICK-Stack sich gegenseitig nicht unbedingt ausschließen, zeigt der Text am Ende.
Influx DB
Das Herz von TICK-Stack ist Influx DB [3]. Das ist eine Time-Series Database, also eine Zeitreihendatenbank. Zur Erinnerung: Zeitreihendatenbanken nutzen als zentrales Element ihrer Datenhaltung keine Tabellen wie klassische Datenbanken, sie richten alle gespeicherten Daten an einem Zeitstrahl aus.
Für Trending ist das besonders praktisch: Hier steht die Frage im Mittelpunkt, welchen Wert ein Parameter über einen bestimmten Zeitraum hat – denn daraus lässt sich schließen, wie sich dieser Wert in der Zukunft weiterentwickelt. Wer weiß, wie die RAM-Nutzung seiner Plattform in den letzten drei Monaten angestiegen ist, erkennt auch, wann er Hardware für die Plattform nachkaufen muss, um nicht in Ressourcen-Engpässe zu geraten.
Eine solche Abfrage ist für herkömmliche Datenbanken mühsam: Sie müssen Tabellen und Zeilen durchforsten und jeweils mit der Zeit abgleichen, die der Admin als Parameter angegeben hat. Fällt ein Eintrag in den angegebenen Zeitraum, gehört er zum Resultat. Erst am Ende lässt sich ein Graph zeichnen. Der Prozess ist deshalb aufwändig, weil das Format des Ergebnisses ein anderes ist als das Format, das die Datenbank intern benutzt. Das nötige Transponieren der Daten ist Ressourcen-intensiv.
Zeitreihendatenbanken legen die Daten hingegen exakt so ab, wie der Admin sie später auslesen möchte – und ersparen sich so viel Overhead. Und weil sich viele Parameter eines Systems über Messdaten darstellen lassen, ist Monitoring eine Art Abfallprodukt des Trending in solchen MAT-Umgebungen. Zumindest dann, wenn man die Zeitreihendatenbank um solche Komponenten ergänzt, die auf Basis spezifischer Messwerte Alarme auslösen können.
Abbildung 1: Influx DB ist das Herz des TICK-Stack und kümmert sich als Time Series Database um das Ablegen der Metrikdaten.
Influx DB kommt die Rolle der Zeitreihendatenbank im TICK-Stack zu (Abbildung 1). Dabei unterscheidet das Tool sich an vielen Stellen merklich von Prometheus. Ein großer Unterschied ist, dass Influx DB nicht nur Zahlen als Messwerte nutzen kann, sondern auch Strings. Das ist gerade dann besonders praktisch, wenn der Admin Event-Logging betreiben möchte. Mit Prometheus geht das nur über Bande: Taucht im Kernellog etwa eine Meldung auf, in der das Wort »ERROR« steckt, kann Prometheus das zwar anhand der Metrik “Logmeldungen mit ERROR” anzeigen; Details zum Problem – etwa die Fehlermeldung selbst – gibt Prometheus aber nicht aus. Influx DB kann das hingegen sehr wohl.
Grundlegende Unterschiede
Auch sonst unterscheidet sich Influx DB von Prometheus. Das geht schon bei den Basics los: Prometheus holt sich seine Metrikwerte direkt bei den Hosts ab (Pull-Prinzip). Influx DB hingegen erwartet, dass ein separater Prozess die Werte anliefert. Beide Prinzipien haben ihre Fans und je nach Kontext eignet sich das eine oder das andere Prinzip besser. Einen elementaren Vorteil kann Influx DB hier nicht für sich verbuchen. Trotzdem muss der Admin diesen Faktor im Hinterkopf haben, wenn er sein zukünftiges Setup plant.
Große Unterschiede gibt es bei der Art und Weise, wie der Admin Daten aus der Datenbank abfragt, etwa um sie später grafisch zu interpretieren. Prometheus nutzt eine Abwandlung von SQL namens Prom QL, die speziell für den Einsatz in MAT-Lösungen gemacht ist. Influx DB setzt hier auf echte SQL-Syntax, der Dialekt heißt Influx QL. Das kommt einem Admin möglicherweise entgegen, der in Sachen SQL schon sattelfest ist. Prom QL ist zwar nicht sehr schwierig zu lernen, aber ganz ohne Mühe funktioniert es dennoch nicht.
Backups und Clustering
Davongezogen ist Influx DB Prometheus klar in Sachen Datenhaltung. Der Ansatz der Prometheus-Entwickler ist simpel: Einzelne Prometheus-Instanzen zeichnen Daten auf und legen sie auf ihrer lokalen Festplatte ab. Wer mehr zu überwachen hat als eine einzelne Instanz schultern kann, betreibt mehrere Instanzen, die jeweils Teile des Setups abdecken.
Clustering lässt sich zwar teilweise erreichen, die Entwickler raten aber explizit davon ab, den Inhalt mehrerer Prometheus-Instanzen in eine zentrale Datenbank zu spiegeln. Wer Backups von Prometheus anlegen will, richtet eine zweite Instanz ein, die dieselben Messwerte wie die erste sammelt.
Influx DB ist hier deutlich wendiger. Wer Clustering braucht, um Instanzen von Influx DB zusammenzuschalten, bekommt in der kommerziellen Version von Influx DB genau dieses Feature gegen Geld. Influx DB folgt einem Modell, das die Entwickler als Open Core beschreiben: Die Basis-Funktionalität gibt es als Open-Source-Software kostenlos. Zusatzfeatures, wie eben das Clustering, kosten.
Die Data Retention ist bei Influx DB ebenfalls flexibler: Statt wie Prometheus nur eine Datenbank kann Influx DB verschiedene Datenbanken enthalten, die jeweils ihre eigene Retention Policy benutzen. Da passt es ins Bild, dass Influx DB eine echte Backup-Funktion hat, die wahlweise Binary- oder Raw-Dateien verwendet – so wie eine klassische Datenbank vom Schlage einer Maria DB.
Besser funktioniert Influx DB auch beim Downsampling, also der Reduktion der Stützstellen einer Zeitreihe. Statt am Anfang Regeln festzulegen, welche Daten zu behalten sind und welche nicht mehr benötigt werden, bietet Influx DB Continuous Queries an. Die lesen anhand einer in Influx QL definierten Abfrage regelmäßig Daten aus Influx DB und speichern sie an einem beliebigen Ort, etwa in einer anderen Datenbank. Downsampling ist damit kinderleicht und sehr flexibel, gerade auch, weil sich die Queries im laufenden Betrieb problemlos ändern lassen.
Alarme dank Kapacitor
Influx DB hat zwar gegenüber Prometheus eine Reihe von Vorteilen, doch ähnlich wie Prometheus ist auch Influx DB nicht dazu in der Lage, auf Basis gespeicherter Messwerte Ereignisse auszulösen. Das ist in einem MAT-Setup ein Problem: Es hilft schließlich nicht, wenn die Datenbank anhand eines Datums zwar erkennt, dass etwas nicht stimmt, aber danach keinen Alarm schlägt. Genau dafür kommt im TICK-Stack Kapacitor ([4], (Abbildung 2) zum Einsatz, er ist der Wachhund von Influx DB und generiert auf Basis festgelegter Parameter Alarme, die er dann an diverse Alarmierungs-Frameworks weitergeben kann. Sucht man den Vergleich mit Prometheus, ist das Pendant am ehesten der Alert Manager.

Abbildung 2: Der Kapacitor löst auf Basis verschiedener Ereignisse Alarme aus und rüstet so die Alerting-Funktionalität nach.
Kapacitor kann aber deutlich mehr: Neben dem Erkennen von Anomalien in den Metriken beherrscht Kapacitor auch eine automatische Erkennung der Umgebung, in der er läuft. Das hilft dem Admin, weil es ihm Konfigurationsarbeit erspart. Merkt der Kapacitor von selbst, dass er in einer AWS-Umgebung läuft, greifen verschiedene Alarme, die für eben dieses Szenario vorkonfiguriert sind. Ähnliches gilt für Microsofts Azure-Cloud oder für Kubernetes-Umgebungen.
Vielseitigkeit ist Trumpf
Wer Kapacitor allerdings als reinen Alarmgenerator betrachtet, tut ihm unrecht. Mit einer Plugin-Schnittstelle lässt sich das Werkzeug durch den Admin nämlich fast beliebig erweitern und auch an verschiedene externe Systeme anschließen. Die Funktionalität ist dann keineswegs mehr auf reines Monitoring beschränkt: Denkbar wäre es etwa, die eingesammelten Messdaten an ein angeschlossenes System für Machine Learning zu übergeben, sodass dieses aus den vorliegenden Informationen Rückschlüsse zieht. Kapacitor ist dem Alert Manager von Prometheus also zumindest in dieser Hinsicht klar überlegen.
Erwähnenswert ist im Hinblick auf Kapacitor schließlich noch, dass er eine eigene DSL (Domain-specific Language) hat, also eine eigene Skriptsprache, mit der Admins beispielsweise die Bedingungen für Alarme definieren. Das Gebilde hört auf den Namen TICK Script; inhaltlich soll ein TICK Script eine Taskbeschreibung sein, die die Bedingung enthält, die zu einer Aktion führt und die auch die Aktion beschreibt, die Kapacitor am Ende ergreifen soll. Für den Admin bedeutet das zwar einmal mehr Lernerei, aber immerhin ist die Kapacitor-DSL gut dokumentiert.
Wo die Daten sind
Das schönste Monitoring funktioniert nicht, wenn es nicht auf irgendeine Art und Weise an seine Daten kommt. Weil der TICK-Stack ein Komplettangebot sein möchte, haben sich seine Entwickler auch über dieses Thema viele Gedanken gemacht. Ihre Antwort heißt Telegraf [5]: Dieser Dienst kümmert sich in einem MAT-System auf Basis von Influx DB darum, die Messwerte auf den Servern einzusammeln und sie an Influx DB zur Speicherung weiterzugeben.
Grundsätzlich ist Telegraf (Abbildung 3) also dem Prometheus Node Exporter ähnlich, doch wie mit Kapacitor und seinem Prometheus-Gegenstück Alert Manager verhält es sich auch hier: Telegraf ist deutlich potenter als der Node Exporter. Das wird schon beim Vergleich des Lieferumfangs deutlich: Über 100 Plugins gibt es für Telegraf, die das Programm um diverse Funktionen erweitern. Grundsätzlich funktioniert das so: Der Admin rollt Telegraf auf den Systemen aus, auf denen er Messwerte sammeln soll. Welche Plugins aktiv sein sollen und welche Daten im Umkehrschluss ihren Weg in Influx DB finden, legt der Admin per Konfigurationsdatei fest.
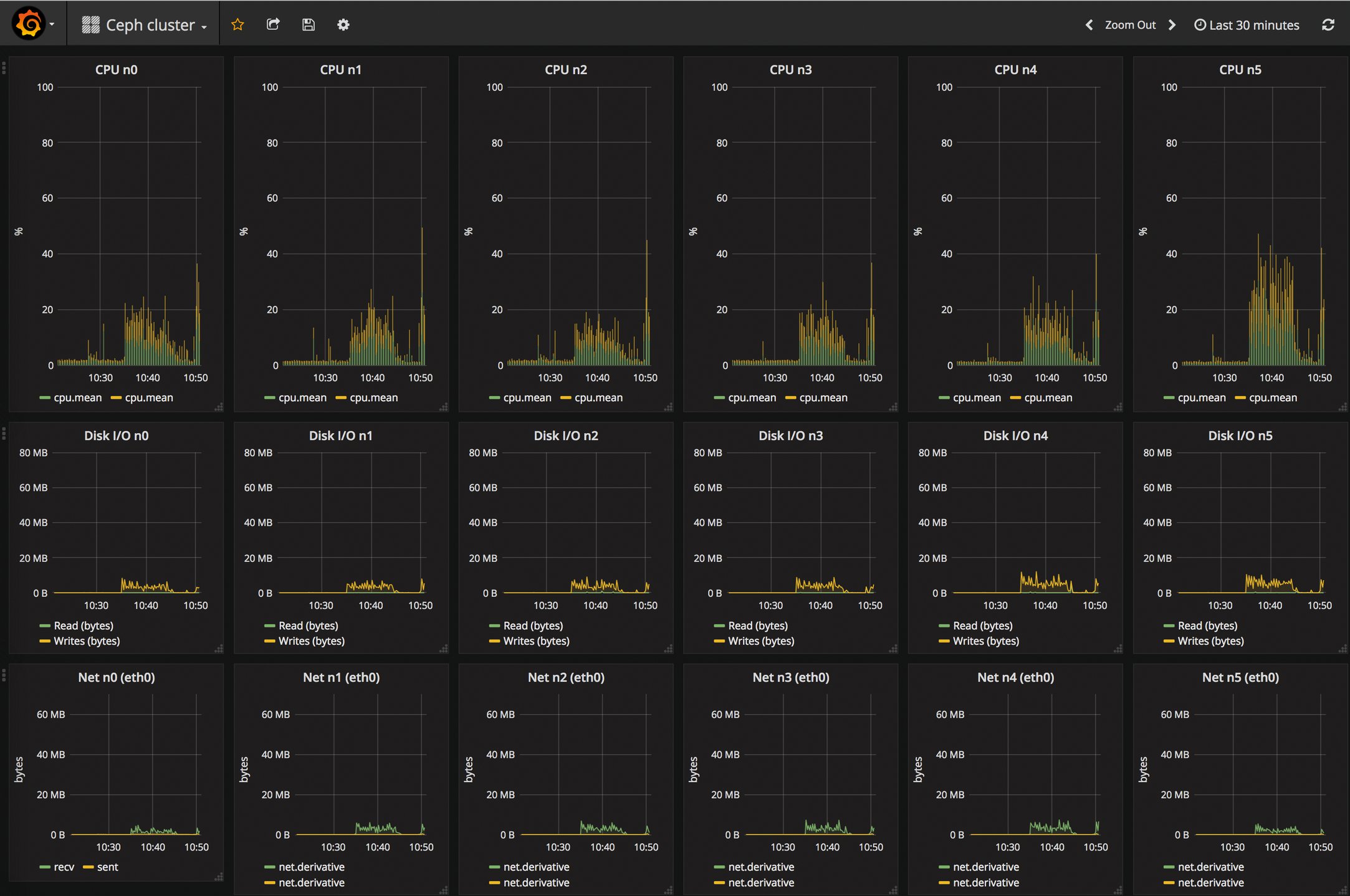
Abbildung 3: Telegraf liest grundlegende Systemwerte aus, hier etwa in einem Ceph-Cluster CPU-Load, Disk-I/O und Netzwerkdurchsatz.
Bei der Wahl der gewünschten Plugins stehen so gut wie alle Werkzeuge zur Verfügung, die des Admin Herz begehrt: Power DNS oder PostgreSQL lassen sich ebenso gut auswerten wie Apache oder IPtables. Auch für diverse andere Datenbanken wie Kafka, Mongo DB oder Couch DB ist bei Telegraf ab Werk gesorgt. Ebenfalls enthalten sind etliche Parameter, die bei klassischen Linux-Systemen interessant sind: Füllzustand der Platten, aktuelle RAM-Nutzung oder Systemlast.
Hinzu kommen diverse Funktionen, die Telegraf das Monitoring von Diensten auf anderen Systemen erlauben. Netzwerkhardware spricht typischerweise SNMP und gibt über diese Schnittstelle Daten aus – Telegraf lässt sich auf den meisten Switches aber nicht installieren. Denn dazu wäre Cumulus notwendig, und das hat trotz aller Vorteile noch immer Nischenstatus. Die Lösung: Rollt der Admin eine Telegraf-Instanz aus, die von den fraglichen Geräten per SNMP Messdaten sammelt, finden diese trotzdem ihren Weg in Influx DB.
Eine zentrale Rolle spielt Telegraf auch beim Generieren von Alarmen. Hier zeigt sich einmal mehr, dass TICK und Prometheus sich im Detail deutlich unterscheiden: Der Alert Manager verbindet sich direkt mit dem Prometheus-Server und überwacht die eingehenden Messdaten. Im TICK-Stack hingegen versorgt Telegraf einerseits den Kapacitor mit Daten und legt diese andererseits parallel in der Datenbank ab. Das bedeutet auch: Will man den TICK-Stack nutzen, braucht man mindestens Kapacitor, Telegraf sowie Influx DB – das minimale Setup.
Bunte Bilder mit Chronograf
Weil TICK den Anspruch hat, ein kompletter Stack zu sein, spielt auch das “C” eine Rolle: Gemeint ist Chronograf, das Werkzeug, das aus bestehenden Daten in Influx DB bunte Graphen zaubert. Die sind aus Sicht des Admins sehr wichtig, denn Messdaten nur anhand der nackten Zahlen zu interpretieren ist ein Ding der Unmöglichkeit.
Tatsächlich ist Chronograf die einzige Komponente von TICK-Stack die den Admin möglicherweise mit gemischten Gefühlen zurücklässt: Während sich Influx DB, Telegraf und Kapacitor als echte Gewinner auf ihren jeweiligen Gebieten erweisen, die zum Teil auch konkurrenzlos sind, stellt sich bei Chronograf die simple Frage nach dem Warum.
Abbildung 4: Grafana ist das Standardwerkzeug, um Metrikdaten auf Influx DB zu visualisieren.
Klar ist: Chronograf hat exakt dieselbe Zielgruppe, die auch Grafana hat – es geht darum, Messdaten visuell darzustellen. Als man bei Influx mit der Chronograf-Entwicklung begann, existierte Grafana aber bereits und konnte auch schon Daten auswerten, die in Influx DB abgelegt waren. Influx stand also vor einer ähnlichen Herausforderung wie die Entwickler von Prometheus. Letztere gaben ihr eigenes UI Prom Dash zugunsten von Grafana (Abbildung 4) auf. Influx ging den entgegengesetzten Weg und fing mit der Entwicklung eines eigenen Userinterface erst an.
Abbildung 5: Als Konkurrent zu Grafana tritt im TICK-Stack Chronograf an, das im direkten Vergleich aber schlechter abschneidet.
Mit mäßigem Erfolg: Chronograf ([6], Abbildung 5) ist naturgemäß besser auf Influx DB ausgelegt als Grafana, bietet aber trotzdem nicht alle Funktionen des Mitbewerbers. Und dass die Chronograf-Graphen viel ansehnlicher sind als jene von Grafana, trifft auch nicht zu. In einem TIK-Setup bietet Chronograf insofern keinen echten Mehrwert, und viele Admins nutzen tatsächlich Influx DB, Telegraf und Kapacitor, verzichten jedoch auf Chronograf. Summa summarum entsteht bei Chronograf jedenfalls das Gefühl, es mit einem ganz klaren Fall von “Not invented here” zu tun zu haben.
Friedliche Koexistenz?
Viele Administratoren sehen in der Wahl zwischen Prometheus und TICK eine Schwarz-Weiß-Entscheidung: Entweder verschreibt man sich Prometheus und setzt auf die Komponenten aus dessen Stack oder man nimmt Influx DB und holt sich dessen Helferlein auf die Systeme. Bekanntlich existieren aber mehr Farben als nur Schwarz und Weiß, bei der Auswahl einer MAT-Lösung ist das nicht anders: Statt einer Entweder-oder-Entscheidung ist nämlich auch eine Sowohl-als-auch-Variante denkbar. Dabei kombiniert der Admin das Beste aus beiden Welten und nutzt alle verfügbaren Funktionen optimal.
Ein solcher Ansatz ist kein Hirngespinst. Anstelle des nicht immer optimal designten Prometheus Node Exporter lässt sich auch Telegraf verwenden, um Metrikdaten auf den Hosts einzusammeln. Das funktioniert gut und bietet dem Admin sogar mehr Möglichkeiten, weil Telegraf diverse Features bietet, die dem Node Exporter von Prometheus fehlen.
Noch besser lassen sich Teile beider Lösungen allerdings kombinieren, wenn es um das Ablegen von Daten geht. Zur Erinnerung: Prometheus ist nicht sehr gut darin, Daten in großen Mengen dauerhaft zu speichern, um Long-Term-Trending zu realisieren.
Influx DB hingegen beherrscht das Ablegen von Daten zum Zwecke des Long-Term-Trending deutlich besser als Prometheus. Wie beschrieben kann es die Daten sogar in einem geclusterten Speicher im Netz verteilt ablegen, und selbst bei großen Datenmengen wird es kaum langsamer.
Vorteile hat Prometheus hingegen in Sachen Short-Term-Trending und es hat ebenfalls die Nase vorn, wenn Metrik-basiertes Monitoring die Aufgabe ist. Was läge also näher, als beide Lösungen miteinander zu kombinieren? Eine solche Möglichkeit sehen auch die Influx DB-Entwickler deshalb mittlerweile explizit vor.
Der Influx-DB-Entwickler Paul Dix, der auch für den Adapter verantwortlich zeichnet, der zwischen Influx DB und Prometheus übersetzt, beschreibt in einem Blog [7] diese Art des Setups ausführlich. In einer Präsentation im Rahmen der Percona Live Europe 2017 geht auch Datenbankhersteller Percona im Detail auf die Kombination der Lösungen ein [8]. Schließlich enthält auch die Dokumentation von Influx DB einen entsprechenden Passus.
Das Beste aus beiden Welten
Funktionieren soll das so: Metrikdaten sammeln wahlweise der Node Exporter von Prometheus, Telegraf oder irgendein anderer Exporter, der die Anforderungen von Prometheus erfüllt. Alle Daten landen zunächst in Prometheus, Chronograf und Kapacitor kommen in einem solchen Setup also nicht vor. Die Daten in Prometheus durchlaufen je nach Admin-Wunsch zunächst ein Downsampling: Statt alle Daten genügt es möglicherweise, exemplarische Datensätze für länger zurückliegende Zeiträume zu sichern – weil die ebenso aussagekräftig sind. Ein Downsampling-Ansatz könnte etwa sein, dass alle Daten der vergangenen vier Wochen ebenso zu behalten sind wie ein Datensatz jedes Tages der vorangegangenen zwei Monate und ein Datensatz pro Woche des letzten Jahres.
Technisch funktioniert das so: Zwischen Prometheus und Influx DB hängt der Admin einen so genannten Adapter. Der kommuniziert auf der einen Seite mit dem Prometheus-Server und auf der anderen Seite mit Influx DB. Auf Basis der vom Admin festgelegten Downsampling-Regeln liest er die benötigten Messdaten aus Prometheus aus und speichert sie in Influx DB. Das alles geschieht aus der Sicht von Prometheus völlig transparent und sorgt auch nicht dafür, dass sich die in Prometheus anliegende Last erwähnenswert erhöht.
Ein solches Konstrukt führt übrigens nicht dazu, dass der Admin den Vorteil eines Single Point of Administration verliert. Zwar steht in einem Setup dieser Art Influx DB als Datenquelle parallel zu Prometheus zur Verfügung. Falls aber Grafana als Werkzeug zum Einsatz kommt, um Metrikdaten zu visualisieren, lassen sich in Grafana entsprechende Dashboards auch für Influx DB integrieren. Am Ende steht also dasselbe Interface, das im Hintergrund jedoch auf eine andere Quelle zugreift.
Damit gilt: Wer Prometheus und Influx DB kombiniert, bekommt das Beste aus den beiden Welten.
Fazit
Weder TICK noch Prometheus sind in Sachen MAT die eierlegende Wollmilchsau. Wer die beiden Produkte vergleicht, sollte sich vor Augen halten, dass schon ihre Zielsetzung nicht deckungsgleich ist: TICK versteht sich als eine Lösung zur Datenverarbeitung auf Basis von Messdaten, die unter anderem auch als Plattform für Monitoring, Alerting und Trending zum Einsatz kommen kann.
Daraus ergibt sich, dass Influx DB Funktionen hat, die bei Prometheus fehlen. Prometheus versteht sich eher als reine MAT-Lösung, kommt allerdings auch mit weniger Overhead aus. Ob man sich für das eigene Setup nun TICK oder Prometheus näher anschaut, hat erst einmal etwas mit den eigenen Anforderungen zu tun.
Wer MAT auf Basis von zahlenbasierten Messwerten betreiben will, ist mit Prometheus besser bedient und vermutlich auch schneller am Ziel. Wer dagegen mehr Flexibilität braucht und neben Metrikdaten auch Events in Form von Texten loggen möchte, der sollte sich zuerst TICK anschauen.
Bedenken sollten Admins zudem stets, dass sich beide Lösungen hervorragend miteinander kombinieren lassen. Wer schließlich TICK als Long-Term-Speicher für seine Prometheus-Daten nutzt, kann Telegraf, den Kapacitor und Chronograf parallel zu Prometheus betreiben und für sich arbeiten lassen.
Infos
-
Prometheus: https://prometheus.io
-
TICK-Website: https://www.influxdata.com/time-series-platform
-
Influx-DB: https://www.influxdata.com
-
Kapacitor: https://www.influxdata.com/time-series-platform/kapacitor
-
Telegraf: https://www.influxdata.com/time-series-platform/telegraf
-
Chronograf: https://www.influxdata.com/time-series-platform/chronograf
-
Blog: https://www.influxdata.com/blog/influxdb-now-supports-prometheus-remote-read-write-natively
Der Autor

Martin Gerhard Loschwitz ist Telekom Public Cloud Architect bei T-Systems und beschäftigt sich beruflich vorrangig mit Themen wie Open Stack, Ceph und Kubernetes.





