
Jeden Tag plagen sich Computernutzer mit der wachsenden Menge an Daten herum: E-Mails, Chat-Protokolle, Office-Dokumente, Urlaubsfotos, Musikdateien. Desktop-Suchmaschinen treten an, um in dem Chaos die gesuchten Informationen zu finden. Dieser Artikel zeigt, ob sie es schaffen.
Seit Urzeiten gehört das Sammeln zu den überlebensnotwendigen Aufgaben des Menschen. Mittlerweile ist bei vielen die Sammelwut jedoch derart ausgeprägt, dass sie beim Wiederfinden Hilfe benötigen. Computer-Messies bilden da keine Ausnahme: Täglich suchen sie auf ihren Festplatten Dokumente, Musikdateien oder E-Mails.
Desktop-Suchsysteme sollen dabei helfen, den Überblick zu behalten. Ironischerweise müssen Anwender aber erst das richtige System auftreiben. Denn neben Produkten von Google und Microsoft (die beide relativ neu in diesem Geschäft sind) gibt es viele weitere Werkzeuge. Linux muss sich hier nicht hinter Windows oder Mac OS verstecken; Anwender erwartet ein ähnlich umfangreiches Angebot wie bei der Konkurrenz.
Die Programme basieren im Grunde alle auf derselben Technik: Ein Index speichert für sämtliche Ressourcen interne Metadaten (ID3-Tags bei MP3-Dateien oder Autor und Seitenzahl eines Office-Dokuments), externe Metadaten (Dateiname, Mailordner) sowie die eigentlichen Inhalte (Text einer Office-Datei).
Aufgabenteilung
Abbildung 1 zeigt exemplarisch das Zusammenspiel der verschiedenen Komponenten einer Desktopsuche. Als Watcher dient beispielsweise ein Kerneltreiber, etwa das I-Notify-Modul. Einige Systeme besitzen keinen Watcher, der Crawler oderIndexer läuft dann im Hintergrund per Scheduler oder die Anwender starten ihn manuell. Die hohe Modularisierung der Suchmaschinen ermöglicht es Benutzern und Entwicklern, dem System über Plugins im Crawler weitere Dateitypen bekannt zu machen.
Die Systeme haben neben der reinen Suche im Dateibaum auch die Aufgabe, Daten aus speziellen Applikationen aufzunehmen. Darunter fallen Bookmarks des Webbrowsers, E-Mails, Chatprotokolle und Adressbücher. Jede Applikation hat zwar meist eine eigene Suchfunktion, doch ergeben sich daraus zwei Nachteile: Das Benutzerinterface sieht stets unterschiedlich aus und der Anwender erreicht die Suche nicht aus anderen Bereichen des Desktops heraus.
Integration der Daten
Der Benutzer will in erster Linie nicht nur erfahren, dass sich die gesuchten Daten auf seinem System befinden, sondern – basierend auf Datentyp sowie externen und internen Metadaten – in welchem Zusammenhang sie auf dem Computer entstanden, wo sie liegen und wie man sie betrachtet beziehungsweise anderweitig nutzt:
- Wann und an wen wurde eine Mail mit einem bestimmten Inhalt
geschickt? - In welchem Ordner welches Mailclients befindet sie sich?
- Wann und mit wem wurde über ein bestimmtes Thema
gechattet? - Wo liegt eine Datei mit bestimmtem Inhalt, wann wurde sie
erstellt und mit welchem Programm?
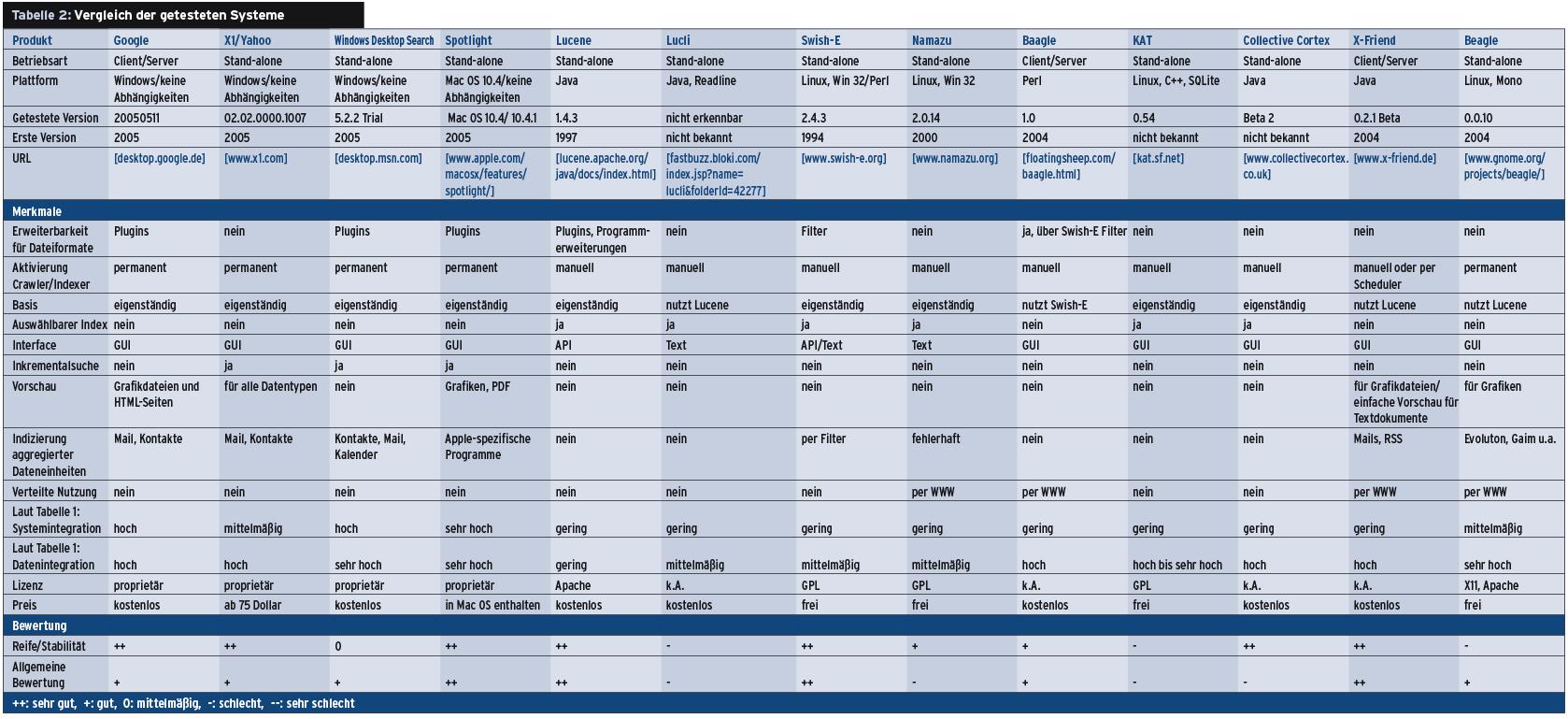
Die gefundenen Daten zeigt ein Suchsystem entweder vollständig an oder wenigstens eine Referenz darauf, eventuell versehen mit Auszügen aus dem Inhalt. Die Behandlung der Ergebnisdaten gerät zur Herausforderung für die Suchprogramme, wenn es sich um aggregierte Dateneinheiten handelt, etwa eine Mbox-Datei oder eine Datenbank. Die Klassifikation in Tabelle 1 bewertet, wie gut Suchsysteme Daten integrieren und wie sie sich in das System einbinden.
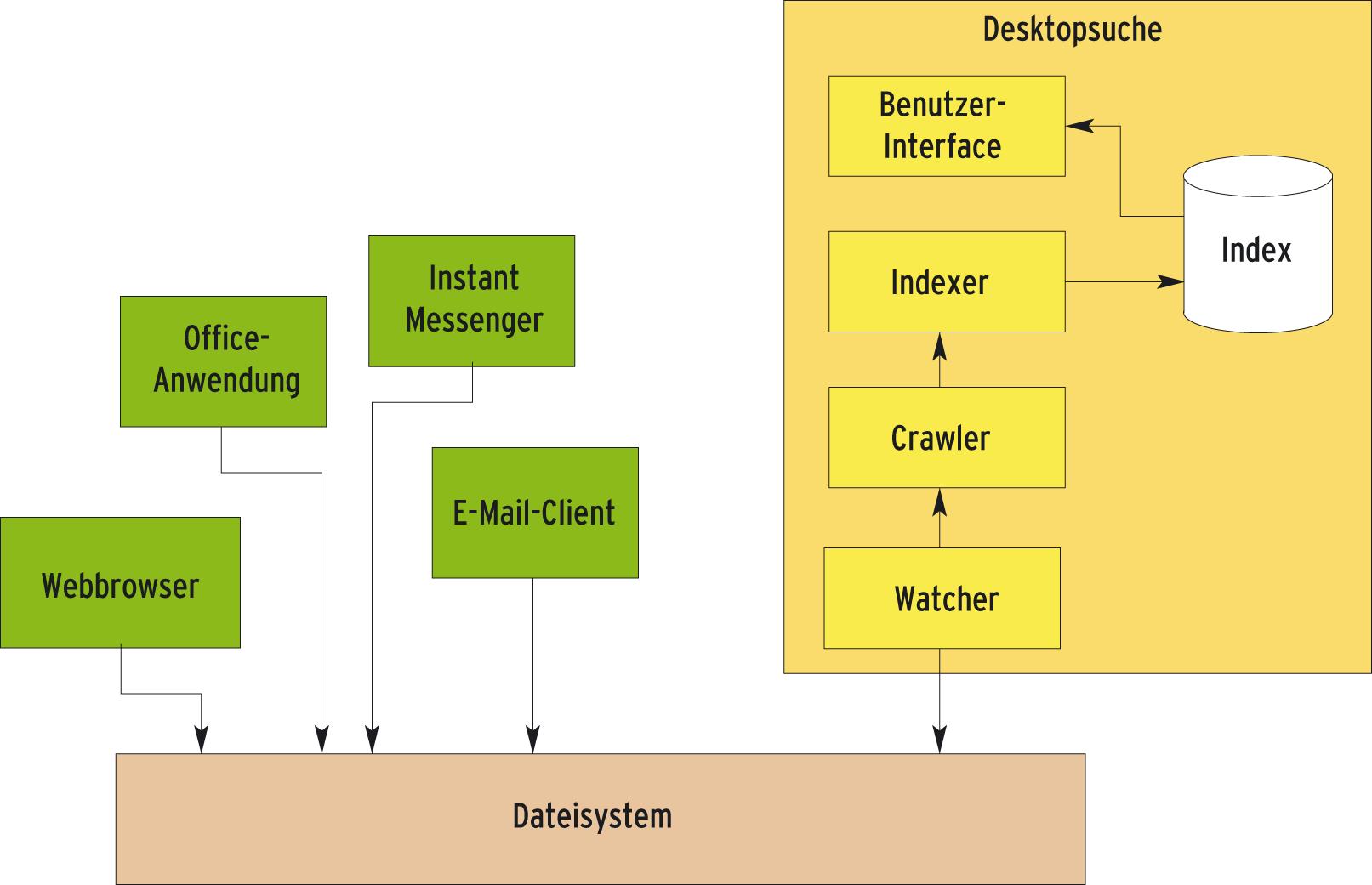
Abbildung 1: Desktop- Suchsysteme bestehen aus mehreren Komponenten. Ein Watcher überwacht das Dateisystem auf Veränderungen und informiert den Crawler. Dieser sucht alle Metadaten aus den Dateien zusammen und übergibt sie an den Indexer, der sie in eine Datenbank einträgt.
Für Windows und Mac OS X
Da dieser Artikel eine Übersicht über die wichtigsten Suchsysteme liefern soll, reihen sich auch Kandidaten ins Testfeld ein, die ausschließlich unter Windows oder Mac OS funktionieren.
Google Desktop Search
Mit Google Desktop Search sollen Anwender ihre Daten möglichst schnell finden. Dank der Integration eines Eingabefelds in die Windows-Taskleiste erreichen sie alle Funktionen zwar sehr flott. Das Programm setzt aber voraus, dass stets ein Browser läuft, beziehungsweise startet ihn jedes Mal neu.
Positiv: Die Desktopsuche integriert sich neben WWW-, News- und anderen Suchen als weitere Funktion in Googles Website. Die Desktop-Ergebnisse zeigt der Browser bei einer Websuche stets mit an (Abbildung 2). Leider lässt sich die Suchsoftware nur mit Administratorrechten installieren und ausführen.
Google verarbeitet nach eigenen Angaben die Mailfolder von Outlook, Mozilla und Thunderbird. Ein Test mit Thunderbird funktionierte jedoch nicht. Einzelne Mails zeigt Google vollständig an und bietet die üblichen Bearbeitungsfunktionen wie Antworten und Weiterleiten.
X1/Yahoo
Ebenfalls im Web-Umfeld erfolgt die Desktopsuche von Yahoo, die auf Produkten der Firma X1 basiert. In einem eigenständigen Fenster zeigt die Software eine Vorschau für alle unterstützten Datentypen. Dazu gehören auch Open-Office-Dokumente, allerdings extrahiert das Programm lediglich den XML-Inhalt aus den Dateien, während Anwender ihre MS-Office-Dateien als vollwertige Vorschauen sehen. Für Open-Office-2.0-Dateien zeigt Yahoo die Struktur des Zip-Archivs.
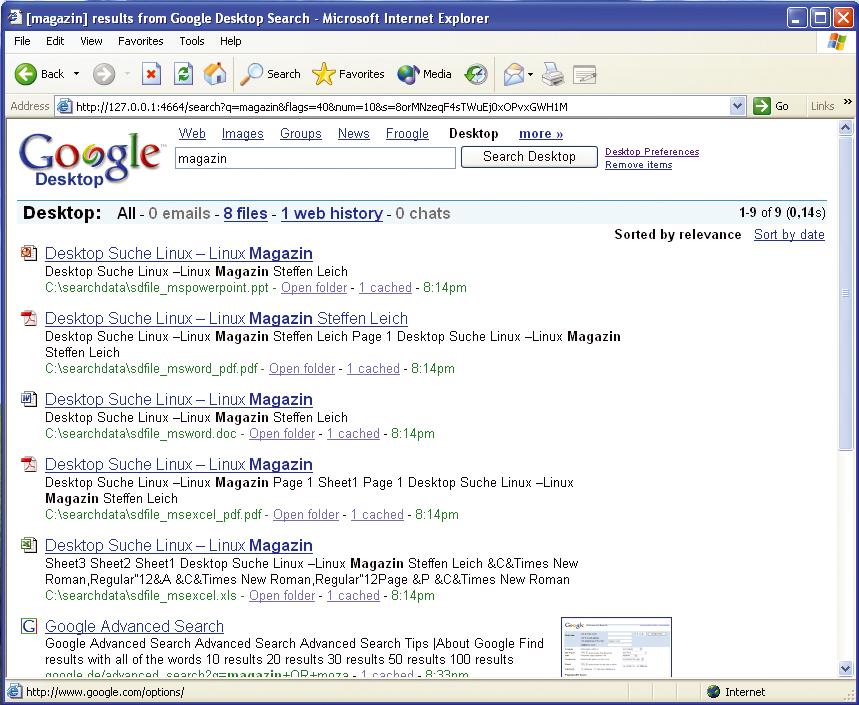
Abbildung 2: Google integriert die Desktopsuche direkt in seine bekannte Website. Daher müssen Anwender nicht zusätzlich ein anderes Programm starten, um Inhalte der Festplatte zu durchsuchen.
Durch die integrierte Vorschau und die Möglichkeit, Audio- sowie Videodateien abzuspielen, mutet das Programm wie ein Dateimanager an. Es gibt zwar kein Taskbar-Symbol und auch keine weitere Integration in den Desktop, aber per Tastatur-Shortcut ist das Programm schnell zu erreichen. Ein Scheduler aktualisiert den Index regelmäßig, die Suche geht auffallend flott vonstatten.
Insgesamt hinterlässt das Produkt den positiven Eindruck eines ausgereiften Werkzeugs mit vielen Funktionen und hoher Leistung, aber eher geringer Desktopintegration.
|
Tabelle 1: |
||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
|
Geringe Integration |
Mittelmäßig Integration |
Hohe Integration |
Sehr hohe Integration |
||||||||||||||||
|
Systemintegration |
Beispiel: Kommandozeile |
System schnell zu erreichen, |
System immer sichtbar, |
Weitgehende Integration in den |
|
Beispiel: Tastatur-Shortcut |
Beispiel: Integration in die |
Desktop, Beispiel: Erreichbar- |
|
|
Taskbar |
keit bei Dateioperationen mit |
|
|
|
dem Filemanager |
||||
|
Datenintegration |
Nur Anzeige der externen |
Anzeige der internen |
Applikationszuordnung der |
Das System zeigt aggregierte |
Metadaten von Dateien |
Metadaten und damit des |
gefundenen Daten |
Daten im Kontext an, Desktop- |
|
|
Kontextes |
|
einstellungen steuern die |
|
|
|
|
|
Verwendung der Ergebnisse |
Windows Desktop Search
Microsoft hat seine MSN-Toolbar-Suite inklusive der Windows Desktop Search Anfang des Jahres veröffentlicht, die Betaphase endete Mitte Mai 2005. Das System ist erwartungsgemäß gut in den Desktop integriert. So erreichen Anwender die Suche über ein Eingabefeld in der Taskbar (Abbildung 3).
Die Ergebnisanzeige in einem eigenen schlanken Fenster ist sehr schnell auf und zu zu klappen und gut erreichbar. Daneben integriert sich die zugehörige Toolbar in Outlook, den Internet- und den Datei-Explorer. Allerdings zeigte im Test eine Eingabe in den Search-Toolbars externer Programme keine Wirkung.
Bei der gewohnt komfortablen Installation fragt ein Wizard die gewünschten Optionen des Systems ab. Danach steht die Suche zurückhaltend im Hintergrund zur Verfügung. Dazu trägt auch der permanente Indexer bei, der die Auslastung des Computers beachtet.
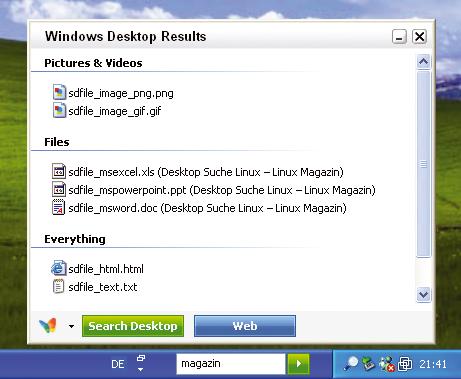
Abbildung 3: Die Windows Desktopsuche nutzt ein spezielles GUI für die Desktop-Integration. Über die Toolbar geben Anwender ihre Suchbefehle ein, ohne ein externes Programm starten zu müssen.
Die Windows Desktop Search zeigt jedoch noch einige Schwächen. Beim Versuch, nach einer Änderung der zu durchsuchenden Ordner eine komplette Neuindizierung vorzunehmen, stürzte der Indexer ab und ließ sich nicht mehr starten. Sonstige Änderungen nahm der Index nur sehr langsam auf. Aggregierte Dateneinheiten wie Mail, Kontakte oder Termine sind nur mit Outlook 2000 indizierbar. Abgesehen von diesen Patzern landen die unter Windows üblichen Dateiformate korrekt im Index.
Apple Spotlight
Auch die Apple-Entwickler haben in den vergangenen Jahren an einer neuen Desktopsuche gearbeitet. Die Spotlight genannte Funktion in Mac OS 10.4 (Tiger) ist als einziges Produkt bereits in das Betriebssystem integriert. Sie passt sich optimal an den Desktop an und macht einen sehr ausgereiften Eindruck.
Spotlight indiziert fast alles, was sich an Daten auf der Festplatte sammelt: Dateien, E-Mails, Kontakte im Adressbuch, Kalendereinträge, Systemeinstellungen und Applikationen. Die Eingabe von »keyboard« etwa führt den Benutzer auf die Einstellungsoptionen für die Tastatur. Ergänzen lassen sich interne und externe Metadaten durch manuell eingegebene Spotlight Comments.
Das System läuft mit einem permanenten Indexer, der nach der ersten Indizierung (Abbildung 4) mit einem Dateisystem-Watcher Änderungen im System unmittelbar aufnimmt. Im Test speicherte das Programm Änderungen aller Art tatsächlich ohne erkennbare Verzögerung.
Suchergebnisse lassen sich unter Tiger als so genannte Smart Folder ablegen und später wieder verwenden. Die sehr tiefe Integration in den Desktop zeigt sich vor allem in Details, die die Arbeit erleichtern. Eingabefelder gibt es in allen Dialogen zum Öffnen und Speichern von Dateien. Dank Cocoa-Framework ist sogar markierter Text in einem Programm per Spotlight aufzuspüren.
Die Integration erstreckt sich bis in den Unix-basierten Maschinenraum von Mac OS X: Auf der Kommandozeile stehen die Werkzeuge »mdls« und »mdfind« zur Verfügung, die Metadaten einer Datei auflisten und Anfragen an die Spotlight-Engine abschicken.
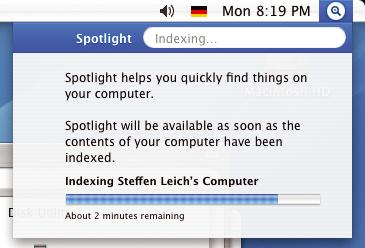
Abbildung 4: Apples Spotlight für Mac OS 10.4 integriert sich perfekt in das System und indiziert sogar Systemeinstellungen. Anwender erweitern die Suchfunktionen mit eigenen Spotlight Comments.
Suchsysteme für Linux
Bei den Linux-basierten Systemen unterteilt dieser Artikel die Frameworks zusätzlich in textbasierte und grafische Werkzeuge. Gerade unter Unix/Linux spielt die Kombination von Kommandozeilenwerkzeugen und grafischen Oberflächen eine bedeutende Rolle – sowohl für Entwickler als auch für Anwender.
Lucene
Das Such-Framework Lucene stellt eine mächtige Bibliothek für die Textsuche zur Verfügung. Bereits 1997 begann Doug Cutting mit der Arbeit an Lucene, er hat bereits Suchsysteme für Xerox, Apple und Excite entwickelt. Lucene unterliegt der GPL-kompatiblen Apache-Lizenz. Neben der Hauptversion – in Java implementiert – gibt es noch einige Portierungen; die Dotnet-Variante dient beispielsweise Beagle als Backend.
Nach Angaben der Entwickler zeichnet sich Lucene durch einen sehr geringen Ressourcenbedarf, hohe Geschwindigkeiten des Crawl- und Indexer-Programms sowie eine geringe Größe der Indexdatei aus. Durch die geringe Speicherbelastung beeinträchtigt etwa das Programm X-Friend mit seiner Lucene-Engine die sonstigen Desktopfunktionen auf dem Testgerät mit installierten 512 MByte RAM nur unwesentlich.
Lucene kann die Suchergebnisse sortieren, die Sucheingabe versteht die Bibliothek als Phrase, Wildcard-Ausdruck, Ähnlichkeitsanfrage oder Range-Ausdruck. Zusätzlich lassen sich mehrere Indizes gleichzeitig durchsuchen und die Ergebnisse mischen. Anwender haben zudem die Möglichkeit, Dokumentzusammenfassungen im Index mit abzuspeichern und über ein Zusatzmodul eine Suchbegriff-Hervorhebung anzuzeigen.
Eine simple, im Programmpaket mitgelieferte Demo-Applikation zeigt, wie einfach sich Lucene mit dem schlanken API in eigene Java-Applikationen einbinden lässt. Die Anwendung Lucli demonstriert die Umsetzung eines Lucene-basierten Kommandozeilen-Werkzeugs.
Swish-E
Einer Desktopsuche ähnliche Programme gibt es auch unter den klassischen Unix-Werkzeugen. Swish-E gehört zu den bekanntesten textbasierten Suchsystemen. Das ursprüngliche Swish erschien bereits 1994. 1996 übernahm die Universität Berkeley das System und erarbeitete die aktuelle Version Swish-E [1], das Simple Web Indexing System for Humans – Enhanced.
Swish-E indiziert alle Daten, die der Indexer übergeben bekommt, etwa Dateien aus dem lokalen Dateisystem oder Seiten von WWW-Servern, die der integrierte Webspider liefert. Nativ kennt Swish-E Text-, XML- und HTML-Daten. So genannte Feed-Plugins konvertieren ein beliebiges Dokument in eines dieser Formate und übergeben es dann dem Crawler. Damit extrahiert Swish-E sogar Datenbanken oder entpackt Archive. Über das manuelle Setzen von Meta-Tags in den Quellen können Anwender ihre Daten mit Schlagwörtern versehen.
Entwickler, die Swish-E in ihre Software integrieren wollen, nutzen das C-API oder ein Perl-Modul. Insgesamt macht das System einen guten Eindruck. Es lässt sich leicht und schnell einrichten, die ersten Schritte zum Erstellen eines Index gestalten sich simpel. Dank der gut strukturierten Konfiguration bietet Swish-E ausreichende Flexibilität.
Namazu
Das zweite Text-Werkzeug, Namazu, enthält zwar eine integrierte Weboberfläche. Sie dient aber vorrangig als Beispiel für eine Implementierung und lässt sich bezüglich der Funktionsvielfalt nicht mit den umfangreichen Oberflächen anderer Systeme vergleichen. Es fehlt zum Beispiel eine Möglichkeit, Namazu um weitere Dateitypen zu ergänzen. Die Ausgabe der Ergebnisse zeigt sich schon etwas flexibler. Sie bietet verschiedene Ausgabeformen an, etwa kompakt, detailliert und HTML-basiert. Entwickler betten Namazu daher recht einfach in ihre Oberfläche ein.
Positiv fällt auf, dass der Indexer bereits in der Standardeinstellung die internen Metadaten von Open-Office-Dateien ausliest. Per Default verläuft die Indizierung inkrementell. Kombinierte Dateneinheiten lassen sich mit Namazu jedoch nicht zufrieden stellend indizieren. Eine aus Thunderbird exportierte Mailfolder-Datei im RFC822/Mbox-Format las das Programm im Test nur unvollständig ein, obwohl es einen speziellen Parameter für die Indizierung von Dateien dieses Formats gibt.
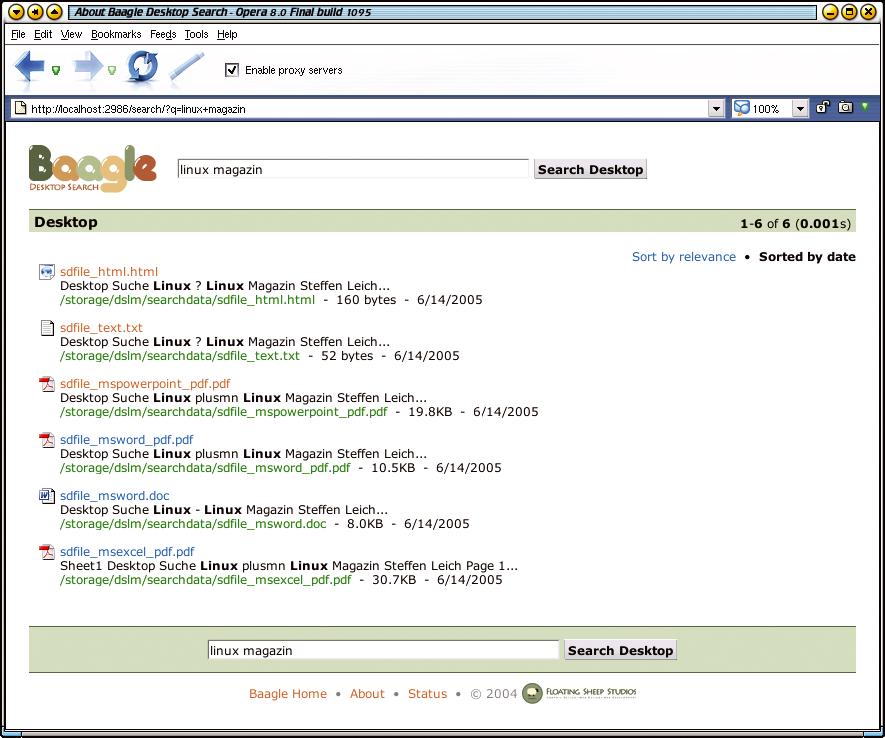
Abbildung 5: Die simple Lösung Baagle basiert auf der Swish-E-Software und präsentiert dem Anwender eine hübsche, Google-ähnliche Weboberfläche.
Baagle
Neben den Kommandozeilen-Werkzeugen haben sich in kurzer Zeit zahlreiche grafische Desktop-Suchprogramme entwickelt. Die kleine Anwendung Baagle basiert auf Swish-E, bringt eigene Datenfilter- und Perl-Module sowie einen einfachen Webserver mit. Anwender geben über eine Konfigurationsdatei die zu verwendenden Filter sowie die zu durchsuchenden Verzeichnisse an.
Das Programm »indexer« indiziert alle Daten und »server« stellt die Weboberfläche zur Verfügung (Abbildung 5). Baagle hat zwar nach Auskunft der Entwickler den Status eines Quick-Hacks, es bietet aber dennoch ein stimmiges Paket, ausgedrückt auch durch die Versionsnummer 1.0. Allerdings fehlen die Integration in den Desktop sowie Komfort beim Installieren und Einrichten.
Kat
Das KDE-Programm Kat speichert seine Indizes in SQLite-Datenbanken, die der Anwender selbst per Knopfdruck auf dem neuesten Stand halten muss. Auch eine Integration in den Desktop lässt noch auf sich warten – Kat besitzt ein komplett eigenständiges GUI. Allerdings öffnet sich mit einem Rechtsklick auf ein Suchergebnis das Kontextmenü des Konqueror-Dateimanagers. Das Programm läuft noch sehr instabil und es fehlen viele Funktionen, etwa eine detaillierte Suche mit Operatoren. Open-Office-Dokumente bezieht Kat nicht mit in die Volltextsuche ein, obwohl die Indizierung dieser Dateitypen laut Dokumentation zum Repertoire gehört.
Kat ist zurzeit die einzige speziell auf KDE ausgerichtete Desktopsuche. Als offizielle Suchmaschine für KDE bezeichnen sie die Entwickler jedoch nicht. Nach Aussagen aus dem KDE-Team wurde bereits auf dem Community World Summit im August 2004 damit begonnen, ein entsprechendes eigenes System zu diskutieren und auch Code dafür zu entwickeln. Es soll in der nächsten großen KDE-Release 4.0 enthalten sein.
Collective Cortex
Collective Cortex von der gleichnamigen Firma basiert wie Kat auf Katalogen, die der Benutzer selbst verwaltet. In der Katalogansicht zeigt das Programm alle Daten aus dem aktuellen Katalog; bei der Suchansicht sieht der Anwender nur die Einträge, die auf den Suchbegriff passen. Das in Java implementierte System besitzt neben Dateimonitoren, die das Dateisystem auf Änderungen überwachen, auch die Möglichkeit, Web- und RSS-Inhalte zu durchsuchen.
Inhalte eines Katalogs lassen sich laut Dokumentation mit Metadaten für die Indizierung ergänzen. Diese Funktion schien jedoch auf dem Testsystem zu fehlen. Für das ins Deutsche übersetzt “kollektive Hirnrinde” genannte Programm gelten neben der funktionalen Ähnlichkeit zu Kat auch dessen Einschränkungen. Es eignet sich nur für kleinere Indexdateien und besitzt zurzeit keine Desktop-Integration.
X-Friend
Mit X-Friend bietet die X-Dot GmbH ein komplett in Java implementiertes Suchsystem, das als Engine die Java-Version von Lucene enthält. X-Friend lässt sich als umfassendes autarkes System von einem normalen Benutzer installieren. Das Paket bringt alle notwendigen Elemente mit und setzt lediglich eine Java-Laufzeitumgebung voraus.
Die Struktur der Benutzeroberfläche gibt einen Überblick über die verfügbaren Datentypen. So lassen sich alle Audiodateien auflisten, diese wiederum nach Album oder Künstler näher untersuchen. Neben einer einfachen Vorschaufunktion für Textdaten zeigt X-Friend Bilder über eine Icon-Ansicht als Thumbnails an. Die Bilder landen nicht verkleinert im Index, sondern sind auf der Ergebnisseite per HTML skaliert. Daher fällt auch die Anzeige etwas zäh aus, wenn sie vielen großen Dateien listet.
Der Indexer lässt sich bei X-Friend per Scheduler oder manuell starten, scheint aber zur Laufzeit die Auslastung des Systems nicht zu berücksichtigen. Hier sollten Anwender eine entsprechende Priorisierung per Nice-Level festlegen. Außerdem bereitete die Indexpflege bei diesem System zum Teil Probleme. Das Scheduling des Indexers erwies sich im Test als nicht konsistent und der Prozess ließ sich manuell nicht stoppen.
Beim Indizieren von kombinierten Dateneinheiten (Mails und RSS) geht das System einen völlig anderen Weg als die übrigen Lösungen. X-Friend nimmt Verbindung zu einem IMAP- oder POP-Server auf und holt alle Mails von dort ab. Auch RSS-Feeds nimmt die Software direkt vom Server auf. Dadurch ergibt sich das Problem, dass Mails unter Umständen früher in der Suchsoftware als im Mailclient auftauchen. Bereits lokal gespeicherte Mails berücksichtigt das Produkt nicht.
Insgesamt hinterlässt X-Friend trotzdem einen guten Eindruck. Die Oberfläche wirkt durchdacht und nutzt das Potenzial einer darunter liegenden Such-Engine gut aus. Beim Indizieren erkennt das System unter anderem MS Office und PDF, Open Office jedoch nicht.
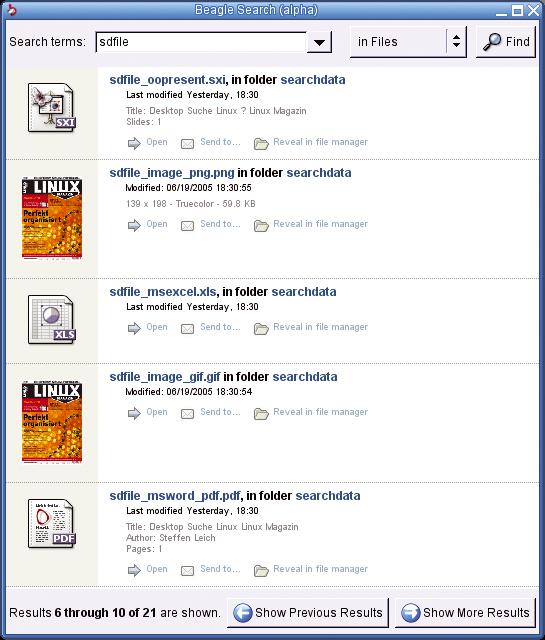
Abbildung 6: Das Beagle-GUI erinnert an Microsofts Desktop Search und zeigt den Kontext, die Bearbeitungsmöglichkeiten und je nach Typ auch eine Vorschau der Fundstellen im kompakten Ergebnisfenster an.
Beagle
Das im Linux-Bereich meistbeachtete Desktop-Suchsystem stammt von den Entwicklern des Gnome-Desktops. Obwohl noch in einem sehr frühen Entwicklungsstadium, handeln viele es bereits als die ultimative Suchmaschine für Gnome. Als Laufzeitplattform dient das Dotnet-Pendant Mono.
Beagle erfasst sowohl die Daten als auch die vollständige Kommunikation des Anwenders über verschiedene Protokolle. Die Software indiziert etwa Inhalte von Gesprächen über den Instant Messenger Gaim. Mit Beagle finden Anwender unter anderem Daten in Evolution, Gaim, Firefox sowie Dateien vom Typ Open Office, MS Office, PDF und weitere.
Crawler und Indexer laufen als permanente Prozesse, die der Beagle-Daemon »beagled« steuert. Dieser Daemon arbeitet standardmäßig sehr zurückhaltend. Das bedeutet, er bezieht die aktuelle Auslastung des Systems mit ein und nutzt nur die Idle-Perioden für seine Arbeit. Beagle verwendet als Crawler- und Indexer-Kern die Dotnet-Variante des Lucene-Framework. Für seine Echtzeitsuche nutzt das System den I-Notify-Mechanismus. Dieser als Kernelpatch implementierte Treiber stellt einen Dateisystem-Event-Monitor zur Verfügung.
Die von Beagle zu durchsuchenden Dateisysteme müssen erweiterte Attribute bereitstellen (die passende Einstellung des Kernels und die Mount-Option »user_xattr«). Die Attribute verwendet Beagle dazu, die Dateien mit Metadaten zu markieren, beispielsweise mit einem Zeitstempel.
Neben einigen Kommandozeilenwerkzeugen dient das grafische »best« (Abbildung 6) für die Eingabe der Suchdaten. Darin lassen sich bereits ausgeführte Suchen wiederholen, Datentypen auswählen und Ergebniselemente je nach Typ unterschiedlich weiterverarbeiten. Die direkte Erreichbarkeit im Desktop gewährleisten ein Taskbar-Icon und der Shortcut [F12].
Die Integration der Suchdaten und die Integration in den Desktop löst Beagle von allen Linux-Kandidaten am umfassendsten. Das System erweist sich allerdings in der aktuellen Version noch als sehr instabil, der Status ist als experimentell einzustufen.
|
Tabelle 2: Vergleich der |
|---|
|
|
Fazit
Unter Linux stehen mit Lucene und Swish-E zwei mächtige Such-Frameworks zur Verfügung, die den Grundstein für weitere Applikationen bilden. Mit X-Friend und Beagle gibt es auch flexible und gut integrierte grafische Systeme. Die große Herausforderung, eine tiefe Integration in den Desktop, bleibt noch zu meistern. Als Hürde erweist sich dabei die Linux-typische Vielfalt: Statt eines einheitlichen Desktops gibt es eine Vielzahl an Umgebungen.
Mit der Ausnahme von Apples Spotlight können die Linux-Werkzeuge denen anderer Systeme durchaus Paroli bieten. Die Diskussionen um weiter gehende Lösungen wie das Dashboard [2] oder erste Ansätze innerhalb des KDE-Projekts zeigen, dass Anwender auf noch bessere und tiefer ins System integrierte Programme hoffen dürfen. (mwe)
|
Infos |
|---|
|
[1] Rolf Strathewerd: “Finden im Sauseschritt – Swish-E”: Linux-Magazin 04/04, S. 100 [2] Dashboard: [http://www.nat.org/dashboard/] |
|
Der Autor |
|---|
|
Steffen Leich ist in einem Unternehmen der Automobilbranche für die Konzeption von internen Informationssystemen zuständig. Seit 1994 begeistert er sich für Linux. |





