
© photocase.com / grundhaerte
Monitoring-Software steht nicht selten vor dem Problem, dass die Applikation, die sie im Auge behalten soll, sich nicht auf Befragen zu ihrem Befinden äußern mag. Die rettende Alternative ist ein Blick in ihr Logfile. Dem Nagios-Plugin »check_logfiles« entgeht dabei keine Zeile.
Wer sich schon näher mit Nagios beschäftigt hat, der mag stutzen: Das gibt es doch alles längst! Die offizielle Nagios-Plugin-Sammlung enthält schließlich bereits »check_log« und zusätzlich »check_log2«. Erfindet hier ein neuer Nagios-Helfer das Rad zum dritten Mal? Nein, denn die bisher existierenden Log-Beobachter hatten ein kleines Problem: Rotierte die Applikation oder ein Skript wie üblich das Log, konnte es vorkommen, dass sie den Anschluss verpassten und ein paar Zeilen übersahen.
Ist aber wie so oft eine lückenlose Überwachung unerlässlich, dann ist dieser Lapsus sicherlich nicht tolerierbar. Deshalb hat sich »check_logfiles« das Ziel gesetzt, ausnahmslos jeden Eintrag zu prüfen, auch wenn das Log während der Beobachtung Ablageort und Namen wechselt oder in einem komprimierten Archiv verschwindet. Das neue Plugin [1] dagegen findet auch dann stets exakt die richtige Anschlussstelle.
Das ist aber noch nicht alles. Das Plugin zeichnet sich außerdem durch eine Reihe weiterer ausgeklügelter Features vor seinen Vorgängern aus. So kann es
- zwischen Suchmustern unterscheiden, die lediglich ein Warning
auslösen sollen, und solchen, die den Status
»Critical« setzen, - mit mehreren solcher Muster gleichzeitig arbeiten,
- mit speziellen Mustern umgehen, die alle zuvor gefundenen
Warnungen oder Alarme wieder aufheben, - Ausnahmen akzeptieren, die eine besondere Teilmenge eines
Suchmusters als harmlos erkennen, - Schwellenwerte berücksichtigen, die dafür sorgen,
dass Nagios nicht sofort, sondern erst ab einer vorher festgelegten
Anzahl von Treffern einen Alarm auslöst, - auf bestimmte Treffer mit Aktionen, beispielsweise einem
Neustart der Applikation, reagieren, - externe Programme integrieren (etwa »errpt« unter
AIX), deren Ausgaben es wie ein Logfile behandelt, - die Anzahl durchsuchter Zeilen und Treffer als Performancedaten
ausgeben und schließlich - gleichermaßen unter Linux, Unix und Windows laufen.
Installation
»Check_logfiles« kommt von [1] als gepackte Tar-Datei daher. Nach dem Entpacken wechselt der Installateur in das Verzeichnis »check_logfiles-2.3.1.1« und erzeugt dort mit dem bekannten Dreisatz »configure;make;make install« das Plugin. Den Schritt »configure« kann er zusätzlich mit unterschiedlichen Optionen steuern (siehe Kasten “Optionen für »configure«”).
|
Optionen für |
|---|
|
Erstes Beispiel
Das erste Beispiel sucht einfach nach dem String »BIGERROR« in einer Datei »suelzomat.log«. Das bewerkstelligt der Aufruf des Plugins mit:
check_logfiles -criticalpattern='BIGERROR'-logfile=suelzomat.log
Wenn in einer Zeile, die seit dem letzten Aufruf hinzukam, der String »BIGERROR« auftaucht, liefert das Plugin den Status »Critical«, sonst »OK«. Der String ist genauer gesagt ein regulärer Ausdruck. Statt »-criticalpattern« ließe sich auch »-warningpattern« verwenden, wie in »–warningpattern=\’SMALLERROR\’«. Als Exitcode ergäbe sich nach erfolgreicher Suche »1« für »Warning«. Selbstverständlich lassen sich beide Optionen auch gleichzeitig verwenden.
Dies erste Beispiel berücksichtigt noch keine Rotation des Logfile. Das Plugin würde diesen Fall zwar erkennen, durchsucht die wegrotierte Datei aber nicht. Wer auch die zwischen zwei Läufen von »check_logfiles« wegrotierten Dateien in die Suche einbeziehen will, sodass keine Lücken entstehen, der muss daher dem Plugin eine Hilfestellung geben, um die wegkopierten Files zu finden. Dazu dient der Parameter »-rotation«, der entweder den neuen Filenamen angibt oder einen regulären Ausdruck enthält, der auf die Namen der rotierten Files passt (Abbildung 1).
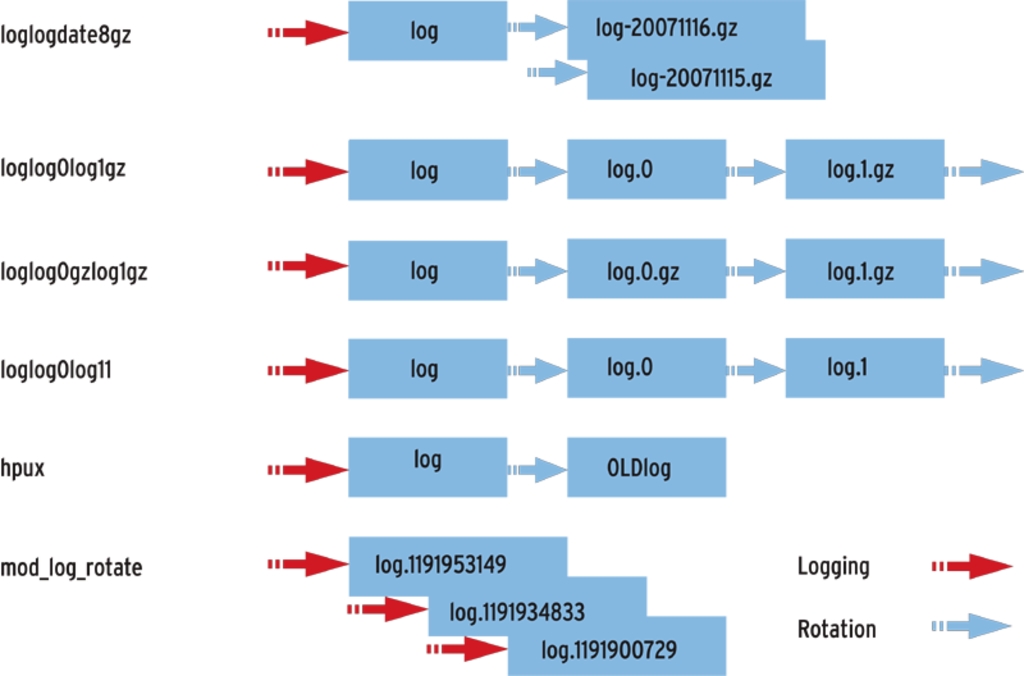
Abbildung 1: Die übliche Rotation von Logfiles macht einigen Plugins Schwierigkeiten. Unter Umständen gehen durch das Wegkopieren oder Umbenennen sogar Einträge verloren.
Angenommen die Datei »suelzomat.log« würde täglich in »suelzomat.log.0« umbenannt und dann wieder eine leere »suelzomat.log« erzeugt. Danach bekäme die vorherige »suelzomat.log.0« den Namen »suelzomat.log.1« und so weiter. In diesem Fall sorgt der Parameter »-logfile=/var/log/suelzomat.log -rotation= \’suelzomat.log.d+\’« dafür, dass das Plugin die jeweilige Vorgängerversion findet und berücksichtigt. Alternativ ließe sich auch direkt der Dateiname »suelzomat.log.0« angeben.
Nur neue Zeilen
Da »check_logfiles« immer nur Zeilen im Logfile untersucht, die seit dem letzten Lauf des Plugins hinzukamen, führen wiederholte Aufrufe zu unterschiedlichen Resultaten. Wurde beim ersten Mal ein »Critical«-Ergebnis geliefert, dann ist beim nächsten Durchlauf in der Regel wieder mit einem »OK« zu rechnen, wie in Listing 1 demonstriert. Eine passende Service-Definition für Nagios ist in Listing 2 zu sehen.
|
Listing 1: Wiederholte |
|---|
01 $ logger "test1 das ist doch 0815"
02 $ logger "das nicht, weil 0916"
03 $
04 $ check_logfiles -logfile=/var/log/suelzomat.log
--tag=0815 -criticalpattern='.*0815.*'
--rotation='loglog0log1'
05 CRITICAL - (1 errors in check_logfiles.protocol-2007-10-10-15-10-02) - Oct 1015:09:56 localhost lausser: test1 das ist doch 0815 |0815_lines=2
06 0815_warnings=0 0815_criticals=1 0815_unknowns=0
07 $
08 $ echo $?
09 2
10 $
11 $ logger "geblubber"
12 $ check_logfiles -logfile=/var/log/suelzomat.log --tag=0815 -criticalpattern='.*0815.*' --rotation='loglog0log1'
13
14 OK - no errors or warnings |0815_lines=1 0815_warnings=0 0815_criticals=0
15 0815_unknowns=0
16 $ echo $?
17 0
|
|
Listing 2: |
|---|
01 define service {
02 service_description check_0815msgs
03 host_name logserver
04 max_check_attempts 1
05 is_volatile 1
06 check_command
07 check_logfiles_critical!0815!/var/log/ suelzomat.log!loglog0log1!.*0815.*
08 }
09 define command {
10 command_name check_logfiles_critical
11 command_line $USER1$/check_logfiles
12 --logfile=”$ARG2$
13 --criticalpattern="$ARG4$" --tag="$ARG1$"
14 --rotation="$ARG3$"
15 }
|
Seine Stärken kann »check_logfiles« allerdings erst dann ausspielen, wenn es statt Kommandozeilenparameter eine Konfigurationsdatei verwendet. Das erste Beispiel benötigt die Konfigurationsdatei »gesuelze.cfg«:
@searches = ({
tag => '0815',
logfiles => '/var/log/suelzomat.log',
criticalpatterns => '.*0815.*',
rotation => 'loglog0log1',
options => 'noprotocol'
});
Das Plugin ruft der Anwender dann mit »check_logfiles -f gesuelze.cfg« auf. Wie unschwer zu erkennen ist, besteht diese Konfigurationsdatei aus Perl-Code. Die Elemente des »@searches«-Array (im Weiteren Search genannt) sind Hashreferenzen, die Logdatei und Suchmuster zusammenfassen.
Das Tag ist dabei ein eindeutiger Bezeichner, der diese Kombination identifiziert. Das Plugin benötigt ihn unter anderem, um jene Dateien voneinander zu unterscheiden, die die Statusinformation für den nächsten Lauf von »check_logfiles« speichern.
Durch die Verwendung eines Array an dieser Stelle ist es möglich, in einem Lauf von »check_logfiles« gleich mehrere Logdateien zu durchsuchen. Als Perl-Code sieht die beschriebene Konfiguration des ersten Beispiels so aus, wie in Listing 3 dargestellt.
|
Listing 3: |
|---|
01 @searches = (
02 {
03 tag => 'lamp-apache'
04 logfile => '/var/log/apache/error.log',
05 criticalpatterns => ['.*error.*, '.*fatal.'],
06 rotation => 'solaris'
07 },
08 {
09 tag => 'lamp-mysql',
10 logfile => '/var/log/mysql.log',
11 criticalpatterns => ['corruption', 'you hit a bug']
12 }
13 );
|
Soll das Plugin umgekehrt einen Alarm auslösen, wenn ein bestimmtes Muster gerade nicht im Logfile auftaucht, dann beginnt das entsprechende Pattern mit »!«. So lässt sich beispielsweise jeden Morgen prüfen, ob die nächtliche Sicherung gelaufen ist:
criticalpatterns => ['!backup successful']
Hier sind auch Ausnahmen definierbar, die zwar zunächst wie eine der gesuchten Meldungen aussehen, aber einen Sonderfall darstellen:
criticalpatterns => ['SCSI Error'], criticalexceptions => ['SCSI Error.*disk0 .*'],
Diese Einträge bewirken, dass die Meldung »SCSI Error /dev/disk5 I/O Timeout« einen Nagios-Alarm auslöst, das Plugin hingegen »SCSI Error /dev/disk0 I/O Timeout« ignoriert.
Am Ende jedes Laufs speichert das Plugin, bis zu welcher Position es ein Logfile gelesen hat und welches Änderungsdatum und welche Inode-Nummer diese Datei hat. Diese Informationen landen in einem so genannten Seekfile. Beim nächsten Lauf vergleicht das Plugin diese Daten mit den Eigenschaften des aktuellen Logfile und ermittelt, ob es gewachsen ist oder gelöscht, rotiert oder neu angelegt wurde oder ob nichts von alledem passierte.
Es geht rund
Im Falle einer Rotation sucht das Plugin die wegrotierte Archivdatei, die es ja erst noch zu Ende lesen muss, um eine lückenlose Überwachung zu gewährleisten. Je nachdem, wie lange der letzte Lauf zurückliegt, können zwischenzeitlich auch mehrere Rotationen stattgefunden haben. Anhand des Zeitstempels findet das Plugin alle Archivdateien, die in Frage kommenden.
In den meisten Fällen ist das Logfile lediglich um einige Zeilen gewachsen. »check_logfiles« fährt dann an der Stelle fort, die beim letzten Lauf das Dateiende markierte, und liest die folgenden Zeilen, bis es wiederum auf das Dateiende stößt (Abbildung 2). Dies hat insbesondere bei großen und schnell wachsenden Logfiles erhebliche Geschwindigkeitsvorteile gegenüber anderen Verfahren, die mittels »diff« die Unterschiede zwischen dem aktuellen Logfile und einer Kopie des alten suchen.
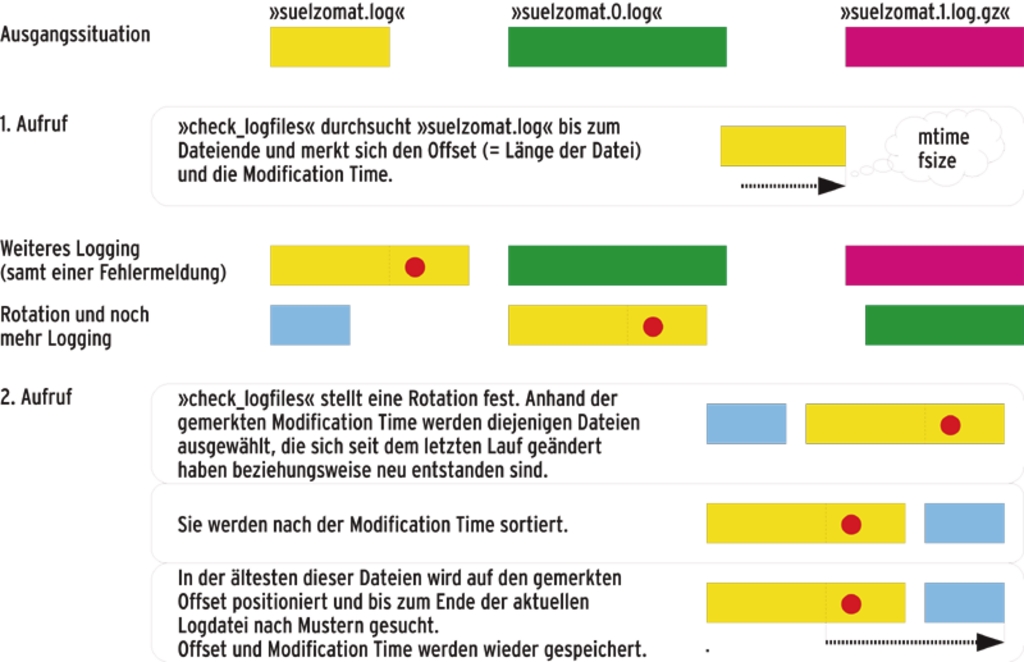
Abbildung 2: Der Log-Checker merkt sich das File und die Position, bis zu der er das Log beim letzten Aufruf gelesen hatte, und fährt genau an dieser Stelle fort.
Das Verzeichnis für die Seekfiles lässt sich mit »./configure with-seekfile-dir« vorgeben, aber auch noch zur Laufzeit über die Variable »$seekfilesdir« in der Konfigurationsdatei ändern. Per Default benutzt das Plugin »/tmp«. Es empfiehlt sich allerdings, dies in »/var/tmp« zu ändern, da bei manchen Betriebssystemen der Inhalt von »/tmp« einen Reboot nicht überlebt.
Logfile-Typen
Neben dem Parameter »rotation« kennt ein Search auch den Parameter »type«. Er gibt an, um welche Art von Logfile es sich handelt. Wenn der Rotation-Parameter existiert, dann nimmt »type« den Wert »rotation« an. Das bedeutet, dass die Archivdateien für die Suche relevant sind. Gibt es keinen Rotation-Parameter, dann nimmt »type« den Wert »simple« an. Diese Einstellung ist sinnvoll, wenn eine Applikation immer wieder ein neues Logfile verwendet und das alte löscht oder wenn der Anwender in Kauf nehmen möchte, dass die letzten Zeilen in einer wegrotierten Logdatei unbeachtet bleiben.
Ein weiterer Typ von Logfiles, den »check_logfiles« ebenfalls durchsuchen kann, ist »virtual«. Verwendet wird diese Kennzeichnung beispielsweise für das »/proc«-Filesystem von Linux-Rechnern. (Auf diese Weise lässt sich schnell eine einfache Hardware-Überwachung bauen.) Die Dateien in diesem Filesystem wachsen nicht, sondern sind so zu behandeln, als seien sie jedes Mal unmittelbar vor dem Lesen neu entstanden. Diese Logfiles durchsucht das Plugin immer vollständig. Beispiel:
@searches = (
{
tag => 'host0',
logfile => '/sys/class/scsi_host/host0/state',
type => "virtual",
criticalpatterns => [
'Link [^Up]+' # Alarm, wenn nicht "Link Up" drinsteht],
options => 'noprotocol',
},
);
Dann gibt es den Typ »errpt« zum Durchsuchen von AIX Error Reports. Damit prüft das Plugin die Ausgabe des »errpt«-Kommandos auf Pattern so, als wäre sie eine gewöhnliche Logdatei. Noch experimentell ist der Typ »psloglist«, der es erlaubt, das Event-Log eines Windows-Rechners zu durchmustern.
Die Suche nach Mustern in den Logfiles lässt sich durch weitere Parameter steuern. Die wichtigsten fasst der Kasten “Suchparameter” zusammen. Eine vollständige Aufzählung findet sich unter [1]. Die Verwendung im Konfigurationsfile demonstriert Listing 4.
|
Suchparameter |
|---|
@searches = (
{
tag => 'minor_errors',
type => 'errpt',
criticalpatterns => ['ADAPTER ERROR',
'The largest dump device is too small.',
'The copy directory is too small.',
'Kernel heap use exceeds allocation count',
'Kernel heap use exceeds percentage thres',
'LINK ERROR',
'SCSI BUS OR DEVICE ERROR',
'SCSI DEVICE OR MEDIA ERROR',
'Possible malfunction on local adapter',
'ETHERNET DOWN',
'UNABLE TO ALLOCATE SPACE IN KERNEL HEAP'
],
}
);
|
Output und Performancedaten
In der Ausgabe von »check_logfiles« finden sich Hinweise zu den Fundstellen:
CRITICAL - (3 errors in check_logfiles.protocol-2007-10-10-16-21-09) InnoDB: Database page corruption on disk or a failed... |mysql_lines=12 mysql_warnings=0mysql_criticals=3 mysql_unknowns=0
Neben dem üblichen Nagios-Exitcode ist hier an den Fortsetzungspunkten (»…«) zu erkennen, dass es noch weitere Zeilen mit Treffern gibt. Für jeden Search oder Tag liefert das Plugin außerdem einen Satz von vier Performancedaten:
- »tag_lines« ist die Anzahl der untersuchten Zeilen
des Logfile. - »tag_warnings« ist die Anzahl der Zeilen, die
Warning-Patterns enthalten. - »tag_criticals« ist die Anzahl der Zeilen, die
Critical-Patterns enthalten. - »tag_unknowns« ist die Zahl der Zeilen, die
Unknown-Patterns enthalten.
Aktionen
Die Option »script« sorgt dafür, dass ein Treffer Code ausführt:
script => 'Name_eines_Programms'
Seit Neuestem ist auch die folgende Form möglich:
script => sub { Perl-Code }
Beispiele für solche Aktionen sind der Restart von Applikationen oder das Versenden von SNMP-Traps oder NSCA-Messages. Dadurch kann »check_logfiles« auch als Standalone-Anwendung laufen und ist nicht auf die Eventhandler von Nagios angewiesen.
Mit den Parametern »scriptparams« und »scriptstdin« lassen sich die externen Skripte auch mit Kommandozeilenparametern aufrufen und sogar mit Eingaben von Stdin versorgen. Ein Beispiel gibt das Listing 5. Dort würde jedes Mal, wenn eine Fehlermeldung in einer Zeile der »messages«-Datei erscheint, diese mit dem »send_nsca«-Kommando an den Nagios-Server geschickt.
Im einfachsten Fall ist der Exitcode des externen Skripts nicht relevant, er beeinflusst den endgültigen Exitcode von »check_logfiles« selbst daher nicht. Sollte also im Beispiel von Listing 4 der Restart der Suelzomat-Applikation erfolgreich verlaufen sein, dann meldet »check_logfiles« trotzdem »Critical« an Nagios weiter.
|
Listing 4: Parameter in der |
|---|
01 $ cat gesuelze.cfg
02 @searches = ({
03 tag => '0815',
04 logfile => '/var/log/suelzomat.log',
05 archivedir => '/var/log/archives',
06 rotation => 'loglog0gzlog1gz',
07 criticalpatterns => '.*0815.*',
08 criticalexceptions => '.*0815 macht aber nix.*',
09 warningpatterns => ['.*failure.*', '!successful'],
10 warningthreshold => 10,
11 okpatterns => '.*cleared.*',
12 options => 'case,noprotocol,script'
13 script => 'restart_suelzomat'
14 });
|
|
Listing 5: |
|---|
01 $scriptpath = '/usr/bin/nagios/libexec:/usr/local/nagios/contrib';
02 $MACROS = {
03 CL_NSCA_HOST_ADDRESS => "lpmon1.muc",
04 CL_NSCA_PORT => 5778
05 };
06
07 @searches =(
08 {
09 tag => 'suelz',
10 logfile => '/var/log/suelzomat.log',
11 criticalpatterns => ['ERROR', 'crashed'],
12 script => 'restart_suelzomat',
13 scriptparams => '--suelzprefix=bla',
14 options => 'script'
15 },
16 {
17 tag => 'san',
18 logfile => '/var/adm/messages',
19 criticalpatterns => [
20 'Link Down Event received',
21 'Loop OFFLINE',
22 'fctl:.*disappeared from fabric',
23 '.*Lun.*disappeared.*'
24 ],
25 options => 'script',
26 script => 'send_nsca',
27 scriptparams => '-H $CL_NSCA_HOST_ADDRESS$ -p $CL_NSCA_PORT$ -to $CL_NSCA_TO_SEC$ -c $CL_NSCA_CONFIG_FILE$',
28 scriptstdin => '$CL_HOSTNAME$t$CL_SERVICEDESC$t$CL_SERVICESTATEID$t$CL_SERVICEOUTPUT$n',
29 });
|
Der Admin kann nun mit der Option »smartscript« dafür sorgen, dass der Exitcode des externen Skripts in das Endergebnis einfließt. Dabei tut das Plugin so, als fände es unmittelbar nach der auslösenden Trefferzeile eine weitere Zeile, deren Text der ersten Zeile der Skriptausgabe und deren Bewertung dem Exitcode des Skripts entspricht. Damit lässt sich jedoch nur ein zusätzlicher Fehler erzeugen, nicht aber die ursprüngliche Meldung im Logfile ungeschehen machen oder neu bewerten.
Die dritte Möglichkeit ist die Option »supersmartscript«. Solche Skripte ersetzen mit ihrem Exitcode und Output den auslösenden Treffer im Logfile, anstatt ihn zu ergänzen. Dem Skript stehen dazu mehrere Environment-Variablen zur Verfügung:
- »CHECK_LOGFILES_SERVICEOUTPUT«: Inhalt der
auslösenden Zeile - »CHECK_LOGFILES_SERVICESTATE«:
»Warning«, »Critical«,
»Unknown« oder »OK« - »CHECK_LOGFILES_SERVICESTATEID«: 0, 1, 2 oder
3
Mit Hilfe dieser Informationen und weiterer Daten wie der Uhrzeit oder dem Ergebnis des Applikationsrestarts lässt sich eine Neubewertung der Fehlermeldung erreichen. Der Logfile-Checker kann auf diese Weise zum Beispiel den Zustand »Critical« auf »Warning« zurückstufen oder mit einem Exitcode von »0« sogar ganz aus der Welt schaffen. Ein Beispiel findet sich in Listing 6.
Aktionen lassen sich auch auslösen, noch bevor die Suche in Logfiles startet oder nachdem alle Suchvorgänge abgeschlossen sind. Dazu gibt es den Parameter »§prescript«, der wie gehabt auf ein externes Skript oder eine Perl-Subroutine verweist.
|
Globale Parameter |
|---|
|
Neben den Parametern, die zu einem Search-Eintrag gehören, gibt es auch globale Variablen, die von allen Searches gelesen werden oder das Verhalten des Plugins unabhängig von einzelnen Suchvorgängen bestimmen:
|
Prescripts und Postscripts
Supersmart-Prescripts brechen den Lauf von »check_logfiles« komplett ab, wenn der Exitcode größer als null ist. So ließe sich beispielsweise zuerst prüfen, ob ein bestimmter Prozess überhaupt läuft. Läuft er nicht – wozu dann noch im Logfile der zugehörigen Applikation nach Fehlern suchen?
Supersmart-Postscripts können das Endergebnis von »check_logfiles« komplett austauschen, egal wie viele Error-Messages vorher zu finden waren. Auch hier stehen Informationen in Environment-Variablen zur Verfügung:
- »CHECK_LOGFILES_SERVICEOUTPUT« : Output des
Plugins - »CHECK_LOGFILES_SERVICEPERFDATA«:
Performancedaten - »CHECK_LOGFILES_SERVICESTATE«:
»Warning«, »Critical«,
»Unknown« oder »OK« - »CHECK_LOGFILES_SERVICESTATEID«: 0, 1, 2 oder
3 - »CHECK_LOGFILES_PROTOCOLFILE«: Name des
Protokoll-File
Wem die Standardform der Ausgabe von »check_logfiles« nicht gefällt, der kann sie mit Hilfe eines Supersmart-Postscript nach seinen Wünschen umformulieren oder aussagekräftiger gestalten. (jcb)
|
Infos |
|---|
|
[1] Check_logfiles: [http://www.consol.de/opensource/nagios/check-logfiles] |
|
Der Autor |
|---|
|
Gerhard Laußer arbeitet als Mädchen für alles beim Münchner IT-Unternehmen Consol. Sein erstes Linux installierte er 1992 von einem Stapel Disketten. Er betreute 2003 die Linux-Einführung bei einem großen Automobilhersteller und hat dort auch eine umfangreiche Nagios-Installation aufgebaut. Seine Hobbys sind sein Beruf und die Natur. |





