
© Terebenthine, Fotolia.com
Immer mehr Linux-Systeme nutzen UTF-8 statt ISO-8859 für die Zeichenkodierung. Beim Update einer Distribution entsteht ohne Konvertierung schnell Datenmüll. Ein Migrationsleitfaden.
Eine globalisierte Welt braucht geeignete Mittel, um sich auszudrücken. Im Bereich von Zeichensätzen unterstützen mittlerweile fast alle Anwendungen die Kodierung UTF-8 von Unicode, sie muss nur aktiviert sein. Auch haben viele Distributionen ihre Default-Kodierung von der ISO-8859-Familie in UTF-8 geändert. In Fedora, Open Suse und den Ubuntu-Varianten ist UTF-8 schon länger die Voreinstellung, zuletzt hat auch Debian mit der Version 4.0 diesen Schritt gewagt.
Unicode wird zum Standard
Für Anwender, die sich nur in einer einzigen Umgebung bewegen, ist die Verwendung der Zeichenkodierung transparent, weil dann sowohl Eingabegeräte wie Tastaturtreiber, verarbeitende Programme wie Editoren als auch Anzeige- und Ausgabewerkzeuge wie Terminalfenster von den gleichen Gegebenheiten ausgehen. In diesem Fall funktioniert die Zusammenarbeit normalerweise problemlos.
Trickreicher wird es, wenn ein Anwender auf zwei Systemen unterschiedlicher Kodierung gleichzeitig arbeitet. Läuft der Admin-Desktop unter Kubuntu 7.10, der Webserver jedoch aus Stabilitätsgründen noch unter Debian 3.1, sind Schwierigkeiten programmiert. Das Terminalprogramm am Desktop erwartet in diesem Szenario vermutlich UTF-8-Zeichen, die Programme auf dem Server, auf den sich der Admin beispielsweise mit der Secure Shell einloggt, produzieren ihre Ausgaben jedoch in der Kodierung ISO-8859-15. Die Situation erinnert an die Sprachverwirrung im biblischen Babylon.
Auch wenn der Admin ein Upgrade eines ehemaligen ISO-Systems auf Unicode durchführt, beispielsweise bei der Aktualisierung auf die aktuelle Debian-Version 4.0, liegt die Tücke im Detail. Viele Benutzer haben ihre Texte in ISO-Kodierung verfasst und einige haben vielleicht Umlaute in Dateinamen verwendet. Das Übertragen solcher Dateien macht eine Konvertierung notwendig.
Für ein Programm ist ein String nur eine Folge von Einzelbytes. Eine direkte Zuordnung von einem Byte in der Zeichenkette zu einem darstellbaren Zeichen gibt es in UTF-8 nicht mehr in jedem Fall. So werden zwar die 128 Zeichen des Ascii-Code auch in UTF-8 in der gleichen Weise repräsentiert, aber bereits der Umlaut ä besteht aus den beiden Bytes 0xC3 und 0xA4. In ISO-8859-15 reichte dazu noch das eine Byte 0xE4.
Zeichendarstellung
Jedes Programm muss daher wissen, wie es eine Bytefolge zu interpretieren hat. Im einfachsten Fall kennt die Datei selbst ihre Kodierung. In E-Mail-Nachrichten findet sich beispielsweise oft ein Header mit dem so genannten Encoding-Type. Andere Programme – wie zum Beispiel Textverarbeitungen – speichern die Kodierung zumeist irgendwo im Dateiformat.
Liegt eine konkrete Angabe der Kodierung nicht vor, nutzen Anwendungen den Locale-Mechanismus, der mehrere Umgebungsvariablen ausliest. Er stellt in der Libc diverse Bibliotheksfunktionen bereit, damit nicht jedes Programm das Rad neu erfinden muss (siehe Kasten “Bibliotheksfunktionen …”).
|
Bibliotheksfunktionen mit |
|---|
|
Eine Reihe von Bibliotheksfunktionen unterstützt Entwickler und Anwender dabei, Anwendungen zu lokalisieren. Je nach Belegung der Umgebungsvariablen »LC_CTYPE« reagieren unter anderem die folgenden Funktionen auf die angegebene Kodierung:
|
Das Kommando »locale« ohne Argumente gibt die Umgebungsvariablen aus, die das System zur Lokalisierung verwendet. Die Variablen definieren neben der Zeichenkodierung auch die Sprache für Textausgaben von Programmen, Zeitformate, das Trennsymbol für Dezimalzahlen, Sortierreihenfolgen und vieles mehr. Der Befehl »locale -a« zeigt die vorhanden Lokalisierungen (Englisch Locales) auf dem System an. Der Administrator legt die Locales an, bevor der Benutzer sie wählen kann. Dies geschieht auf Debian-basierten Systemen durch den Root-Benutzer mittels »dpkg-reconfigure locales«.
Dort wählt der Admin die gewünschten Locales aus, die der Paketmanager dann eventuell nachinstalliert. Unter Ubuntu kann er die Liste der unterstützten Locales der Datei »/usr/share/i18n/SUPPORTED« entnehmen und eine weitere Locale beispielsweise mit »locale-gen de_DE@euro« erzeugen.
Relevant für die Zeichenkodierung ist die Variable »LC_CTYPE«. Auf einem ISO-8859-15-System ist beispielsweise
LANG=de_AT@euro LC_CTYPE="de_AT@euro"
eingestellt, auf einem UTF-8-System hingegen:
LANG=de_AT.utf8 LC_CTYPE="de_AT@utf8"
Der erste Teil des Wertes, hier »de« für Deutsch, gibt die Sprache an und verwendet Codes, die der ISO-639-1-Standard festlegt [2]. Der folgende Abschnitt gibt nach ISO-3166-1 das Land an, im Beispiel »AT« für Österreich [3].
Der dritte Teil definiert die Zeichenkodierung, also beispielsweise »@euro« für die europäische Erweiterung von ISO-8859-15 oder »@utf8« für die häufigste Kodierung von Unicode. Die Kodierung nach UTF-8 sorgt dafür, ein Unicode-Zeichen in eine Folge von einem bis zu vier Bytes abzubilden. Andere Kodierungen bilden die Zeichen aus Unicode in einer anderen Weise ab, beispielsweise UTF-16 immer in Paaren von zwei Bytes.
Die systemweite Voreinstellung der Lokalisierung findet üblicherweise in der Datei »/etc/environment« statt. Der Befehl »dpkg-reconfigure« erledigt den Eintrag bereits mit.
Terminalprogramme
Eine gern genutzte Schnittstelle zwischen Mensch und Maschine ist das Terminalprogramm. Es nimmt die rohen Tastenanschläge entgegen und erzeugt daraus Zeichenfolgen, die über die Standardeingabe beispielsweise an die Shell gelangen. Umgekehrt verarbeitet das Terminalprogramm die Ausgaben der in der Shell laufenden Programme und stellt die entsprechende Glyphen auf dem Bildschirm unter Berücksichtigung der Kodierung dar.
Der Betriebsmodus der meisten Programme richtet sich nach der Locale-Einstellung beim Programmstart. Wenn ein Terminalprogramm wie »xterm«, »konsole« oder »gnome-terminal« also auf eine andere Kodierung umschalten soll, bekommt das Terminal dies vor dem Programmstart per Environment mitgeteilt:
export LANG=de_DE@UTF8 xterm &
Diese Angaben in der neu geöffneten Shell zu machen, hat für das Terminalprogramm selbst keine Auswirkungen, sondern nur für danach aufgerufene Programme. Die besseren Terminalprogramme können allerdings über Menüs auch zur Laufzeit ihre Kodierung ändern. Bei »konsole« geht dies über »Einstellungen | Kodierung | Unicode (utf8)«.
Zwischen zwei Welten
Die tückischen Probleme entstehen erst, wenn Anwender Systeme benutzen, auf denen unterschiedliche Kodierungsschemata laufen. Das ist insbesondere der Fall, wenn ein Netzwerklogin beispielsweise mittels »ssh« stattfindet. Die entfernten Programme erzeugen Zeichen in einer anderen Kodierung als das Anzeigeprogramm, das Terminal, sie erwartet. Dies führt zu einer unleserlichen Anzeige von E-Mails oder Texten.
Ein Lösungsansatz ist, das entfernte System auf die Locale am Client umzustellen. Die Secure Shell kann beispielsweise den Inhalt der wichtigsten Umgebungsvariablen an das Zielsystem übertragen. Auf dem Client muss dazu der Eintrag
SendEnv LANG LC_*
in der Datei »/etc/ssh/ssh_config« stehen. Umgekehrt sollte das Zielsystem diese Angaben mit der entsprechenden Direktive »AcceptEnv« auch annehmen. Dieser Weg funktioniert natürlich nur, wenn auf dem Server die gleiche Locale wie auf dem Client aktiv ist.
Wer diesen Weg einschlägt, sollte darauf achten, dass die Startskripte der Shells, beispielsweise ».bashrc«, ».profile« oder ».login«, die Eintragungen nicht gleich wieder zunichtemachen. Feste Definitionen der beschriebenen Umgebungsvariablen sollten Anwender daher am besten aus ihren Dateien löschen. Dies gilt auch für einige Variablen spezieller Anwendungen wie »LESSCHARSET«, die noch aus Zeiten vor dem Locale-System stammen. Heute benutzen praktisch alle Anwendungen die standardisierten Variablen »LANG« und das davon abgeleitete »LC_CTYPE« für die Kodierung.
Andere Netzwerktools wie Telnet übertragen jedoch nicht die Umgebungsvariablen der Zeichenkodierung. In diesem Fall müsste das Zielsystem eine Heuristik besitzen, die beispielsweise abhängig vom Ursprung des Login die Kodierung setzt. Diese Verfahren sind generell recht fehleranfällig, Administratoren sehen das Übertragen von Umgebungsvariablen selbst bei »ssh« durchaus kritisch. Daher raten einige Experten dazu, die jeweils voreingestellten Locales auf allen Systemen beizubehalten und am Terminal die Kodierung entsprechend zu wählen.
Den Umstieg wagen
Besser als die Verwaltung eines Mangels ist natürlich dessen Beseitigung. Da heute die meisten Anwendungen mit Unicode und UTF-8 zurechtkommen, steht aus funktionaler Sicht kaum etwas gegen einen Umstieg auf Unicode. Alle modernen Distributionen bieten die Kodierung als Default an. Es bleibt die Migration bestehender Dateien, die bestimmte Zeichen in den verschiedenen Kodierungen unterschiedlich darstellen. Enthalten beispielsweise Dateinamen Sonderzeichen oder Umlaute, zeigt das System diese nach der Umstellung der Locale falsch an. Die Benutzer müssen sie manuell oder mit einem Tool umbenennen. Debian (in Testing und Unstable) und Ubuntu (in Universe) stellen ein Hilfmittel zur Konvertierung von Dateien nach UTF-8 zur Verfügung (siehe Abbildung 1).
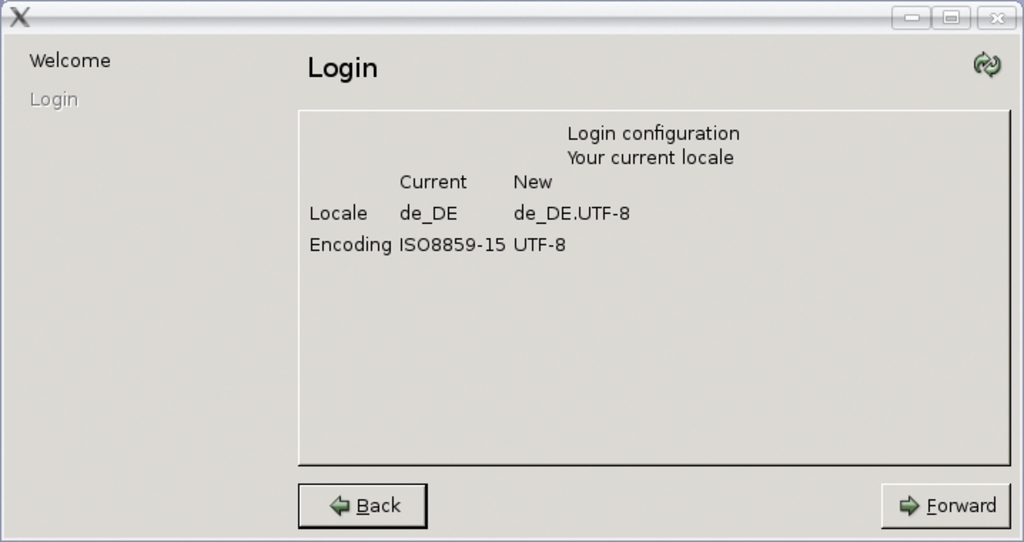
Abbildung 1: Das Migrationswerkzeug »utf8migrationtool« hilft dem Benutzer bei der Konvertierung von alten Kodierungen.
Vor dem Aufruf ist darauf zu achten, dass sowohl die alte, in der die bisherigen Dateien kodiert sind, als auch die gewünschte neue Locale UTF-8 vorhanden sind. Ist dies nicht der Fall, sind sie zu erzeugen. Vor dem Aufruf setzt der Administrator die Locale noch auf den Wert der alten Kodierung:
export LANG=de_DE@euro utf8migrationtool
Wer sichergehen will, fertigt vor dem Starten von »utf8migrationtool« ein Backup an. Das Programm sucht im Verzeichnis des Nutzers nach Dateien mit Sonderzeichen und listet sie auf. Nach einer Bestätigung benennt das Tool sie um (Abbildung 2). Wer nun die Locale auf UTF-8 umstellt, wird mit einer richtigen Darstellung belohnt.
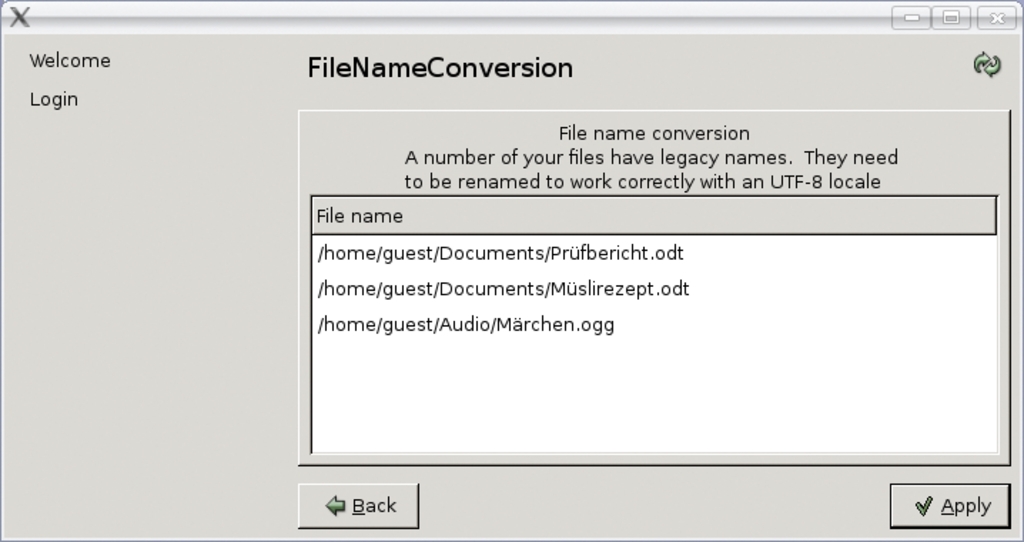
Abbildung 2: Dateien mit zu konvertierenden Zeichen im Namen schlägt das Werkzeug vor und bittet den Anwender sie zu bestätigen.
Das Migrationstool verändert nur Dateinamen, keine Inhalte. Mit Bordmitteln lässt sich jedoch auch der Inhalt von Dateien konvertieren, die in Textform vorliegen. Binärdateien sind auf diese Weise nicht konvertierbar. Komplexere Dateiformate wie Open Document bedürfen keiner Konvertierung, da die Kodierung in diesen Dateien bereits abgelegt ist.
Inhalte umwandeln
Da oft eine größere Menge an Dateien zu konvertieren ist, bietet es sich an, zunächst eine Liste der betroffenen Dateien anzulegen. Das Kommando »file« kann dabei helfen. Dieses Programm versucht zu erraten, in welcher Kodierung eine Datei vorliegt. Das ist nicht immer zuverlässig möglich und sollte daher noch einmal kontrolliert werden.
Die Befehlszeile »find $HOME -exec file {} ;« wendet das beschriebene Tool auf alle Dateien im eigenen Homeverzeichnis an. Ein Auszug der Ausgabe könnte beispielsweise so aussehen:
/home/guest/datei-1: ASCII text /home/guest/datei-2: ISO-8859 text /home/guest/datei-3: UTF-8 Unicode text
Ascii-Dateien bleiben unverändert, die Angabe »UTF-8« zeigt bereits konvertierte Dateien an. Es erwarten also nur Dateien mit der Bezeichnung »ISO-8859« eine Umwandlung. Darauf aufbauend kann sich jeder Anwender eine Liste von Kandidaten zusammenstellen (siehe Listing 1). Es empfiehlt sich, mit einem Texteditor zu überprüfen, ob alle vorgeschlagenen Kandidaten zu Recht auf der Liste stehen. Auch hier bietet sich zur Sicherheit ein Backup an.
|
Listing 1: Suche nach |
|---|
01 #!/bin/sh
02
03 if [ -z $1 ]
04 then
05 startdir=$HOME
06 else
07 startdir=$1
08 fi
09
10 find . -exec file {} ; | grep 'ISO-8859 text$' |
11 sed 's/: ISO-8859 text$//' > kandidaten
|
Das Kommando »recode« kann Dateien zwischen vielen gängigen Kodierungen hin und her konvertieren. Eine Liste der verfügbaren Kodierungen zeigt »recode -l« an. Im folgenden Beispiel bezeichnet »latin9« die ISO-Kodierung (inklusive Euro-Zeichen), »utf8« ist die Schreibweise für die Zielkodierung:
xargs -l1 recode latin9..utf8 < kandidaten
Wer mutig ist, lässt durch diesen Aufruf alle Kandidaten zugleich umwandeln.
Mühsame Konvertierung
Das Umwandeln aller Dateien bedeutet im Allgemeinen eine gewisse, dafür aber einmalige Mühe. Auf Dauer zahlt sich der Aufwand jedoch aus, da abzusehen ist, dass Unicode der zukünftige Standard auf immer mehr Computern sein wird. Die meisten Anwendungen und Distributionen bieten heute hinreichende Unterstützung dazu an. Nach einer Umwandlung, die mit Unterstützung durch Tools die Benutzer auch selbst bewältigen können, ist in absehbarer Zeit dieses Thema abgehakt. Die Globalisierung kann kommen.
|
Infos |
|---|
|
[1] Bruno Haible, Oliver Frommel, “In fremden Zungen”: Linux-Magazin 10/04, S. 118 [2] Abkürzungen für Sprachen nach ISO 639: [http://de.wikipedia.org/wiki/ISO_639] [3] Abkürzungen für Länder nach ISO 3166: [http://de.wikipedia.org/wiki/ISO_3166] [4] Locale-Support der Glibc:[http://www.gnu.org/software/libc/manual/html_node/Locales.html#Locales] [5] Einführung in die Lokalisierung:[http://www.debian.org/doc/manuals/intro-i18n/] |
|
Der Autor |
|---|
|
Kester Habermann arbeitet als Software-Entwickler bei der ESOC in Darmstadt. Als Referent für den technischen Betrieb beim Linuxtag e. V. verantwortet er die IT-Systeme des Vereines. |





