
Wer in seinen Programmen interessante Daten aus Webseiten weiterverarbeiten will, braucht einiges Geschick beim Herausfischen dieser Inhalte aus dem Sumpf von Formatierungsinfos, Abbildungen und interaktiven Abfragen. Tcl und eine Hand voll Module verhelfen ihm zu Angler-Ruhm und -Ehre.
Viele Daten-Fundgruben im Web oder im Intranet bereiten ihre Inhalte vor allem optisch auf – hübsche Seiten, die dem Auge des Betrachters schmeicheln. Für automatische Auswertungen braucht ein Programm die relevanten Informationen aber ohne Schnörkel und sauber in Häppchen zerlegt.
Idealerweise stellen Webserver dazu ihre Daten zusätzlich per SOAP bereit ([1], Simple Object Access Protocol). Wer diese glückliche Lage nicht vorfindet, schreibt kurzerhand eigene Tools, um die relevanten Daten aus der Seite zu extrahieren. Zwei Beispiele zeigen im Folgenden den kompletten Prozess vom Laden der Seite (was bei interaktiven Anwendungen schon eine Herausforderung ist) bis zum gezielten Aufspüren der gesuchten Daten (bei komplexen HTML-Layouts keine einfache Aufgabe).
Als Datenquelle für die Tcl-Skripte dienen die Pegelstände der Elbe bei Hamburg St. Pauli (Abbildung 1) sowie die Suchseite des Tclers Wiki (Abbildung 2).
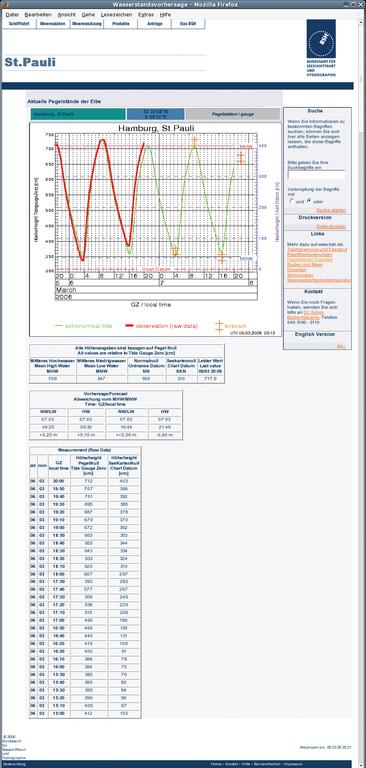
Abbildung 1: Auf seiner Webseite veröffentlicht das BSH (Bundesamt für Seeschifffahrt und Hydrographie) unter anderem die Pegelstände der Messstation Hamburg St. Pauli. Ein Tcl-Skript extrahiert daraus die einzelnen Messwerte.
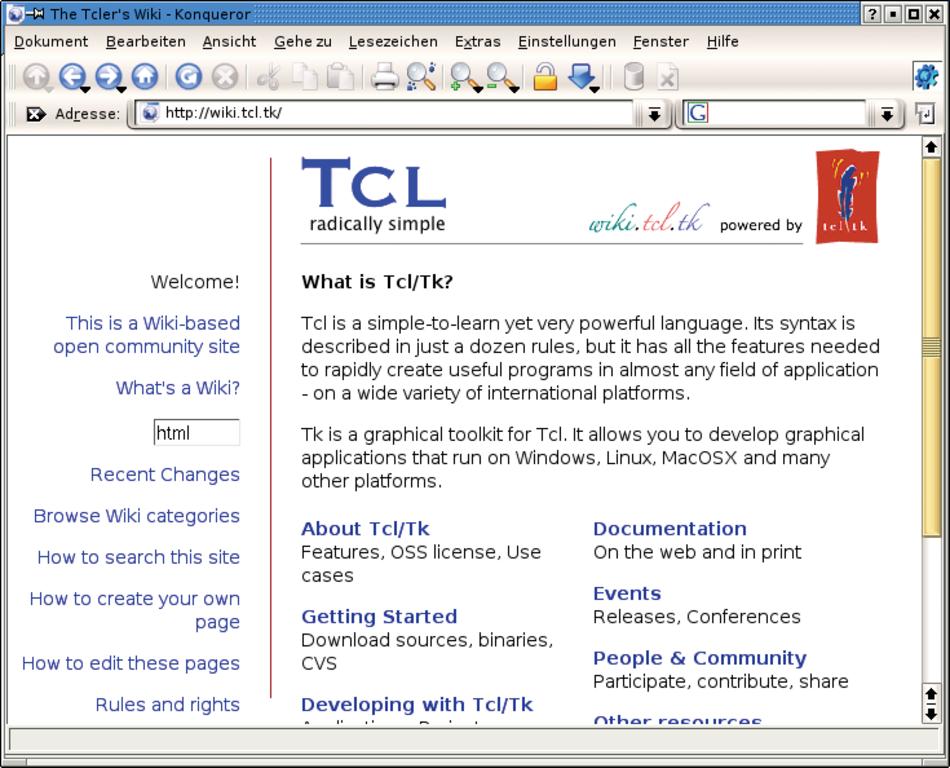
Abbildung 2: Auf der Eingangsseite des Tclers Wiki darf der Besucher nach beliebigen Stichworten suchen (rot umrahmt). Um diesen Ablauf nachzubilden, muss ein Skript die passende HTTP-Anfrage stellen.
Hergezaubert
Es gibt viele Möglichkeiten, Webseiten vom Server zu erhalten. Angefangen beim Abspeichern aus dem Browser über spezielle Programme wie Wget [2] bis zur direkten Kommunikation mit Tcl-Bordmitteln. Die Seite per Browser speichern ist sinnvoll, wenn der Anwender den Inhalt der Seite nur einmal benötigt. Erwartet die Webseite jedoch Parameter von dem Programm oder ändert sich der Inhalt häufig, dann ist das Abholen per Tcl bei weitem bequemer. Das klappt für einfache statische Seiten ebenso wie für dynamische Anfragen an einen Server, bei denen gewöhnlich der User ein Formular ausfüllt.
Auf seiner Webseite [3] stellt das Bundesamt für Seeschifffahrt und Hydrographie (BSH) die aktuellen Pegelstände der Elbe für die Station Hamburg St. Pauli bereit. Wie in Listing 1 zu sehen, ist das Laden einer Seite mit fester Adresse sehr einfach. Das Tcl-Skript verwendet dazu das »http«-Paket (Zeile 3), es gehört zum normalen Lieferumfang.
Der Befehl »http::geturl« lädt Dokumente von einem Webserver. Im einfachsten Fall genügt es, die URL anzugeben. Damit bei langsamen Netzverbindungen und überlasteten Servern das Programm nicht beliebig lange wartet, sorgt die »timeout«-Option (Zeile 10) dafür, dass der Befehl nach spätestens 10 Sekunden abbricht. Das Resultat ist in beiden Fällen ein Array mit den Server-Antworten. Es enthält neben dem Inhalt die Statusinformationen der Anfrage.
|
Listing 1: Pegelstände in |
|---|
01 #!/usr/bin/tclsh
02
03 package require http
04 package require dom
05
06 ### Seite herunterladen
07 set url "http://www.bsh.de/aktdat/wvd/StPauli_pgl.htm"
08
09 # Timeout in Millisekunden
10 set abfrageID [::http::geturl $url -timeout 10000]
11
12 if [string match ok [http::status $abfrageID]] {
13 set inhalt [::http::data $abfrageID]
14 ::http::cleanup $abfrageID
15 } else {
16 puts stderr "Laden der Seite $url fehlgeschlagen"
17 puts stderr [http::status $abfrageID] [http::error $abfrageID]
18 ::http::cleanup $abfrageID
19 exit 1
20 }
21
22 ### Messwerte auslesen
23 # Überflüssiges »</form>«-Element löschen
24 set zeilen [split $inhalt "n"]
25 set out [open pegel.html w]
26 foreach zeile $zeilen {
27 if [regexp {^</form>} $zeile] {
28 puts stderr "Lösche $zeile"
29 } else {
30 puts $out $zeile
31 }
32 }
33
34 # Tidy aufrufen, um sauberes XML zu erhalten
35 if [catch {exec tidy -utf8 -i -o sauber.xml -asxhtml pegel.html} res] {
36 #puts $res
37 }
38
39 # In DOM einlesen
40 set fd [open sauber.xml]
41 set inhalt [read $fd]
42 close $fd
43 set doc [dom::parse $inhalt]
44
45 # Die Tabelle mit Pegelständen findet sich unter XPath:
46 # html/body/table/tr[5]/td/table/tr/td[2]/table/tr/td/table/tr[3]/td[2]/table[5]
47
48 # Teil 1: html/body/table/tr[5]
49 set trs [dom::selectNode $doc //html/body/table/tr]
50 set tr [lindex $trs 4]
51 # Teil 2: td/table/tr/td[2]
52 set tds [dom::selectNode $tr td/table/tr/td]
53 set td [lindex $tds 1]
54 # Teil 3: table/tr/td/table/tr[3]
55 set trs [dom::selectNode $td table/tr/td/table/tr ]
56 set tr [lindex $trs 2]
57 # Teil 3: td[2]
58 set tds [dom::selectNode $tr td]
59 set td [lindex $tds 1]
60 # Teil 4: table[5]
61 set tables [dom::selectNode $td table]
62 set table [lindex $tables 4]
63
64 ### In CSV abspeichern
65 set fd [open pegelstand.csv w]
66 puts $fd "# Tag; Monat; Zeit; Pegelnull; Seekartennull"
67 foreach zeile [lrange [dom::selectNode $table tr] 2 end] {
68 foreach zelle [dom::node children $zeile] {
69 switch [dom::node cget $zelle -nodeName] {
70 th -
71 td {
72 set text [string trim [dom::node stringValue $zelle]]
73 puts -nonewline $fd "$text;"
74 }
75 default {# andere Knoten ignorieren}
76 }
77 }
78 puts $fd ""
79 }
80 close $fd
|
Internetverbindungen arbeiten nicht immer zuverlässig, deshalb prüft in Zeile 12 der Aufruf »http::status« erst einmal den Zustand der Abfrage. Ist er okay, gibt »http::data« die vom Webserver gelieferten Daten aus. Das Programm speichert sie in der Variablen »inhalt« (Zeile 13). Im Fall eines Fehlers schreibt das Skript die Gründe für den Fehlschlag auf Stderr (falsche URL, Timeout und so weiter) und beendet sich. Nach dem Auswerten des Array löscht »http::cleanup« dessen Daten, um Speicher zu sparen. Insbesondere bei großen Dateien ist dieser Schritt ratsam.
Formularfrage
Statische Webseiten sind der einfachste Fall. Häufig präsentieren die Server ihre Informationen aber erst, nachdem der Besucher Daten in ein Formular eingetippt hat. Ein Beispiel hierfür ist das Tclers Wiki. Wie auf modernen Webseiten üblich enthält es eine Suchfunktion. Damit ein Tcl-Skript wie ein Webbrowser seine Anfrage an den Server stellen kann, muss der Programmierer die Zieladresse und die benötigten Parameter kennen. Am einfachsten erfährt er dies aus dem HTML-Code der Formularseite. Gerade bei Formularen verstecken sich die Parameter allerdings oft tief in der Formatierung.
Eingabefelder liegen bei HTML innerhalb eines »form«-Tag. Dies enthält die Definition von Eingabefeldern für Text (»input«-Tag), Comboboxen (»select«-Tag) oder Checkboxen (»input«-Tag vom Typ »radio«). Neben den Eingaben tragen manche Formulare zusätzliche Parameter, die der Benutzer nicht sieht (»input«-Tag, Typ »hidden«), der Browser aber unverändert an den Server übergibt. Eine gute Einführung in die genaue Definition von Formularen findet sich in der HTML-Bibel Selfhtml [4].
Gib’s mir
Normale HTTP-»GET«-Anfragen kodieren die Parameter aus dem Formular als der Teil der URL, sie folgen auf ein Fragezeichen am Ende der Adresse. In Abbildung 2 will der Anwender nach dem Stichwort »html« suchen, Abbildung 3 zeigt das Ergebnis dieser Aktion. Die Anfrage entspricht der Form Parameter=Wert, in diesem Fall »Q=html«. Bei mehreren Parametern trennt ein kaufmännisches Und (&) die Paarungen.
Abbildung 2: Auf der Eingangsseite des Tclers Wiki darf der Besucher nach beliebigen Stichworten suchen (rot umrahmt). Um diesen Ablauf nachzubilden, muss ein Skript die passende HTTP-Anfrage stellen.
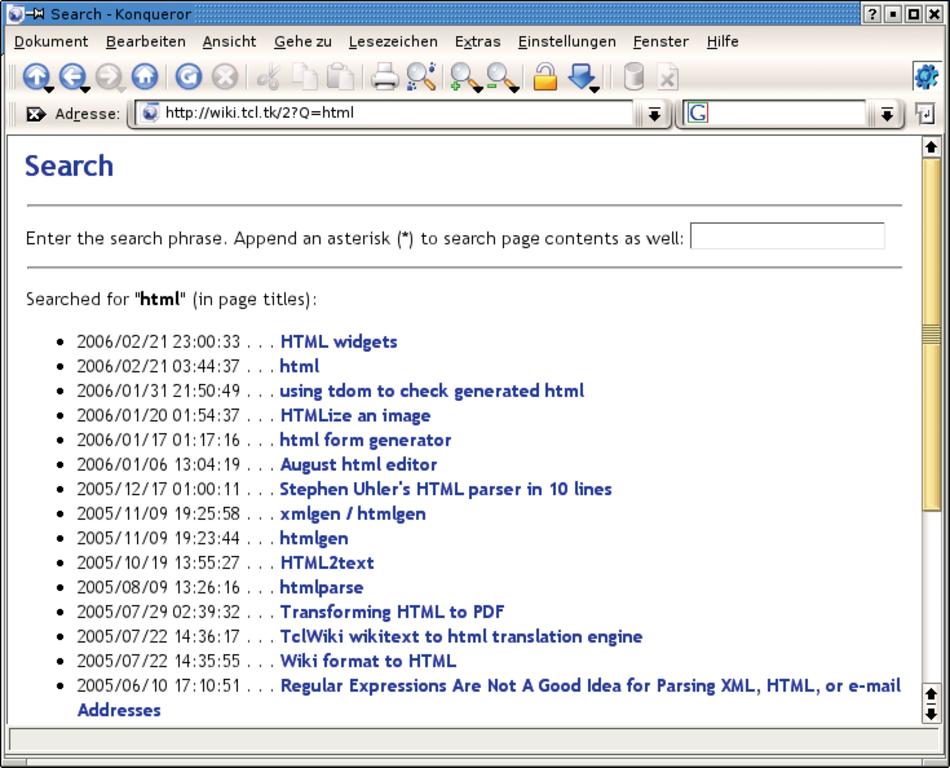
Abbildung 3: Die Antwort auf die Suchanfrage aus Abbildung 2. In der Adresszeile sind nun die Parameter des GET-Aufrufs zu sehen (rot umrahmt).
Damit die Werte auch Frage-, Gleichheits- oder andere Sonderzeichen enthalten dürfen, ohne dass der Server sie als Trennsymbol interpretiert, wandelt der Aufruf »http::formatQuery« diese Zeichen in die URL-Encoded-Darstellung. Aus den paarweise angegebenen Parametern und Werten erzeugt der Aufruf eine Anfrage für den Server (Listing 2, Zeile 8). Zeile 9 legt die URL zusammen mit dem Fragezeichen als Trenner fest und Zeile 10 befragt mittels »http::geturl« den Server nach der URL inklusive Parameter.
Nicht bei allen Formularen genügt diese simple Anfrage. Das HTTP-Protokoll bietet genügend Fallstricke, etwa Redirects oder POST-Requests. Auch solche Fälle beherrscht das »http«-Package, Beispiele finden sich im Tclers Wiki [5] und [6]. Reagiert der Server nur mit wilden Fehlermeldungen, lohnt es sich manchmal, die Kommunikation zwischen einem normalen Browser und dem Server zu belauschen. Wer über Root-Rechte verfügt, findet in Ethereal [7] das geeignete Programm, der Rest kommt mit Sockspy [8] ebenfalls zum Ziel.
|
Listing 2: Suche im Tclers |
|---|
01 #!/usr/bin/tclsh
02
03 package require http
04
05 ### Seite herunterladen
06 set suchwort html
07 puts "Suche nach »$suchwort«"
08 set anfrage [http::formatQuery Q $suchwort]
09 set url "http://wiki.tcl.tk/2?"
10 set abfrageID [http::geturl $url$anfrage]
11
12 if {! [string match ok [http::status $abfrageID]]} {
13 puts stderr "Laden der Seite $url fehlgeschlagen"
14 puts stderr [http::status $abfrageID][http::error $abfrageID]
15 ::http::cleanup $abfrageID
16 exit 1
17 }
18 set inhalt [::http::data $abfrageID]
19 ::http::cleanup $abfrageID
20
21 ### alle Links ausgeben
22 set inhalt [split $inhalt n]
23 set anzahl 0
24 foreach zeile $inhalt {
25 if {[regexp {<a href="">([[:graph:][:space:]]+?)</a>} $zeile alles url text ]} {
26 puts "$text -> http://wiki.tcl.tk/$url"
27 incr anzahl
28 }
29 }
30 puts "n$anzahl Links gefunden"
|
Sind ganze Webseiten oder größere Bereiche davon zu holen, bieten sich dafür spezielle Programme an, etwa Wget [2] und Curl [9]. Sie laden die Seiten auf die lokale Festplatte und verfolgen die darin enthaltenen Links zu weiteren Seiten. Wget oder Curl lassen sich als externe Programme von Tcl aus starten. Zudem steht Curl in Form von Tclcurl [10] auch als Tcl-Erweiterung zur Verfügung.
Ausgekratzt
Nach dem Laden der Webseite folgt der schwierigere Teil: die benötigten Daten auslesen. Geht es nur um wenige Zahlen oder Buchstaben, genügt vielleicht eine Regular Expression, angewendet direkt auf das HTML. Sind kompliziertere Analysen nötig, etwa das Auslesen ganzer Tabellen, verspricht der Umweg über DOM (Document Object Model) deutlich eher zum Erfolg zu führen. Diese Variante berücksichtigt die hierarchische Struktur des Dokuments.
Keep it simple
Um in der Suchseite des Tclers Wiki alle Links und Texte zu finden, reicht ein regulärer Ausdruck. Der beschreibt, wie eine gewünschte Textstelle aussehen muss, also aus welchen Zeichen sie besteht. Mit dem richtigen Ausdruck versehen findet das Tcl-Kommando »regexp« eine solche Textstelle im HTML-Code. Zeile 25 in Listing 2 enthält einen solchen Ausdruck:
- Die URL beginnt mit »<a href=””>« abgeschlossen.
- Um einen Treffer von dem restlichen HTML-Code zu trennen, ist
der relevante Teil durch runde Klammern umrahmt.
Danach folgen nach ähnlichem Prinzip das Muster für den Text zur URL und abschließend das »</a>«-Tag. Dieser reguläre Ausdruck deckt zwar beileibe nicht jedes gültige »<a href«-Tag ab, er genügt aber für die Variationen in der vorliegenden Webseite.
Den Textausschnitt, auf den das Muster insgesamt passt, legt der Aufruf in der Variablen »alles« ab. Den Inhalt des ersten Runde-Klammer-Paares schreibt er in »url«, den zweiten Block in »text«.
Fundstellen
Das Programm in Listing 2 liest aus der Webseite (Fundstellen im Tclers Wiki, Abbildung 3) alle Links mit Namen und URL. Dazu zerlegt »split« (Zeile 22) die Seite in einzelne Zeilen. Die folgende »foreach«-Schleife prüft jede Zeile einzeln mit dem regulären Ausdruck (Zeile 25). Ist die Prüfung erfolgreich, gibt »regexp« den Wert »1« zurück und schreibt die URL und den Text der Fundstelle in die entsprechenden Variablen.
Das Beispielprogramm gibt die Treffer einfach auf der Kommandozeile aus (Zeile 26). Eine nützliche Anwendung würde die gefundenen Seiten vielleicht aufrufen und ihren Inhalt auswerten.
Auf Umwegen
Reguläre Ausdrücke erweisen sich als besonders praktisch, um einfache Werte oder Links aufzuspüren. Liegen die Daten aber in einer HTML-Tabelle, bietet sich eher der Weg über DOM an. Das Document Object Model beschreibt ein Modell, das XML-Dokumente in einer Baumstruktur ordnet. Für jedes Tag des XML-Dokuments gibt es einen Knoten im DOM. Zum Lesen und Schreiben von DOM besitzt Tcl mit Steve Balls Tclxml [11] und Jochen Löwers Tdom [12] zwei umfangreiche Erweiterungen. Listing 1 verwendet Tclxml (Zeile 4).
Leider lassen sich die wenigsten HTML-Seiten direkt in ein DOM einlesen. HTML ist keine XML-Sprache und zudem enthalten Webseiten häufig Syntaxfehler, sind also nicht einmal korrektes HTML. Auch die Seite mit den Pegelständen bildet keine Ausnahme. Zwar liegen die Daten in einer HTML-Tabelle und sollten normalerweise einfach zu lesen zu sein. Allerdings enthält die Seite einen Fehler in Form eines überflüssigen »</form>«-Tags. Solche Fehler sind so häufig, dass die Browser sich bemühen, tolerant zu sein und die HTML-Seite trotzdem anzuzeigen. XML-Parser bleiben dagegen streng und verweigern dem fehlerhaften HTML den Zugang ins DOM.
|
Das Neueste |
|---|
|
Geschichte wiederholt sich gern: Die Firma mit den meisten Tcl-Entwicklern wird aufgekauft und wieder abgestoßen. Nach dem Verkauf von John Ousterhouts Scriptics trifft es diesmal Activestate [14], die sich um etliche Skriptsprachen verdient gemacht hat (Tcl, Perl, Python, PHP, Ruby). Reger Handel mit Tcl-EntwicklerfirmenSophos hatte Activestate wegen der Erfahrungen im Antivirus-Geschäft erstanden und nun an eine kanadische Venture-Gruppe verkauft. Der Support und die Entwicklungswerkzeuge für Skriptsprachen sollen wieder das Kerngeschäft von Activestate werden. Damit finanziert die Firma unter anderem die Weiterentwicklung von Tcl, Perl und Python. München ist offenbar ein gutes Pflaster für Tcl-Entwickler. Neben der kürzlich in der Federlesen-Reihe vorgestellten Anbindung für Open Office ([15], [16]) entsteht bei Paul Obermaier gerade Tcl 3D [17]. Diese Erweiterung bietet Zugriff auf den 3D-Standard OpenGL. Damit können Tcl-Skripte dreidimensionale Welten erzeugen und steuern (Abbildung 5). Durch die Unterstützung von Joysticks und Nvidias Shaderlanguage taugt das Gespann sogar für 3D-Spiele. 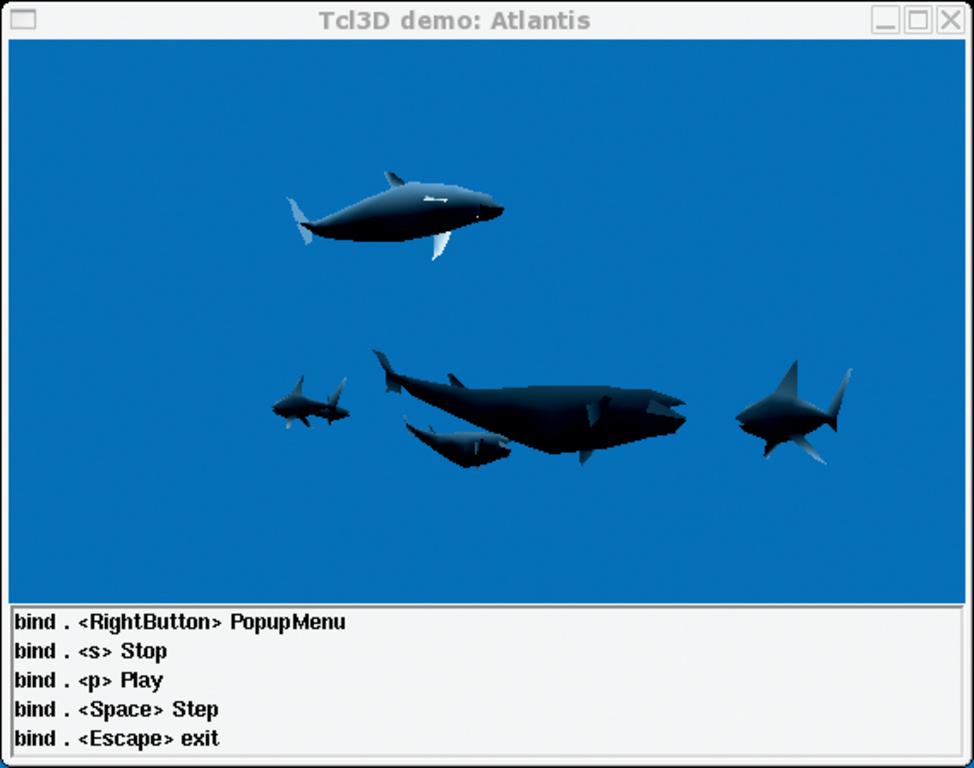 Abbildung 5: Dank Paul Obermeiers neuer Extension Tcl 3D können Tcl-Skripte nun direkt die Funktionen von OpenGL nutzen und damit flotte 3D-Animationen auf den Bildschirm zaubern. Nachdem Eurocontrol den Flugverkehr über Belgien, den Niederlanden und Norddeutschland seit Ende Februar mit einer Tcl-Anwendung kontrolliert [18], scheint nun die Zeit reif für einen Flugsimulator. In Tcl 3D finden sich als Demo bereits typische Flugzeuginstrumente wie Altimeter und Kompass (Abbildung 6). In Bergisch Gladbach findet am 26. und 27. Mai das sechste Europäische Tcl/Tk Usermeeting statt [19]. Hier gibt es Gelegenheit, bekannte Tcl-Entwickler zu treffen und sich über die neuesten Entwicklungen zu informieren. 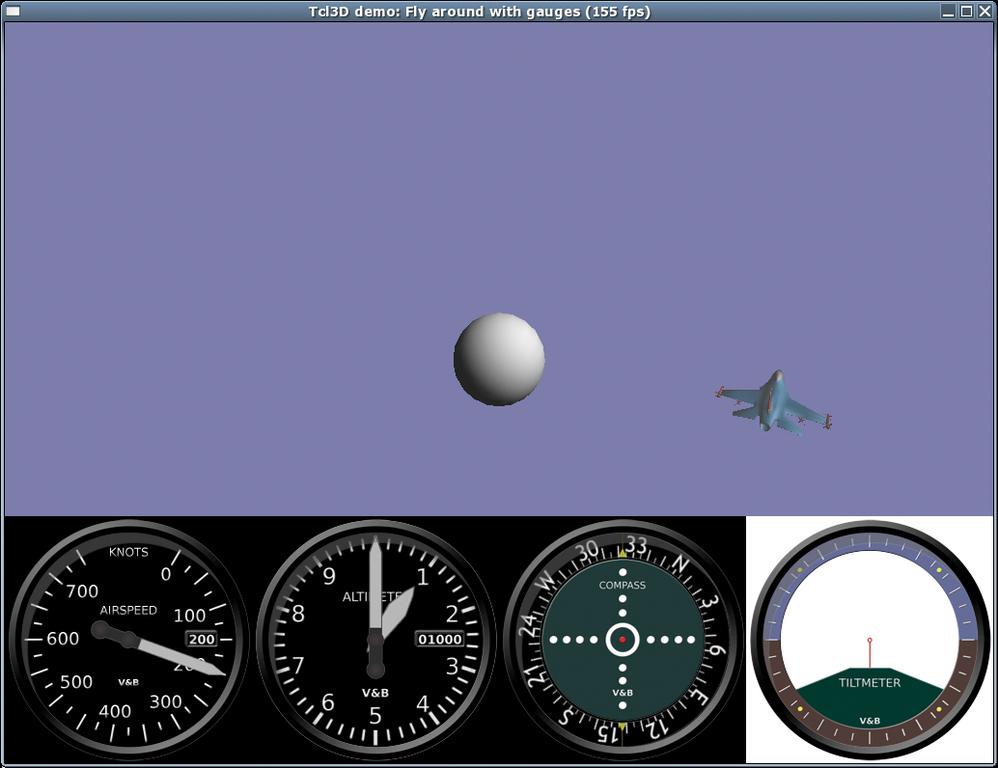 Abbildung 6: Tcl 3D bringt sogar erste Ansätze für einen Flugsimulator mit: Die 3D-Darstellung in diesem Beispielprogramm ist zwar noch reichlich simpel, dafür sehen die Instrumente aber schon gut aus. Leistungsfähiges HTML-Widget für Tcl/TkTcl-Fans betrachten die Einladung zum Usermeeting mit Tkhtml [20]: Nach langer Pause geht die Arbeit an diesem Widget zur Anzeige von HTML weiter. Es kann zwar noch nicht mit Mozilla/Gecko oder Konqueror/KHTML konkurrieren, eignet sich aber bereits bestens, um Hilfeseiten oder Reports ohne externe Browser anzuzeigen. Das Projektziel lautet: Webseiten mindestens so schnell, schön und korrekt wie die Konkurrenz darzustellen. |
Fremde Fehler
Die meisten Linux-Distributionen enthalten mit Tidy [13] ein nützliches Werkzeug, das Fehler in HTML findet und einige Missgeschicke auch gleich korrigiert. Bei dieser Seite streckt jedoch selbst Tidy die Waffen und verweist auf manuelle Reparatur. Das Tcl-Skript wertet den Inhalt der Seite deshalb zunächst zeilenweise aus (Listing 1, Zeile 30) und ignoriert den bekannten Fehler.
Der reguläre Ausdruck in Zeile 27 spürt den Störenfried auf. Die korrekten Zeilen landen in der Datei »pegel.html« (geöffnet in Zeile 25), die fehlerhafte Stelle führt nur zu einem Hinweis (Zeile 28). Der Aufruf in Zeile 35 verwandelt per Tidy den HTML-Code in sauberes XML (in der Datei »sauber.xml«). Fürs Einlesen in die DOM-Struktur ist der Code in den Zeilen 40 bis 43 zuständig. Der Aufruf »dom::parse« erwartet als Parameter das komplette XML-Dokument.
Die Seite des BSH besteht aus mehreren ineinander verschachtelten Tabellen, wobei für das Beispiel nur die Tabelle mit den Pegelständen wichtig ist. Das Problem lautet, den richtige Knoten zu finden. Gerade wenn HTML-Tabellen sowohl fürs Seiten-Layout als auch für die Daten zuständig sind, kommen komplexe Dokumente zustande. Die gewünschte Tabelle findet sich erst in der 14. XML-Ebene als fünfte geschachtelte Tabelle. Die Aufgabe sieht aber schwieriger aus, als sie ist: Ein guter XML-Editor hilft den XPath ermitteln.
Pfadsucher
Per KDE-XML-Editor findet der Programmierer den Startknoten für die Tabelle recht schnell. Praktischerweise zeigt die Software den XPath zum Knoten gleich an (Abbildung 4). Dieser Weg führt durch die XML-Baumstruktur zum ausgewählten Knoten. Leider ist die XPath-Unterstützung von Tclxml nicht komplett, der Zähler in eckigen Klammern fehlt (zum Beispiel »/tr[5]« für den fünften »<tr>«-Knoten).
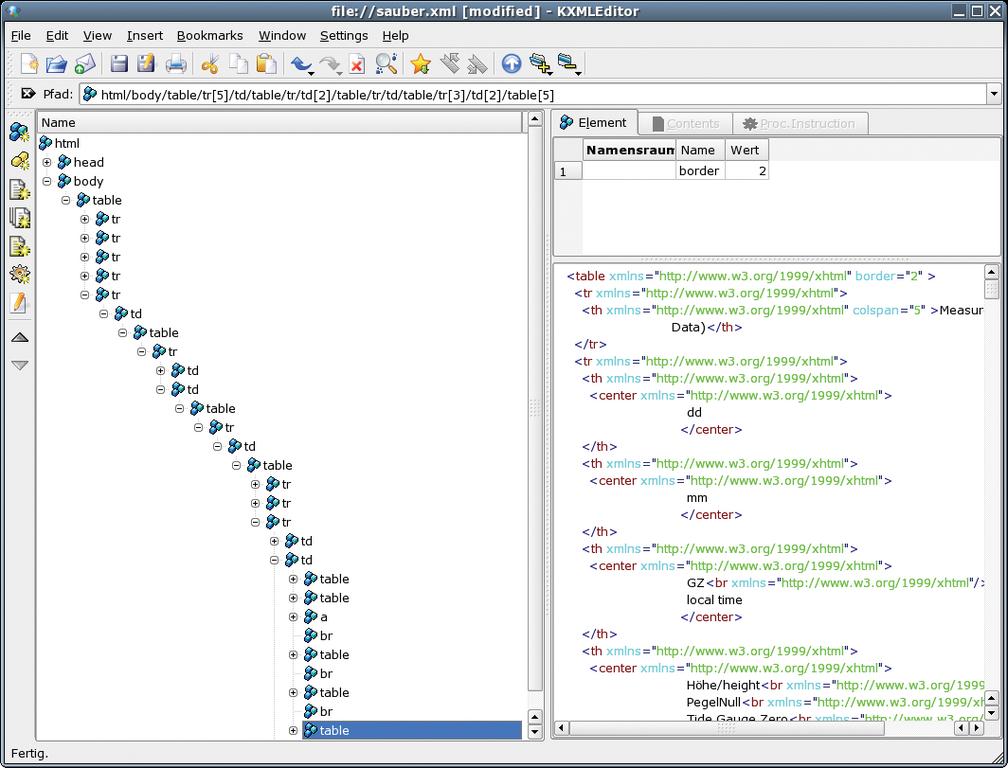
Abbildung 4: Der KDE-XML-Editor stellt die DOM-Struktur der Webseite aus Abbildung 1 dar. Im Pfad-Feld oben ist die längliche XPath-Angabe für das unten markierte »table«-Element zu sehen.
Als Workaround hangelt sich das Tcl-Skript stückweise zum Ziel vor. Jeden Abschnitt des vollständigen XPath (Zeile 46) bis zur nächsten eckigen Klammer geht das Skript einzeln durch, zum Beispiel in den Zeilen 48 bis 50. Der vollständige XPath-Support von Tdom hätte die Suche des Tabellenelements auf eine Zeile reduziert, allerdings lehnt dieser Parser das Dokument selbst nach der Tidy-Reinigung ab.
Bleibt zuletzt noch übrig, die Daten aus der Tabelle in eine CSV-Datei für die weitere Verwendung zu schreiben. Zwei geschachtelte Schleifen (Zeilen 67 bis 79) iterieren über die Zeilen und Zellen, »dom::node stringValue« liest den Text aus den »th«- und »td«-Tags und schreibt ihn nach geeigneter Formatierung (Zeile 72) in die Datei.
Trickreich
Auch wer sich nicht ausgerechnet für die Pegelständen der Elbe bei St. Pauli interessiert und das Tclers Wiki lieber per Browser liest, findet in diesen Beispielen die nötigen Tricks, um Daten aus HTML-Seite zu lesen. Den Inhalt per »http«-Paket zu laden ist meist der einfachste Teil. Ihn XML-konform aufzubereiten und als DOM zu interpretieren bedarf jedoch einiger Kniffe, die sich bei komplexem HTML aber lohnen. (fjl)
|
Infos |
|---|
|
[1] Carsten Cerbst, “Stets zu Diensten – SOAP-Webservices mit Tcl nutzen”: Linux-Magazin 11/05, S. 116 [2] Wget kopiert Webseiten auf die Festplatte: [http://www.gnu.org/software/wget/] [3] Bundesamt für Seeschifffahrt und Hydrographie, Pegelstände in St. Pauli: [http://www.bsh.de/aktdat/wvd/StPauli_pgl.htm] [4] Selfhtml, Anleitung für HTML-Autoren: [http://de.selfhtml.org] [5] HTTP-Redirect mit der Tcl-Extension »http«: [http://wiki.tcl.tk/11831] [6] POST-Request aus Tcl absetzen: [http://wiki.tcl.tk/3211] [7] Ethereal: [http://www.ethereal.com] [8] Sockspy: [http://sockspy.sourceforge.net/sockspy.html] [9] URLs auf der Kommandozeile abfragen mit Curl: [http://curl.haxx.se] [10] Tcl-Erweiterung Tclcurl: [http://personal1.iddeo.es/andresgarci/tclcurl/english/] [11] Tclxml: [http://tclxml.sourceforge.net] [12] Tdom: [http://www.tdom.org] [13] Tidy findet und behebt Fehler in HTML: [http://tidy.sourceforge.net] [14] Activestate: [http://www.activestate.com] [15] Tcluno: [http://tcluno.sourceforge.net] [16] Carsten Cerbst, “Schreibstube – Tcl-Erweiterungen, um Open Office zu automatisieren”: Linux-Magazin 03/06, S. 110 [17] Tcl 3D: [http://www.tcl3d.org] [18] Eurocontrol: [http://wiki.tcl.tk/15535] [19] Tcl/Tk User Meeting in Bergisch Gladbach: [http://wiki.tcl.tk/13567] [20] HTML-Widget Tkhtml: [http://tkhtml.tcl.tk] |
|
Der Autor |
|---|
|
Carsten Zerbst lebt und arbeitet in Hamburg. Seit er 1991 auf Linux stieß, ist Tcl/Tk die Skriptsprache seiner Wahl. Inzwischen arbeitet er im Bereich der Produktdatenverwaltung bei einem großen Dienstleister. |





