
Von Soundcloud stammt die verteilte Monitoringlösung Prometheus 2.0, die mittlerweile vor allem im Containerumfeld Freunde findet. Version 2.0 reduziert den Fußabdruck der Software, erlaubt Snapshot-Backups der Datenbank und durchforstet riesige Mengen an Zeitreihen effizienter.
Die neue, leistungsfähigere Zeitreihen-Datenbank startete Anfang 2017 als Experiment, die in praktischen Benchmarks gewonnenen Ergebnisse können sich aber sehen lassen: Die Latenzzeiten für Abfragen sind konsistenter und skalieren besser, zugleich geht der Ressourcenverbrauch in realen Produktionsszenarien deutlich zurück.
Fabian Reinartz stellte die Neuerungen von Prometheus 2.0 unter anderem bereits im Oktober auf dem Open Source Summit in Prag vor.
Zahlen dazu liefert unter anderem das Projekt selbst in einem Blogpost von Entwickler Fabian Reinartz, der sie bereit auf dem Open Source Summit in Prag vorstellte (Abbildung 1). Demnach reduziert sich die CPU-Auslastung gegenüber Version 1.8 um 20 bis 40 Prozent. Prometheus 2.0 braucht 33 bis 50 Prozent weniger Plattenplatz als die Vorgängerversion und Disk I/O liegt ohne große Last normalerweise bei weniger als einem Prozent.
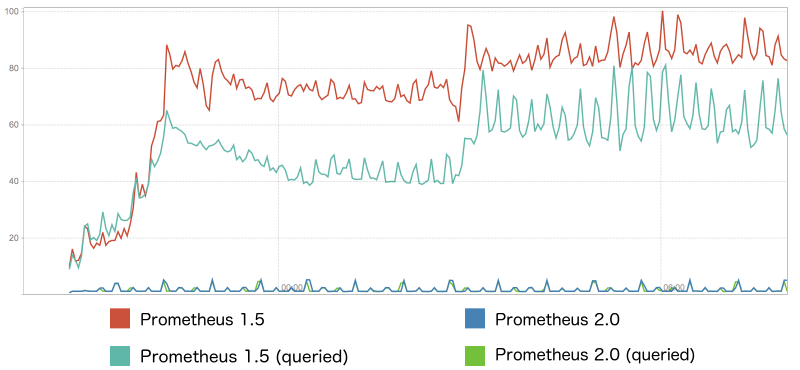
Prometheus 2.0 schreibt deutlich weniger Daten auf die Festplatte. Die Benchmarks stammen von “prombench”. (Quelle: coreos.com)
Auch Core OS beteiligt sich an der Entwicklung von Prometheus und sieht die “dramatischste Verbesserung in Prometheus 2.0” in der geringeren Menge an Daten, die die Monitoring-Software pro Sekunde auf die Festplatte schreibt (Abbildung 2), es seien bis zu zwei Größenordnungen weniger Daten. Dies erhöhe die Lebensdauer von SSDs und senke die Kosten. Wer viele Zeitreihendaten schreibt, könne so erheblich Plattenplatz einsparen.
Schal nach fünf Minuten
Nutzer dürften auch begrüßen, dass die neue Version das seit Jahren bestehende und recht komplex zu behebende Problem mit der 5-Minuten-Staleness löst. Denn erhält Prometheus etwa beim Auswerten eines Instant Vektor fünf Minuten lang keine aktualisierten Datenpunkte, betrachtet es die dazugehörige Zeitreihe als “schal” oder “abgestanden” (englisch: stale). Der Admin weiß dann nicht genau, ob ein Wert tatsächlich konstant ist oder er auf einen veralteten Datenpunkt schaut.
Das führt unter anderem dazu, dass die Alerts auch dann noch gehen, wenn ein Problem bereits behoben ist. Prometheus 2.0 trackt daher nun auch verschwindende Targets oder deren Zeitreihen, was nicht nur Abfrage-Artefakte verhindert, sondern auch die Reaktionsfähigkeit der Alerts bessert.
Schnappschüsse machen
Neu ist außerdem der integrierte Support für Snapshot-Backups der gesamten Datenbank. Dazu setzt der Admin die Flag “–web.enable-admin-api” ein und verwendet dann einen einfachen API-Call:
# curl -XPOST http://<prometheus>/api/v2/admin/tsdb/snapshot {"name":"2017-10-18T13:44:35Z-3f6a679bb001e65d"}
Der Snapshot landet in einem Verzeichnis mit dem zurückgelieferten Namen und lässt sich dann in einen Archivspeicher hochladen, wobei er kaum zusätzlichen Speicherplatz belegt. Auf Basis der gesicherten Daten lässt sich dann einfach ein neuer Prometheus-Server starten, indem der Admin den Schnappschuss in das Datenverzeichnis des neuen Servers schiebt.
Speichermotor
Prometheus sammelt Daten als Zeitreihen. Überwacht es in großen Setups hunderte bis tausende von Containern, kommen Millionen von Zeitreihen über einen Cluster zusammen, was das kontinuierliche Schreiben zu einer technischen Herausforderung macht. Dank Kubernetes entstehen und verschwinden die Container zum allem Ärger auch noch permanent. Das ist gewollt und wird in Zukunft eher zunehmen. Da Prometheus Zeitreihen für jeden einzelnen Container anlegt, fallen über die Zeit Milliarden von Zeitreihen an, auch wenn die Monitoring-Software sie nicht alle trackt.
Eine neue Storage Engine verwendet invertierte Indizes und orientiert sich am Vorbild Volltextsuche. Sie erlaubt es, Zeitreihen schneller zu durchforsten. Zugleich hilft es, dass ein neues Festplattenformat verwandete Zeitreihendaten besser beieinander hält und ein Write-ahead-Log für eine bessere Crash-Resistenz sorgt. Neu ist auch, das die Aufzeichnungs- und Alarmierungsregeln nun im YAML-Format vorliegen, was es erleichtert, die Daten im Konfigurationsmanagement und in Templates zu verwenden.
Admins die eine Migration erwägen, sollten einen Blick in das Migrationshandbuch werfen. Ausprobieren lässt sich die neue Version über die offiziellen Binaries und Container-Images.



