
Jens Körte, sxc.hu
Mit den Threading Buildings Blocks 1.0 bietet Intel für Parallelprogrammierung ein C++-Template-basiertes kommerzielles Framework an. Zwei Intel-Entwickler führen in das komplexe Konzept ein, das sich für alle Multicore- und SMP-Systeme eignet, und stellen wichtige Features vor.
Für die Parallelisierung einer seriellen Anwendung gibt es verschiedene Vorgehensweisen. Interessant ist, dass sich in diesem Bereich nur Sprachergänzungen (OpenMP, Cilk) zu den gängigen Programmiersprachen (C/C++, Fortran) und Bibliotheksansätze (PVM, MPI, Pthreads, Win32-Threads) durchgesetzt haben und nicht etwa inhärent parallele Sprache wie Erlang. Auch die Intel Threading Building Blocks (TBB) bieten eine solche Bibliothek [1].
Thread-basierte Modelle
Die meisten parallelen Ansätze beruhen auf dem Prozesskontext-Modell. Der Kontext beinhaltet den vollständigen Zustand eines Prozesses zu einem bestimmten Zeitpunkt. Prozesse können ihrerseits mehrere nebenläufige Threads erzeugen, von denen jeder einzelne seriell abläuft. Die Reihenfolge und Priorität, mit denen die CPU die einzelnen Instruktionen oder Bereiche der Threads ausführt, ist dem Betriebssystem oder einem eigenen Steuerprogramm (Scheduler) überlassen.
Die Erzeugung von Threads ist deutlich schneller und effizienter als die Erzeugung von Prozessen, weil kein vollständiger Austausch des Prozesskontextes notwendig ist. Threads teilen sich eine Reihe von Betriebsmitteln mit dem zugehörigen Prozess, etwa Code- und Datensegmente sowie Dateideskriptoren. Jeder Thread besitzt aber einen eigenen Befehlszähler und Stack. Da Threads demselben Prozess zugeordnet sind, kommunizieren sie über den gemeinsamen Adressenraum. Diese Kommunikation ist sehr schnell, da der limitierende Faktor nur die Cache-Latenz oder die Speicherzugriffszeit ist.
Zu den Shared-Memory-Programmiermodellen gehören alle Ansätze, die im weitesten Sinne auf Multithreading basieren, also Thread-Bibliotheken wie Pthreads [2] oder Win32-Threads, Sprachen mit Thread-Erweiterungen wie Java und C# und Spracherweiterungen wie OpenMP (siehe den Artikel in diesem Schwerpunkt).
Dieser Artikel stellt die für die Threading Building Blocks relevanten Teile des Shared-Memory-Modells vor. Wie alle anderen Multithreading-Varianten greifen auch sie auf Betriebssystemaufrufe zum Erzeugen und Verwalten von Threads zurück. Bei gleichzeitiger Ausführung mehrerer Prozesse oder Threads muss das Betriebssystem oder ein eigener Scheduler die Zugriffe auf die vorhandenen Ressourcen wie CPU, Speicher und Festplatte regeln.
Der Scheduling-Algorithmus entscheidet zum Beispiel, wann und in welcher Reihenfolge die Instruktionen der verschiedenen Threads relativ zueinander ablaufen und wann ein Thread eine Speicherzelle ändert. Solche Zustandsänderungen sind besonders kritisch, wenn mehrere Threads auf denselben Speicher zugreifen. In solchen Fällen kann es zu so genannten Wettläufen (Race Conditions) kommen, die in der Praxis unvorhersehbar und oft nicht reproduzierbar sind, da sie von dem jeweiligen zeitlichen Ablauf abhängen.
Schwierige Fehlersuche
Ein weiteres Problem taucht immer dann auf, wenn sich Threads durch abhängige Zugriffe auf dieselben Ressourcen blockieren (Deadlock). Diese Mechanismen bewirken bei parallelen Programmen eine Unbestimmtheit, die sequenzielle Programme nicht aufweisen. Dadurch ergeben sich Probleme, die beim Entwicklungszyklus der Software zusätzliche Werkzeuge notwendig machen, um die Korrektheit des Ablaufs zu überwachen und Speicherzugriffsfehler von Threads aufdecken zu können.
Die Multithreading-Ansätze unterscheiden sich im Wesentlichen durch Granularität und Funktionsumfang. Dabei geht es im Kern darum, ob der Entwickler die maximale Kontrolle bei der Erzeugung und Synchronisation der Threads haben und damit auch den komplexesten und fehleranfälligsten Weg gehen möchte (Win32-Threads, Pthreads) oder ob er einen einfachen, eventuell inkrementellen Weg wie OpenMP wählt oder den Template-basierten Ansatz der Threading Building Blocks. Bei OpenMP wie auch bei TBB überlässt der Programmierer Details wie Erzeugung und Synchronisation der Laufzeitumgebung, gibt dadurch aber einen Teil der Kontrolle ab.
Ein richtig synchronisiertes paralleles Programm zu entwerfen ist deutlich komplexer und anfälliger für Fehler als der Entwurf seines sequenziellen Pendants. Das liegt an der Verwendung der Betriebssystemfunktionen zur Synchronisation von Threads sowie an den Verfahren zur Zugriffssteuerung, den so genannten Monitoren, Mutexen (Mutual Exclusion), Semaphoren und Locks.
Ein Mutex-Objekt zum Beispiel verhindert, dass nebenläufige Threads gleichzeitig auf Daten zugreifen und somit inkonsistente Zustände erzeugen können. Für einen objektorientierten Ansatz wäre es wünschenswert, wenn es gekapselte Varianten für den Zugriff auf die feingranularen Betriebssystemfunktionen sowie die Zugriffsbeschränkungen gäbe, die sich nahtlos in den objektorientierten Gesamtentwurf eingliedern.
Aufgabenorientiert
Ziel bei der Entwicklung paralleler Programme mit den TBB ist es, den Programmierer von den zeitaufwändigen, komplexen und fehleranfälligen Details zu befreien und korrekt Daten zwischen mehreren Threads zu synchronisieren. Die Threading Building Blocks verfolgen einen abstrakten Ansatz, der die Synchronisation vereinfacht.
Dazu gehört das Zerlegen der zu verarbeitenden Aufgabe in kleinere Teilaufgaben, so genannte Tasks, die parallel und unabhängig voneinander ablaufen. Mit den TBB kann der Entwickler dadurch inkrementell und objektorientiert die Performance-relevanten Bereiche seiner Applikation auf die vorhandenen Prozessorkerne verteilen, ohne sich Gedanken zu machen, wie viele Prozessorkerne vorhanden und wie viele Threads für eine optimale Auslastung zu erzeugen sind. Das verhindert, dass versehentlich zu viele (Over-Subscription) beziehungsweise zu wenige (Under-Subscription) Threads erzeugt werden.
Spart Kontextwechsel
Im Gegensatz zu anderen Thread-Modellen verwenden die TBB einen eigenen Scheduler. Das hat mehrere Vorteile. Der Betriebssystem-Scheduler erzeugt wegen der Kontextwechsel einen deutlichen Overhead gegenüber dem TBB-Scheduler: Threads und Synchronisations-Konstrukte sind Objekte des Betriebssystemkerns (Kernelobjects), laufen also im Kernel-Modus ab. Die x86-Architekturen unterscheiden vier Privilegierungsstufen, bei denen der Ring 0 die höchste Stufe ist, die dann immer weiter eingeschränkt wird. Alle anderen Objekte laufen im Benutzer-Modus (User Mode), also im Ring 3.
Die verschiedenen Ringe bezeichnen also ganz allgemein Privilegierungs- beziehungsweise Sicherheitsstufen. Jeder Wechsel von einem Ring zum anderen erfordert einen Kontextwechsel, der einige Rechenzeit in Anspruch nimmt, da von der CPU dabei prozessrelevante Daten zu sichern sind.
Der TBB-Scheduler hingegen verwendet leicht gewichtige (leightweight) Threads und Konstrukte, die im User-Modus laufen und somit weniger Zeit brauchen, da die Kontextwechsel entfallen. Ein weiterer Unterschied ist, dass der Betriebssystem-Scheduler fair ist, er versucht also den einzelnen Threads möglichst gleich viel Zeit zuzuteilen. Das kann aber zu einer ungünstigen Cache- und Speicherausnutzung führen.
Der TBB-Scheduler dagegen ist unfair und bevorzugt Threads, die zu einer günstige Cache- und Speicherausnutzung führen. Er verwendet das so genannte Taskstealing, bei dem nach dem Leerlaufen der eigenen Taskqueue ein Thread versucht aus anderen Taskqueues Tasks zu stehlen. Die Verwendung eines eigenen Schedulers hat aber nicht nur Vorteile. Bei Blockierung der Threads durch häufige I/O-Operationen funktioniert der TBB-Scheduler weniger gut.
Parallele Algorithmen
Die verschiedenen Thread-Implementierungen haben – wenn auch nicht kompatibel – die Eigenschaft, sehr betriebssystemnahe Funktionen und Mechanismen zu verwenden. Pthreads, Win32-Threads und selbst OpenMP stellen Ausdrucksmittel auf einem sehr niedrigen Abstraktionsniveau zur Verfügung. Die Benutzung dieser einfachen Konzepte in abstrakten und objektorientierten Sprachen gestaltet sich allerdings oft schwierig, da sie dem höheren Abstraktionskonzept zuwiderlaufen.
Vorbild: STL
Die Threading Building Blocks implementieren ein Laufzeit-basiertes Programmiermodell mit generischen, parallelen Algorithmen auf Basis einer Template-Bibliothek ähnlich der C++ Standard Template Library (STL). Templates sind Programmierkonstrukte, die eine vom Datentyp unabhängige Programmierung ermöglichen. Sie unterstützen die generische Programmierung und sind ein abstraktes Mittel, das Vererbung und Überladen von Operatoren zu mächtigen Konzepten kombiniert.
Allgemein sind C++-Templates Konstruktionsgerüste, bei dem ein oder mehrere Typen parametrisiert sind. Bei anderen Programmiersprachen heißen solche Konstrukte zum Beispiel generische Typen. Der große Vorteil von Templates gegenüber C-Makros ist die Typsicherheit, die der Compiler überprüft und dadurch Laufzeitfehler vermeidet. Es gibt Funktions-Templates, Klassen-Templates und selbst Template-Templates. C++-Programmierer verwenden Template-Templates, um das Abstraktionsniveau noch weiter zu steigern.
Aufgrund des Abstraktionskonzepts ist die Syntax etwas gewöhnungsbedürftig. Ein einfaches Funktions-Template, um das größere von zwei Elementen zu berechnen, sieht folgendermaßen aus:
template <typename T>
T max(T x, T y)
{
if (x < y)
return y;
else
return x;
}
Dieses Template lässt sich mit »max(3, 7)« wie eine normale Funktion aufrufen. Der Compiler legt anhand der Parameter den tatsächlichen Typ fest.
Dies würde auch für andere Datentypen wie Strings und andere Klassen funktionieren, solange der Vergleichsoperator und der Kopierkonstruktor für sie definiert sind. Durch die STL stellt jeder standardkonforme C++-Compiler bereits die gängigen Datenstrukturen wie verkettete Listen, Felder oder balancierte Suchbäume bereit.
Was die Standard Template Library dabei auszeichnet, ist die Realisierung der Programmierschnittstelle über so genannte Iteratoren. Ein Iterator »it« verhält sich auf den ersten Blick ähnlich wie ein Zeiger: Man kann mit »*it« auf das Element zugreifen, auf das er zeigt, und mit »++it« auf das nächste Element der Containerklasse weiterschalten.
Funktoren
Wahre C++-Enthusiasten benutzen allerdings lieber Funktoren, um Elemente einer Datenstruktur zu bearbeiten. Unter einem Funktor ist im Grunde genommen einfach eine Klasse zu verstehen, die sich wie eine Funktion verwenden lässt, da sie den Klammer-Operator »operator()« definiert. Eine Liste von Zahlen zusammenzählen kann mit einem Funktor konkret so erfolgen, wie in Listing 1 zu sehen ist.
|
Listing 1: |
|---|
01 #include <list>
02 #include <algorithm>
03 #include <iostream>
04
05 struct Sum {
06 double sum;
07 Sum():sum(0.0) {}
08 void operator()(const double & d) { sum += d; }
09 };
10
11 std::list<double> myList;
12 ...
13 Sum mySum = std::for_each(myList.begin(), myList.end(), Sum());
14 std::cout << "Summe " << mySum.sum << std::endl;
|
Die Klasse Sum realisiert dabei die Summenbildung. Der Konstruktor initialisiert den Wert mit »0.0«. Außerdem definiert er den Klammer-Operator »operator()«, der die Aufgabe übernimmt, einen weiteren Wert hinzuzuzählen. Die Klasse »Sum« lässt sich mit dem Ausdruck »for_each« benutzen, den wiederum die C++-Standardbibliothek zur Verfügung stellt. Der Ausdruck »for_each« ruft nun einfach die Funktion »operator()« für jedes Element der Liste »myList« auf. Das Ergebnis liefert »for_each« dann zurück. Also steht in »mySum.sum« die Summe der Elemente.
Die TBB-Bibliothek stellt parallele Funktions-Templates wie »parallel_for«, »parallel_while«, »parallel_reduce«, »pipeline«, »parallel_sort« sowie »parallel_scan« bereit. Exemplarisch sollen hier »parallel_for« und »parallel_reduce« vorgestellt werden. Sie übernehmen die (rekursive) Aufteilung der Daten in einzelne Tasks bis zu einer wählbaren Mindestgröße (Grain Size).
Für das zu verarbeitende Intervall stellen die TBB die Template-Klasse »tbb::block_range« zur Verfügung, die sich zum Beispiel mit ganzen Zahlen, Zeigern oder Random-Access-Iteratoren instanziieren lässt. Der Funktor muss dann statt eines einzelnen Elements einen ganzen Bereich verarbeiten (Listing 2).
In diesem Listing hat der Funktor »Scale« die Aufgabe, das Element eines Vektors mit einem Faktor zu multiplizieren. Den Faktor selbst bekommt er dabei durch den Konstruktor übergeben. Der Anwender von »parallel_for« muss nur den zu bearbeitenden Bereich sowie den Funktor übergeben. Dem Konstruktor von »blocked_range« teilt er dabei den Bereich durch die Iteratoren »theVector.begin()« und »theVector.end()« mit, zudem die Größe, bis zu der unterteilt werden soll, in diesem Fall 1000.
|
Listing 2: |
|---|
01 struct Scale {
02 const double& factor;
03
04 Scale(const double& f ) : factor( f ) {}
05 typedef tbb::blocked_range < std::vector<double>::iterator > range_type;
06
07 void operator()( const range_type& range ) const {
08 for ( std::vector<double>::iterator it=range.begin(); it!=range.end(); ++it )
09 *it *= factor;
10 }
11 };
12
13
14 std::vector<double> theVector;
15 ...
16 tbb::blocked_range< std::vector<double>::iterator >
17 theRange( theVector.begin(), theVector.end(), 1000 );
18 Scale someScale(3.0);
19 tbb::parallel_for( theRange, someScale );
|
Wer aber zum Beispiel das Maximum der Elemente berechnen möchte, muss die Teilergebnisse von jedem Bereich wieder zusammenfügen. Der Algorithmus »parallel_reduce« macht dies über eine Funktion »join« des Funktors, die das Teilergebnis eines anderen Bereiches hinzufügt. Darüber hinaus muss der Funktor einen Konstruktor zur Aufteilung bereitstellen, der aber in diesem Fall trivial ist. Dieser Konstruktor hat ein Dummy-Argument vom Typ »split«, um ihn vom Kopierkonstruktor zu unterscheiden (Listing 3). Würde man die gleiche Funktionalität direkt mit Posix-Threads programmieren, wäre das Listing ungefähr viermal so lang.
|
Listing 3: |
|---|
01 struct Max {
02 double myMax;
03
04 Max() : myMax( std::numeric_limits<double>::min() ) {}
05 Max( Max& m, tbb::split ) : myMax( std::numeric_limits<double>::min() ) {}
06
07 void operator()(const tbb::blocked_range < std::vector<double>::iterator>& range )
08 {
09 for ( std::vector<double>::iterator it=range.begin(); it!=range.end(); ++it )
10 if ( *it > myMax )
11 { myMax = *it; }
12 }
13
14 void join( const Max& rhs ) {
15 if ( rhs.myMax > myMax )
16 { myMax = rhs.myMax; }
17 }
18 };
19 Max theMaximum;
20 tbb::parallel_reduce( theRange, theMaximum );
21 std::cout << " Maximum = " << theMaximum.myMax << std::endl;
|
Thread-sichere Datenstrukturen
Neben parallelen Algorithmen bieten die TBB auch skalierbare Implementierungen von generischen Containern wie »map«, »queue« und »vector« (siehe Abbildung 2). Diese Templates kann der Benutzer im eigenen Code oder in Verbindung mit den parallelen Algorithmen benutzen. Da die Standardcontainer in der STL-Implementierung nicht für Threading ausgelegt sind, kommt es häufig zu Race Conditions und zum unabsichtlichen Überschreiben von Daten. Das liegt in der Regel an der nicht Thread-sicheren (threadsafe) Implementierung der STL-Container.
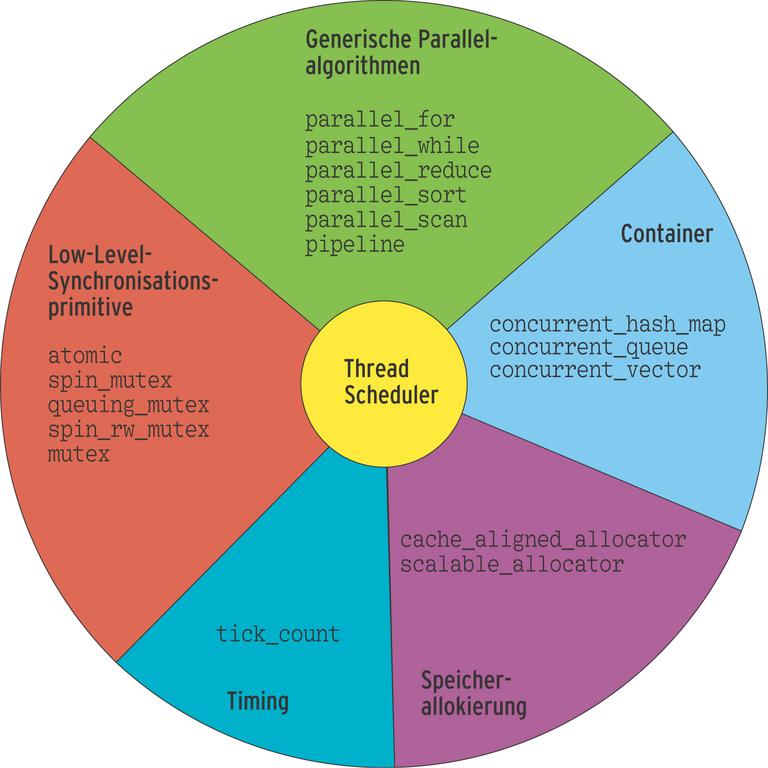
Abbildung 2: Aufbau der Intel Threading Building Blocks: Von Synchronisationsprimitiven bis zu Thread-sicheren Containern.
Deshalb lassen sich die Container der Threading Building Blocks auch als Thread-sicheres Komplement zu den STL-Containern verstehen. Diese heißen dann »concurrent_hash_map«, »concurrent_queue« und »concurrent_vector«. Außerdem bieten die TBB Klassen zur Speicherverwaltung in parallelen Algorithmen. Sie bedienen sich dabei des Konzepts eines Allokators und fügen sich dadurch auch gut in die Standard Template Library ein.
Synchronisieren
Als weitere Hilfsmittel stellen die TBB in Klassen eingekapselte Varianten von Locks wie Mutex, »spin_mutex« und »queueing_mutex« sowie die entsprechenden Pendants mit nicht blockierendem Lesezugriff »spin_rw_mutex« und »queueing_rw_mutex« bereit. Entsprechend der Philosophie von C++ wird dabei ein Lock durch den Destruktor eines Lock-Objekts freigegeben (Listing 4). Abgesehen davon, dass man dadurch nie wieder vergisst, einen Mutex freizugeben, funktionieren diese Locks mit gleicher Syntax auf allen unterstützten Betriebssystemen.
|
Listing 4: Gekapselter |
|---|
01 #include "tbb/mutex.h"
02
03 Tbb::mutex myMutex ;
04 ...
05 {
06 tbb::mutex::scoped_lock myLock( myMutex );
07 // geschützter Bereich
08 ...
09 } // Hier wird myMutex wieder freigegeben
|
Um innerhalb des geschützten Bereichs nur eine einzige Variable zu schützen, ist ein Mutex eine vergleichweise aufwändige Konstruktion. Für solche Operationen wie zum Beispiel das Erhöhen eines Zählers gibt es effizientere Methoden, die die TBB in der Klasse »Atomic« kapseln. Sie erlaubt es, in atomaren Operationen Variablen zu erhöhen (»fetch_and_increment«), zu erniedrigen (»fetch_and_decrement«), etwas hinzuzuzählen (»fetch_and_add«), den Wert auszutauschen (»fetch_and_store«) oder sogar nur in den Fällen auszutauschen, wenn er einen vorgegebenen Wert hat (»compare_and_swap«).
Intels Threading Building Blocks sind eine von Compiler und Plattform unabhängige, Template-basierte Laufzeitbibliothek für die C++-Programmierung. Mit ihnen können objektorientierte Multithread-Anwendungen einfacher entwickelt werden als mit einem der systemnahen Konzepte wie Pthreads. Sie integrieren sich in die C++-Standard-Template-Library und bieten einen abstrakten Satz von parallelen Algorithmen und Containern.
Das Paket bietet generische Konstrukte für ein objektorientiertes Design, die es in dieser Art bei keinem anderen Ansatz gibt. Kurz gesagt sind die Threading Building Blocks für C++-Programmierer das, was OpenMP für C- und Fortran Programmierer ist.
Eine Einzellizenz der TBB für Linux kostet ungefähr 250 Euro, eine Floating-Lizenz das Doppelte. Interessierte können Evaluierungsversionen für die Plattformen Windows, Linux und Mac OS von der Website [1] kostenlos herunterladen und ausprobieren. (ofr)
|
Infos |
|---|
|
[1] Threading Building Blocks: [http://www3.intel.com/cd/software/products/asmo-na/eng/294797.htm] [2] Ulrich Wolf, Wolfgang Hetzler, “Prozesse und Threads”: Linux-Magazin 04/03, S. 39 [3] Rohit Chandra et. al., ” Parallel Programming in OpenMP”: Morgan Kaufmann |
|
Die Autoren |
|---|
|
Dr. Mario Deilmann ist Diplom-Ingenieur und hat an der Ruhr-Universität-Bochum im Bereich numerische Simulation promoviert. Er arbeitet seit 2003 als Senior Software Engineer bei der Firma Intel und ist im Bereich des technischen Consulting für die Compiler-Gruppe tätig. Dr. Thomas Willhalm ist Diplom-Mathematiker mit Nebenfach Physik und hat 2005 an der Universität Karlsruhe in Informatik promoviert. Seitdem berät er für die Firma Intel unabhängige Softwarehersteller. Ein Schwerpunkt seiner Arbeit ist dabei die Optimierung für neue Prozessoren inclusive Multicore-Architekturen. |





