
© Brent Olson, 123RF
David Strauss’ Firma Pantheon liefert Contentmanagement-Systeme auf Basis von Drupal und WordPress massenhaft aus. Container und entsprechende Kernelfunktionen helfen ihm, die Sites auf Servern in großer Dichte zu betreiben. Den Gründen für und seine Erfahrungen mit dem Setup widmet sich der Artikel.
Mit Hilfe unserer Plattform Pantheon [1] bauen, testen und veröffentlichen Entwickler Webseiten auf Basis von Drupal [2] und WordPress [3]. Heute verarbeitet die Plattform Milliarden von Anfragen pro Monat, die Anfänge im Jahr 2010 waren aber deutlich bescheidener.
Die erste Plattform nutzte pro Webseite je eine einzelne virtuelle Maschine, bot aber immerhin als erste im Markt vorgefertigte Entwicklungs-, Test- und Live-Umgebungen mit integrierten Deployment-Tools an. Zwar ließ sich eine Webseite auf diesem Wege schnell veröffentlichen, aber schon da zeichneten sich die Grenzen ab. Einzelne VMs lassen sich weder herunterskalieren, um kleine Seiten kostensparend zu betreiben, noch heraufskalieren, um sie hochverfügbar und fit für viel Datenverkehr zu machen.
Also bauten wir Pantheon 2011 um und nutzten damals so genannte Bindings, die 2016 als Container bekannt sind. Beim Umbau verfolgten wir ein paar Ziele:
- Freie Entwicklungstools für die Programmierer,
- günstige Angebote für kleine Sites,
- Angebote für Sites mit viel Traffic,
- all das auf einer einheitlichen Plattform mit konsistenter Performance, Entwicklertools und Projektmanagement-Möglichkeiten.
Die Konkurrenz bedachte zu diesem Zeitpunkt im Höchstfall drei der vier Merkmale. Meist bot sie kleine und große Sites an, lieferte diese aber auf radikal unterschiedlicher Infrastruktur aus.
Das führte nicht selten zu Überraschungen beim Launch und bei größeren Updates. Der Grund: Die Programmierer entwickelten die Seite auf einem einzelnen Server, anschließend landete sie jedoch auf dem Produktionsserver in einer geclusterten Infrastruktur. Beim Bauen und Testen der Site konnten die Entwickler die Performance daher nicht zuverlässig abschätzen.
Wir suchten also erstens nach einem Weg, PHP- und MySQL-/Maria-DB-Laufzeitumgebungen mandantenfähig anzubieten, ohne in die Ressourcenprobleme beim Shared Hosting zu laufen. Zweitens wollten wir den eingehenden Traffic für Tausende Seiten ausbalancieren, ohne ständig die Load Balancer neu einzurichten, da diese beim Rekonfigurieren kurz ihre Arbeit unterbrechen. Drittens benötigten wir ein Dateisystem für Drupal und WordPress, mit dem sich Sites kostengünstig entwickeln lassen, das aber aus Gründen der Skalierung sowie HA mehrere Webserver-Clients unterstützt.
Dichteprobleme
Dichte (Density) bedeutet in diesem Zusammenhang möglichst das optimale Ausnutzen vorhandener Hardware mit Hilfe von Software – für einen effizienten Rechnerbetrieb ein unerlässliches Ziel. Häufig führte Dichte aber zu Problemen mit der Sicherheit und der Performance. Die schlimmsten Security-Probleme, mit denen wir konfrontiert waren, entstanden über lange Zeit, wenn sich mehrere Kunden Runtime-Prozesse teilten. Mittlerweile gibt es viele Alternativen wie PHP-FPM [4], die das verhindern. Eine weitere große Herausforderung lag darin, eine konsistente Performance zu erreichen. Sie ließ sich erst mit Technologien überwinden, die der Artikel im folgenden beschreibt.
Die erste Aufgabe lautete, den Systemressourcen Luft zu geben. Effizienz erfordert es zwar, Seiten in großer Dichte zu betreiben, doch das blieb erfolglos, wenn entweder zu viele Sites auf dem Server liefen oder wenige sehr gut besuchte. Traditionell musste ein Admin also die Zuverlässigkeit zugunsten der Effizienz senken oder den umgekehrten Weg gehen. Als Hürde für ein Rebalancing erwies sich dabei, dass es nicht möglich war, den Dateistatus zu migrieren, während die zugehörige Anwendung lief. Zudem brachten die Kunden selten DNS- oder IP-Konfigurationen mit, die es erlaubten, individuelle Sites umzusiedeln.
Kontrolle mit Cgroups
Selbst bei schnellem Rebalancing treten mitunter Zugriffsspitzen auf. Die Ressourcenisolierung war früher primitiv – zumindest, wenn Prozesse sich den Linux-Kernel teilten. Gewinner-orientierte Mechanismen wie »nice« oder »ionice« konnten Prozesse priorisieren, aber jene mit niedriger Priorität hungerten.
Cgroups (Control Groups, [5]) ermöglichen heute eine feingranulare Kontrolle. CPU-Shares helfen dabei, die Prozesse zu priorisieren, ohne andere auszuhungern. Mit Cgroups mildert Pantheon die drängensten Ressourcen-Engpässe ab.
Ressourcenplanung
Eine intelligente Ressourcenverwaltung stößt bei einzelnen Maschinen schnell an ihre Grenzen. Daher stellt Pantheon für zahlende Kunden gleich mehrere kleine Container bereit.
Ein sinkender Anfragedurchsatz signalisiert, dass ein Container mehr Ressourcen verlangt. Seine Warteschleife für Anfragen füllt sich, schließlich lehnt er unter Umständen zusätzlichen Traffic ab. Styx [6], Pantheons Request-Routing-System, leitete die abgelehnten Anfragen dann an belastbare Container weiter.
Wie erwähnt sollten Systeme aus Security-Gründen keine Laufzeitprozess-Pools zwischen Kunden teilen. Dennoch ergibt es Sinn, ausführbare Dateien und Bibliotheken für alle Container auf einer Maschine nur einmal zu laden. Der Linux-Kernel ist klug genug, Arbeitsspeicher nicht doppelt zu belegen, wenn das System dieselbe Datei mehrmals verwendet. Allerdings scheitert er daran, solche Duplikate im Speicher zu vermeiden, wenn es nur um ähnliche Inhalte geht.
Aus diesem Grund bindet Pantheon nur eine Kopie jeder großen Runtime (etwa PHP 5.6 oder PHP 7) in das Dateisystems auf dem Server ein, etwa in »/opt/pantheon/php-5.6« , und startet dann in jedem Container die passende. Das spart etwa 10 GByte Arbeitsspeicher pro Server.
Containereinsatz
Trotz des aktuellen Hype um Linux-Container besitzt der Kernel an sich kein Konzept für Container. Er kennt User, Kontrollgruppen, Namespaces und weitere Mechanismen zur Isolation. Wer die miteinander kombiniert, erhält Container. LXC [7], Docker [8] oder Core OS [9] vereinfachen diesen Prozess und kümmern sich darum, die Images zu verteilen und zu verwalten.
Pantheon setzt auf Systemd, um die Kernelmechanismen zur Isolation zu verwenden. Während Container-fokussierte Software wie RKT beim Start möglichst viel an Isolation aktiviert, die der Admin stückweise abschaltet, deaktiviert Systemd einen Großteil der Isolationsfeatures. Diese ergänzen Admins nachträglich, was besser zur Arbeitsweise des Kernels passt und zu Pantheons Ziel, den Runtime-Speicher effizient zu nutzen. Es hindert uns auch daran, schlecht skalierende Isolationsfunktionen zu verwenden, etwa jeden Container mit NAT zu betreiben.
Anstatt Images zu verwenden, automatisiert Pantheon sowohl die initiale als auch die fortlaufende Container-Konfiguration mit Hilfe von Chef. Der Ansatz verhindert einen weitreichenden Overhead beim erneuten Ausliefern von Images, kann sich aber bei größeren Änderungen als fragil erweisen. In einigen Fällen bringen wir Änderungen daher nur an neuen Container-Hosts und Containern an.
Der Mähdrescher
Eine Sache, die uns recht früh auffiel, war der von aktiven, aber untätigen Daemons erzeugte Overhead. Beispielsweise lasten PHP-FPM-Pools oder ähnliche Daemons die CPU etwa um 0,2 Prozent aus. Während diese Last auf typischen Servern kaum eine Rolle spielt, beschäftigt sie bei Tausenden Servern mehrere Kerne.
Als Lösung hat Pantheon einen Mähdrescher (Reaper) implementiert, der laufende Container analysiert und diese stoppt, wenn sie sich als permanent untätig erweisen. Das würde Probleme verursachen, gingen dabei Sites offline. Doch die Server lassen sich dank einer Socket-Aktivierung mit Systemd innerhalb von Sekunden wiederbeleben, sobald neue Anfragen eintreffen. Selbst wenn der Sensenmann einen Container direkt vor der nächsten Anfrage stoppt, führt diese noch zum Erfolg. In der Tat erwies sich der Ansatz als so erfolgreich, dass Pantheon Container nur noch angehalten ausliefert und darauf wartet, dass sie beim ersten Request aufwachen.
Beispielkonfiguration
Der Einsatz von Socket Activation erfordert zwei Systemd-Units. Eine Socket-Unit (Abbildung 1) informiert Systemd darüber, auf welchen Stream es hören soll. Eine Service-Unit legt fest, welchen Dienst Systemd dämonisieren soll, sobald eine Anfrage eintrudelt. Pantheon legt dann Container-User mit UIDs von »10000« aufsteigend an, die jeweilige UID bestimmt auch über den Containerport. Abbildung 1 und Listing 1 zeigen als Beispiel die Systemd-Socket- und -Service-Dateien für Chef auf Nginx-Basis, wobei wir die Container-IDs im Dateinamen dynamisch generieren (»<%= @id %>« ) und dafür Standard-UUIDs nutzen.
Listing 1
nginx_123e4567e89b12d3a456426655440000.service
01 [Unit] 02 Requires=nginx_<%= @id %>.socket php_fpm_<%= @id %>.service 03 After=php_fpm_<%= @id %>.service 04 05 [Service] 06 User=<%= @id %> 07 Type=simple 08 ExecStart=/usr/sbin/nginx -c/srv/containers/<%= @id %>/nginx.conf 09 ExecReload=/bin/kill -HUP $MAINPID 10 TimeoutStartSec=45 11 TimeoutStopSec=15 12 RestartSec=10 13 CPUShares=512 14 15 # Tell nginx to inherit the listener socket file descriptor from socket activation. 16 Environment=NGINX=3; 17 18 # Nginx wants SIGQUIT instead of the default SIGTERM for a graceful shutdown. 19 # Also need mixed mode in case the children are orphaned. 20 KillMode=mixed 21 KillSignal=SIGQUIT 22 23 # Sandbox a root escalation. 24 NoNewPrivileges=true 25 26 # Use a file system namespace. 27 PrivateTmp=true
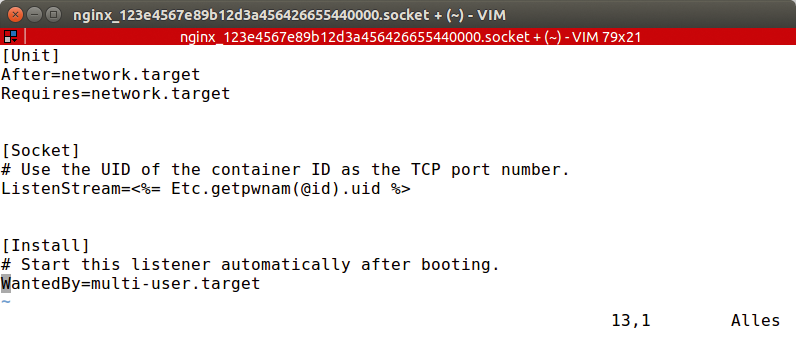
Abbildung 1: Die Socket-Unit informiert Systemd, auf welchem Port das Initsystem lauschen soll.
Styx: Balancierte Routen
Wichtig ist auch die Risikoverteilung. Ein schlecht designter Load Balancer multipliziert Risiken pro verfügbarem Backend anstatt sie zu dezimieren. Meist gehen Admins dieses Problem an, indem sie jedes Backend aktiv überwachen, um keine Anfragen an fehlerhafte oder nicht erreichbare Backends zu schicken. Weil das jedoch den kompletten Stack jeder Site aufwecken würde, wandte sich Pantheon einem Ansatz mit passivem Monitoring und Mehrfachversuchen zu. Dabei half der in Go geschriebene Load Balancer Styx [6], der einen ähnlichen Ansatz wie Kubernetes’ Ingress-Projekt [10] verfolgt. Taucht eine neue Anfrage auf, wählt Styx einen zufälligen Container aus, um sie zu bearbeiten. Ist die Warteschleife dieses Containers voll oder schlägt die Verbindung fehl, versucht Styx es bei anderen Containern, solange welche verfügbar sind. Er merkt sich zugleich die nicht erreichbaren Container und meidet sie vorübergehend.
Neukonfigurationen erweisen sich im Umfeld mit großer Dichte ebenfalls als Herausforderung. Die meisten Load Balancer starten oder laden Dienste nach einer Rekonfiguration neu. Angesichts der ausufernden Migrationen von Containern muss Pantheon solche Änderungen anders behandeln. Kommt die erste Anfrage an, lädt Styx langsam die Backend-Daten des Containers, also IP-Adressen und Portnummern. Migriert das System dann einen Container, macht es die gecachten Daten ungültig. Verwendet Styx solche veralteten Backend-Daten, scheitert er beim Verbinden, frischt seine Daten auf und versucht es erneut.
Valhalla: Web-Dateisystem
Diese schwebende Container-Infrastruktur wäre ohne das Entfernen der härtesten Abhängigkeit nicht möglich: dem Ort, an dem Drupal und WordPress ihre hochgeladenen Dateien speichern. Dieser Ort muss nicht nur stets beschreibbar sein, sondern auch konsistent zwischen den Webcontainern – auch in der Zeit zwischen mehreren Anfragen. Traditionelle und eher unflexible Systeme nutzen dafür bevorzugt das lokale Dateisystem oder ein aufwändig zu skalierendes Clustersystem wie Gluster-FS.
Um die Zahl der Container zu skalieren und diese dynamisch zu relokalisieren, hat Pantheon mit Valhalla [11] ein verteiltes Dateisystem entwickelt, das die Webobjekte verwaltet. Ohne zu sehr ins Detail zu gehen: Container hängen Volumes mit Hilfe eines in C geschriebenen Fuse-basierten Clients ein. Im Backend des Dateisystems lagern die Metadaten der Dateien und die Inhalte getrennt, ähnlich wie bei P-NFS [12].
Fazit
Indem wir die Metadaten von den Inhalten isolieren, können wir unsere vier Produktionscluster (die auf zwölf Servern laufen) so skalieren, dass sie über 100000 Webseiten anbieten. Indem wir moderne Kernelfeatures und Container effizient einsetzen und mit sorgfältigem Management zustandsloser Daten und mit Anfrage-Routing kombinieren, können wir das Verhältnis von Dichte und Performance zu unseren Gunsten einrichten.
Infos
- Pantheon: https://pantheon.io
- Drupal: https://www.drupal.org
- WordPress: https://wordpress.org
- PHP-FPM: http://php-fpm.org
- Cgroups: https://www.kernel.org/doc/Documentation/cgroup-v1/cgroups.txt,https://www.kernel.org/doc/Documentation/cgroup-v2.txt
- Styx: https://pantheon.io/blog/improving-performance-and-reliability-edge-golang-overhaul
- LXC: https://linuxcontainers.org
- Docker: https://www.docker.com
- Core OS: https://coreos.com
- Ingress: http://kubernetes.io/docs/user-guide/ingress/
- Valhalla: https://pantheon.io/blog/inside-pantheon-valhalla-filesystem
- P-NFS: http://www.pnfs.com





