
© robert cocquyt, 123RF
In den Kerneln von Linux und Android schlummern Mechanismen, welche die ganz eigenen Anforderungen von Mobilgeräten an drahtlose Netzwerk berücksichtigen. Der folgende Artikel zeigt, dass die Praxis das Glücksversprechen für Smartphone-Besitzer aber erst noch einlösen muss.
Bereits 2010 haben die Verkaufszahlen der Smartphones die der PCs überholt [1],[2]. Zugleich arbeiten die Apps auf den Mobilgeräten immer datenintensiver. Entsprechend erwartet zum Beispiel der Cisco Visual Networking Index (VNI), der das globale Datenverkehrsaufkommen prognostiziert, dass das Mobilfunk-Datenvolumen zwischen 2013 und 2018 um den Faktor 11 steigen und am Ende des Zeitraumes jenes von Draht-Verbindungen übersteigen wird [3].
Allerdings besitzen Drahtlosschnittstellen andere Charakteristika als die drahtgebundenen, für die das Internet ursprünglich entworfen wurde. Für Mobilgeräte ist zudem der Stromverbrauch wichtig, was zusätzlich limitiert [4]. Betriebssysteme und Infrastruktur müssen daher andere Verhaltensweisen implementieren. Ziel dieses Artikels ist ein Überblick über solche Optimierungen.
Unter Netzwerkperformance versteht man im Allgemeinen die Dienstgüte einer Ende-zu-Ende-Verbindung zweier Geräte. Sie bemisst sich mit den Größen Durchsatz, Latenz, Paketverlustrate und Jitter. Für die Anwendungen sind abgeleitete Größen wichtiger, da Verbindungsaufbau, Fehlerkorrektur und Flusskontrolle die sichtbare Datenrate und Reaktionszeit reduzieren [5],[6],[7].
Die zentralen Größen für die Performance-Bestimmung sind damit Goodput und Reaktionszeit. Goodput bemisst die den Applikationen bereitstehende Datenrate, und Reaktionszeit beschreibt die Zeit, die von einer Anfrage des Clients bis zur ersten Antwort des Servers vergeht. Beide Metriken sind von Abläufen auf allen Ebenen des Standard-Schichten-Modells beeinflusst.
Auf den Ebenen 1 und 2 arbeiten Mobiltelefone über WLAN oder Mobilfunknetze wie GSM, UMTS oder LTE. Der damit erzielte Durchsatz und die Latenz hängen nicht nur stark von der Funktechnologie ab, sondern auch von der Güte der Datenübertragung innerhalb der Funkzelle [8]. Aus Sicht des Betriebssystems erscheinen diese Einflussfaktoren nicht veränderlich. Dieser Artikel betrachtet sie deshalb auch nicht weiter.
Erst auf den Ebenen 3 und 4 kann das Betriebssystem eingreifen bei den Protokollen IP und TCP. Goodput und Reaktionszeit sind maßgeblich von den TCP-Algorithmen und deren Umgang mit Verbindungsaufbau, Paketverlusten oder Verbindungsabbrüchen abhängig.
Bufferbloat
Jede (mobile) Internetverbindung setzt sich aus vielen Teilstücken mit unterschiedlichen Geschwindigkeiten und Latenzen zusammen. Dies führt dazu, dass Router nicht immer Kapazitäten auf den ausgehenden Verbindungen frei haben, um eingehende Pakete sofort weiterzuleiten. Um die Geschwindigkeitsunterschiede und Lastspitzen abzufangen, speichert ein Router eingehende Pakete zwischen, bis die ausgehenden Leitungen wieder frei sind ([9], S. 1).
Nun würde man erwarten, dass die Puffer groß sind, um möglichst wenig Pakete verwerfen zu müssen. Doch die praktische Erfahrung zeigt, dass diese Erwartung falsch ist. Grund für das kontra-intuitive Verhalten: TCP besitzt die Eigenheit, sich der Datenrate des langsamsten Teils der Verbindung anzunähern [10]. Das Protokoll nimmt verworfene Pakete als Indikator für eine gesättigte und damit langsame Verbindung [11].
In Abbildung 1 ist bereits zum Zeitunkt t0 die Verbindung überlastet. Durch einen großen Puffer im Netzwerkgerät (Router, Accesspoint, Mobiltelefon) vor dem Bottleneck werden die ersten Pakete aber viel später – in t1 – verworfen, sodass TCP die Datenrate bis dahin trotz Überlast weiter erhöht. Wegen der langen Verzögerung erkennt TCP erst in t2 den Paketverlust und reduziert die Senderate. Warteschlangen und Latenz am Bottleneck wachsen dadurch immer weiter, ohne dass die Datenrate weiter steigt.
Mit der Round Trip Time (RTT) der Pakete wächst zudem die Zeit, die TCP benötigt, um Paketverluste festzustellen, was zugleich das Beheben der Paketverluste deutlich verlängert ([9], S. 61 und [12], S. 2). Erreichen wegen der langen Warteschlangen die Antwortpakete der Gegenstelle den Sender nicht mehr rechtzeitig, führt das im Extremfall sogar zum Abbruch der Verbindung. Eine konservative Haltung von TCP gegenüber dem Verwerfen von Paketen und fallende Preise bei Speicherbausteinen haben diese Entwicklung begünstigt ([9], S. 59). Zu große Puffer (Bufferbloat) senken also die Performance von Verbindungen in modernen Netzen.
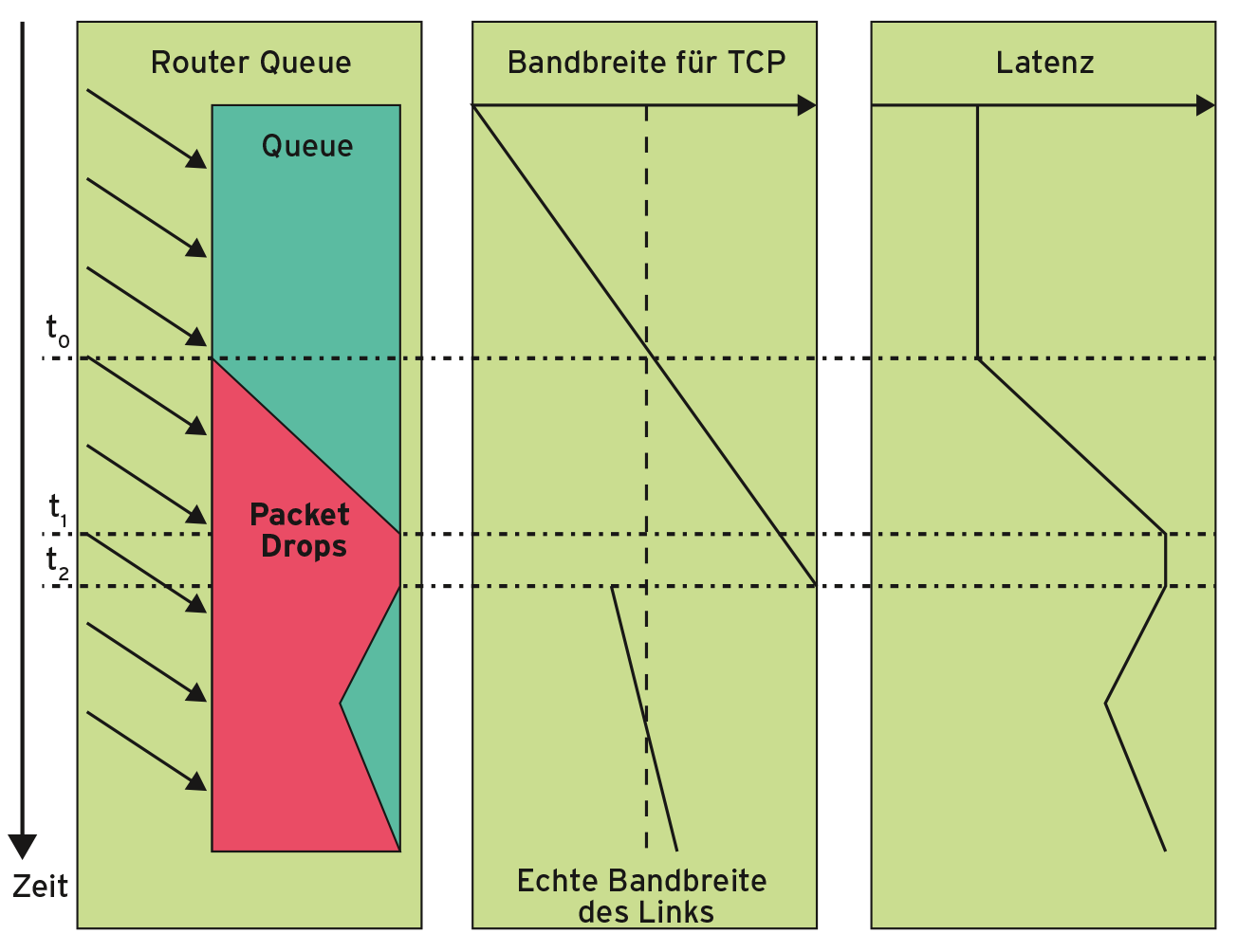
Abbildung 1: Warteschlangenlänge, Bandbreite und Latenz im Zeitverlauf einer Bufferbloat-Situation.
Nicht mehr auf Draht
Die Spezifikation von TCP für das rein drahtgebundene Internet ging von einigen Annahmen aus, die für drahtlose Schnittstellen so nicht mehr gelten. Zunächst variieren drahtlose Schnittstellen ihre Übertragungsraten und Latenzen dynamisch, während TCP mit statischen Datenraten und Latenzen rechnet.
Die meisten Drahtlosverbindungen sind außerdem weniger performant als ihre drahtgebundenen Pendants. Damit liegt der Flaschenhals vieler Verbindungen kurz vor dem Endgerät. Weiterhin sind Puffer für statische Datenraten und Latenzen konzipiert und fördern in Kombination mit dem möglichen Bottleneck das Entstehen von Bufferbloat direkt am mobilen Gerät ([9], S. 62).
Und: Auf drahtlosen Wegen sind viele Übertragungsfehler und Verbindungsabbrüche zu beklagen. Verlorene Pakete sind gemeinhin ein Zeichen von Leitungsüberlastung, bei drahtlosen Verbindungen treten Paketverluste jedoch im Regelbetrieb sogar als Bursts auf, beispielsweise wenn die Verbindung für eine Weile zusammenbricht [13].
TCP nimmt allerdings an, dass Paketverluste stets ein Zeichen von Überlast sind. Deshalb drosselt TCP nach einigen Bitfehlern Drahtlosverbindungen oft, obwohl die Leitung gar nicht ausgelastet ist. Weiterhin führt jeder Wechsel zwischen Mobilfunk- und WLAN-Netzwerken zum Abbrechen der einen und Neuaufbau der anderen Verbindung.
Drittens ist die Nutzungsdauer von Mobiltelefonen vergleichsweise kurz. Viele Anwendungen transferieren nur wenige Daten oder bauen sehr kurzlebige Verbindungen auf. Webbrowser erweisen sich hier als Killer-App [14], denn durchschnittlich ist ein Webseiten-Bestandteil (Bild, Stylesheet, Javascript) nur rund 2 KByte groß. Erfolgt der Transfer mit dem noch immer weitverbreiteten HTTP/1.1, entstehen sehr viele kurzlebige TCP-Verbindungen [15],[16].
Nicht selten ist der einzelne Transfer schon passiert bevor TCP die maximale Geschwindigkeit überhaupt erreicht hat, was bei der Masse negativ spürbar wird. Hinzu kommt, dass die Kürze der Verbindungen spontan auftretende Paketverluste erst sehr spät erkennbar macht und Lösungsstrategien kaum greifen.
Schließlich verhält sich auch die Hardware der Smartphones anders als in den unter Linux üblichen Laptops, Desktops oder Servern. In den meisten Mobiltelefonen liegt zum einen der so genannte Baseband-Prozessor, also das Funkmodem, nicht offen. Dass ihn eine propietäre Firmware ansteuert hindert das Betriebssystem daran, das Pufferverhalten des Baseband-Prozessor zu steuern [17],[18]. Zum anderen gilt die Akkulaufzeit als kritische Größe für den Erfolg von Mobiltelefonen. Die klassischen TCP-Implementierungen nehmen darauf jedoch keinerlei Rücksicht.
Lösungsansätze
Die geschilderten Probleme sind nicht neu. Es existieren auch einige etablierte Verfahren, die jeweils eigene Aspekte adressieren, um Antwortzeit oder Goodput zu verbessern. Sie lassen sich unterschieden danach, ob sie
- bestehende oder neu aufzubauende Verbindungen
- Fehlerbehandlung oder Normalbetrieb
- Sender, Empfänger oder Infrastruktur (Router) betreffen.
So verkürzen TCP Fast Open [19] und Initial Congestion Window [20] den Verbindungsaufbau nach einem Fehler und sind vor allem für die TCP-Endpunkte relevant. Analog versuchen Tail Loss Probe [21] und Early Retransmit [22] Paketverluste schneller zu erkennen oder besser darauf zu reagieren (Proportional Rate Reduction [22]).
Dieser Artikel konzentriert sich auf zwei Ansätze neueren Datums, die gerade intensiv diskutiert werden. Sie versprechen für Betriebssysteme als Verwalter der Kommunikationsendpunkte eine effiziente Einflussnahme. Der erste Ansatz besitzt zudem eine erhebliche Bedeutung für das gesamte Internet, nicht nur für mobile Endgeräte.
AQM und Co Del
Gegen die zuvor geschilderte Bufferbloat-Problematik scheint Active Queue Management (AQM) mit dem Controlled-Delay-Algorithmus (Co Del) eine gangbare Lösung zu sein. AQM-Algorithmen im Allgemeinen überwachen die Warteschlangenlänge von Netzwerkschnittstellen und verwerfen selbsttätig Pakete, noch bevor die Warteschlange zu lang wird. Dadurch lässt sich der TCP-Implementierung des Senders früher signalisieren, dass sie die Sendedatenrate aufgrund der unmittelbar bevorstehenden Überlastung drosseln soll. Außerdem begünstigt die kurze Wartezeit die Reaktionszeit der Fehlerbehandlung von TCP ([9], S. 59).
Schon 1998 hat die Internet Research Task Force über die Notwendigkeit für AQM informiert und als Lösung den Random-Early-Detection-Algorithmus (RED) auf Routern beworben ([23], S. 2). Er und seine Nachfolger zeigen allerdings in einigen Situation Schwächen und erfordern zudem Expertenwissen ([24], S. 1, [9], S. 63). AQM-Algorithmen nutzen außerdem die Warteschlangenlänge als Indikator für Überlast, was viele als ineffektiv ansehen [25].
Der Co-Del-Algorithmus versucht hingegen ohne Stellschrauben auszukommen, indem er als Indikator für eine Überlastsituation die Verweildauer der Pakete in der Warteschlange heranzieht. Dieser Wert verbessert zudem die gespürte Performance ([24], S. 6).
Konkret definiert eine Konstante »target« die akzeptable, ständige Wartezeit während eines Zeitraums »interval« . Liegt die minimale Wartezeit während eines ganzen Intervalls über »target« , verwirft Co Del das nächste zu versendende Paket. Anders als beim Tail-Drop-Mechanismus, der eingehende Pakete verwirft, erlaubt das Verwerfen von ausgehenden Paketen schneller den Paketverlust anhand von Lücken im TCP-Sequenzstrom zu erkennen, da nachfolgende Pakete nicht erst die Warteschlange durchlaufen müssen. Co Del verwirft sukzessive häufiger Pakete, bis die Wartezeit wieder unter dem Zielwert »target« liegt ([24], S. 6).
»target« sollte so gewählt sein, dass sich die Wartezeit minimiert, aber noch Raum für Verkehrsspitzen bleibt. Ein guter Wert für »interval« , der dem Sender genug Zeit gibt, um auf Paketverluste zu reagieren, ist die höchste zu erwartende RTT. Ein »target« von 5 Millisekunden funktioniert in den meisten Situationen gut, niedrigere Werte können den Durchsatz mindern und höhere Werte bringen nichts. Ein »interval« von 100 Millisekunden eignet sich für RTTs von 10 bis 1000 Millisekunden, bei optimaler Performance 10 bis 300 Millisekunden ([24], S. 6).
Co Del kommt also nicht völlig ohne Parameter aus, allerdings decken diese Standardwerte die meisten Situationen ab. Simulationen haben gezeigt, dass die Performance von Co Del genau so gut wie die von RED ist, in manchen Fällen sogar besser – speziell bei hochdynamischen Datenraten ([24], S. 7). Für Extremsituationen wie den Einsatz im Rechenzentrum oder auf sehr großen Routern ist eine unmodifizierte Version von Co Del allerdings nicht geeignet [26].
FQ-Co Del, BQL und TCP Small Queues
Interaktive Kommunikationsarten mit Paketarten geringer Größe wie ACKs, DNS-Anfragen, SSH, HTTP-Anfragen, ARP, ICMP und VoIP lassen sich mit FQ-Co Del, einer Kombination aus Co Del und fairem Paketscheduling, zusätzlich bevorzugen [27]. FQ-Co Del weist dazu jedem Flow – ein Datenstrom mit Paketen, dessen Quelle (Adresse und Port), Ziel (Adresse und Port) und Protokoll (TCP oder UDP) gleich sind – eine eigene Warteschlange zu.
Der Scheduler differenziert zwischen alten und neuen Flows und versendet bevorzugt Pakete aus neuen. Ein Flow gilt gewöhnlich so lange als neu, bis er einen Ethernetframe an Daten übertragen hat. Alte Flows löscht der Scheduler, wenn ihre Warteschlangen geleert sind, und er behandelt die nächsten Pakete dieses Flows bevorzugt als neuen Flow.
Co Del und FQ-Co Del arbeiten auf dem IP-Layer und lassen sich sowohl in Soft- als auch in Hardware implementieren ([24], S. 14). Beide sind bereits seit Kernel 3.5 im offiziellen Linux verfügbar [28]. Aber auch auf anderen Protokollebenen gibt es Puffer zur Trafficsteuerung: Unterhalb von Co Del haben die Linux-Entwickler Byte Queue Limits (BQL, [29]) implementiert. Sie steuern Warteschlangen auf der Ebene der Ethernettreiber und verhelfen auch Co Del zu mehr Effektivität [26]. Oberhalb von Co Del setzen TCP Small Queues [31] an. Sie verhindern, dass Applikationen zu viele Daten in ihre Socketpuffer schreiben.
Diese Kombination reduziert Bufferbloat effektiv. Allerdings stellen viele Netzwerkgeräte wie Kabel- und DSL-Modems (zumindest für den Endanwender) keine Möglichkeit bereit, AQM zu aktivieren ([24], S. 14). Auch in mobilen Geräten hat sich AQM bislang nicht durchgesetzt, da sich die Puffer der Paketaggregierung und der Fehlerkorrektur in für die AQM-Algorithmen unzugänglichen WLAN- und Mobilfunk-Layern befinden.
Multipath-TCP
Drahtlosverbindungen arbeiten meist unzuverlässiger als drahtgebundene. Allerdings können viele mobile Geräte – insbesondere Smartphones – mit mehr als einer Drahtlostechnologie funken, üblich sind eine WLAN und eine Mobilfunkschnittstelle. Das nutzt bei Standard-TCP nur wenig, da jede Schnittstelle eine eigene IP besitzt und das Protokoll zum Identifizieren einer Verbindung das 4er-Tupel aus IP-Adresse und den Port der Quelle und des Ziels heranzieht.
Transparente Handover zwischen beiden Infrastrukturen sind zwar theoretisch möglich, aber kaum verbreitet [32]. Mobile IP ist eine weitere Möglichkeit die Verbindungen aufrecht zu erhalten, drosselt aber die Performance und benötigt extra Hard- und Software [33],[34]. Einen besseren Weg geht die Protokollerweiterung Multipath TCP (MPTCP), indem sie nicht nur IP-Adresswechsel toleriert, sondern auch mehrere Verbindungen gleichzeitig bedient.
Zwei MPTCP-fähige Endpunkte sind in der Lage, eine MPTCP Verbindung mit mehreren Subflows aufzubauen. Ein Subflow lässt hierbei als eine normale TCP-Verbindung betrachten. Als Beispiel soll die MPTCP-Session eines per WLAN verbundenen Mobilgerätes dienen: Während des Aufbaus des ersten Subflows werden die MPTCP-Fähigkeit geprüft und kryptografische Schlüssel ausgetauscht. Das Mobilgerät kann weitere Subflows zur Verbindung hinzufügen, indem es zum selben Server eine Verbindung über das Mobilfunknetz herstellt.
Um Datensicherheit und -schutz zu gewährleisten, schickt das Protokoll die eben generierten kryptografischen Schlüssel als Authentifizierungsmerkmal mit. Beide Endpunkte können Subflows zu jedem beliebigen Zeitpunkt erzeugen oder entfernen, und sie verteilen den Verkehr nach eigenem Ermessen auf die Subflows. Denkbar ist, dass das mobile Gerät umgehend einen zweiten Subflow aufbaut, um einerseits die Umschaltzeit im Fehlerfall zu minimieren und andererseits beide Verbindungen für eine bessere Datenrate zu bündeln. Wenn das Mobilgerät eher die Strategie verfolgt, den Akku zu schonen, wird es vielleicht den zweiten Subflow nur aufbauen, falls die WLAN-Verbindung abbricht.
Kompatibel zu TCP bleiben
Wie Abbildung 2 verdeutlicht, verfolgt MPTCP das Ziel, kompatibel zum aktuellen Internet zu sein. Einerseits zeigt es sich transparent gegenüber Applikationen, sodass die Unterstützung im Netzwerkstack des Betriebssystems für MPTCP ausreicht. Andererseits verhalten sich die Subflows – abgesehen von einer neuen TCP-Option – genau wie normale TCP-Verbindungen, um Firewalls und Middleboxen passieren zu dürfen. Dies ist notwendig, da diese Geräte TCP-Sequenzummern und IP-Adressen ändern, Verbindungen bei Lücken in der Sequenznummernfolge beenden und Pakete verwerfen, die unbekannte TCP-Optionen nutzen.
MPTCP implementiert Features, um diesen Herausforderungen zu begegnen: Jeder Subflow erhält eine eigene TCP-Sequenznummernfolge (SSN), welche das Protokoll auf die Sequenzfolge der MPTCP-Session (DSN) abbildet. Weiterhin referenziert MPTCP Interfaces mit IDs anstelle von IP-Adressen und prüft, ob die Subflows nutzbar sind und verwirft sie im Negativfall. Kann MPTCP gar keine Verbindung aufbauen, fällt das Protokoll auf Standard-TCP zurück. MPTCP verspricht zwar mobile Systeme besser zu unterstüzen, ist aber noch ein experimenteller Internetstandard.
Aus dem gleichen Grund existieren zwar Patches, die MPTCP in den Android- und Linux-Kernel implementieren, aber nicht Teil des Mainline-Kernels sind ([35],[36],[37]). Da Empfänger und Sender MPTCP-kompatibel sein müssen, ist MPTCP bis zur Aufnahme in den Kernel hauptsächlich in geschlossenen Systemen anzutreffen. Beispielsweise setzt Citrix die Technologie auf ihren Netscaler Plattformen ein [38], und Apple nutzt MPTCP zur Datenübertragung zwischen I-OS-7-Geräten und den Siri-Servern [39].
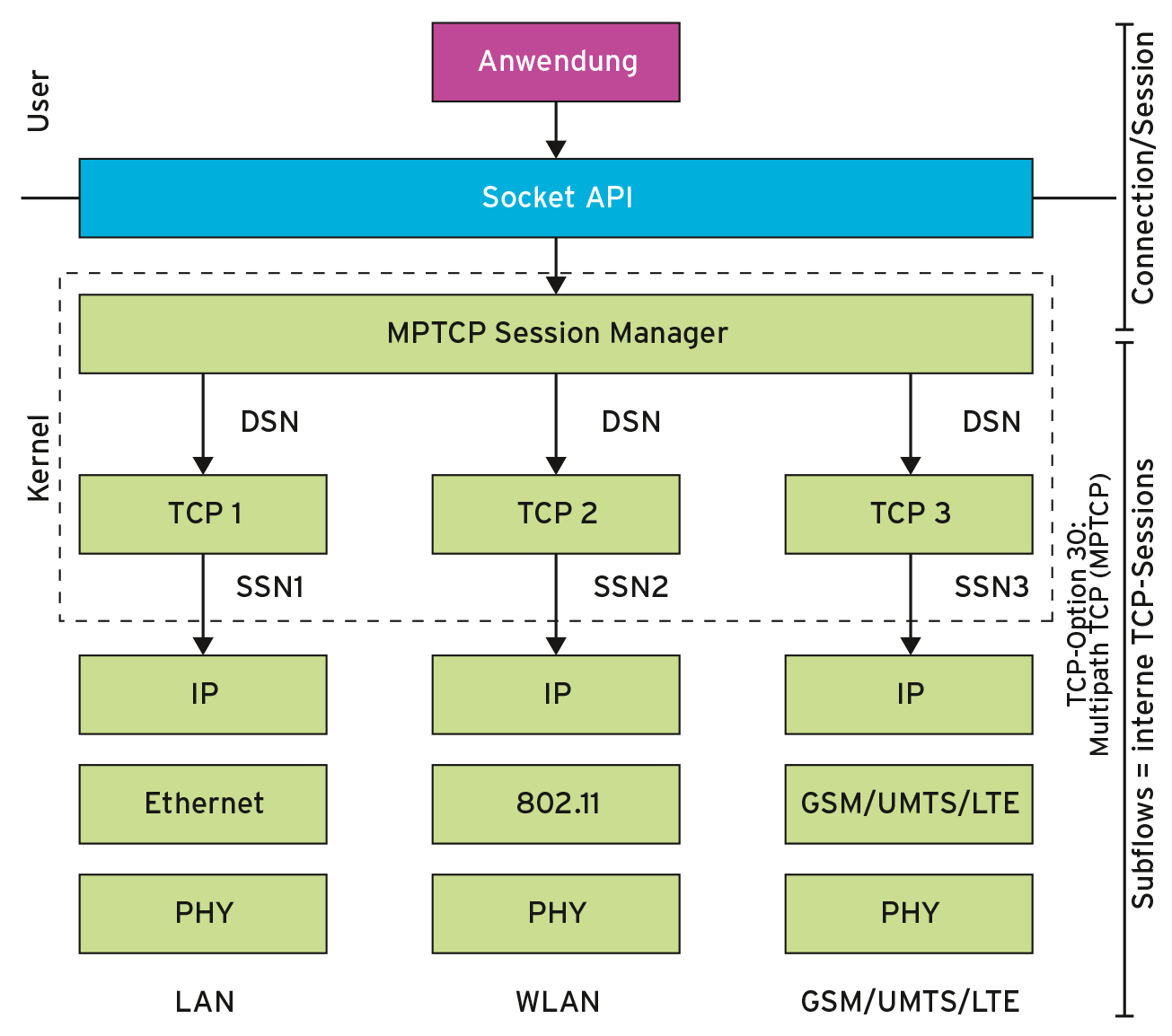
Abbildung 2: MPTCP fasst transparent für Applikationen und Infrastruktur mehrere Subflows über mehrere Schnittstellen hinweg zu einer MPTCP-Session zusammen.
Informationen sind rar
Sowohl AQM-Co Del als auch MPTCP sind beide noch nicht im praktischen Alltag von Linux-Anwendern und Administratoren angekommen. Wer sie heute nutzen will, muss etwas Eigeninitiative entwickeln und Arbeit leisten. Die Autoren möchten deshalb Erfahrungen aus Tests mit diesen Ansätzen vermitteln, die vielleicht bei der Entscheidung helfen können, sich mit diesen Themen tiefer auseinanderzusetzen.
Die so genannte Middleboxes (ALG, NAT, VPN Concentrator, SSL-Terminator et cetera) erweisen sich für alle erweiterten Formen von IP und TCP als problematisch, da sie – anders als reine Router – gerne tief in die Header von IP und TCP eindringen, dort Parameter ändern oder Filter auf Headerfelder definieren. So ist die TCP-Variante MPTCP durch den Wert 30 im Feld »options« des TCP-Headers gekennzeichnet [36] oder TCP Fast Open durch den – für experimentellen Einsatz vorgesehenen – Wert 254 [7]. Wenn nun Middleboxes TCP-Optionen ausfiltern, scheitern die neuen TCP-Varianten.
Leider publizieren die Anbieter solcher Middleboxes (Barracuda, Checkpoint, Juniper oder McAfee) keine Informationen über ihr Blockierverhalten bei experimentellen oder neuen TCP-Optionen heraus. Bei Cisco gibt es zumindest eine Liste über die MPTCP-Unterstützung der eigenen Geräte [40]. Eine Arbeit mit den neuen Ansätzen erfordert damit derzeit eine genauere Beschäftigung mit dem jeweiligen Hersteller.
In der Praxis ist es oft nicht einfach zu erkennen, wo der Bufferbloat entsteht. Findet er sich an einem Gerät, das der Admin nicht kontrollieren kann, bleibt nur die Möglichkeit, auf einem vorgeschalteten Router die Rate künstlich zu begrenzen, um damit das Bottleneck in das eigene Hoheitsgebiet zu verschieben und dort AQM einzusetzen ([24], S. 14).
Benchmarks nötig
Bislang ist die Frage offen geblieben, ob der Nutzen den Aufwand rechtfertigt, also: Gibt es derzeit einen messbaren positiven Effekt auf die Performance? Dazu haben die Autoren umfangreiche Tests auf einem typischen Mobilgerät, einem Sony Xperia Z1 compact D5503, absolviert. Als Betriebssystem in der Testumgebung setzten sie auf Cyanogenmod 11, das Pendent zu Android 4.4, das einen Android-Linux- Kernel 3.4.0 aufweist. Das Problem, dass »fq_codel« erst ab Kernel 3.5 verfügbar ist, lösten die Tester mit Compat, dem Linux Backport Modul [41]. MPTCP 0.86 holten sie aus einem Nexus 5, dessen Kernel MPTCP bereits unterstützt [42], und passten das Ganze auf den Cyanogenmod-Kernel an.
Das erste Szenario hat im Mobilfunk-Netz (3G) und für die mehrere WLAN-Standards (IEEE 802.11*) Latenz und Datenrate (Up- und Download) für den Standardalgorithmus Fifo sowie »fq_codel« gemessen. Dazu setzten die Tester Netperf [43] ein, punktuell ergänzt um Messungen von Standard-HTTP-Anfragen, da dies gewöhnlich sehr realitätsnahe Daten liefert.
Im zweiten Szenario liefen Tests zur Bewertung von MPTCP. Im 3G-Fall befand sich der Netperf-Server auf einem virtuellen Server (3,3 GHz, 1 GByte RAM, 100-MBit-Anbindung) bei einem Hoster (Hetzner). Für die WLAN-Tests stand ein Netperf-Server im lokalen Netz (2x 2,5 GHz, 4 GByte RAM, 1000 Mbit) zur Verfügung. Auf beiden Servern waren Debian-basierte Distributionen installiert. Die MPTCP-Unterstützung stellte ein aus dem APT-Repository des MPTCP-Projekts stammender Linux Kernel 3.5 bereit.
Tests im Mobilfunknetz
Die Matrix aller erhobenen Testergebnisse ist zu umfangreich, um sie hier komplett wiederzugeben. Die folgenden Aussagen beschränken sich darun auf die zentralen Erkenntnisse. Für das erste Szenario zur Bewertung von FQ-Co Del haben die Tester zunächst die TCP-Latenz (TCP_RR-Test) zum Server bei gleichzeitig ausgelastetem Uploadkanal (TCP_STREAM-Test) gemessen. Eine zweite Testreihe lastete zusätzlich den Downloadkanal (TCP_MAERTS-Test) aus.
Wie in Abbildung 3 veranschaulicht, erreichte »fq_codel« bei kompletter Auslastung beider Kanäle einer 3G-Verbindung keine signifikante Änderungen gegenüber dem bisherigen Standard Fifo. Bei alleiniger Auslastung des Uploadkanals hingegen reduzierte sich die Latenz mit »fq_codel« deutlich von 1115 auf 260 Millisekunden. Die während der Tests gemessen Datenraten blieben aber praktisch gleich, wie in Abbildung 4 zu erkennen ist.
In einem weiteren Test wurde die Ladezeit der Homepage von Linux-Magazin Online bei ausgelastetem Uploadkanal gemessen. Die Auswirkungen der Latenzreduktion werden hier deutlicher, da für einen Seitenaufruf ungefähr 60 bis 70 HTTP-Anfragen anfallen. Abbildung 5 zeigt, dass sich die Transferzeit der Homepage über 3G mit »fq_codel« um 40 Sekunden verkürzt.
Abbildung 3: Gemessene Latenz im 3G-Netz mit traditionellem Fifo-Algorithmus und neuem »fq_codel«.
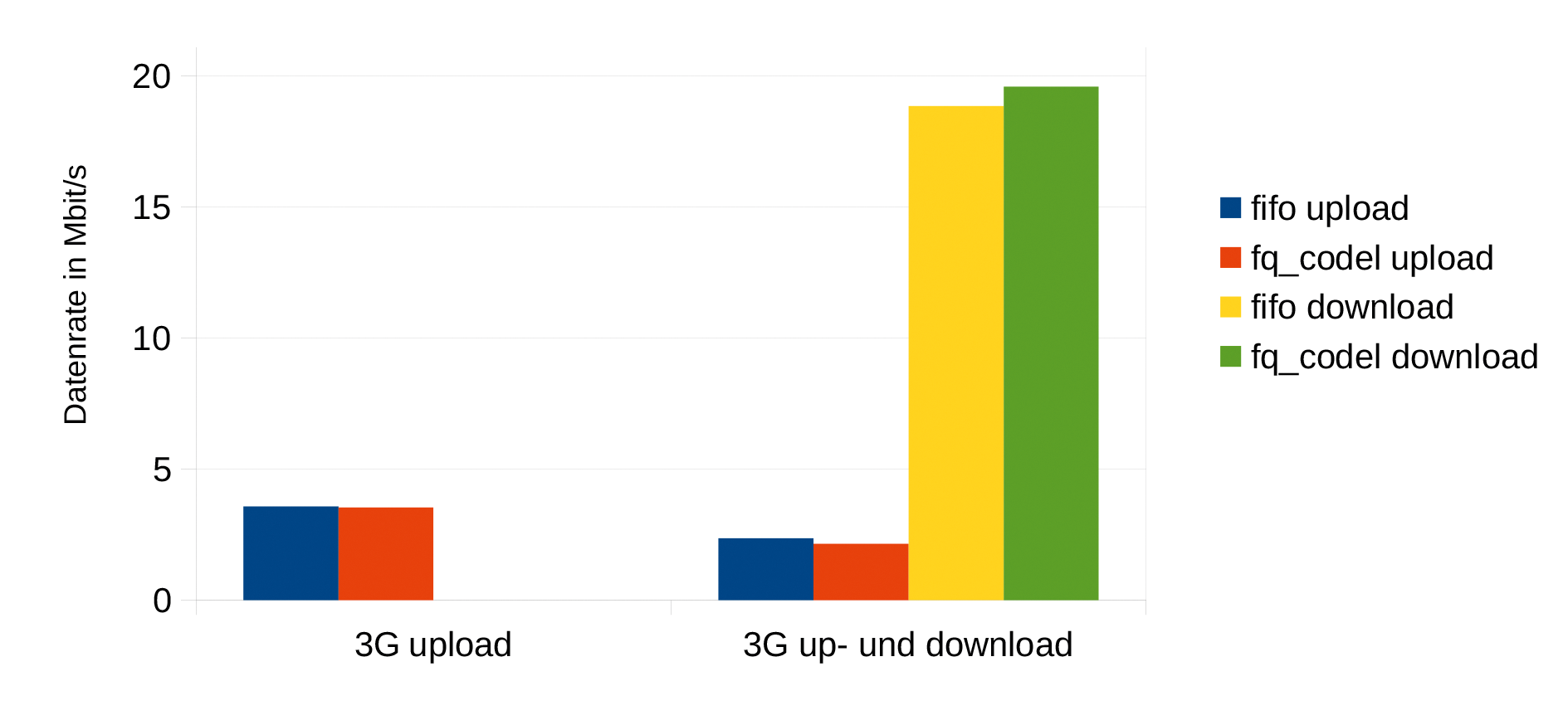
Abbildung 3
gemessene Datenrate im 3G-Netz.” width=”300″ height=”138″ /> Abbildung 4: Parallel zu Abbildung 3 gemessene Datenrate im 3G-Netz.
https://www.linux-magazin.de
mit Fifo und »fq_codel«.” width=”300″ height=”156″ /> Abbildung 5: Übertragungszeit von https://www.linux-magazin.de mit Fifo und »fq_codel«.Testergebnisse im WLAN
Im WLAN zeigen die Tests mit Netperf und normalen HTTP-Anfragen ein noch uneinheitlicheres Bild. Je nach WLAN-Standard führt »fq_codel« zu leicht besseren, aber auch zu schlechteren Ergebnissen bei Latenz und Datenrate. Generell arbeitet »fq_codel« mit höheren WLAN-Bitraten schlechter zusammen. Besonders problematisch sind derzeit 802.11n und Weiterentwicklungen wie 802.11ac, da der Algorithmus dort die massiv eingesetzte Paketaggregierung behindert. Die Performance wird noch weiter beeinträchtigt, wenn Up- und Downlink zeitgleich belastet sind.
Der FQ-Co-Del-Algorithmus ist nach diesen Erfahrungen im Mobilfunk-Netz bereits heute ohne Nachteile einsetzbar. Die Verringerung der Latenz ist in realistischen Szenarien deutlich spürbar. Eine Nutzung im WLAN erfordert aber zumindest eigene Tests. Derzeit sind noch Inkompatibilitäten von Co Del und WLAN-Standards zu beobachten, die hier bis zur besseren Integration in die WLAN-Protokolle [44] zur Vorsicht raten lassen.
Der MPTCP-Failover-Test
Bei der Bewertung von MPTCP haben sich die Autoren auf die Failover-Szenarien konzentriert, da die Performance bei der Bündelung von WLAN und 3G durch hohe Latenz sowie Jitter im Mobilfunknetz schlechter als bei einer einzelnen Verbindung ausfallen kann [45]. Weiterhin ist ein paralleler Betrieb mehrerer Pfade nicht einfach dadurch zu erreichen, dass MPTCP im Linux-Kernel aktiviert wird, da Android die mobile Datenverbindung bei einer aktiven WLAN-Verbindung trennt. Der parallele Betrieb mehrerer Pfade würde die Umprogrammierung der Netzwerkroutinen erfordern. Positiv ausgedrückt, reicht die Aktivierung von MPTCP im Linux-Kernel bereits jetzt aus, um die Robustheit von TCP-Verbindungen gegen kurzzeitige Ausfälle der Funkverbindungen zu erhöhen.
Für den MPTCP-Failover-Test initiierten die Tester eine Netperf-Sitzung mit MPTCP über die WLAN-Schnittstelle. Während des Datentransfers trennten sie die WLAN-Verbindung. Nach Aufbau einer Internetverbindung über das Mobilfunknetz fügte MPTCP dann automatisch die 3G-Verbindung zur Sitzung hinzu, sodass der Datentransfer weiterlief. Später wurde auf die gleiche Art wieder auf WLAN umgeschaltet.
Die Abbildung 6 zeigt, dass bei aktiviertem MPTCP nach Verlust der WLAN-Verbindung die MPTCP-Verbindung über Mobilfunk nach ungefähr 4 Sekunden weitergeführt werden kann. Das zurückschalten auf WLAN bedarf einer Übertragungspause von 2 Sekunden. Die Umschaltzeiten lassen sich durch den Parallelbetrieb beider Schnittstellen reduzieren und bei geplanten Netzwerkwechseln komplett eliminieren.
Vergleiche von MPTCP-Verbindungen mit jeweils einem einzelnen Stream und reinen TCP-Verbindungen zeigen keine signifikanten Performanceunterschiede auf. MPTCP ist jedoch wie beschrieben ein noch experimentelles Protokoll, ist nicht im Mainline-Linux-Kernel enthalten und erfordert Unterstützung von Client und Server. Weiterhin verwerfen einige Firewalls oder andere Middleboxen Pakete mit der neuen TCP-Option. MPTCP weicht in diesem Fall auf Standard-TCP aus, muss dafür aber ein Timeout abwarten, sodass es im schlechtesten Fall zum verzögerten Verbindungsaufbau kommt. Die Autoren empfehlen daher MPTCP zunächst für geschlossene Systeme.
Abbildung 6: Der MPTCP-Failover-Test mit gemmessenen Ausfallzeiten und Datenraten.
Fazit
Neuere Forschungen zeigen, dass Anstrengungen notwendig sind, um auch in Zukunft mobile Systeme mit hinreichender Performance und Robustheit an das Internet anzubinden. Linux bietet hier gute Ansätze, die allerdings zu wenig bekannt sind. Mit dem AQM in der FQ-Co-Del-Form steht ein aussichtsreicher Kandidat gegen Bufferbloat-Probleme bereit. Weiterhin existiert mit MPTCP eine gute Lösung gegen Verbindungsabbrüche bei Netzwerkwechseln.
Die Tests zeigen aber, dass beide Ansätze weder die mobile Netzwerkproblematik im Ganzen lösen noch produktiv ohne Weiteres einzusetzen sind. Diese Einschränkungen rühren aus der mangelnden Co-Del-Unterstützung der führenden Netzwerk- und Security-Ausrüster im Besonderen und der konservativen Einstellung gegenüber neuen TCP-Optionen im Allgemeinen her.
Als eine Art Beifang haben die Messungen anlässlich dieses Artikels ergeben, dass sich in den Mobilfunknetzen von 1&1 (Vodafone) und Blau.de (E-Plus) keine MPTCP-Verbindungen aufbauen ließen, da dort die nötige TCP-Option aus den Paketen entfernt wurde. Bei T-Mobile gelangen die MPTCP-Tests.
Es gibt noch einige Arbeiten zu verrichten, bis mobile Geräte im Netz optimal arbeiten. Bis dahin müssen Administratoren und Entwickler, denen die Performance ihrer mobilen Systeme besonders am Herzen liegt, eigene realistische Testumgebungen aufbauen.
Infos
- J. West, M. Mace: “Browsing as the killer app”: http://www.joelwest.org/Papers/WestMace2010-WP.pdf
- PC- vs. Smartphone-Verkaufszahlen: http://en.wikipedia.org/wiki/Mobile_operating_system#Market_share, http://en.wikipedia.org/wiki/Market_share_of_personal_computer_vendors#Unit_sales
- “Cisco Visual Networking Index, 2013-2018”: https://www.cisco.com/c/en/us/solutions/collateral/service-provider/ip-ngn-ip-next-generation-network/white_paper_c11-481360.html
- Y. Nishi, “Lithium ion secondary batteries; past 10 years and the future”: Journal of Power Sources 100 (2001), Nr. 1, S. 101
- “Increasing TCP’s Initial Window”: RFC 5256, S. 3, https://tools.ietf.org/html/rfc5256
- “Tail Loss Probe (TLP)”: https://tools.ietf.org/html/draft-dukkipati-tcpm-tcp-loss-probe-01
- “TCP Fast Open”: https://tools.ietf.org/html/draft-ietf-tcpm-fastopen-09
- C. E. Shannon, “Communication in the presence of noise”: Proceedings of the IRE 37 (1949), Nr. 1, S. 10 ff., http://nms.csail.mit.edu/spinal/shannonpaper.pdf
- J. Gettys, K. Nichols, “Bufferbloat: Dark buffers in the internet”: Queue 9 (2011), Nr. 11, 40, https://dl.acm.org/citation.cfm?id=2071893
- B. Gijsbers, D. D. Akkoorath, “Performance simulation of buffer bloat in routers”: http://www.delaat.net/netbuf/bufferbloat_BG-DD.pdf, S. 1 f.
- “TCP Congestion Control”: RFC 5681, S. 12, https://tools.ietf.org/html/rfc5681
- Jonathan Corbet, “The CoDel queue management algorithm”: https://lwn.net/Articles/496509/
- C. Hsu et al., “Rate control for robust video transmission over burst-error wireless channels”: IEEE Journal on 17, Nr. 5, S. 756-773, http://sipi.usc.edu/~ortega/papers/HsuOrtegaKhansari99.pdf
- J. West, M. Mace, “Browsing as the killer app”: http://www.joelwest.org/Papers/WestMace2010-WP.pdf
- “TCP over Second (2.5G) and Third (3G) Generation Wireless Networks”: RFC 3481, S. 17, https://tools.ietf.org/html/rfc3481.html
- S. Ramachandran, “Web metrics: Size and number of resources”: https://developers.google.com/speed/articles/web-metrics
- A. Back, “How free is my phone?”: http://www.h-online.com/open/features/How-free-is-my-phone-1634071.html
- E. Dumazet, “[Bloat] Testing fq_codel on Android Galaxy Nexus AK kernel”: https://lists.bufferbloat.net/pipermail/bloat/2013-February/001368.html
- T. Schöler, M. Feilner, “Netzbeschleunigung mit TCP Fast Open”: Linux-Magazin 02/13, S. 70, https://www.linux-magazin.de/Ausgaben/2013/02/TCP-Fast-Open
- J. Corbet, “Increasing the TCP initial congestion window”: https://lwn.net/Articles/427104/
- “Tail Loss Probe (TLP): …”: https://tools.ietf.org/html/draft-dukkipati-tcpm-tcp-loss-probe-01
- N. Dukkipati et al., “Proportional Rate Reduction for TCP”: https://research.google.com/pubs/pub37486.html
- “Recommendations on Queue Management and Congestion Avoidance in the Internet”: RFC 2309, S. 2, https://tools.ietf.org/html/rfc2309
- K. Nichols, V. Jacobson, “Controlling queue delay”: Communications of the ACM 55 (2012), Mai, Nr. 7, S. 42 bis 50, https://queue.acm.org/detail.cfm?id=2209336
- W. c. Feng et al., “The BLUE active queue management algorithms”: IEEE/ACM Transactions on Networking 10 (2002), August, Nr. 4, 513 bis 528, http://www.thefengs.com/wuchang/blue/ToN-02.pdf
- Bufferbloat-Projekt, “Codel Overview”: https://www.bufferbloat.net/projects/codel/wiki/Wiki?version=70
- “FlowQueue-Codel”: https://tools.ietf.org/html/draft-hoeiland-joergensen-aqm-fq-codel-00
- E. Dumazet, “[PATCH v12] codel: Controlled Delay AQM”: https://lwn.net/Articles/496502/
- J. Corbet, “Network transmit queue limits”: https://lwn.net/Articles/454390/
- T. Høiland-Jørgensen, “The State of the Art in Bufferbloat”: https://www.ietf.org/proceedings/86/slides/slides-86-iccrg-0.pdf
- J. Corbet, “TCP small queues”: https://lwn.net/Articles/507065/
- “Architecture for Mobile Data Offload over Wi-Fi Access Networks”: https://www.cisco.com/c/en/us/solutions/collateral/service-provider/service-provider-wi-fi/white_paper_c11-701018.html
- “IP Mobility Support for IPv4, Revised”, RFC 5944: https://tools.ietf.org/html/rfc5944
- “Mobility Support in IPv6”, RFC 6275: https://tools.ietf.org/html/rfc6275
- J. Corbet, “Multipath TCP: an overview”: https://lwn.net/Articles/544399/
- “TCP Extensions for Multipath Operation with Multiple Addresses”, RFC 6824: https://tools.ietf.org/html/rfc6824
- Linux Kernel Multipath TCP: http://multipath-tcp.org/pmwiki.php/Main/HomePage
- J. Gudmundson, “Maximize mobile user experience with NetScaler Multipath TCP”: http://blogs.citrix.com/2013/05/28/maximize-mobile-user-experience-with-netscaler-multipath-tcp/
- O. Bonaventure, “Apple seems to also believe in Multipath TCP”: https://perso.uclouvain.be/olivier.bonaventure/blog/html/2013/09/18/mptcp.html
- “MPTCP and Product Support Overview”:https://www.cisco.com/c/en/us/support/docs/ip/transmission-control-protocol-tcp/116519-technote-mptcp-00.html
- Linux Kernel Backport Compatibility Module: https://mcgrof.github.io/compat/
- MPTCP-Kernel für das Nexus 5: https://github.com/gdetal/mptcp_nexus5
- Netperf-Suite: http://www.netperf.org
- “FQ Codel on Wireless-n”: http://www.bufferbloat.net/projects/cerowrt/wiki/Fq_Codel_on_Wireless
- Gary Miguel, Angad Singh, “Multipath TCP over WiFi and 3G links”: http://reproducingnetworkresearch.wordpress.com/2012/06/04/multipath-tcp-over-wifi-and-3g-links/





