
© Glen Gaffney, 123RF.com
Moderne Grafikkarten zeichnen sich durch eine Vielzahl (mehrere Hundert) von parallel arbeitenden Kernen aus, die Berechnungen sehr schnell ausführen. Da sich die Hardware stark von der gebräuchlichen x86-Prozessorarchitektur unterscheidet, fordert die Programmierung besonders am Anfang einiges Umdenken vom Entwickler.
Programmierbar
Ein Grafikkartenprozessor (GPU, Graphics Processing Unit) arbeitet nach dem Pipeline-Prinzip: Mehrere hintereinander geschaltete Schritte berechnen den Farbwert eines Pixels. Die einzelnen Funktionen dieser Grafik-Pipeline waren bis vor wenigen Jahren hart verdrahtet. Die Hardware einer modernen GPU ist so aufgebaut, dass die einzelnen Module frei programmierbar sind. Damit sind Grafikkarten für alle interessant, die auch jenseits der Grafik-Ausgabe viel Rechenleistung benötigen und deren Aufgabenstellung parallelisierbar ist. Einen weiteren Schub für GPGPU (General Purpose Computation on GPU) hat gegeben, dass Nvidia diese Entwicklung unterstützt [1] und ein SDK herausgibt.
Was ist der Unterschied im Aufbau der Hardware zwischen einer CPU und einer modernen GPU mit mehreren Kernen? Es gibt hierzu eine sehr einfache Klassifikation aus der Informatik, die die Bearbeitung von Befehlen und Daten im Verhältnis zueinander beschreibt. Das erste Kriterium unterscheidet, ob die CPU in einem Schritt einen Befehl (SI, Single Instruction) oder unterschiedliche Befehle (MI, Multiple Instruction) abarbeitet. Das zweite Kriterium untersucht, ob der Prozessor einzelne Daten (SD, Single Data) oder eine Vielzahl unterschiedlicher Daten (MD, Multiple Data) parallel verarbeitet (siehe Abbildung 1).
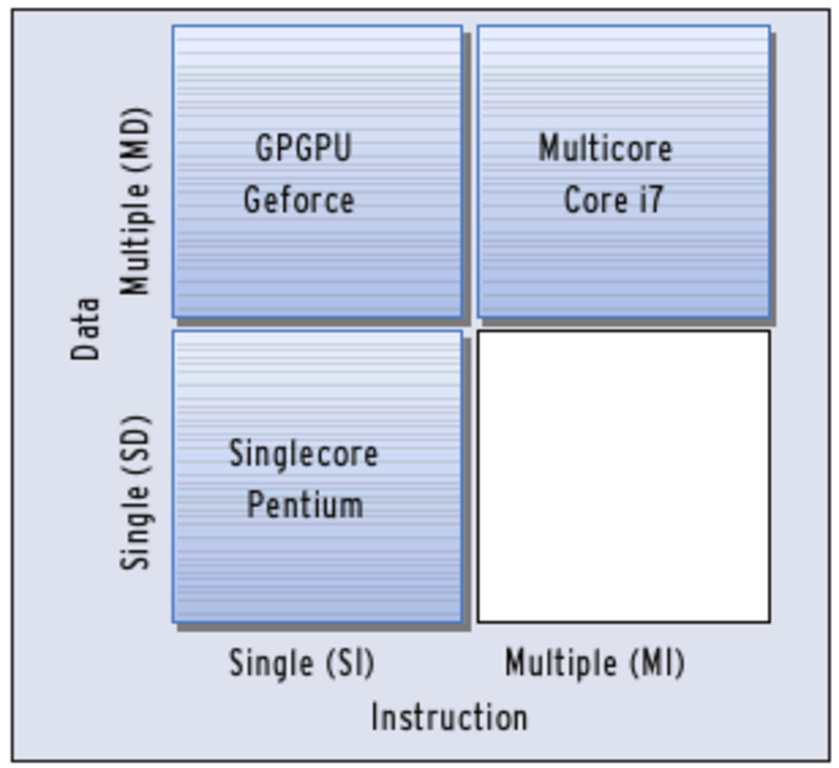
Abbildung 1: Obwohl die Klassifikation von Flynn aus dem Jahr 1966 stammt, lassen sich auch heutige Systeme grob einer der Klassen zuordnen. Nur für MISD-Systeme gibt es keine sinnvolle Anwendung.
Der klassische x86-Rechner mit einem Kern (wie 486, Pentium) ist vereinfacht ein SISD-Rechner: Zu einem Zeitpunkt arbeitet die CPU genau eine Instruktion ab. Die inzwischen vorherrschenden Multicore-CPUs arbeiten nach dem MIMD-Prinzip. So können beispielsweise vier Kerne unabhängig voneinander unterschiedliche Befehle für unterschiedlichen Daten ausführen.
Ein Befehl, viele Daten
Moderne GPUs sind im Gegensatz dazu mit SIMD-Systemen verwandt: Sie führen auf unterschiedlichen Daten zu einem Zeitpunkt die identische Instruktion aus. Auf den klassischen, datenparallelen SIMD-Systemen läuft somit auf allen Recheneinheiten der identische Kontrollfluss. Eine If-Verzweigung mit alternativen Ablauffäden (Threads) ist nicht möglich. Nvidia hat die SIMD-Technik weiterentwickelt und nennt das Resultat SIMT, wobei MT für Multiple Threads steht. Sie macht es möglich, dass Threads unterschiedliche Pfade durch das Programm nehmen.
Das Listing 1 zeigt eine einfache C-Funktion, die als Parameter einen Index »i« und ein Feld »arr« von vorzeichenbehafteten ganzen Zahlen erhält und jeweils das Vorzeichen für ein Feldelement berechnet. Die Funktion gibt 1 für positive und -1 für negative Zahlen zurück. Ist die Zahl 0, dann bekommt der Aufrufer auch 0 zurück. Die Funktion lässt sich parallel ausführen, zum Beispiel auf einem Feld mit den Werten -12, 0, 24, 36. Ein vollwertiges MIMD-System mit vier Kernen und der gleichen Anzahl von Threads berechnet das Vorzeichen unabhängig voneinander. Jeder Thread durchläuft die Funktion unbeeinflusst von den anderen.
| Listing 1: Unterschiedlicher Kontrollfluss |
|---|
01 signed int sign(unsigned int i, signed int arr[]) {
02 signed int result=0;
03 if (arr[i]>0)
04 result=1;
05 else if (arr[i]<0)
06 result=-1;
07 return result;
08 }
|
Reine SIMD-Systeme können die »sign«-Funktion nicht abarbeiten, weil der Kontrollfluss – abhängig vom Vorzeichen – unterschiedliche Pfade durchläuft. Auch die SIMT-Technologie führt nur einen Befehl zu einem Zeitpunkt aus. Aber ein Trick erlaubt es, Verzweigungen zuzulassen: Alle Threads, die denselben Pfad durch das Programm nehmen, ordnet die GPU einer Gruppe zu. Da der Befehl für alle Threads einer Gruppe identisch ist, läuft dieser parallel ab. Die Befehle unterschiedlicher Gruppen werden sequenziell ausgeführt. Die Konsequenz ist, dass nun auch verschiedene Pfade durch das Programm möglich sind.
Allerdings hat das Auswirkungen auf die Performance, denn es kommt zu Verzögerungen. Nur wenn alle Threads den gleichen Befehl ausführen, lässt sich das Maximum aus der Grafikkarte herausholen. In Abbildung 2 geben die grauen Kästchen die zeitliche Abarbeitung von Listing 1 an, die Zahlen entsprechen den Codezeilen.
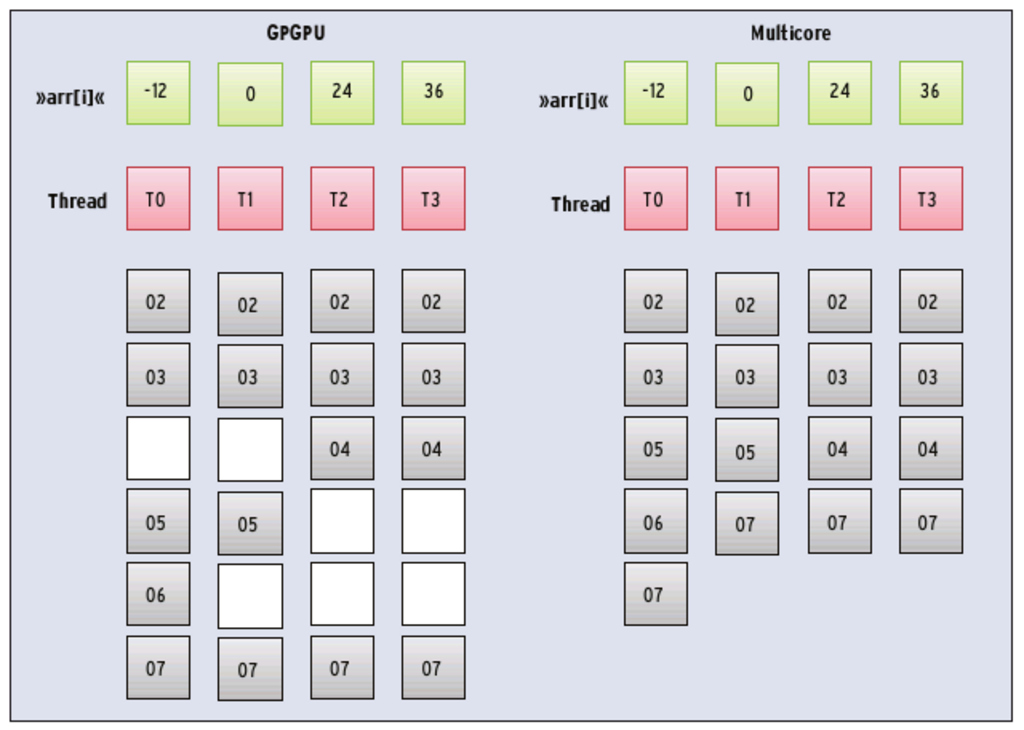
Abbildung 2: SIMT-Systeme (links) verarbeiten zu einem Zeitpunkt nur einen Befehl parallel. Threads, die unterschiedliche Pfade nehmen, können daher nur sequenziell ablaufen. Für ausgewachsene Multicore-Systeme (rechts) gilt diese Einschränkung nicht. Die Zahlen entsprechen den Zeilennummern in Listing 1.
Hardware-Architektur
Cuda steht für Compute Unified Device Architecture und bezeichnet die Architektur der GPU von Nvidia. Eine der derzeit stärksten Grafikkarten, Nvidias Geforce GTX295, besteht aus 2 mal 30 Stream-Multiprozessoren (SM), die ihrerseits jeweils acht Stream-Prozessoren (SP) zusammenführen. Somit arbeiten 480 Prozessoren parallel. Jeder der Prozessoren verfügt über ein eigenes Rechenwerk für 32-Bit-Integer- und -Float-Arithmetik. Zusätzlich hat jeder SM zwei Prozessoren, die komplexere Fließkommaoperatoren erlauben. Es existiert ein Befehlswerk pro SM. Der als Nächstes auszuführende Befehl wird an alle acht SP übermittelt und dann – entsprechend SIMD – parallel bearbeitet.
Software-Architektur
Ein Kernel oder auch eine Kernelfunktion ist eine C-ähnliche Funktion, die alle Threads ausführen. Die SIMT-Technologie erlaubt es, dass der Kontrollfluss einzelner Threads verschieden ist. Die Unterschiede in der C-Programmierung sind minimal, beispielsweise gibt es keine rekursiven Funktionsaufrufe. Cuda fasst Threads in Blöcke zusammen, die ihrerseits zu einem Gitter (Grid) angeordnet sind. Für viele reale Problemstellungen bietet es sich an, die Threads und Blöcke in zwei oder drei Dimensionen anzuordnen. Abbildung 3 skizziert diese hierarchische Thread-Organisation.
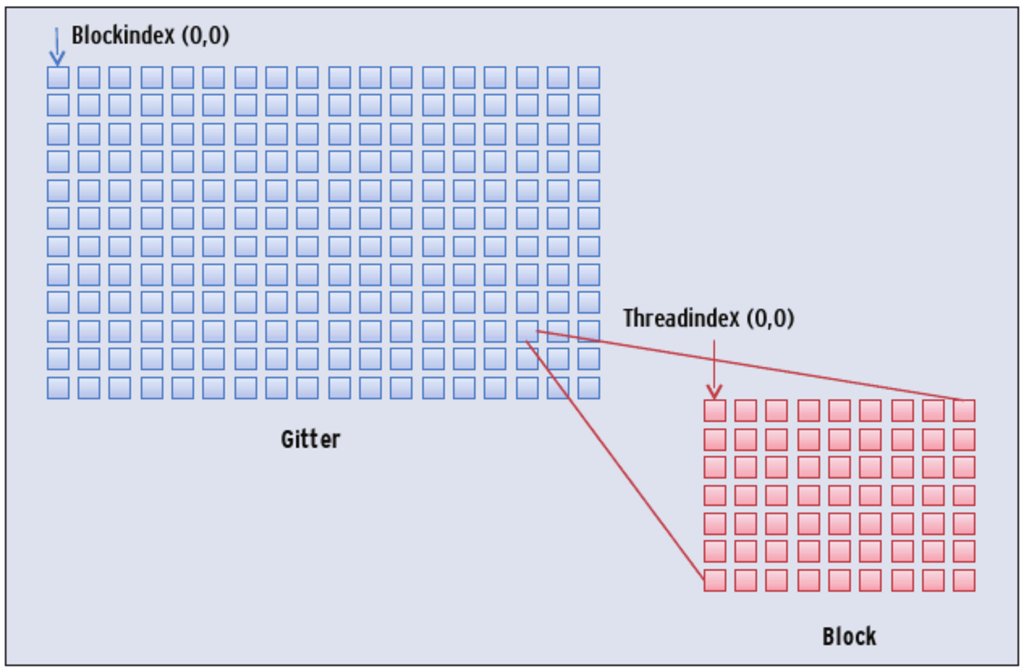
Abbildung 3: Threads organisieren sich hierarchisch. Für die Programmierung ist bedeutend, dass sich nur Threads innerhalb eines Blocks synchronisieren lassen. Die eindeutige Identifikation eines Thread erfolgt über den Block- und den Thread-Index.
Das zentrale Element ist ein Block von Threads, der die folgenden Eigenschaften aufweist:
- Ein Block kann bis zu 512 Threads enthalten –
unabhängig davon, in wie vielen Dimensionen die Threads
angeordnet sind. - Die Threads in einem Block haben Zugriff auf gemeinsamen
schnellen Speicher. Threads unterschiedlicher Blöcke tauschen
Daten nur über den langsamen Hauptspeicher der Grafikkarte
aus. - Nur Threads innerhalb eines Blocks lassen sich synchronisieren.
Es gibt keine Möglichkeit, die Ausführung von Threads
verschiedener Blöcke zu synchronisieren. - Ein Block ist genau einem SM für die Dauer der
Kernelfunktion zugeordnet. Es findet keine Migration von Threads
statt. Sind mehr rechenbereite Threads als SP vorhanden, dann
führt die Hardware ein Scheduling durch. - In einem Block führt die GPU immer Mengen von 32 Threads
parallel aus. Diese Gruppen werden häufig auch als Warp
bezeichnet.
Auch bei der Synchronisation von parallel arbeitenden Kernen ist die SIMT-Technologie einfacher gehalten als bei ausgewachsenen Multicore-Systemen. Als Konsequenz der blockinternen Synchronisation ergibt sich für die Programmierung, dass der parallele Algorithmus so definiert sein muss, dass keine Annahmen über die Reihenfolge der Ausführung der unterschiedlichen Blöcke erfolgt. Sind mehrere Blöcke zu synchronisieren, kann das nur über verschiedene Kernelaufrufe erfolgen.
Innerhalb eines Blocks steht als einziges Mittel für die Synchronisation eine Barriere (Barrier) zur Verfügung. Eine solche Barriere lässt sich bildlich als großes verschlossenes Tor einer Stadtmauer vorstellen: Alle Threads warten an dem Tor, bis auch der letzte Thread angekommen ist. Erst wenn das der Fall ist, öffnet sich das Tor und alle Threads rennen weiter.
Eine Barriere setzt voraus, dass alle Threads die entsprechende Stelle im Code überhaupt erreichen (Vorsicht bei Verzweigungen in If-Anweisungen). Übertragen auf das Bild der Stadtmauer bedeutet dies, dass Threads nicht unterschiedliche Tore in die Stadt nehmen dürfen. Sonst besteht die Gefahr einer Art Deadlock: Eine Gruppe von Threads wartet auf die anderen, die aber ihrerseits an einem anderen Tor auf Einlass warten.
Zwei Beispiele zeigen einen möglichen Ansatz von Cuda unter Linux. Beide Beispiele sind anschaulich und lassen sich von der Grundidee auf andere Einsatzgebiete übertragen. Das erste Beispiel verwendet für jeden Bildpunkt einen Thread. Eine Synchronisation ist nicht notwendig. Im zweiten Beispiel müssen viele parallele Threads zusammenarbeiten und sich synchronisieren.
Beispiel: Sobel-Operator
Die Bilderkennung identifiziert häufig im ersten Schritt die Umrisse von möglichen Objekten. Der Sobel-Operator [2] detektiert Kanten und findet sich auch in gängigen Bildverarbeitungsprogrammen wie Gimp. Für Grauwert-Bilder funktioniert der Sobel-Operator so: Die Farbe Schwarz bekommt den Grauwert 0, Weiß wird mit dem Wert 255 kodiert. Grautöne liegen dazwischen. Eine Kante ist eine abrupte Änderung des Grauwerts, die es nun zu detektieren gilt.
Der Sobel-Operator sieht sich für jeden Bildpunkt die Nachbarpixel an und berechnet Differenzen in horizontaler und vertikaler Richtung. Die Differenzbildung hebt Unterschiede hervor (Differenz von Grauwerten ist groß) und unterdrückt Flächen ähnlichen oder gleichen Grauwerts (Differenz ist klein oder null). Das Ergebnis ist oft sehr dunkel, wobei die markanten Umrisse hervorstechen.
Das Berechnungsgitter baut sich aus einer zweidimensionalen Struktur von Blöcken auf. Jeder Thread eines Blocks ermittelt den Sobel-Wert für genau einen Bildpunkt aus einer Gewichtung der Grauwerte der Nachbarpunkte. Der Operator berechnet dazu Differenzen in horizontaler und vertikaler Richtung getrennt.
Abbildung 4 zeigt das Prinzip für die horizontale Richtung. Die Zahlen der Nachbarpunkte geben die Gewichtung an, wie diese in der Differenzbildung berücksichtigt werden:

Abbildung 4: Der Sobel-Wert für einen Bildpunkt berechnet sich aus den Grauwert-Differenzen der Nachbarpunkte. Neben dem dargestellten horizontalen benötigt die Berechnung des Gradienten auch den vertikalen Sobel-Operator.
sh(x,y)=1*g(x-1,y+1)-1*g(x-1,y-1)+2*g(x,y+1) -2*g(x,y-1)+1*g(x+1,y+1)-1*g(x+1,y-1)
In analoger Weise wird sv als Differenz in vertikaler Richtung berechnet. Der zweite Schritt ermittelt den Betrag des Gradienten:
s(x,y)=sqrt(sh*sh+sv*sv)
Die Grundstruktur eines Cuda-Programms ist in den meisten Fällen ähnlich zu der »main()«-Funktion in Listing 2. Die »main()«-Funktion läuft auf dem Host (CPU des PC) und kümmert sich um das Speichermanagement zum Device (GPU der Grafikkarte). Die Funktion »readpgm()« liest die Bild-Pixel und die -Dimensionen aus einer Datei.
| Listing 2: »main()«-Funktion |
|---|
01 int main() {
02
03 cout << "Beispielprogramm fuer Sobel-Operator mit CUDA-Umgebung" << endl;
04
05 // --Grauwertbild einlesen und Speicher auf dem Host allokieren
06 unsigned char* ipicture=0;
07 int length=0,width=0;
08 readpgm("pic/starbucks.pgm",ipicture,length,width);
09
10 // --Speicher auf dem Device (GPU) allokieren
11 int memsize=length*width;
12 unsigned char* device_ipicture=0,*device_opicture=0;
13 // --Speicher fuer Ein- sowie Ausgabebild
14 cudaMalloc((void**)&device_ipicture,memsize);
15 cudaMalloc((void**)&device_opicture,memsize);
16
17 // --Speicher vom Host auf das Device kopieren
18 cudaMemcpy(device_ipicture,ipicture,memsize,cudaMemcpyHostToDevice);
19
20 // --Kernelfunktion starten
21 sobel(device_ipicture,device_opicture,length,width);
22
23 // --Speicher vom Device auf den Host kopieren
24 unsigned char* opicture=new unsigned char[memsize];
25 cudaMemcpy(opicture,device_opicture,memsize,cudaMemcpyDeviceToHost);
26
27 // --Speicher auf dem Device freigeben
28 cudaFree(device_ipicture);
29 cudaFree(device_opicture);
30
31 savepgm("result.pgm",opicture,length,width);
32
33 // --Speicher auf dem Host freigeben
34 delete ipicture;
35 delete opicture;
36
37 return 0;
38 }
|
Hin und her kopieren
CPU und GPU verwenden unterschiedlichen Speicher. Analog zu den Standard-C-Funktionen gibt es daher »cudaMalloc()« und »cudaFree()«, um Speicher auf der Grafikkarte zu allokieren und freizugeben. Das Beispiel legt sowohl auf dem Host als auch auf dem Device jeweils zwei Speicherbereiche an, für das Eingangs- und das Sobel-Bild.
Der nächste Schritt kopiert den Speicherinhalt des Eingangsbilds (Abbildung 5) vom Host auf das Device. Hierzu stellt Cuda die Funktion »cudaMemcpy()« bereit. Diese arbeitet ähnlich dem Standard-C-Pendant, mit einer Ausnahme: Der zusätzliche Parameter gibt an, ob sie vom Host zum Device oder in die andere Richtung kopiert.

Abbildung 5: Ein Anwendungsfall für den Sobel-Operator und seine parallelisierte Umsetzung: Gesucht sind die markanten Kanten an einer New Yorker Straßenecke. Diese Bilddatei dient als Eingabe.
Die »sobel()«-Funktion (Listing 3) dimensioniert das Gitter. Sie berücksichtigt dabei, dass sich auf dem Bildrand wegen der fehlenden Nachbarpunkte kein Sobel-Wert berechnen lässt. Eine Faustregel besagt, dass jeder Block mindestens 32 Threads hat und dass es mindestens genauso viele Blöcke wie Prozessoren gibt. Ansonsten würde die zur Verfügung stehende Rechenleistung der GPU nicht effizient genutzt, da einige Prozessoren sich langweilen. Danach startet der Kernel. Die Funktion wird neben den Funktionsparametern mit den Gitter- und Block-Dimensionen in dreifach spitzen Klammern aufgerufen.
| Listing 3: Die »sobel()«-Funktion |
|---|
01 // --Hier werden die Gitter- und Blockdimensionen definiert und der Kernel gestartet.
02
03 const int numThreadsPerDim = 16;
04
05 extern "C" void sobel(unsigned char* in, unsigned char* out, int length, int width) {
06
07 // --Dimension eines Blocks ist quadratisch (bspw. 16x16 = 256)
08 dim3 dimBlock(numThreadsPerDim,numThreadsPerDim);
09
10 // --Berechnung der Anzahl der Bloecke (Dimension des Gitters). Das Bildformat wird
11 // --um 2 Punkte jeweils reduziert, da auf dem Bildrand nicht gerechnet wird.
12 dim3 dimGrid((length-2+dimBlock.x-1)/dimBlock.x,(width-2+dimBlock.y-1)/dimBlock.y);
13
14 // --Starte die Kernelfunktion auf dem Gitter
15 sobel_operator<<<dimGrid,dimBlock>>>(in,out,length,width);
16
17 }
|
Haben alle Threads ihre Arbeit zu Ende ausgeführt, kopiert der letzte Schritt mit »cudaMemcpy()« das Ergebnis vom Device zurück auf den Host. Die Funktion »savepgm()« speichert das Ergebnisbild in einer Datei. Im Gegensatz zu den schwergewichtigen Threads in Multicore-CPU-Systemen besteht der Kernel in vielen Fällen nur aus wenigen Zeilen Code, meist unter 100. Die offene Frage bleibt, woher der Kernel weiß, auf welchen Daten er arbeiten soll, wenn alle Threads mit den gleichen Parametern starten. Daher ist eine Kernelfunktion (Listing 4) so aufgebaut, dass sie anhand von »blockDim«, »blockIdx« und »threadIdx« erfahren kann, wo sie gerade läuft. Danach erfolgt die eigentliche Bearbeitung. In Abbildung 6 ist das Ergebnis nach Anwendung des Sobel-Operators dargestellt, das ursprünglich sehr dunkle Bild ist invertiert.

Abbildung 6: Das Bild nach Anwendung des Sobel-Operators. Flächen gleichen Grauwerts werden unterdrückt, Kanten werden hingegen hervorgehoben. Zur besseren Darstellung ist das Bild invertiert.
| Listing 4: Kernelfunktion |
|---|
01 // --Kernel-Funktion fuer Sobel-Operator
02
03 #define AT(x,y) ((y)*length+(x))
04
05 __global__ void sobel_operator(unsigned char* in, unsigned char* out, int length, int width) {
06
07 // --Wer bin ich? Bestimmung des Bildpunktes
08 // --Es wird jeweils um 1 inkrementiert, da auf dem Rand kein Sobel-Wert berechnet wird.
09 int x=blockDim.x*blockIdx.x+threadIdx.x+1;
10 int y=blockDim.y*blockIdx.y+threadIdx.y+1;
11
12 // --Anwendung des Operators (Achte auf Rand!)
13 if (x<length-2 && y<width-2) {
14
15 // --Sobel-Operator in horizontaler Richtung
16 int sh=1*in[AT(x-1,y+1)]-1*in[AT(x-1,y-1)]+
17 2*in[AT(x,y+1)]-2*in[AT(x,y-1)]+
18 1*in[AT(x+1,y+1)]-1*in[AT(x+1,y-1)];
19
20 // --Sobel-Operator in vertikaler Richtung
21 int sv=1*in[AT(x+1,y+1)]-1*in[AT(x-1,y+1)]+
22 2*in[AT(x+1,y)]-2*in[AT(x-1,y)]+
23 1*in[AT(x+1,y-1)]-1*in[AT(x-1,y-1)];
24
25 // --Zusaetzlich invertieren zur besseren Darstellung
26 out[AT(x,y)]=255-(unsigned char)sqrt(float(sh)*float(sh)+float(sv)*float(sv));
27 }
28 }
|
Nicht alle Probleme lassen sich so offensichtlich parallelisieren und lösen wie bei der Bildbearbeitung mit dem Sobel-Operator. Die GPU ist mit dem Plan entstanden, ein zwei- oder dreidimensionales Bild in Bereiche zu zerlegen und den Grafikprozessor dann jeden Bereich, jedes Pixel fast unabhängig von allen anderen berechnen zu lassen.
Die Welt ist aber manchmal komplexer. Berechnungen, die einen Wert ermitteln, der vom Vorgänger abhängig ist, lassen sich sequenziell mit einer For-Schleife schnell lösen. Die Rückführung eines Vektors von Werten auf einen einzelnen wird als Reduktion bezeichnet. Schon eine Operation wie die Bildung der Summe einer Zahlenfolge ist auf den ersten Blick schwer parallel auszuführen. Aber hier hilft die Mathematik weiter: Es gibt einige Operationen, bei denen es egal ist, in welcher Reihenfolge sie ablaufen. Sind etwa die Zahlen 12, 4 und 23 zu addieren, spielt es keine Rolle, ob man erst 12 und 4 addiert und dann anschließend 23 oder ob man zuerst 4 und 23 und dann 12 addiert. Diese nützliche Eigenschaft wird als Assoziativität bezeichnet.
Parallele Reduktion
Die Grundidee bei der parallelen Reduktion findet sich auch in Sportwettkämpfen wieder. Beim jährlichen Tennisturnier in Wimbledon tritt eine Vielzahl von Spielern gegeneinander an. Im K.o.-Verfahren kommt jener Spieler eine Runde weiter, der das Spiel gewinnt. Die Anzahl der Spieler reduziert sich in jeder Runde um die Hälfte bis zum Finale.
Der folgende Algorithmus macht sich dies zunutze und ist die Basis für eine ganze Klasse ähnlicher Algorithmen. Er zerlegt die Summe in eine Vielzahl von Teilsummen zweier Zahlen und berechnet diese parallel. Der nächste Schritt addiert immer zwei Teilsummen – so lange, bis die Gesamtsumme ermittelt ist.
Abbildung 7 zeigt dieses Berechnungsschema für die Addition von acht Zahlen. Der erste Schritt bildet vier Teilsummen, die vier Threads parallel berechnen. Der nächste Schritt fasst die Ergebnisse in zwei Teilsummen zusammen, die sich wieder parallel berechnen lassen. Im dritten und letzten Schritt gibt es nur noch eine Summe, die von einem der vier Threads berechnet wird.
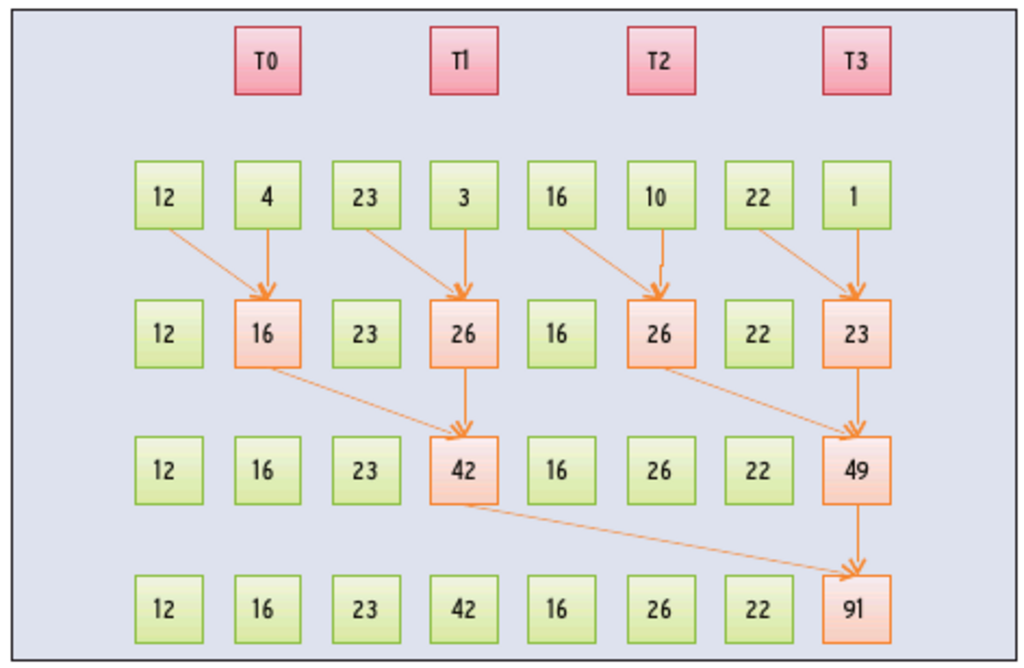
Abbildung 7: Parallele Reduktion berechnet die Summe einer Zahlenfolge analog einem K.-o.-Ausscheidungsverfahren im Sport. Die Anzahl der rechnenden Threads halbiert sich in jedem Schritt.
Jeder Schritt verkleinert die Anzahl der parallelen Berechnungen. Im Beispiel sind statt sieben sequenzieller Additionen nur drei parallele Reduktionsschritte nötig. Im allgemeinen Fall sind nur dem Logarithmus entsprechend viele Schritte notwendig: Bei der Summe von 1024 Zahlen statt 1023 also nur 10. Das führt zu einer starken Reduzierung der Rechenzeit und ist nicht auf die Addition beschränkt. Weitere Operationen mit dieser günstigen Eigenschaft sind die logischen Verknüpfungen Und sowie Oder und die Minimum- und Maximum-Bestimmung.
Listing 5 zeigt die Kernelfunktion »parallel_reduce()«. Nach jedem parallelen Schritt synchronisiert Zeile 14 die Threads, da die Reduktion im Gleichtakt erfolgt. Die notwendige Barriere ist durch »__syncthreads()« gegeben. Da es nicht möglich ist, über Blockgrenzen hinweg die Threads im Gleichklang zu halten, reduziert jeder Block nur 1024 Zahlen. Anschließend summiert ein sequenzieller Schritt die Teilergebnisse aller Blöcke, aber das ist ein anderes Thema.
| Listing 5: »reduce()« |
|---|
01 // --Kernel-Funktion fuer die Parallele Reduktion
02
03 __global__ void parallel_reduce(int* arr, int radix2_size,int nsteps) {
04 // --Wer bin ich?
05 int index=(blockDim.x*blockIdx.x+threadIdx.x)*2,s=0;
06
07 for(int i=0;i<nsteps;i++) {
08 s=1<<i; // --s: Schrittweite
09 // --Ueberpruefe, ob Thread aktiv rechnen muss.
10 if (threadIdx.x % s == 0)
11 arr[index]+=arr[index+s];
12
13 // --Synchronisiere mit allen anderen Threads im Block
14 __syncthreads();
15 }
16
17 }
18
19
20 // --Hier werden die Gitter- und Blockdimensionen definiert und der Kernel gestartet.
21
22 const int radix2Threads = 9; // --2^.. Threads
23
24 extern "C" void reduce(int* arr, int radix2_size) {
25
26 // --Dimension eines eindimensionalen Blocks
27 dim3 dimBlock(1<<radix2Threads);
28
29 // --Berechnung der Anzahl der Bloecke im eindimensionalen Gitter
30 dim3 dimGrid(1<<(radix2_size-radix2Threads-1));
31
32 // --Berechnung der Anzahl der Reduktionsschritte pro Block
33 int nreduction=radix2Threads+1;
34
35 // --Starte die Kernelfunktion auf dem Gitter
36 parallel_reduce<<<dimGrid,dimBlock>>>(arr,radix2_size,nreduction);
37
38 }
|
Die reine parallele Reduktion ist nicht besonders effizient. Bereits nach der ersten Reduktion ist die Hälfte der Kerne ohne Arbeit. Daher wird häufig ein effizienteres Verfahren eingesetzt, das eher dem jetzt wieder bei der Fußball-Weltmeisterschaft in Südafrika eingesetzten entspricht, es unterscheidet zwischen einer Vor- und einer Hauptrunde.
Cuda bietet daneben einige (nicht objektorientierte) Konzepte aus der Programmiersprache C++. Dazu gehören Polymorphismus von Funktionen, die Möglichkeit, Default-Parameter anzugeben, die Überladung von Operatoren sowie Namespaces und Funktionstemplates. Das Klassenkonzept unterstützt Cuda nicht.
Abbildung 8: Ist die Installation des Nvidia-Treibers für Linux erfolgreich abgeschlossen, zeigt der Eintrag »Nvidia X Server Settings« unter anderem Informationen zu Grafikkarte, Displaynamen und der Treiberversion an.
Nvidia stellt die Werkzeuge, das SDK und die Dokumentation für alle Interessierten kostenfrei zur Verfügung. Allerdings handelt sich nicht um freie Software im GPL-Sinne; einige Komponenten sind auch nur binär verfügbar. Neben Nvidia ist auch ATI [3] bei der Entwicklung von GPGPU-Systemen sehr aktiv. Der Notwendigkeit einer Standardisierung der Programmierung von Grafikkarten trägt die Khronos-Gruppe [4] Rechnung. Die Organisation, Hüterin mehrerer offener Standards, beispielsweise Open GL, hat inzwischen eine erste Version von Open CL vorgestellt, einer standardisierten Sprache für die Programmierung von GPUs wie auch CPUs.
Das Know-how entscheidet
Der Einstieg in das Rechnen auf der Grafikkarte ist schnell gemacht. Die umfangreiche Dokumentation und die ausführlichen Codebeispiele im SDK sind eine taugliche Starthilfe für Interessierte. Trotzdem erfordert die Programmierung einige Kenntnisse über die eingesetzte Hardware, da ansonsten der Superrechner unterm Schreibtisch seine Leistung nicht ausspielen kann. (mhu)
| Installation und Konfiguration |
|---|
Die Installation der Komponenten erfordert teilweise Handarbeit. Die nachfolgenden Hinweise sind eine Zusammenfassung diverser Foreneinträge, Readme-Dateien und Erfahrungen des Autors. Der Test fand statt mit der Ubuntu-Version 9.10 (Karmic Koala) in 64 Bit, zum einen auf einem Core-i7-System mit einer Geforce-GTX260-Grafikkarte sowie zum anderen auf einem Lenovo-x200s-Notebook, dort aber nur mit der Emulation, da das Gerät keine Nvidia-Grafikkarte enthält. Die Kernelversion ist auf beiden getesteten Systemen 2.6.31-14.
Grafiktreiber, Toolkit und SDKUbuntu bietet im Software-Center einige ältere Versionen von Nvidias Cuda-Treiber zur Installation an. Um die zuletzt erschienene Cuda-Version 2.3 zu installieren, ist allerdings ein Download direkt von Nvidia [5] notwendig. Nach der Auswahl des Betriebssystems (Linux 64 Bit) ist die Distribution (Ubuntu 9.04) zu wählen. Die für diesen Artikel genutzte Version ist 190.18 Beta. Anschließend ist der Treiber zu installieren, allerdings muss dies im Runlevel 3 erfolgen, also ohne laufenden X-Server. Wenn alles glattgegangen ist, steht nach einem erneuten Start des X-Servers der Eintrag »System | Einstellungen | Nvidia X Server Settings« zur Verfügung (Abbildung 8). Das Toolkit enthält alle notwendigen Dateien, Bibliotheken und Werkzeuge, um Programme für die Grafikkarte zu entwickeln. Auch hier muss der Admin das Paket von Nvidia direkt laden und anschließend installieren (vorzugsweise unter »/opt«). Die Umgebungsvariable »PATH« ergänzt er dann um »/opt/cuda/bin« sowie »/etc/ld.so.conf« um »/opt/cuda/lib64«. Zusätzlich muss er einmalig »ldconfig« als Root ausführen, sodass der Linker die Cuda-Bibliotheken findet. Alternativ kann er auch die »LD_LIBRARY_PATH«-Variable erweitern. Nun lassen sich Cuda-Programme übersetzen und auszuführen. Hilf- und lehrreich ist es allerdings, auch das separate SDK zu installieren, das eine Vielzahl von Beispielen im Sourcecode bereithält. Nach dem Auspacken des Archivs nach »/opt« oder in ein Homeverzeichnis gilt es, das SDK zu übersetzen. Und hier fangen die Schwierigkeiten an: Ubuntu 9.10 hat standardmäßig GCC 4.4 installiert, damit kommt aber das SDK nicht klar. Zum anderen ist die SDK-Software etwas empfindlich, wenn man andere Pfade verwendet als der Nvidia-Mitarbeiter, der das Paket zusammengebaut hat (es also beispielsweise unter »/opt« installiert). Ubuntu bietet die Möglichkeit, parallel verschiedene Versionen des Compilers zu verwalten. Hierzu sind über die Paketverwaltung die beiden Pakete »gcc-4.3« und »g++-4.3« und Abhängigkeiten nachträglich zu laden und zu installieren. Hinzu kommen noch die Pakete »freeglut3« und »freeglut3-dev«. Dann ist alles beisammen zur Übersetzung der Beispiele und Bibliotheken des SDK. Links zu BibliothekenDas SDK erwartet, dass die Bibliotheken zum Linken eine bestimmte Namenskonvention erfüllen. Das ist aber für die getestete Ubuntu-Version nicht komplett der Fall. Daher sind symbolische Links notwendig, die als Root zu erzeugen sind: ln -s /usr/lib/libglut.so.3 /usr/lib/Ulibglut.so ln -s /usr/lib/libGLU.so.1 /usr/lib/UlibGLU.so ln -s /usr/lib/libX11.so.6 /usr/lib/UlibX11.so ln -s /usr/lib/libXi.so.6 /usr/lib/UlibXi.so ln -s /usr/lib/libXmu.so.6 /usr/lib/UlibXmu.so Nach der Installation des GCC 4.3 ist das zentrale Makefile »common.mk« unter »/opt/NVIDIA_GPU_Computing_SDK/C/common« entsprechend zu modifizieren. Die folgenden Änderungen erzwingen, dass die erwünschte ältere Compilerversion beim Übersetzen des SDK zum Einsatz kommt: CUDA_INSTALL_PATH ?= /opt/cuda CXX := g++-4.3 CC := gcc-4.3 LINK := g++-4.3 -fPIC NVCCFLAGS := --compiler-bindir=U/usr/bin/gcc-4.3 Nach dem Aufruf von Make in »/opt/NVIDIA_GPU_Computing_SDK/C« und nach ein paar Minuten Übersetzungszeit (nicht von den vielen Compiler-Warnungen irritieren lassen) stehen in »/opt/NVIDIA_GPU_Computing_SDK/C/bin/linux/release« die Programme zur Ausführung bereit. Das Programm »deviceQuery« liefert beispielsweise einige Informationen zur verbauten Nvidia-Grafikkarte. EmulationIst keine Cuda-fähige Grafikkarte im System vorhanden, dann sollte man die Emulation im Release- oder Debug-Modus erstellen. Das geschieht durch die Eingabe von »make emu=1« und »dbg=1«. Die ganze Cuda-Applikation läuft dann auf dem Host, also der CPU des Linux-PC. Diese Emulation ist übrigens die einzige Möglichkeit, den Cuda-Code im Debugger zu inspizieren. Auf der Grafikkarte selbst ist dies nicht möglich. Für die Cuda-Entwicklung bietet sich Eclipse Galileo mit dem CDT-Plugin an. Der folgende Wrapper hilft gegen einen lästigen GTK+-Bug, der sich unter Ubuntu 9.10 eingeschlichen hat: #!/bin/bash export GDK_NATIVE_WINDOWS=1 /opt/eclipse/eclipse Das im Cuda mitgelieferte Template-Projekt lässt sich als Vorlage für Cuda-Projekte in Eclipse verwenden. |
| Infos |
|---|
| [1] Cuda-Seite bei Nvidia: [http://www.nvidia.de/object/cuda_home_new_de.html]
[2] Sobel-Operator: [http://de.wikipedia.org/wiki/Sobel-Operator] [3] GPGPU bei ATI: [http://developer.amd.com/gpu/ATIStreamSDK/Pages/default.aspx] [4] Khronos-Gruppe: [http://www.khronos.org] [5] Cuda-Download: [http://www.nvidia.com/object/cuda_get.html] |
| Der Autor |
|---|
| Michael Uelschen ist Professor für Software-Engineering für technische Systeme an der Fachhochschule Osnabrück. Er befasst sich unter anderem mit Multicore- und GPGPU-Systemen. |





