
© loft39studio / 123RF.com
Die Forschung hat im Bereich der künstlichen Intelligenz in den letzten Jahren einen bemerkenswerten Fortschritt gemacht. Eine der tatsächlich innovativen Entwicklungen in diesem Feld ist das Konzept der Generative Adversarial Networks (GANs), die auf Trainingsdaten aufbauend neue Daten generieren.
Hinter GANs steckt eine spezielle Klasse neuronaler Netzwerke, die aus zwei Komponenten bestehen: einem Generator und einem Diskriminator. Der Generator erzeugt neue Datenproben, die eine ähnliche Verteilung wie die Trainingsdaten aufweisen, während der Diskriminator versucht, echte von derart künstlich erzeugten Daten zu unterscheiden. Durch diesen ständigen Wettstreit lernen beide Netzwerke, immer bessere und realistischere Daten hervorzubringen und zu identifizieren (Abbildung 1). Als Eingabe verwenden die GANs Zufallsrauschen, das der Generator anschließend entsprechend der Trainingsdaten modifiziert.
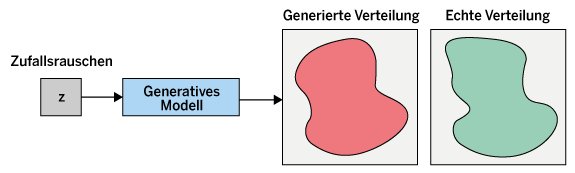
Abbildung 1: Die Generierte und die echte Verteilung nähern sich im Verlauf des Wettstreits der beiden Netze immer weiter an.
In der Bildverarbeitung und Computergrafik kommen GANs zum Einsatz, um realistische Bilder zu erzeugen, für die Bildbearbeitung und für künstlerische Effekte. Unter anderem dienen GANs dazu, aus wenigen Beispielbildern realistische Gesichter zu generieren. Die nutzt dann die Film- und Unterhaltungsindustrie für visuelle Effekte und Charakteranimationen. Ebenso können GANs bestehende Bilder stilistisch verändern, wie es bei der Anwendung von CycleGANs in der Kunst der Fall ist.
In der Medizin bieten GANs wertvolle Möglichkeiten zur Simulation medizinischer Bilder. Das erweist sich besonders da als nützlich, wo es darum geht, synthetische Trainingsdatensätze zu erzeugen, die es zum Entwickeln und Testen neuer medizinischer Bildgebungsverfahren oder diagnostischer Algorithmen braucht. Die von GANs geschaffenen realistischen medizinischen Bilder unterstützen zudem die Forschung und Ausbildung. Weiterhin tauchen GANs im Bereich der Text- und Spracherzeugung auf. Anwender greifen auf sie zurück, um realistische Dialoge zu schreiben. Alternativ tragen sie dazu bei, Spracherkennungssysteme zu verbessern, indem sie synthetische Sprachdaten generieren, die Trainingsdatensätze erweitern. Beispielsweise helfen GANs dabei, natürliche und flüssige Texte für Chatbots zu erstellen.
Architektur
GANs setzen sich, wie erwähnt, aus dem Generator und dem Diskriminator (Abbildung 2) zusammen. Beide sind neuronale Netzwerke, die in einem wettbewerbsorientierten Trainingsprozess gegeneinander arbeiten, um die Qualität der erzeugten Daten kontinuierlich zu steigern.
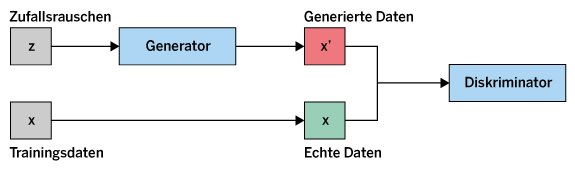
Abbildung 2: Dem Diskriminator werden solange zwei Datensätze vorgelegt, bis er sie nicht mehr unterscheiden kann.
Der Generator übernimmt die Aufgabe, realistische Datenproben zu erzeugen. Das Zufallsrauschen als Eingabe stammt meist aus einer gleichverteilten oder normalverteilten Zufallsvariable. Es fungiert als Ausgangspunkt für die Datenproduktion. Der Generator transformiert das Rauschen durch eine Vielzahl von Schichten in eine Datenprobe, die der Verteilung der realen Daten ähnelt. Dabei durchläuft das Zufallsrauschen zunächst eine Eingabeschicht, die es in den Generator einspeist. Es folgen mehrere dichte Schichten, die die Dimension des Zufallsvektors erhöhen und nichtlineare Transformationen anwenden. Letztere spielen eine entscheidende Rolle, da sie es dem Netzwerk ermöglichen, komplexe Muster zu lernen und zu erzeugen.
Der Diskriminator wird darauf trainiert, zwischen echten und vom Generator erstellten Daten zu unterscheiden. Er bewertet die Eingabedaten und gibt eine Wahrscheinlichkeit bezüglich der Echtheit der Daten aus. Der Diskriminator wird einerseits mit echten Datenproben gefüttert, die zusätzlich mit dem Label “echt” versehen sind, und andererseits mit vom Generator geschaffenen Datenproben, die das Label “falsch” tragen.
Der typische Aufbau eines Diskriminators beginnt mit einer Eingabeschicht, die die Datenprobe entgegennimmt – unabhängig davon, ob sie echt oder vom Generator erzeugt ist. Die Ausgabeschicht des Diskriminators liefert schließlich die Wahrscheinlichkeit dafür, dass die Eingabedaten echt sind, normalerweise durch eine Sigmoid-Funktion normalisiert, die Werte zwischen 0 und 1 ausgibt.
Der Trainingsprozess eines GANs basiert auf einem Minimax-Spiel zwischen dem Generator und dem Diskriminator. Beim Minimax-Spiel machen zwei Spieler abwechselnd Züge. Der Minimax-Algorithmus zielt darauf ab, die besten Züge zu ermitteln, indem das Spiel als Entscheidungsbaum modelliert wird. Einer der Spieler versucht, seinen Gewinn zu maximieren (Max), während der andere diesen Gewinn minimieren möchte (Min). Jeder Zug wird bewertet, und Max wählt den Zug, der den höchsten minimalen Gewinn bringt, während Min den Zug wählt, der zum niedrigsten maximalen Verlust führt. Der Ansatz findet sich häufig in Nullsummenspielen wie Schach oder Tic-Tac-Toe wieder.
Das GAN-Minimax-Spiel charakterisiert eine spezialisierte Verlustfunktion. Solche Verlustfunktionen leiten das Lernen der beiden Netzwerke und bestimmen ihre jeweilige Optimierungsrichtung. Die Verlustfunktion des Diskriminators maximiert die Log-Likelihood-Funktion so, dass echte Daten als echt erkannt werden und vom Generator erzeugte Daten als falsch identifiziert werden. Die Verlustfunktion des Generators hingegen minimiert die Log-Likelihood-Funktion so, dass die vom Diskriminator bewerteten generierten Daten als falsch identifiziert werden.
Alternativ lässt sich der Generator so trainieren, dass er den Diskriminator täuscht, indem er die Wahrscheinlichkeit maximiert, dass der Diskriminator die generierten Daten als echt klassifiziert. Diese Variante dient oft dazu, stabile Gradienten während des Trainings zu gewährleisten. Der Trainingsprozess eines GANs ist iterativ und wechselseitig. In jedem Schritt wird zuerst der Diskriminator mit einer Mischung aus echten und vom Generator erzeugten Daten trainiert. Dabei lernt er, besser zwischen beiden zu unterscheiden. Danach ist der Generator mit dem Training an der Reihe: Indem er für realistischere Daten sorgt, versucht er den Diskriminator zu täuschen.
Dieser Minimax-Prozess wiederholt sich, bis ein Gleichgewicht erreicht ist und der Generator derart hochrealistische Daten ausspuckt, dass sie der Diskriminator nicht mehr von echten Daten unterscheiden kann. Beide Netzwerke lernen durch ein adversariales Trainingsverfahren (daher der Name) und nutzen spezialisierte Verlustfunktionen, um ihre Fähigkeiten kontinuierlich zu verbessern.
Theoretische Garantien
Die theoretische Grundlage von GANs beruht auf einem Prinzip, das sich durch einen zentralen mathematischen Satz verdeutlicht: Wenn der Diskriminator optimal arbeitet, ist die Optimierung des GAN-Verlusts äquivalent zur Minimierung der Jensen-Shannon-Divergenz (JS-Divergenz) zwischen der Verteilung der echten Daten und der Verteilung der vom Generator erzeugten Daten. Einem optimalen Diskriminator gelingt es, bestmögliche Unterscheidungen zwischen Daten zu treffen.
Der Generator hingegen wird so trainiert, dass er die Wahrscheinlichkeit maximiert, dass der Diskriminator seine erzeugten Daten für echt hält. Der entscheidende theoretische Punkt lautet: Wenn der Diskriminator optimal arbeitet, ist die Maximierung des GAN-Verlustes gleichbedeutend mit der Minimierung der Jensen-Shannon-Divergenz zwischen der Verteilung der echten Daten und der Verteilung der generierten Daten. Die Jensen-Shannon-Divergenz ist ein Maß für die Ähnlichkeit zwischen zwei Wahrscheinlichkeitsverteilungen. Eine geringe JS-Divergenz bedeutet, dass die beiden Verteilungen sehr ähnlich ausfallen.
Durch diese Anpassung verringert der Generator die Unterschiede zwischen seiner Verteilung und der Verteilung der echten Daten. Je kleiner die JS-Divergenz, desto näher liegt die Verteilung der generierten Daten an der Verteilung der echten Daten. Mit anderen Worten, der Generator wird befähigt, Datenproben zu erzeugen, die von den echten Daten praktisch nicht zu unterscheiden sind. Diese theoretische Grundlage erklärt, warum GANs so effektiv bei der Erzeugung realistischer Datenproben sind. Sie bietet einen tiefen Einblick in die Funktionsweise dieser faszinierenden Technologie. Dabei erreichen GANs eine beeindruckende Qualität bei der Datenproduktion.
GAN-Varianten
GANs haben sich seit ihrer Einführung erheblich weiterentwickelt. Es gibt zahlreiche Varianten, die jeweils spezifische Herausforderungen adressieren und verschiedene Anwendungen ermöglichen. Conditional GANs (cGANs) erweitern die klassische GAN-Architektur (Abbildung 3), indem sie sowohl dem Generator als auch dem Diskriminator zusätzliche Informationen in Form von Bedingungsvariablen mitgeben. Dazu zählen Labels, Texte oder Bilder, die die Art der zu generierenden Daten spezifizieren. Technisch gesehen wird dem Eingabevektor des Generators und dem Eingabebild des Diskriminators ein Bedingungsvektor hinzugefügt. Beispielsweise kommt beim Erzeugen von handschriftlichen Ziffern als Bedingung die zu generierende Ziffer zum Einsatz. Der Generator erhält somit nicht nur das Zufallsrauschen als Eingabe, sondern eben zudem die Information, welche Ziffer er generieren soll.
Mit dieser Methode lassen sich gezielt Daten erstellen, was besonders hilfreich für Bild-zu-Bild-Übersetzungen, das Färben von Schwarz-Weiß-Bildern oder das Erzeugen von Bildern aus Skizzen ist. Die Architektur von cGANs umfasst typischerweise zusätzliche Schichten, die die Bedingungsinformationen verarbeiten und in den Generationsprozess integrieren.
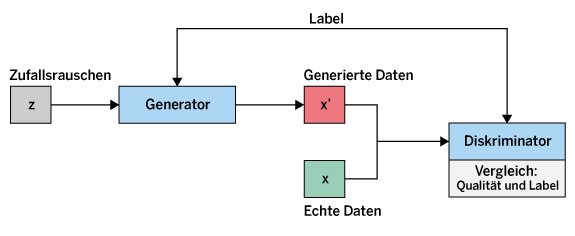
Abbildung 3: Bei Conditional GANs erhält der Diskriminator noch eine Zusatzinformation zu den generierten Daten.
CycleGANs (Abbildung 4) sind darauf ausgelegt, Bilder von einer Domäne in eine andere zu transformieren, ohne dass es eine paarweise Übereinstimmung der Trainingsdaten gibt. Diese Architektur verwendet zwei Generatoren: einen für jede Richtung der Umwandlung, und zwei Diskriminatoren. Der Schlüssel zu CycleGANs liegt im Cycle-Rekonstruktionsverlust, der sicherstellt, dass ein Bild, das von der ersten Domäne in die zweite Domäne und dann wieder zurück in die erste Domäne übersetzt wird, dem ursprünglichen Bild ähnlich bleibt. Der Prozess umfasst zwei Verlustfunktionen: eine für die Vorwärtsübersetzung und eine für die Rückwärtsübersetzung. CycleGANs eignen sich besonders für Aufgaben wie das Transformieren von Fotografien in Gemälden, das Ändern von Wetterbedingungen in Bildern oder das Transformieren von Tag- in Nachtbilder. Die Zykluskonsistenz sorgt dafür, dass beim Stilwechsel kein wesentlicher Inhalt verloren geht.
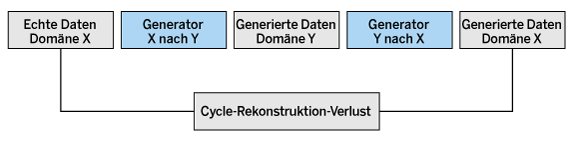
Abbildung 4: CycleGANs arbeiten mit zwei Generatoren und zwei Diskriminatoren.
Fazit
Generative Adversarial Networks gelten als eine bahnbrechende Methode im Bereich der künstlichen Intelligenz, die 2014 von Ian Goodfellow und seinem Team entwickelt wurde. Sie bestehen aus zwei konkurrierenden neuronalen Netzwerken, dem Generator und dem Diskriminator. Der Generator erzeugt synthetische Daten, während der Diskriminator versucht, diese von echten Daten zu unterscheiden. In diesem Wettbewerb verbessert sich der Generator kontinuierlich, bis er sehr realistische Daten liefert.
Das Training von GANs erweist sich mitunter allerdings als schwierig und instabil – immerhin gilt es dabei, die Herausforderung zu meistern, ein Gleichgewicht zwischen Generator und Diskriminator zu erreichen. Ein weiteres Problem besteht im Modus-Kollaps, bei dem der Generator lediglich eine begrenzte Vielfalt von Daten schafft. Zuletzt erfordert das Training von GANs erhebliche Rechenressourcen und Zeit.





