
© Kasper Ravlo / 123RF.com
Auch beim Design von APIs lohnen sich Patterns, damit wartungs- und zukunftssichere Systeme entstehen. Mike Schilli widmet sich Anfragen, die von Natur aus etwas länger dauern.
Man sollte nicht glauben, dass das Thema API Design Patterns so viel hergibt: Schließlich hat sich REST zum Anlegen, Auflisten, Modifizieren oder Löschen von Ressourcen auf der Server-Seite seit Jahrzehnten als Standard etabliert. Aber es gibt ein dickes Buch zum Thema [1], das ausführlich, wenngleich auch für meinen Geschmack etwas zu weitschweifig, die Vor- und Nachteile bestimmter Designentscheidungen beleuchtet.
Ist es besser, den Zugriff auf zwei verwandte Ressourcen einheitlich oder durch getrennte Aufrufe zu implementieren? Welche Schnittstelle bevorzugt ein Client, der lange laufende Server-Prozesse per API kontrollieren möchte? Was spricht für und gegen persistente Datenhaltung? Wie sollte der Server längliche Ergebnisse scheibchenweise an den Client übermitteln? All dies will vor dem Schreiben der ersten Codezeile wohlüberlegt sein, denn nur wer die Vor- und Nachteile bestimmter Implementierungen vorab kennt, kann ein wartungsfreundliches und zukunftssicheres System bauen.
Jedenfalls gilt es, sich beim Entwurf von APIs ähnlich wie beim Design von Applikationscode das geplante Endprodukt aus der Sicht zukünftiger Anwender vorzustellen. Wird es so funktionieren, oder warten böse Überraschungen beim ersten Ausprobieren?
Doku im Augenwinkel
Bei APIs besteht die Zielgruppe oft aus Entwicklern, die schon mit etlichen Webschnittstellen Erfahrung gesammelt haben und einfach annehmen, dass bestimmte Aktionen immer gleich ablaufen: neue Ressourcen erzeugen, bestehende auflisten, modifizieren oder löschen. Idealerweise schreiben Anwender die Schnittstelle ihres Applikationscodes zur Web-API einfach nach Schema F, die Dokumentation zwar im Augenwinkel, aber eigentlich unnötig.
Baldrian für Ungeduldige
Ein interessantes Design Pattern für APIs ist das für Server-Antworten, die etwas mehr Zeit benötigen. Normale Requests verarbeitet der Server so schnell wie möglich, doch manche brauchen von Natur aus länger. Verlangt ein User zum Beispiel Akteneinsicht in seine Google-Daten, lässt sich der Riese ein paar Tage Zeit, bis die Antwort als Datei vorliegt.
Eine natürliche, aber voreilige Design-Entscheidung wäre es, Requests einfach sofort zu beantworten, wenn die Antwort vorliegt. Das bringt aber API-User in die Bredouille: Wie lange soll der Client warten, bis die Antwort eintrifft – zehn Sekunden, eine Minute, eine Stunde? Zu keiner Zeit kann er sich sicher sein, dass der Server noch an der Antwort arbeitet. Nach allen Regeln der Kunst könnte er auch abgeschmiert sein, und länger zu warten, wäre reine Zeitverschwendung.
Das Design-Pattern API für LROs (Long Running Operations) bietet deshalb nicht einen API-Call, sondern gleich eine gute Handvoll: eine Funktion zum Absetzen des Requests, eine weitere zur Prüfung, wie lange es denn noch dauern wird, und eine dritte, die das Ergebnis abholt (Abbildung 1). Eine Luxusvariante böte sogar noch Schnittstellen zum Abbrechen laufender Server-Arbeiten oder auch zum Pausieren und Wiederanlaufen einmal gestarteter Prozesse.
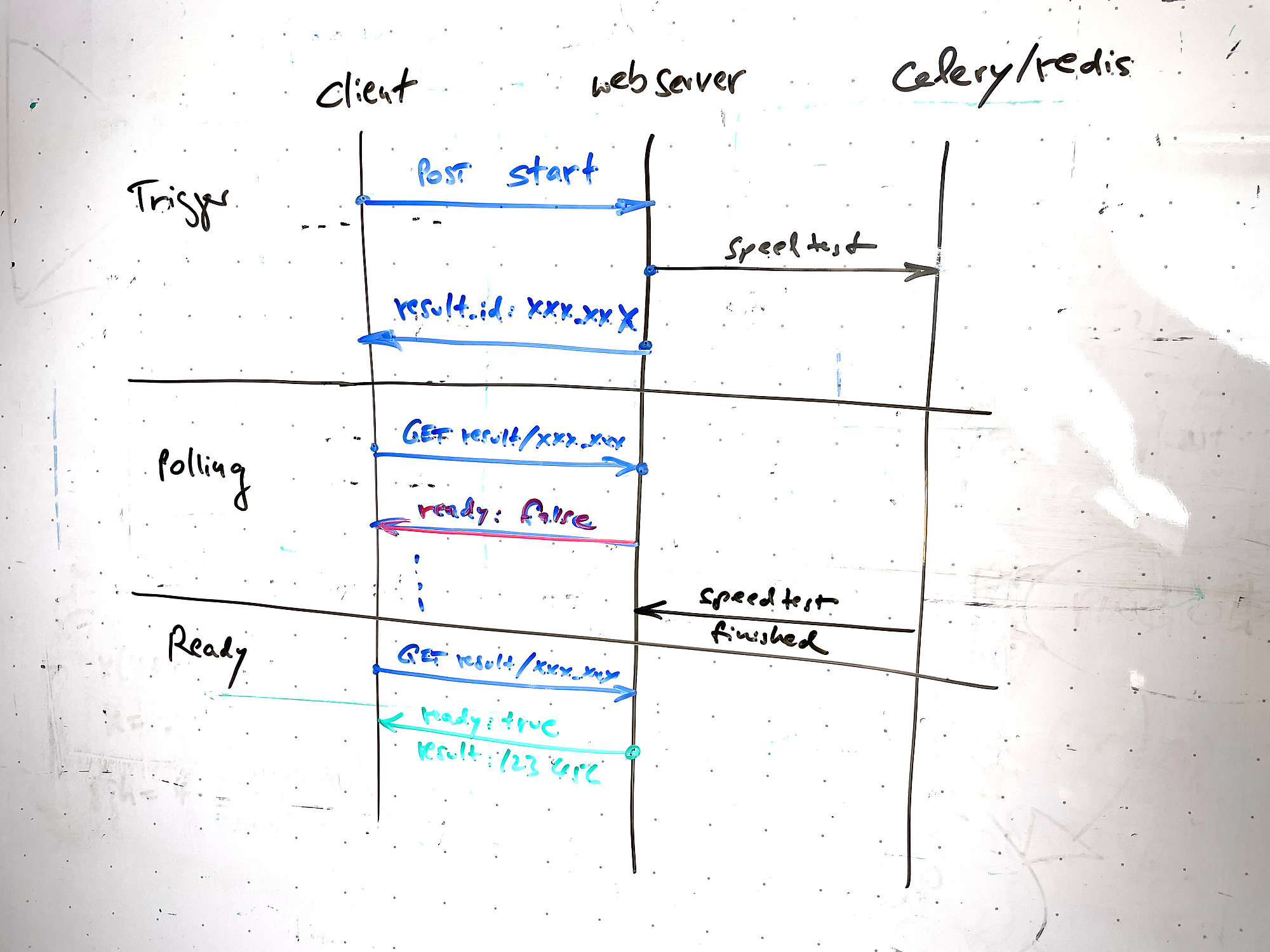
Abbildung 1: Diagramm der Client-Server-Kommunikation.
Radarmessung im Netz
Artikel in diesem Magazin beschreiben nie nur graue Theorie, sondern liefern praktische Anwendungsbeispiele, also implementieren wir eine LRO in Form einer Brandbreitenmessung auf der Server-Seite. Das Python-Paket »speedtest-cli« kontaktiert dazu den Google-Server und ermittelt den Datendurchsatz in beide Richtungen, als Up- und Download-Geschwindigkeit. Je nach Bandbreite und Server-Auslastung kann die Messung durchaus 10 oder 20 Sekunden dauern. Sie übersteigt damit den generell akzeptierten Rahmen für Web-Requests von ein paar Hundert Millisekunden bei Weitem.
Der API-Server startet auf einen Request des Clients hin den Netzwerktest. Statt zu warten, bis er terminiert, und dann das Ergebnis der Messung dem immer noch wartenden Client zu senden, schickt er dem Client sofort nach Eingang des Requests eine ID als Antwort zurück und beendet die Verbindung. Derweil läuft die Netzwerkmessung im Hintergrund an, und über die ID kann der Client nun neue Anfragen absetzen und so laufend abfragen, ob auf dem Server schon ein Ergebnis vorliegt. Kommt der Polling-Call als »ready« zurück, steht in der JSON-Antwort auch noch das Ergebnis der Messung in Bytes pro Sekunde für Up- und Download (markierte Zeile in Abbildung 2).
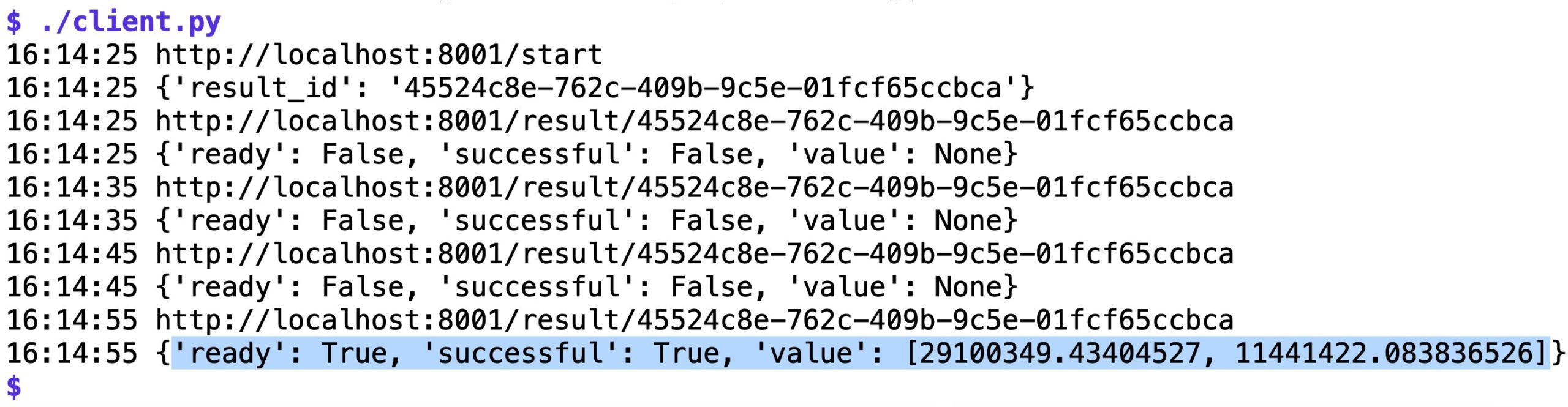
Abbildung 2: Die Ausgabe des Clients.
Die Implementierung des Clients zeigt Listing 1. Die Python-Library requests (flugs installiert mit »pip3 install requests«) kann mit »post()« und »get()« HTTP-Kommandos an den später implementierten und auf »localhost« auf dem Port 8001 laufenden Server absetzen. Die Antworten kommen im Erfolgsfall im JSON-Format zurück, und die Python-Library dekodiert die Antworten mit »json()« in interne Datenstrukturen. Im vorliegenden Fall ist die Antwort jeweils ein Dictionary, das Schlüsseln wie »result_id« oder »ready« entsprechende Werte zuweist (Abbildung 3).
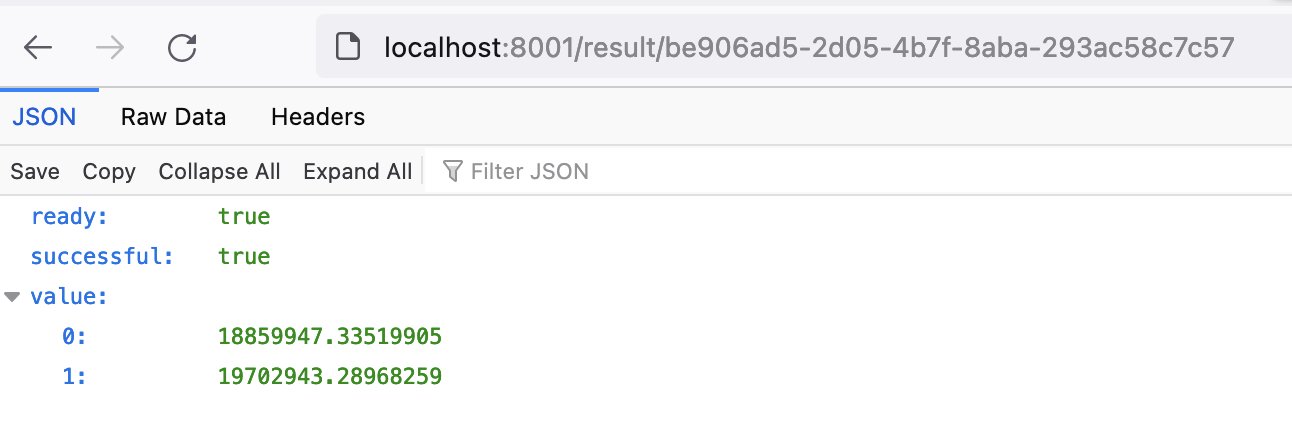
Abbildung 3: Das Ergebnis im Webbrowser.
Listing 1
Client
#!/usr/bin/env python3
import requests
import logging
import time
BASE_URL='http://localhost:8001'
logging.basicConfig(
format='%(asctime)s %(message)s',
level=logging.INFO,
datefmt='%H:%M:%S')
start_url=f"{BASE_URL}/start"
logging.info(start_url)
response=requests.post(start_url)
logging.info(response.json())
id=response.json()["result_id"]
while True:
res_url=f"{BASE_URL}/result/{id}"
logging.info(res_url)
response=requests.get(res_url)
logging.info(response.json())
if response.json()["ready"]:
break
time.sleep(10)
Wunder der Technik
Wie sieht nun die Implementierung dieses Wunderwerks auf der Server-Seite aus? Selbst eine Skriptsprache wie Python, die ein hohes Maß an Abstraktion bietet und teilweise geradezu abenteuerliche Magie an den Tag legt, erfordert hier einige geistige Klimmzüge, selbst wenn der eigentliche Code dann schön kurz und bündig gerät.
Auch die Umgebung, in der der Webserver läuft, benötigt das ein oder andere zusätzlich bewegliche Rädchen. Das Dockerfile in Listing 2 erzeugt ein auf Ubuntu 22.04 basierendes Image, in das es Python 3 und dessen Package-Manager Pip3 pflanzt. Das Python-Modul flask stellt den API-Server bereit. Dessen Routinen weisen auf Python-Funktionen, die Decorators mit dem Webserver verlinken.
Für später im Hintergrund angestoßene Tasks auf eingehende Requests wird allerdings schweres Gerät aufgefahren – ein Webserver sollte sich ja nur mit der schnellen Bearbeitung von Requests befassen. Das nicht gerade triviale Absetzen und die Kontrolle von Hintergrund-Tasks sollte man an Spezialsoftware delegieren.
Listing 2
Dockerfile
FROM ubuntu:22.04 RUN apt-get update RUN apt-get install -y curl vim make RUN apt-get install -y python3 python3-pip RUN apt-get install -y redis-server RUN pip3 install flask celery redis RUN pip3 install speedtest-cli WORKDIR /build
Schweres Gerät
Der Python-Task-Manager Celery [2] beherrscht verteiltes Task-Management aus dem Effeff, und die NoSQL-Datenbank Redis sorgt als Backend für das persistente Speichern der Ergebnisse. Dazu initialisiert der Code des API-Servers (Listing 3, »api-server.py«) eine Celery-Verbindung und stellt sowohl als Broker als auch als Backend den lokalen Redis-Server ein (Zeile 8). Auch Flask und Celery müssen voneinander wissen. Deswegen teilt Zeile 9 mit »update« der Konfiguration in »celery_app« die Konfiguration des Flask-Frameworks mit. Später wird der externe Celery-Worker-Prozess ebenfalls auf Listing 3 losgelassen, von wo er sich die Variable »celery_app« herauspickt und somit um die Redis-Konfiguration seines Backends weiß.
Kommt im API-Server ein Request für eine Bandbreitenmessung am Webserver als »/start« an, überlässt »Flask« den Aufruf der zugewiesenen Python-Funktion »run_speedtest()« ab Zeile 12 dem »celery«-Framework. Zum Aufsetzen des Handlers dekoriert Zeile 17 die Funktion »start_task()« ab Zeile 18. Diese wiederum ruft »run_speedtest.delay()« auf, eine magische Erweiterung der Funktion »run_speedtest()« ab Zeile 12, nur dass Python diese nun asynchron aufruft.
Woher stammt dieses Hexenwerk? Der Decorator »@celery_app.task()« in Zeile 11 dekoriert die Funktion »run_speedtest()« ab Zeile 12 mit einer Portion Celery, und nur deshalb existiert »run_speedtest.delay()« überhaupt.
Listing 3
API-Server
#!/usr/bin/env python3
from flask import Flask
from celery import Celery, Task
import time
import speedtest
app = Flask(__name__)
celery_app = Celery(app.name, broker="redis://localhost", backend="redis://localhost")
celery_app.conf.update(app.config)
@celery_app.task()
def run_speedtest():
st = speedtest.Speedtest()
st.get_best_server()
return st.download(), st.upload()
@app.route('/start', methods=['POST'])
def start_task() -> dict[str, object]:
result = run_speedtest.delay()
return {"result_id": result.id}
@app.get("/result/<id>")
def task_result(id: str) -> dict[str, object]:
result = celery_app.AsyncResult(id)
return {
"ready": result.ready(),
"successful": result.successful(),
"value": result.result if result.ready() else None,
}
# Run the web server
if __name__ == '__main__':
app.run(debug=True, host='0.0.0.0', port=8001)
Frankenstein
Zeile 19 ruft diese Frankenstein-Funktion bei jedem auf »/start« hereinkommenden POST-Request auf. Im Rückgabewert »result« liegt anschließend eine Datenstruktur, unter deren Attribut »id« die ID des auf Celery ausgelagerten Tasks mit der Speedtest-Funktion liegen. Während das Framework sich um deren Ausführung kümmert, baut der Web-Router in Zeile 20 die JSON-Antwort mit der ID unter dem Schlüssel »result_id« als JSON-Paket zusammen, das das Flask-Framework verzögerungsfrei an den Client zurücksendet.
Unter der Haube dieser simpel erscheinenden Aktion geht es nun erst richtig los. Die Funktion »run_speedtest.delay()« übergibt die Ausführung von »run_speedtest()« an den Celery-Taskmanager. Der erste Eintrag mit dem Schlüsselwort »Task« in der Log-Datei aus Abbildung 4 zeigt mit »received« an, dass Celery zum Zeitpunkt »17:39:43« den Auftrag angenommen hat. Dessen Ausführung dauerte bis »17:40:08,910«, also gut 25 Sekunden. Die entsprechende Zeile der Log-Datei bestätigt mit »succeeded« auch den erfolgreichen Abschluss.
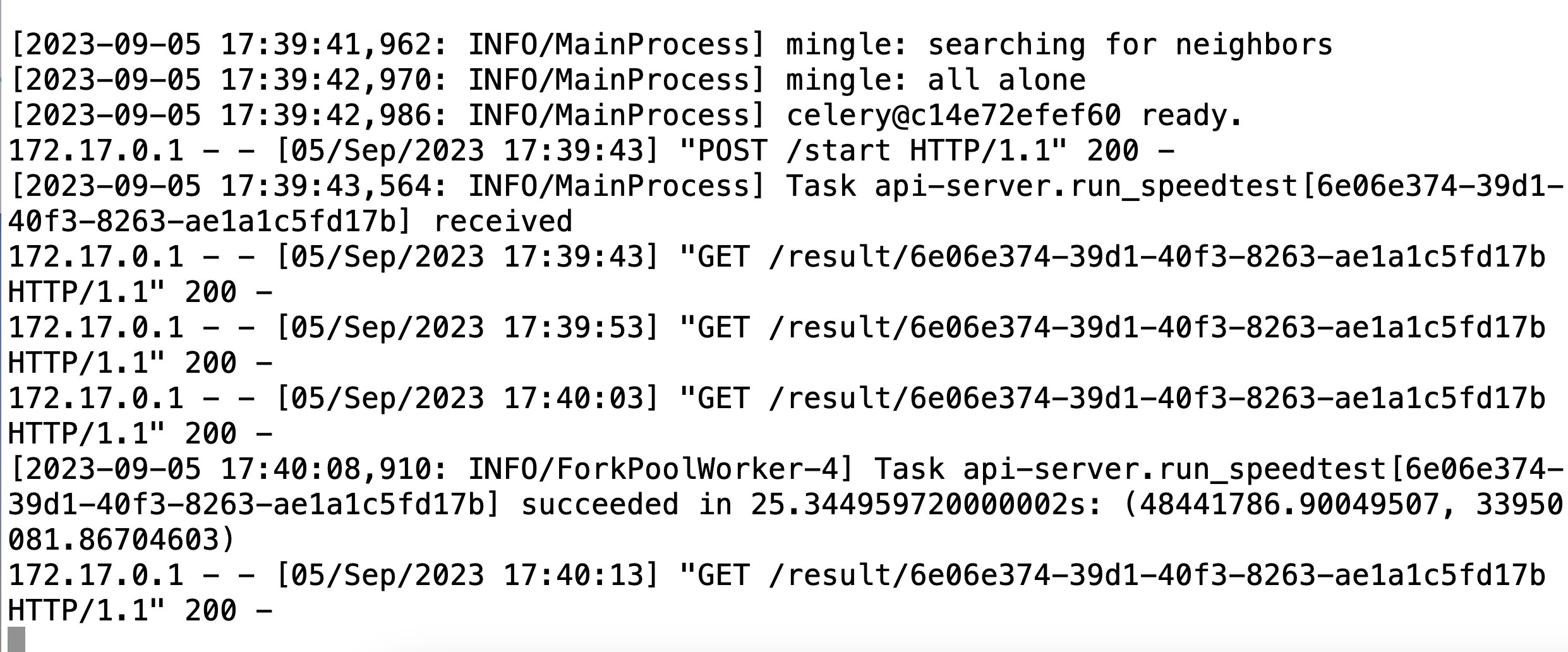
Abbildung 4: Die Log-Einträge des Web- und des Celery-Servers.
Zieleinlauf
Nach dem Start der Messung erkundigt sich der Webserver bei Anfragen auf der Route »/result/<id>« beim Celery-Dienst per »AsyncResult()« (Zeile 24) nach der vorher übermittelten ID. Der externe Celery-Prozess kontaktiert daraufhin sein Backend, einen Redis-Server, und liefert eine Statusmeldung. Läuft die Messung noch, wird das Feld »ready« einen falschen Wert erhalten.
Nach dem Zeitpunkt »17:40:08,910« ist der Speedtest laut der Log-Datei in Abbildung 4 abgearbeitet, das Ergebnis für Up- und Download-Geschwindigkeit liegt vor. Der Celery-Server gibt auf Anfrage des Webservers im Feld »ready« einen wahren Wert zurück. Dieses Status-Update geht anschließend vom Webserver wieder zurück an den anfragenden Client. Der beendet daraufhin am Ende von Listing 1 per »break« seine Endlosschleife. Vorher hat er noch per »logging.info()« das Messergebnis ausgegeben.
Dank der persistenten Speicherung des Ergebnisses im Redis-Server kann der Client auch noch nach geraumer Zeit den Status der Messung und die ermittelten Bandbreitenwerte abfragen. Das klappt so lange, bis ein externer Prozess oder eine Redis-Konfiguration die Messwerte aus Platzgründen abräumt.
Bereit zum Abheben
Vor dem Start des API-Servers in Listing 3 muss die laufende Plattform noch einen Celery-Worker starten. Der nimmt LROs als Tasks entgegen, führt sie aus, überwacht sie und speichert die Ergebnisse in einer Redis-NoSQL-Datenbank. Die muss deshalb ebenfalls als Server-Prozess laufen, damit das ganze System wunschgemäß funktioniert.
Zur Vermeidung von Installationsmüll liegt die Testumgebung in einem Docker-Container gemäß dem »Dockerfile« aus Listing 2. Naturgemäß läuft in einem Container aber immer nur ein einziger Prozess im Vordergrund, und das soll der API-Server von Listing 3 sein. Für die beiden Begleitprozesse, den Celery-Worker und die Redis-Datenbank, definiert Listing 4 deshalb eine Datei »startup.sh«. Sie feuert das Duo mittels »&« im Hintergrund ab, bevor es ans Starten des Python-Webservers in »api-server.py« geht.
Listing 4
Startup-Skript
#!/bin/bash /usr/bin/redis-server & celery -A api-server.celery_app worker --loglevel=info & ./api-server.py
Das Makefile in Listing 5 definiert das Target »docker«, um das Docker-Image aus dem Dockerfile (Listing 2) zusammenzubauen. Docker erhält dabei das Tag »api-patterns«, und das Target »start« startet mit »docker run« einen auf dem Docker-Image basierenden Container.
Listing 5
Makefile
DOCKER_TAG=api-patterns start: docker run -v`pwd`:/build -p8001:8001 -it --rm $(DOCKER_TAG) ./startup.sh docker: docker build -t $(DOCKER_TAG) .
Vom Urknall zum Zerfall
Die vermischten Ausgaben der insgesamt drei verschiedenen Server nach dem Starten des Containers zeigt Abbildung 5. Nach einigen Sekunden ist alles betriebsbereit, und die Anzeige verharrt mit dem API-Server im Vordergrund. Nun darf der Client auf dem Host seine Requests absetzen. Wer mag, kann auch mit einem Webbrowser auf der API herumfuhrwerken. Der Container läuft, bis ihn ein [Strg]+[C] von der Konsole herunterfährt und die Begleitprozesse wegen des zerfallenden Universums mit in den Orkus reißt.
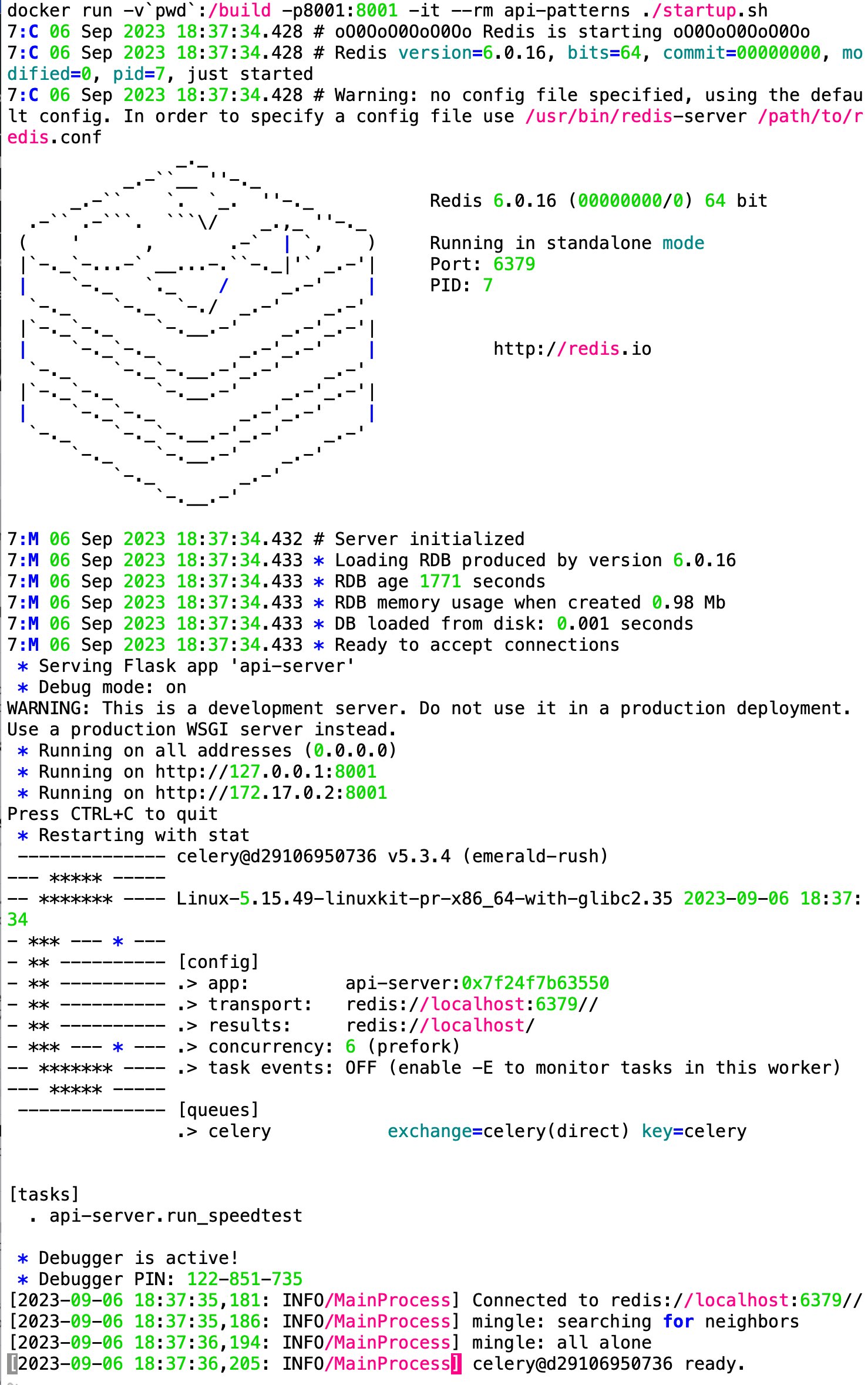
Abbildung 5: Der Container startet mit drei Servern.
Der API-Server lauscht im Container auf Port 8001. Damit er für den Client auch außerhalb des Containers zur Verfügung steht, also auf dem Host, verbindet die Option »-p8001:8001« beim Aufruf von »docker run« die beiden Welten. Die Option »–rm« räumt den Container wieder ab, nachdem der User den Reigen mit [Strg]+[C] abgebrochen hat.
Wichtig ist daneben auch die Option »host=’0.0.0.0’« des API-Servers aus Listing 2. Sie veranlasst den Server dazu, sich mit allen Interfaces des Containers zu verbinden. Nur so kann dieser die Port-Öffnung zum kontrollierenden Host durchstoßen.
Dienstags Müllabfuhr
In der vorgestellten Version hält der Redis-Server als Backend einmal gewonnene Ergebnisse dauerhaft vor. Das würde bei einem öffentlich verfügbaren Dienst aber schnell dazu führen, dass veraltete Daten immer mehr Platz verschwenden. Deswegen muss sich ein robustes System selbst ums Aufräumen kümmern. Die dazu aktivierte Methode hängt stark von der Anwendung ab. Im vorliegenden Fall könnte ein Cronjob alle fünf Minuten anspringen und alle Einträge löschen, die älter als zehn Minuten sind. Wenn Clients die Ergebnisse ihrer Messungen bis dahin nicht abgeholt haben, brauchen sie sie wohl auch nicht mehr.
Läuft der API-Service auf mehreren Instanzen einer Server-Farm, kommen Client-Anfragen nicht immer beim selben Server heraus, und das Backend muss von allen helfenden Instanzen aus erreichbar sein. Nur so kann ein weiterer Bearbeiter den von einem anderen Server gestarteten Task über dessen ID finden und über den Status berichten. (uba/jlu)
Der Autor
Michael Schilli arbeitet als Software Engineer in der San Francisco Bay Area in Kalifornien. In seiner seit 1997 laufenden Kolumne forscht er jeden Monat nach praktischen Anwendungen verschiedener Programmiersprachen. Unter mailto:mschilli@perlmeister.com beantwortet er gern Ihre Fragen.
Infos
- “API Design Patterns”: https://www.amazon.com/API-Design-Patterns-JJ-Geewax/dp/161729585X
- Celery Distributed Task Queue: https://docs.celeryq.dev/en/stable/index.html






Hallo Herr Schilli,
was für ein toller Artikel wieder einmal!
Wunderbar, wie man auf wenigen Seiten ein gar nicht triviales Beispiel mit Python, Redis, Queues und Docker zusammenbauen entwickeln kann!
Übrigens musste ich auf meinem Ubuntu 22.04 unter WSL noch die Skripte startup.sh, api-server.py und natürlich client.py ausführbar machen.
Viele Grüße aus Wiesbaden