
© serezniy / 123RF.com
Heute ist Kubernetes in der IT allgegenwärtig. Anbieter versuchen fast schon mit der Brechstange, das eigene Klientel von den Vorzügen des Container-Orchestrierers zu überzeugen. Doch der hat zum Teil erhebliche Qualitätsprobleme.
Seit Jahren haben die großen Hersteller der Linux-Welt ein absolutes Lieblingsthema: Container, Container, Container. Was einst als Bastellösung galt, hat durch die Pionierarbeit von Docker nicht nur einen professionellen Rahmen bekommen, sondern auch mächtig kommerziellen Aufwind. Etliche aktuelle Deployment-Szenarien wären ohne Linux-Container schon deshalb praktisch undenkbar, weil voll- oder paravirtualisierte Systeme im Gegensatz zu Docker & Co. viel mehr Ressourcen für den eigenen Betrieb benötigen.
Weil es mit Containern alleine aber nicht getan ist, feiert auch Kubernetes seit langer Zeit einen wahren Höhenflug: Der Orchestrierer für Container, der einst bei Google entstand und mittlerweile unter der Ägide einer eigens dafür gegründeten Stiftung steht, ist längst eine feste Größe im Cloud-Umfeld. Red Hat wie Suse haben tief in die Tasche gegriffen, um fertige Kubernetes-Distributionen entweder zu kaufen (Rancher bei Suse (Abbildung 1)) oder selbst zu entwickeln (OpenShift bei Red Hat (Abbildung 2)).
Abbildung 1: Auch Suse will ein Stück des Kubernetes-Kuchens abhaben und hat sich dafür Rancher einverleibt. Das Produkt gilt wie OpenShift als solide Deployment-Methode für Standard-konforme Kubernetes-Cluster. Quelle: Suse
Abbildung 2: Lösungen wie OpenShift von Red Hat helfen Administratoren dabei, die größten Klippen im Kubernetes-Kontext zu umschiffen, lösen aber auch nicht alle Probleme der Umgebung. Quelle: Red Hat
Ganz gleich, welches Thema man seither anspricht: Fast immer laufen die feilgebotenen Lösungen der Unternehmen auf Container und Kubernetes hinaus. Das gegebene Versprechen eint dabei sämtliche Anbieter: Mit Kubernetes ließen sich moderne Anwendungen auf moderne Art und Weise ausrollen und betreiben, heißt es da; viele klassische Probleme aus grauer Vorzeit seien mit dem Gespann aus Containern und Kubernetes kein Problem mehr.
Dass dabei viel zu oft das Marketing der Vater des Gedankens war, merkt mancher Administrator erst, wenn er kopfschüttelnd die ersten Gehversuche in Kubernetes hinter sich hat. Wie üblich ist auch bei Kubernetes nicht alles Gold, was glänzt. Allerdings wäre die Laune manches K8s-Administrators wohl eine bessere, stieße man in Kubernetes nicht regelmäßig auf lausige Codequalität und kaputte Funktionen. Da entsteht das allgemeine Gefühl, dass Wunsch und Wirklichkeit bei der Lösung stark divergieren.
Nicht wenige Administratoren kehren Kubernetes nach einer anfänglichen Evaluation schnell wieder den Rücken, und das aus handfesten Gründen: Das Produkt leidet nicht nur an zum Teil haarsträubenden Fehlern, sondern auch an einem ausgesprochen komplexen Ökosystem. Darin möchte jeder Anbieter ein kleines Stück vom großen Kuchen abbekommen und eine Nischenlösung für einen hochspezifischen Einsatzzweck in Geld verwandeln.
Der folgende Artikel wagt eine Bestandsaufnahme und nennt einige der gröberen Kubernetes-Probleme beim Namen. Dabei geht es auch um die Entwickler-Community hinter dem Produkt: Die ist einerseits zwar riesig, hegt andererseits aber auch eine große Zahl von Spezialinteressen. Dass das dem Code von Kubernetes an vielen Stellen erkennbar schadet, nimmt die K8s-Gemeinschaft dabei allerdings billigend in Kauf.
Klarstellung
Vor dem großen Rant auf den Container-Orchestrierer sei eine Einordnung der folgenden Vorwürfe jedoch gestattet. Kubernetes ist ein verteiltes System, das die Zustände verschiedenster Ressourcen über die physischen Grenzen einzelner Server hinweg konsistent verwalten und zugeteilte Aufgaben in diesem Rahmen zuverlässig erledigen soll. Das ist technisch alles andere als trivial: Nicht aus Versehen gilt der Bau verteilter Systeme als eine Königsdisziplin innerhalb der IT.
Andere Lösungen haben kaum weniger holprige Wege hinter sich. Erinnert sei in diesem Zusammenhang etwa an das heutige Pacemaker, das sein Leben einst als Heartbeat 2 bei Suse begann und später von Red Hat mit viel Geld massiv ausgebaut wurde. In den Anfangstagen von Heartbeat 2 war es nicht ungewöhnlich, dass ein mithilfe der Software konstruierter HA-Cluster durch Programmierfehler in der Software völlig anders agierte, als der Administrator es erwartete.
Red Hat wusste, dass ein zuverlässiger Cluster-Manager für Linux eine schiere Notwendigkeit ist und machte sich in Person von Andrew Beekhof und mit Unterstützung der HA-Community daran, die Kuh vom Eis zu bringen. Dass viele Entwickler im Kubernetes-Dunstkreis stattdessen die Nutzer ihrer Werkzeuge als Dilettanten darstellen, die einfach mit den Gegebenheiten der Moderne nicht zurechtkommen, wird dieser Text später noch thematisieren.
Davon unabhängig kann man es Kubernetes kaum zum Vorwurf machen, dass beim Umsetzen eines verteilten Systems derartiger Komplexität hier und dort eben auch mal etwas schiefgeht. Kritik erlaubt ist aber durchaus an der Art und Weise, wie das Projekt sich organisiert und dadurch erst anfällig für Fehler verschiedener Art macht, diesen Umstand aber konsequent ignoriert. Viele Fehler, die Kubernetes-Administratoren heute plagen, sind eigentlich klassische Kinkerlitzchen, die die Kubernetes-Entwickler sich aber konsequent weigern zu beseitigen.
Was ist Kubernetes?
Zwar wird im Rahmen dieses Texts durchgehend von Kubernetes die Rede sein, doch fällt schon die Feststellung unerwartet schwer, was genau Kubernetes eigentlich ist und was die Bezeichnung meint. Nicht wenige Kommentatoren der Szene schreiben nämlich Kubernetes, meinen damit aber die API sowie die zur Lösung gehörenden Basisdienste. Sie implizieren dabei, dass diese überhaupt nur im Kontext einer kommerziellen Kubernetes-Distribution zum Einsatz kommen. Demnach gilt, dass Admins Kubernetes ausschließlich in Form von Produkten wie OpenShift, Rancher, K3s oder anderen fertigen Lösungen konsumieren.
Das ist Fluch und Segen zugleich: Einerseits abstrahieren OpenShift und Konsorten einige der hier beschriebenen Probleme zwar tatsächlich weg, indem sie ab Werk mit entsprechenden Workarounds oder fertigen Konfigurationen daherkommen. Andererseits erhöhen sie die Komplexität einer Lösung aber durch ihre eigene Funktionalität erheblich. Das wiegt umso schwerer, als Kubernetes selbst alles andere als leicht zu verstehen und zu benutzen ist.
Ein “echtes” Kubernetes gibt es indes durchaus: Auf der Projekt-Website bekommen Interessierte die Vanilla-Variante der Software, die sich ohne Weiteres separat betreiben und nutzen lässt. Im Netz finden sich zudem etliche Anleitungen, die das Setup eben dieser Kubernetes-Variante im Detail für verschiedene Linux-Distributionen erklären. Wer die pure K8s-Erfahrung will, liegt hier also richtig.
Wer diesen Weg wählt, entscheidet sich allerdings für einen ausgesprochen steinigen Pfad. Denn ein Kubernetes-Administrator steht bereits am Anfang eines Deployments vor etlichen wichtigen Entscheidungen, die sich später nur zum Teil oder gar nicht mehr korrigieren lassen. Dazu gehört die Wahl einer Software-defined-Networking-Lösung ebenso wie jene für den passenden Speicher für persistente Daten.
Kubernetes implementiert die Spezifikationen für Container Networking Interfaces (CNI) und Container Storage Interfaces (CSI) zwar vorbildlich. Lösungen wie Flannel oder Calico (Abbildung 3) sind aber keine Selbstläufer und auch nicht mal eben so auszurollen. Stattdessen hat der Admin hier eingangs regelmäßig viel zu lernen, bevor er sich durch Versuch und Irrtum an das richtige Setup herantastet – erst im Labor, dann in der Produktion. Wie bereits erwähnt: Kubernetes löst ein komplexes Problem und ist selbst entsprechend komplex.
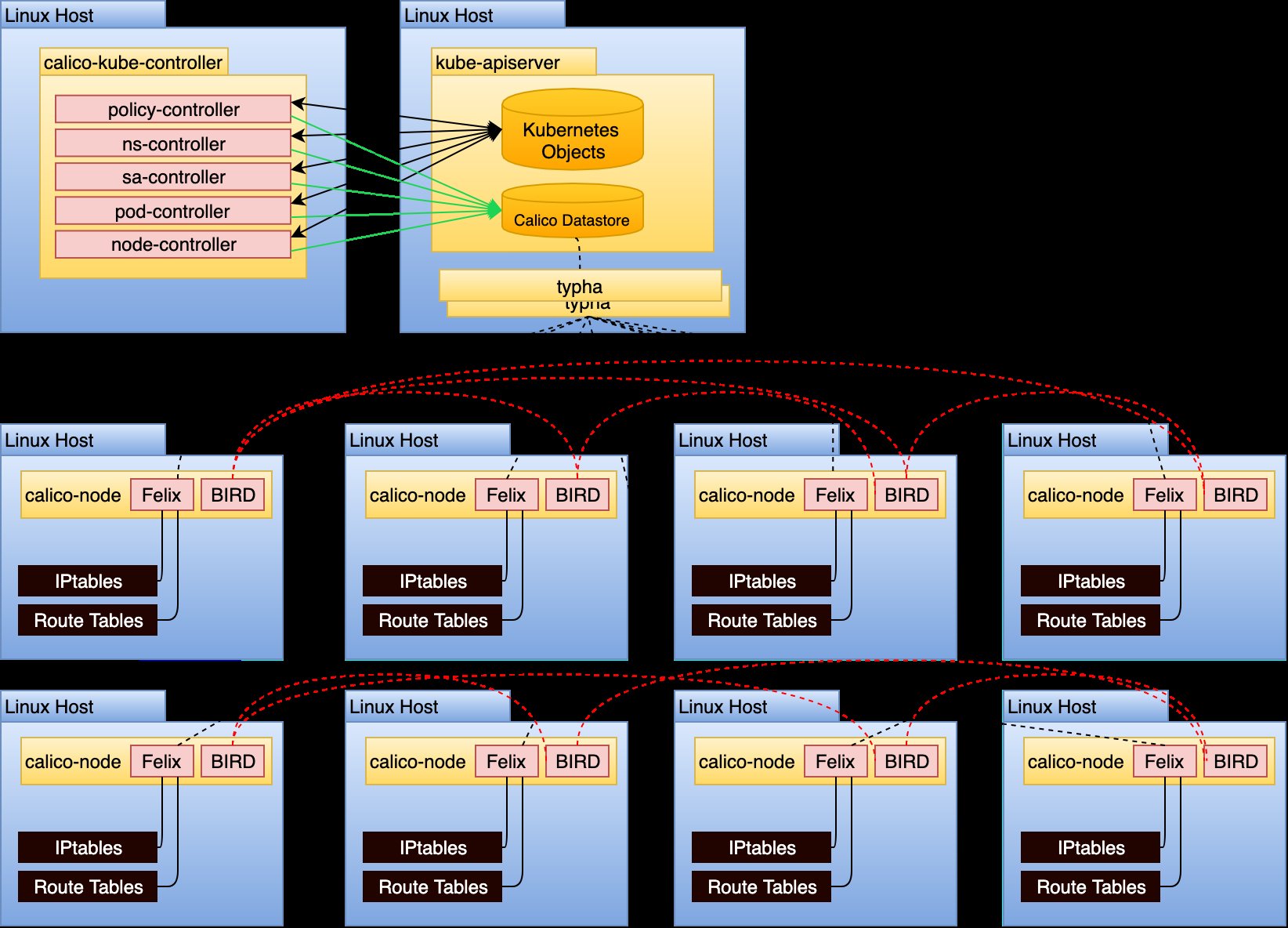
Abbildung 3: Externe Zusatzprodukte wie Calico erweitern Kubernetes zwar um Funktionen, drehen aber auch mächtig an der Komplexitätsschraube und werden dadurch Teil des Problems. Quelle: Vmware
Irre Fehler
Dass die Software so fehlerbehaftet ist, dass Kubernetes-Administratoren oft aus dem Staunen gar nicht mehr herauskommen, verschärft das Problem jedoch erheblich. Grundsätzlich gilt: Um in K8s auf die ersten Probleme und Fehler zu stoßen, muss man üblicherweise gar nicht lange suchen.
Mehrere Kategorien von Fehlern liefern sich hier fast schon ein Duell: Manche Probleme sorgen dafür, dass in Kubernetes eigentlich angelegte Funktionen gar nicht oder nicht richtig funktionieren, zumindest aber keinen einfachen Lösungsweg anbieten. Besonders kritisch sind Konsistenzprobleme in den eigenen Metadaten beispielsweise beim Löschen von Ressourcen. Auch darauf gehen wir im Folgenden noch ausführlich ein.
Wie bereits beschrieben leidet Kubernetes zudem an einer gefährlichen Mixtur aus Verplantheit und Abgehobenheit auf der organisatorischen Ebene. Das dürfte in jüngerer Vergangenheit bereits zahllosen Administratoren schlaflose Nächte bereitet haben. Ein paar Beispiele machen das schnell offensichtlich.
Negativbeispiel Reddit
Beim Online-Forendienst Reddit hat man auf die harte Tour gelernt, auf liebgewonnene Annahmen bei der Systemadministration lieber nicht allzu sehr zu vertrauen. Vor ein paar Monaten führte dort ein Update von Kubernetes 1.23 auf 1.24 für einen mehrstündigen Totalausfall der ganzen Plattform, weil etliche im K8s-Kontext problematische Faktoren zusammenfielen.
Im Fokus der Kritik steht dabei zunächst das Versionsschema, das Kubernetes nutzt. Längst hat sich in der Open-Source-Welt der sogenannte SemVer-Standard etabliert, also das Semantic Versioning. Das sieht vor, dass sich die Versionsnummer einer Softwareversion in drei Bestandteile zerlegen lässt: Vorn steht die Major-Versionsnummer, die sich nur bei großen Änderungen erhöht, falls eine neue Version zu ihrem Vorgänger nicht mehr kompatibel ist. Die Minor-Versionsnummer an zweiter Stelle darf auch größere Änderungen verkünden, solang diese kompatibel zu vorherigen Versionen bleiben. Der letzte Teil der Versionsnummer ist schließlich für Minor-Updates reserviert, also vorrangig Fehlerkorrekturen sowohl im Hinblick auf die Funktionalität als auch in Sachen Security.
Wer sein Kubernetes wie Reddit seinerzeit von der Version 1.23 auf die Version 1.24 hebt, geht auf Grundlage des SemVer-Standards also mit Fug und Recht davon aus, sich damit keine Inkompatibilitäten ins Haus zu holen, die den Betrieb unterbrechen. Diese Annahme war jedoch die Falle: In Kubernetes 1.24 hatten die Entwickler nämlich die interne Bezeichnung von Diensten in den URLs geändert, die externe Lösungen wie das bei Reddit genutzte Calico für die Kommunikation mit K8s nutzen. Statt des vorherigen Wortes »master« musste in der URL ab Kubernetes 1.24 »control-plane« stehen, und die genutzte Calico-Version hatte diese Änderung schlicht noch nicht integriert.
Die K8s-Apologeten haben gleich eine ganze Reihe von Gründen auf Lager, wieso nicht Kubernetes an der Malaise schuld sei, sondern einzig das Personal von Reddit. Zunächst, so heißt es dann, nutze Kubernetes durchaus den SemVer-Standard, und tatsächlich kommt Kubernetes in Versionen wie 1.24.0 daher. Allerdings macht die genutzte Versionsnummer per se eben noch keine Compliance mit SemVer aus, und aus der Erfahrung heraus erwarten Administratoren beim Sprung von v1.23 zu v1.24 gerade keine Änderungen, die die Kompatibilität mit der Vorversion brechen.
Dann, so heißt es weiter, hätte ein Blick in das Changelog ja für Klarheit sorgen können. Das stimmt grundsätzlich, unterschlägt aber einen wichtigen Faktor: Wer K8s im Gespann mit Lösungen wie Calico oder Flannel einsetzt, darf eigentlich erwarten, dass deren Hersteller sich um solche Probleme kümmern oder zumindest eindeutige Aussagen bezüglich der Kompatibilität mit bestimmten Kubernetes-Versionen treffen. Regelmäßig wissen Administratoren, die Calico & Co. nutzen, gar nicht im Detail, was unter deren Hauben eigentlich passiert. Das fast schon gebetsmühlenartig wiederholte Versprechen der Einfachheit von Lösungen wie Calico oder Flannel rächt sich hier bitter.
Wäre die Reddit-Outage ein Verkehrsunfall, würde ein Gericht den Parteien am Ende vermutlich jeweils eine Teilschuld zusprechen. Dass Kubernetes es Administratoren so schwer macht, schon anhand der Versionsnummer fundamentale Änderungen zu identifizieren, müsste aber eigentlich nicht sein.
Schlimmer geht immer
Immerhin: Den Reddit-Ausfall hätten die dortigen Admins durch sorgfältige Changelog-Lektüre sowie vorhergehende Tests verhindern können. Das ist aber längst nicht bei allen Kubernetes-Problemen der Fall, mit denen ein Administrator es üblicherweise zu tun bekommt, wie mehrere Beispiele verdeutlichen.
Gegeben sei beispielsweise eine frische Laborumgebung, bestehend aus drei nagelneuen Servern mit genügend Wumms unter der Haube und Ubuntu 22.04. Folgt man den diversen Anleitungen im Netz, um auf einem solchen System ein Vanilla-Kubernetes auszurollen, beobachtet man regelmäßig allerlei bemerkenswerte Effekte. So nutzt Kubernetes intern CoreDNS für die Namensauflösung. Funktioniert die nicht, lassen sich typische Anwendungen aus dem Kubernetes-Universum wie Istio gar nicht erst nutzen, weil sie nicht starten.
Von zuverlässiger Funktionalität bei CoreDNS war K8s in der Version 1.26, die bei der Entstehung dieses Artikels aktuell war, jedenfalls weit entfernt. In vier von zehn Fällen funktionierte nach dem Ausrollen von Kubernetes (jeweils nach der kompletten Neuinstallation der Systeme per Lifecycle-Management) CoreDNS in Kubernetes aus nicht nachvollziehbaren Gründen nicht. Dass ein Neustart der CoreDNS-Pods diese auf magische Weise zum Leben erweckte, ist da nur ein schwacher Trost, denn die Ursache für das Problem war im Nachhinein nicht mehr herauszufinden. Vertrauenerweckend ist das nicht gerade.
Das gilt umso mehr, da die Kakofonie zwischen Lösung und Admin sich für die nächsten Schritte hin zur Container-Plattform nahtlos fortsetzt. Fast schon berühmt-berüchtigt sind die Inkonsistenzen in der Ressourcenverwaltung von Kubernetes. Dazu muss man wissen, dass es sich in der Kubernetes-Welt eingebürgert hat, externe Software per Paketmanager (Helm) oder über fertige State-Dateien vorzunehmen. Letztere gibt man dem Cluster per »kubectl apply« mit auf den Weg.
Viele größere Softwareprojekte wie Rook, das Ceph durch Kubernetes hindurch ausrollt, kommen mit entsprechend vielen State-Beschreibungen in vielen einzelnen Dateien. Wendet der Administrator diese auf den Cluster an und merkt, dass beim Deployment etwas schiefgeht, hat er üblicherweise eine klare Erwartungshaltung: Dass er nämlich die bereits bestehenden Ressourcen löschen und den Prozess von vorn beginnen kann. Das leuchtet theoretisch ein, funktioniert so in der Praxis allerdings regelmäßig nicht.
Ebenso wie das Deployment-Schema selbst hat es sich im Kubernetes-Umfeld eingebürgert, logisch zusammenhängende Ressourcen in Kubernetes-Namespaces von anderen Ressourcen im selben Cluster abzugrenzen. Greift der Administrator nun aber zur Brechstange und löscht den gesamten Namespace, sieht er statt der in der Dokumentation angepriesenen rückstandslosen Entfernung aller sich darin befindlichen Einträge oft ein Potpourri aus Zombie-Ressourcen. Die verhindern das Löschen eines Namespaces nachhaltig und dauerhaft. Ebenso scheitert Kubernetes daran, sie zu entfernen. Dann helfen bloß noch krude Hacks auf der Kommandozeile, wie der aus Listing 1 für K8s-Datenschutzlösung.
Listing 1
Ressourcen löschen
# kubectl delete apiservice v1alpha1.actions.kio.kasten.io v1alpha1.apps.kio.kasten.io v1alpha1.vault.kio.kasten.io
Wem der gezeigte Kommandozeilenwust noch zu intuitiv ist, der findet im Netz an anderer Stelle den Hinweis, dem Cluster doch gleich per Curl und JSON-Template zu Leibe zu rücken, was dann aber wirklich ganz sicher und versprochen funktioniere (Abbildung 4). Wer, um im vorherigen Beispiel zu bleiben, dachte, nach der unbeliebten XML-Notation der Ressourcen in Pacemaker könne es kaum noch schlimmer kommen, sieht sich hier eines Besseren belehrt.
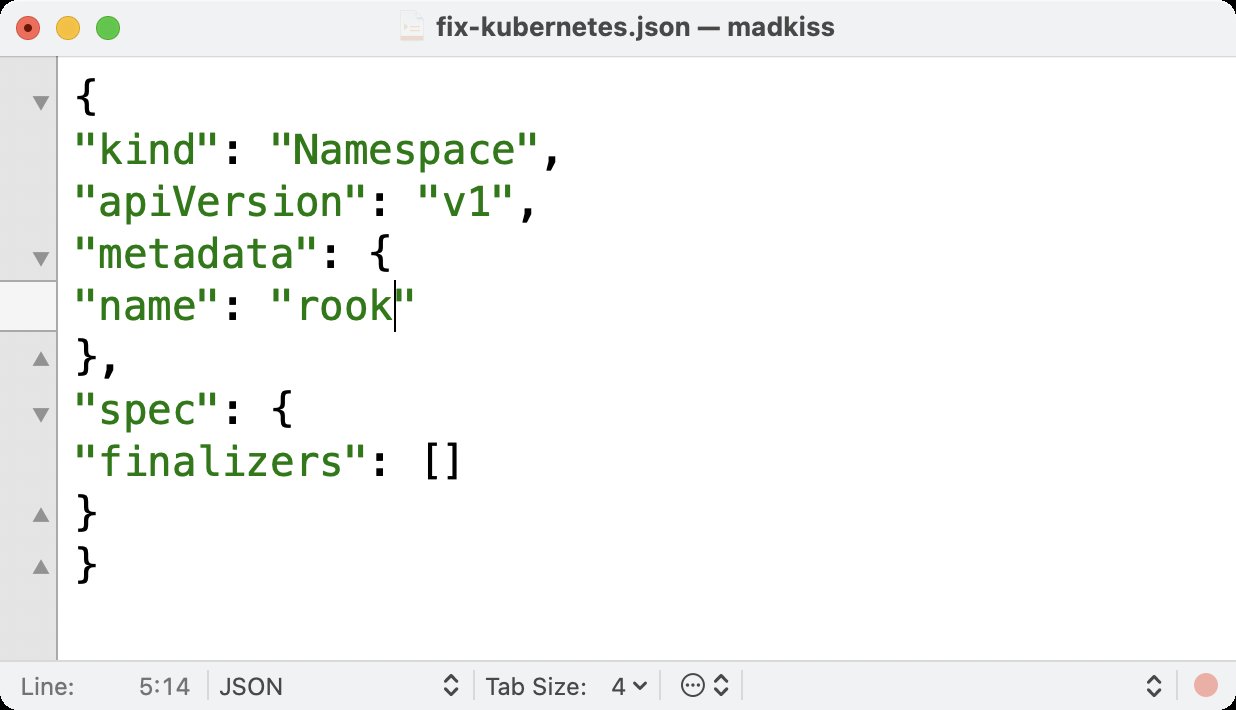
Abbildung 4: Mit JSON-Snippets wie diesem sollen Administratoren ihrem Kubernetes-Cluster zu Leibe rücken, wenn Ressourcen sich dort nicht rückstandslos mitsamt ihren Namespaces entfernen lassen.
Admins, die selbstverständlich davon ausgehen, es vor und nach dem Absetzen eines Kommandos an einen Dienst mit einem konsistenten Zustand zu tun zu haben, wackeln in der Regel spätestens jetzt mit den Ohren.
Bräsige Überheblichkeit
Um es zu wiederholen: Dass eine komplexe Lösung wie Kubernetes mit Fehlern daherkommt, ist weder ungewöhnlich noch unerwartet. Den Blutdruck des Administrators treibt einerseits aber die Art und Weises in die Höhe, wie Kubernetes-Entwickler und -Fans auf Probleme reagieren, und andererseits die Erkenntnis, dass Kubernetes viele seiner aktuellen Probleme gar nicht haben müsste.
Schließlich ist Kubernetes nicht die erste und auch nicht die einzige Software, die sich mit den Tücken eines verteilten Systems herumschlagen muss. Ein anderes, prominentes Softwareprojekt musste vor ein paar Jahren ganz ähnliche Herausforderungen meistern wie die, vor denen K8s heute steht: OpenStack. Wer nun aber annimmt, man habe bei Kubernetes viel Wert auf den Erfahrungsschatz der OpenStack-Entwickler gelegt, sieht sich spätestens nach der Lektüre einschlägiger Mailing-Listen und ebenso zahl- wie fruchtlosen Debatten bei Konferenzen wie der KubeCon eines Besseren belehrt.
Ein Großteil der Community rund um Kubernetes hat in den OpenStack-Entwicklern stets einen Haufen von Idioten gesehen, der für gegebene Probleme viel zu komplexe Lösungen erfand, statt jeweils den einfachsten Weg einzuschlagen. Dabei übersehen die Kritiker, dass etliche OpenStack-Komponenten es zu Beginn der Entwicklung von OpenStack durchaus mit der einfachsten Lösung versucht und sich dabei eine blutige Nase geholt haben. Wie bei Pacemaker hat man daraus bei OpenStack gelernt, die Software sukzessive verbessert, Bugs ausgeräumt und OpenStack in eine verlässliche Lösung für spezifische Einsatzzwecke entwickelt. Beim Kubernetes-Projekt will man von diesem Ansatz in weiten Teilen allerdings nichts wissen.
Stattdessen sind die Reaktionen auf Kritik und Fehlerberichte innerhalb der Community heute fast schon vorhersehbar: Öffnet man den Bug-Tracker der Lösung auf Github [1], finden sich dort über 500 noch offene Einträge, die mit needs-triage gekennzeichnet sind. Ein großer Teil davon lässt sich gar nicht erst sinnvoll reproduzieren. Nicht selten erhalten verzweifelte Administratoren durch die Blume die Auskunft, es müsse wohl irgendetwas am lokalen Setup defekt sein. Man solle das Deployment – oder besser noch gleich das ganze Kubernetes – noch einmal neu ausrollen und sich wieder melden, sollte sich das Problem dadurch nicht in Wohlgefallen auflösen. Mit sinnvoller Reproduzierbarkeit hat auch das freilich absolut nichts zu tun.
Mehr noch: Wer mit Kubernetes-Jüngern über Sinn und Unsinn technischer Entscheidungen oder über ein konkretes Problem spricht, bekommt in der Regel völlig ungefragt, dafür aber neunmalklug erläutert, wieso keinesfalls Kubernetes die Ursache des Problems sein kann. Man habe halt einfach nicht genug Ahnung von der Lösung, heißt es dann. Oder, besonders gern im Kontext des beschriebenen Problems mit Ressourcen-Zombies nach dem Löschen von Namespaces: Ja, das sei zwar unschön, doch ließe eben diese Inkonsistenz überhaupt erst Nutzungsvarianten für Kubernetes zu, die ansonsten gar nicht zur Verfügung stünden.
Inkonsistenz-as-a-Service? Unwillkürlich fühlt man sich an Apple unter Steve Jobs erinnert, das auf Kritik an der seinerzeit schwachen Empfangsleistung von iPhones lapidar darauf hinwies, die Kunden würden die Geräte einfach falsch halten (Abbildung 5).

Abbildung 5: Apple-Chef Steve Jobs sorgte vor vielen Jahren für Lacher, als er Empfangsprobleme beim iPhone auf das falsche Handling des Geräts zurückführte. Quelle: Wikipedia / Matt Buchanan, CC-BY 2.0
Gekommen, um zu bleiben?
Was gestandene Systemadministratoren dabei erstaunt zurücklässt, ist die Selbstverständlichkeit, mit der Kubernetes-Verfechter davon ausgehen, dass K8s in Sachen Container-Orchestrierung der Weisheit letzter Schluss sei. Tatsächlich ist auf dem Container-Markt eine Alternative zu Kubernetes im Augenblick nicht in Sicht. Der einzige einstige Konkurrent Docker Swarm wird seitens des Herstellers zwar noch immer aktiv gepflegt. Auf dem Markt hat die Lösung aber kaum noch Traktion, sodass eine Wachablösung auf dem Thron der Container-Orchestrierer in absehbarer Zeit nicht ansteht. Canonical erweist sich bei Ubuntu in dieser Hinsicht obendrein ebenfalls als Totalausfall: Dort versucht man noch immer, das hausinterne Snap-Format zu propagieren, für das eine Container-Orchestrierung gleich gar nicht zur Verfügung steht.
Gottgegeben ist die Alternativlosigkeit von Kubernetes dennoch keineswegs. Wer der F/LOSS-Community die Fähigkeit abspricht, in relativ kurzer Zeit mit einer Alternative aufzuwarten, unterschätzt ihre Innovationsfähigkeit erheblich. Es muss ja gar kein kompletter Neubau werden: Ein Fork, der sich auf die Stabilisierung der Funktionen und das Beseitigen lästiger Kinderkrankheiten konzentriert, wäre aus Sicht genervter Administratoren bereits eine riesige Verbesserung. Hilfreich wäre es zudem, diente die Kubernetes-Community nicht länger als riesiger Feldversuch für sämtliche Glücksritter, die mit ihren halbgaren Produkten versuchen, schnelle Kasse zu machen. Auch die sind nämlich ein erheblicher Teil des Problems.
Bis etwaige Bewegungen Oberhand gewinnen, bleibt Kubernetes-Administratoren nur, sich mit der Situation zu arrangieren. Wer ein neues K8s-Projekt aus dem Boden stampfen will, setzt dafür idealerweise auf eine Lösung wie OpenShift, Rancher oder Gardener, um sich den größten Teil der Deployment-Probleme von vorneherein vom Hals zu halten. Auch die Kubernetes-Distributionen der Hyperscaler (AWS, Azure, GCP) kommen passend vorkonfiguriert daher und funktionieren deutlich besser als ein manuell zusammengezimmertes Upstream-Kubernetes. Letzteres, so sagen Kubernetes-Fans, sei ohnehin unüblich und fehleranfällig – freilich, ohne dafür konkrete Gründe anzuführen.
Fazit
Zwar suggerieren Anbieter wie Suse oder Red Hat, dass Kubernetes die Zukunft der IT sei und es keine Alternative gebe. Dann muss sich beim Projekt wie bei seinen Produkten absehbar aber manches ändern und vieles verbessern. Hoffnung besteht durchaus, jedoch in einer Form, die Kubernetes-Fans kaum schmecken dürfte: Auch OpenStack wurde sukzessive erst ab jenem Zeitpunkt immer besser, an dem die Hype-affinen Anwender in Richtung Kubernetes weitergezogen waren (Glücksritter inklusive).
Das Sprichwort, wonach viele Köche den Brei verderben, hat auch in der Softwarewelt durchaus einen wahren Kern, und noch tummeln sich definitiv zu viele Köche in der Kubernetes-Küche. Da bleibt nur, Kubernetes-Administratoren der Gegenwart starke Nerven zu wünschen. (jcb)
Infos
- Kubernetes-Bugtracker: https://github.com/kubernetes/kubernetes/issues





