© supatthanan / 123RF.com
Histogramme sind ein probates Mittel, um in Prometheus beispielsweise Latenzen darzustellen. Bisher gab es dabei verschiedene Einschränkungen. Native Histogramme schaffen jetzt Abhilfe.
Prometheus-Histogramme bieten eine Methode, um die Verteilung kontinuierlicher Werte darzustellen. Sie geben Aufschluss über Spannweite und Form der Daten und kommen oft zum Einsatz, um Perzentile zu berechnen, also Prozentränge. Dazu teilt man die Verteilung in 100 Bereiche auf. Das x-te Perzentil ist dann der Wert, den x Prozent der Beobachtungen unterschreiten. Histogramme sind etwa für die Darstellung von Latenzen besonders nützlich.
Die klassische Histogramm-Metrik unterteilt einen Wertebereich in kleinere Abschnitte (in Prometheus: “Buckets”) und zählt die Anzahl der Beobachtungen pro Bereich. In klassischen Histogrammen muss man diese Bereiche zuerst definieren. Für einen Bereich steht jeweils seine Obergrenze. Der Bereich 5s enthält somit die Anzahl aller Beobachtungen mit einem Wert kleiner oder gleich fünf Sekunden. Zusätzlich zu den Bereichen sind noch zwei Werte interessant: die Summe aller Beobachtungen und ihre Anzahl.
Um das an einem praktischen Beispiel zu verdeutlichen: Wir definieren ein Histogramm mit den drei Buckets 1s, 2,5s und 5s. Danach beobachten wir zwei Anfragen, von denen die eine zwei und die andere vier Sekunden dauerte. Die erste Beobachtung fällt in die Bereiche 2,5s, 5s und +Inf, die zweite in die Bereiche 5s und +Inf (Abbildung 1). Daraus lässt sich in Prometheus ein Histogramm der HTTP-Request-Dauer in Sekunden erstellen (Listing 1).
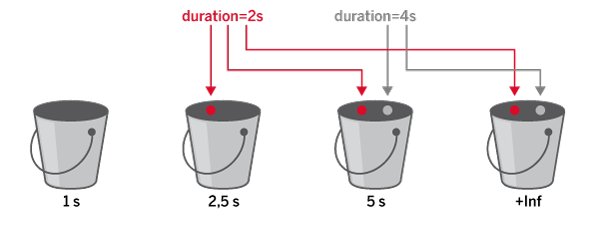
Abbildung 1: Die zwei Sekunden dauernde Anfrage fällt in die Bereiche 2,5s und 5s, die vier Sekunden dauernde in 5s und +Inf.
Listing 1
HTTP-Request-Dauer in Sekunden
# HELP http_request_duration_seconds Histogram of latencies for HTTP requests.
# TYPE http_request_duration_seconds histogram
http_request_duration_seconds_bucket{le="1"} 0
http_request_duration_seconds_bucket{le="2.5"} 1
http_request_duration_seconds_bucket{le="5"} 2
http_request_duration_seconds_bucket{le="+Inf"} 2
http_request_duration_seconds_sum 6
http_request_duration_seconds_count 2
Die Berechnung der Bereiche erfolgt kumulativ. Gibt es zu viele Buckets, kann das zu Performance-Problemen führen. In einem solchen Fall können Sie einige Bereiche via »metric_relabel_configs« löschen, noch während Prometheus die Werte sammelt.
Schwachstellen
Die Festlegung der Bereichsgrenzen ist bei klassischen Histogrammen ein kritischer Schritt. Die Anzahl und Größe der Buckets beeinflusst die Genauigkeit der Quantil-Schätzungen, die sich mithilfe des Histogramms erzeugen lassen. Quantil ist der Oberbegriff zu Perzentil; Perzentile sind die Quantile 0,01 bis 0,99 in Schritten von 0,01.
Sind die Bereiche zu fein aufgeschlüsselt, resultiert daraus eine große Anzahl von Zeitreihen und ein hoher Verbrauch an Speicher und Plattenplatz. Andererseits führt eine zu grobe Einteilung zu ungenauen Quantil-Schätzungen. Die Balance zwischen der Anzahl und Größe der Bereiche zu finden, erfordert sowohl domänenspezifisches Fachwissen als auch statistisches Verständnis. In einigen Fällen gehen Sie vielleicht von Annahmen aus, die sich als realitätsfern erweisen, sobald Ihre Anwendung produktiv zum Einsatz kommt. Da sich zudem Histogramme mit unterschiedlichen Bereichslayouts nicht zusammenführen lassen, stellt eine Änderung von Bereichsgrenzen alles andere als eine triviale Aufgabe dar.
Die neuen nativen Histogramme vereinfachen es, sich für eine Bereichsverteilung zu entscheiden, indem sie ein dynamisches und adaptives Layout verwenden. Sie ermöglichen eine präzisere Darstellung der Daten, indem sie die Größe und die Anzahl der Bereiche auf der Grundlage der Datenverteilung selbstständig anpassen [1].
Ein weiteres Problem bei klassischen Histogrammen ist ihre Größe und deren Auswirkung auf die Performance. Jeder Bereich umfasst eine Zeitreihe, die Indizierung und Speicherplatz beansprucht; leere Bereiche werden immer dargestellt. Außerdem ist die Partitionierung der Histogramme mit mehreren Labels sehr ineffektiv, da jedes Label unabhängig von der Anzahl der tatsächlich verwendeten Bereiche gleich viel Aufwand verursacht. Aus diesem Grund bleiben in Histogrammen oft auch nützliche Labels wie “Fehlercode” außen vor, da jeder Fehlercodewert zu Dutzenden neuer Zeitreihen führen könnte.
Native Histogramme
Native Histogramme verwenden ein exponentielles Bucket-Layout mit einer sparsamen Darstellung der Daten. Leere Bereiche fallen heraus, was den Speicher- und Festplattenplatz-Overhead reduziert. Es kommt ein regelmäßiges logarithmisches Bereichslayout mit hoher Auflösung zum Einsatz. Zudem benutzt dieser Histogrammtyp einfache statt kumulative Bereiche. Die Anwendung, die die Histogramme ausgibt, bestimmt das Schema auf der Grundlage anfänglicher Hinweise.
Die traditionelle Prometheus-Zeitreihendatenbank erlaubt keine sparsame Darstellung. Ein klassisches Histogramm verwendet üblicherweise zwei Zeitreihen für Anzahl und Summe der Werte sowie eine zusätzliche Zeitreihe pro Bucket, einschließlich der leeren Bereiche. Viele Bereiche verursachen deshalb sehr schnell einen hohen Aufwand. Daher werden die neuen nativen Histogramme anders gespeichert [2]. Die Prometheus-Zeitreihendatenbank legt sie in einer Struktur ab, die alle Abschnitte sowie die Summe und die Anzahl zusammen enthält. Diese Strukturen betrachtet die Anwendung als eindeutige (“native”) Objekte und nicht als unabhängige Zeitreihen. Auf diese Weise fällt der Zeitreihen-Overhead nur einmal an.

Abbildung 2: Ein natives Histogramm wird mit allen Bereichen als ein einziges Objekt gespeichert. Alle nicht leeren Bereiche (und nur diese) gehören zu einer Zeitreihe.
Wiederverwendet
Schon früher hat Prometheus in Form von Protocol Buffers oder kurz Protobuf einen sprach- und plattformunabhängigen Mechanismus zum Serialisieren von Daten verwendet. Dabei kommt statt eines Textformats, das Menschen direkt lesen könnten, ein Binärformat zum Einsatz. Über die Jahre setzte sich das Textformat als Norm durch, die Komplexität der Histogramme bringt nun doch Protobuf wieder ins Spiel. Es erlaubt eine sehr kompakte Darstellung und macht das (De-)Serialisieren gut beherrschbar. Schalten Sie diese Option ein, speichert Prometheus alle Metriken mit Protobuf, sofern das Ziel dieses Format unterstützt. Metriken lassen sich zwar nach wie vor optional mit Tools wie Curl einsammeln, doch das erzwingt eine Rückkehr zum Textformat und schließt damit das Verwenden nativer Histogramme aus.
Umschalten
Um native Histogramme in Prometheus nutzen zu können, müssen Sie sie über das Flag »–enable-feature=native-histograms« aktivieren. Dadurch erfolgt die Datensammlung auf dem Ziel über das Format Protobuf. Sie sollten dazu die neueste verfügbare Version von Prometheus verwenden, da diese Funktion noch als experimentell gilt und laufend Änderungen unterliegt. In Go unterstützt die Bibliothek Client_golang 0.14 native Histogramme. Den Code passen Sie dazu wie in Listing 2 gezeigt an.
Listing 2
Anpassung für native Histogramme
requestDuration: prometheus.NewHistogramVec(
prometheus.HistogramOpts{
Name: "prometheus_http_request_duration_seconds",
Help: "Histogram of latencies for HTTP requests.",
- Buckets: []float64{.1, .2, .4, 1, 3, 8, 20, 60, 120},
+ NativeHistogramBucketFactor: 1.1,
+ NativeHistogramMaxBucketNumber: 150,
},
[]string{"handler"},
)
Etwas vereinfacht ausgedrückt, verwenden native Histogramme exponentiell gestaffelte Buckets, um den gesamten Float64-Wertebereich abzudecken. Die Breite der Bereiche nimmt um einen konstanten Faktor zu, der sich anpassen lässt, um Aufwand und Genauigkeit auszubalancieren. Ein Faktor von 1,1 (jeder folgende Bereich ist 10 Prozent breiter als der vorherige) bietet einen guten Kompromiss und führt zu acht Bereichen pro Zweierpotenz, beispielsweise zwischen 1 und 2, 2 und 4, 4 und 8 und so weiter.
Die Höchstzahl von Bereichen geben Sie über die Option »NativeHistogramMaxBucketNumber« vor. Ohne diese Einstellung könnte die Anzahl der Bereiche unkontrolliert wachsen und einen hohen Speicherbedarf verursachen. Die Beschränkung auf eine bestimmte Anzahl ermöglicht dem nativen Histogramm, seine Bereiche neu zu berechnen und gegebenenfalls einige davon zu aggregieren, um den Speicherplatzbedarf zu reduzieren.
Resultate
Abbildung 3 zeigt für identische Daten einen Vergleich der Berechnung des 95. Perzentils einer spezifischen Anfrage. An jedem Punkt der X-Achse stellt der entsprechende Y-Wert den Schwellenwert dar, unter den 95 Prozent der Anfragen zu diesem Zeitpunkt gefallen sind. Links sehen Sie eine Berechnung mit einem klassischen Histogramm, rechts mit der nativen Variante.
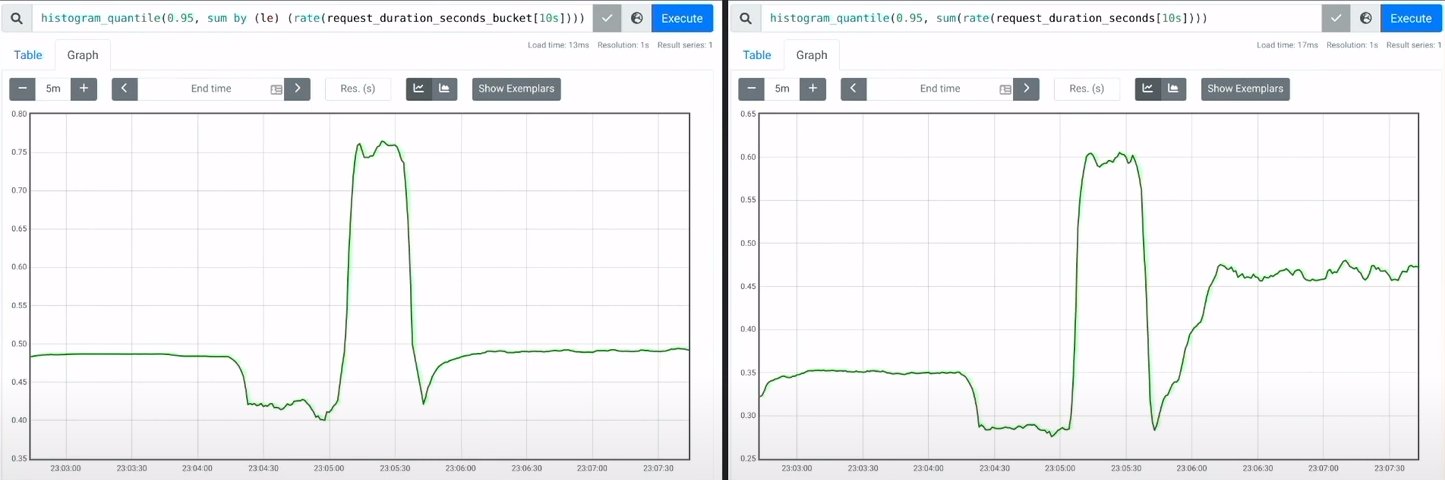
Abbildung 3: Ein Vergleich der Berechnung des 95. Perzentils einer spezifischen Anfrage im Zeitverlauf mit klassischem (links) und nativem Histogramm (rechts). Quelle: https://youtu.be/fikCqhlUOmQ
Der Vergleich zeigt, dass die nativen Histogramme eine viel exaktere Schätzung des Perzentilwerts liefern. Im Gegensatz dazu können klassische Histogramme irreführenderweise suggerieren, die Werte lägen vor und nach einer Spitze identisch. Tatsächlich liegt der Perzentilwert im Beispiel vor dem Spike bei etwa 350 Millisekunden, während er nach dem Spike bei rund 500 Millisekunden liegt. Diesen Unterschied von 150 Millisekunden bilden klassische Histogramme nicht ab.
Fazit
Zusammenfassend lässt sich sagen, dass das Prometheus-Datenmodell durch die Erweiterung um native Histogramme eine große Veränderung erfährt [3]. Diese neue Funktion liefert eine genauere Darstellung der Daten und ermöglicht eine bessere Berechnung der Perzentile als klassische Histogramme. Die Umstellung auf die Verwendung von Protobuf für das Sammeln von Metriken ist ein bedeutendes Upgrade. (jcb/jlu)
Der Autor
Julien Pivotto hat als Maintainer von Prometheus maßgeblich zur Entwicklung und Weiterentwicklung des Tools beigetragen. Er zählt zu den Gründern des Unternehmens O11y, das Premium-Support für verschiedene Open-Source-Überwachungswerkzeuge wie Prometheus, Thanos und Grafana bereitstellt.
Infos
- Native Histogramme in Prometheus: https://docs.google.com/document/d/1cLNv3aufPZb3fNfaJgdaRBZsInZKKIHo9E6HinJVbpM/edit
- Native Histogramme in Prometheus (Vortragsvideo): https://promcon.io/2022-munich/talks/native-histograms-in-prometheus
- PromQL für native Histogramme (Vortragsvideo): https://promcon.io/2022-munich/talks/promql-for-native-histograms






