
© quils / 123RF.com
Wenn die Lippenbewegungen des Schauspielers in der Großaufnahme nicht zum gesprochenen Text passen, sabotiert das nicht nur Hörgeschädigte, es strengt auch normal Hörende an. Beim lippensynchronen Übersetzen von Filmtexten kann KI helfen.
Die automatisierte Verarbeitung natürlicher Sprache ist ein wichtiges Anwendungsfeld der künstlichen Intelligenz. Das Aufgabenspektrum reicht hier von der Textrecherche (wie bei der Websuche) bis zur Interaktion mit gesprochener Sprache (wie bei Siri, Alexa oder ähnlichen sprachgesteuerten Agenten). Verfahren zur intelligenten Sprachverarbeitung, die über das einfache Abspeichern und Durchmustern von Texten hinausgehen, werden seit über 70 Jahren entwickelt. Der berühmte Turing-Test [1] sieht das Verstehen und Produzieren von Sprache sogar als zentrales Kriterium für künstliche Intelligenz an.
Die automatisierte Sprachverarbeitung ist mit der Spracherkennung zudem eine der frühesten Anwendungen für Big-Data-Analysen. So ließen sich im Spracherkennungssystem Aubrey der Bell Labs bereits 1952 die Parameter für jeden Nutzer so einstellen, dass das System Ziffernfolgen mit hoher Genauigkeit erkannte. Zunächst erfolgte dieses Feintuning der Parameter von Hand. Die Automatisierung dieses Schritts führt zum maschinellen Lernen, also dem Einstellen von Modellparametern auf der Grundlage von Trainingsdaten.
Das Ergebnis des Lernens sind dann die Modelle und ihre Parameter. Entsprechend spricht die Fachwelt auch nicht von künstlicher Intelligenz, sondern von Modellen der künstlichen Intelligenz. Ein Durchbruch für das maschinelle Lernen war die breite Einführung neuronaler Netze. Obwohl auch deren theoretische Grundlage schon früh gelegt wurde, erforderte die breite Nutzung zunächst ein Voranschreiten der Rechenleistung von Computern.
Die einzelnen Neuronen des Netzes erledigen dabei eine jeweils kleine und relativ einfache Aufgabe. Ein Neuron hat keine direkte Information über seine Nachbar-, Vor- oder Folgeneuronen. Es verhält sich wie ein kleines Zahnrädchen in einer Taschenuhr, das für das Weiterticken der Uhr nicht fehlen darf, aber auf sich allein gestellt keine Zeit misst.
Die Aufgabe jedes Neurons ist folgende: Es summiert zunächst die gewichteten Eingaben der ihm vorgeschalteten Neuronen. Seine Aktivierung hängt davon ab, ob diese Summe einen gewissen Schwellwert überschreitet. Das Addieren geschieht nicht proportional, sondern nichtlinear, also so, dass Werte weit unterhalb des Schwellwerts eine 0 ergeben und Werte oberhalb eine 1. Das Verhalten lässt sich mit dem klassischer Transistoren vergleichen und ermöglicht (hinreichend großen) neuronalen Netzen im Prinzip, jede mögliche Funktion zu berechnen.
Im Unterschied zu Transistoren ist die Aktivierung jedoch nicht sprunghaft, sondern stetig (es gibt auch Werte zwischen 0 und 1) und dadurch differenzierbar. Dadurch lassen sich die Fehlerkosten, die ein neuronales Netz zum Beispiel bei der Klassifizierung eines Bilds als “Katzenbild” oder “kein Katzenbild” macht, auf die einzelnen Parameter des Modells (die Gewichte der Eingaben und Schwellwerte für die Aktivierung jedes einzelnen Neurons) umrechnen. Man bildet hierfür die (partiellen) Ableitungen nach jedem der Parameter und weiß dann, wie eine Änderung des jeweiligen Parameters den Fehler beeinflusst.
Die Parameter werden dann ein Stück in Richtung kleinerer Fehler angepasst und von da aus die Fehlerkosten erneut berechnet und so weiter. Die Fehlerrückführung (Backpropagation) und das Anpassen der Parameter in Richtung auf kleinere Fehler (Gradientenabstieg) sorgen dafür, dass die Neuronen in ihrer Gesamtheit kombiniert das Lösen einer Aufgabenstellung erlernen können. Man trainiert neuronale Netze, indem man ihnen Paare von Eingaben und erwarteten Ausgaben vorlegt und sie die Modellparameter Stück für Stück anpassen, bis die Ergebnisse möglichst geringe Fehlerkosten verursachen.
Die Neuronen im neuronalen Netz werden in Schichten organisiert, ähnlich wie die visuelle Verarbeitung im Gehirn. Obwohl man beweisen kann, dass theoretisch eine einzige innere Schicht genügt, um beliebige Funktionen zu approximieren, hat sich gezeigt, dass sich Netze mit mehr Schichten häufig einfacher trainieren lassen (Abbildung 1). An dieser Stelle setzt das Deep Learning an, wobei die Grenze von flach zu tief von der jeweiligen Marketingabteilung der Unternehmen gesetzt wird und eigentlich keine praktische Relevanz besitzt.
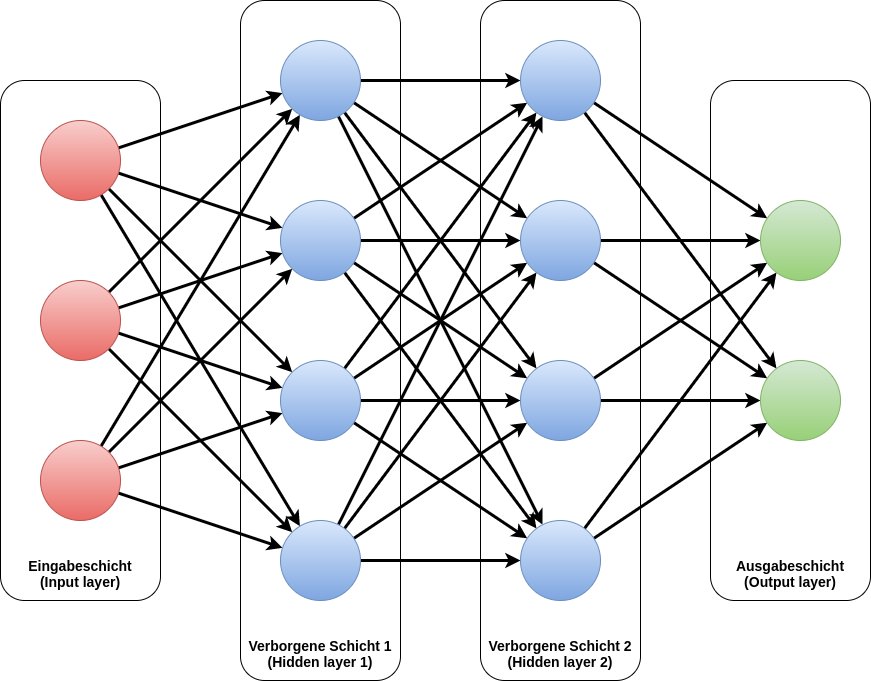
Abbildung 1: Ein Beispiel für ein neuronales Netz mit zwei inneren Schichten. Die (roten) Eingabeneuronen aktivieren sich entsprechend der Eingabedaten. Alle folgenden Schichten berechnen jeweils ihre daraus folgende Aktivierung entsprechend der gelernten Parameter. Das Ergebnis lässt sich an der Aktivierung der (grünen) Ausgabeneuronen ablesen.
So oder so: Maschinelles Lernen führt bisher eher nicht zu allgemeiner künstlicher Intelligenz (Artificial General Intelligence, AGI), die sich in allen unterschiedlichen Bereichen der Welt intelligent verhält (obwohl auch hier manche Marketingabteilung anderes behauptet). Stattdessen hängen die Fähigkeiten jeweils genau von den Daten ab, mit denen die Modelle trainiert wurden. Sie sind also Spezialisten – was wenig überrascht, denn wir erwarten ja auch nicht von einem Musiker, dass er ein Auto reparieren kann, oder von einer Mathematikerin, dass sie eine Bleiverglasung anfertigt.
Allerdings werden einige Modelle (so wie die unten beschriebenen) mittlerweile mit dermaßen vielen und unterschiedlichen Daten und teils auch auf unterschiedliche Ziele hin trainiert, dass sie durchaus den oberflächlichen Eindruck von Intelligenz vermitteln können.
Sequenzlernprobleme
Natürliche Sprache zeichnet sich unter anderem dadurch aus, dass Sätze aus unterschiedlich vielen Wörtern bestehen und dass die Reihenfolge der Wörter für die Bedeutung des Satzes herausragend wichtig ist. Bei gesprochener Sprache ist es sogar noch komplizierter: Im Satz “Ich sagte nicht, wir sollten ihn umbringen!” kann man die Hauptbetonung auf jedes beliebige Wort legen, und jedes Mal ergibt sich eine andere Bedeutung. Probieren Sie es aus!
Sprache entwickelt sich über die Zeit, beim Lesen und Schreiben und noch viel mehr beim Hören und Sprechen. So ist es nur natürlich, dass Menschen Sprache Wort für Wort verarbeiten und die Bedeutung Stück für Stück erschließen, bis sie am Ende eines Texts ankommen. Einige Verfahren des maschinellen Lernens haben Schwierigkeiten mit Sequenzlernproblemen, also wenn man sie mit Sequenzen von Worten (sprich: Sätzen) oder Buchstaben (sprich: Wörtern) konfrontiert.
Rekurrente neuronale Netze (RNNs) und ihre Spielarten und Abkömmlinge eignen sich für Sequenzlernprobleme (wie in Abbildung 2) besonders gut. RNNs haben keine fixe Anzahl innerer Neuronenschichten, sondern diese richtet sich nach der Länge der Eingabe. Jede Schicht verarbeitet ein Element der Eingabesequenz und betrachtet dabei auch die vorangehende innere Schicht mit.
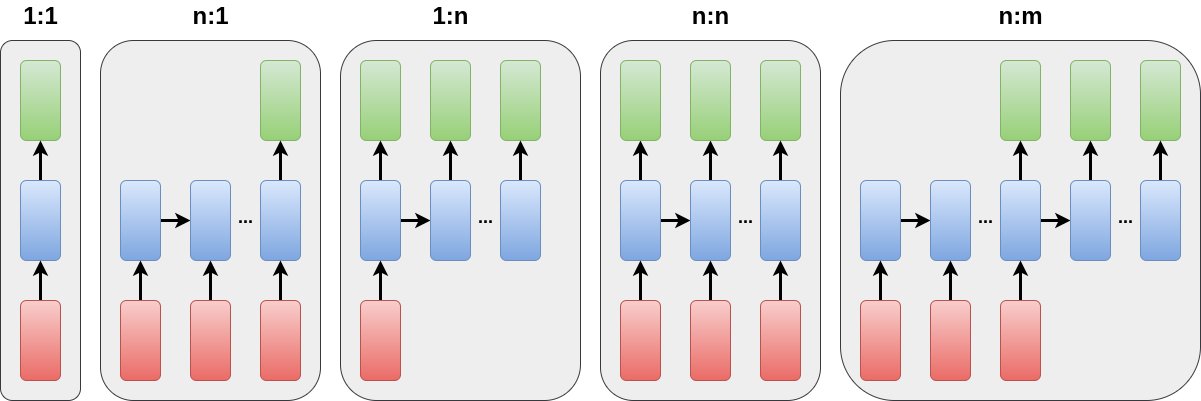
Abbildung 2: Mögliche Sequenzlernaufgaben, die bei der Verarbeitung von Sprache auftreten. (Bild abgewandelt nach Karpathy, 2015).
Im Unterschied zu normalen neuronalen Netzen teilen sich die inneren Schichten eines rekurrenten neuronalen Netzes ihre Parameter. So kann ein RNN lernen, die gemeinsame Bedeutung der zwei Wörter “Kugel” und “Eis” zu erfassen, unabhängig davon, wo genau sie im Satz beieinander stehen. Die Zusammenhänge, die das RNN erfassen kann, beschränken sich tatsächlich nicht nur auf benachbarte Wörter. Es kann – zumindest theoretisch – beliebig komplexe und entfernte Zusammenhänge erkennen lernen.
RNNs können vielfältige Varianten von Sequenzlernproblemen bearbeiten. Ganz links in Abbildung 2 sehen Sie den einfachsten Fall, eine 1:1-Beziehung zwischen Ein- und Ausgabe. Sie enthält gar keine Sequenz, sondern entspricht dem Beispiel aus Abbildung 1.
Sehr häufig ist die Many-to-one-Architektur (n:1), die zum Beispiel zur Klassifizierung dient und bei der nur die Eingabe eine Sequenz ist. Auf diese Weise lässt sich zum Beispiel ein Eingabetext einer Kategorie eines gegebenen Kategoriensystems zuordnen. Dabei besteht die Eingabe aus einer Sequenz von Wörtern und die Ausgabe aus der zu ermittelnden Kategorie. Das Verfahren läuft dabei iterativ (in Abbildung 2 von links nach rechts) durch die inneren Zustände (blau). Das Ergebnis (grün) basiert auf der gesamten Sequenz von Eingabewörtern (rot).
Die umgekehrte Art des Sequenzlernproblems besteht darin, aus einer Eingabe fixer Länge eine variabel lange Ausgabe zu erzeugen. Das ist zum Beispiel beim Generieren von Texten wünschenswert, etwa wenn man aus einer fixen Anzahl an Messwerten eine Wettervorhersage erzeugen will. Hier findet die One-to-many-Architektur (1:n) ihren Einsatz. Nach dem Training nutzt man das Modell, um jeweils das nächstes Wort der Ausgabesequenz zu bestimmen (oder die Ausgabe abzuschließen).
Die erste in Abbildung 2 zu sehende Many-to-many-Architektur (n:n) erzeugt eine Ausgabesequenz, die genauso lang ist wie die Eingabesequenz. Hiermit lassen sich unter anderem Tagging-Aufgaben bearbeiten, also zum Beispiel die Markierung von Firmennamen in Texten. Ein weiteres Exempel wäre das Markieren von Start- und Endbahnhof, Datums- und Zeitangaben sowie sonstigen Informationen, die ein Nutzer bei der Bestellung eines Fahrscheins weitergeben könnte.
Die Many-to-Many-Architektur (n:m) ganz rechts schließlich erlaubt unterschiedlich lange Ein- und Ausgaben, was vielfältige neue Möglichkeiten eröffnet, die die n:n-Architektur so nicht bietet. Frage und zugehörige Antwort sind hier nur zufällig einmal gleich lang.
Texte lassen sich oft nicht inhaltsgetreu in eine andere Sprache übersetzen, wenn man die Anzahl der Wörter dabei nicht verändern darf. Dieses Modell heißt Encoder/Decoder, weil es die Eingabesequenz zunächst nach dem n:1-Prinzip in eine Repräsentation fixer Länge encodiert und diese danach zur Ausgabesequenz decodiert. Für lange Sequenzen ergibt sich dabei ein Flaschenhals, da das Modell alle Informationen durch die fixe Repräsentation hindurchpressen muss.
Erweiterungen des Encoder-Decoder-Modells nutzen eine Aufmerksamkeitssteuerung, die nach jedem Schritt des Decodings die Aufmerksamkeit über die Zwischenschritte der Eingabesequenz erneut berechnet. Dies ist zum Beispiel für eine zuverlässige Übersetzung aus einer Sprache in eine andere sehr hilfreich, weil während des Encodings hauptsächlich die Gesamtbedeutung des Eingabesatzes erfasst werden muss. Aus der ergibt sich, ob zum Beispiel “Bank” besser als “bench” oder als “bank” ins Englische übersetzt werden sollte. Außerdem gleicht die Aufmerksamkeitssteuerung Unterschiede im Satzbau während des Decodings aus.
Hören und sehen
Ein besonderes Problem ergibt sich, wenn man ein System zur maschinellen Übersetzung mit der Encoder-Decoder-Architektur so anpassen muss, dass zusätzliches externes Wissen in den Übersetzungsprozess mit einfließen kann (Abbildung 3). Das ist zum Beispiel nötig, um Übersetzungen zu erzeugen, die möglichst gut lippensynchron gedubbt werden können. Zunächst wollen wir aber erklären, warum das wichtig ist.
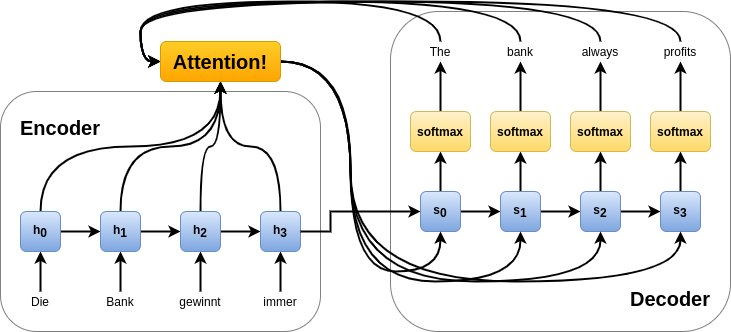
Abbildung 3: Ein n:m-Encoder-Decoder-Modell mit Aufmerksamkeitssteuerung für die Ende-zu-Ende-Umformung von natürlicher Sprache in natürliche Sprache.
Während des Sprechens bewegen sich die Lippen, der Kiefer und Teile des Gesichts in einer Art und Weise, die den erzeugten Lauten entspricht. Für die Laute M und B müssen sich Ober- und Unterlippe unweigerlich berühren, während ein A oder O mit offenen Lippen gesprochen wird. Das nutzen Hörgeschädigte beim Lippenlesen, um auch ohne (verständlichen) Ton den Inhalt des Gesprochenen zu erfassen. Selbst Normalhörende betrachten immer Lippen und Mimik des Sprechers und nutzen das beim Erfassen des Gesagten – je nach Hintergrundgeräuschen mehr oder weniger.
Das umgekehrte Phänomen bezeichnet man als McGurk-Effekt: Unterscheiden sich die visuell wahrgenommenen Lippenbewegungen und das Gehörte, kann der visuelle den Höreindruck quasi überschreiben. “Gaga” wird bei einem Video mit sich schließenden Lippen als “Baba” wahrgenommen. Unpassende Lippenbewegungen führen aber nicht nur zu falschen Wahrnehmungen. Die kognitive Dissonanz zwischen Hör- und Seheindruck ist für das Gehirn zugleich anstrengend und ermüdend.
Filmübersetzungen müssen also berücksichtigen, dass Zuschauer den Sprecher nicht nur hören, sondern auch sehen. Die Übersetzung muss Lippenbewegungen miteinbeziehen, damit der synchronisierte Film in der Zielsprache möglichst angenehm zu konsumieren ist und keine Artefakte der Synchronisierung den Eindruck trüben wie zum Beispiel Phantombewegungen der Lippen. So soll die audiovisuelle Übersetzung von Medien oft dem Zuschauer den Eindruck vermitteln, dass der Sprecher im Bild gar nicht erst übersetzt und neu vertont werden musste, sondern dass er den zu hörenden Text wirklich selbst gesprochen hat.
Für den Übersetzungsprozess bedeutet das eine zusätzliche Einschränkung, weil auch der visuelle Kanal beachtet werden muss. Während es bei der Übersetzung normalerweise darum geht, eine Transkription zu finden, die den Inhalt eines Quelltexts möglichst wahrheitsgetreu in die Zielsprache überträgt, gilt es bei der audiovisuellen Übersetzung zwischen inhaltlicher und visueller Passung abzuwägen. In erster Linie müssen die audiovisuellen Übersetzungen ähnlich lang sein, was schwierig sein kann, wenn gleichbedeutende Wörter in zwei Sprachen unterschiedlich lang sind (etwa “einzigartig” und “unique”). Zusätzlich muss man Lippen- und Kieferstellung beachten, jedenfalls, wenn der oder die Sprechende gerade im Bild ist.
Abbildung 4 demonstriert das anhand eines Beispiels aus der Fernsehserie “Heroes”. Der Schauspieler sagt hier im Original “No no, each individual’s blood chemistry is unique, like fingerprints”. Das führt selbstverständlich dazu, dass genau diese Wortsequenz perfekt auf die sichtbaren Bewegungen passt. Während eine möglichst quellentreue Übersetzung nun zwischen der “individuellen Blutchemie” oder der “Chemie des Bluts jedes Menschen” auswählen mag, wurde für die Synchronfassung tatsächlich die Chemie komplett ignoriert: Die Zuschauer hören an dieser Stelle “Nein nein, das Blut jedes Menschen ist einzigartig, wie Fingerabdrücke”, was zeitlich sehr gut passt.
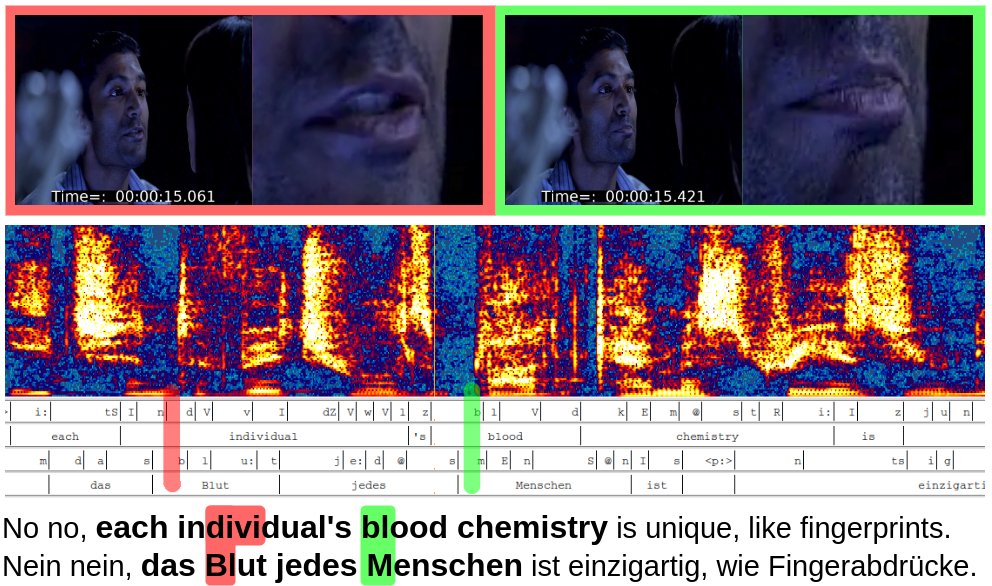
Abbildung 4: Das Einhalten der Lippensynchronität im Dubbing am Beispiel einer kurzen Szene aus der amerikanischen Fernsehserie “Heroes”.
Perfekt ist es jedoch nicht. An der grün markierten Stelle ersetzt das “M” das “Bl” wie gewünscht lippensynchron, da beide Laute nur durch sich treffende Lippen erzeugt werden können. Ganz anders verhält es sich bei der rot markierten Stelle: Während das “divi” aus der Originalfassung eine wahrnehmbare Öffnung der Lippen erfordert, kann das nun zu hörende “Bl” nur durch sich schließende Lippen erzeugt werden.
Kleine und seltene Abweichungen fallen den meisten Zuschauern nicht auf. Obendrein kann ein langwieriger und wiederholter Konsum von synchronisiertem Material bei Zuschauern eine Gewöhnung herbeiführen, sodass sie über solche Kleinigkeiten (oft unbewusst) hinwegsehen. Mehren sich jedoch in einem Video starke Störungen der Lippensynchronität oder werden zu extrem (wenn etwa die Stimme eines Charakters für Sekunden zu hören ist, während dessen Lippen bewegungslos bleiben), so mindert das die vom Zuschauer wahrgenommene Qualität drastisch.
Computer übersetzen lippensynchron
Das bereits vorgestellte Encoder-Decoder-Modell kann Übersetzungen erzeugen, die anschließend lippensynchron eingesprochen werden können, wenn man es an einer entscheidenden Stelle erweitert: Im unteren Teil der Abbildung 5 ist der von uns entwickelte “dubbing estimator” eingezeichnet, der während des automatischen Übersetzens die Abwägung zwischen möglichst quellentreuer Übersetzung und möglichst gut passender Lippensynchronität vornimmt.
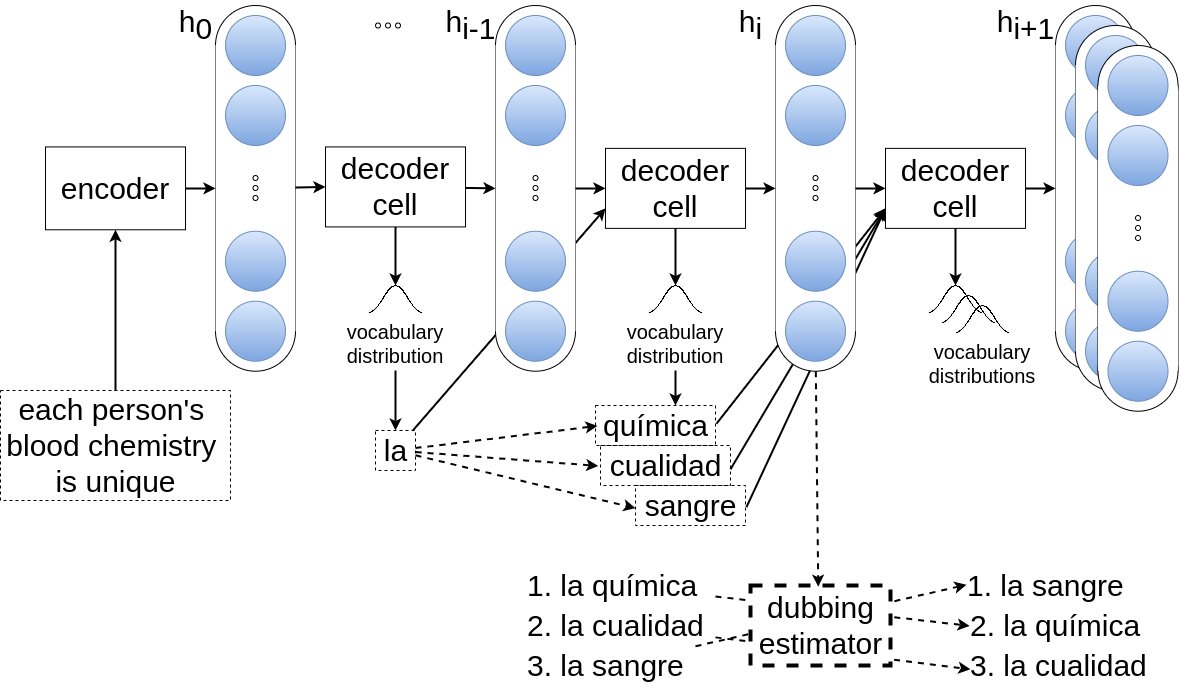
Abbildung 5: Die Encoder-Decoder-Architektur, erweitert um eine Komponente (“dubbing estimator”), die die Synchronsprechbarkeit der Übersetzung verbessert.
Er betrachtet dazu einerseits die Sprechdauer und Silbenzahl in der Quellsprache und gleicht diese mit der geschätzten Dauer und Silbenzahl in der Zielsprache ab. Andererseits tariert er Ergebnisse einer Videoanalyse der Gesichtsbewegungen (und ob der Sprecher überhaupt sichtbar ist) mit den erwarteten Bewegungen beim Aussprechen der Übersetzung aus. Dabei ist es nützlich, dass die Gesichtsmuster (Viseme) weniger streng sind als die Laute: P, B und M sehen im Video praktisch gleich aus.
Der Encoder des Systems bleibt unverändert und ist deshalb in der Abbildung nicht extra dargestellt. Beim Decoding wird dann allerdings nicht bloß das jeweils wahrscheinlichste nächste Wort der Übersetzung erstellt, sondern mehrere, und davon ausgehend wieder mehrere wahrscheinlichste nächste Worte. Die sich ergebenden Wortfolgen sortiert das Modell nach der geschätzten Übersetzungsgüte: das beste zuerst, die schlechteren auf den hinteren Plätzen. Der Dubbing Estimator berechnet nun für jeden Kandidaten die Synchrongüte und gewichtet diese beiden Maße miteinander. Schlecht passende Übersetzungen landen auf den hinteren Plätzen, um einen möglichst guten Kompromiss zwischen Übersetzungs- und Synchrongüte zu erzielen.
Wir haben unsere Experimente mit englisch-spanischen Daten ausgeführt, weshalb das Beispiel spanische Worte zeigt. Man kann erkennen, dass “la química” und “la cualidad” zwar erst einmal bessere Übersetzungen wären, jedoch im Zusammenspiel mit der Synchrongüte hinter “la sangre” zurückbleiben. So ergibt sich die relativ synchron sprechbare Übersetzung “La sangre da cada indivíduo es único, como una huella”. Auch im Spanischen ist es also günstig, die “blood chemistry” zu verkürzen, um ausreichend Zeit für “de cada indivíduo es único” zu schaffen.
Ausblick
Das hier exemplarisch Gezeigte ist Gegenstand der aktuellen Forschung im Feld der Sprachtechnologie. Die Wissenschaft geht derzeit noch Fragen nach wie: Welche Gewichtung der einzelnen Faktoren wie Übersetzungsgüte und Synchrongüte führt zu einer Optimierung der Gesamtqualität? Ab welchem Punkt genau merken Menschen überhaupt, dass die Lippensynchronität nicht mehr perfekt ist?
Außerdem gilt es zu bedenken, dass die Sprachen der Welt sich so sehr unterscheiden und diese Problemstellung so komplex ist, dass ein einziges Modell dem nicht gerecht werden kann. Folglich gilt es, für die verschiedenen Paare von Sprachen, zwischen denen übersetzt werden soll, eigene Modelle zu trainieren. (jcb/jlu)
Die Autoren
Timo Baumann ist Professor für Künstliche Intelligenz mit dem Schwerpunkt Natural Language Processing an der Fakultät für Informatik und Mathematik an der OTH Regensburg. Seine Forschungsschwerpunkte sind sozial und interaktiv adäquat interagierende konversationale Agenten, Prosodieverarbeitung und automatisches lippensynchrones Dubbing. Christian Schuler studiert derzeit Informatik im Master of Science an der Universität Hamburg. Seine Bachelor-Thesis handelte von der Erfassung von wahrgenommener Qualität der Lippensynchronität bei audiovisuell übersetztem Material.
Infos
- “Computing Machinery and Intelligence” (Turing, 1950): https://academic.oup.com/mind/article/LIX/236/433/986238





