
© Mikhail Laptev / 123RF.com
Zum 25-jährigen Jubiläum des Programmier-Snapshots greift Mike Schilli ein altes Problem noch einmal auf und löst es statt mit Perl nun mit Go.
Hurra! Mit dieser Ausgabe wird der Programmier-Snapshot 25 Jahre alt! Im Oktober 1997 erschien die erste Ausgabe im Linux-Magazin, damals noch unter dem Titel “Perl-Snapshot”. Doch die Zeiten haben sich geändert, mittlerweile kommen die Programmierbeispiele hauptsächlich in Go, aber auch Ruby, Python oder wie sogar letztens TeX sind keine Tabuthemen.
Zu diesem Dinosaurier-Jubiläum dachte ich mir, ich könnte ein damals zu Dot-Com-Zeiten in Perl zusammengeklopftes Tool aus heutiger Sicht nochmals in Go schreiben. Den Foto-Tagger aus dem Jahr 2003 (er hieß Image Database [1] oder kurz Idb) habe ich mir schon lange wieder gewünscht. Den Ur-Artikel dazu finden Sie als HTML im Download-Bereich zu diesem Beitrag.
Das Tool Idb weist einer Reihe von Fotodateien auf der Platte eines oder mehrere Tags zu. Später fieselt es zu einem gegebenen Tag wieder die damit markierten Fotos heraus. Nun hatte ich aber weder Zeit noch Lust, durch die Installations- und Abhängigkeitshölle aller dafür benötigten Perl-Module zu gehen. Zudem ist seither viel Zeit vergangen, und manch ein Entwickler eines CPAN-Moduls hat mittlerweile bedenkenlos alte Programmierschnittstellen über Bord geworfen. Außerdem kann Go im Jahr 2022 statische Binaries kompilieren, die ohne Heckmeck überall laufen, bis in alle Ewigkeit.
Auch nutzte das Skript damals einen MySQL-Server, und heute mag ich – zumindest für Tools, die nur lokal laufen – lieber alles aus einem Guss, etwa aus einer SQLite-Flatfile-Datenbank. Dank neuer Technik ging der Rewrite bemerkenswert flott von der Hand.
SQLosaurus Rex
SQL-Datenbanken sind heutzutage etwas aus der Mode gekommen. Wer nur einen Key-Value-Store für seine Daten braucht, nimmt eher einen persistenten Cache oder eine Server-Lösung wie Redis. Für lokale Daten, deren Umfang wohl kaum ein paar Megabyte überschreitet, lohnt sich allerdings kein extern laufender Prozess, und den binären Daten in Caches sowie Key-Value-Stores wie BerkeleyDB traue ich eher nicht blind. Lieber nehme ich sie direkt von Zeit zu Zeit persönlich in Augenschein. SQLite als Datenbank ist ideal, da es die Daten in einer einzigen Datei ablegt, in der ein Kommandozeilentool wie Sqlite3 zum Herumstöbern einlädt. Zudem geht das Backup einer Einzeldatei einfacher von der Hand, als den Dump einer laufenden Datenbank zu erzeugen und zu archivieren.
Überdies ist SQLite eines der wenigen Open-Source-Tools, das wirklich in der Public Domain liegt. So darf zum Beispiel ein Go-Modul auf Github wie »mattn/go-sqlite3« einfach den SQLite-Quellcode mit beipacken. Go macht aus SQLite, der Library und der Applikation dann ein einziges Binary, das man beliebig auf andere Rechner mit ähnlicher Architektur kopieren kann und das dort ohne Murren läuft. Das Ende der Abhängigkeitshölle – dass wir das noch erleben dürfen! Bei der Installation zumindest; beim erneuten Kompilieren sieht es unter Umständen anders aus.
Drei Tabellen
Welches relationale Datenmodell eignet sich nun für die Anwendung eines Foto-Taggers? Das Tool weist einer oder mehreren Dateien ein oder mehrere Tags zu. Für solche Many-to-many-Relationen hat sich seit der Steinzeit der Datenverarbeitung das Modell mit drei Tabellen als nützlich erwiesen: Zwei Tabellen, um den Namen von Tags sowie Dateipfaden Indexnummern zuzuweisen, die dann eine dritte, zweispaltige Tabelle einander zuordnet, wenn an einer bestimmten Datei ein bestimmtes Tag klebt.
Auf diese Weise muss die Datenbank den vollen Tag- oder Dateinamen jeweils nur einmal speichern, eine Grundvoraussetzung einer normalisierten Datenbank. Das hat Vorteile, die über den sonst verschwendeten Speicherplatz für Duplikate hinausgehen: Verbessert der Benutzer zum Beispiel einen Tippfehler in einem Tag, muss ihn die Datenbank nur an einer Stelle korrigieren, selbst wenn das Tag an Tausenden von Dateien klebt.
Um zum Beispiel die Fotodatei »dsc13.jpg« mit dem Tag »surfing« zu versehen (Abbildung 1), erzeugt das Tool erst einmal, falls noch nicht vorhanden, einen neuen Eintrag für das Tag »surfing« in der Tabelle »tag« (links in der Abbildung). Die zugehörige laufende Indexnummer 2 weist SQLite dem Eintrag automatisch zu, da die Einträge bei Index 0 starten und »surfing« der dritte Eintrag in der Spalte »name« ist. Außerdem muss der Dateiname »dsc13.jpg«, falls dort noch nicht vorhanden, in die Tabelle »file« wandern – in der Abbildung landet er in der dritten Reihe und trägt dort die ab 0 aufsteigende Indexnummer 2.
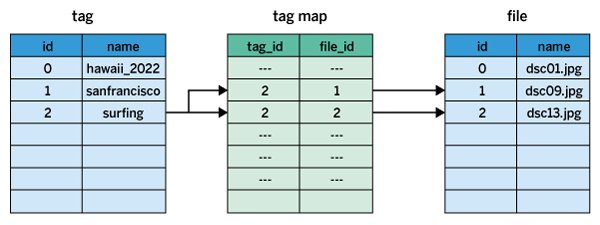
Abbildung 1: Das SQL-Datenbankschema für den Foto-Tagger.
Soweit die beiden Lookup-Tabellen. Nun fehlt noch die eigentliche Zuweisung des Tags zum Foto. Die übernimmt ein Eintrag in der (mittleren) Tabelle »tagmap«, die die Tag-ID 2 der File-ID 2 zuweist. Fertig! Mittels der unter SQL üblichen Joins ist es der Datenbank anschließend ein Leichtes, die Frage zu beantworten, welche Fotos mit »surfing« getaggt wurden. Eine entsprechende Anfrage spuckt ohne Fisimatenten (unter anderem) die Datei »dsc13.jpg« aus. Ebenfalls leicht findet die Query-Engine heraus, welche Tags am Foto »dsc13.jpg« kleben, auch dies durch einen Join der Tabellen.
Nach Hausmacherart
Das Binary »idb«, aus den Go-Quellen dieses Artikels zusammengelinkt, kann die in der Tabelle “Kommandos” aufgelisteten Befehle ausführen. Unterstützt werden das Ankleben von Tags an Dateien, die Suche nach Dateien mit einem bestimmten Tag und das Auflisten aller Tags. Als besonderes Schmankerl generiert die Option »–xlink« für gefundene Dateien zu einem bestimmten Tag ein Verzeichnis voller Symlinks, die auf die Originalfotos verweisen. Mit einem Werkzeug wie dem letztens vorgestellten Inuke [2] lassen diese sich anschließend betrachten und die besten herausfiltern.
|
»idb –tag=foo image.jpg …« |
Fotos mit dem Tag “foo” versehen. |
|
»idb –tag=foo« |
Fotos mit dem Tag “foo” suchen. |
|
»idb –tag=foo –xlink« |
Fotos mit dem Tag “foo” suchen und lokalen Symlink erzeugen. |
|
»idb –tags« |
Alle Tags auflisten. |
Aus einem Guss
Wie funktioniert das Tool Idb nun? Zuerst nimmt es Kontakt zur Tag-Datenbank auf, die in der Datei ».idb.db« im Home-Verzeichnis liegt. Falls Idb dort noch keine Datenbank findet, legt es eine neue an. Dazu dienen die SQL-Kommandos in »createDBSQL()« ab Zeile 23 in Listing 1.
Listing 1
dbinit.go
package main
import (
"database/sql"
_ "github.com/mattn/go-sqlite3"
"os"
"path"
)
const DbName = ".idb.db"
func dbInit() (*sql.DB, error) {
homedir, err := os.UserHomeDir()
if err != nil {
return nil, err
}
dbPath := path.Join(homedir, DbName)
db, err := sql.Open("sqlite3", dbPath)
_, err = db.Exec(createDBSQL())
return db, err
}
func createDBSQL() string {
return `
CREATE TABLE IF NOT EXISTS tag (
id INTEGER PRIMARY KEY,
name TEXT UNIQUE
);
CREATE TABLE IF NOT EXISTS tagmap (
tag_id INTEGER,
file_id INTEGER,
UNIQUE(tag_id, file_id)
);
CREATE TABLE IF NOT EXISTS file (
id INTEGER PRIMARY KEY,
name TEXT UNIQUE
);`
}
Einige SQLite-Besonderheiten in den drei Tabellendefinitionen erleichtern später die Arbeit beim Einfügen. Die Tabellen »tag« und »file«, die den Tag- und Dateipfaden numerische IDs zuordnen, definieren als erste Spalte »id« einen Integer mit dem Attribut »primary key«. Das veranlasst SQLite dazu, die IDs neuer Einträge stetig um eins hochzuzählen – ideal, um sie später kurz und bündig eindeutig per ID zu referenzieren.
Der »unique«-Specifier in der String-Spalte zur Rechten für die Namen von Tags oder Dateien bestimmt, dass die Tabelle keine Namensduplikate zulässt. Als praktischen Nebeneffekt kann das Tool später mit »insert or ignore« in einem Rutsch Einträge erstellen, falls diese bislang noch nicht existieren, und bestehende dort ohne Murren belassen.
Listing 2
db.go
package main
import (
"database/sql"
"fmt"
_ "github.com/mattn/go-sqlite3"
)
func name2id(db *sql.DB, table string, name string) (int, error) {
query := fmt.Sprintf("INSERT OR IGNORE INTO %s(name) VALUES(?)", table)
stmt, err := db.Prepare(query)
panicOnErr(err)
_, err = stmt.Exec(name)
panicOnErr(err)
id := -1
query = fmt.Sprintf("SELECT id FROM %s WHERE name = ?", table)
row := db.QueryRow(query, name)
_ = row.Scan(&id)
return id, nil
}
func tagMap(db *sql.DB, tagId, fileId int) {
query := "INSERT OR IGNORE INTO tagmap(tag_id, file_id) VALUES(?, ?)"
stmt, err := db.Prepare(query)
panicOnErr(err)
_, err = stmt.Exec(tagId, fileId)
panicOnErr(err)
return
}
func tagSearch(db *sql.DB, tagId int) ([]string, error) {
result := []string{}
query := `
SELECT file.name FROM file, tagmap
WHERE tagmap.tag_id = ?
AND file.id = tagmap.file_id;`
rows, err := db.Query(query, tagId)
if err != nil {
return result, err
}
for rows.Next() {
path := ""
err = rows.Scan(&path)
if err != nil {
return result, err
}
result = append(result, path)
}
return result, nil
}
func tagList(db *sql.DB) {
query := `SELECT name FROM tag`
rows, err := db.Query(query)
panicOnErr(err)
for rows.Next() {
tag := ""
err = rows.Scan(&tag)
panicOnErr(err)
fmt.Printf("%s\n", tag)
}
return
}
Name zu Nummer
Die Funktion »name2id« in Listing 2 tut genau das: Sie nimmt einen Namen entgegen, entweder einen Datei- oder einen Tag-Namen, und fügt ihn in die Lookup-Tabellen »file« oder »tag« ein, je nachdem, worauf der Parameter »table« gesetzt ist. Existiert der Name noch nicht, hängt ihn das »insert«-Kommando in Zeile 10 unten an die Tabelle an, und SQLite generiert dazu automatisch einen bislang ungenutzten Index-Integer »id«.
Nach der Vorbereitung des Statements mit »Prepare« in Zeile 11 fügt »Exec()« in Zeile 14 den Namen »name« gegen SQL-Injections gesichert in das SQL-Kommando ein und führt es aus. Existiert die Datei oder das Tag schon in der Datenbank, passiert dank »or ignore« gar nichts.
Die anschließende Abfrage des Namens mit »select« ab Zeile 19 sucht denselben Eintrag wieder und gibt die dazugehörige »id« zurück, wenn Zeile 21 die einzige Ergebnisreihe abholt. Die Funktion »name2id()« ist also nichts anderes als eine bequeme, persistente Methode, Namen numerischen IDs zuzuordnen und letztere auf Anfrage zurückzugeben.
Mit den Indexnummern für Tag und Datei kann »tagMap()« ab Zeile 26 ein Tag an eine Datei kleben, indem es mit »insert« eine neue Tabellenzeile mit den beiden Nummern anhängt. Falls die Datei das Tag schon trägt, sorgt »or ignore« wie vorher für Ruhe im Karton.
Aus drei mach eins
Um nun alle Dateien mit einem Tag zu suchen, muss die »select«-Anweisung in der Funktion »tagSearch()« ab Zeile 35 alle drei Tabellen kombinieren. Das gesuchte Tag in »tag« weist eine Indexnummer auf, die »tagmap« der Indexnummer einer Datei zuordnet. Deren Name wiederum steht unter einem Index in der Tabelle »file«.
Da das gesuchte Tag wegen des vorhergehenden Aufrufs von »name2id()« bereits als Indexnummer vorliegt, obliegt es der Query, eine Bedingung zu definieren, die die zwei Tabellen »tagmap« und »file« zu einer zusammenschweißt. Dabei muss die »file_id« der Tabelle »tagmap« mit der »id« der Tabelle »file« übereinstimmen. Die Namen der ab Zeile 46 hereinpurzelnden Dateitreffer hängt Zeile 52 an die Variable »result« an, einen Slice von Strings, den die Funktion am Ende an den Aufrufer zurückreicht.
Die letzte Funktion in Listing 2, »tagList«, listet schließlich alle in der Tabelle »tag« gefundenen Tag-Namen auf, nachdem SQLite sie mit dem Kommando »select« ab Zeile 59 extrahiert hat.
Das Hauptprogramm in Listing 3 schließlich verarbeitet Flags wie »–tag« (Tag setzen oder abfragen) oder »–tags« (Tags auflisten), die der Anwender dem Aufruf auf der Kommandozeile mitgibt. Es öffnet in Zeile 23 die Datenbank, wobei »dbInit()« die SQLite-Datei neu anlegt, falls sie noch nicht existiert. Sollten auf ein »–tag=…« keine Dateien folgen, holt Zeile 40 mit »tagSearch()« alle passenden Dateipfade aus der Datenbank, und die For-Schleife ab Zeile 42 gibt sie aus. Ist zudem »–xlink« gesetzt, erzeugt Zeile 44 jeweils einen Symlink zur Fotodatei im gegenwärtigen Verzeichnis. So lassen sich Kollektionen von Fotos mit identischen Tags in einem temporären Verzeichnis anlegen, ansehen und verarbeiten.
Listing 3
idb.go
package main
import (
"flag"
"fmt"
"os"
"path"
"path/filepath"
)
func main() {
flag.Usage = func() {
fmt.Printf("Usage: %s --tag=tagname photo ...\n", path.Base(os.Args[0]))
os.Exit(1)
}
tags := flag.Bool("tags", false, "list all tags")
xlink := flag.Bool("xlink", false, "create links in current dir")
tag := flag.String("tag", "", "tag to assign/search")
flag.Parse()
db, err := dbInit()
panicOnErr(err)
defer db.Close()
if *tags {
tagList(db)
return
}
if tag == nil {
flag.Usage()
}
tagId, err := name2id(db, "tag", *tag)
panicOnErr(err)
if flag.NArg() == 0 {
matches, err := tagSearch(db, tagId)
panicOnErr(err)
for _, match := range matches {
if *xlink {
err := os.Symlink(match, filepath.Base(match))
panicOnErr(err)
}
fmt.Println(match)
}
} else {
for _, file := range flag.Args() {
ppath, err := filepath.Abs(file)
panicOnErr(err)
fileId, err := name2id(db, "file", ppath)
panicOnErr(err)
fmt.Printf("Tagging %s with %s\n", ppath, *tag)
tagMap(db, tagId, fileId)
panicOnErr(err)
}
}
}
func panicOnErr(err error) {
if err != nil {
panic(err)
}
}
Hat der Benutzer der Tag-Angabe eine oder mehrere Dateien mitgegeben, klebt der Else-Zweig ab Zeile 49 die Tags an die Dateien. Dazu fügt Zeile 53 mit »name2id« den Namen der Fotodatei erst einmal in den Index ein (falls sie dort nicht schon liegt) und ruft dann mit der damit erhobenen Indexnummer in Zeile 58 »tagMap()« auf, was die Relation in der Tabelle »tagmap« herstellt.
Zur Fehlerbehandlung nutzen die Listings wie üblich »panicOnErr()« (ab Zeile 64), was mit Fehlern kurzen Prozess macht und das Programm abbricht. In Produktionssoftware behandelt man Fehler stattdessen meist durch Rückgabe in höhere Ebenen.
Die ganze Chose kompilieren Sie, unter Einbinden aller referenzierten Github-Pakete, mit den Kommandos aus Listing 4. Es entsteht das Binary »idb«, das alle vorgestellten Funktionen aus dem Effeff beherrscht.
Listing 4
Binary erzeugen
$ go mod init idb $ go mod tidy $ go build idb.go db.go dbinit.go
Ausblick
Das Tool Idb weist Fotos Tags zu, ließe sich aber auch anderweitig zum Markieren von Einträgen im Dateisystem einsetzen, etwa für wichtige Konfigurationsdateien, deren Pfade man immer vergisst, oder die in den Untiefen der Verzeichnishierarchie zuletzt bearbeiteten Videodateien. Einmal getaggt, fördert Idb sie bei Bedarf blitzschnell wieder zutage.
Das Werkzeug lässt sich zudem einfach erweitern. Wie wäre es mit einer Tabelle von Metadaten, die zu allen Fotos deren GPS-Koordinaten abspeichert? Oder eine Transaktionstabelle, die es erlaubt, versehentlich getaggte Bilder durch »–undo« wieder von den Tags zu befreien? Wie immer sind der Kreativität bei selbst geschriebenen Tools keine Grenzen gesetzt. (uba/jlu)
Infos
- Perl-Snapshot: Mike Schilli, “Digitale Plattenkamera”, LM 04/2003, S. 112, https://www.lm-online.de/3495
- Snapshot: Mike Schilli, “Die Schlechten ins Kröpfchen”, LM 11/2021, S. 86, https://www.lm-online.de/44800





