
© Dmitrii Shironosov / 123RF.com
Diesen Fehler mache ich kein zweites Mal, nimmt man sich vor, und lernt dabei aus Erfahrung. Übersetzt man die Erfahrungen in Daten, können Computer das auch: Sie verbessern sich, ohne dass ein Programmierer ihnen jeden Schritt vorgibt.
Im Mai 2022 schrieb mich eine nette Person des Linux-Magazins an und fragte, ob ich einen kurzen Artikel zu der Frage “Was ist maschinelles Lernen?” als Einstieg für die Ausgabe im August schreiben könnte. Nach einigen kurzen Rückfragen habe ich zugesagt, wie Sie hier sehen können. Ich versuche, das Anliegen kreativer umzusetzen, als lediglich den ausführlichen englischen Wikipedia-Artikel durch den Übersetzungsdienst DeepL zu jagen und dann zu kürzen. Das wäre nämlich eine erste Antwort gewesen: Maschinelles Lernen – darauf basiert DeepL – ist ein Ansatz, um günstig Vorlagen für Artikel im Deutschen zu erzeugen.
Da wir uns jetzt schon ein paar Zeilen kennen, erlauben Sie mir eine etwas persönliche Frage: Haben Sie beim Lesen der Eingangszeilen einen Mann oder eine Frau aus dem Redaktionsteam des Linux-Magazins vor Ihrem geistigen Auge gesehen? Zweite Frage: Egal, wer es war – können Sie sich vorstellen, warum? Die meisten von uns setzen beim Lesen aus ihren Erfahrungen Bilder zusammen. Da Sie keine Informationen hatten, nutzte Ihr Gehirn die Erfahrungen, die es zusammen mit Medien allgemein oder dem Linux-Magazin im Speziellen hatte oder glaubte zu haben.
Sie nutzen also Erfahrung, um auf neue unbekannte Situationen zu schließen, und Sie tun das andauernd, ohne dass es besonders auffällt. Selbstverständlich klappt das nicht immer, aber das ist oft auch kein Problem. Maschinelles Lernen zielt darauf ab, Computern ebenfalls die Fähigkeit zu geben, aus Erfahrungen zu lernen und zu verallgemeinern. Erfahrungen sind bei Computern Daten, und Lernen hat hier nichts mit Bewusstsein oder Intelligenz im engeren Sinne zu tun. Es geht um das Erlangen und gegebenenfalls das Verbessern von Fähigkeiten aus Erfahrungen, ohne darauf klassisch programmiert zu sein.
So oder so ähnlich hat es Arthur L. Samuel schon 1959 definiert, und ich denke, an dem Datum erkennt man, was maschinelles Lernen nicht ist: Es ist kein klassisches Buzzword. Es handelt sich um eine für die Informatik recht alte Disziplin, die nah an die Mathematik gebaut ist, was ihr zu Unrecht ein gewisses Schreckenspotenzial für Studierende und Anwender gibt.
Wir tasten uns zunächst einmal heran, indem wir drei Hauptvarianten maschineller Lerntechniken unterscheiden: Es gibt im Wesentlichen das überwachte, das unüberwachte und das bestärkende Lernen. Dazu kommen ein paar Spielarten wie semiüberwachtes Lernen und so weiter, aber das lassen wir heute einmal weg. Der Unterschied zwischen den drei Hauptvarianten liegt primär in der Art, wie Erfahrungen zur Verfügung gestellt werden.
Überwachtes Lernen
Beim überwachten Lernen müssen Paare aus einem gewünschten Input X und Output Y vorliegen. Beispielsweise kann es sich bei X um Bilder von Tieren handeln, sagen wir Hund(1), Katze(2), Maus(3) und Elefant(4). Die Zahlen dahinter sind dann die Y-Werte, die Menschen vorher für eine gewisse Anzahl an Bildern vergeben haben müssen. Anhand dieser Datenbank aus Beispielen können Sie das Lernen überwachen und ein Ziel vorgeben. Der Computer lernt dann eine Funktion f:X->Y, die jedem hereinkommenden Bild eine der vier Klassen zuweist.
Die Menge an Bildern, die für das Training verwendet wird, heißt naheliegenderweise Trainingsmenge. Idealerweise kann der Computer am Ende des Trainings jedes Bild aus dieser Menge der korrekten Klasse zuordnen. Aber eigentlich ist das kein Mehrwert, denn diese Klassenzuordnung kannten wir ja vorher schon. Es geht um das Generalisieren, also die Fähigkeit, mit neuen Beispielen umzugehen. Wie verlässlich so eine Funktion (beim maschinellen Lernen nennt man sie in der Regel ein Modell) ist, findet man dadurch heraus, indem man dem Modell eine Reihe von neuen Beispielen (in unserem Beispiel Bildern) zeigt und dabei testet, wie gut es auf dieser Menge funktioniert.
Da wir das Modell auf dieser Menge testen, heißt sie Testmenge. In jeder öffentlichen Diskussion oder Schulung stellen die Teilnehmer an dieser Stelle üblicherweise eine der beiden folgenden Fragen, manchmal auch beide: Wie viele Datenpaare braucht man für ein erfolgreiches Training und wie viele für einen aussagekräftigen Test? Allerdings gehen beide Fragen von einer falschen Voraussetzung aus. Es geht nicht primär um die Anzahl von Beispielen oder die Größe der Datenbank in Giga- oder Terabyte – es geht vielmehr um Information.
Wenn Sie im obigen Beispiel ausschließlich die Hunde aus der benachbarten Dackelzucht aufgenommen haben und für die Trainings- und Testmenge verwenden, fällt das Ergebnis einfach nicht so gut aus. Egal, wie oft diese Tiere aus welchen Winkeln und bei welchen Aktionen abgebildet wurden: Das Modell hat in diesem Fall nie einen Husky oder eine Dogge gesehen. Selbstredend ist beim Umgang mit Daten mehr wünschenswerter als weniger, aber es kommt auf eine gute repräsentative Mischung an.
Das gilt, wenn es um kritische Anwendungen geht, gerade auch für die Testmenge. Was nicht enthalten ist, kann nicht getestet werden. Keine Panik: Bei vielen Modellen kann man das Lernen aus Beispielen mit dem Domain-Wissen kreuzen, um mit dem Unbekannten umzugehen, aber das ist dann schon schwieriger und klappt nicht überall. Halten wir also einmal fest, dass wir für das überwachte Lernen Datensätze brauchen, die Menschen bereits aufgewertet haben, und dass dabei zwar mehr besser ist als weniger, aber es letztlich auf die Mischung ankommt (Abbildung 1).

Abbildung 1: Wo es einen Lehrer gibt (und sei es im übertragenen Sinn), der die richtigen Antworten kennt und den Schüler korrigieren kann, da handelt es sich um überwachtes Lernen. Gelernt wird aus Beispielen anhand vom Lehrer als richtig oder falsch bewerteter Antworten. Quelle: Ian Allenden / 123RF.com
In unserem Beispiel haben wir übrigens eine der beiden Hauptarten von überwachten Aufgaben im Kopf durchgespielt, die Klassifikation. Daneben gibt es noch die Regression. In gewisser Weise liegt der Unterschied primär in dem Raum, in dem man bei der Funktion f:X->Y abbildet. Wenn Y diskret ist, also nur wenige einzelne Elemente enthält (Hund, Katze, Maus, Elefant), dann liegt eine Klassifikation vor. Ist Y kontinuierlich, steht also zum Beispiel für einen Kreditrahmen, eine Temperatur, eine Wahrscheinlichkeit und so weiter, dann ergibt sich eine Regression. Mathematisch geht es übrigens immer irgendwie um ein Optimierungsproblem auf stochastischen Daten. Der Grund ist, dass man die Fehler quasi aufsummiert und diese Summe selbstverständlich klein halten möchte.
Unüberwachtes Lernen
Jetzt kommen wir zum unüberwachten Lernen. Dabei liegt keine Zielinformation im Sinne von (x,y)-Paaren vor. Wir haben nur die Beispiele X selbst. Was kann man damit wohl machen? Mehr, als man vielleicht glaubt.
Das unüberwachte Lernen ist ausschließlich darauf angewiesen, direkt mit den Strukturen zu arbeiten, die in den Beispielen vorliegen. Eine der häufigsten Anwendungen besteht darin, diese Beispiele zu clustern (Abbildung 2). Man bildet also Gruppen auf der Basis der Ähnlichkeit der einzelnen Beispiele. Damit ein Computer das erledigen kann, muss man die Ähnlichkeit allerdings sauber im Sinne einer Abstandsfunktion definieren – Mathematiker sprechen da von einer Metrik. Hat man eine solche festgelegt, kann es losgehen, und die Algorithmen des maschinellen Lernens bilden beispielsweise Gruppen aus den Daten über Kunden oder Benutzer.
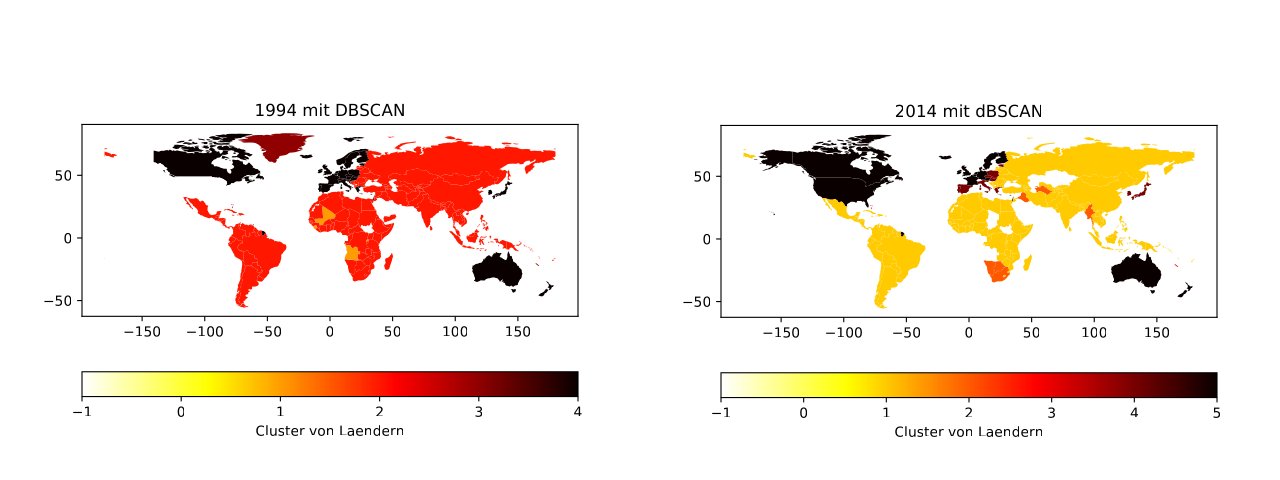
Abbildung 2: Eine unüberwachte Einteilung von Ländern 1994 und 2014 in Cluster. Weiß dargestellte Länder stellen Ausreißer dar, die zu keinem Cluster gehören. Wie man sieht, verliert die USA in dieser Einteilung die Sonderrolle als Ausreißer, und die EU wird durch die Nachwirkungen der Finanz- und Wirtschaftskrise 2008/2009 in zwei Gruppen aufgespaltet.
Was hat man nun davon, Gruppen zu bilden? Zum einen könnte man sie für Kauf- oder Produktempfehlungen benutzen. Für viele Anwendungen braucht man keine definierte Klasse im Sinne eines überwachten Lernens. Schafft man es, Personen mit einem ähnlichen Verhalten in Gruppen einzusortieren, kann man von einer auf eine andere schließen und damit etwa Empfehlungssysteme aufbauen.
Man könnte auch ganz klassisch durch die verschiedenen Brillen von Fachdisziplinen auf die entstandenen Gruppen sehen und sie analysieren. Das hieße, das unüberwachte Lernen quasi als Zwischenschritt in einem wissenschaftlichen Verfahren zu nutzen und eine alternative Taxonomie von einem Computer vorschlagen zu lassen. Ein Beispiel für eine Taxonomie ist die Einteilung von Sprachen in Familien, mit Beziehungen untereinander.
Oft ist aber auch das Gegenteil von Gruppenbildung interessant. Man lässt Gruppen bilden, interessiert sich jedoch gar nicht für diese, sondern vielmehr für die Ausreißer. Verwendet man Verfahren, die solche Ausreißer zulassen, dann kann man sich die Einzelgänger hinterher genauer ansehen. Eine typische Anwendung wäre die Erkennung von Sicherheitsverletzungen und Betrugsversuchen.
Wenn sich in einem System jemand völlig anders verhält als die anderen, ist das vielleicht verdächtig. Wenden Sie dieses Verfahren auf die User von Computersystemen an, merken Sie sofort, warum man so etwas nur als ersten Filter verwenden sollte und nicht als Automatik: Typischerweise machen sich hier die Personen mit administrativen Rechten als Erste verdächtig. Sie benehmen sich anders, arbeiten zu ungewöhnlichen Zeiten und wuseln in anderen Dateien herum. Wirklich interessant wird es erst abseits solcher erwartbaren Ausreißer.
Bestärkendes Lernen
Aus der Sicht eines Computerprogramms stellt man sich beim überwachten und unüberwachten Lernen am besten eine Funktion vor, die einem Input einen Output, eine Klasse, einen Wert oder Cluster zuordnet. Dagegen ist die beste Näherung beim bestärkenden Lernen eher ein Objekt mit Methoden, nämlich ein Agent, also eine Software, die autonom in ihrer Umgebung agiert. Dabei kann eine Umgebung die Realität sein und der Agent ein Roboter, es kann sich aber auch um einen Bot im World Wide Web handeln oder Ähnliches. Dieser Agent agiert gemäß einer Strategie, die im Englischen Policy heißt und daher in der Literatur oft mit dem griechischen Buchstaben Pi abgekürzt wird.
Da es um maschinelles Lernen geht, wird ihm diese Strategie nicht hart von einem Menschen einprogrammiert, sondern der Agent lernt sie auf der Basis von Daten. Diese Daten liegen in einer anderen Qualität vor als bei den beiden vorangegangen Arten des maschinellen Lernens. Beim überwachten Lernen hat das System quasi gesagt bekommen, wie es richtig geht. Man spricht oft auch davon, dass es durch diese bereits aufbereiteten Daten eine Art Lehrer gibt. Das Gegenteil ist beim unüberwachten Lernen der Fall, wo man mit den vorhandenen Strukturen auskommen muss.
Beim bestärkenden Lernen liegen wir quasi dazwischen und geben dem Agenten ein Feedback (typischerweise als Reward bezeichnet). Er hat das Ziel, einen möglichst hohen Reward, also eine Belohnung, zu erhalten. Das gelingt freilich nicht in einem Schritt – das wäre sehr kurzsichtig –, sondern summiert über die ganze Aufgabe (Abbildung 3). Der Agent bekommt also keine Rückmeldung darüber, wie es richtig geht, sondern lediglich ein Feedback-Signal. Dahinter steht keine Bösartigkeit seitens der Menschen, sondern die schiere eigene Unkenntnis, wie die beste Strategie denn aussehen könnte. Wüsste man das, hätte man sie ja direkt einprogrammiert.
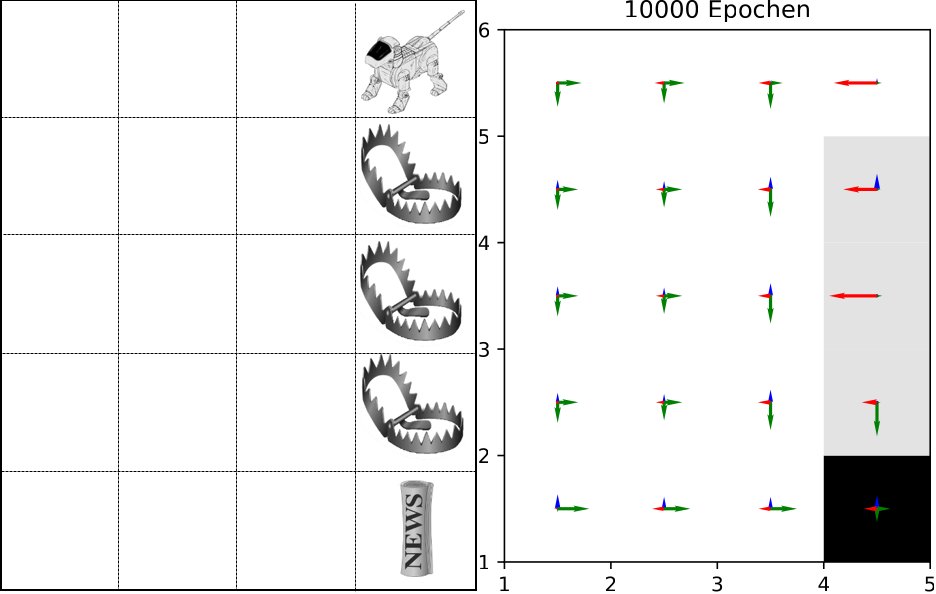
Abbildung 3: Der Agent hat die Aufgabe, in möglichst wenigen Zügen von jedem beliebigen Startpunkt aus die Zeitung zu erreichen. Rechts befindet sich die mit einem elementaren bestärkten Lernansatz gelernte Strategie. Je länger ein Pfeil, desto eindeutiger die Tendenz, in die entsprechende Richtung zu gehen.
Nehmen wir ein Beispiel mit Kindern und Eltern, das leicht unethische Züge annimmt, wenn man es ernst meinen würde. Das Ziel ist ein aufgeräumtes Zimmer, allerdings sagen Sie dem Kind das nicht. Sie geben nur ein Feedback in Form von ungesunder, aber dafür gewünschter Nahrung. Das Gute bei einem Computeragenten: Es wäre egal, ob man Süßigkeiten verteilt (positiver Reward), unterschiedlich starke Ohrfeigen (negativer Reward) oder eine Mischung aus beiden. Wir bleiben aber in unserem Beispiel bei dem weniger gewaltorientierten, aber dafür ungesunden Bild.
Ein wichtiger Aspekt beim bestärkenden Lernen besteht darin, wann man das positive respektive negative Feedback gibt. Sie könnten etwa im Zimmer bleiben und immer, wenn ein Spielzeug vom Fußboden in einen Schrank wandert, ein Schokostück springen lassen. Der Agent / das Kind wird schnell verstehen, dass das ein gewünschtes Verhalten darstellt. Sie könnten aber auch sehr lange kein Feedback geben und ganz am Schluss so viel Schokolade verteilen, wie freie Fläche auf dem Zimmerboden hergestellt wurde. In diesem Fall dauert das Erlernen des erwünschten Verhaltens vermutlich länger.
Soll man also immer möglichst kleinschrittig Feedback geben? So einfach ist es dann doch nicht. Das Ziel des Agenten besteht ja nicht darin, das Zimmer aufzuräumen – er strebt an, einen möglichst hohen summierten Reward zu erhalten. Dazu muss er die beste Strategie für eine möglichst hohe Ausbeute finden. Ihr Ziel ist es hingegen, die beste Strategie für ein reales Problem zu identifizieren. Da besteht oft ein großer Unterschied.
Um einmal ein reales Beispiel zu geben: Stellen Sie sich einen Reinigungsroboter vor, der nicht kräftig gegen Möbel fahren soll. Ob er das tut, stellt ein Bumper an der Vorderseite des Robots fest. Ihr Ziel ist es, Macken an den Möbeln zu vermeiden. Die wahrscheinlichste Lösung besteht aus Sicht des Agenten darin, rückwärts zu fahren, weil der Bumper dann nicht eingedrückt wird und das Problem sich aus seiner Sicht erledigt hat.
Ähnliche ungewollte Effekte können Sie durch zu enge Feedback-Schleifen erreichen. Im Design der Feedback-Schleife liegt nämlich immer Ihr Vorwissen. Wenn das gut ist, klappt vermutlich alles super. Wenn Sie allerdings so genau wüssten, wie die Lösung aussieht, warum haben Sie sie dann nicht direkt sauber erklärt?
Beim Aufräumen eines Zimmers gehen Eltern ja üblicherweise auch einen Weg, der sich eher am überwachten Lernen orientiert: Sie machen es vor beziehungsweise räumen zusammen mit den Kindern auf, einfach, weil sie (glauben zu) wissen, wie es am besten geht. Die hohe Kunst besteht hier oft darin, die richtige Feedback-Funktion zu finden, samt des richtigen Qualitätsmaßes, aus dem sich diese häufig ableitet. Die freie Bodenfläche im Kinderzimmer kommt da eher nicht infrage – oder wollen Sie einfach alle Sachen auf dem Bett wiederfinden?
Übrigens: Auch hier haben wir es mit Optimierung in stochastischen Umgebungen zu tun. Es handelt sich um eine Optimierung, weil das Ziel des Agenten die Maximierung einer Zielgröße ist. Der Begriff stochastisch kommt hinzu, weil aus Sicht des Agenten die Umgebung in der Regel zufällig erscheinende Aspekte aufweist.
Andere Arten zu lernen
Der ein oder andere meint jetzt vielleicht, dass ich wichtige Dinge vergessen habe, lassen sich doch mithilfe von maschinellem Lernen auch Texte und Bilder erzeugen oder verändern. Diese Tätigkeiten lassen sich aber oft auf ein intelligentes Zusammensetzen der drei Haupttechniken zurückführen.
Beispielsweise funktionieren Generative Adversarial Networks (GANs) so, dass ein künstliches neuronales Netzwerk A in der Lage sein sollte, ein echtes Bild eines Hunds von einem falschen respektive Nicht-Hund-Bild zu unterscheiden. Wir geben diesem Netz aus unserem Vorrat manchmal Bilder mit Hunden und manchmal welche, die ein anderes künstliches neuronales Netz (nennen wir es B) erzeugt hat. Hat A sich geirrt, wissen wir das und können diesen Fehler genauso nutzen wie zuvor beim überwachten Beispiel mit Hund, Katze, Maus und Elefant. Konnte A hingegen die Fälschung von B erkennen, wird dieses Versagen wiederum als Fehler für die Optimierung in Netz B eingespeist. Funktioniert das, werden beide Netze immer besser in ihrem jeweiligen Job, nämlich künstliche Bilder zu erzeugen beziehungsweise solche zu erkennen.
Sprache oder Texte lassen sich auf der Basis von neuronalen Netzen mit Gedächtnis erzeugen. Aktuell sind das oft Transformer-Netze, wobei auch Long-Short-Term-Memory-Netze (LSTM) oft einen guten Job machen. Beide Varianten liefern als überwachte Techniken im Prinzip nur Vorhersagen über die Wahrscheinlichkeit, welcher Satzteil, Buchstabe oder welches Wort vermutlich als Nächstes folgt. Durch das Lernen auf sehr großen Sprachkorpora entwickelt sich ein Modell, das angefangene Texte oder Artikel fortsetzen kann.
Es wäre in der Regel auch möglich, so etwas auf der Basis von Stichworten zu implementieren. Lesen Sie also irgendwo, dass jetzt eine künstliche Intelligenz Zeitungsartikel schreibt, dann ist da immer noch keine Intelligenz im Spiel. Es geht schlicht darum, dass es etwa für Sportberichte so viele typische Strukturen gibt, dass es einem Modell leichtfällt, aus wenigen harten Fakten – wer wann ein Tor geschossen hat zuzüglich einiger Besonderheiten – einen typischen Text zu erzeugen. Das spricht eher gegen den Sportteil der Zeitung als für die KI.
Das soll nicht heißen, dass ein trainiertes Modell nichts Neues schaffen kann. Dank der aktuellen Urheberrechtsnovelle von 2021 haben ja sicherlich viele den Begriff Pastiche kennengelernt. Machine-Learning-Systeme sind sehr gut darin, Dinge neu zu kombinieren. Erhalten sie eine positive Rückmeldung darüber, was gut ankommt, können Sie auch schöne Bilder liefern. Gilt es lediglich, den Stil zu imitieren, liefert zum Beispiel ein Neural Style Transfer (Abbildung 4) leichter und stabiler schöne Ergebnisse als ein GAN.

Abbildung 4: Ein Beispiel für Neural Style Transfer: Der Style der Welle vor Kanagawa (Mitte) wird auf den Content (links) übertragen. Das Ergebnis (rechts) hängt davon ab, wie sehr die Optimierung Style und Content-Treue priorisiert.
Es bleibt aber dabei, dass es sich im Wesentlichen um mathematische Funktionen mit In- und Outputs handelt, die sich durch Optimierungsalgorithmen verbessern. Dass sie scheinbar immer mehr Aufgaben erledigen, von denen wir bisher dachten, ein Lebewesen müsste dazu sehr intelligent oder kreativ sein, dürfte mehr darauf schließen lassen, dass wir unsere Begriffe klarer fassen müssen. So handelt es sich bei Intelligenz nicht gerade um ein glasklar definiertes Konzept. Gemessen am einfachsten Ansatz – Intelligenz sei, was ein Intelligenztest misst – sind maschinelle Modelle vermutlich schon bald intelligent.
Auf der International Joint Conference on Artificial Intelligence im Jahr 2019 wurde zum Beispiel eine große Datenbank mit typischen Fragen aus Intelligenztests vorgestellt. Es ist also vermutlich nur eine Frage der Zeit, bis sich die damals noch übersichtlichen Ergebnisse verbessern. Ist es so weit, dürfte sich die Kritik verschärfen, die es an dieser simplizistischen Intelligenzdefinition gibt, und man wird den Begriff vermutlich weiterentwickeln müssen. Wenn die Wissenschaft Glück hat, findet sich eine saubere Definition, die man auch formal fassen kann.
Im Bereich des maschinellen Lernens gibt es einen schon Jahrzehnte andauernden Wettbewerb zwischen genauer, schneller und weiter (mehr Daten). Freilich sind diese Aspekte immer noch wichtig und werden es auch bleiben. Viele aktuelle Fragen ranken sich gerade in Europa aber um andere Themen wie Trustworthy AI, Bestimmung von Unsicherheit, Green AI und andere mehr. Viele Aspekte und Diskussionen um den Begriff Trustworthy AI bündeln sich in den 2021 von der EU veröffentlichten “Ethics Guidelines for Trustworthy AI”. Man kann unter anderem die Themen Privacy and Data Governance, Transparency und Diversity, Non-Discrimination und Fairness als spezifisch europäische Impulse herauslesen. Rund um diese Themen passiert in Europa gerade recht viel.
Es wird immer wieder hinterfragt, ob Europa in Sachen AI – eigentlich ist oft maschinelles Lernen gemeint – mit Konkurrenten wie China und den USA mithalten kann. Die Antwort lautet vermutlich: Das hängt vom Thema ab. Der Ausdruck Green AI wiederum stammt aus einem gleichnamigen Artikel [1], dessen Schlüsselsatz lautet: “The term Green AI refers to AI research that yields novel results while taking into account the computational cost, encouraging a reduction in resources spent.” Bisher wurde also kaum auf den Ressourcenverbrauch geachtet. Lassen sich bei der Unterscheidung verschiedener Klassen ein paar Zehntel Prozentpunkte mehr Genauigkeit erreichen, ist das oft schon eine Veröffentlichung wert. Dabei bleiben die Kosten für das Training und den Betrieb in der bisherigen Tradition weitgehend außen vor.
Wunsch und Wirklichkeit
Am Ende ist auch eine Software, die auf Algorithmen aus dem Bereich des maschinellen Lernens basiert, nur eine Software. Das bedeutet, sie möchte getestet und gewartet werden. Darüber hinaus wäre es wunderbar, wenn es sich um Open Source handeln würde. Das aber schreibt sich leichter, als es umzusetzen ist.
Hinsichtlich des Testens muss man sich klarmachen, dass es sich um eine Software handelt, die sich nicht ohne Weiteres durch klassische Testansätze abdecken lässt. Die Software ist zwar in der Regel selbst deterministisch – man muss also keine Angst haben, dass ein Modell ein und dasselbe Bild manchmal als Hund und manchmal als Katze klassifiziert. Es gibt jedoch viele andere Fallstricke. Beispielsweise konnten in einem realen Versuch [2] zwar alle Wölfe als solche identifiziert werden. Der Versuch, das Modell auf einige Bilder aus einem deutschen Zoo anzuwenden, verlief jedoch deprimierend. In den Trainings- und Testdaten waren viele Bilder von Wölfen, jedoch alle im Schnee. Das System hatte “Schnee” als wesentlichen Faktor für “Wolf” gelernt – kein Schnee, kein Wolf (Abbildung 5). Solche Fehler muss man anders ermitteln als bei einer klassischen Qualitätskontrolle.

abb. 5: Das Bild aus “Why Should I Trust You?” – Explaining the Predictions of Any Classifier, M. T. Ribeiro, S. Singh, C. Guestrin, Proc. of the 22nd ACM SIGKDD, 2016 zeigt, was für die Fehlentscheidung verantwortlich ist.
Der andere Punkt ist: Wie sähe Open Source für Software aus, die auf maschinellem Lernen basiert? Man könnte denken, darum wäre es gut bestellt, da alle verbreiteten Softwarepakete für das maschinelle Lernen wie Scikit-learn, Tensorflow/Keras, PyTorch und so weiter unter einer Open-Source-Lizenz stehen. Das sind jedoch lediglich die Bibliotheken, mit denen man Software baut.
Nehmen wir als Beispiel eine Software an, die ein künstliches neuronales Netz enthält. Die Gewichtungen sind kein Quelltext, der in einer für den Menschen lesbaren und verständlichen Form vorliegt, sondern das Kondensat aus einem Prozess. Will man den Prozess wiederholen, braucht man die Bibliotheken (kein Problem), Informationen über den Aufbau des Netzes (werden oft geliefert), die genauen Parameter für die Optimierung (hier wird es schon dünner) und den Datenbestand, auf dem das Training ausgeführt wurde. An der letzten Position ist in der Regel Schluss, man bekommt die Daten nicht.
Das bedeutet, dass sich in engen Grenzen hält, was man mit einem solchen Netz noch tun kann, wenn es als Teil einer offengelegten Software weitergegeben wird. Es lässt sich zu dem Zweck und genau mit der Qualität weiter nutzen, die zur Verfügung gestellt wurde. Um es zu verbessern, kann man diesen Trainingsstand meist nur im Sinne eines Transfer Learnings verwenden. Transfer Learning bedeutet, dass ein Netz zum Beispiel für viele Bildklassen trainiert wurde.
Ein typisches Beispiel ist die Imagenet-Datenbank, die viele Tiere, Menschen und so weiter enthält. Ein solches Netz kann man inklusive der Werte der Gewichte nehmen und an eine neue Aufgabe anpassen, für die Daten vorliegen. Will man etwa nur südamerikanische Vögel unterscheiden, finden sich nicht alle Arten in Imagenet, aber das Netz hat schon viele nützliche Filter gelernt. Man entsorgt dann den Teil des Netzes, den man nicht gebrauchen kann, und trainiert das zusammengesetzte Netz von dem vortrainierten Stand aus auf die eigene Bildersammlung südamerikanischer Vögel. Dadurch kommt man mit weniger Bildern aus und erreicht vermutlich höhere Genauigkeit bei weniger Energiekosten im Training. Das ist gut und auch recht häufig möglich.
Als eigentliche Idee steht hinter der Forderung nach Open-Source-Software jedoch, dass man sie verändern und in der veränderten (und damit in der Regel verbesserten) Form weitergeben kann. Das ist nicht mehr voll erfüllt. Sind nicht alle Daten verfügbar, beschränkt das auch die Möglichkeit zur Weiterentwicklung, von den zahlreichen Softwarepatenten im Machine-Learning-Umfeld ganz zu schweigen.
Fazit und Ausblick
Maschinelles Lernen gibt es schon lange, aber die steigende Bedeutung allein sollte schon ein Ansporn sein, weiter hinter die Kulissen zu sehen. Nebenbei macht es auch wirklich viel Spaß.
Verfügen Sie beispielsweise über eine große Sammlung von LaTeX-Dokumenten, trainieren Sie damit doch einmal ein LSTM oder Transformer-Netzwerk. Sie können sogar über den Übersetzer eine Feedback-Schleife bauen, damit das System lernt, fehlerfreien LaTeX-Code zu schreiben. Der Inhalt wird sicherlich ein wenig drollig bleiben, aber die Übung ist unterhaltsam.
Hat man dann verstanden, worum es geht, fragt man sich als Open-Source-Enthusiast vielleicht, was diese Technologie für die eigene Bewegung bedeutet. Man erinnere sich hier an das sogenannte ASP-Schlupfloch, das die AGPL schließen sollte. Ich persönlich glaube, dass ein breiter Einsatz von Machine-Learning-Software dazu führen sollte, noch einmal zu überdenken, wie man Open Source hier weiterentwickeln beziehungsweise mit der Idee von Open Data zusammenbringen möchte. Vielleicht kommt man aber auch zu dem Schluss, dass man das gerade nicht will. (jcb/jlu)
Infos
- “Green AI”: https://cacm.acm.org/magazines/2020/12/248800-green-ai/fulltext
- “Why Should I Trust You?”: https://www.kdd.org/kdd2016/papers/files/rfp0573-ribeiroA.pdf





