
© lassedesignen / 123RF.com
Wer bei Paketmanagern an Rpm oder Dpkg denkt, muss in der Kubernetes-Welt umdenken: Dort gibt stattdessen Helm den Ton an. Wir zeigen, wie das Tool im Detail funktioniert und wie Sie als Admin den größten Nutzen daraus ziehen.
Darüber, ob Geschichte sich wiederholt, streiten sich die Gelehrten. Ein oft Mark Twain zugeschriebenes Zitat, wonach Geschichte sich zwar nicht wiederhole, wohl aber reime, gilt mittlerweile als Fälschung, denn es findet sich nirgends in Twains Schriften. Klar ist aber: Der ein oder andere Trend kehrt zurück, mancher technische Ansatz der IT begegnet dem Admin immer wieder – in etwas anderem Gewand und vielleicht unter neuem Namen, doch das Prinzip bleibt dasselbe.
So ähnlich verhält es sich mit Helm (englisch: Ruder, Steuerung): Dabei handelt es sich um eine Art Paketmanager, wie ihn viele Admins von den klassischen Distributionen kennen – Rpm und Dpkg lassen grüßen. Die will Helm aber nicht ersetzen, denn es hat eine völlig andere technische Heimat: Es richtet sich an Kubernetes-Anwender und will das Verteilen von Software für Kubernetes erleichtern. Die allermeisten Admins haben im Kontext von Kubernetes zumindest schon einmal von Helm gehört. Über das Wissen um die Existenz des Werkzeugs reicht bei vielen Admins die Helm-Kenntnis allerdings nicht hinaus. In der Folge kursieren um die Lösung so manche Mythen, und die resultierende Unsicherheit lässt Helm in einem schlechteren Licht dastehen als es verdient.
Dieser Artikel geht im Detail auf Helm ein. Er führt in die Architektur der Lösung ein, beschreibt, wie Helm-Charts funktionieren, und stellt praktische Anwendungsbeispiele vor. Im ersten Schritt geht es jedoch um die Frage, wozu Helm überhaupt taugt und welche Probleme es im Kubernetes-Kontext löst.
Was soll das?
Kubernetes hat in den vergangenen Jahren einen Siegeszug hingelegt, wie es ihn in dieser Geschwindigkeit und Vehemenz in der IT nicht allzu oft gibt. Heute scheint es beinahe unmöglich, Container-Virtualisierung in Linux zur Sprache zu bringen, ohne dabei Kubernetes zumindest zu erwähnen. Das ist freilich kein Zufall, denn anders als manche Beobachter behaupten, haben Kubernetes und Cloud-Computing eine ganze Menge miteinander zu tun. Ohne das Cloud-Computing-Konzept wäre Kubernetes nicht denkbar. Will sagen: Man kann sich heute nicht mehr vorstellen, einen in Container verpackten Workload effizient zu betreiben, ohne sich der Prinzipien des Cloud-Computings zu bedienen – also so, dass man über einen Schwarm von Servern hinweg einzelne Container mit Anwendungen automatisch steuert.
Kubernetes (kurz: K8s) ist mittlerweile aber deutlich komplexer als noch vor ein paar Jahren. Die Menge der fertigen Abbilder von Drittanbietern, aus der Admins die Wahl haben, lässt sich kaum noch überblicken. Auch der Funktionsumfang von K8s selbst wuchs kontinuierlich: Custom Resource Definitions (CRDs), immer neue API-Erweiterungen und diverse architektonische Umbauten tragen dazu bei, dass es schwerfällt, die Übersicht zu behalten. Ganz zu schweigen von den Features, die externe Anbieter dann noch in den Container-Orchestrierer einbringen, um ihr Stück vom Kuchen abzubekommen – mit zum Teil wirklich großartiger Innovation. Mesh-Netzwerke etwa wie Istio sichern den Netzwerkverkehr zwischen den Mikrokomponenten einer Anwendung, kümmern sich um das Load Balancing und bieten auch noch SSL-Verschlüsselung on the fly.
Deklarative Sprache
Möchte der Admin Kubernetes klarmachen, welche Art von Workload er starten will, tut er das über eine API-Komponente und eine deklarative Sprache (Abbildung 1). Der Admin beschreibt also den Wunschzustand seiner Container in einer Template-Datei, die er an K8s schickt. Kubernetes versucht dann, den Ist-Zustand so gut wie möglich jenem anzupassen, den das Template beschreibt.
Parallel dazu muss der Admin sich bei Kubernetes an eine neue Terminologie gewöhnen, denn wer mit dem Werkzeug hantiert, ohne zu wissen, was ein Pod ist, kann nicht glücklich werden. Knifflig wird es, wenn der Admin in Kubernetes größere Workloads betreiben möchte, die mehr als ein einzelnes Abbild umfassen, das nur ein paar Konfigurationsparameter benötigt. In Mikroarchitekturanwendungen stecken etliche Komponenten, die man in den Pod-Definitionen alle beachten muss. Selbst wenn es darum geht, mehrere monolithische Apps in Form von Kubernetes-Pods auszurollen, ist es eine eher lästige Fingerübung, dafür die passenden Pod-Definitionen zu erstellen.
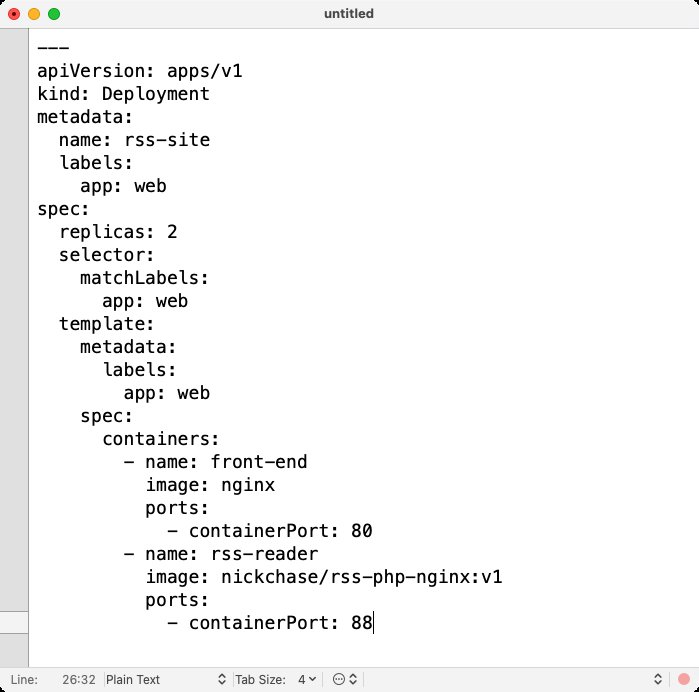
Abbildung 1: Diese Pod-Definition für Kubernetes zählt zu den noch eher übersichtlichen Exemplaren. Je größer die Umgebungen werden, desto komplexer fallen auch die zugehörigen Ressourcendefinitionen aus.
Den Anbietern von Software, die ihre Produkte auf K8s-Basis an die Frau und den Mann bringen wollen, kann das nicht recht sein. Wie üblich gilt, dass bei Admins hoch im Kurs steht, wer ein Produkt möglichst schlüsselfertig ausliefert. Das heißt im Kubernetes-Kontext: Idealerweise erhält der Systemverwalter alle zu einem Produkt gehörenden Komponenten vorkonfiguriert, sodass er für seinen eigenen Kubernetes-Cluster nur noch die umgebungsspezifischen Konfigurationsparameter angeben muss. Um den ganzen Rest der Inbetriebnahme einer bestimmten Software kümmert sich idealerweise das System. Das Konzept ist letztlich dasselbe, das auch bei Paketmanagern gilt. Wo auf konventionellen Systemen eben Rpm oder Dpkg ihren großen Auftritt haben, kommt bei Kubernetes Helm ins Spiel.
Alter Hase
Helm hat im Kubernetes-Universum bereits einige Lenze miterlebt – mittlerweile liegt das Programm in Version 3 vor, die sich von den vorherigen Versionen zum Teil beträchtlich unterscheidet. Admins merken das immer wieder, wenn sie im Netz auf die Suche nach Helm-Informationen gehen.
Die Unterschiede treten vor allem bei den zu Helm gehörenden Komponenten offen zutage. Der sogenannte Tiller war in Helm 2 die zentrale Komponente für die Kommunikation mit Kubernetes. Der Admin hatte also einen Helm-Client auf der Kommandozeile, der mit dem Tiller kommunizierte und ihm Befehle einflüsterte – das heißt, ihm Vorlagen für virtuelle Setups übermittelte, die in der Helm-Terminologie Charts heißen (Abbildung 2). Kubernetes machte sich dann daran, die vom Tiller vorgegebenen Setups zu erstellen. Zeit seines Lebens litt Tiller allerdings unter mehreren Problemen, die in seinem Design angelegt und mithin nur sehr schwer zu korrigieren waren. Das betraf die Verwaltung von Rechten, die Parallelität von Vorgängen in Helm und einige weitere zentrale Aspekte.
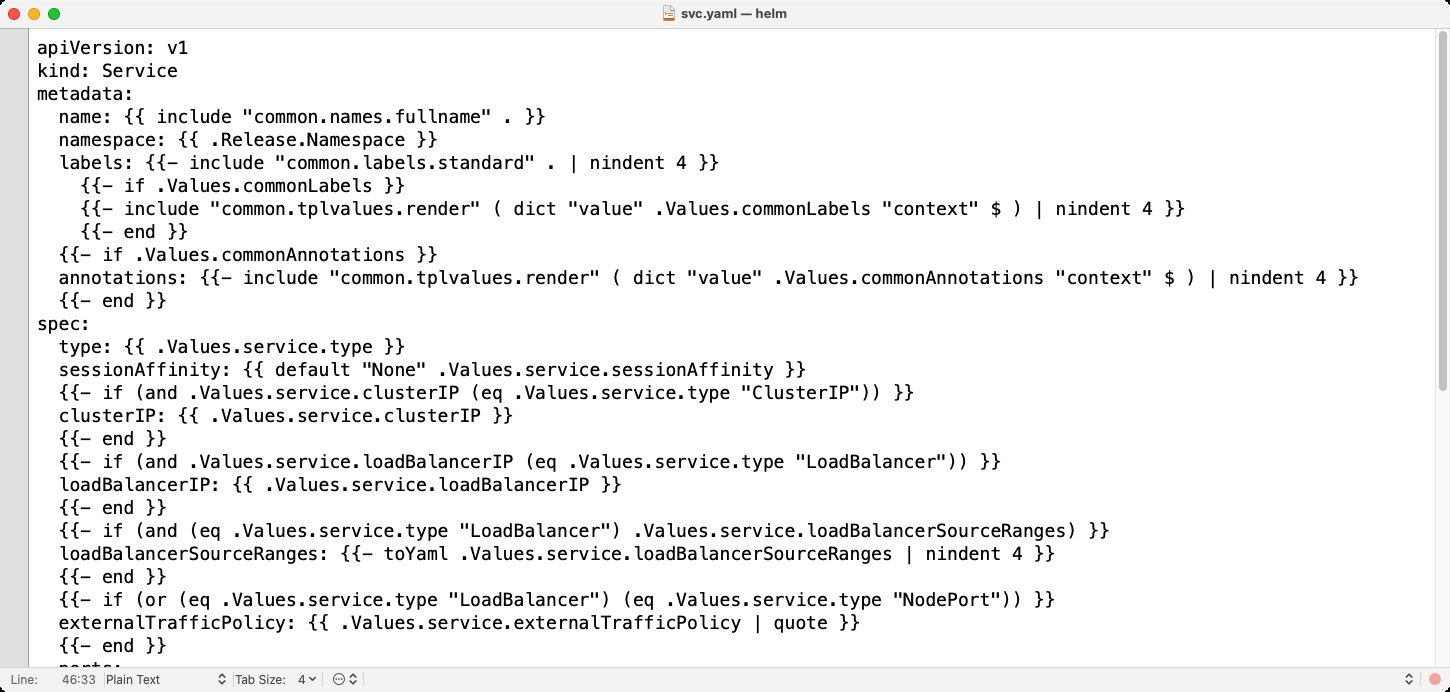
Abbildung 2: Helm fungiert als Übersetzer zwischen Kubernetes und dem Anwender. Unter der Haube lässt sich bei den Helm-Templates gut erkennen, dass sie letztlich in Kubernetes landen werden.
In Helm 3 machten die Entwickler dem Tiller deshalb kurzerhand den Garaus. An seine Stelle treten einerseits ein leistungsfähigerer Kommandozeilen-Client, der nach wie vor auf die Bezeichnung Helm hört, und andererseits eine Bibliothek, die für den Client als Brücke zu Kubernetes dient. Eine eigene Verwaltungsinstanz hat Helm 3 entsprechend nicht mehr. Es ist sehr wichtig, das im Hinterkopf zu behalten, denn Helm-Neulinge geraten bei der Suche nach Informationen auch heute noch oft an alte Doku und fliegen aus der Kurve, wenn sie Helm 3 ausrollen und dort der Tiller fehlt.
Das Problem
Wie funktioniert Helm nun aber im Detail? Der Vergleich eines Deployments derselben Software einmal mit und einmal ohne Helm macht das deutlich.
Angenommen, der Admin will eine beliebige Microservices-Anwendung in Kubernetes ausrollen. Der klassische Weg hierfür wäre, eine Pod-Definition zu verfassen, die Instanzen aller benötigten Container enthält. In aller Regel ist es damit aber nicht getan. Zu den Containern gesellen sich ja Konfigurationsparameter. Schließlich müssen die Dienste in den einzelnen Pods später wissen, wie sie miteinander kommunizieren sollen.
Wer das Thema gleich richtig angehen will, setzt auf externe Lösungen wie Istio: Das spannt ein Mesh zwischen allen Komponenten auf und routet den Traffic dynamisch. Dazu muss es selbst aber auch wieder Bestandteil der Pod-Definition sein, was diese ein gutes Stück länger macht. Hat der Admin seine Pod-Definitionen abgeschlossen, übergibt er sie Kubernetes, das die entsprechenden Ressourcen startet.
Ein jähes Ende findet die Freude oft allerdings, wenn derselbe Admin ein paar Monate oder Jahre später das laufende Setup in Kubernetes verändern möchte, ohne sich in der Zwischenzeit viel damit befasst zu haben. “Wie war das gleich wieder?” ist eine in diesem Kontext viel gehörte Frage.
Noch dicker kommt es aus Unternehmenssicht, wenn der ursprüngliche Autor der Pod-Definitionen mittlerweile das Unternehmen verlassen hat und sich ein Nachfolger zunächst einarbeiten muss. Zwar folgt Kubernetes bei seinen Pod-Definitionen einer strengen, weil YAML-basierten Syntax. Zu verstehen, was der Vorgänger aus welchen Gründen wie zusammengesteckt hat, dürfte in aller Regel trotzdem eine Weile dauern, und je komplexer die ursprünglichen Pod-Definitionen waren, desto länger dauert die Einarbeitung.
Irgendwann kommt es dann zum Showdown: Fühlt der Admin – egal, ob es sich um denselben oder einen neuen handelt – sich hinreichend sicher, nimmt er Veränderungen vor. Gehen diese allerdings schief, hilft in vielen Fällen nur noch, die bestehenden Pods wegzuwerfen und mit den Daten der alten eine komplett neue virtuelle Umgebung hochzuziehen.
Der gesamte Vorgang ist weder sonderlich komfortabel noch im Hinblick auf betriebliche Stabilität sehr sicher. Genau an dieser Stelle kommt dem Admin deshalb Helm zur Hilfe. Eingedampft auf die absoluten Basics, handelt es sich bei Helm um eine Art Übersetzungshilfe. Die Helm-Bibliothek nimmt vom Helm-Client Informationen entgegen und wandelt sie on the fly in Pod-Definitionen um, die Kubernetes versteht. Zur Admin- und Anwenderseite hin exponiert Helm gleichzeitig eine Schnittstelle, die im Prinzip einer Lösung für Automation- und Konfigurationsmanagement ähnelt.
Im konkreten Beispiel würde der Admin für seine Mikroarchitekturanwendung eine Anweisung in Helm für das Deployment schreiben, die aus zwei Teilen besteht: einerseits den generischen Anweisungen, aus denen Helm dann via Helm-Bibliothek Pod-Definitionen für Kubernetes baut, und andererseits einer Datei namens »values.yaml«, die die Konfigurationsparameter definiert, die der Admin von außen zu beeinflussen vermag.
Die Gesamtheit dieser Dateien, also der Templates für Kubernetes einerseits und der durch den Admin modifizierbaren Variablen andererseits, heißt im Helm-Sprech Chart. Bei einem Chart handelt es sich also um ein aus mehreren Teilen bestehendes Template, mit dessen Hilfe sich Workloads schlüsselfertig auf Kubernetes ausrollen lassen. Genau aus diesem Grund bezeichnen viele Helm auch als Paketmanager für Kubernetes.
Laufende Workloads
Helm stößt bei Admins auch deshalb auf viel Akzeptanz, weil es ihnen nicht nur das erste Ausrollen eines Workloads in Kubernetes ermöglicht. Komplementär dazu bietet es überdies Funktionen, um laufende Workloads in Kubernetes zu verändern, falls es diese zuvor selbst ausgerollt hat.
Ein klassisches Beispiel dafür ist die Veränderung der Replica-Zahl etwa von Frontend-Servern im Webbetrieb. Hier kommt einmal mehr das klassische Webshop-Beispiel zum Tragen: Online-Shops, die über das Jahr verteilt vorhersehbare Umsätze erzielen, ächzen zu besonderen Anlässen und insbesondere in der Vorweihnachtszeit oft unter hohen Zugriffszahlen. Wer seinen Workload beispielsweise in AWS oder Azure hostet, will in der heißen Phase entsprechend virtuelle Instanzen nachrüsten, die mit der erhöhten Last zurechtkommen. Genau das ist ja das Heilsversprechen, mit dem Anbieter ihre Kunden locken: Bezahlt werden muss nur, was der Kunde tatsächlich an Ressourcen konsumiert.
Der Workload und die Werkzeuge, die ihn verwalten, müssen dieses Skalieren aber auch beherrschen. Kubernetes bietet die Funktionalität zwar nativ, doch gilt hier, was dieser Artikel zuvor bereits als Herausforderung beschrieben hat: Je nach dem, wie die Pod-Definitionen verfasst wurden, kann bei Unachtsamkeit ein Stack-Update in einem veritablen Desaster enden. Helm eilt dem Administrator hier mit seinem standardisierten Interface zu Hilfe, das immer gleich funktioniert.
Die meisten Charts, die man online findet, kennen einen Replica-Parameter. Die Anweisung »helm update« vermag diesen für laufende Workloads in einem Kubernetes-Cluster zu verändern. Der Rest passiert automatisch: Ein einzelner Helm-Befehl bringt die Helm-Bibliothek dazu, die eigenen Pod-Definitionen in Kubernetes so anzupassen, dass nicht mehr zehn Instanzen eines Webservers laufen, sondern 20 oder wie viele auch immer der Admin zu brauchen glaubt.
Mit Helm loslegen
Wenn Sie nun Lust bekommen haben, sich mit Helm genauer zu beschäftigen und vielleicht eigene Charts zu produzieren, müssen Sie dafür nicht viel tun. Sie holen zunächst CLI und Bibliothek auf das eigene System; die Helm-Website [1] enthält aber neben Paketquellen für Snap und Apt auch ein statisch gelinktes Binary, das sich entsprechend verwenden lässt. Haben Sie einen Rechner mit MacOS als Arbeitsplatz, bekommen Sie Helm bei Bedarf über die Homebrew-Umgebung (Abbildung 3). Obendrein bieten die Entwickler auf ihrer Website eine Art Guide für Best Practices an, wenn es um das Verfassen von Charts geht [2].
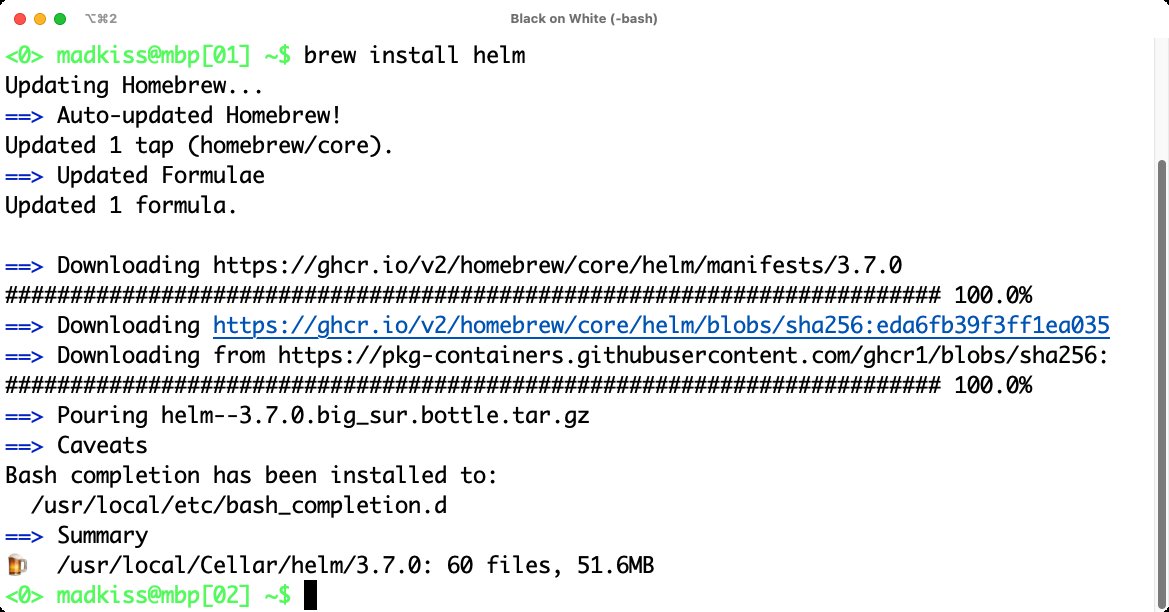
Abbildung 3: Das Helm-CLI zusammen mit seiner Bibliothek steht auf diversen Systemen zur Verfügung – mittels Brew etwa auch für MacOS.
Steht Helm lokal zur Verfügung, kann es losgehen. Jede Instanz eines Workloads, die Sie via Helm ausrollen, heißt Release. Sie nutzen also ein fertiges Chart, um ein beliebig benanntes Release einer virtuellen Umgebung in Kubernetes zu erstellen. Die Charts stammen wie bei Paketmanagern üblich aus verschiedenen Repositories. Das hilft gerade Einsteigern dabei, sich in Helm zurechtzufinden. Weil es mittlerweile diverse Repositories gibt, ist die Wahrscheinlichkeit gar nicht so gering, dass Sie keine eigenen Helm-Charts verfassen müssen, sondern auf bestehende zurückgreifen können.
Der Helm-Client kennt ab Werk das Hub-Repository, das den Artifact Hub [3] nach Charts durchsucht (Abbildung 4). Auf der Kommandozeile holt etwa »helm search hub wordpress« fertige Charts für WordPress auf den Schirm. Praktisch: Artifact bündelt die Ergebnisse aus diversen Repos, sodass Sie sie nicht alle Ihrer lokalen Repo-Listen hinzufügen müssen. Sollen allerdings Charts aus einem Repository zum Einsatz kommen, das der Artifact Hub nicht kennt, müssen Sie das Repo zuvor mittels »helm repo add Name URL« hinzufügen. Das Kommando »helm repo list« zeigt eine Liste aller aktivierten Repos an.
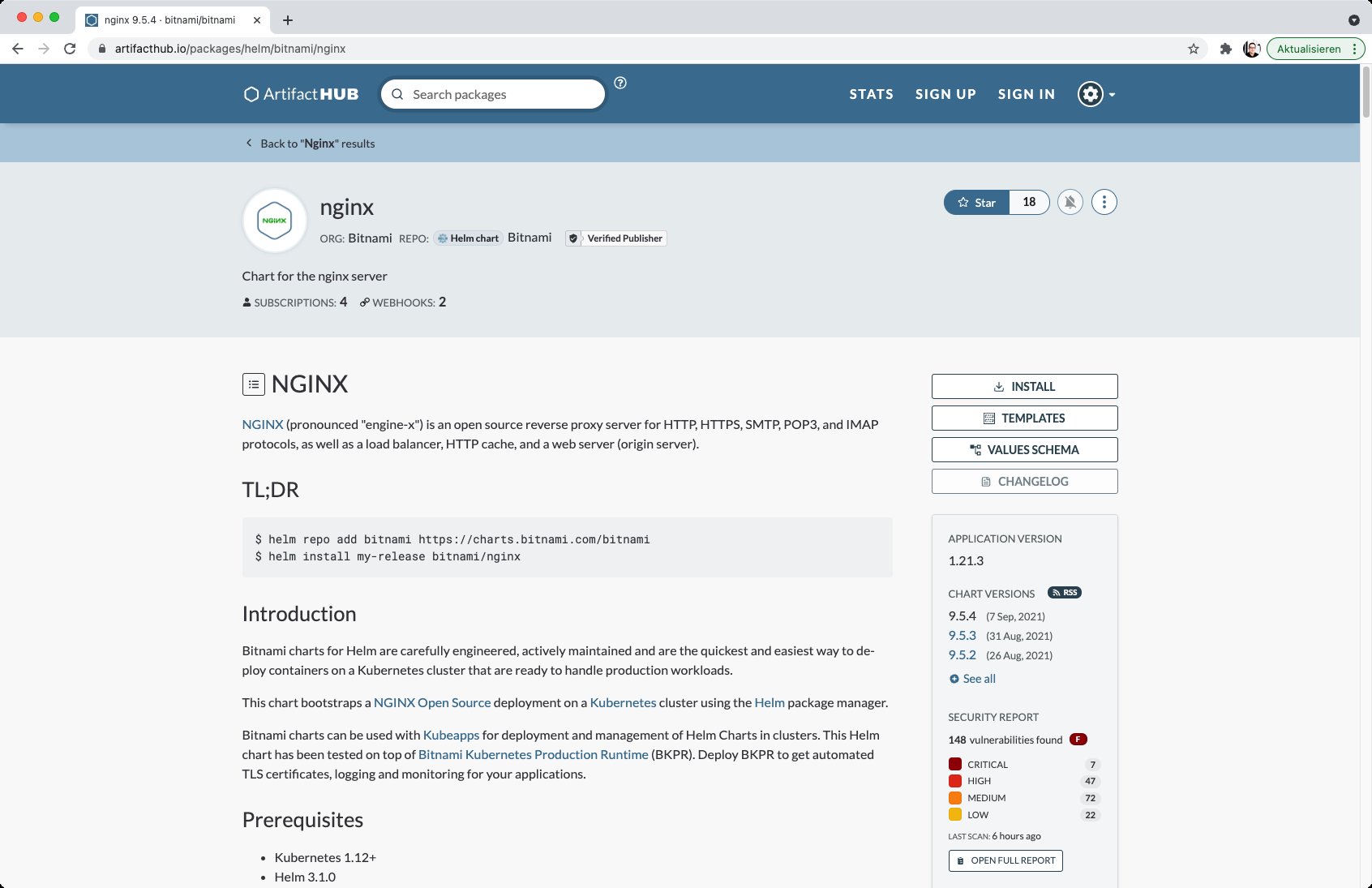
Abbildung 4: Der Artifact Hub von Helm zeigt dem Admin Helm-Charts aus diversen Verzeichnissen an, sodass dieser die Daten nicht selbst zusammentragen muss.
Mit Helm arbeiten
Neben dem Anlegen und Löschen von virtuellen Umgebungen (also Releases von bestimmten Charts) bietet Helm viele Optionen, laufende Stacks zu analysieren. Der Befehl »helm status Release« zeigt Informationen über ein Release inklusive dessen Revisionsnummer an, die zeigt, wie oft das Release bereits im laufenden Betrieb verändert wurde.
An dieser Stelle sei noch auf einen Umstand hingewiesen, der Admins, die mit Helm eigene Charts verfassen, bereits viel Zeit gekostet haben dürfte. Falls Helm-Chart und Container-Abbild nicht von denselben Autoren stammen, setzen Charts für Helm in Kubernetes regelmäßig auf andere Abbilder als die Originale der Anbieter. Wer etwa das WordPress-Chart von Bitnami verwendet, nutzt unter der Haube nicht das offizielle WordPress-Abbild für Container, sondern ein von Bitnami modifiziertes.
Das liegt daran, dass die offiziellen Abbilder viele Parameter nicht unterstützen, die Helm in den Containern nutzen will. Möchten Sie eigene Charts produzieren, stehen Sie möglicherweise vor demselben Problem und müssen eigene Abbilder der jeweiligen Software für den Betrieb im Container erstellen. Dafür gibt es im Netz diverse Anleitungen, die Container etwa als Ergebnis einer CI/CD-Pipeline produzieren.
Helm am Beispiel
Am Ende dieses Artikels darf nach viel Theorie ein ganz praktischer Einblick in das, was mit Helm möglich ist, nicht fehlen. Aktuell eignet sich dafür kaum eine Software am Markt so gut wie Owncloud. Mancher Admin, der in der Vergangenheit schon mit Helm zu tun hatte, gerät hier vielleicht ins Stutzen: Der große PHP-Monolith Owncloud steht nun wirklich nicht im Verdacht, sich sonderlich gut für den Betrieb in Kubernetes zu eignen oder mit Helm verwalten zu lassen. Allerdings: Wer so denkt, ist nicht mehr auf dem aktuellen Stand der Technik.
Owncloud hat sich in den vergangenen Monaten praktisch neu erfunden. Die PHP zum Teil in die Wiege gelegten Performance-Einschränkungen verursachten über die Jahre hinweg immer wieder Schwierigkeiten. Viele moderne Programmier-Mantras und Techniken etwa fehlen in PHP, zum einen, weil sie noch nicht erfunden waren, als die Sprache an den Start ging, und zum anderen, weil ein Nachrüsten nicht trivial ist. Ein gutes Exempel dafür liefert das immer wieder angeführte Beispiel Multithreading.
Im Rahmen von Owncloud X entschieden sich dessen Entwickler deshalb für einen radikalen Schritt, sprich: einen fast vollständigen Rewrite. Statt PHP kommt nun Go zum Einsatz, und von der monolithischen Programmierweise der Vergangenheit haben die Entwickler sich ebenso verabschiedet. Stattdessen besteht Owncloud X aus Mikroarchitekturanwendungen, die über festgelegte APIs miteinander kommunizieren. Durchaus bemerkenswert ist dabei, dass sich das Client-Protokoll von Owncloud nicht verändert hat. Existierende Clients tun also weiter ihren Dienst, und Owncloud-Apps wie jene für iOS oder Android brauchen ebenfalls kein Update.
Damit ist auch klar: Owncloud X bietet den Betreibern von Kubernetes-Clustern ein mögliches Deployment-Modell. Bis vor wenigen Wochen war es allerdings eine nervige Angelegenheit, Owncloud in einem Kubernetes-Cluster zum Laufen zu bringen. Das Bitnami-Projekt hat damit nun Schluss gemacht: Owncloud steht ab sofort als Chart für Helm zur Verfügung und lässt sich auf beliebigen Kubernetes-Clustern ausrollen – etwa auch auf AKS, also Amazons K8s-Spielart. Die Macht und die Effizienz, die von sinnvoll eingesetzten Helm-Charts ausgehen, werden dabei überdeutlich. Es genügen zwei Befehle, um eine nagelneue Owncloud-Umgebung in Kubernetes an den Start zu bekommen (Listing 1).
Listing 1
Owncloud-Deployment
# helm repo add bitnami https://charts.bitnami.com/bitnami # helm install MyRelease bitnami/owncloud
MyRelease ersetzen Sie dabei durch einen beliebigen Namen, unter dem der nun ausgerollte Stack später in Kubernetes firmiert. Sind Sie sich nicht ganz sicher, welche Namen bereits vergeben wurden, zaubert der Befehl »helm list« eine Liste auf den Bildschirm. Soll das Helm-Chart später wieder vom System verschwinden, erledigt das der Befehl »helm delete MyRelease«.
Zugegeben, die Bitnami-Entwickler haben hier ziemlich leichtes Spiel, denn Owncloud leistet aktive Schützenhilfe: Seit Owncloud X für die generelle Nutzung freigegeben wurde, steht es auch in Form von Docker-Abbildern bereit. Die wiederum bilden die Grundlage für die Bitnami-Helm-Charts. Bitnami nutzt zwar nicht unmittelbar das von Owncloud angebotene Abbild, baut jedoch darauf auf.
Leichtes Spiel
Wie viel Arbeit Helm dem Administrator abnimmt, lässt sich am Owncloud-Chart von Bitnami gut verdeutlichen. Zwar haben die Entwickler dort eine ganze Reihe von Parametern eingebaut, über die Owncloud im Container sich bis ins kleinste Detail steuern lässt. In der »values.yaml« kann der Systemverwalter sich also nach Belieben austoben. In den meisten Fällen dürfte das aber gar nicht notwendig sein. Ein paar grundlegende Parameter wie der Pfad zum zu nutzenden SSL-Zertifikat oder die zu verwendende öffentliche IP-Adresse wird der Admin wohl aber angeben wollen (Abbildung 5).
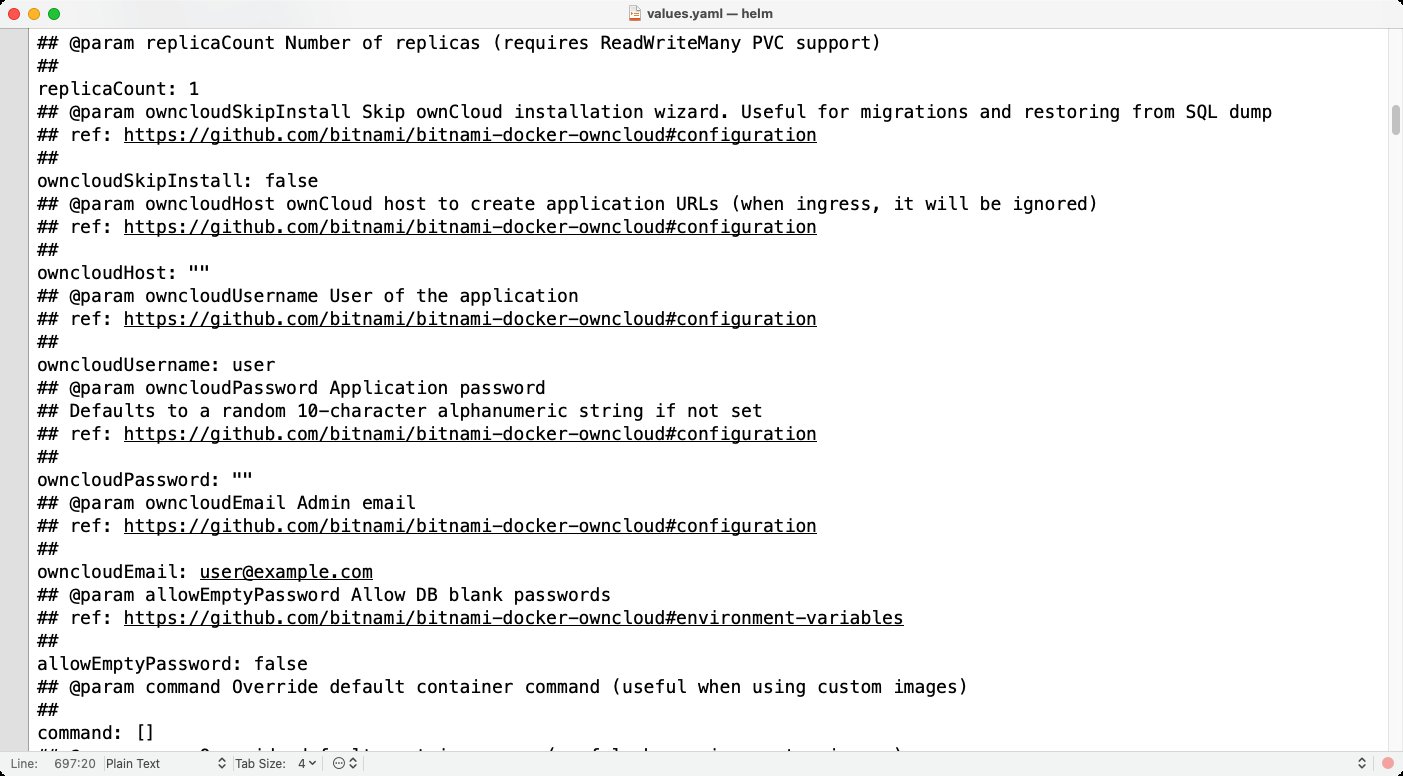
Abbildung 5: Helm-Charts wie dieses für Owncloud bringen eine »values.yaml« mit, in der der Systemverwalter bei Bedarf lokale Parameter festlegt.
Bei einer lokalen Änderung an der »values.yaml« hängt der Admin an den Aufruf »helm install« eben noch ein »-f values.yaml« an, um auf seine lokale Datei zu verweisen. Nach wenigen Sekunden läuft Owncloud X verteilt im lokalen Kubernetes (Abbildung 6); um Themen wie die benötigten Replicas kümmert Helm sich obendrein automatisch. Mit dem Parameter »mariadb.architecture=replication« stemmt Helm gegebenenfalls sogar eine hochverfügbare Datenbank. Verglichen mit dem Aufwand, die benötigten Pod-Definitionen selbst zu verfassen und aufeinander abzustimmen, lässt sich der in Helm anfallende Arbeitsaufwand praktisch vernachlässigen.
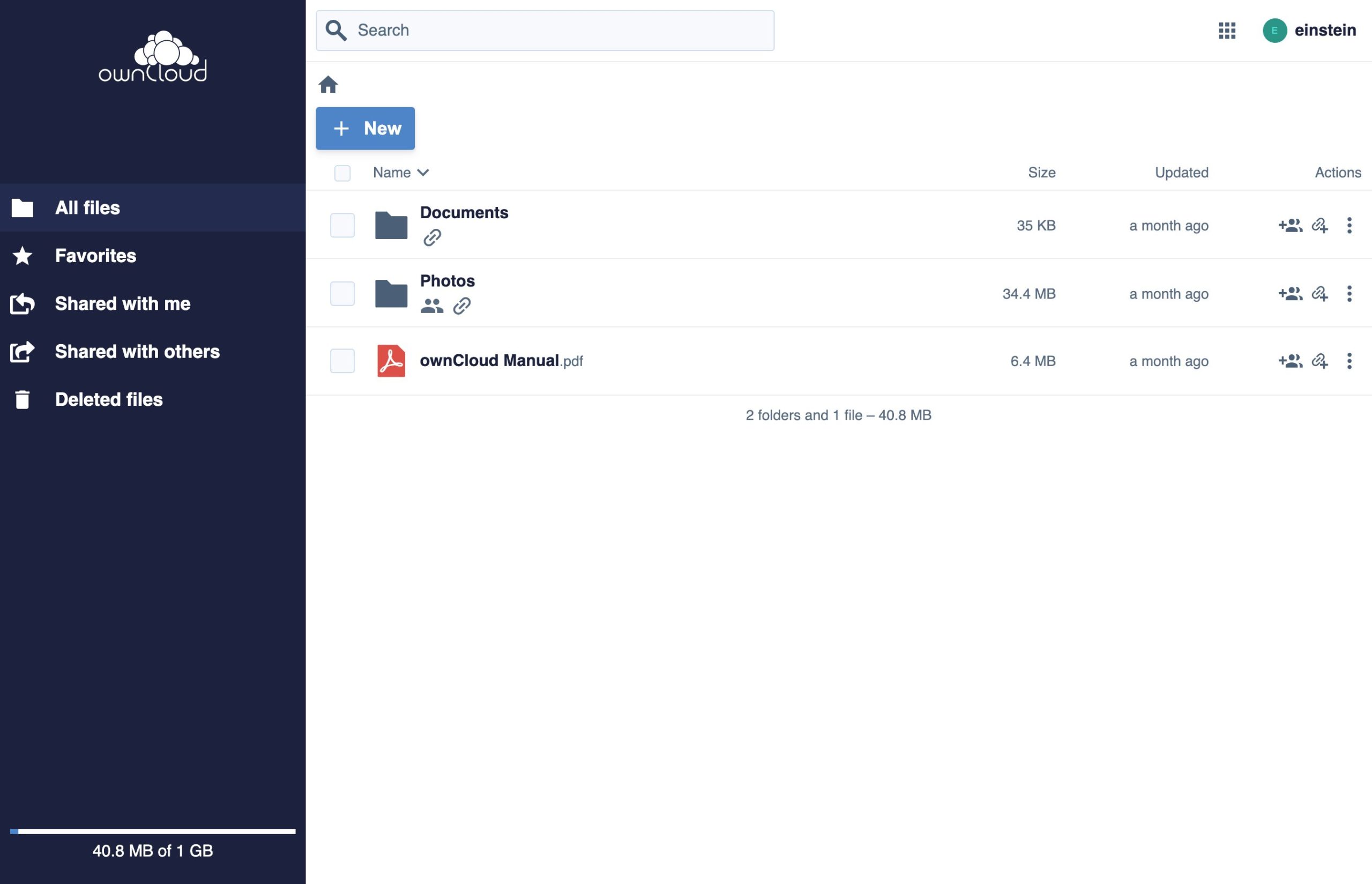
Abbildung 6: Owncloud X (OCIS) kommt mittlerweile als modulare Anwendung in Go daher und lässt sich neuerdings als Helm-Chart in Kubernetes problemlos ausrollen.
Fazit: Cool, aber …
Helm ist kein reiner Paketmanager. Wer es mit Rpm oder Dpkg vergleicht, muss stets im Hinterkopf behalten, dass die zwar auch vorkonfigurierte Dienste ausliefern, mehrere Pakete sind dabei in aller Regel aber nicht aneinander angepasst. Ein Helm-Chart dagegen rollt fertige Abbilder so aus, dass sie anschließend perfekt aufeinander abgestimmt sind. Als eigentliche “Pakete” fungieren in dieser Gleichung fertige Docker-Abbilder, die meist die Anbieter von Software selbst erstellen und feilbieten. Helm spinnt einerseits ein Netz aus Konfiguration um die Images herum und bietet dem Administrator andererseits eine einfache Schnittstelle, um neue Workloads in Kubernetes zu starten oder bestehende zu verändern.
Entsprechend steht Helm eigentlich in Konkurrenz zur Riege der Automatisierer. Ansible, Chef & Co. können mittlerweile ebenfalls Workloads in Kubernetes starten. So wäre etwa ein eigenes Ansible-Playbook denkbar, um Owncloud in Kubernetes an den Start zu bekommen – mit dem Schönheitsfehler, dass es nicht nativ in K8s integriert wäre. Andererseits hätte ein solches Playbook auch nicht das Problem, das viele an Helm zu Recht bemäkeln: Es wäre nämlich keine YAML-Schaufel, die auf der einen Seite Konfigurationsparameter vom Anwender entgegennimmt und sie auf der anderen an die Programme in den Containern weitergibt.
Hier läuft Helm in ein systemisches Problem: Wer alle Parameter der containerisierten Anwendungen für Änderungen anbieten will, muss sie irgendwie nach außen durchreichen. Teile des Helm-Charts für Owncloud funktionieren deshalb im Grunde als simple Übersetzungshilfe für Parameter. Wer alle Owncloud-Parameter nutzen möchte, könnte sich jedoch eine passende Pod-Definition letztlich wohl auch selbst schreiben. Echte Effizienzsteigerung bietet Helm besonders und gerade dann, wenn man die meisten Vorgaben der Entwickler des jeweiligen Charts übernimmt.
Infos
- Helm installieren: https://helm.sh/docs/intro/install/
- Tipps für Chart-Autoren: https://helm.sh/docs/chart_best_practices/conventions/
- Artifact Hub: https://artifacthub.io/





