
© Andrey Snegirev / 123RF.com
Kubernetes unterstützt Mandantenfähigkeit nur eingeschränkt, weshalb viele Admins lieber mehrere eigenständige Kubernetes-Cluster bauen. Das frisst Ressourcen und erschwert die Verwaltung. Loft startet beliebig viele Cluster innerhalb derselben Control Plane.
Kubernetes gilt als Spitzenreiter in Sachen Container-Orchestrierung, und weit und breit ist kein möglicher Nachfolger in Sicht. Ganz gleich in welcher Geschmacksrichtung, ob in Form von OpenShift, Rancher oder nacktem Kubernetes: Wer Container betreibt, kommt am Flottenmanagement mit Kubernetes kaum vorbei – nicht zuletzt deshalb, weil ehemalige Alternativen wie Docker Swarm mittlerweile praktisch bedeutungslos geworden sind.
Der Kubernetes-Ruhm bedeutet freilich auch, dass Admins nicht sehr viel Auswahl haben, falls ihnen etwas an Kubernetes nicht passt. Und Dinge, die dem Admin an Kubernetes nicht passen können, gibt es viele. Ein oft genannter Kritikpunkt etwa ist die traditionell schlechte Unterstützung für mehrere Mandanten. De facto war die Lösung seitens ihrer Erfinder nie dafür ausgelegt, die Container vieler Kunden parallel zu verwalten – Fluch und Segen zugleich. Segen, weil Kubernetes viel weniger komplex ausfällt als beispielsweise OpenStack, bei dem die Mandantenfähigkeit von Anfang an zum Konzept gehörte. Fluch, weil durch den eher mäßigen Mandanten-Support der Betrieb von Kubernetes-Clustern schnell ausartet.
Wie bei allen zentralen Verwaltungswerkzeugen gibt es auch bei Kubernetes mehrere Komponenten, die zwingend vorhanden sein müssen. Das prominenteste Beispiel dafür ist die Kubernetes-API. Zur Control Plane mit der zentralen Intelligenz gehören aber noch viel mehr Komponenten, etwa der Kubernetes-Scheduler oder Etcd als Konsenssystem. Auf den Compute-Knoten läuft zusätzlich Kubelet, das von der Control Plane seine Anweisungen erhält und sie in lokale Konfiguration übersetzt. Wer also einen Kubernetes-Cluster bauen möchte, braucht dafür ein bisschen Hardware, zumal die Control Plane üblicherweise redundant ausgerollt sein will. Zwar hat der Admin nicht gleich einen Loss of Functionality, falls sie mal nicht funktioniert, ganz sicher aber einen Loss of Control.
Für viele ist es mühsam
Weil es nicht legitim ist, für jedes Test-Setup gleich ein komplettes Kubernetes-Setup hinzustellen, haben die Kubernetes-Entwickler sich in den vergangenen Jahren manchen Gedanken über die Mandantenfähigkeit der Lösung gemacht.
Mittlerweile setzen sie auf die sogenannten Namespaces, um in einem Kubernetes-Cluster die Workloads verschiedener Benutzer und Projekte voneinander zu trennen. Wer sich an die Namespaces des Linux-Kernels erinnert fühlt, liegt richtig: Teile des Separationskonzepts von Kubernetes sind von den Namespaces des Linux-Kerns zumindest inspiriert. Und sie kommen auch ganz konkret zum Einsatz, weil Kubernetes das Kernel-Feature nutzt, um unterschiedliche Projekte auf den Zielsystemen voneinander zu trennen.
Alles tipptopp also im Kubernetes-Land? Eher nicht. Die meisten Admins sind sich darin einig, dass Namespaces in Kubernetes keinen vollwertigen Ersatz für echte Mandantenfähigkeit bieten. Zur Wahrheit gehört allerdings auch, dass sie das nie sein wollten.
Herausforderung Namespaces
Wer verstehen will, vor welche Herausforderungen Kubernetes-Namespaces ihre Nutzer stellen, stellt sich am besten einen Multi-Tenant-Prozess vor, wie er etwa bei OpenStack aussähe. Hier würde für einen neuen Kunden einfach ein neues Projekt in der Umgebung angelegt. Das böte sofort die Option, seine eigenen virtuellen Netze anzulegen, die von denen anderer Kunden strikt getrennt wären. Eigene Quotas für vCPUs, vRAM und virtuelle Blockgeräte wären augenblicklich in Kraft. Darüber hinaus stünden dem Projekt allerdings alle dokumentierten Funktionen der OpenStack-API zur Verfügung, die reguläre Projekte nutzen dürfen. Welchen Workload ein Projekt etwa in OpenStack aufruft, ist der Plattform herzlich egal, solange sich das innerhalb der festgelegten Quotas abspielt.
Bei Namespaces in Kubernetes sieht die Sache etwas anders aus. So kommt Kubernetes ab Werk etwa mit einer Rollenverwaltung, die sich auf der Ebene von Namespaces allerdings nicht variieren lässt. Das heißt im Klartext, dass sich für unterschiedliche Namespaces keine unterschiedlichen Rollen mit eigenen Berechtigungen definieren und implementieren lassen. Das wiederum führt dazu, dass sich ein Projekt mit Zugriff auf einen bestimmten Namespace die für den eigenen Namespace geltenden Regeln nicht anzeigen lassen darf – sehr zum Verdruss vieler Admins, die etwaige Probleme debuggen wollen.
Auch die in Kubernetes sehr beliebten CRDs stehen Namespace-Nutzern nicht zur Verfügung. Dahinter verbergen sich die Custom Resource Definitons, also Erweiterungen der Kubernetes-API, die Nutzer selbst anlegen und verwalten können. CRDs erleichtern Kubernetes-Administratoren die Arbeit teils massiv, und obendrein brauchen diverse externe Werkzeuge wie viele Charts des Kubernetes-Paketmanagers Helm sie ebenfalls. Das heißt im Umkehrschluss: Das Fehlen von CRDs bedeutet eine massive Einschränkung hinsichtlich der installierbaren Helm-Charts und bringt die permanente Gefahr mit sich, dass Standardoperationen wegen Namespaces gar nicht oder nicht richtig funktionieren.
Noch mehr Probleme
Damit ist die Liste der Namespace-Einschränkungen allerdings noch keineswegs zu Ende. Cluster-weite Ressourcen gelten immer für alle Namespaces. Benötigt ein Projekt also solche Ressourcen und lässt sie vom Admin installieren, führt das möglicherweise zu Konflikten mit den für andere Namespaces definierten Ressourcen. Aus der Sicht eines Namespaces ist das aber ohnehin nur von untergeordneter Bedeutung, denn aus einem Namespace heraus ist der Zugriff auf Cluster-weite Ressourcen ohnehin stark eingeschränkt. Benötigt eine fertige Lösung für den Betrieb in Kubernetes also Cluster-weite Ressourcen, kann der Admin sich den Namespaces-Plan gleich wieder abschminken.
Namespaces sind also zwar auf dem Papier eine gute Idee, ihr praktischer Nutzen indes hält sich in Grenzen. Allen Admins, die frustriert nun doch wieder zu vielen Kubernetes-Inseln greifen wollen, eilen die Entwickler von Loft [1] nun mit einem neuen Produkt zur Hilfe. Es verspricht, virtuelle Kubernetes-Cluster in Namespaces so auszurollen, dass deren Admins ein vollwertiges Kubernetes nutzen können, ohne die Ressourcen einzelner und echter Kubernetes-Cluster zu benötigen. Wenn das klappt, wäre Loft so etwas wie der heilige Gral der Tenant-Funktionalität für Kubernetes. Grund genug, sich das Produkt genauer anzusehen.
Wie Loft funktioniert
Schon ein Blick auf das Architekturdiagramm der Lösung (Abbildung 1) zeigt, dass es sich bei Loft um ein ziemlich komplexes Konstrukt handelt. Naturgemäß greift es tief in die Kubernetes-Instanzen ein, die es nutzt – doch dazu später mehr.
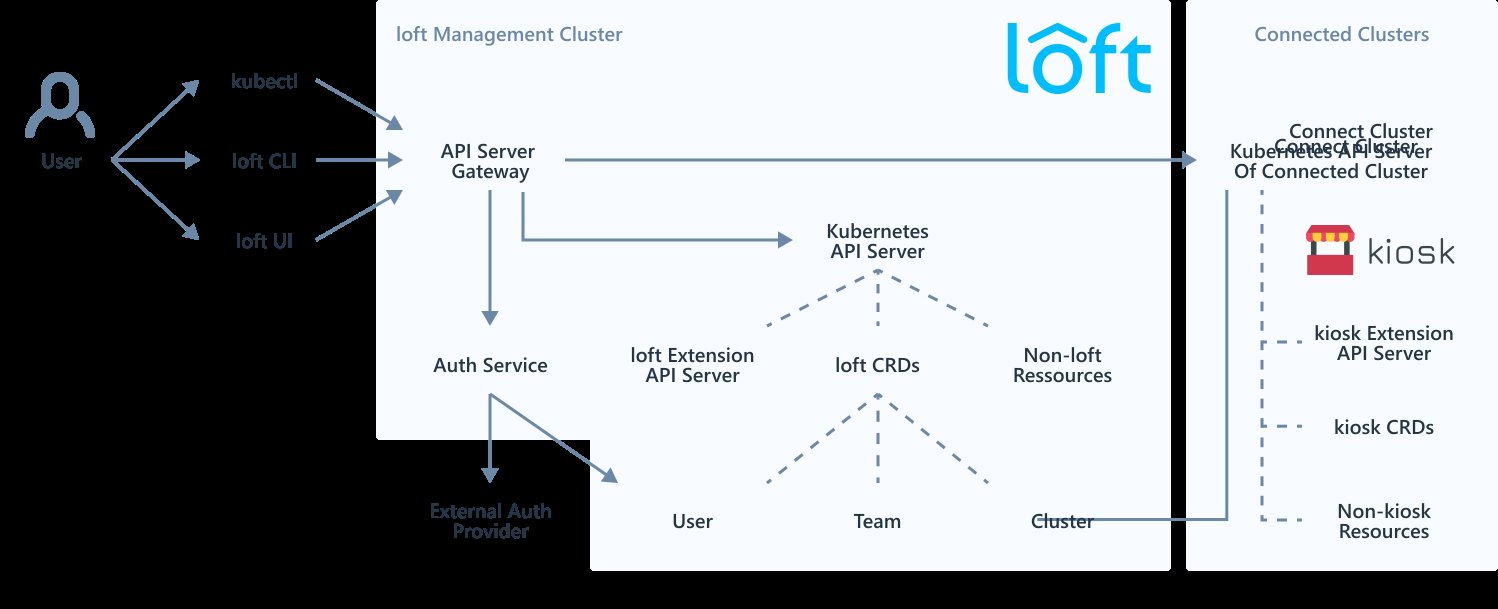
Abbildung 1: Loft fügt der Kubernetes-API eine eigene API hinzu, mit einer Vielzahl von Erweiterungen, um den Container-Orchestrierer für typische Mandatenfähigkeit fit zu machen. Quelle: Loft
Den Kern der Lösung bildet das Loft Management Center, für Endanwender die erste Anlaufstelle für jedwede Kommunikation mit den Kubernetes-Clustern, die Loft für seine Aufgaben zur Verfügung stehen. Hier landen also unmittelbar auch Befehle zum Starten von Ressourcen oder zum Ausrollen von Pods. Teil des Management Centers ist eine eigene Kubernetes-API-Instanz. Anwender, die an eine von Loft verwaltete Kubernetes-Instanz Befehle senden, sprechen also gar nicht direkt mit der K8s-Zielinstanz, weil der elementare Funktionen in Sachen Mandantenfähigkeit fehlen.
Das Thema Benutzerauthentifizierung macht das schnell deutlich. Kubernetes hat zwar gewisse Möglichkeiten, seine Benutzerverwaltung etwa via LDAP zu beziehen, doch nicht wenige Administratoren verabscheuen die aus ihrer Sicht unsägliche Fummelei mit HTTP-Request-Headern oder Webhooks. Will man Nutzer aus externen Authentifizierungsquellen zudem in das Kubernetes-RBAC integrieren, ist das alles andere als stringent oder komfortabel. Auch hier merkt man wieder, dass Kubernetes auf echten Multi-Tenant-Betrieb ganz einfach nicht ausgelegt ist.
Für Loft stellt das freilich ein Problem dar (Abbildung 2), denn die Lösung wirbt ja gerade damit, eine Art Multi-Tenancy-Fähigkeit für Kubernetes komfortabel und ohne riesigen Ressourcenaufwand nachzurüsten. Folgerichtig gehört zu Loft ein Authentifizierungsdienst, der alle Stücke spielt, die man von einem modernen Dienst dieser Art erwarten würde. LDAP lässt sich hier beispielsweise über das CNCF-Dex-Modul nahtlos einbinden. Andere Optionen wie SAML 2.0 oder die Anmeldung via GitHub-SSO stehen ebenfalls zur Verfügung.
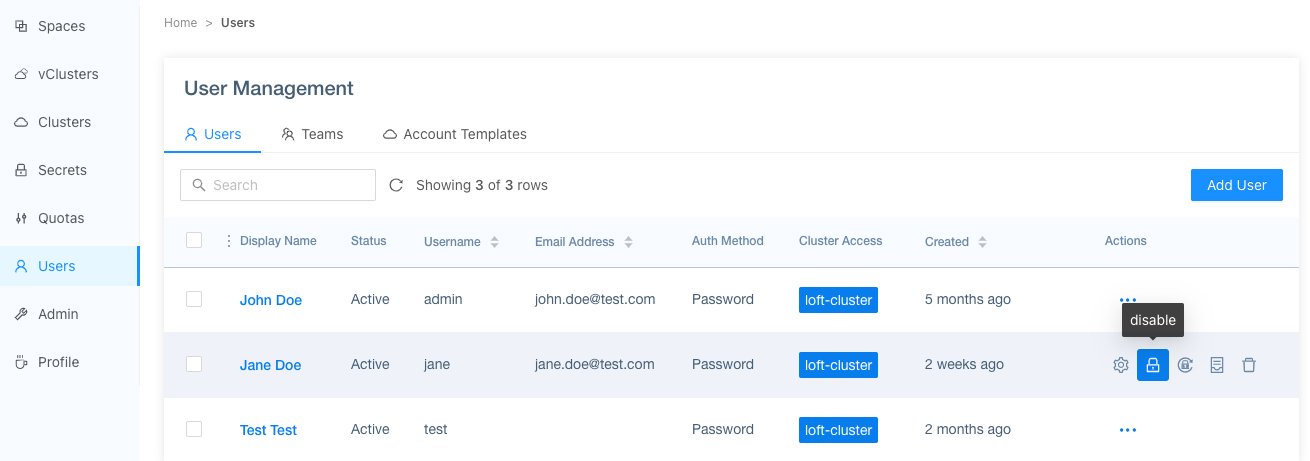
Abbildung 2: Loft erweitert Kubernetes unter anderem um eine komplette Benutzerverwaltung, die es in die Ziel-Cluster durchschleift. Quelle: Loft
Mithilfe eines der Loft-Kubernetes-API vorgeschalteten API-Gateways bindet Loft den Dienst ein, sodass in einer Loft-Instanz etliche verschiedene Accounts zur Verfügung stehen können. Hier funktioniert das Multi-Tenancy-Konzept von Loft also so, wie es die Entwickler versprechen. Das API-Gateway erfüllt zudem eine weitere Funktion, denn es dient in Loft als Single Point of Contact für eingehende Anfragen und als eine Art Signalweiche. Empfängt es Loft-spezifische Befehle, verarbeitet es sie selbst; generische Kubernetes-API-Aufrufe hingegen leitet das API-Gateway an die echten K8s-Schnittstellen im Hintergrund weiter.
Von Accounts zu Namespaces
Bis zur Mandantenfähigkeit auf der Kubernetes-Seite – oder der virtuellen Mandantenfähigkeit, wie es in der Loft-Dokumentation manchmal heißt – fehlt allerdings noch einiges. Die Kubernetes-API von Loft enthält etwa diverse Ressourcen, die einem offiziellen Kubernetes fehlen. Das umfasst alle Loft-eigenen Ressourcen, die über eine Loft-Extension mit eigener API angebunden sind, aber auch Loft-CRDs, ohne die die Nutzer durch Loft hindurch keine Ressourcen starten könnten.
Die Loft-CRDs unterscheiden sich von normalen CRDs zudem in einem sehr wichtigen Detail: Sie haben eigene API-Felder für die Angabe von Nutzern, Teams oder Ziel-Clustern, in denen sie laufen sollen. Dass diese Details in Kubernetes fehlen, liegt auf der Hand, ist die Lösung doch wie schon beschrieben nicht für Mandanten ausgelegt. Will Loft also Kubernetes um eine Mandantenfähigkeit erweitern, muss es die entsprechenden Felder hinzufügen. Dass die Entwickler das im Einklang mit den API-Spezifikationen von Kubernetes tun, ist ihnen in hohem Maße anzurechnen. Auch die Loft-API für Kubernetes lässt sich mit dem normalen Kubectl verwenden, wenn der Nutzer die nötigen Parameter wo nötig definiert.
Dass Loft ein eigenes, sehr viel komfortableres CLI-Werkzeug und gar eine eigene Oberfläche mitbringt, ist zwar schön. Im Falle eines Falles aber Loft mit Standardwerkzeugen steuern zu können, stellt einen nicht zu unterschätzenden Vorteil dar.
Wie Loft interagiert
Damit ist klar: Der größte Teil der Mandantenfähigkeit, die Loft auf Basis von Kubernetes-Namespaces nachrüstet, existiert zunächst in dessen eigener API. Das wirft die Frage auf, wie die Befehle aus den Loft-Diensten denn nun zu Kubernetes-Befehlen werden und dort letztlich für ausgerollte Pods sorgen. Um dieses Ziel zu erreichen, stellen die Loft-Entwickler den mit ihnen verbundenen Kubernetes-Clustern eine Art Kindermädchen namens Kiosk zur Seite. Offiziell firmiert Kiosk als eine Erweiterung für Kubernetes, die diesem Mandantenfähigkeit beibringt.
Was theoretisch klingt, gestaltet sich in der Praxis eigentlich recht simpel: Kiosk ist verantwortlich dafür, auf der Kubernetes-Seite die dortigen Namespaces zu verwalten und sie mit den aus Loft selbst stammenden Details zu verbinden. Allerdings bekommt der Admin es auch hier wieder mit einer eigenen Nomenklatur zu tun: Spricht die Doku von Loft und Kiosk plötzlich von Spaces, meint sie keineswegs dasselbe wie Namespaces in Kubernetes. Bei einem Space handelt es sich stattdessen um einen virtuellen Namespace. Der sieht für Loft-Nutzer von außen wie ein echtes Kubernetes aus, ist aber im Backend “nur” ein Namespace in Kubernetes mit den Zusatzfunktionen aus Loft.
Der Loft-Workflow
Loft ist komplex. Daher erscheint es aus Sicht des Admins hilfreich, sich den Workflow von Loft und einzelner Befehle darin am konkreten Beispiel vorzustellen.
Die Loft-Installation selbst fällt dabei Kubernetes-typisch gar nicht so komplex aus: Die nötigen Dienste kommen in Form fertiger Container daher, die sich in Kubernetes in Sekundenbruchteilen ausrollen lassen. Hier muss der Admin lediglich festlegen, ob der Cluster, den er für den Betrieb von Loft nutzen möchte, auch jener sein soll, in dem später die Loft-Namespaces lagern. Wer genügend Budget hat, tut allerdings gut daran, ein Rumpf-Kubernetes für die Loft-Komponenten zu betreiben und eine klare Trennung der Verantwortlichkeiten zu erhalten.
Läuft Loft selbst, steht im nächsten Schritt der Anschluss von Kubernetes auf dem Plan, also jenes Kubernetes-Clusters, in dem die virtuellen K8s-Umgebungen entstehen sollen. Loft macht dem Admin diese Aufgabe leicht, denn mittels des Loft-UIs gelingt die Verbindung mit einer bestehenden API eines Kubernetes-Clusters flott. Wer lieber auf der Kommandozeile unterwegs ist, erzielt denselben Effekt mit wenigen Kubectl-Befehlen.
Geteilte Dienste sind möglich
Den Loft-Entwicklern ist es erkennbar wichtig, mit ihrem Produkt möglichst viele Einsatzbereiche für Kubernetes abzudecken. So haben sie Loft grundsätzlich zwar darauf ausgelegt, Mandantenfähigkeit auf Kubernetes aufzupropfen, verlieren dabei aber nicht aus dem Blick, dass zwischen “ein Kubernetes pro Kunde” und “strikt getrennte Namespaces für alle Kunden” Grauzonen existieren.
Die Shared Services in Loft sind dafür ein Beispiel: Falls es Dienste gibt, die in einer Umgebung allen angeschlossenen Kunden gemeinsam zur Verfügung stehen sollen, lassen diese sich als Shared Service implementieren. Als Beispiel führen die Entwickler einen Certbot an, der SSL-Zertifikate unter einer einheitlichen Domäne für verschiedene Dienste auf Zuruf erstellt. Direkt aus Loft heraus lässt sich für einen solchen Dienst sowohl die nötige Subdomäne als auch der Dienst selbst erstellen (Abbildung 3).
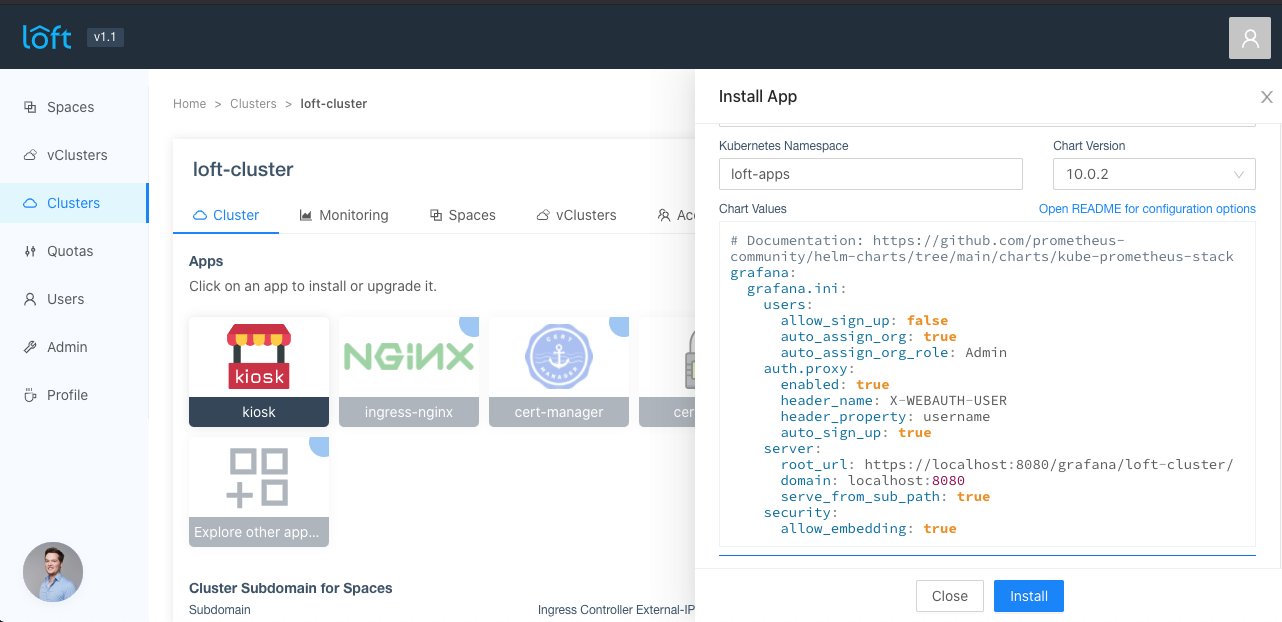
Abbildung 3: Zwar sind die Loft-Cluster streng voneinander getrennt, gemeinsam genutzte Dienste lassen sich aber dennoch einrichten. Quelle: Loft
Domänen, Cluster und Isolation
Der Haupteinsatzzweck von Loft ist freilich die strikte Trennung von Setups verschiedener Kunden – letztlich ja auch Lofts USP. Nachdem er also Loft selbst aufgesetzt und mit einem bestehenden Kubernetes-Cluster verbunden hat, koppelt der Admin im nächsten Schritt eine Benutzerverwaltung an Loft an. Hier ergeben sich wie beschrieben mehrere Möglichkeiten.
Die einfachste davon ist, die Benutzer in Loft selbst zu pflegen. Die Lösung bietet die nötige Funktionalität und kann eine lokale Benutzerdatenbank verwalten. In Unternehmen mit zentralem Benutzerverzeichnis stößt ein solcher Ansatz aber mit einiger Wahrscheinlichkeit nicht auf Gegenliebe. Er verletzt das Prinzip der Single Source of Truth im Hinblick auf Benutzerdaten.
Erfreulicherweise lässt sich Loft auch an bestehende Lösungen wie ein LDAP-Verzeichnis ankoppeln. Die Benutzerdaten kommen dann direkt aus dem Verzeichnis, eine lokale Benutzerdatenbank in Loft entfällt. Komplementär lässt sich die Anmeldung auch per SSO-Dienst verwalten, was faktisch einer Deaktivierung des passwortbasierten Logins in Loft entspricht.
Benutzer und Cluster verbinden
Dann folgt der neuralgische Moment im Zusammenspiel von Kubernetes und Loft. In Loft legt der Administrator einen Cluster-Account an, der einem lokal bekannten Nutzer Zugriff auf einen von Loft per Kiosk verwalteten Kubernetes-Cluster ermöglicht. Sobald der Admin einem lokalen Benutzer den Zugang zu einem Cluster erteilt, erstellt Loft via Kiosk dort den passenden Namespace und hält ihn als virtuelles Kubernetes für das Deployment von Diensten vor.
Das Anlegen von Accounts muss dabei nicht händisch geschehen: Mittels Template lässt sich der Schritt automatisieren. Will ein Admin also, dass jeder Mitarbeiter eines Unternehmens in jedem angeschlossenen K8s-Cluster einen Account hat, klappt das mit relativ geringem Aufwand. Der Clou aus Anwendersicht: Die Dienste lassen sich in den von Loft gebauten Spaces anschließend transparent genauso erstellen wie in einem normalen Kubernetes-Cluster. Um die gesamte Logik hinter den Kulissen kümmert sich Loft mit seinem Helferlein Kiosk.
Virtuelle Cluster zur Hilfe
Hat der Administrator es bis hierhin geschafft, ist Loft fast bereit für den vorgesehenen Einsatz. Es fehlt nur noch ein einziges Gestaltungselement. An diesem Punkt steht dem Admin lediglich ein Loft-Space zur Verfügung, in Kubernetes also ein Namespace, der mit eigener Benutzerverwaltung daherkommt und sich unter der Haube weitgehend wie ein echtes Kubernetes verhält. Dem Endanwender fehlen zu seinem Glück nur noch die Kubernetes-APIs selbst.
Hier kommt ein kleines Werkzeug der Loft-Entwickler ins Spiel, das auf den Namen vCluster hört (Abbildung 4). Ebenfalls eine Loft-Entwicklung, beruht es im Wesentlichen auf dem Prinzip, einen kleinen, aber vollständigen Kubernetes-Cluster in ein bestehendes Kubernetes auszurollen. Der Admin erhält also Kubernetes on Kubernetes.
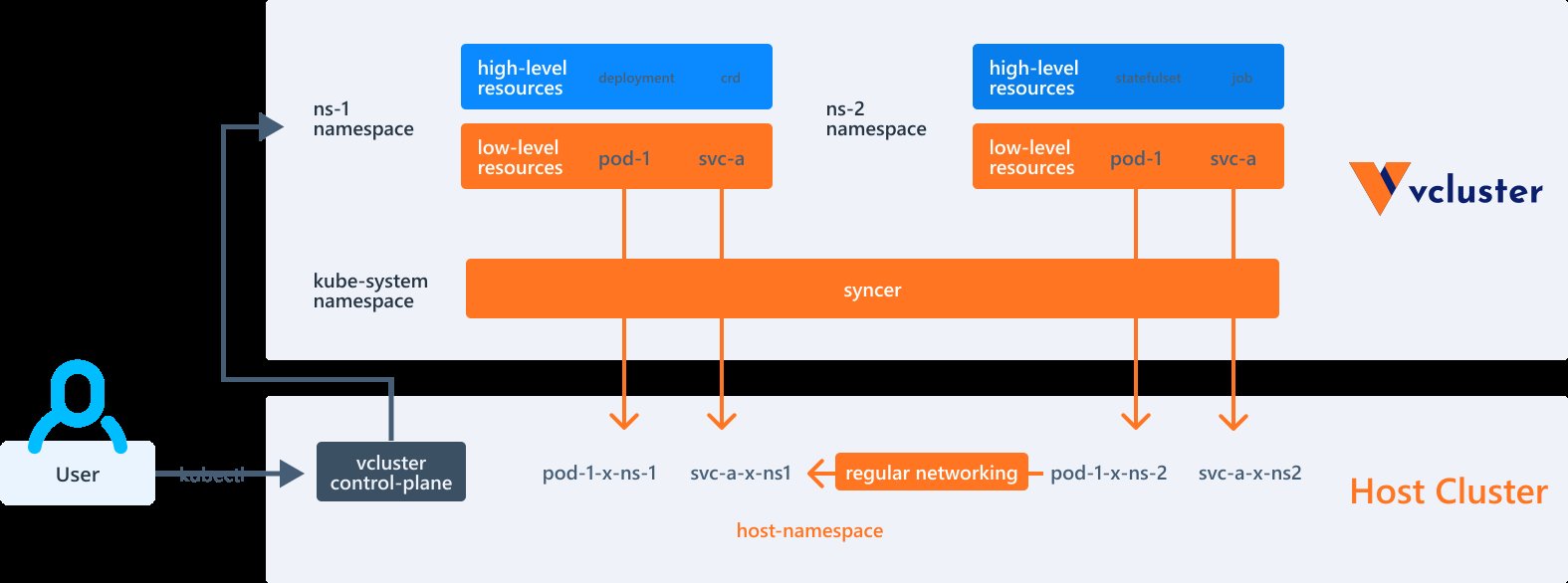
Abbildung 4: Auch vCluster entspringt der Loft-Feder. Das Werkzeug startet in einem Kubernetes-Cluster einen virtuellen Kubernetes-Cluster und schont so die Ressourcen. Quelle: Loft
Ganz neu ist diese Idee freilich nicht, es gibt Vorbilder aus anderen Bereichen. So ist es durchaus üblich, OpenStack auf OpenStack auszurollen, um Test- oder Staging-Umgebungen zu bekommen. vCluster von Loft erreicht für Kubernetes dasselbe und verpackt die zu Kubernetes gehörenden Komponenten dabei so, dass sie selbst in einem Kubernetes-Cluster laufen können.
Das hat aus Sicht des Administrators mehrere große Vorteile. Zunächst ist ein auf diese Weise ausgerollter Kubernetes-Cluster ein echtes, mit der K8s-API kompatibles Kubernetes, das auch eine offizielle Zertifizierung vorweisen kann, die das beweist. Es handelt sich also keineswegs um Bastelei, sondern aus Anwendungssicht um echtes K8s. Anders als im eingangs beschriebenen Szenario braucht das allerdings – und das ist der zweite große Vorteil – kein eigenes Blech. Es nutzt den bestehenden Kubernetes-Cluster samt dessen Ressourcen und rollt die benötigten Komponenten selbst als Pods aus. Weil Kubernetes Dienste längst redundant ausrollen kann, stellt auch Hochverfügbarkeit kein Problem dar.
Drittens, und auch das ist ein großer Vorteil von Loft, muss der Admin anders als bei klassischem Kubernetes nicht Namespaces und die Nutzer dafür händisch einrichten. Wie erwähnt lassen Nutzer sich für die Anmeldung automatisch integrieren, und Loft kümmert sich mit der eigenen Rechtevergabe im Anschluss darum, die gewünschten Berechtigungen in den Zielinstanzen von Kubernetes richtig zu implementieren. Praktisch implementiert Loft auf diese Weise also für Endanwender ohne Admin-Account in den Kubernetes-Zielinstanzen die Möglichkeit, sich echte und komplette eigene K8s-Instanzen zu klicken.
Loft spart Ressourcen
Damit erspart das Tool Unternehmen einerseits die Notwendigkeit, viel Geld für Hardware auszugeben, und bietet andererseits zusätzliche Features zum Sparen von Ressourcen: Momentan nicht genutzte virtuelle Kubernetes-Cluster kann Loft auf Wunsch des Admins ohne dessen explizites Zutun in eine Art Dämmerschlaf versetzen, bis sie wieder benötigt werden. Dieses Feature richtet sich offensichtlich an Firmen, in denen Entwickler ihre Kubernetes-Umgebungen für Tests nur unregelmäßig brauchen. Praktisch führt das Abschalten gerade nicht benötigter Instanzen dazu, dass sich mit derselben Hardware in Summe Tests effizienter planen und durchführen lassen.
Weitere Annehmlichkeiten
Praktisch erweitert Loft Kubernetes um eine Form von Mandatenfähigkeit, die sich mit dem Original nicht einmal annähernd erreichen lässt. Das genügt den Machern der Lösung aber offensichtlich noch nicht, und so spielen sie virtuos auf der Klaviatur der Features, die skalierbare Software heute haben sollte.
Wer etwa wissen möchte, wie die durch Loft verursachte Ressourcennutzung in den Ziel-Clustern aussieht, rollt mit wenigen CLI-Befehlen das in Loft integrierte Prometheus aus. Die Zeitreihendatenbank profitiert davon, dass Loft selbst diverse Metrikdaten im Prometheus-kompatiblen Format zur Verfügung stellt. Die Dienste greifen also nativ ineinander (Abbildung 5).
Abbildung 5: Auch an Schnittstellen für moderne Monitoring-Systeme wie Prometheus haben die Loft-Entwickler gedacht. Quelle: Loft
Verschiedene Versionen
Loft ist keine quelloffene Software, sondern ein proprietäres Produkt. Teile der Lösung finden sich zwar unter einer offenen Lizenz auf GitHub; wer die Lösung im großen Stile einsetzen möchte, muss aber entsprechende Lizenzen vom Hersteller erwerben. Die Free-Variante kommt ohne Preisschild daher, erlaubt aber nur das Nutzen von drei unterschiedlichen User-Accounts, kann maximal zwei Kubernetes-Cluster anbinden und fünf virtuelle Cluster ausrollen. Die Productive-Variante schlägt mit 20 US-Dollar pro Benutzer und Monat zu Buche und unterstützt bis zu 200 Nutzer. Sie vermag zehn Kubernetes-Cluster anzubinden und beliebig viele virtuelle Cluster zu erstellen. Wer das größere Paket und Features wie Hochverfügbarkeit auf der Loft-Ebene benötigt, greift zur Enterprise-Lizenz für 47 US-Dollar pro Anwender und Monat.
Fazit
Dass Kubernetes ab Werk ohne Mandantenfähigkeit daherkommt und sämtliche Kubernetes-Distributionen wie OpenShift und Rancher ihre eigene Art und Weise implementieren, Mandanten in Kubernetes zu unterstützen, stellt in den Augen vieler Admins ein riesiges Problem dar.
Loft legt einen validen Ansatz zur dessen Lösung vor, der sowohl mit der ganz offiziellen Kubernetes-Version als auch mit den Distributionen der diversen Hersteller funktioniert. Er erweitert den Container-Orchestrierer um ein effektives Prinzip für Multi-Tenancy-Einsatzzwecke, greift dazu aber auch tief in Kubernetes selbst ein. Virtuelle Cluster und eine flexible, schonende Nutzung der vorhandenen Hardware-Ressourcen sind der Mühe Lohn.
Allerdings fallen die von Loft aufgerufenen Preise recht happig aus. Admins sollten also zunächst die Free-Version des Programms evaluieren, wenn sie auf der Suche nach Multi-Tenancy-Fähigkeiten für Kubernetes sind. Im Falle eines Falles gilt es daneben, mit spitzem Bleistift zu prüfen, ob sich der Loft-Einsatz lohnt oder separate (gegebenenfalls virtuelle) Hardware nicht doch die bessere Lösung darstellt. (jcb/jlu)
Infos
- Loft: https://www.loft.sh





