
© Sergey Tryapitsyn / 123RF.com
Die Multimodelldatenbank ArangoDB erlaubt das Speichern von JSON-Dokumenten und optional deren Verknüpfung durch einen Graph. Mit Python und dem Package Python-arango lassen sich alle Fähigkeiten und Features von ArangoDB nutzen.
Neben den traditionellen, relationalen Datenbanken haben in den letzten Jahren auch NoSQL-Datenbanken ihren Platz in IT-Projekten erobert. Zu den populären Vertretern dieser Spezies zählen unter anderem MongoDB als traditioneller JSON Document Store, Cassandra als hochskalierbarer Column Store, aber auch Graph-Datenbanken wie Neo4J oder Timeseries-Datenbanken wie InfluxDB. Jedes dieser Datenbanksysteme hat eigene Stärken, Schwächen und Anwendungsgebiete.
In diesem Artikel stellen wir die Multimodelldatenbank ArangoDB [1] vor. Die Bezeichnung leitet sich von dem Fakt ab, dass die ArangoDB verschiedene Datenmodelle gleichzeitig unterstützt, nämlich wahlweise einen Key-Value Store zur Speicherung von Schlüssel-Wert-Paaren, einen Document Store zur Speicherung von Dokumenten respektive JSON-Daten oder einen Graph Store zur Speicherung von Graphen. Ein Graph besteht dabei aus Knoten (in ArangoDB: Dokumente) und Kanten, die eine Beziehung zwischen zwei Dokumenten beschreiben. Kanten lassen sich mit beliebigen Attributen belegen.
Einer der großen Vorzüge von ArangoDB besteht darin, dass man neben der klassischen Ablage von Daten als Dokument falls notwendig auch Datenbeziehungen über die Graph-Komponente modellieren kann. Anders als etwa MongoDB bringt ArangoDB diese Funktionalität direkt mit, man muss sie nicht umständlich in Eigenregie implementieren. Die wichtigsten Features führt der Kasten “Schlüsselmerkmale von ArangoDB” auf.
Schlüsselmerkmale von ArangoDB
- Hoch skalierbar und Cluster-fähig (durch Verwendung von RocksDB als Storage Engine).
- Benutzerdefinierbare Transaktionen. Transaktionen in ArangoDB sind ACID kompatibel (Atomicity, Consistency, Isolated, Durable). Transaktionen können sich über mehrere Dokumente und Dokumentkollektionen erstrecken.
- Eingebautes Foxx-Framework zur Realisierung von Microservices auf Basis von Javascript oder Typescript.
- Schemafrei (JSON-Schemata optional konfigurierbar).
- Arango Query Language (AQL) als deklarative Abfragesprache für alle Datenmodelle.
- Volltextsuche (via ArangoSearch).
- Sekundärindizes zur effizienten Suche nach Daten.
- Unterstützung für Geospatial-Applikationen.
- Web-GUIs zur Administration der Datenbanken und von Clustern.
- Rollenbasiertes Authentifizierungs- und Autorisierungsmodell auf Datenbank- und Kollektionsebene.
ArangoDB steht als Open-Source-Projekt unter der Apache License 2.0 und wird von der Firma ArangoDB GmbH betreut. Die als Community-Edition bezeichnete kostenlose Variante von ArangoDB lässt sich auch kommerziell nutzen. Daneben gibt es eine Enterprise-Version, deren Fokus auf Security, Datacenter Awareness und hoher Skalierbarkeit liegt.
Die Community-Edition genügt den Anforderungen der meisten Anwendungsfälle. In Szenarien, in denen es auf hohe Skalierbarkeit ankommt, kann man auch auf ArangoDB in der Cloud (ArangoDB OASIS [2]) als SaaS-Option zurückgreifen.
Auf die Installation von ArangoDB gehen wir hier nicht ein, da diese einfach über den Paketmanager der verwendeten Distribution oder auch Docker erfolgen kann. Für alle gängigen Betriebssysteme und Distributionen stehen entsprechende Pakete bereit.
Daten modellieren
Daten oder Dokumenten speichert ArangoDB in sogenannten Kollektionen (Collections). Mehrere Kollektionen lassen sich zu einer Datenbank zusammenfassen. Das Beispiel aus Listing 1 zeigt, wie man mithilfe der Arango-Shell von der Kommandozeile aus mit der Datenbank interagiert. In diesem Beispiel haben wir zwei Personendatensätze gespeichert.
ArangoDB hat dabei jeweils automatisch den Primärschlüssel »_key« generiert. Wie bei einer relationalen Datenbank könnte ihn auch eine Applikation vorgeben. Der Primärschlüssel in ArangoDB ist unveränderlich. Das generierte Attribut »_id« dient als interne ID zur Identifizierung des Datensatzes. Das Attribut »_rev« repräsentiert die interne Version des Datensatzes und kommt bei der Replikation und Synchronisation von Daten innerhalb eines ArangoDB-Clusters zum Einsatz.
Listing 1
Beispiel-Session mit der Arango-Shell
$ arangosh --server.password pnmaster 127.0.0.1:8529@_system> db._createDatabase("demo") true 127.0.0.1:8529@demo> db._create("data") [ArangoCollection 32359054, "data" (type document, status loaded)] 127.0.0.1:8529@demo> data_col = db.data [ArangoCollection 32359054, "data" (type document, status loaded)] 127.0.0.1:8529@demo> data_col.save({name: "ingo", age: 42}) { "_id" : "data/32359101", "_key" : "32359101", "_rev" : "_cBD44C6---" } 127.0.0.1:8529@demo> data_col.save({name: "jamie", age: 17}) { "_id" : "data/32359115", "_key" : "32359115", "_rev" : "_cBD5HHm---" }
AQL
ArangoDB verfügt mit der ArangoDB Query Language (AQL [3]) über eine wohldefinierte, deklarative Abfragesprache, mit der man alle Abfragen für alle Datenmodelle formulieren kann. Der Vorteil von AQL gegenüber in JSON formatierten Queries etwa bei MongoDB oder Elasticsearch liegt nach Meinung des Autors in der einfachen Lesbarkeit. In JSON formatierte Abfragen geraten gerade bei Elasticsearch schnell zu stark verschachtelten Gebilden, bei denen Verständlichkeit, Lesbarkeit, Wartbarkeit und Nachvollziehbarkeit leiden.
Das AQL-Beispiel aus Listing 2 foltert die Collection »demo« nach »age=17«. Das entspricht der SQL-Abfrage »select * from demo where age=17«. AQL verfügt über sämtliche gängigen Features, die man von SQL kennt. Darüber hinaus unterstützt es auch alle Features von ArangoDB, etwa die Abfrage über Dokumente, die durch einen Graph verknüpft sind.
Listing 2
AQL-Beispiel
FOR doc in demo FILTER doc.age == 17 return doc
Neben dem Kommandozeilen-Tool Arangosh bringt ArangoDB auch ein sehr nützliches Web-Interface (Abbildung 1) mit, das man nach der Installation über http://localhost:8529 erreicht (Abbildung 2).
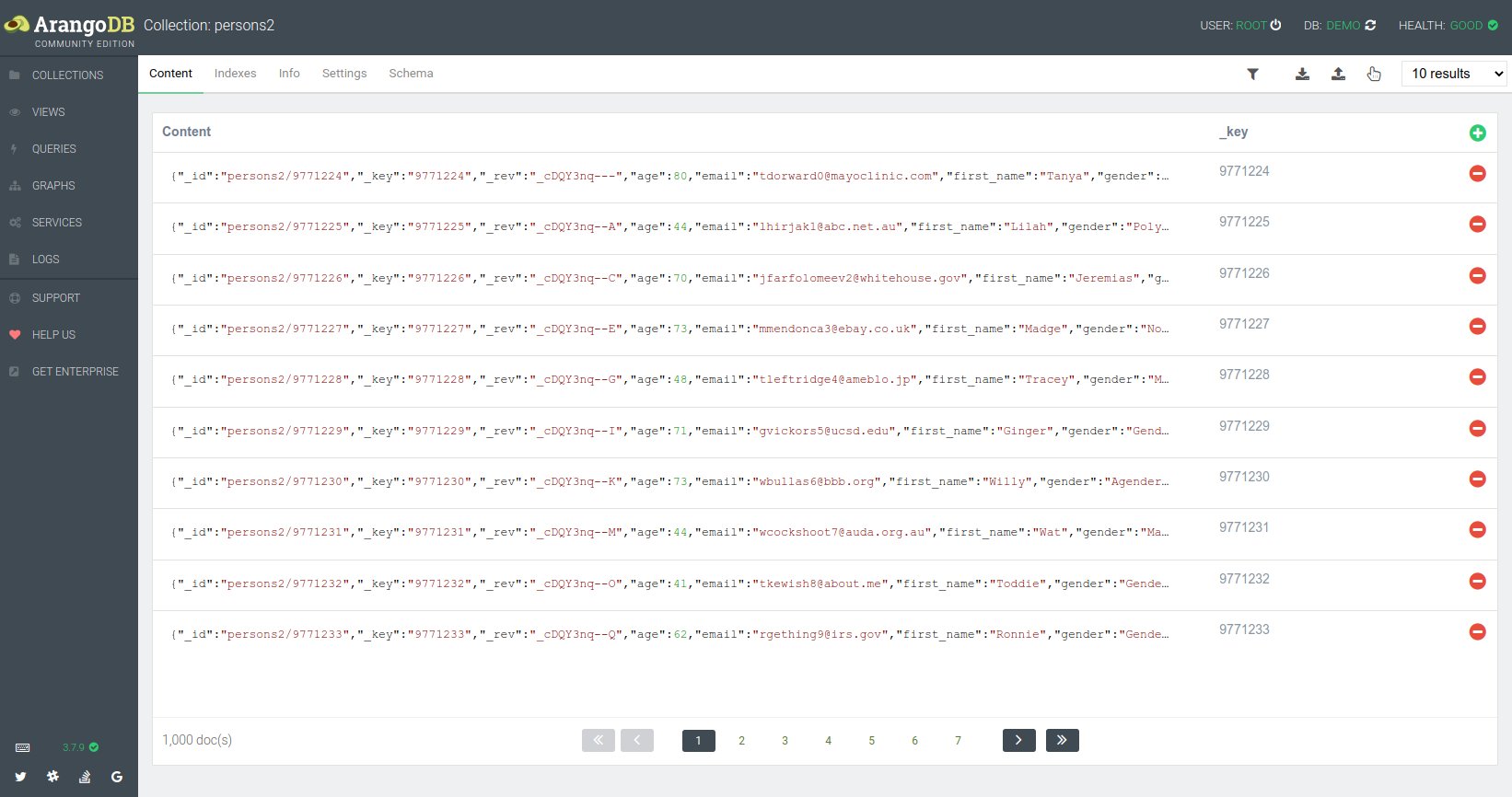
Abbildung 1: Eine Übersichtsansicht aller Dokumente einer Collection …
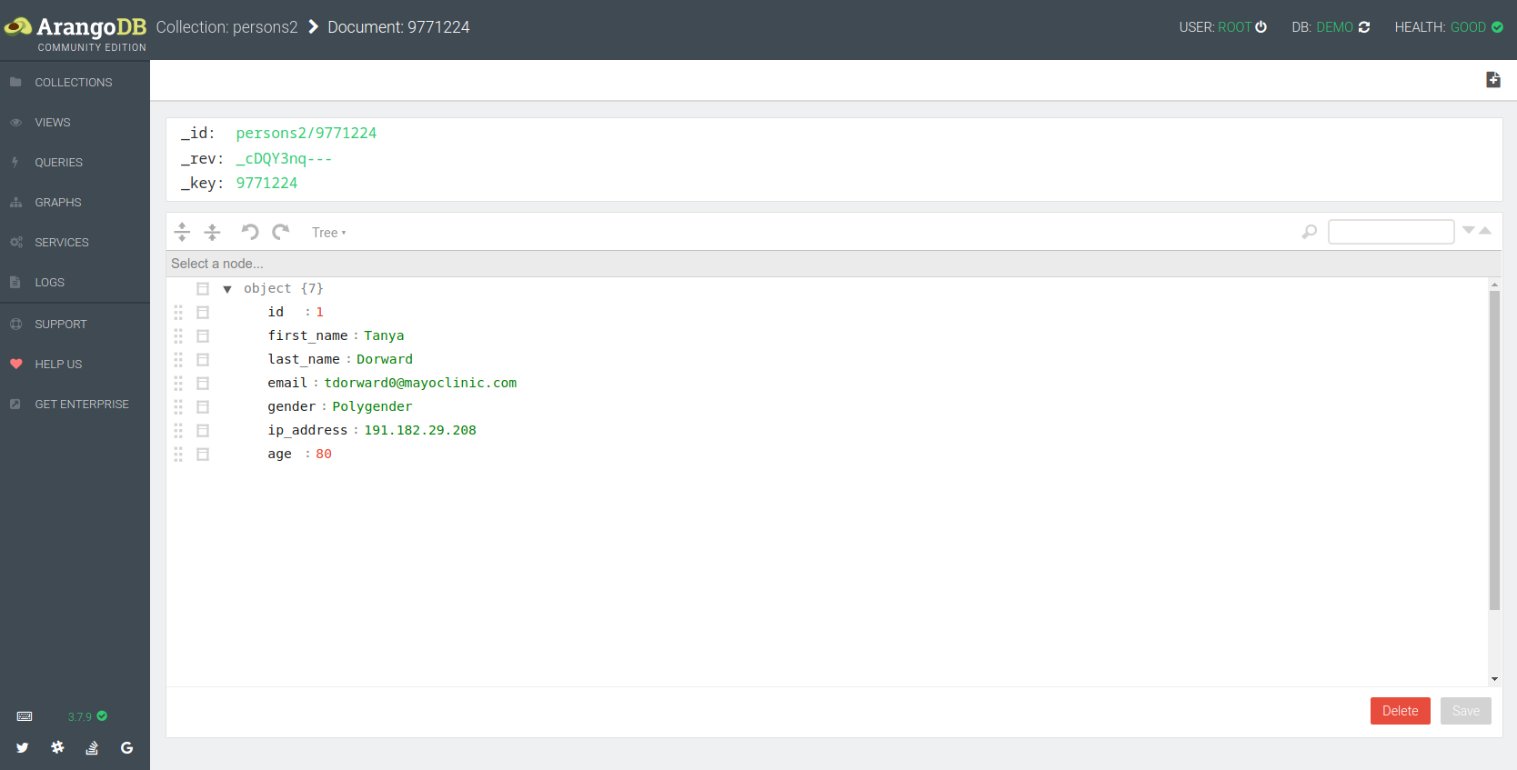
Abbildung 2: … und die formatierte JSON-Ansicht eines konkreten Datensatzes.
Python und ArangoDB
ArangoDB verfügt wie die meisten NoSQL-Datenbanken über eine ReST-Schnittstelle, über die man mit der Datenbank via HTTP gemäß dem CRUD-Prinzip (Create, Read, Update, Delete) interagieren kann. Im Laufe der Jahre entstanden mehrere Python-Treiber für ArangoDB.
Wir verwenden in diesem Artikel den offiziellen Treiber python-arango [4], der seit Jahren kontinuierlich weiterentwickelt wird und die Features der aktuellsten ArangoDB Version-unterstützt. Für die folgenden Beispiele benötigen Sie eine aktuelle Python-3-Version ab v3.7. Listing 3 zeigt einige typische Befehle und Abfragen.
Listing 3
Python-arango verwenden
import arango
# ArangoDB Client Connection
client = arango.ArangoClient()
# Login in die Datenbank _system
sys_db = client.db("_system", username="admin", password="passwd")
# Anlegen einer neuen Datenbank demo
sys_db.create_database("demo")
demo_db = client.db("demo", username="admin", password="passwd")
# Anlegen einer Collection persons in der DB demo
coll = demo_db.create_collection("persons")
# Einfügen mehrerer Datensätze
coll.insert({"name": "jamie", "age": 42})
coll.insert({"name": "matthias", "age": 17})
# Alle Dokumente der Collection "persons"
for person in coll.all():
print(person)
# Ausgabe
# {'_key': '9767348', '_id': 'persons/9767348', 'name': 'jamie', 'age': 42}
# {'_key': '9767350', '_id': 'persons/9767350', 'name': 'matthias', 'age': 17}
age_17 = list(coll.find({"age": 17}))
# Resultat: [{'_key': '9767534', '_id': 'persons/9767534', 'name': 'matthias', 'age': 17}]
# Datensatz ändern ("jamie" wurde ein Jahr älter)
coll.update_match({"name": "jamie"}, {"age": 43})
age_43 = list(coll.find({"age": 43}))
# Resultat: [{'_key': '9767656', '_id': 'persons/9767656', 'name': 'jamie', 'age': 43}]
# Löschen des Eintrags von "matthias"
coll.delete_match({"name": "matthias"})
Wie bei allen Datenbanken üblich kann man in ArangoDB Indizes anlegen, um bei der Suche nach gängigen Feldern oder Attributen die Geschwindigkeit zu steigern. ArangoDB kennt neben persistenten Indizes (mit Sparse-Option zur Beschränkung der Indexeinträge auf solche Dokumente, die dem Index Werte bereitstellen) auch solche zur Volltextsuche auf Texten sowie Geospatial-Indizes zur Suche auf Geodaten.
In den ersten beiden Zeilen von Listing 4 werden über die Indexdefinition für das Feld »age« einzelne Werte eines Felds indexiert. Häufig hat man jedoch in Datensätzen auch mit Arrays (oder aus Sicht von Python mit Listen) zu tun, die man ebenfalls indexieren muss. Einen Datensatz mit dem Feld »colors«, der eine Liste von Farbwerten enthält, würde man in Python so definieren wie in der dritten Zeile; einen Index dafür legt die vierte Zeile an. Beachten Sie dabei die »[]«-Notation hinter dem Feldnamen.
Listing 4
Beispiele für Indizes
coll.add_persistent_index(fields=["age"], sparse=True) coll.add_fulltext_index(fields=["name"]) colors = ["grün", "blau", "weiss"] coll.add_persistent_index(fields=["colors[]"], sparse=True)
AQL in Python
Die bisherigen Beispiele zeigen, wie man von Python aus einfach und gezielt Datensätze in ArangoDB speichert und manipuliert. Es gibt jedoch viele Situationen, in denen man nicht um das Verwenden der Abfragesprache AQL herumkommt. Insbesondere komplexere Queries würden sich mit einer entsprechenden Python-Notation nur umständlich formulieren lassen.
@Aus dem Bereich der relationalen Datenbanken kennt man das Konzept der Object Relation Mapper (ORM). Deren bekannteste Vertreter in der Python-Welt sind SQLAlchemy oder der Django-ORM. In einem ORM versucht man, die Komplexität eines gegebenen Datenmodells zu abstrahieren und auf eine Objektstruktur abzubilden. Für Python und ArangoDB existiert der Arango-ORM, den wir aber hier nicht weiter beleuchten.
Im Beispiel aus Listing 5 generieren wir eine Anfrage über AQL, die alle Einträge für Personen mit einem Alter unter 20 ausliest. Analog zu anderen Python-SQL-Anbindungen erhält man für eine gegebene Query einen Datenbank-Cursor zurück, mit dessen Hilfe man dann über alle gefundenen Datensätze iteriert.
Listing 5
AQL in Python-arango
import arango
# ArangoDB Client Connection
client = arango.ArangoClient()
demo_db = client.db("demo", username="admin", password="passwd")
aql = demo_db.aql
# AQL Statement mit Bind Variablen
cursor = aql.execute(
"FOR doc in persons filter doc.age < @value RETURN doc",
bind_vars={"value": 20}
)
for doc in cursor:
print(doc)
# Resultat: {'_key': '9768314', '_id': 'persons/9768314', 'name': 'matthias', 'age': 17}
Um AQL-Anfragen zu testen, kann man sie auch im Web-Interface erstellen und ausprobieren. Dabei erfolgt eine syntaktische Prüfung der Anfrage. Die Resultate lassen sich wahlweise als JSON (Abbildung 3) oder als Tabelle (Abbildung 4) darstellen; das Result Set kann man im JSON-Format herunterladen. Damit eignen sich ArangoDB und das Web-UI auch hervorragend für Data Scientists zur Ansicht und Analyse von Daten.
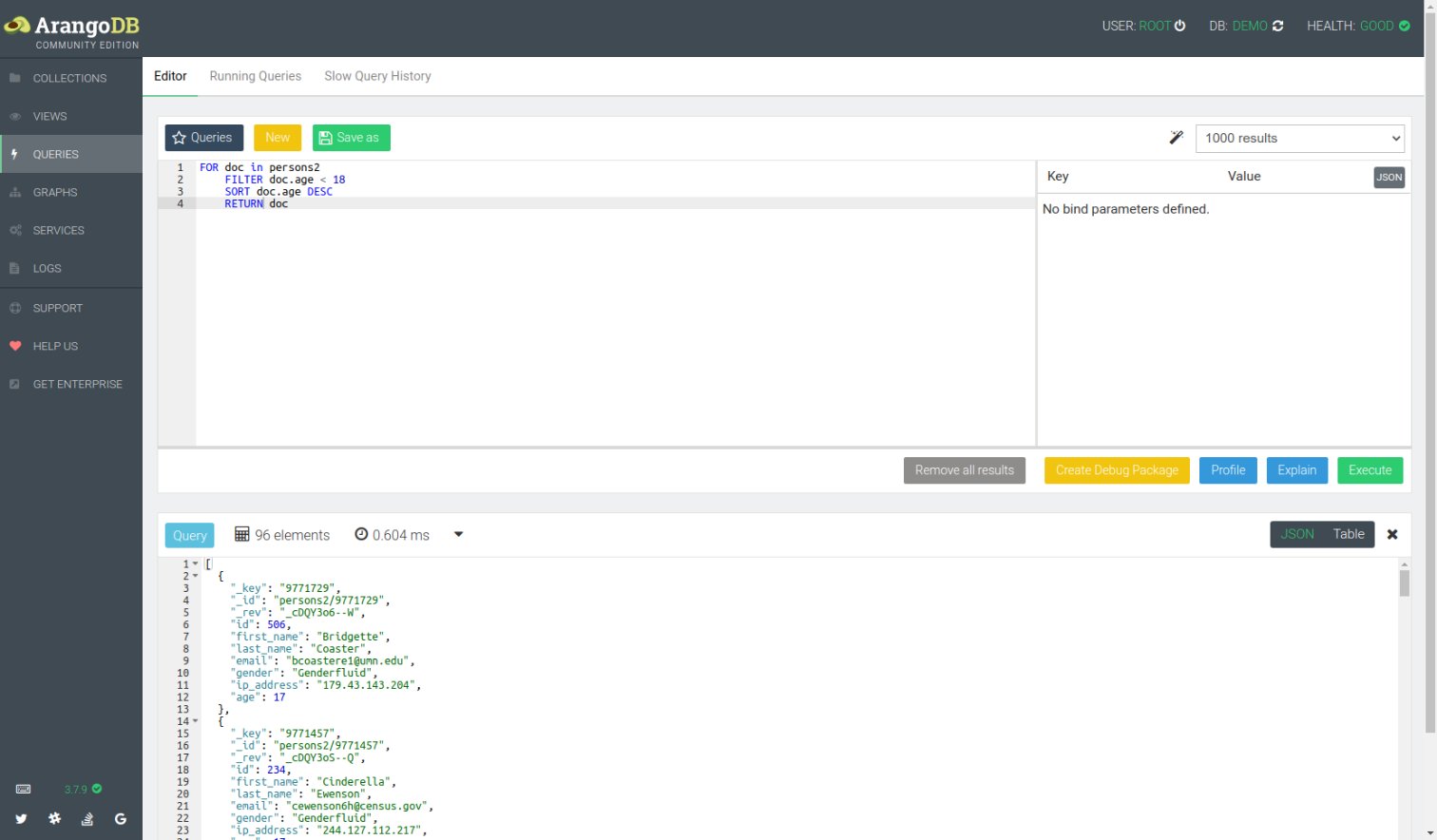
Abbildung 3: Das Resultat einer AQL-Anfrage als JSON …
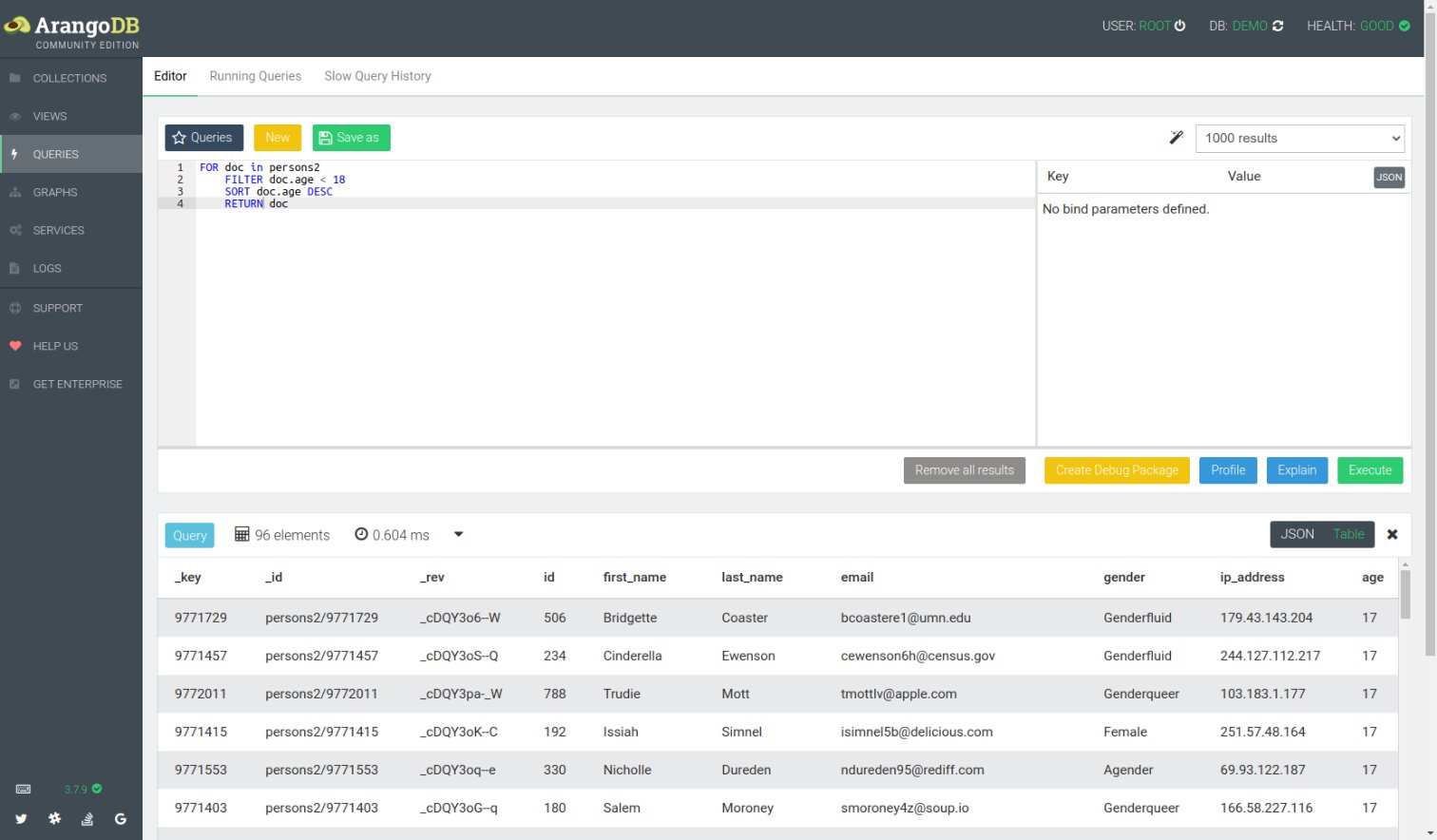
Abbildung 4: … und in der Darstellung als Tabelle.
Asynchrone Ausführung
Für das asynchrone Verarbeiten von Code kennt Python 3 die Schlüsselworte »async« zur Definition einer Coroutine und »await«, um auf deren Resultat zu warten. Python-arango tut sich mit der asynchronen Verarbeitung etwas schwer; das ist der langen Historie des Moduls und der bestehenden Kompatibilität mit Python 2.7 geschuldet.
Für das asynchrone Verarbeiten bedient sich Python-arango eines »ASyncDatabase«-Objekts, das dieselbe API wie das Database-Objekt hat, aber statt des Resultats einer Query ein Job-Objekt zurückliefert, dessen Status man im Laufe der Verarbeitung selbst abfragen kann.
Anhand der While-Schleife in Listing 6 und des expliziten »time.sleep()«-Aufrufs sieht man, dass die asynchrone Verarbeitung mit Python-arango sehr umständlich realisiert wurde. Glücklicherweise hat die Python-Community mit Aioarangodb [5] einen Fork von Python-arango geschaffen, über den sich die Async-Funktionalität moderner Python-Versionen auch mit ArangoDB nutzen lässt (Listing 7).
Listing 6
Asynchronität
client = ArangoClient()
db = client.db("demo", username="..", password="..)
async_db = db.begin_async_execution(return_result=True)
async_aql = async_db.aql
async_col = async_db.collection("demo")
job = async_col.insert({"name": "Peter"})
while job.status() != 'done':
time.sleep(0.01)
job = async_aql("FOR doc in demo RETURN doc")
while job.status() != 'done':
time.sleep(0.01)
Listing 7
Aioarangodb
from aioarangodb import ArangoClient
client = ArangoClient(hosts="http://localhost:8529")
sys_db = client.db("_system", username="..", password="..")
await sys_db.create_database("demo")
db = await client.db("demo", username="..", password="..")
persons = await db.create_collection("persons")
await persons.insert({"name": "Jane"})
cursor = await db.aql.execute("FOR doc in students RETURN doc")
students = [doc["name"] async for doc in cursor]
Graphen in ArangoDB
Zur Modellierung von Dokument- und Datenbeziehungen bietet ArangoDB eine Graphenkomponente an, mit der sich Datenstrukturen wie Bäume und Graphen abbilden lassen [6]. Hierzu gibt es spezielle Kollektionen für Knoten (Vertices) und Kanten (Edges), wie Listing 8 demonstriert.
Listing 8
Modellierung von Graphen
client = ArangoClient(hosts="http://localhost:8529")
db = client.db("test", username="root", password="..")
# Neuen Graph school anlegen
graph = db.create_graph("school")
# Knoten-Collection anlegen für Studenten und Vorlesungen
students = graph.create_vertex_collection("students")
lectures = graph.create_vertex_collection("lectures")
# Relation register zwischen Studenten und Vorlesungen anlegen
edges = graph.create_edge_definition(
edge_collection="register",
from_vertex_collections=["students"],
to_vertex_collections=["lectures"]
)
# Studenten und Vorlesungen anlegen
students.insert({"_key": "01", "full_name": "Anna Smith"})
students.insert({"_key": "02", "full_name": "Jake Clark"})
students.insert({"_key": "03", "full_name": "Lisa Jones"})
lectures.insert({"_key": "MAT101", "title": "Calculus"})
lectures.insert({"_key": "STA101", "title": "Statistics"})
lectures.insert({"_key": "CSC101", "title": "Algorithms"})
# Studenten mit Vorlesungen verknüpfen
edges.insert({"_from": "students/01", "_to": "lectures/MAT101"})
edges.insert({"_from": "students/01", "_to": "lectures/STA101"})
edges.insert({"_from": "students/01", "_to": "lectures/CSC101"})
edges.insert({"_from": "students/02", "_to": "lectures/MAT101"})
edges.insert({"_from": "students/02", "_to": "lectures/STA101"})
edges.insert({"_from": "students/03", "_to": "lectures/CSC101"})
# Breitensuche, die für Anna Smith alle Vorlesungen ermittelt
result = graph.traverse(
start_vertex="students/01",
direction="outbound",
strategy="breadthfirst"
)
Fazit
ArangoDB präsentiert sich als vielseitiger Allrounder unter den NoSQL-Datenbanken, der sich auch im Enterprise- und Cloud-Umfeld sehr gut einsetzen lässt. Zu seinen großen Vorteilen zählt die Möglichkeit, Graphen auf Datensätze zu definieren und damit die Vorteile einer dedizierten Graphdatenbank wie zum Beispiel Neo4J auch in einer klassischen Document Database nutzen zu können.
Clustering und Replikation unterstützen den Aufbau ausfallsicherer Systeme entweder in der Cloud, On-Premises oder als gemanagte Lösung ArangoDB OASIS. Viele weitere erwähnenswerte Features wie View, ArangoSearch und das ReST-Framework Foxx können wir hier nur erwähnen.
Im Projektalltag des Autors hat sich ArangoDB bestens bewährt und gehört neben PostgreSQL für relationale Datenmodelle und InfluxDB für Zeitreihen zu seinen Standardwerkzeugen, die er in kleinen und sehr großen Projekten erfolgreich einsetzt. (jcb/jlu)
Der Autor

Andreas Jung arbeitet seit 28 Jahren mit Python und realisiert als Freiberufler Python-Applikationen im Bereich Web, Plone CMS, Electronic Publishing, Pharma und Medizin. Für den medizinischen Fachverband DGHO e.V. betreut er das Leitlinienportal Onkopedia. Sein Projekt Print-css.rocks beleuchtet die Generierung von hochqualitativen PDF-Dokumenten mithilfe von HTML/XML und CSS auf Basis von CSS Paged Media.
Infos
- ArangoDB: https://arangodb.com
- ArangoDB OASIS: https://cloud.arangodb.com
- AQL: https://www.arangodb.com/docs/stable/aql
- Python-arango: https://docs.python-arango.com
- Aioarangodb: https://github.com/bloodbare/aioarangodb
- Graph-Tutorial: https://arangodb.com/learn/graphs/graph-course





