
© Igor Zakharevich, 123RF
Algorithmen zur Deduplizierung von Listenelementen kommen oft als Einstellungsfragen vor, aber auch in der Praxis bei der Verschlankung von Datensammlungen. Mike Schilli zeigt seinen bevorzugten schnellsten Weg.
Entgegen der allgemeinen Vorstellung vom glamourösen Programmieralltag in großen Software-Schmieden (Abbildung 1) verdienen Industriesöldner ihr tägliches Brot doch hauptsächlich durch das Lösen allseits bekannter Probleme [1]. Eine oft auftauchende Aufgabe ist das Entfernen von mehrfach auftretenden Elementen in einem Array. Dabei gilt es oft, die ursprüngliche Reihenfolge der Einzelelemente beizubehalten und nur die Duplikate wegzulassen sowie die entstehenden Lücken durch Nachrücken zu füllen.
Ein Systemadministrator löst das Problem normalerweise ratzfatz mit dem Befehl »cat items | sort | uniq«. Das taugt für Aufgaben, bei denen die Reihenfolge der Einträge im Ergebnis keine Rolle spielt und die Anzahl der Zeilen in »items« nicht größer als ein paar Tausend ist. Die Größe des Arrays schlaucht insbesondere die Sort-Funktion, die im Normalfall mit O(n log n) skaliert und deren Laufzeit deshalb mit der Anzahl der Elemente etwas stärker als linear anwächst. Muss die Reihenfolge der Elemente konstant bleiben, braucht man einen anderen Ansatz.
Abbildung 1: Ein sehenswerter Clip über Fiktion und Realität im Programmieralltag. Quelle: Youtube
Naiv rattern
Nun könnte eine Funktion mit einem Index »i« durch den Array rattern, und, bevor sie einen Eintrag im Array belässt, prüfen, ob der bisher schon einmal auftrat, indem sie mit einem zweiten Index »j« von vorn beginnt und diese Bedingung bis zum aktuellen Eintrag prüft. Das schont zwar den Speicher, treibt aber die Laufzeit in die Höhe, die dadurch quadratisch auf O(n2) ansteigt.
Als Gedächtnis für schon einmal aufgetretene Elemente eignet sich oft eine Hash-Tabelle, die neue Einträge in Nullkommanichts entgegennimmt und auch ebenso schnell prüft, ob ein Eintrag bereits vorkam. Die exakte Zugriffszeit hängt von der Implementierung der Tabelle und deren Bucket-Konfiguration ab, beträgt aber praktisch O(1). Der einzige Nachteil liegt im Memory-Aufwand, denn die Tabelle muss alle Einträge des Arrays aufnehmen. Daher eignet sich das Verfahren nicht für Monster-Arrays, die nicht in den flüchtigen Speicher des Rechners passen.
Schneller mit Gedächtnis
Das Programm in Listing 1 zeigt die Lösung als Go-Source-Code, aus der »go build dedup.go« ein Binary »dedup« generiert, und das Ergebnis (Listing 2) stimmt.
Listing 1
dedup.go
package main
import (
"fmt"
)
func main() {
list := []string{"foo", "bar", "foo",
"baz", "foo", "zap"}
fmt.Printf("original: %v\n", list)
list = deDup(list)
fmt.Printf("deduped: %v\n", list)
}
func deDup(orig []string) []string {
wIdx := 0
dup := map[string]bool{}
for i := 0; i < len(orig); i++ {
_, ok := dup[orig[i]]
if ok {
continue
}
dup[orig[i]] = true
orig[wIdx] = orig[i]
wIdx++
}
orig = orig[:wIdx]
return orig
}
Listing 2
Ergebnischeck
$ ./dedup
original: [foo bar foo baz foo zap]
deduped: [foo bar baz zap]
Listing 1 definiert ab Zeile 16 die Funktion »deDup()«, die ein String-Slice entgegennimmt. Sie entfernt daraus die Duplikate und gibt das neue, deduplizierte und deswegen vielleicht geschrumpfte Array-Slice zurück. Der Code definiert zwei Index-Läufer, »i« zum Lesen und »wIdx« zum Schreiben (Abbildung 2). Mit »i« schreitet er das Array-Slice von vorn nach hinten ab und sieht sich mit »orig[i]« jeweils den Inhalt des aktuellen Elements an.
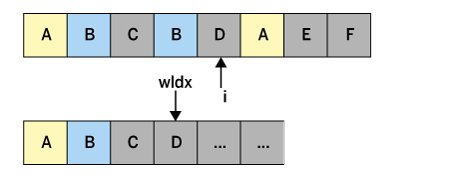
Abbildung 2: Die Zähler »i« und »wIdx« rattern von links nach rechts durch das Original.
Kam das aktuelle Element bislang noch nicht vor, kopiert Zeile 26 den Eintrag am Index »i« an die Stelle, auf die der Index »wIdx« zeigt. Dann erhöht »deDup« beide Zähler um eins und geht in die nächste Runde.
Stellt sich das aktuelle Element hingegen als Duplikat eines bereits gelesenen Elements heraus, erhöht die For-Schleife zwar den Lesezähler »i«, belässt aber den Schreibindex »wIdx« auf dem alten Wert. Kopiert wird in diesem Fall nichts, und wegen des konstant belassenen Schreibindex kommt das nächste, ungesehene Element auf den Platz, auf dem vorher ein Duplikat war.
So geht es weiter, bis der Leseindex am rechten Ende des Array-Slices anschlägt. Zeile 30 terminiert dann die eventuell geschrumpfte Datenstruktur am Index »wIdx«, ab dem keine Schreibvorgänge mehr stattfanden.
Blitzschnell mit Maps
Um Duplikate zügig zu erkennen, definiert Zeile 18 eine Hash-Map »dup«, mit Strings als Schlüsseln sowie einem booleschen Wert (»true« oder »false«). Zeile 21 prüft bei jedem Durchgang, ob das aktuell untersuchte Array-Element schon in der Hash-Map liegt. Dabei ignoriert es mit »_« den eventuell zurückkommenden Wert und untersucht nur die Variable »ok«. Sie liefert »true«, falls die Map den Wert enthält, und anderenfalls »false«.
Streng genommen müsste der Hash auch nur Schlüssel und keine zugehörigen Werte führen: Schließlich bestimmt die bloße Existenz eines Eintrags, unabhängig vom zugewiesenen Wert, ob ein fraglicher Ausdruck vorher schon auftrat. In diesem Sinn handelt es sich bei den zu sammelnden Daten um ein Set, und eine Funktion muss nur schnell prüfen, ob ein neuer Wert schon Teil des Sets ist. Statt mit »map[string]bool« zu arbeiten, könnte so eine leere Struktur als Wert zu jedem Hashmap-Eintrag zum Einsatz kommen [3]. Allerdings spart dieses Verfahren nur wenig Speicher und ist etwas umständlicher zu lesen.
In-place oder ausgelagert
Je nach Größe des zu deduplizierenden Datenfelds stellt sich die Frage, ob der Algorithmus ein neues Array mit kopierten Elementen anlegen soll oder einfach das bereits existierende in-place modifiziert. Letzteres ist ohne Frage effizienter und geht sparsamer mit den verfügbaren Ressourcen um, während die erste Methode vielleicht bei kurzen Arrays sinnvoll wäre, falls man deren Originalinhalt anderswo noch braucht.
Nun übergibt Go Array-Slices definitionsgemäß by value, also als Wert und nicht als Pointer. Allerdings ist ein Array-Slice in Go nur eine Minimalstruktur, die das erste Element und die Länge eines darunterliegenden Arrays definiert, auf den sie mittels eines Pointers verweist. Übergibt ein Go-Programm einen Array-Slice an ein Unterprogramm, reicht es zwar diese Minimalstruktur by value weiter, aber den darunterliegenden Array indirekt als Pointer.
Vom Unterprogramm vorgenommene Veränderungen im Array-Slice bleiben daher später auch im Hauptprogramm sichtbar, lange nachdem das Unterprogramm seine Arbeit erledigt hat. Was das Unterprogramm allerdings nicht verändern kann, selbst wenn es darauf herumorgelt, ist die Rahmenstruktur des Array-Slices: Die wurde als Wert übergeben, nicht als Pointer.
Inhalt änderbar, Länge nicht
Im Endeffekt kann also das Unterprogramm also zwar nach Gutdünken Elemente des übergebenen Array-Slices verändern, aber dessen Länge weder verkürzen noch vergrößern: Diese Information steht in der Rahmenstruktur, nicht im darunter liegenden Array. Eine Funktion wie »Strings()« aus dem Standardfundus von Gos sort-Paket nimmt einfach ein Array-Slice von Strings als Wert entgegen (kein Pointer) und modifiziert die Elemente des darunterliegenden Arrays (indirekt per Pointer referenziert), was das Hauptprogramm später auch so sieht. Da beim Sortieren keine Längenanpassung erfolgt, muss das Unterprogramm auch nicht tricksen.
Damit eine Funktion wie unser »deDup()« nun auch auf die Länge des modifizierten Arrays Einfluss nehmen kann, gibt es zwei Möglichkeiten. Im einfachsten Fall gibt die Unterfunktion das neue, in der Länge angepasste Slice zurück, sodass das Hauptprogramm es mit »slice = deDup(slice)« wieder aufschnappen kann. Alternativ kommt die Pointer-Methode zum Einsatz.
Dabei übergibt das Hauptprogramm das Slice als Pointer (»&slice«). Das Unterprogramm muss, um auf Elemente zuzugreifen, zuerst den Pointer dereferenzieren. Das erste Element des als Pointer überreichten Array-Slices »slice« käme so mit »(*slice)[0]« zutage. Die Klammern sind essenziell – sonst würde Go versuchen, das Array-Element zu dereferenzieren und nicht das Array-Slice als solches. Nach getaner Arbeit sieht dann das Hauptprogramm ein eventuell geschrumpftes Array-Slice. Letzteres wurde als Pointer übergeben, und deshalb kann das Unterprogramm auch dessen Rahmenstruktur so anpassen, dass es das Hauptprogramm mitbekommt.
Wegen der schlanken Rahmenstruktur macht es keinen großen Performance-Unterschied, welchen Weg der Programmierer hier wählt. Die explizite Zuweisung des Rückgabewerts hilft aber vielleicht dem nächsten Bearbeiter des Codes, zu verstehen, dass sich die Länge des Array-Slices bei diesem Verfahren eventuell im Hauptprogramm ändert. Manchmal ist etwas weitschweifiger Code tatsächlich besser, wenn er sinnfällig verdeutlicht, was hinter den Kulissen abläuft. Der Kollege in der Wartung wird es dem Originalautor danken. (uba/jlu)
Infos
- “What people think programming is vs. how it actually is”: https://www.youtube.com/watch?v=HluANRwPyNo
- “The empty struct”: https://dave.cheney.net/2014/03/25/the-empty-struct
- Listings zu diesem Artikel: http://www.linux-magazin.de/static/listings/magazin/2021/02/snapshot/





