
© Wichai Wongjongjaihan, 123RF
Teure Performance-Engpässe kann man durch vorausschauende Erweiterung vermeiden. Doch wie viel man wovon tatsächlich braucht, lässt sich oft schwer sagen. Monitoring-Daten helfen bei der Prognose.
Das zunehmende Outsourcing von IT-Infrastruktur hat einen Pferdefuß: Es erschwert die Prognose des zukünftigen Bedarfs. Das liegt daran. dass nicht alle IT-Service-Provider Einblick in den realen Ressourcenverbrauch erlauben beziehungsweise die Metriken oft nur für kurze Zeiträume verfügbar machen. Das erschwert Langzeitprognosen: Die Nutzer müssten die Daten regelmäßig auslesen und mühsam selbst aufarbeiten. Die Abstraktion von physischer Hardware kompliziert Kostenanalysen zusätzlich.
Mehr Informationen hat man in der Regel zur Hand, wenn ein Dienstleister die Infrastruktur vor Ort zur Verfügung stellt. Doch auch dann ist die Aufzeichnung genauer Metriken noch aufwendig. Zudem braucht es komplexe Analysemethoden, um Zusammenhänge zwischen einzelnen Messwerten richtig zu verstehen und Verzerrungen durch kurzzeitige Einflüsse zu vermeiden. Das gelingt nur mit ausgefeilten mathematischen Methoden. Die Kunden aber erwarten zunehmend solche kompetenten Capacity-Vorhersagen von ihrem Service-Provider. Sie wandern ab, wenn die Auskünfte ungenau sind und entweder unerwartete Mehrkosten entstehen oder sich das Gefühl breit macht, die Ressourcen würden nicht optimal genutzt.
Dieser Artikel erläutert einen praktischen Lösungsansatz für Capacity Management als Dienstleistung. Dabei nutzt der Service-Provider Metriken aus dem IT-Monitoring zum Erstellen von Prognosen für seine Kunden. Fortschrittliche Datenanalyseverfahren erkennen zeitweise Veränderungen des Ressourcenverbrauchs als Trend und passen die Vorhersage automatisch an. Durch Integration der Analyse in das Monitoring vereinfacht sich die praktische Anwendung.
Capacity Management für Kernbankensysteme
Die Idee für diesen Ansatz entstand im Rahmen eines Projekts im Finanzbereich. Der Kunde betreibt in diesem Fall die Systeme für mehrere Banken und hostet sie auf seiner Infrastruktur. Core-Banking-Systeme – bei Core handelt es sich um ein Akronym für Centralized Online Real-time Exchange – verarbeiten eine große Menge an Transaktionsdaten mit hohem Durchsatz. Sie gehören seit vielen Jahren zum Standard in Banken.
Verändert sich bei einem Kunden beispielsweise der Status von Einlagen und Krediten oder kommt es zu einer anderen Buchung, überträgt die Bank diese Informationen über Datenbanken in das Kernbankensystem, das die Anpassung sofort verbucht. Da der Input dezentral generiert wird, kann sich die Auslastung der Systeme schnell ändern.
Als Kernbankensysteme in den 1970er-Jahren eingeführt wurden, ging es ursprünglich um die Interaktion verschiedener Bankfilialen. Durch die Digitalisierung verändern sich die Nutzergewohnheiten. Die Erwartungen der Anwender steigen deutlich, und damit auch die Performance-Anforderungen an das Core-Banking. Durch Banking-Apps und Bezahldienstleister erhöhen sich die Anzahl der Transaktionen, und Verzögerungen bei der Datenverarbeitung wirken sich negativ auf die Nutzererfahrung und somit letztendlich auch auf den Umsatz aus.
In eigener Sache
Das Linux-Magazin achtet streng auf die Unabhängigkeit seiner Autoren, die normalerweise nicht über Produkte ihres Arbeitgebers schreiben können. Von dieser Regel gibt es seltene Ausnahmen, die wir dann explizit kenntlich machen – wie diesen Artikel. Die enthaltenen Informationen erschienen uns einerseits als ideale Ergänzung zum Schwerpunktthema dieser Ausgabe, andererseits waren sie nur aus erster Hand zu bekommen. Deshalb sind wir den Kompromiss eingegangen und weisen an dieser Stelle ausdrücklich darauf hin, dass der Autor zugleich einer der Entwickler der vorgestellten Lösung ist.
Ein Service-Provider, der eine entsprechende Umgebung zur Verfügung stellt, kümmert sich um das Einhalten von spezifischen Finance-Standards und garantiert Performance-Vorgaben. Die Kunden buchen in der Regel monatlich anpassbare Pläne mit Zielvorgaben für CPU, RAM und Festplattenspeicher. Aus Datenschutzgründen sowie zur Gewährleistung kontinuierlich hoher Leistung und maximaler Zuverlässigkeit sind Cloud-Anbieter für die Banken selten eine Option. Stattdessen laufen die Systeme samt Datenbanken auf physischen Servern beim Dienstleister. Das verringert im Vergleich zum Deployment in virtuellen Umgebungen auch den Overhead.
Eine Besonderheit: Der Dienstleister kann Limits für CPU und RAM nicht erzwingen. Kernbankensysteme sind derart essenziell für Banken, dass ein hartes Durchsetzen der gebuchten Leistungsvorgaben fatale finanzielle Folgen für die Finanzhäuser hätte. Überlastete Systeme führen zunächst zu Verzögerungen bei der Verarbeitung. Jede Minute Wartezeit entspricht aber realen Umsatzeinbußen, sodass schon bei geringen Performance-Engpässen finanzielle Schäden entstehen. Deshalb ermöglichen Service-Provider in der Regel eine kurzfristige Erweiterung der Rechenleistung und des Arbeitsspeichers bei laufendem Betrieb, um Ausfälle zu vermeiden.
Die Computer in solchen Systemen sind oft Großrechner unter AIX oder Solaris. Sie erlauben eine sichere Segmentierung der Ressourcen über logische Partitionen (LPAR). Jeder Kunde erhält einen getrennten Bereich für seine gebuchte Infrastruktur; gleichzeitig können die Administratoren bei laufendem Betrieb bei entsprechendem Bedarf die Ressourcen erweitern.
Monitoring-Daten spielen eine Schlüsselrolle
Die Banker wollen wissen, in welchem Maße sie ihre Kapazitäten nutzen und ob sie in Zukunft ihre Pläne anpassen sollten. Dabei gilt es, zu bedenken, dass – im Gegensatz zu Public-Cloud-Anbietern – bei physischen Servern vor Ort die Preise für die gebuchten Ressourcen fix sind und man sie nicht etwa nach genutzter CPU-Rechenzeit abrechnen kann. Außerdem kostet das Überschreiten der gebuchten RAM- und CPU-Limits eine hohe Gebühr.
In der Vergangenheit haben die Infrastrukturexperten des Dienstleisters Capacity-Management-Reports für einzelne Kunden manuell erstellt, für die sie Überwachungsdaten verwendeten. Die mathematischen Modelle waren einfach, weshalb die Admins unterschiedliche Zeiträume analysieren mussten, um die Auswirkung verschiedener Vorkommnisse abzuschätzen.
Allerdings ergaben sich nun je nach gewähltem Zeitraum unterschiedliche Vorhersagen – abhängig davon, welches Event die Messwerte beeinflusst hatte. Auch fehlten Kontextinformationen zu den Events, um die unterschiedlichen Prognosegraphen zu interpretieren. Dadurch enthielten die Berichte zwar wichtige Empfehlungen, aber es fehlte an Präzision.
Das sollte sich ändern: Man suchte nach einer Analysetechnik, die genauere und verständliche Resultate liefern sollte. Als Grundlage für die Kapazitätsanalysen sollten die Überwachungsdaten der hauseigenen Monitoring-Software Checkmk dienen, die bereits vielfältig im Einsatz war. Sie überwachte die Netzwerksegmente der Kunden, diente der Steuerung der erwähnten kurzfristigen Ressourcenerweiterungen von CPU und RAM und wurde von der Buchhaltung benutzt, um die Kundenpakete und eventuelle Zusatzleistungen abzurechnen.
Automatisierte Capacity-Management-Analyse
Checkmk bietet durch zahlreiche Plugins eine breite Palette an Monitoring-Informationen und enthält von Haus aus eine eigene Graphing-Engine, die künftige Entwicklungen prognostizieren kann. Sie war jedoch auf Anomalieerkennung und entsprechende Alarmierung ausgelegt. Die Engine eignete sich daher nicht für Voraussagen über den zukünftigen Ressourcenbedarf. Deshalb baute das Entwicklerteam eine neue Forecast-Engine.
Capacity-Management-Analysen erfordern raffinierte Algorithmen, die mit nichtlinearen Verläufen zurechtkommen. Gerade bei der CPU-Auslastung sieht man häufig einen sprunghaften Anstieg, wenn zum Beispiel eine neue Applikation auf dem Server gestartet wird. Dies zeigt Abbildung 1. Eine lineare Extrapolation (orange) würde von einem kontinuierlich steigenden Bedarf ausgehen, während sich die Auslastung (blau) in der Realität nach einem Anstieg auf dem neuen Niveau einpendelt.
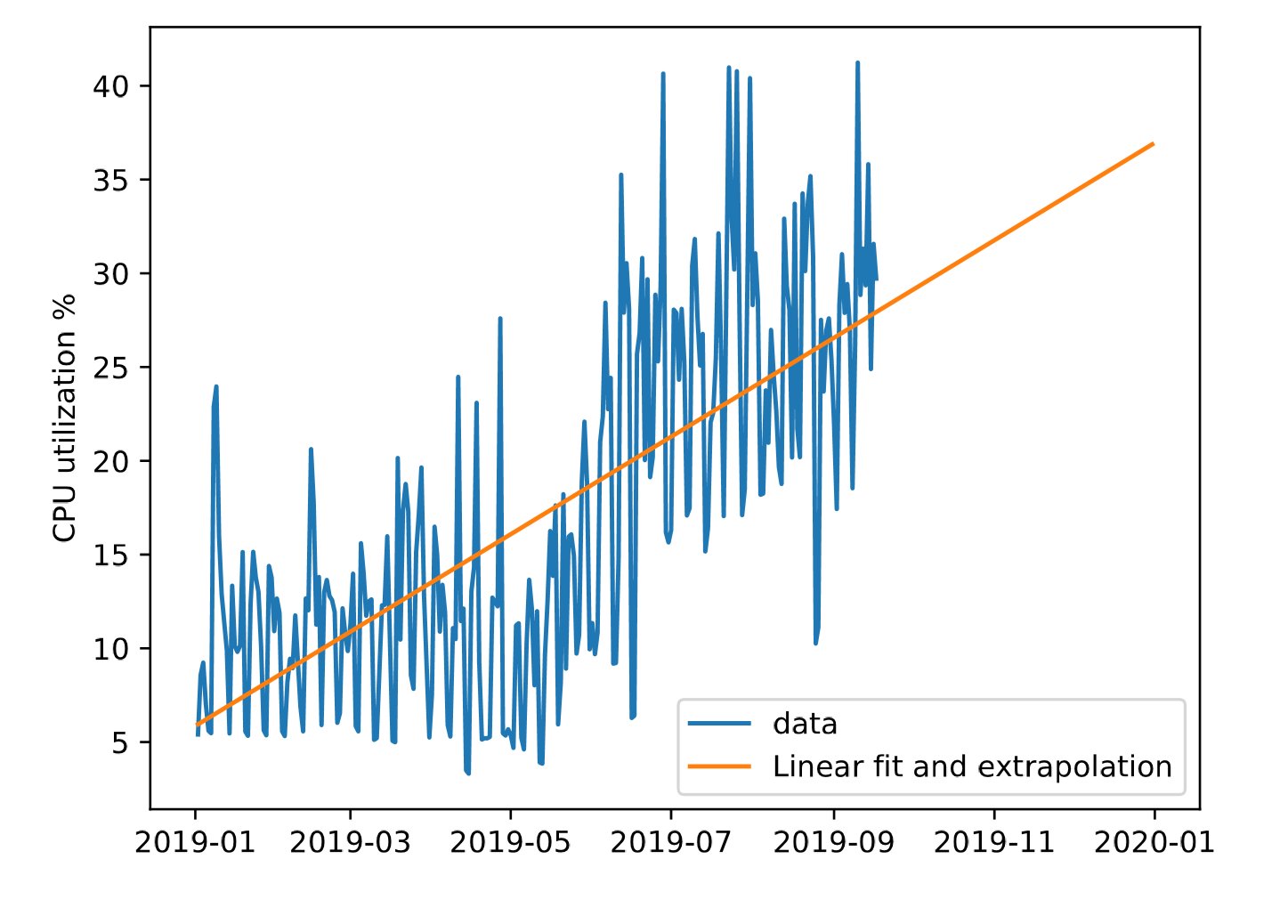
Abbildung 1: Eine lineare Regression würde den sprunghaften Anstieg des CPU-Verbrauchs als als ununterbrochene Steigerung interpretieren.
Diese Sprungeffekte sowie eine relativ starke Streuung der Messwerte machen eine zuverlässige Voraussage mit einfachen Methoden schwierig. Die Entwickler wollten die Analysefähigkeit so weit entwickeln, dass die Prognosefunktion reale Trends entsprechend erkennt und einbezieht.
Die nötigen Verfahren samt Code-Grundlage fanden sich in der Open-Source-Library Prophet von Facebook. Das Entwicklungsteam des IT-Dienstleisters verschlankte die Codebasis deutlich, entfernte unnötige Abhängigkeiten und integrierte alles in Checkmk. Im Ergebnis kann die Vorhersagefunktion Umbrüche erkennen und den ursprünglichen Graphen bei Bedarf in Abschnitte zerlegen. Für diese Segmente nähert die Engine dann je eine Funktion an und fügt diese zum Schluss wieder zu einem Graphen zusammen.
Die Anpassungsfähigkeit der Funktionen an Veränderungen steuert Checkmk über bedingte Wahrscheinlichkeiten mithilfe des Satz von Bayes. Dabei haben die Entwickler fünf Schwellwerte für die bedingte Wahrscheinlichkeit vorbereitet, die entscheiden, wie schnell der Graph auf eine Veränderung reagieren soll. Das Monitoring überträgt also eine gewünschte Metrik in die Forecast-Engine. Der Graph erkennt mögliche Trendentwicklungen in der Vergangenheit und nähert sich den realen Messwerten besser an. Dadurch ändert sich auch der Verlauf der Vorhersage.
Abbildung 2 zeigt – auf Basis derselben Messwerte wie in Abbildung 1 – den neuen Graphen. Dabei wurde im Modell die bedingte Wahrscheinlichkeit zur Annahme von Änderungen als sehr flüchtig (very voluble) angenommen. Das ist die höchste der fünf möglichen Stufen; damit passt sich der Graph relativ schnell an Trends an.
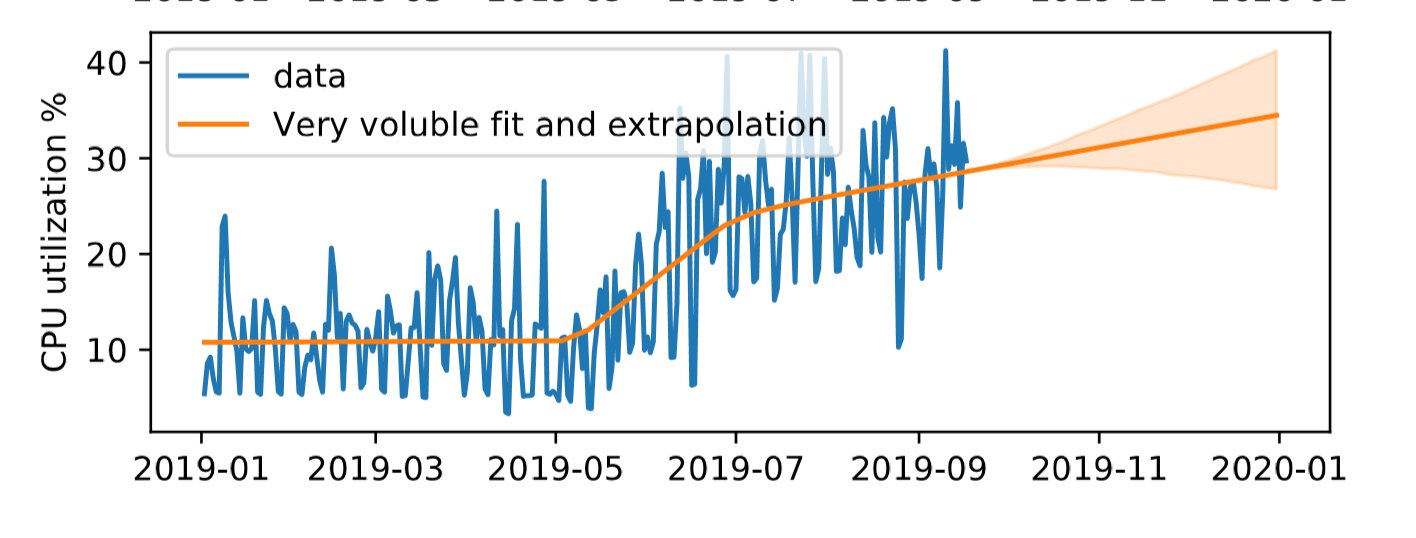
Abbildung 2: Die neue Vorhersage-Engine passt sich den beobachteten Daten auf nichtlineare Weise an und modelliert damit einen stufenweisen Anstieg.
Auf derselben Datengrundlage erkennt die verbesserte Analyse nun mehrere Umbrüche und kann sie für die Prognosefunktion nutzen. Im Vergleich zur Vorhersage zuvor, die auf einer einzigen linearen Funktion basierte, fällt die Prognose der CPU-Auslastung jetzt niedriger aus, weil der Sprung in der Auslastung im Juni 2019 besser miteinbezogen wird. Zudem erkennt man einen Toleranzbereich der Prognose auf Basis der bisherigen Schwankungen (orange schattiert).
Das ist nur ein Beispiel der implementierten Methoden, verdeutlicht aber die Möglichkeiten für das Capacity Management durch die Kombination von Überwachungsdaten und automatischer Analyse. Tatsächlich haben die Entwickler noch weitere Methoden zur Verfeinerung eingebaut. Zum Beispiel nimmt das gezeigte Model noch an, dass – trotz des zunehmenden CPU-Verbrauchs – die Unterschiede zwischen Spitzen- und Ruhephasen bei der Auslastung gleich bleiben.
Das muss aber nicht immer so sein. Um auch saisonale Einflüsse abbilden zu können, helfen Elemente der Fourier-Analyse. Das Team von Checkmk hat hier zwei Funktionen eingebaut, um eine gleichbleibende (Additive Seasonality) und eine proportional wachsende Entwicklung der Saisonalitäten (Multiplicative Seasonality) zu simulieren.
Dank der Integration der mathematischen Methoden in das Monitoring brauchen sich die Admins nicht unbedingt mit den Feinheiten der statistischen Datenanalyse auseinanderzusetzen. Für sie ist es viel wichtiger, dass sie auf diese Weise grundsätzlich zu jeder ausreichend großen Zeitreihe von Verbrauchsdaten Prognosen erstellen können. Prinzipiell unterstützt die Engine alle Metriken und eignet sich nicht nur für Core-Banking-Systeme; jedoch sollte man Prognosen immer auf ihre Praxistauglichkeit prüfen.
Der Dienstleister kann seine Kunden nun mit angepassten Prognosen für gewünschte Metriken auf Basis passender Analysen aus Checkmk versorgen. Je nach Wunsch erfolgt das in Form eines PDF-Reports oder als Echtzeit-View. Die Kunden selbst brauchen keinerlei Erfahrung im Bereich IT-Überwachung, Statistik oder Software-Entwicklung. Sie bekommen ganz einfach einen präzisen Plan für ihr Capacity Management.
Fazit: Mehr Sicherheit für die Planung
IT-Infrastruktur ist komplex, ihre Überwachung noch komplexer. Anstrengungen, um diese Komplexität zu bewältigen, lohnen sich aber: Mit den richtigen Prognosen sparen Unternehmen Geld und können gewährleisten, dass ihre Systeme dauerhaft performant arbeiten. Die Kombination aus Überwachungsdaten mit mathematischer Methodik, die zu einer automatischen Analyse führt, ermöglicht einen Blick in die Zukunft. Die Kunden erhalten wesentlich präzisere Prognosen und können sicher in die Zukunft planen. Neben der Vorhersage sehen sie die Auswirkung von Events in der Vergangenheit und könne diese besser beurteilen. (jcb)





