
© sxwx, 123RF
Werkzeuge, die auf dem erweiterten Berkeley Packet Filter basieren, ermöglichen Performance-Messungen direkt im Kernel.
Die Abkürzung eBPF steht für Extended Berkeley Packet Filter [1]. Der ursprüngliche Berkeley Packet Filter (BPF) datiert zurück auf 1992. Er wurde geschrieben, um einen direkten Zugriff auf die Sicherungsschicht zu ermöglichen, den Layer 2 im OSI-Modell. BPF erlaubte es Userspace-Programmen, Netzwerkpakete auf effiziente Weise zu empfangen, zu filtern und zu senden.
Ab dem Kernel 3.18 bauten die Entwickler die virtuelle Maschine hinter dem Berkeley Packet Filter deutlich aus. Sie ließ sich nun auch für andere Dinge einspannen als den Netzwerkverkehr und wuchs unter anderem zu einem Profiler für den kompletten Stack. Der Linux-Kernel unterstützt die erweiterte virtuelle Maschine, die den Namen eBPF trägt. Das klassische BPF, auch cBPF genannt, gilt inzwischen als weitgehend obsolet. Wer also heute von BPF redet, meint in der Regel eBPF.
Bei eBPF handelt es sich um ein Framework, das Events verarbeitet. Es kommt häufig für das Monitoring zum Einsatz, lässt sich aber auch für Prozesse im Netzwerk-Stack verwenden. Moderne Versionen von eBPF bringen zusätzlich einen JIT-Compiler mit. Er übersetzt die zugehörigen Programme für die virtuelle Maschine in nativen Opcode, um im Kernelspace eine möglichst hohe Effizienz zu erreichen. Am Ende laufen sowohl die interpretierten als auch die kompilierten eBPF-Programme als reguläre Instruktionen auf der CPU. Aus Sicherheitsgründen verfügen die eBPF-Programme jedoch nur über eingeschränkte Feature-Sets.
Zwar steckt eBPF-Code seit 2014 im Kernel und ist damit bereits eine Weile im Einsatz, dennoch programmieren die Linux-Entwickler weiterhin daran. Neben größeren Neuerungen für eBPF bringt fast jedes kleinere Kernel-Release zusätzliche Features für eBPF mit [2]. Die reichen von neuen Instrumentierungspunkten, die eBPF-Programme mit Kprobes und anderen sogenannten Kernel-Sonden verbinden, bis hin zu unterschiedlichen neuen Fähigkeiten. Dazu zählen weitere Datenstrukturen und neue Arten, Events zu verarbeiten und zu sammeln.
In den letzten Jahren wurde eBPF zudem in das Performance-Tooling-System integriert, das sich als Framework für die interaktive Performance-Analyse des Linux-Kernel anbietet. Der Artikel stellt später einige der eBPF-basierten Performance-Tools vor.
BPF-Programme
Die eBPF-Programme sind in einer speziellen Assemblersprache geschrieben. Der Kernel lädt sie über den »bpf()«-Systemaufruf, der JIT-Compiler übersetzt sie und führt sie dann in einer Sandbox-Umgebung aus. Üblicherweise klinken sich diese Programme in die dynamischen Analysetools im Kernel ein, die häufig Probes heißen (etwa Kprobes, Uprobes und so weiter). Werden diese Analysetools aktiv, nehmen auch die eBPF-Programme ihre Arbeit auf. Ein Vorteil für Entwickler: Sie gelangen beim Debuggen an Datenstrukturen des Kernels, ohne diesen neu übersetzen zu müssen.
Als vorteilhaft erweist sich, dass eine Verifier-Komponente verschiedene Checks absolviert, bevor sie die Programme akzeptiert. Es ist zwar nicht unmöglich, Fehler einzubauen, aber schwierig. Der Verifier erschwert es zum Beispiel, eBPF-Programme zu schreiben und diese in einen Tracepoint einzufügen, was das System komplett zum Absturz bringen würde. Integriert ein Entwickler zum Beispiel eine Endlosschleife in das eBPF-Programm, lehnt die Validierungskomponente es ab. Es lässt sich dann nicht verwenden.
Aktuell schreiben Entwickler eBPF-Programme in C und übersetzen sie mit dem LLVM-Clang-Compiler in den Bytecode, den eBPF intern verwendet. Da der Übersetzungsprozess üblicherweise Kernel-abhängig verläuft, ist das Installieren von eBPF etwas aufwendiger. Allerdings müssen nur wenige Nutzer eBPF-Programme direkt laufen lassen.
Um diese Hürde zu überwinden, entstand das BCC-Projekt, die BPF Compiler Collection [3]. Sie bringt eine komplette Toolchain mit, um eBPF-Programme zu schreiben, die weniger Kernel-abhängig sind. Abbildung 1 zeigt ein mit Tcpdump erzeugtes eBPF-Code-Beispiel. Tcpdump gehört zu den Werkzeugen, die eBPF zum Filtern der Pakete einsetzen. Das Tool erweist sich auch als praktisch, um eBPF-Programme aufzubrechen und den Assembler-artigen Code zu betrachten, der den Bytecode repräsentiert.
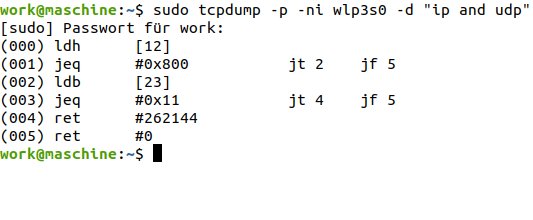
Abbildung 1: Das Netzwerk-Tool Tcpdump setzt auf eBPF und zeigt auch den Bytecode der Programme an.
Userspace vs. Kernelspace
eBPF unterstützt sowohl den User- als auch den Kernelspace. Auf Brendan Greggs Webseite [4] wartet eine anschauliche Illustration, die zeigt, wie eBPF arbeitet (Abbildung 2). Ein Userspace-Programm erzeugt Bytecode, den der Kernel mithilfe des eBPF-Verifiers überprüft.
Das Programm verbindet sich dann mit den Kernel-Analysetools, darunter »kprobes«, »uprobes«, »tracepoints« and »perf_events«. Die in der Grafik gezeigten »maps« dienen als Datenstrukturen, um die von den Kernel-Sonden gesammelten Daten zu transportieren. Am Ende liest ein Userspace-Programm die gesammelten und in den Maps verpackten Daten aus.
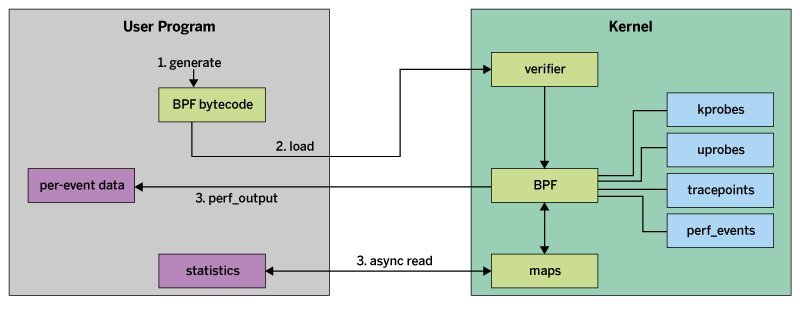
Abbildung 2: Eine der Ideen hinter eBPF ist es, aus dem Userspace möglichst Kernel-nah und effizient Messungen vorzunehmen. Quelle: http://www.brendangregg.com/ebpf.html
Der Blick auf Brendan Greggs Webseite macht auch klar, dass es bereits sehr viele Tools gibt, die eBPF verwenden. Admins müssen also nicht unbedingt eigene Kernel-Sonden oder eBPF-Programme schreiben. eBPF richtet sich ohnehin nur bedingt an einfache Anwender; auch die darauf aufbauenden Tools sind nicht für die breite Öffentlichkeit gedacht.
Tools in Aktion
Im Folgenden stellt der Artikel ein paar dieser Tools und deren Fähigkeiten vor. Nicht alle Werkzeuge stecken dabei in einem einzigen Paket. Wer sich einen Eindruck verschaffen möchte, kann unter anderem in perf-tools-unstable nachsehen. In den instabilen Versionen gibt es meist mehr Features zu testen.
Daneben gibt es das Iovisor-Projekt [5]. Es bietet Tools wie BCC und Ply an, die sich mit einfachen Shell-Skripten kombinieren lassen. Diese beiden Werkzeuge sind relativ ausgereift und auch vergleichsweise einfach zu installieren.
Profile
Profile erlaubt es dem Admin, den Ablauf eines Programms zu verfolgen und nachzuvollziehen, wo in einem Stack die verschiedenen Threads stecken. Das ist anders als zum Beispiel bei Perf, das sich typischerweise auf den CPU-Einsatz konzentriert. Mit Profile erkennt der Admin, ob Threads im Programm hängen. Das kann helfen zu verstehen, weshalb genau ein Programm blockiert und warum es nicht so schnell läuft.
Biolatency
Das nützliche Werkzeug Biolatency misst nicht etwa den Biorhythmus des Admins, sondern den Datendurchsatz von Block-Storage. Das erweist sich speziell zum Aufdecken von Verzögerungen in Cloud-Speichern als wertvoll.
Im Beispiel aus Abbildung 3 benötigen die meisten I/O-Anfragen weniger als 32 Millisekunden. Am unteren Ende taucht jedoch ein Request auf, der zwischen 2 und 4 Sekunden braucht, um fertig zu werden – eine eher schlechte Performance für ein Blockgerät. Das dürfte sich in freier Wildbahn negativ auswirken, etwa, wenn der Admin einen Datenbankserver mit dieser Latenz betreibt.
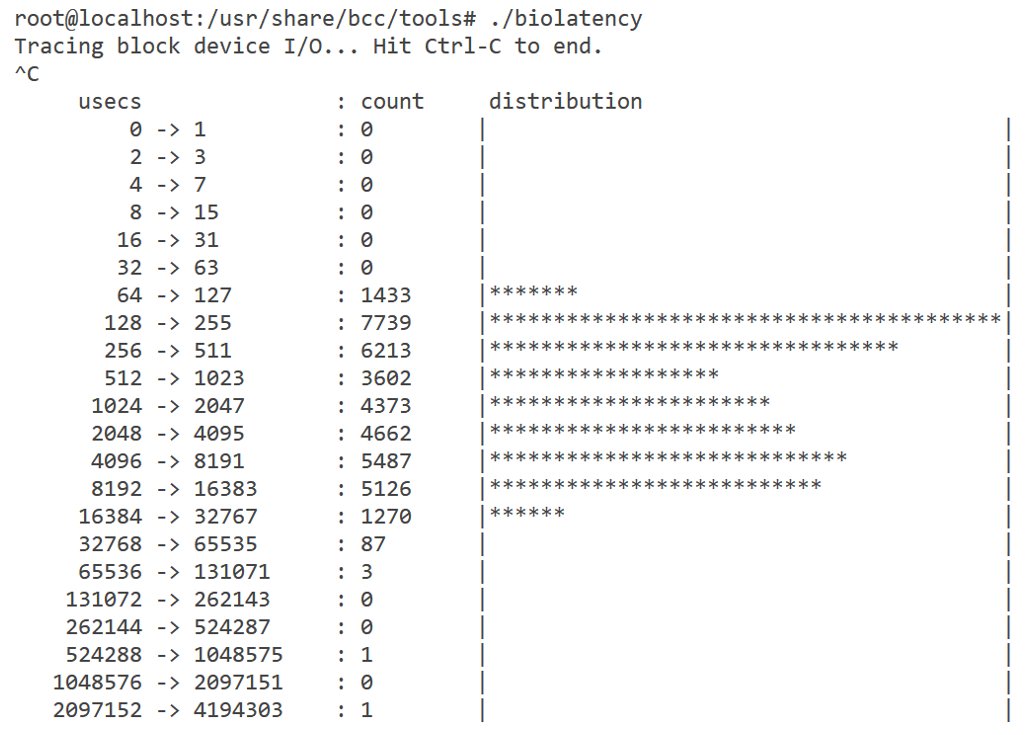
Abbildung 3: Biolatency zeigt an, wie die Latenzen beim Zugriff auf Blockgeräte ausfallen. Insbesondere für Cloud-Speicher ist das interessant.
Biosnoop
Ebenfalls auf den Datendurchsatz von Blockgeräten zielt Biosnoop ab. Wer sich jemals gefragt hat, ob Datenein- und -ausgaben sequenziell ablaufen oder sich zufällig verteilen, kann dies mit Biosnoop recht einfach überprüfen. Mit weiteren Programmen analysiert, plottet und visualisiert der Admin dann die mit Biosnoop gesammelten Messdaten, um so mehr über die Ein- und Ausgabemuster zu erfahren.
Ext4dist
BCC, die BPF Compiler Collection, bietet Werkzeuge an, die auf allen Dateisystemen identisch arbeiten. In der Sammlung warten auch Tools, die sich auf spezifische Dateisysteme wie Ext4 und XFS konzentrieren. Hängen Dateisysteme, liegt das oft am Speicher, mitunter aber auch an Kernel-Problemen. Die Hänger beeinflussen jedoch den Betrieb der laufenden Programme, deren Ein- und Ausgabeoperationen sich nicht im Detail tracken lassen. Ext4dist hilft, indem es Betriebsverzögerungen von Ext4-Systemen entdeckt und als Histogramm anzeigt.
Ext4slower
Ein mit Ext4dist verwandtes Tool heißt Ext4slower. Es geht nicht den Latenzen nach, sondern spürt Ein- und Ausgabeoperationen auf, die nicht den vereinbarten Service-Level-Zielen entsprechen. Damit lassen sich zum Beispiel I/O-Operationen erkennen, die Zeiträume von Millisekunden überschreiten. Die Zeiträume definiert der Admin selbst, Ext4slower zeigt die langsameren Anfragen.
Cachestat
Viele Anwender haben sich schon gefragt, wie effizient der Festplatten-Cache von Linux eigentlich tatsächlich arbeitet. Hält ein System mehr Zugriffe aus, wenn man dem Cache mehr Speicher zuweist? Erhält der Cache tatsächlich mehr oder weniger Zugriffe? Mit eBPF lässt sich das sehr leicht überprüfen. Das Cachestat-Tool zeigt, wie viele lesende Anfragen auf den Cache es insgesamt gab, wie viele gescheiterte Anfragen, wie viele Speicherblöcke berührt wurden und so weiter. Das kann am Ende helfen, die Cache-Performance zu verstehen.
Runqlat
Bei CPU-lastigen Anwendungen gehört es zu den kritischen Fragen, wie lange der Kernel braucht, um der Applikation eine CPU zuzuweisen. Wenn alle CPUs beschäftigt sind, muss die Anwendung warten, bis eine weitere CPU verfügbar wird oder preempted ist. Runqlat prüft die CPU-Run-Queue-Latenz und zeigt dem Anwender, wie lange es dauert, bis der Scheduler die Anwendung ins Rennen schickt. Das ist ein praktischerer Weg, um die Task-Sättigung der CPU zu verstehen, als nur auf die Durchschnittswerte der CPU-Auslastung zu starren.
Execsnoop
Wer sich jemals gefragt hat, welche anderen Tools ein Shell-Skript oder eine Anwendung aufruft, sollte einen Blick auf Execsnoop werfen. Es sieht sich für ein komplettes System oder für eine spezifische Anwendung an, welche anderen Programme diese aufruft. Das hilft, besser zu verstehen, was ein Programm tut und warum Probleme oder Fehler auftauchen.
Einige BCC-Tools erlauben es, Prozesse über die PID zu filtern. Execsnoop tut das nicht. Dafür kann es sehen, wenn ein neuer Prozess mit demselben Namen startet, und so zum Beispiel mehrere Instanzen von »sleep« im Auge behalten: Wenn jemand das Binary unter »/bin/sleep« mehrfach ausführt, erhält es jedes Mal eine neue PID.
Einige Programme rufen zudem, während sie laufen, weitere Instanzen von sich selbst oder andere Binärdateien auf. Neben dem Prozessnamen verfolgt Execsnoop Programme wahlweise anhand der Cgroups, Mount-Namespaces und Linux-User-IDs.
Opensnoop
Opensnoop erweist sich als besonders hilfreich, wenn Programme keine brauchbaren Fehlermeldungen zur Diagnose liefern. Die Rückmeldungen beziehen sich dann oft nur vage auf I/O-Fehler oder fehlende Dateien. Mit Opensnoop vollzieht ein Admin nach, auf welche Dateien ein Programm zuzugreifen versucht. Auf diese Weise findet er heraus, was vermutlich schiefläuft, und kann das Problem hoffentlich beheben. Startet der Anwender Opensnoop ohne Argumente, verfolgt es alle »open()«-Systemaufrufe. Daneben filtert Opensnoop nach Prozessen (über die PID), nach Cgroups, Mount-Namespaces und Linux-User-IDs.
Tcpconnect
Neben den verwendeten Dateien lässt sich auch herausfinden, womit sich die Programme eines Systems verbinden. Mit Tcpconnect ist es möglich, ausgehende TCP-Verbindungen zu verfolgen, um zu verstehen, wie ein Programm funktioniert, und es bei Bedarf zu reparieren.
Tcpretrans
Viele moderne Netzwerke glänzen mit einer niedrigen Latenz. Das ändert sich, sobald Pakete verlorengehen und neu gesendet werden müssen, was große Verzögerungen verursacht. Mit Tcpretrans lässt sich genau beobachten, ob und wo genau im Netzwerk diese Retransmits passieren. Das klappt nicht nur für den Traffic insgesamt, sondern auch für spezifische Verbindungen. Für Letztere lässt sich zudem feststellen, welches Programm und sogar welcher Benutzer involviert sind.
Gethostlatency
Das Auflösen von DNS-Namen kann einen großen Einfluss auf die Performance haben, wenn es darum geht, sich mit einem Dienst zu verbinden. Gethostlatency kümmert sich um zögerliche DNS-Antworten (Abbildung 4).
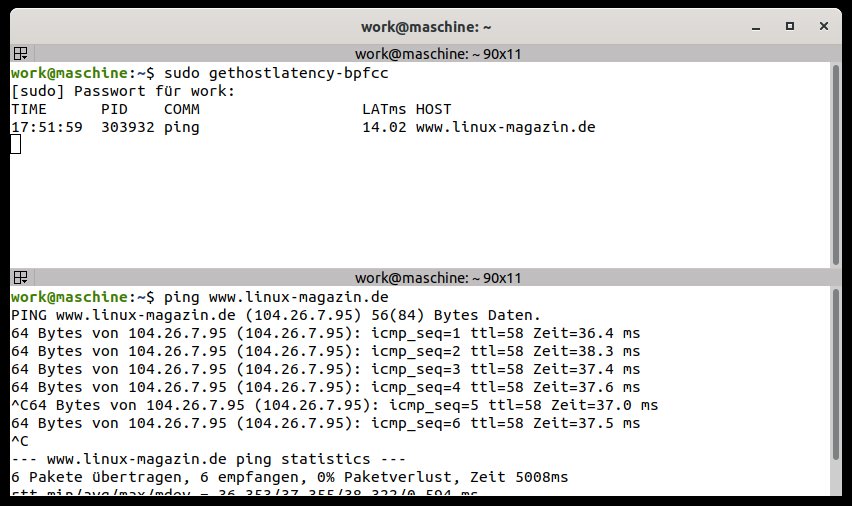
Abbildung 4: Die Latenzen bei DNS-Auflösungen lassen sich mit einem weiteren BPF-basierten Tool erfassen.
… und mehr
Neben den vorgestellten Beispielen umfasst das Portfolio der BPF Compiler Collection (BCC) noch viele weitere nützliche Werkzeuge, die sich zudem permanent weiterentwickeln.
Ply
Das von BCC unabhängige Tool Ply [6] erlaubt es, neben den vorgestellten spezialisierten Tools flexible Skripte einzusetzen. Es verwendet eine eigene Skriptsprache und hilft so, einfache Untersuchungen anzustellen. Ein Admin kann zum Beispiel sagen: “Ich verbinde mich mit diesem Kernel; gib mir ein Histogramm der Return-Werte.” Ply erzeugt dann ein übersichtliches Diagramm dazu.
Ein Beispiel für die Syntax von Ply zeigt Listing 1. Wer sich ein wenig mit Programmierung auskennt, dem fällt es leicht, die angepasste Sprache von Ply zu verstehen und zu erlernen.
#!/usr/bin/env ply
kprobe:SyS_execve {
@exec[tid()] = mem(arg(0), "128s");
i=0;
unroll(16) {
argi = mem(arg(1) + i * sizeof("p"), "p");
if (!argi)
return;
@argv[tid(), i] = mem (argi, "128s");
i = i + 1
}
}
Cloudflare eBPF Exporter
Alle bislang hier vorgestellten Tools analysieren Probleme in Echtzeit. Was aber, wenn ein Admin bereits erfasste Statistiken analysieren möchte? Genau dafür gibt es den eBPF-Exporter [7] von Cloudflare, der auf Github als “Prometheus exporter for custom eBPF metrics” auftaucht [8]. Das Tool gibt es auch in Form einer Binärdatei; daneben finden sich auf Github auch Beispiele, die zeigen, wie sich die eBPF-Dienste für Prometheus instrumentieren lassen [9].
Der eBPF-Exporter nutzt die BCC-Frontend-Bibliothek zum Erfassen der Daten. Er holt sie direkt aus den Ausgaben der BCC-Programme ab und überführt sie ins Prometheus-Format. So integriert er sie in das Dashboard von Prometheus und verwaltet sie dort in einer Time-Series-Datenbank. Der Exporter plottet die Prometheus-Daten mit Grafana, lässt sich mit Alerts versehen und bringt weitere Features mit. Das macht die Metriken des Linux-Kernel auch in Prometheus sichtbar.
Allerdings sollten Admins vorsichtig sein und in Produktivumgebungen den Performance-Overhead von eBPF-Analysen berücksichtigen. Wer zum Beispiel eine sehr komplexe Analyse für eine gängige Operation entwirft, die Millionen Mal pro Sekunde läuft, erzeugt reichlich Overhead. Man sollte also darauf achten, Testszenarien nicht direkt in den Produktivbetrieb zu überführen.
Ausblick
Angesichts des hohen Nutzwerts stellt sich die Frage, wie die Zukunftspläne für eBPF aussehen. Für sehr vielversprechend hält der Autor Bpftrace [10], eine Art funktionsreichen Ersatz für Dtrace. Aktuell erscheint das Werkzeug noch nicht ausgereift und lässt sich auch nicht einfach installieren. Es dürfte sich aber in den nächsten ein bis zwei Jahren zu einem der vielseitigsten eBPF-Tools entwickeln. (kki/jlu)
Der Autor

Peter Zaitsev, CEO und Mitbegründer von Percona, zählt zu den bekanntesten Experten für MySQL-Strategie und -Optimierung. Er hält regelmäßig Vorträge auf Konferenzen und ist Co-Autor des populären Buchs “High Performance MySQL: Optimization, Backups, and Replication”.
Infos
-
eBPF-Dokumentation: https://docs.cilium.io/en/latest/bpf/
-
Status des eBPF-Supports im Kernel: https://github.com/iovisor/bcc/blob/master/docs/kernel-versions.md
-
Brendan Greggs Performance-Webseite: http://www.brendangregg.com/ebpf.html
-
Iovisor-Projekt: https://github.com/iovisor
-
Cloudflare über den eBPF-Exporter: https://blog.cloudflare.com/introducing-ebpf_exporter/
-
eBPF-Exporter-Code für Prometheus: https://github.com/cloudflare/ebpf_exporter
-
Beispiele für den eBPF-Exporter: https://github.com/cloudflare/ebpf_exporter/tree/master/examples
-
Bpftrace: https://github.com/iovisor/bpftrace





