
© kantver, 123RF
In verteilten Setups ist zentralisiertes Logging sehr wichtig. Verschiedene Konzepte stehen zur Verfügung. Wie der Admin das für sich passende findet und realisiert, verrät dieser Artikel.
So mancher Cloud-Apologet möchte andere glauben machen, die Welt bestünde bloß noch aus Containern, Mikroarchitektur-Applikationen und hyperagiler Entwicklung. So ist es freilich nicht: Zwar werden neue Anwendungen heute tatsächlich regelmäßig nach den Cloud-ready-Regeln verfasst, doch auch die klassische Infrastructure-as-a-Service-Dienstleistung nimmt bei den Anbietern noch immer viel Raum ein.
Geändert haben sich in den vergangenen Jahren allerdings die Spielregeln für die Anbieter, die solche Infrastrukturen zur Verfügung stellen. Wo man früher noch für den jeweiligen Einzelfall Virtualisierungsumgebungen strickte, entstehen heute riesige Computing-Farmen, die die Kunden der Plattformbetreiber häppchenweise konsumieren: immer nur so weit, wie tatsächlich notwendig. Entsprechende Software, die solche Workloads verwaltet, steht längst zur Verfügung: OpenStack wickelt den IaaS-Teil ab, Kubernetes auf echtem Blech oder auf OpenStack den Container-Teil.
Mehr Komplexität
Das macht die Umgebungen, mit denen man es zu tun hat, allerdings nicht weniger komplex. Das gilt sowohl für die Plattformanbieter als auch für die Admins, die virtuelle Workloads betreiben.
Computing-Farmen stellen ihre Admins vor erhebliche Herausforderungen. Das gilt besonders, wenn etwas schiefgeht: In verteilten Umgebungen ist es viel schwieriger, die Ursache eines Problems herauszufinden, als in kleinen konventionellen Setups. Das liegt an der Vielzahl der Komponenten, die zusammenspielen.
In OpenStack etwa kümmern sich etliche API-Dienste um das Beantworten von Anfragen. Sie schreiben in einen Messaging-Bus – zumeist RabbitMQ – Befehle, die Agenten auf den Compute-Knoten abfangen und lokal ausführen. Für Software Defined Networking kommt Open vSwitch zum Einsatz, das eigene Dienste mitbringt und auf den Zielsystemen durch eigene Agenten gesteuert wird. Auf den Controller-Knoten spielt auch noch MariaDB mit, meist in Kooperation mit der Cluster-Lösung Galera.
Funktioniert alles wie geplant, ergibt sich ein rundes, tolles Setup. Geht aber auf einem Controller-Knoten etwas schief, führt das im schlimmsten Fall dazu, dass auf beliebigen Compute-Knoten Fehlermeldungen auftauchen, die im ersten Moment unverständlich sind.
Kaum besser ergeht es den Admins, die etwa Workloads innerhalb von Kubernetes betreiben: Sie sehen sich mit einer Vielzahl von Containern konfrontiert, die schlimmstenfalls riesige Mengen an Protokolldateien produzieren und ständig kommen und gehen: Skalierbarkeit ist ein Kernprinzip von Containern. Steigt die Last, steigt die Zahl der Container verschiedener Komponenten.
Zentralisiertes Logging
Klar ist daher: In großen verteilten Setups zählt zentralisiertes Logging zu den wichtigen Erfolgsfaktoren. Am Markt existieren allerdings mehrere Lösungen für das Problem. Sie unterscheiden sich radikal im Hinblick auf ihre Architektur und auch im Hinblick auf die gebotenen Funktionen. Dennoch haben sie, je nach Ziel und Setup, alle durchaus ihre Daseinsberechtigung.
Die Krux für den Admin: Ohne Vorwissen oder ausführliche Tests lassen sich die Vor- sowie Nachteile einer Lösung kaum benennen. Das wiederum verhindert, die für das eigene Setup am besten geeignete Variante zu finden. Dieser Artikel dient als eine Art Leitfaden: Er untersucht Elasticsearch, Logstash und Kibana (also den sogenannten ELK-Stack sowie manche seiner Variationen), Splunk sowie Loki [1] im Hinblick auf deren Funktionalität und erklärt, wodurch die drei Produkte sich voneinander unterscheiden.
Protokollpflicht
Bevor es aber um die drei konkreten Implementierungen zentralen Loggings geht, lohnt sich ein Blick auf die Aufgaben, die in verteilen Setups beim Thema Logging für den Admin anstehen.
Wie üblich gilt: Setzt ein Unternehmen auf Ressourcen in einer Public Cloud, fällt ein Teil der Arbeit weg – jener Teil, der sich mit dem Betrieb und der Überwachung der physischen Infrastruktur beschäftigt. Diese Aufgaben übernimmt in der Public Cloud der jeweilige Anbieter. Die Public Cloud ist aber längst nicht für jedes Unternehmen eine valide Option. Dieser Artikel geht daher davon aus, dass ein Unternehmen nicht nur Container oder IaaS betreibt, sondern auch die darunter liegende Infrastruktur. Allein dadurch erhöhen sich die Anforderungen enorm.
Das Thema Logging teilt sich in zwei Bereiche auf: einerseits das Logging der Infrastruktur, andererseits das Logging des darauf beheimateten Workloads. Letzteres kommt in mehreren Varianten daher: IaaS impliziert eigene virtuelle Systeme, deren Log-Daten es zu sammeln gilt, während containerbasierte Workloads im Wesentlichen die Logs der Applikationen in den Containern produzieren.
Das Logging von Virtualisierungshosts verursacht entsprechend viel Aufwand: Hier sind es ja nicht nur die üblichen Verdächtigen in »/var/log/«, die ihren Weg ins zentrale Logging finden müssen, sondern auch die Dateien von Zusatzdiensten wie die der OpenStack-Komponenten. Allein deren Einsatz führt zu Dutzenden Log-Dateien auf jedem Host, die man ebenso zentral sammeln muss.
Container-Setups
Beim zentralen Monitoring physischer Systeme besteht die Herausforderung in erster Linie aus der Menge der zu sammelnden Log-Dateien. Die spielt bei Containern hingegen gar keine so große Rolle: Hier ist es eher die Dynamik dieser Setups, die für Herausforderungen sorgt.
In Container-Umgebungen gibt es meist einen Schalter für On-demand-Skalierung. Beantwortet ein Setup also gerade viele Anfragen, erhöht Kubernetes automatisch die Anzahl der Container. Das klappt auf einer Per-Dienst-Basis, weil moderne Cloud-ready-Apps in den meisten Fällen einer Mikroservice-Architektur folgen. Das bedeutet im Umkehrschluss aber auch: Letztlich hat ein Logging-Dienst es hier mit einer beliebigen Anzahl von Logs von beliebig vielen Diensten zu tun, die dynamisch kommen und gehen. Eben das ist letztlich auch der Grund, warum klassisches, zentralisiertes Logging in Container-Umgebungen nur bedingt funktioniert – doch dazu später mehr.
ELK und Splunk
Bis ein funktionales zentralisiertes Logging für die Infrastruktur eines Setups existiert, erwartet den Admin bereits einige Arbeit. Neben Splunk findet sich als Standardwerkzeug im Admin-Baukasten die Kombination aus Elasticsearch, Kibana und einem Log-Sammler (meist Logstash), was dieser Kombination die Abkürzung ELK eingebracht hat (Abbildung 1). Wenn dieser Artikel im Folgenden den Begriff ELK verwendet, dann sind stets auch die Ansätze gemeint, die Rsyslog oder andere Komponenten anstelle von Logstash nutzen.
Abbildung 1: Elasticsearch, Logstash und Kibana gelten als das FL/OSS-Standardwerkzeug für zentralisiertes Logging. Quelle: Elastic
Schon auf den ersten Blick fällt auf: ELK und Splunk sind sich im Hinblick auf ihre Architektur sehr ähnlich. Beide Lösungen verwenden vergleichbare Ansätze, um ihre Aufgabe zu lösen. Konkret bedeutet das: Sowohl ELK als auch Splunk teilen die ihnen zugedachte Aufgabe in drei kleine Schritte auf, die sie dann mit spezialisierten Werkzeugen abarbeiten: Sammeln, Indizieren und Suchen.
Das Sammeln
Beim Sammeln geht es darum, die relevanten Daten von den Zielsystemen zu erhalten. Dieser Schritt ist nicht weiter kompliziert: Im Normalfall hängt sich ein dafür gemachtes Programm an einzelne Log-Dateien, liest diese aus und sendet die eingehenden Meldungen an das Logging-System. Setzen Zieldienste lieber auf die Syslog-Facilities, lassen sich auch Programme wie Rsyslog mit den jeweiligen Logging-Anwendungen koppeln. So oder so ist die Aufgabe, die die jeweiligen Programme erledigen, nicht sehr komplex: Es geht im Grunde lediglich darum, Daten auf den Zielsystemen zu sammeln und an das Logging weiterzuleiten.
Wesentlich komplexer ist die zweite Station, die Log-Meldungen in typischen zentralisierten Logging-Systemen wie ELK und Splunk durchlaufen, nämlich die Indizierung. Der zentrale Aspekt beim Einsatz zentralisierter Logging-Lösungen besteht ja darin, dem Admin das Debugging zu erleichtern, insbesondere im Fehlerfall. Wer sich schon mal einem OpenStack-Problem gegenüber sah, der weiß: Ein Fehler auf einem Host führt schlimmstenfalls zu einem Problem auf einem anderen Host. Ohne die Fehlermeldungen buchstäblich nebeneinander zu sehen, hat der Admin kaum eine Chance, sie zu verstehen.
Die beiden Probanden im Test begegnen diesem Problem mit der Keule: Sie nehmen die eingehenden Log-Meldungen entgegen und indizieren sie sehr umfangreich. Das bedeutet konkret: Anhand verschiedener Schlüsselbegriffe sortieren beide Lösungen die Log-Meldungen und machen sie so durchsuchbar und auch korrelierbar.
Die Indizierung
Technisch betrachtet ist die Indizierung der Log-Meldungen allerdings viel schwieriger, als es im ersten Augenblick den Anschein hat. Anders als beim Sammeln der Logs geht es bei der Indizierung um eine hochkomplexe Aufgabe. Das wird schnell klar, hält man sich die Natur und den Umfang von Log-Meldungen vor Augen. Gemeint sind hier offensichtlich nicht einfache Log-Meldungen einzelner Dienste – die lassen sich schnell verarbeiten, vorausgesetzt, die dafür in ELK oder Splunk hinterlegten Pattern passen. Viel schwieriger im Handling sind die Log-Meldungen, die beispielsweise aus mehreren Zeilen bestehen.
Stack-Traces aus Python liefern ein gutes Beispiel: Hier müssen die in Splunk und ELK hinterlegten Muster zur Log-Analyse und zur Indizierung extrem gut sein. Andernfalls können Anfang und Ende von Fehlermeldungen nicht korrekt ausgemacht werden, und im Suchindex landet nur Mist. Exakt hierin besteht übrigens einer der Unterschiede zwischen Splunk und ELK: Splunk kommt ab Werk mit einer riesigen Anzahl vorgefertigter Filter für das Logging, während der Admin bei ELK auf Ressourcen im Internet und Handarbeit zurückgreifen muss.
Mit der Komplexität der Aufgabe beim Indizieren von Log-Meldungen geht ein hoher Ressourcenbedarf einher. Schlimmer noch: Die Menge der benötigten Ressourcen steigt exponentiell mit der Zahl der Logs, die der Admin mit Splunk oder ELK & Co. verarbeiten möchte – und damit auch mit der Zahl der Knoten im Setup. Je größer also die Installation, die Splunk oder ELK nutzt, umso mehr Ressourcen müssen für diese Dienste zur Verfügung stehen.
Das bedeutet ganz konkret: Wer eine komplette Cloud-Umgebung per Splunk oder ELK mit zentralisiertem Logging versorgen möchte, braucht dafür schon einen äußerst gut bestückten Cluster. Ist die Hardware zu schwach, fällt das zentralisierte Logging zuerst aus, was niemandem weiterhilft. Dieser Umstand gilt als große Schwachstelle bei Systemen wie ELK und Splunk und macht Admins das Leben nicht leichter.
Die Suche
Der Vollständigkeit halber sei die Suchfunktion als dritte Ebene einer zentralisierten Logging-Lösung benannt. Was deren Ressourcenverbrauch angeht, ist sie im Kontext einer Gesamtlösung allerdings beinahe schon zu vernachlässigen. Bei beiden Ansätzen konsumiert die Indizierung so massiv Rechenleistung, dass alles andere praktisch egal ist.
Frage der Bequemlichkeit
Wer sich nach einer leistungsfähigen Lösung mit umfassender Indizierung umsieht, landet früher oder später zwangsläufig bei Splunk oder ELK. Auf welche Alternative die Wahl dann fällt, hängt letztlich vor allem von der Frage ab, wie viel Zeit und wie viele Mitarbeiter zur Verfügung stehen. Das zentrale Unterscheidungsmerkmal zwischen Splunk und ELK ist der Preis.
Ein ELK-Cluster lässt sich schnell aus dem Boden stampfen, und für Ansible, Puppet und auch alle anderen gängigen Werkzeuge existiert Automation, die dem Admin selbst diesen Task noch abnimmt. Allerdings ist dieser Teil eben nur die halbe Miete: Die meiste Zeit fällt auf der administrativen Seite dafür an, Filter für die Indizierung zu bauen, die zum jeweiligen Use Case passen. Vorgefertigte Filter aus dem Netz kann man in der Regel nicht einfach so auf ein neues Setup anwenden, sie bedürfen stattdessen der Adaption. Dafür gibt es alle zu ELK gehörenden Komponenten kostenlos im Netz. Hoher Personalaufwand steht hier also geringen Anschaffungskosten gegenüber.
Wer soll das bezahlen?
Exakt andersherum verhält es sich mit Splunk (Abbildung 2). Der Hersteller liefert das Produkt mit Filtern für nahezu jedes denkbare Programm aus, sodass sich ein Splunk-Cluster schnell in Betrieb nehmen lässt. Der Anbieter verrechnet das allerdings anhand des Traffics, den der Splunk-Cluster empfängt, und zwar bis hinunter auf einzelne Gigabytes über einen bestimmten Zeitraum.

Abbildung 2: Viel Funktionalität, hohe Lizenzgebühren: Technisch ist Splunk ELK an vielen Stellen voraus, aber die Lösung ist sehr teuer. Quelle: Splunk
Hinzu kommt, dass Splunk nicht gerade günstig ist. Schon relativ einfache Setups schlagen mit Anschaffungskosten von einer halben Million Euro und mehr zu Buche. So gern manche kleineren Unternehmen Splunk auch nutzen wollen – das recht starre Preiskonzept des Herstellers macht den Einsatz vielerorts schlicht zu teuer und mithin unmöglich.
Auf der ELK-Seite gilt dasselbe, aber im Hinblick auf Personal: Kleinere Abteilungen und Unternehmen haben nicht die Ressourcen, um monatelang Leute einen ELK-Cluster tunen zu lassen. Gerade für kleine Firmen ist zentralisiertes Logging mithin schwierig zu erreichen, ganz gleich, ob es um ELK oder Splunk geht.
Loki schafft Abhilfe
Diese Malaise haben auch die Entwickler von Grafana erkannt. Grafana ist ja bekanntlich der Traum jedes Admins, der Metrikdaten jedweder Art grafisch aufbereiten muss. Längst aber schauen die Grafana-Entwickler über den Tellerrand und beschäftigen sich nicht mehr nur mit der optischen Aufbereitung von Metrikdaten, sondern auch mit deren Erhebung. Exemplarisch dafür ist Cortex, eine horizontal skalierbare Prometheus-Variante, die ebenfalls auf die Grafana-Entwickler zurückgeht.
Manch einer fragt sich nun vielleicht, was zentralisiertes Logging und das Einsammeln von Metrikdaten miteinander zu tun haben. Die Antwort auf diese Frage seitens der Grafana-Entwickler heißt Loki – und hat das Potenzial, das Thema zentralisiertes Logging vom Kopf auf die Füße zu stellen. Die Grafana-Entwickler bezeichnen Loki als “Tail und Grep für Kubernetes” – und in diesen paar Wörtern steckt bereits ein deutlicher Fingerzeig auf das, was die Programmierer hinter Loki als das zentrale Problem bei Lösungen wie ELK betrachten.
Die vollständige Indizierung aller Inhalte halten die Loki-Entwickler gar nicht für sinnvoll. Zwar erlaube diese es, den gesamten Log-Bestand nach einzelnen Schlüsselwörtern zu durchsuchen und sie auch über die Grenzen einzelner Hosts hinweg zu korrelieren. Im Alltag sei das aber gar nicht so wichtig, argumentiert die Loki-Crew. Von Interesse seien für den Admin ja stets bloß jene Hosts, auf denen, aus welchen Gründen auch immer, gerade etwas nicht funktioniert. Und da, so die Annahme, genüge es, Log-Daten ähnlich wie mit dem Kommando »tail« von mehreren Hosts gleichzeitig betrachten zu können. Und genau darum geht es bei Loki im Kern.
Wie Loki funktioniert
Die Loki-Entwickler haben sich deutlich erkennbar von Prometheus (Abbildung 3) inspirieren lassen. Zur Erinnerung: Prometheus ist ja zunächst einmal eine Datenbank für Zeitreihendaten. Anders als konventionelle Datenbanken speichert es seine Daten daher nicht in Tabellen, sondern als Einzelwerte entlang einer Zeitreihe. Damit trägt das Tool dem Umstand Rechnung, dass in modernen, massiv skalierbaren Setups die Frage nach einzelnen Ereignissen gar nicht so relevant ist. Viel wichtiger ist stattdessen die Frage, wie sich einzelne Parameter des Systems über einen bestimmten Zeitraum hinweg verändern. Diese Art der Information lässt sich anhand eines Zeitstrahls deutlich besser modellieren als auf Basis von Tabellen.
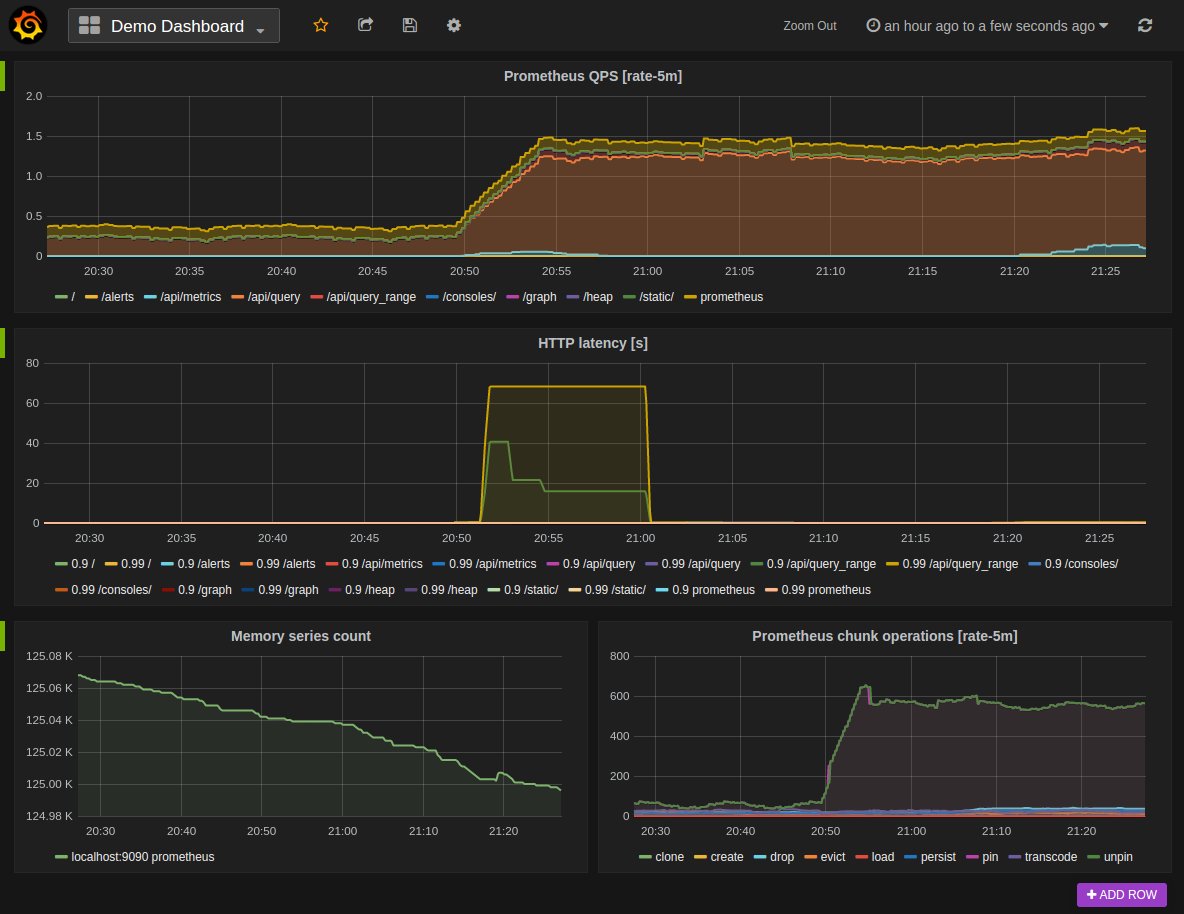
Abbildung 3: Prometheus gilt als ein Standardwerkzeug, um Metrikdaten in Container-Umgebungen einzusammeln. Quelle: Prometheus
Die Zeitreihendatenbank selbst ist freilich nur die halbe Miete. Zwingend braucht Prometheus auf den Zielsystemen Programme, die die relevanten Metrikdaten einsammeln und für das Abrufen durch Prometheus zur Verfügung stellen. Bewusst haben die Entwickler sich für ein Pull-Verfahren durch Prometheus selbst entschieden, weil es so deutlich einfacher ist, mit einer zentralen Registry aller beteiligten Zieldienste zu arbeiten. Metriksammler gibt es zudem mittlerweile eine ganze Reihe: Prometheus selbst stellt solche zur Verfügung, aber diverse Programme wie etwa Ceph haben mittlerweile ebenfalls eingebaute Metrikdaten-Schnittstellen für Prometheus.
Für ihr Projekt führen die Loki-Entwickler zunächst eine gedankliche Reduktion durch: Sie gehen davon aus, dass es sich bei Metrikdaten grundsätzlich um jede Art von Information handeln kann, also nicht zwangsläufig um festgelegte Paare aus Schlüssel und Wert (Key-Value). Im nächsten Schritt erklären sie dann Log-Meldungen kurzerhand ebenfalls zu Metrikdaten und schlagen vor, diese wie die anderen Metrikdaten auch zentral zu sammeln und zu speichern. Die Zeitreihe rückt hier allerdings in den Hintergrund; im Fokus steht bei dieser Art der Datenhaltung eher die Frage nach der Effizienz der Storage-Lösung.
Zwar beziehen sich die Loki-Entwickler immer wieder auf Kubernetes, das auch ihr primäres Einsatzszenario darstellt. Fix auf Kubernetes gemünzt ist Loki (Abbildung 4) aber nicht: Auch in klassischen IaaS-Umgebungen lässt sich das Produkt gut verwenden.
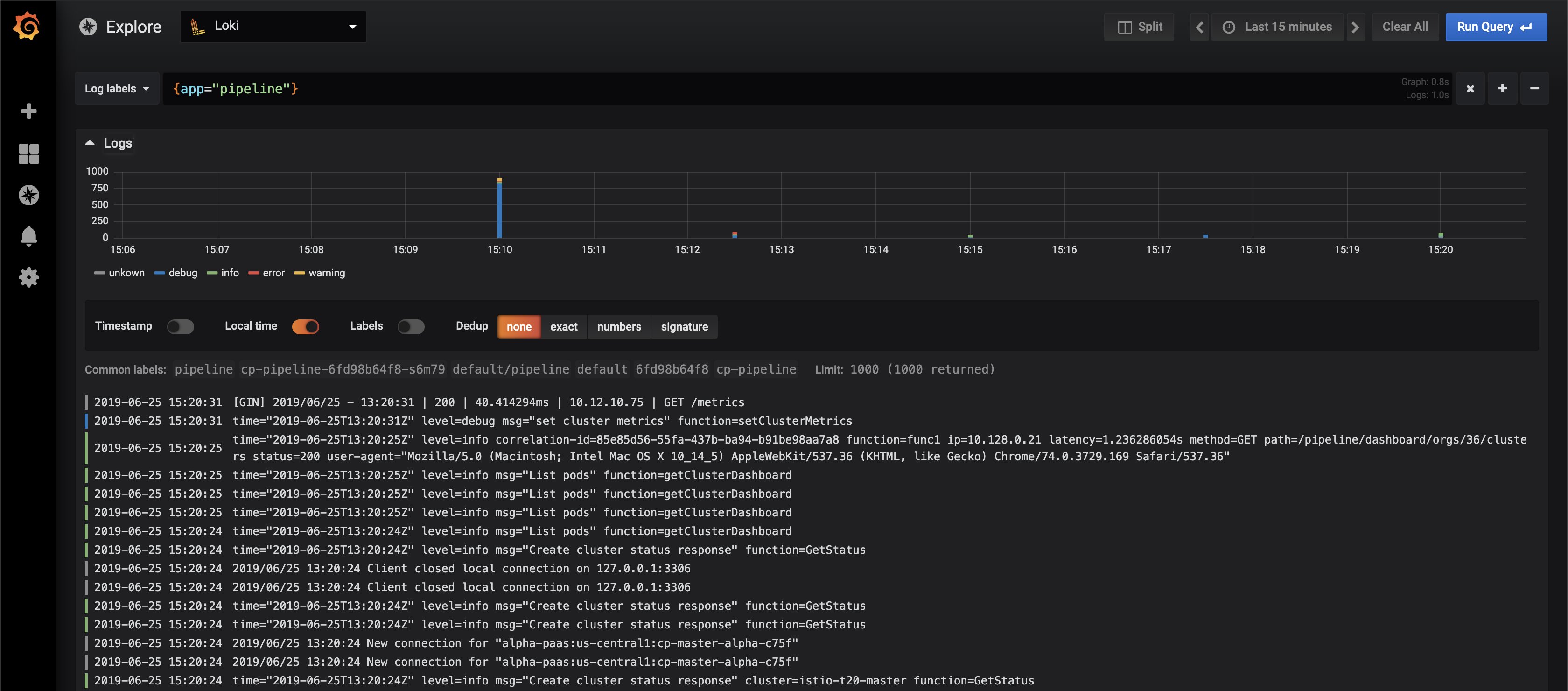
Abbildung 4: Die Loki-Entwickler nahmen sich Prometheus zum Vorbild und schufen eine Lösung, die Log-Meldungen wie Metrikdaten darstellen kann. Quelle: Grafana
Das wirkt sich sogar auf der Code-Ebene aus. Loki besteht aus mehreren Komponenten, namentlich dem Distributor, dem Ingester, einer Datenbank im Hintergrund sowie einer Schnittstelle für Abfragen (dem Querier). Wahlweise lassen diese Bestandteile sich als einzelnes Go-Binary betreiben (meist in All-in-One-Setups) oder auf viele Hosts (oder Container) verteilen. Die zu Loki gehörenden Komponenten lassen sich also auch als Mikroservice betreiben und damit horizontal skalieren.
Loki als Alternative
Tatsächlich ist Loki schnell eingerichtet und kommt wegen des Verzichts auf Indizierung ohne hohe Hardware-Anforderung aus. Obendrein ist das Werkzeug quelloffen und kostenlos im Internet zu beziehen. Bei reduziertem Funktionsumfang kombiniert es faktisch also die Vorteile von Splunk und ELK miteinander. Weil die umfassende Indizierung wegfällt, müssen Admins auch nicht Stunden und Tage damit verbringen, Filter für Loki zu programmieren. Erkennt der Admin ein Problem, wirft er direkt einen Blick auf die Logs der betroffenen Systeme statt in eine indizierte Datenbank. Im Hintergrund speichert Loki diese Logs komprimiert in Chunks.
Zwar richtet Loki sich vorrangig an Container-Nutzer und kommt auch mit diversen Funktionen daher, die den Einsatz in entsprechenden Umgebungen erleichtern. Letztlich fußt aber auch Loki auf der Überzeugung, dass die in Container laufenden Komponenten klassische Log-Dateien produzieren. Das allerdings ist immer seltener der Fall. Selbst wenn ein Werkzeug wie Loki Log-Dateien zentral verfügbar macht, bleibt zudem das Problem, dass der Admin die Meldungen aus diversen Logs händisch korrelieren muss. Das wird umso komplexer, je dichter das Kommunikationsnetz innerhalb einer Container-Umgebung ist. Kommen Lösungen wie Istio zum Einsatz, kommuniziert irgendwann jede Komponente mit jeder anderen. Das bedeutet auch, dass der Absturz einer Komponente seinen Ursprung an ganz anderer Stelle haben kann.
Debugging-Lösungen für solche Konzepte verlagern daher den Kernaspekt vom Mitschreiben bei Problemen hin zum expliziten Setzen von Wegmarken, um Abläufe nachvollziehbar zu machen. Was im ersten Moment mit zentralisiertem Logging augenscheinlich nichts zu tun hat, entpuppt sich bei genauerem Hinsehen als dessen logische Evolution.
Standard: OpenTracing
Im Kern funktioniert das so: Mittels einer fertigen Lösung setzt der Entwickler in seiner Applikation Wegmarken für bestimmte Ereignisse und vergibt via Setup Namensschilder für Daten. Zentral ist dabei der Begriff des Span. Als solcher gilt jede Operation mit Daten, also insbesondere auch jene, die Daten verändern. Aus dem Verlauf von Spans, die eine Information durchläuft, und den Spans, die Änderungen der Information bewirken, ergibt sich ein Trace.
Standards wie OpenTracing, das mittlerweile in OpenCensus aufging, beschreiben Methoden, um diese Traces mitzuschreiben und die gewonnenen Informationen in zentralen Datenbanken zu speichern. Vom Ansatz unterscheidet sich das gar nicht so sehr von ELK, Splunk und Loki, zumal die eingesetzten Komponenten ähnliche Aufgaben bewältigen. Konkrete Implementierungen des Konzepts gibt es bereits: Jaeger [2] implementiert die OpenTracing-Spezifikation und bietet eine Vielzahl an Möglichkeiten.
Wachablösung durch Jaeger
So existieren für Jaeger eine Vielzahl von Anbindungen an die üblichen Programmier- und Skriptsprachen per Binding. Im Hintergrund legt Jaeger (Abbildung 5) seine Daten nach Bedarf in unterschiedlichen Datenbanken ab, auch eine All-in-one-Option mit eingebauter Datenbank steht zur Verfügung.
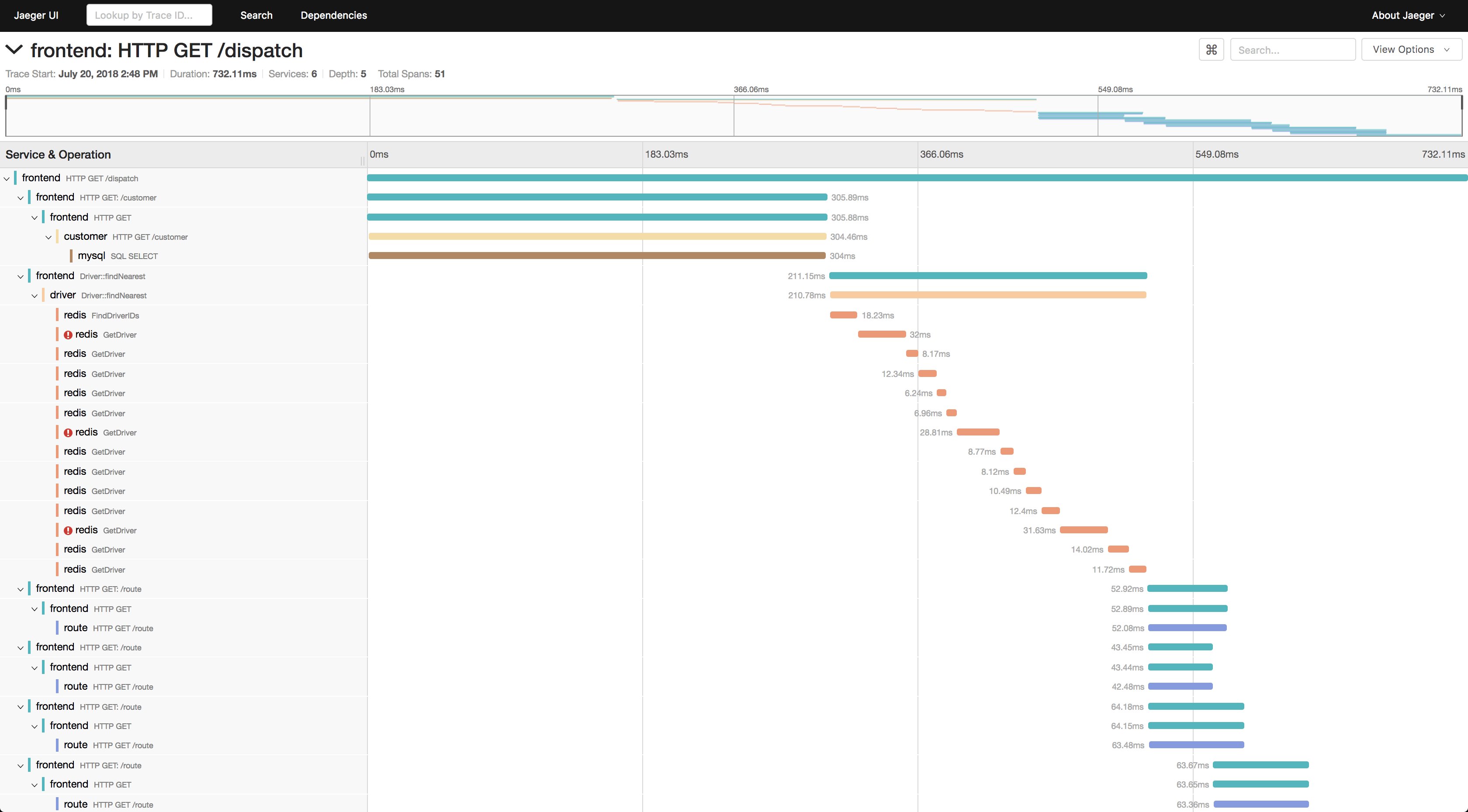
Abbildung 5: Jaeger ist die Zukunft der Überwachung für Container: Es ersetzt sowohl klassisches Monitoring als auch zentralisiertes Logging in weiten Teilen. Quelle: Jaeger
Alle Jaeger-Komponenten lassen sich nahtlos in die Breite skalieren. Den Zugriff auf die in Jaeger abgelegten Daten macht eine eigene API möglich, die als Query-Komponente dient und Traces im Bedarfsfall auch optisch darstellen kann. In Summe ist Jaeger damit am besten an den Einsatz in modernen Container-Umgebungen angepasst – kein Wunder, wurde es doch spezifisch für diesen Zweck verfasst.
Lösungen wie Jaeger und andere auf Basis der OpenTracing-API werden in dynamischen Cloud-ready-Umgebungen wohl konventionellen Systemen wie Splunk und ELK früher oder später den Rang ablaufen. Loki positioniert sich in der Mitte beider Ansätze und ist insofern ein guter Allrounder. Welcher Ansatz für ein Setup der richtige ist, hängt also immer vom konkreten Einzelfall ab; eine grundsätzliche Empfehlung lässt sich daher nicht machen. (jcb)
Der Autor
Martin Gerhard Loschwitz ist Cloud Platform Architect bei Drei Austria und beackert dort Themen wie OpenStack, Kubernetes und Ceph.
Infos
- Loki: https://grafana.com/oss/loki/
- Jaeger: https://jaegertracing.io/





