
© Maksim Shebeko, 123RF
Mit GraphQL erzeugt ein Entwickler nach dem REST-Prinzip simpel strukturierte Anfragen, um gezielt Datensätze abzurufen. Ein Beispiel demonstriert, wie er solche Abfragen in GraphQL entwirft und in Go programmiert.
Als Facebook 2015 den Quellcode von GraphQL [1] unter eine Open-Source-Lizenz stellte, passierte erst einmal eine ganze Weile lang wenig. Doch spätestens 2018, als die Linux Foundation das Projekt unter ihre Fittiche nahm, setzte ein Run auf GraphQL ein, der bis heute anhält. Inzwischen kommt die zustandslose Abfragesprache und Serverumgebung in zahlreichen Projekten zum Einsatz. Der Artikel zeigt an einem kleinen Beispiel, wie Programmierer eine Brücke zwischen Go und GraphQL bauen.
Zunächst gilt es jedoch, die Frage zu klären, was GraphQL überhaupt ist. Einerseits handelt es sich um eine REST-ähnliche Sprache, in der Entwickler Abfragen entwerfen und an einen Server senden, der dann verschiedene Datentypen zurück liefert. Andererseits zählt zu GraphQL auch eine serverseitige Laufzeitumgebung, die versucht, die Abfragen auf Basis der existierenden Daten zu erfüllen.
GraphQL arbeitet dabei datenbank- und speicheragnostisch, sodass es sich schnell in Projekte mit vorhandenen Daten und Code einbinden lässt. Dass es die Daten über Endpunkte bezieht, unterscheidet GraphQL von SQL- und einigen No-SQL-Datenbanken und rückt es in die Nähe von REST. Anders als REST gibt GraphQL aber auf eine einzelne Anfrage hin auch mehrere Datenfelder zurück.
Ein Entwickler baut mittels GraphQL zum Beispiel ein API, über das er mit der GraphQL-eigenen Abfragesprache Daten an einem Endpunkt abholt. Dabei bestimmt er detailliert, welche Daten die Anfrage zurück liefern soll, ohne dafür etwas am Backend zu verändern.
Der selbst programmierte API-Server akzeptiert, parst und bearbeitet die GraphQL-Anfragen und schickt die vom Nutzer gewünschten Daten zurück. Dabei sendet der Server die Queries stets an dieselben Endpunkte (meist »/graphql« oder »/query«). Das ist zugleich der entscheidende Unterschied zu REST-APIs, die üblicherweise für jede Funktion oder jeden separaten Rückgabewert einen eigenen Endpunkt anbieten.
GraphQL versus REST
Listing 1 zeigt vergleichend, wie eine Abfrage in GraphQL aussieht (Zeile 1 bis 6) und wie bei einem REST-API (Zeile 8). Die GraphQL-Abfrage scheint im ersten Moment, länger zu sein. Daher enthält das Listing noch eine weitere Abfrage, die lediglich die Namen der Bücher ausgeben soll, nicht aber die ISBN. Die Zeilen 10 bis 14 definieren die GraphQL-Abfrage dafür, Zeile 16 zeigt den entsprechenden Aufruf via Rest-API. Für Letzteren müsste ein Entwickler allerdings serverseitig eine neue Funktion beziehungsweise einen Endpunkt schreiben.
Listing 1
GraphQL-Query
query{
books{
name
isbn
}
}
GET /api/v2/books
query{
books{
name
}
}
GET /api/v2/books_noisbn
Gegebenenfalls kann der Entwickler die GraphQL-Abfrage auch einengen und nur nach bestimmten Büchern fragen. Dazu gibt er dann in den Feldern darunter an, welche Werte er im Detail benötigt. In Listing 2 zeigen die Zeilen 1 bis 6 eine Abfrage, die lediglich die ISBN und den Namen eines bestimmten Buchs ausgibt. Der Code der Zeilen 8 bis 19 rückt zusätzlich die Seitenzahl sowie ergänzende Informationen zum Autor heraus. Auch hier legt der Programmierer fest, welche Felder die Antwort enthalten soll.
Listing 2
Verfeinerte GraphQL-Abfrage
query{
books(name: "Harry Potter"){
name
isbn
}
}
query{
books(name: "Harry Potter"){
name
isbn
seiten
erstveröffentlichung
autor{
name
alter
}
}
}
Wer nun zu den Abfragen aus Listing 2 eine REST-Schnittstelle bauen möchte, bräuchte dafür zwei verschiedene Endpunkte: Einmal einen, der die Suche ausführt und den Namen sowie die ISBN liefert, sowie einen weiteren, der den Namen, die ISBN, die Seitenanzahl, die Erstveröffentlichung und die Daten zum Autor retourniert.
Hier offenbart sich der erwähnte Vorteil von GraphQL: Es fasst ohne Umstände die Endpunkte einer normalen REST-Schnittstelle zusammen. Mittels der eigentlichen Abfragesprache erhält der Entwickler dann die Daten, die er braucht, ohne zusätzliche Endpunkte oder eine neue Logik in den Server programmieren zu müssen.
GraphQL und Go
Um die Abfragen umzusetzen, verwendet der Autor des Artikels die beliebte Programmiersprache Go. Darin gibt es verschiedene Portierungen für GraphQL; die Wahl fiel auf Gqlgen [2]. Der komplette Quellcode zum Beispiel wartet übrigens, wie so häufig, auf dem Listing-Server des Linux-Magazins [3].
Zwar befindet sich Gqlgen mit der aktuellen Version 0.10.1 noch in einer späten Beta-Phase, doch die starke Verbreitung auf Github und die vielen an Gqlgen beteiligten Entwickler deuten darauf hin, dass die Portierung einigen Support erhält und eine Community die Software aktiv entwickelt. Zudem bringt die Portierung als einzige einen aktiven Sponsor mit (99Designs), der selbst aus der Webentwicklung kommt. Dessen Ideen und Problemlösungen aus der Praxis dürften die Gqlgen-Versionen ebenfalls bereichern.
Daneben bietet die Portierung eine Typsicherheit, die bei manch anderer Portierung fehlt. Programmierer müssen sich dann mit Konstrukten wie »map[string]interface{}« herumschlagen.
Nicht zuletzt setzt Gqlgen auf einen Schema-First-Ansatz: Das Programm richtet sich also nach einem Schema, welches von den jeweils vorhandenen Daten abhängt. Tatsächlich darf der Entwickler also zuerst ein Schema definieren und anschließend den Code generieren, den er benötigt. Am Ende schreibt er nur noch Abfragen, um an die richtigen Daten zu gelangen.
Workspace vorbereiten
Wer mit Go und GraphQL anfangen möchte, sollte zuerst Go installieren, den »$GOPATH« einrichten (er liegt üblicherweise unter »$HOME/go/«) und dann einen Workspace für das Projekt anlegen (Abbildung 1). Unter Ubuntu 18.04 führt der Weg über eine Snap-Installation, da Apt noch ein altes Go 1.10 verwaltet.
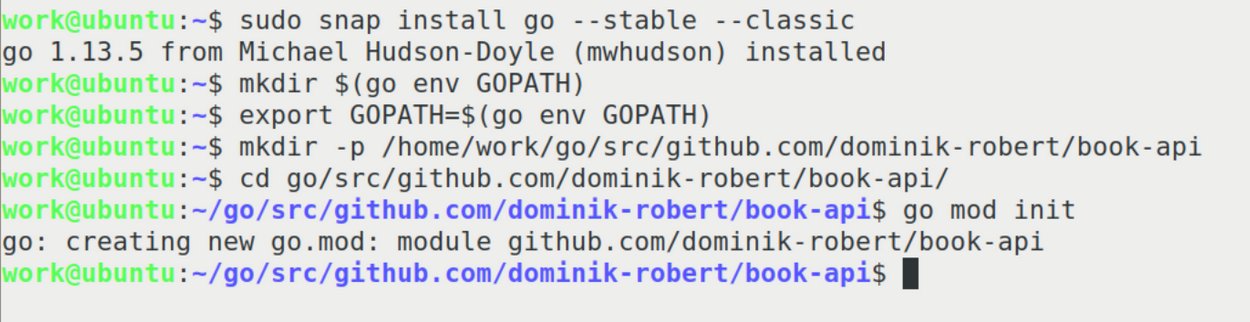
Abbildung 1: Der letzte Befehl, »go mod init«, funktioniert nur mit neueren Go-Versionen.
Dann legt der Programmierer im »$GOPATH« eine Quelle an, die den Namen des Projekts sowie die kompletten Dateien beinhaltet. Für das Beispiel erzeugt der Autor einen neuen Ordner unter »$GOPATH/src/github.com/dominik-robert/« und platziert sein Projekt »book-api« dort.
Der vierte Befehl legt das Verzeichnis samt Unterverzeichnissen an, mit dem fünften wechselt der Entwickler dorthin. Der letzte Befehl verwandelt das Verzeichnis schließlich in ein Go-Modul, was unter anderem die Datei »go.mod« erzeugt, die die Abhängigkeiten und die verwendete Go-Version auflistet.
Der Schema-First-Ansatz wurde schon erwähnt, und so gilt es nun, ein Schema zu verfassen. Dafür legt der Programmierer eine Datei im eben generierten Workspace an, die standardmäßig »schema.graphql« heißt. In ihr landet das Schema für den GraphQL-Server. Die Schema-Syntax folgt dabei dem offiziellen GraphQL-Schema [4].
Nach Schema F
Das Schema soll für diesen Artikel ein einfaches Buch-API abbilden. Darüber darf der Nutzer nicht nur Bücher anlegen, löschen und verändern, sondern es lassen sich auch alle oder nur bestimmte Bücher anzeigen.
Das Schema für den Aufbau der Typen fällt recht simpel aus. Nach dem Schlüsselwort »type« folgt der Name des zu bauenden Typs. Dann definiert der Entwickler in geschweiften Klammern die Felder, aus denen sich der neue Typ zusammensetzt. Hängt er ein Ausrufezeichen an einen dieser Basistypen, ist dieser zwingend erforderlich. Steht der Typ in eckigen Klammern, handelt es sich um ein Array.
Listing 3 legt zunächst im zuvor eingerichteten Workspace ein Schema für Bücher an. Die Zeilen 1 bis 9 beschreiben den Aufbau der Typen, die ein API-Nutzer später als Antwort erhält. Hier benötigt also jedes Buch zwingend eine ISBN, einen Namen und einen Autor, wobei jeder Autor wiederum zwingend einen Namen besitzt. Damit wäre bereits der Aufbau der Rückgabetypen beschrieben.
Listing 3
schema.graphql
type Book {
isbn: String!
name: String!
author: Author!
}
type Author {
name: String!
}
type Query {
books: [Book!]
book(isbn: String!): Book!
}
type Mutation {
createBook(input: NewBook!): Book!
updateBook(input: UpdateBook!): Book!
deleteBook(isbn: String!): Book!
}
input NewBook {
isbn: String!
name: String!
authorname: String!
}
input UpdateBook {
isbn: String!
name: String
authorname: String
}
Nun folgt die Abfrage. Dazu verwendet der Programmierer ebenfalls das Schlüsselwort »type«, allerdings gefolgt von »Query«, damit der GraphQL-Server weiß, dass es sich um Anfragen handelt. Die Zeilen 11 bis 14 beschreiben die beiden Queries, die Anwender später verwenden dürfen: Einmal eine Abfrage, die sämtliche Bücher zurückgibt (Zeile 12), einmal eine, die nur das Buch samt der ISBN retourniert (Zeile 13) enthält.
Als nächstes ergänzt der Entwickler im Schema die Operationen Löschen, Anlegen und Ändern. GraphQL subsummiert sie unter dem Typ »Mutation« und leitet sie ebenfalls mit dem Schlüsselwort »type« ein. Die Zeilen 16 bis 20 von Listing 3 definieren dann die Operationen selbst.
Bei Mutationen darf der Entwickler auf Wunsch Parameter angeben, die GraphQL später beim Bau der Antwort verwendet. Das dürfen einzelne Parameter sein oder Objekte, die er zunächst mit dem Schlüsselwort »input« und einem eindeutigen Namen definiert. Dann legt er die »input«-Objekte selbst fest. Für »updateBook« und »createBook« erledigt Listing 3 das in den Blöcken nach den Zeilen 22 und 28.
Relevante Dateien nachliefern
Ist das Schema vollständig, kann Gqlgen sehr viele weitere Bestandteile automatisch generieren. Um das anzuleiern, wechselt der Entwickler in den Ordner mit der zuvor angelegten Datei »schema.graphql« und gibt folgenden Befehl ein:
$ go run github.com/99designs/gqlgen init
Der Befehl sucht im Ordner nach der »schema.graphql« und holt dann die Abhängigkeiten, die GraphQL und Go aus dem Github-Repository benötigen. Dazu schreibt er zunächst das GraphQL-Paket mit der aktuellen Version in die Datei »go.mod« und generiert anschließend die Verzeichnisstruktur aus Abbildung 2.
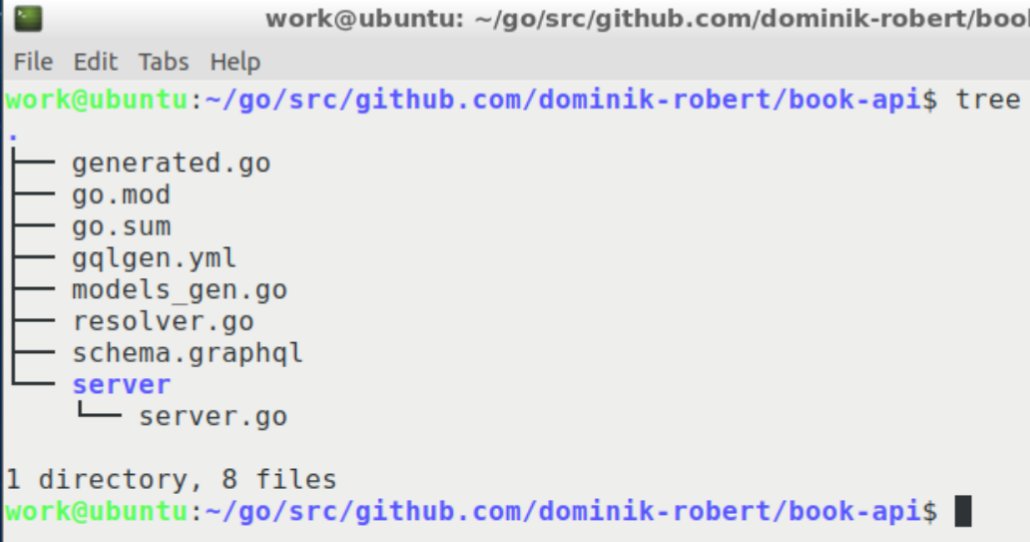
Abbildung 2: Die durch den »init«-Befehl generierte Verzeichnisstruktur mit allen dazugehörigen Dateien.
Die Datei »gqlgen.yaml« enthält die Konfiguration für den »gqlgen«-Befehl, um neue Dateien zu generieren. Darüber definiert der Entwickler bei Bedarf weitere Dateien mit Definitionen für zusätzliche Typen, die das Schema erweitern, oder gibt noch mehr eigene Dateien an.
Auch die »schema.graphql« listet die Datei auf, der Programmierer könnte ihr hier einen neuen Namen geben. Die Datei mit dem Namen »modles_gen.go« enthält im Prinzip nur die eben von uns definierten Schema-Typen aus GraphQL, allerdings in Form von Typen für die Programmiersprache Go.
Die Datei »generated.go« zieht hinter den Kulissen die Fäden. Sie versieht die zuvor generierten Typen mit der eigentlichen Logik. Sie sorgt zum Beispiel dafür, die Felder richtig zuzuweisen und nur die gewünschten Felder anzuzeigen und zurückzugeben. Darum sollen sich Anwender später nicht mehr kümmern müssen, sondern lediglich ihre Daten übergeben.
In der Datei »server.go« im Ordner »server/« warten die Definition und die Endpunkte für den Playground. Über dieses Webinterface lassen sich Abfragen und Endpunkte für die Queries testen (hier »/query«) sowie die Dokumentation betrachten (dazu später mehr).
Die Datei »resolver.go« ist wichtig, weil sie weiß, woher die Daten kommen. Im Folgenden bearbeitet der Entwickler sie daher als einzige der vorhandenen Dateien.
Die Datei <C>resolver.go<C>
Die Datei »resolver.go« sorgt dafür, dass der Server die Daten mit den Strukturen verbindet. Das bedeutet, dass in dieser Datei ein wesentlicher Teil der Action passiert. Der Server löst hier die Daten auf, die er braucht, um eingehende Abfragen zu erfüllen.
Erfreulicherweise passt Gqlgen den Code bereits so weit an, dass dem Entwickler sofort ins Auge springt, was er modifizieren muss. Steht im Code »panic(“not implemented”)«, fehlt an dieser Stelle eine Definition dazu, woher die Daten kommen sollen (Abbildung 3). Im Bücher-Beispiel handelt es sich um ein lokales Array, da der Artikel aus Gründen der Einfachheit keine Datenbank verwendet.
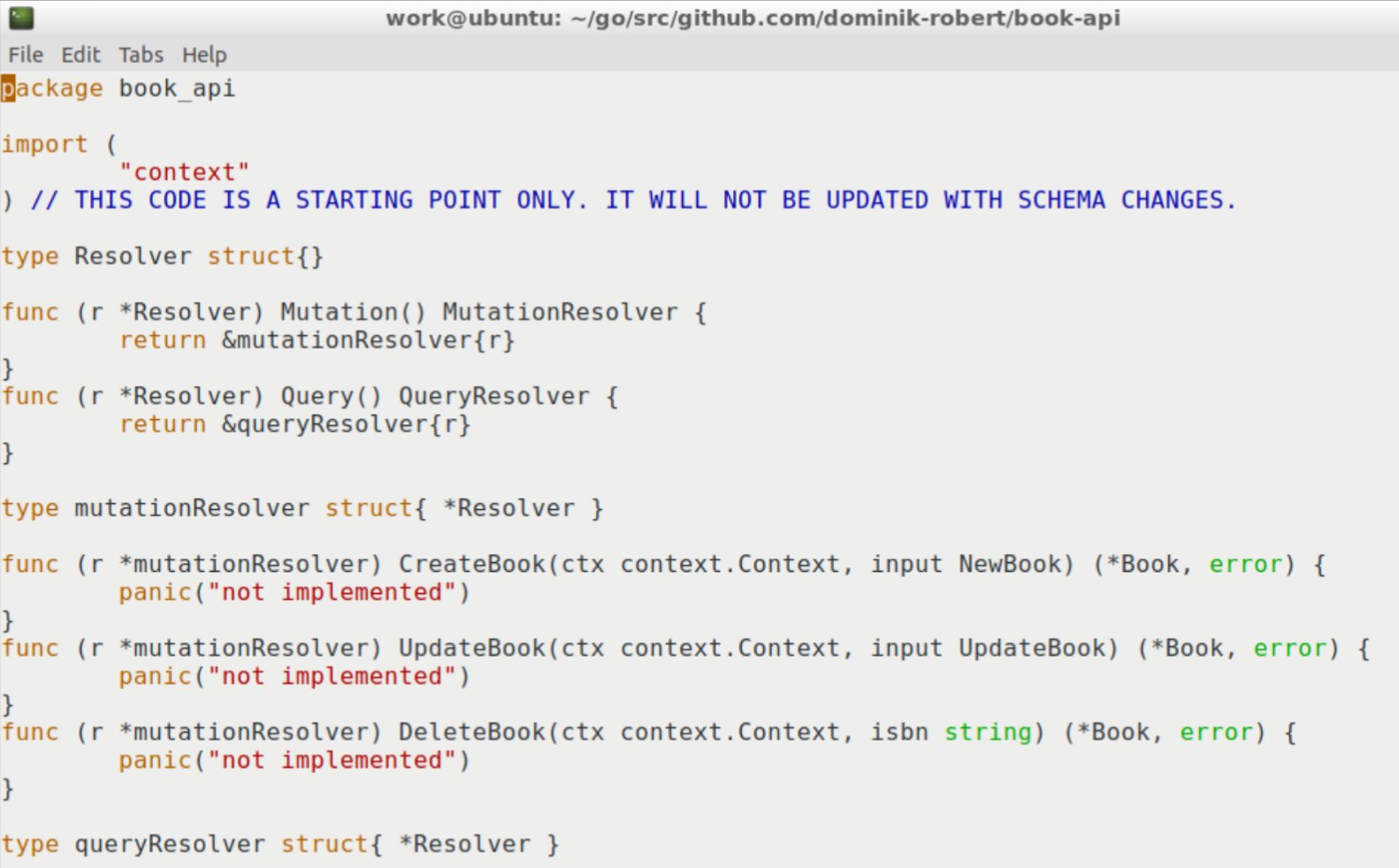
Abbildung 3: Im Code (hier ein Auszug) sind die vom Entwickler auszufüllenden Passagen deutlich markiert.
Das Array definiert der Entwickler üblicherweise ganz oben in der Resolver-Struktur. Theoretisch ist es aber egal, an welcher Stelle im Code der Programmierer das Array einträgt oder woher die Daten stammen. Er erweitert einfach die »struct« um eine Zeile:
type Resolver struct {
MyBooks []*Book
}
GraphQL arbeitet nur mit Pointern. Daher verlangt der Code für ein Array auch nach einem Pointer auf ein Array.
Abfrage-Aufbau
Im nächsten Schritt schreibt der Entwickler die beiden Abfragen. Auch sie gehören in die Datei »resolver.go«. Die Funktionsköpfe existieren dort bereits; der GraphQL-Programmierer muss lediglich angeben, welche Daten GraphQL zurückgeben soll.
Zuerst geht es um die Abfrage, die sämtliche Bücher retourniert. Um sie anzupassen, genügt es, den Körper der Funktion abzuändern, wie in Zeile 2 von Listing 4 gezeigt. Dann gibt die Anfrage nach allen Büchern einfach das komplette Array zurück. Eine wirkliche Fehlerbehandlung lässt der Code zur Vereinfachung außen vor; auf das Array greift er dabei über die Variable »r« zu, wie in »r.MyBooks«.
Die andere Funktion soll nur ein spezielles Buch zurückgeben (Zeilen 6 bis 13). Dazu muss sie zunächst das komplette Array durchlaufen, um nach der als Parameter übergebenen »isbn« zu fahnden. Stößt die Funktion auf die ISBN, liefert sie nur das zugehörige Buch zurück. Verläuft die Suche erfolglos, gibt sie »nil« zurück, was eine Fehlermeldung triggert, die den Nutzer über den Fehlschlag informiert.
Listing 4
Query-Resolver in der resolver.go
[...]
func (r *queryResolver) Books(ctx context.Context) ([]*Book, error) {
return r.MyBooks, nil
}
func (r *queryResolver) Book(ctx context.Context, isbn string) (*Book, error) {
for _, book := range r.MyBooks {
if book.Isbn == isbn {
return book, nil
}
}
return nil, errors.New("Found no Book with this ISBN")
}
Mutanten dazu
Damit wären die Suchanfragen programmiert. Jetzt schiebt der Programmierer die einzelnen Mutationen hinterher, um das API auch mit Daten zu befüllen. Dafür sieht er sich die einzelnen generierten Funktionen in der Datei »resolver.go« an, kopiert sie in eine eigene Datei oder bearbeitet sie vor Ort.
Zuerst passt er die Abfrage an, die ein neues Buch erzeugt. Die Funktion dazu heißt im Schema »createBook()«, in Golang hingegen »CreateBook()«. Das ist so, weil in Go Funktionen stets mit einem Großbuchstaben beginnen.
Dieser Funktion übergibt der Entwickler dann zwei Parameter. Der erste definiert einen Kontext (»ctx context.Context«), in dem die Funktion gilt – im Beispiel ist das der Webserver. Dieser Kontext ist unter anderem für ordnungsgemäße Shutdowns wichtig. Der zweite bringt eine Variable mit dem Namen »input« vom Typ »NewBook« ins Spiel. Dieser Typ steckt ebenfalls im Schema. Innerhalb der Funktion stehen deshalb die im Schema genannten Felder des Typs bereit.
Go erzeugt nun lokal ein neues Buch mit den Werten der »input«-Variablen. Anschließend kopiert der Code das neue Buch in das Array. Listing 5 zeigt die entsprechende Funktion in den Zeilen 2 bis 12. Die Zeile 11 gibt das neu angelegte Buch zurück und verzichtet dabei auf die Fehlerbehandlung.
Listing 5
Mutation in der resolver.go
[...]
func (r *mutationResolver) CreateBook(ctx context.Context, input NewBook) (*Book, error) {
newBook := &Book{
Isbn: input.Isbn,
Name: input.Name,
Author: &Author{
Name: input.Authorname,
},
}
r.MyBooks = append(r.MyBooks, newBook)
return newBook, nil
}
func (r *mutationResolver) DeleteBook(ctx context.Context, isbn string) (*Book, error) {
for i, book := range r.MyBooks {
if book.Isbn == isbn {
r.MyBooks = append(r.MyBooks[:i], r.MyBooks[i+1:]...)
return &Book{Isbn: isbn}, nil
}
}
return nil, errors.New("No isbn found for deletion")
}
func (r *mutationResolver) UpdateBook(ctx context.Context, input UpdateBook) (*Book, error) {
updatedBook := &Book{
Isbn: input.Isbn,
Name: input.Name,
Author: &Author{
Name: *input.Authorname,
},
}
for i, book := range r.MyBooks {
if book.Isbn == input.Isbn {
r.MyBooks[i] = updatedBook
return updatedBook, nil
}
}
return nil, errors.New("No isbn found for deletion")
}
Die Funktion »DeleteBook()« ab Zeile 14 bezieht sich auf die Mutation »deleteBook«. Bei Bedarf ließe sich auch diese Funktion wieder in eine Extradatei kopieren, um die Übersicht zu behalten. Die Logik der Funktion besteht darin, durch das vorhandene Array zu iterieren und das Buch mit der übergebenen ISBN zu löschen. Findet sie es nicht, wirft sie einen Fehler.
Zu guter Letzt aktualisiert die Funktion »UpdateBook()« (Zeilen 23 bis 38) ein Buch. Sie generiert zuerst eine eigene Struktur vom Typ »Book« mit den Inhalten der »input«-Variablen. Als nächstes iteriert sie über das vorhandene Array, bis sie auf die übergebene ISBN stößt, um diese aus Gründen der Einfachheit komplett mit der übergebenen Struktur zu überschreiben.
API abfragen
Damit wäre das API mit dem zugrunde liegenden Schema verknüpft und einsatzbereit. Der Server lässt sich nun mit dem Befehl »go run server/server.go« starten. Klappt alles, fordert ein Text den Entwickler auf, sich mit »localhost:8080« zu verbinden.
Nach getaner Arbeit stellt Gqlgen den Playground von GraphQL aufs Gleis, der zum Testen dient und Dokumentation anbietet. Daneben bringt er Query-Endpunkte an, die später beim Abfragen des API zum Einsatz kommen. Gibt der Nutzer nun die lokale Adresse »http://localhost:8080« in die URL-Leiste des Browsers ein, erscheint im Browserfenster der Playground.
Darin darf der Anwender nicht nur selbst Abfragen starten, er erhält auch Einblicke in die Dokumentation und navigiert durch das Schema. Die Dokumentation zeigt alle Abfragen mit der jeweiligen Zusammensetzung an Parametern und Rückgabewerten (Abbildung 4). Das ist informativ, um zum Beispiel Nutzern des API zu zeigen, welche Felder sie wann zurück erwarten dürfen.
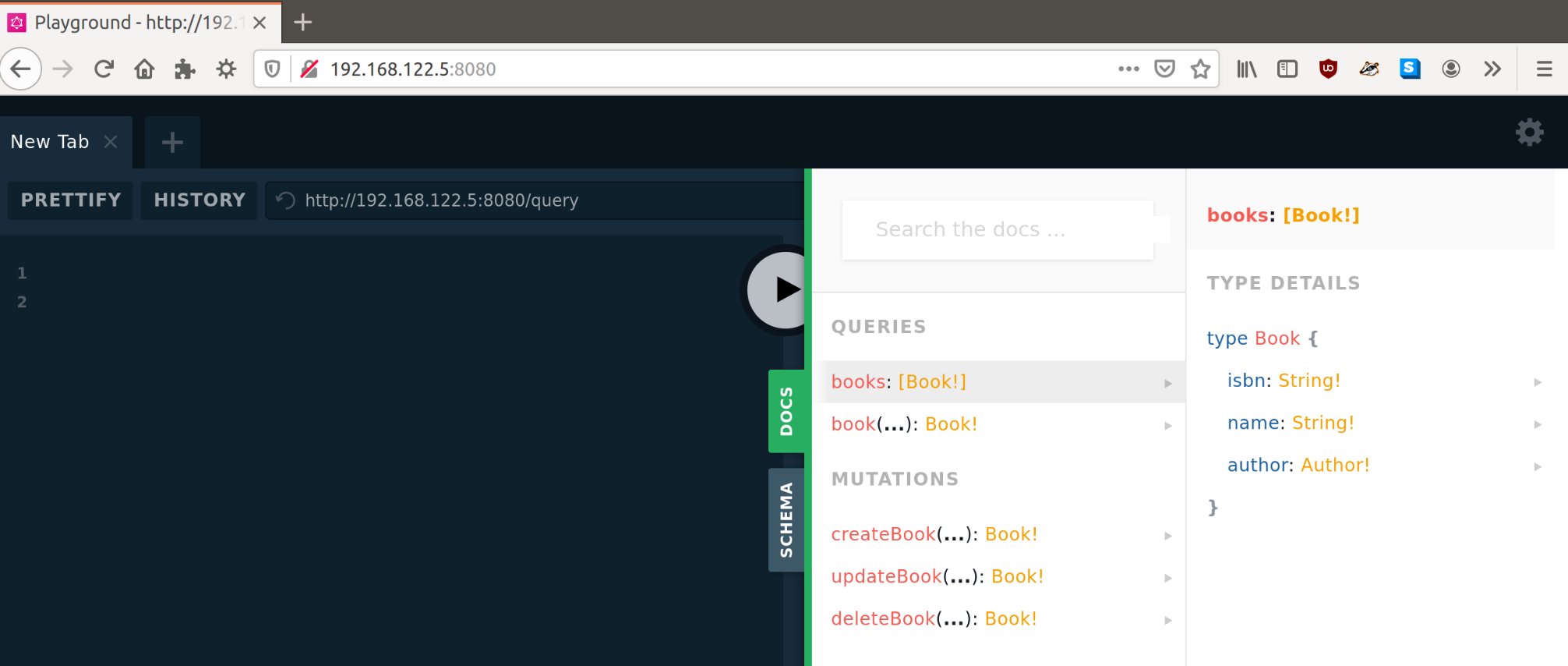
Abbildung 4: Über die URL gelangt der Nutzer zum Playground, wo unter anderem die Dokumentation für das erzeugte API wartet.
Wie eine solche API-Abfrage funktioniert, zeigt das folgende Beispiel. Es prüft zuerst, ob das API überhaupt in der Lage ist, auf Daten zuzugreifen. Dazu fragt der Testcode alle Bücher ab, die das Array enthält – es sollte anfangs leer stehen. Die dazu passende Abfrage lässt sich direkt im Playground eingeben, das Schlüsselwort »query« leitet sie ein. Danach folgt das abgefragte Objekt. Da der Anwender alle Bücher sehen möchte, lautet die Query »books«.
Innerhalb der Abfrage ergänzt der Tester zusätzlich noch jene Felder, die auch in der Antwort auftauchen sollen, etwa »isbn«. Normalerweise unterbreitet der Playground automatisch Vorschläge zu den verfügbaren Feldern. Ein Klick auf den Play-Button in der Mitte führt die Query aus, das Ergebnis lautet »null« (Abbildung 5). Wie erwartet, zeigt sich: Das API liefert momentan noch keine Daten zurück.
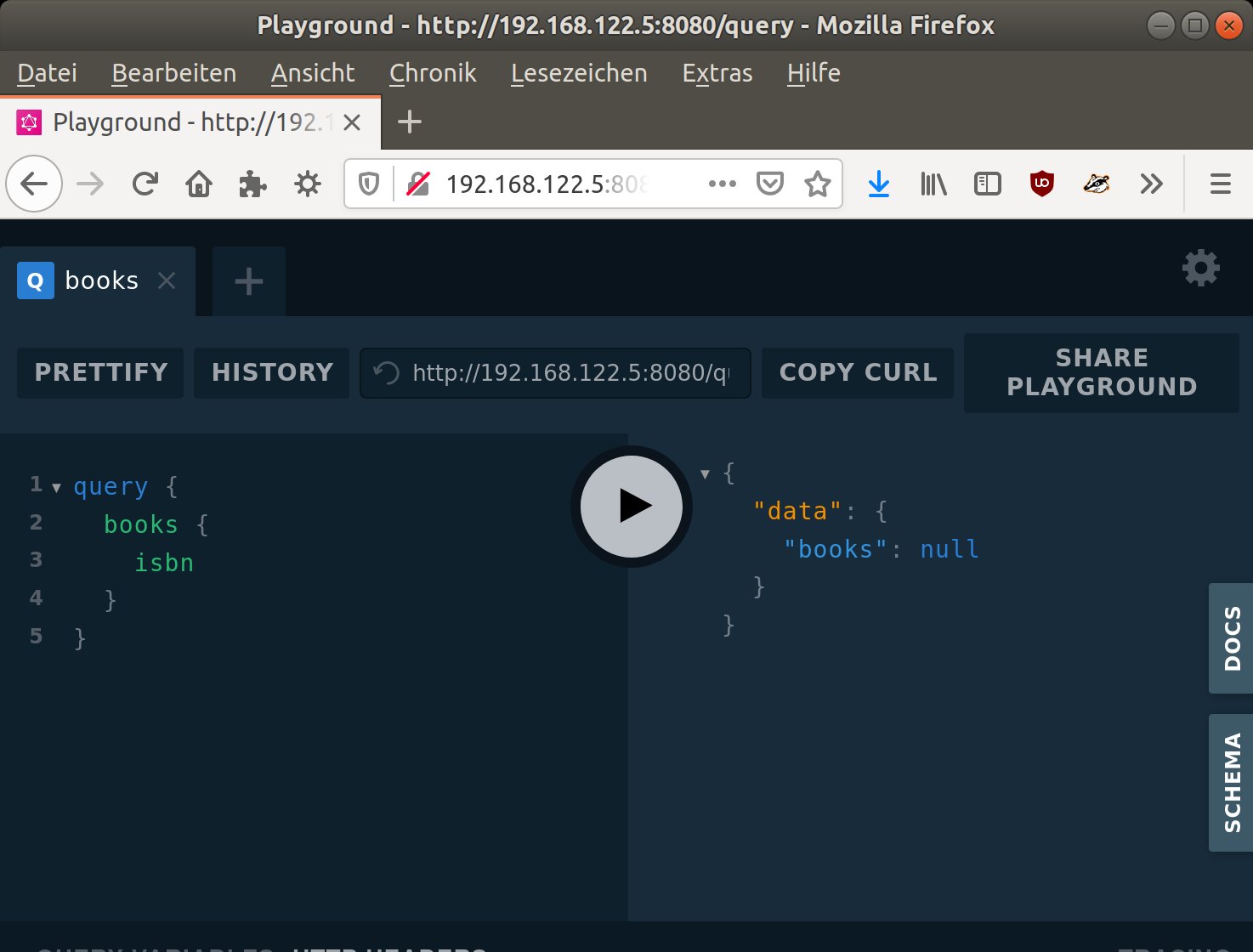
Abbildung 5: Die Testabfrage und ihr nicht ganz unerwartetes Ergebnis im Playground.
Gegebenenfalls kann der Entwickler auch mehrere Felder abfragen, die dann in der Antwort erscheinen. Um die Details dieser Abfragen kümmert sich GraphQL automatisch.
Im nächsten Schritt lässt sich das API testweise mit Daten füttern. In GraphQL kommt dazu die im Schema angelegte Mutation »createBook« zum Einsatz. Mutationen beginnen in den Abfragen mit dem Schlüsselwort »mutation«, gefolgt vom Namen der Mutation, also »createBook«. Danach ergänzt der Anwender in normalen Klammern die Parameter, wobei »createBook« ein Objekt vom Typ »NewBook« erwartet. Dafür übergibt der Anfragende eine »input«-Variable mit der eigentlichen Struktur (Listing 6).
Listing 6
Mutationen in GraphQL
mutation {
createBook(input:{isbn:"1234567890123", name:"Kurze Antworten auf große Fragen",authorname:"Stephen Hawking"}) {
isbn
name
}
}
Nach dem Erzeugen des Buchs folgt noch einmal die ursprüngliche Abfrage sämtlicher Bücher, um sicherzustellen, dass das neue ebenfalls erscheint. Nach dem Ausführen der Abfrage tauchen Buchtitel, ISBN und Autor auf der rechten Seite des Playgrounds auf (Abbildung 6).
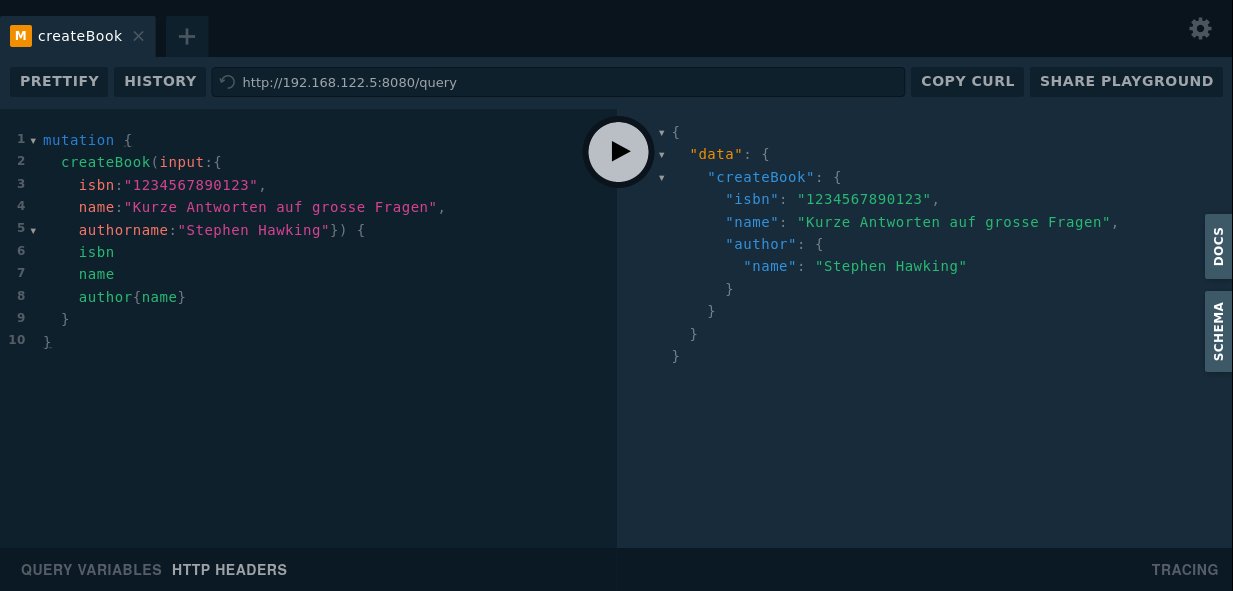
Abbildung 6: Im Playground lassen sich Bücher auch anlegen und dann abfragen.
Die Mutation für das Aktualisieren des Buchs spart sich der Artikel, da sie beinahe ebenso aussieht wie die zum Erzeugen eines Buchs. Lediglich der Name ändert sich von »createBook« zu »updateBook«.
Zum Löschen kommt die Mutation »deleteBook« zum Zug (Listing 7). Als Parameter braucht sie kein »input«-Objekt, sondern verwendet direkt eine ISBN. Es genügt, das Feld »isbn« mit der passenden Nummer anzugeben.
Listing 7
Funktion deleteBook
mutation {
deleteBook(isbn: "1234567890123") {
isbn
}
}
Fazit
Mittels Gqlgen setzt ein Entwickler GraphQL-Server zügig auf und integriert die Abfragen in seine Webanwendung. So bindet er beispielsweise schnell eine Suche ein und zieht die Daten im Hintergrund aus der API. Dazu bettet er die Abfrage in einen »POST«-Request ein und übergibt diesen als Body an den Server, oder er hängt die Abfrage als Parameter an einen »GET«-Request.
Um die Suchfunktion vollständig zu implementieren, fragt der Programmierer normalerweise die API ab. Dazu sendet er HTTP-Requests mit den Methoden »GET« oder »POST« sowie den gesuchten Parametern, beispielsweise der zu suchenden ISBN. Die angefragten Daten landen dann beim Client, der sie direkt anzeigt. Zugleich generiert die Software eine Dokumentation, die grundlegende Funktionen der API erklärt. Das ersetzt allerdings keine komplette Dokumentation, die der Entwickler zusätzlich schreiben sollte.
Da GraphQL Daten im JSON-Format ausgibt, können die meisten anderen Programmiersprachen die Resultate problemlos weiterverarbeiten und anzeigen. Der Entwickler spart sich so zusätzlichen Aufwand beim Umwandeln der Strukturen. (kki)
Der Autor
Der 22 Jahre alte Dominik Robert arbeitet aktuell als Informatiker in einer Versicherung und beschäftigt sich auch in seiner Freizeit mit dem Programmieren von Systemen und Webanwendungen.
Infos
-
GraphQL: https://graphql.org
-
GraphQL-Dateien: http://www.linux-magazin.de/static/listings/magazin/2020/03/graphql/
-
GraphQL-Schema: https://GraphQL.org/learn/schema/





