
© Khuntnop Asawachiwantorngul, 123RF
Dringt ein Angreifer in die eigene Cloud ein und erlangt sogar Benutzerdaten, ist die Katastrophe mit Händen zu greifen. Mit ein paar einfachen Tipps lässt sich das Risiko aber beträchtlich reduzieren.
Wer nichts Böses ahnend am Samstagmorgen am Frühstückstisch sein Tablet startet, um Nachrichten zu lesen, wird eines Tages womöglich von einer E-Mail erschreckt, in der ihm ein Onlinedienst oder eine Hotelkette oder der Admin seines Lieblings-Rollenspiel-Forums mitteilt, dass es vor kurzer Zeit leider zu einem Einbruch gekommen sei und dass die Angreifer alle Nutzerdaten mitgenommen haben, die zu finden waren.
Dass wenig später in Wanne-Eickel eine Waschmaschine im Gegenwert eines Geländewagens an eine gefakte Lieferadresse zugestellt wird, erfährt der betroffene Anwender erst dann, als der finanzielle Schaden längst in die Tausende geht. Was machte den Datendiebstahl möglich? Vielleicht eine Backupdatei, die der Admin unachtsam angelegt und so postiert hatte, dass sie direkt über den Webserver herunterladbar war.
Diese Geschichte ist keineswegs an den Haaren herbeigezogen: Längst ereignen sich solche Einbrüche regelmäßig. Und leider ist es völlig unmöglich, die Kontrolle über einmal verloren gegangene Daten wiederzugewinnen.
Da hilft nur, sofort das Richtige zu tun: Eventuell betroffene Kreditkarten sind sofort zu sperren und auszutauschen. Wer das gestohlene Passwort an anderen Stellen benutzt, muss die Passwörter auch dort sofort ändern.
Was tut Open Stack?
Einbrüche in Onlinedienste sind grundsätzlich fatal. Open Stack bildet da keine Ausnahme. Seine Entwickler versprechen ja gerade, dass es problemlos große Umgebungen für Plattformanbieter bau- und betreibbar macht. Je mehr Kunden eine Plattform jedoch hat, desto größer ist im Falle eines Einbruchs der entstandene Schaden.
Grund genug also, einen genaueren Blick auf das Thema Speicherung der Benutzerdaten in Open Stack zu werfen – und die Frage zu stellen: Inwiefern ist Open Stack besonders anfällig für oder besonders geschützt gegen die Angriffe auf seine Nutzerdaten? Welche Fallstricke sind aus Sicht des Administrators zu vermeiden? Und wie speichert Open Stack die Daten seiner Nutzer und deren Credentials überhaupt?
Diesen Fragen geht der Artikel auf den Grund. Ganz am Anfang der Betrachtungen steht logischerweise die in Open Stack für Nutzerverwaltung zuständige Komponente Keystone – nach einer kurzen Klärung, was Benutzerdaten im Open-Stack-Kontext überhaupt sind.
Der Begriff Benutzerdaten
Wer in Open Stack Ressourcen konsumieren möchte, muss sich dafür per Username und Passwort anmelden. Open Stack selbst verfügt damit über Nutzerdaten, die zu den Open-Stack-Metadaten gehören, die es selbst verwaltet und die Keystone speichert, worauf der Artikel zurückkommen wird.
In Clouds gibt es zusätzlich aber meist noch eine zweite und ebenso wichtige Kategorie der Nutzerdaten – nämlich solche, die die Cloudanwender selbst speichern. Wer etwa sein Angelgeschäft in einer Open-Stack-Installation betreibt, wird dort im Backend meist eine ganz klassische Datenbank für Produkt- und eben Benutzerdaten haben. Beschäftigt man sich mit der Frage, wie Open Stack Benutzerdaten schützt, gehören diese ebenso mit zur Betrachtung – denn kommen sie abhanden, ist das zwar für die Plattform nicht so schlimm, doch für den betroffenen Cloudanwender ist es fatal. Naturgemäß fällt der Fokus aber zunächst auf die Open-Stack-Metadaten, also auf Keystone.
Der Grundpfeiler
Keystone (Abbildung 1) bedeutet aus dem Englischen übersetzt soviel wie Grundstein, eine Bezeichnung, die durchaus zutrifft. Denn Keystone ist in jeder Open-Stack-Cloud diejenige Komponente, die als erste präsent sein und funktionieren muss. Die Architektur von Authentifizierung und Autorisierung in Open Stack sieht nämlich vor, dass jeder API-Aufruf mit einem gültigen Token ausgestattet sein muss.

Abbildung 1: Keystone ist der zentrale Open-Stack-Dienst, der die Logins und Passwörter aller Nutzer der Cloud verwaltet – und somit das Haupteinfallstor für Angreifer darstellt. © Oracle
Tatsächlich ist das bereits ein erster Beitrag von Open Stack, um den Angriffsvektor zu verkleinern. Und das geht so: Jeder Anwender hat eine gültige Kombination aus Passwort und Benutzername. Obendrein hat er meist auch eine Rolle im Open-Stack-Rechteschema im Kontext eines Projekts. Über das Keystone-API erfragt der Nutzer nun genau mit der Kombination aus Benutzername und Passwort einen temporär gültigen Autorisierungsschlüssel im Kontext dieses Projekts (Token).
Dieses Token lässt sich anschließend für API-Abfragen bis zum Ende seiner Gültigkeit nutzen. Benutzt der Admin die CLI-Clients oder das Open-Stack-Dashboard, holen diese sich mit Passwort und Username automatisch ein gültiges Token und verwenden es wie beschrieben.
Zur Nutzer-Seite hin gibt es also Vorsichtsmaßnahmen, die den Verlust der Login-Credentials zumindest unwahrscheinlicher machen. Doch welchem Sicherheitsansatz folgt Keystone grundsätzlich? Leider schaut es da, vom Token-System abgesehen, nicht allzu gut aus.
Die Datenbank im Hintergrund
Zweifellos das größte Einfallstor ist die Datenbank im Hintergrund, in der Keystone die Benutzerdaten ablegt. Wie jeder Open-Stack-Dienst setzt Keystone für seine eigenen Metadaten – und dazu gehören auch sämtliche Benutzernamen und Passwörter – auf eine Datenbank, im Regelfall MySQL. Im Idealfall liegt eben jene Datenbank auf einem separaten Server und ist per Firewall klar von jenen Servern getrennt, auf denen die Keystone-Instanzen selbst laufen. Auch einen Anschluss ans Internet braucht dieser Server nicht, denn außerhalb der Open-Stack-Umgebung sind die Open-Stack-Credentials nutzlos.
Gelingt es einem Einbrecher, sich Zugriff auf Keystone zu verschaffen, so findet er bei einer Trennung der Funktionen auf demselben Rechner nicht gleich auch noch MySQL. Freilich sind die Passwörter in MySQL verschlüsselt abgelegt, doch wie immer gilt auch hier: Vorsicht ist besser als Nachsicht. Zudem schadet es auch aus Sicht der Performance nicht, Keystone und MySQL auf unterschiedliche Hardware zu packen.
Hinter einem Load Balancer
Wer den vorgeschlagenen Weg mit separaten Datenbank-Servern so nicht gehen möchte, kann Keystone und MySQL durchaus auf denselben Hosts betreiben. Dann sollte allerdings sichergestellt sein, dass diese keine direkte Verbindung ins Netz haben und keinen Login von außen erlauben. Am einfachsten geht das mit einem vorgeschalteten Load Balancer nebst einer Firewall, die zusammen den Zugriff reglementieren. Unter allen Umständen gilt es aber zu verhindern, dass auf den Datenbank-Host jemand Remote-Zugriffsmöglichkeiten erhält.
Selbst wenn ein Ganove als normaler Nutzer Zugriff auf ein System mit Keystone (und womöglich MySQL) erlangt, ist noch nicht alles zu spät. Er kann nämlich zunächst mal gar nicht viel tun. Denn an die MySQL-Dateien, die meist in »/var/lib/mysql« liegen, kommt er ohne Weiteres nicht heran.
Die Keystone-Konfiguration
Hier fällt dem Admin im schlimmsten Fall allerdings eine Unachtsamkeit auf die Füße, die mit der Vergabe von Dateiberechtigungen zu tun hat. Gleich zwei potenzielle Einfallstore ergeben sich: In »/etc/keystone/keystone.conf« sind im Regelfall die Datenbank-Credentials verzeichnet, mit denen der Login in MySQL möglich wird. Bestehende Passwörter lassen sich damit zwar nicht auslesen, aber verändern, sodass das Problem Missbrauch der Cloud wieder auf die Tagesordnung tritt. Die Datei ist deshalb so zu schützen, dass nur der Dienst selbst sie lesend öffnen darf.
Ähnliches gilt für die Datei »stackrc«, die oft im Verzeichnis »/home/stack« auf Open-Stack-Bootstrap-Knoten zu finden ist. Sie enthält meist die Login-Credentials für mindestens ein Open-Stack-Projekt und regelmäßig auch die Credentials für einen Account mit der »admin«-Rolle, mit der sich die Daten in Keystone wiederum nach Belieben verändern lassen. Stehen die Rechte für diese Datei auf »0777«, ist sie den Augen unberechtigter Zuschauer ohne jeden Schutz ausgeliefert.
Dasselbe gilt übrigens auch für eine lokale Konfigurationsdatei für den MySQL-Kommandozeilen-Client »mysql«. Viele Anwender wollen nicht bei jedem Aufruf des Programms Benutzername und Passwort angeben und legen sie deshalb in einer Datei in »$HOME« ab. Ermöglichen diese allerdings den Zugriff auf MySQL, dann ist von dieser Vorgehensweise dringend abzuraten.
Setzt der Admin auf Automation etwa per Ansible, baut er in seine Rollen am besten einen Check ein, der sowohl »/etc/keystone/keystone.conf« als auch eine eventuell vorhandene »stackrc« mit den entsprechenden Zugriffsrechten versieht.
Das Admin-Token
Aus grauer Keystone-Vorzeit erhalten geblieben ist dem Administrator das Admin-Token in »/etc/keystone/keystone.conf«, ein besonderes Token (Abbildung 2), das früher notwendig war, um Keystone mit dem ersten Satz an Service-Credentials für die anderen Open-Stack-Dienste zu versorgen.
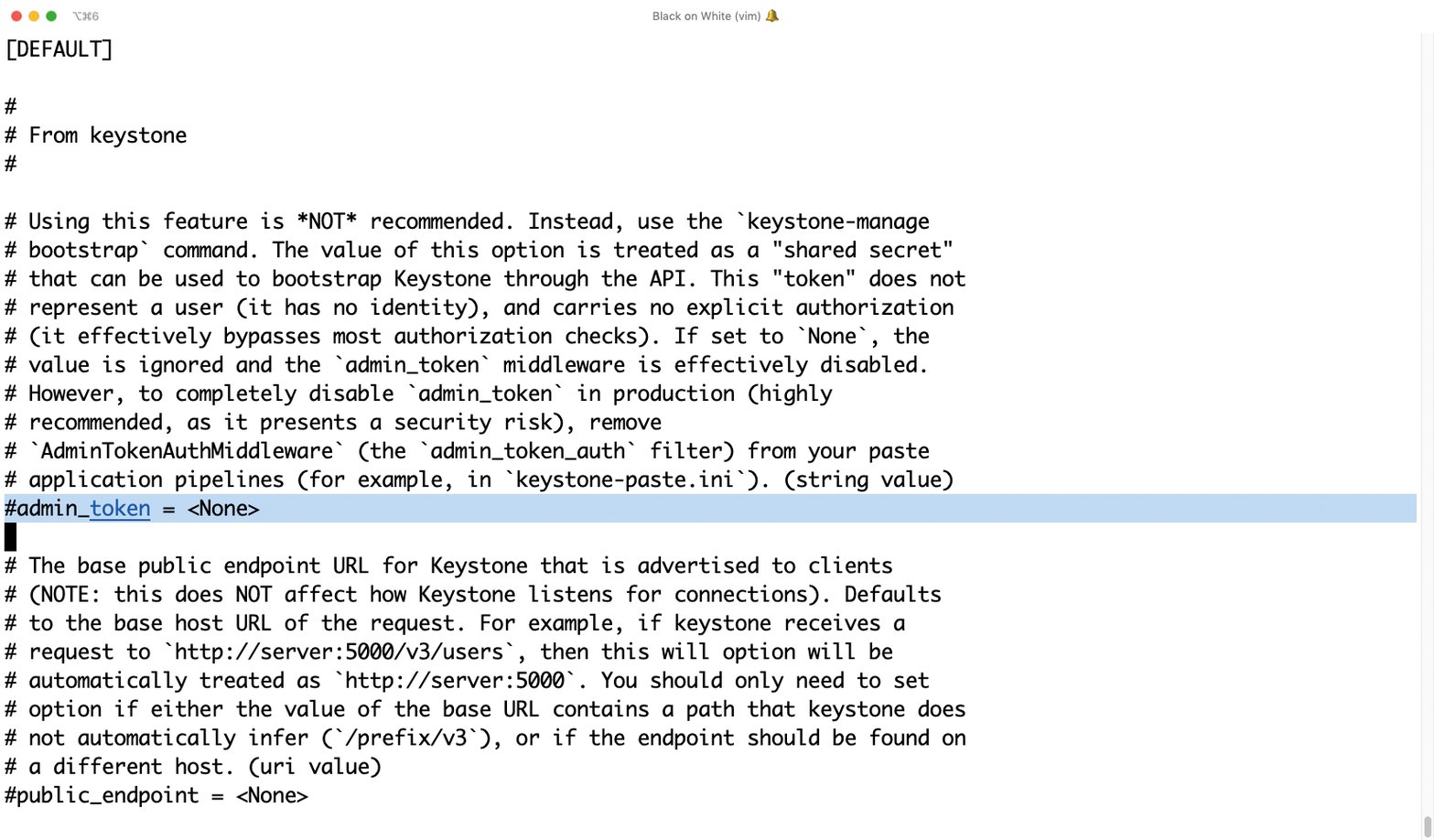
Abbildung 2: Das »admin_token« ist noch ein Relikt aus grauer Vorzeit und sollte bei Open-Stack-Clouds unbedingt deaktiviert sein.
Heute ist das so nicht mehr nötig, aber trotzdem erlaubt Keystone es bis heute, den Wert in der Konfigurationsdatei zu setzen. Admins tun gut daran, hier sicherzustellen, dass die entsprechende Zeile auskommentiert ist. Stattdessen einen leeren Wert setzen hilft nicht, denn dann ist der Keystone-Zugriff tatsächlich per leerem Admin-Token möglich.
Bekommt ein Angreifer einmal per Admin-Token Zugriff auf Keystone, kann er die dort befindlichen Benutzerdaten zwar nur zum Teil auslesen – die Passwörter bleiben ihm verborgen. Aber ändern kann er sie und so die Ressourcen der Cloud missbrauchen.
Updates nicht vergessen
Mittlerweile gilt es im Cloud-Kontext zwar als Binse, aber dennoch weist auch dieser Artikel ausdrücklich darauf hin: Von den Anbietern zur Verfügung gestellte Sicherheitsupdates sind unbedingt einzuspielen. Gerade in Clouds ist der Betrieb eines Softwaremuseums brandgefährlich. Regelmäßig entdecken die Open-Stack-Entwickler und Sicherheitsforscher Lücken in den einzelnen Teilen von Open Stack – ebenso wie bei jedem anderen Projekt auch. Nur wer Updates für diese Lücken regelmäßig einspielt, schützt sich effektiv.
Dasselbe gilt in gleichem Maße freilich auch für alle Nicht-Open-Stack-Komponenten. Bekommt ein Angreifer durch einen Fehler in Keystone erst Kommandozeilen-Zugriff auf ein System und anschließend über eine Privilege Escalation die Rechte von Root, nützen die besten Sicherheitsmaßnahmen gar nichts.
Falls doch mal etwas schiefgeht
Mal angenommen, sämtliche um Keystone aufgebauten Schutzmaßnahmen haben versagt – was ist bei einem Einbruch in Keystone eigentlich das Worst-Case-Szenario? Nur wer den Angriffsvektor versteht, kann sinnvoll prüfen und sich effektiv schützen – hier deshalb ein kleiner Überblick.
Für die Plattform selbst ist ein solcher Vorgang eine Katastrophe, die sich aber schnell beheben lässt, indem der Admin einmal alle Passwörter auf die radikale Art händisch ändert und den Nutzern die neuen Zugangsdaten zukommen lässt. Tut er das nicht, läuft er Gefahr, dass jemand mit den Daten aus Keystone in Open Stack Ressourcen anlegt und diese danach missbraucht. Auch für Anwender und deren (Benutzer-)Daten entsteht einiger Schaden, den zu reparieren mühsam sein wird.
Datensparsamkeit
Zunächst stehen in Keystone meist nur Benutzernamen mit dem zugehörigen Passwort. Zwar ist es möglich, weiterführende Informationen wie etwa Mailadressen zu hinterlegen. Kreditkartendaten stehen in Keystone aber definitiv nicht. Kommt es zu einem Keystone-Datenraub, erlangen Ganoven also nicht sofort Zugriff auf Kreditkartendaten, die im Anschluss für böswillige Zwecke leicht zu verwenden wären.
Passwörter sind in der Cloud out
Hinzu kommt: Das gern genutzte Passwort-Recycling (“Ein Passwort für alles”) ist in Clouds schon deshalb schwierig umzusetzen, weil die meisten Distributoren in ihren Cloudabbildern gar keine Passwörter erlauben. Hier sind SSH-Schlüssel die Regel. Gelangt jemand unautorisiert an die Login-Daten aus Keystone, kann er sich zwar in die jeweiligen Open-Stack-Accounts einloggen. Bestehende Systeme verändern darf der Angreifer aber im Normalfall nicht. Denn aus den Passwörtern in Keystone ist es meist unmöglich, Rückschlüsse auf eben jene Passwörter zu ziehen, die etwa für VMs in der Cloud gelten.
Stattdessen kommen vermehrt SSH-Schlüssel zum Einsatz. Startet ein Nutzer eine VM in Open Stack, muss er bei fast allen Images der großen Distributoren beim Anlegen der VM einen öffentlichen SSH-Schlüssel festlegen. Der wird dann über »cloud-init« in der Cloud hinterlegt und erlaubt den Login als ganz normaler Nutzer. Mittels »sudo« sind dann die Rechte von Root erreichbar. Um Schaden unmittelbar innerhalb der VMs anzurichten, müsste ein Angreifer in der Regel also auch den privaten SSH-Schlüssel haben, der zu den öffentlichen SSH-Schlüsseln in den VMs passt.
Also: Eigentlich alles gar nicht so schlimm, möchte man meinen. Doch ganz so leicht ist es dann doch nicht.
Totale Kontrolle
Wer in einer Open-Stack-Umgebung Zugriff auf ein Projekt hat, etwa weil er zuvor Keystone geknackt hat, erlangt umfangreiche Freiheiten. Hat sich ein Gauner Zugriff auf ein Projekt in Open Stack verschafft, darf er in der Regel laufende VMs anhalten und bestehende Volumes von diesen abkoppeln. Er kann im Anschluss eigene VMs starten, jene Volumes an diese anhängen und verändern.
Ist ein Volume die Root-Festplatte einer VM, könnte er sich zum Beispiel Zugriff auf den Root-Account verschaffen, indem er in »/etc/passwd« einen ihm bekannten Wert für das Passwort hinterlegt. Danach startet er die ursprüngliche VM erneut mit dem geänderten Passwort und loggt sich etwa per SSH ein.
Ebenso gut könnte er einfach die virtuelle Maschine abschalten, auf der die Nutzerdaten einer Kundenumgebung liegen – etwa die Datenbank des Webshops – und diese Daten davontragen. Natürlich wäre es auch denkbar, dass ein Angreifer laufende VMs durch präparierte eigene VMs ersetzt (Abbildung 3).
Abbildung 3: Verschafft sich ein Bösewicht Zugriff auf einen Tenant in der Cloud, darf er Volumes von laufenden VMs abkoppeln und verändern. © LinBit
Hier hilft nur Monitoring und sorgsames Auswerten der Logdateien. Denn ohne Downtime funktioniert der beschriebene Prozess nicht – kommt es also im Rahmen eines Einbruchs in eine Open-Stack-Cloud plötzlich zu Ausfallzeiten von VMs, ist höchste Aufmerksamkeit geboten. Wer seine Systeme sorgfältig mit Werkzeugen wie Inspec http://1 überwachtundToolswieAidehttp://2 nutzt, merkt schnell, wenn sich etwas ohne triftigen Grund im Dateisystem ändert.
Das setzt freilich voraus, dass es zumindest ein basales Monitoring gibt, das außerhalb der Cloud läuft – auf das ein Angreifer also nicht unmittelbaren Zugriff hat, nachdem er erfolgreich Keystone angegriffen hat (Abbildung 4).
Abbildung 4: Durchdachtes Monitoring ist essenziell, um Angriffe so rasch wie möglich zu erkennen. © Prometheus
Was übrigens zumindest im Kontext gehijackter Volumes hilft, ist deren Verschlüsselung: Der Angreifer kann dann zwar die verschlüsselten Inhalte vom Volume auslesen, aber die Nutzdaten bleiben vor seinen Augen verborgen.
SSL ist Pflicht
Eigentlich sollte im Jahre 2019 jedem Admin klar sein, dass Dienste, die mit Nutzerdaten hantieren, ihre Verbindungen zur Außenwelt und untereinander nur auf Basis von SSL-Verschlüsselung nutzen sollten. Die Erfahrung des Autors lehrt aber etwas anderes: Auf den Load Balancern, über die Anwender sich mit den Keystone-Backends verbinden, kommt zwar SSL regelmäßig zum Einsatz. Doch die Load Balancer dienen als SSL-Terminatoren – im Inneren des Setups sprechen die Dienste untereinander allesamt Klartext miteinander.
Diesem Ansatz liegt die Idee des sicheren und vertrauenswürdigen lokalen Netzwerks zugrunde, die sich aber schon oft genug als fataler Trugschluss herausgestellt hat. Gelingt es einem Angreifer, auch nur auf einem Knoten des Setups Rootrechte zu erlangen, kann er über Werkzeuge wie »tcpdump« den gesamten Netzwerkverkehr mitschneiden. Wenn darin Keystone-Credentials zu finden sind, hat er anschließend Keystone-Zugriff – im schlimmsten Fall als Account mit Admin-Rolle.
Es ist deshalb unbedingt empfehlenswert, die verschiedenen API-Dienste auch über SSL-gesicherte Verbindungen miteinander kommunizieren zu lassen. Dann muss man sich hinsichtlich der Frage, wie Verbindungen gegen Lauschangriffe abzusichern sind, merklich weniger Gedanken machen.
Schatulle für Benutzerdaten
Zumindest was die Nutzerdaten in Kundenapplikationen angeht, bietet Open Stack übrigens noch einen besonderen Dienst, der nicht unerwähnt bleiben soll: Barbican. Wobei die Bezeichnung Dienst für Barbican vielleicht etwas hoch gegriffen ist – ähnlich wie Keystone ist Barbican eigentlich nur ein API, das beim Speichern von Passwörtern allerdings praktisch ist (Abbildung 5).

Abbildung 5: Barbican ist ein Open-Stack-Dienst, der das sichere Speichern von Passwörtern an zentraler Stelle ermöglicht. © Open Stack
Im Grunde handelt es sich um eine Art Key-Value-Store: Unter einem Namen in Form eines Strings legt der Admin per API-Aufruf ein Passwort in Barbican ab. Der Dienst kümmert sich darum, dieses Passwort verschlüsselt in seiner eigenen Datenbank als Base64-kodierten String abzulegen. Haupteinsatzzweck dafür sind eigentlich Kryptoschlüssel, beispielsweise die schon genannten Pärchen aus öffentlichem und privatem SSH-Schlüssel oder Gnu-PG-Keys.
Die Motivation bei der Entwicklung von Barbican war, dass es bisher weder für Windows noch für Linux ab Werk eine gute Methode gibt, vertrauliche Informationen zu speichern. Den privaten Teil eines SSH-Schlüssels beispielsweise kann der Admin nicht einfach statisch in eine VM kopieren, weil er dann weg ist, wenn jemand die VM aufbricht. Und ebenso ist es keine gute Idee, relevante Passwörter oder die Benutzerdaten des eigenen Onlineshops im Klartext in irgendwelche Datenbank innerhalb einer VM abzulegen.
Barbican tritt deshalb als generische, gut dokumentierte API-Schnittstelle an, die einerseits den Aspekt abdeckt, Daten sicher zu speichern. Und andererseits bietet Barbican auch eine Schnittstelle, um benötigte Credentials unverschlüsselt auszulesen, wenn sie im laufenden Betrieb gebraucht werden. Dazu muss der verarbeitende Client sie sich allerdings nicht permanent merken oder lokal zwischenspeichern. Denn selbst nach einem Reboot kann er ja die entsprechenden Daten wieder ganz regulär auslesen.
API-Anpassungen
Wer Barbican auf die beschriebene Art und Weise nutzen möchte, sieht sich in den meisten Fällen aber wohl eines Rewrite von Teilen seiner Applikation gegenüber. Denn so verbreitet ist Barbican nicht, dass es im Massenmarkt für die gängigen CMS- oder Webshop-Systeme fertige Anbindungen gäbe.
Immerhin: Weil Barbican quelloffene Software und ein offener Standard ist, existiert eine detaillierte Dokumentation für Entwickler. Auf Basis dieser Dokumentation ist es nicht allzu schwierig, die eigene Applikation so umzubauen, dass sie die Benutzerdaten eben nicht mehr im Hintergrund auf MySQL oder aus PostgreSQL fischt, sondern per REST-Abfrage direkt aus Barbican.
Eine Challenge gibt es dabei allerdings zu bewältigen: Barbican läuft längst nicht auf jeder Public-Open-Stack-Installation mit. Vielen Admins ist gar nicht klar, dass der Dienst überhaupt existiert, denn anders als Nova oder Neutron gehört er nicht zu den Kerndiensten, ohne die Open Stack sich nicht betreiben lässt. Wer eine Open-Stack-Cloud administriert, sollte also prüfen, ob er Barbican bereits anbietet – und falls nicht, den Dienst entsprechend nachrüsten. Wer Open Stack ohnehin automatisiert ausrollt, findet in seiner Automationslösung garantiert das passende Modul, das auch Barbican an den Start bringen kann.
Fazit
Leider kommt Open Stack nicht mit besonders vielen Bordmitteln, die Keystone gegen Angriffe absichern. Das Motto für den Admin ist eher Eigeninitiative. Doch zum Glück lässt die Situation sich mit ein paar einfachen Kniffen ganz erheblich entschärfen. Dazu gehört das Verteilen der verschiedenen Dienste auf mehrere Server, um eine Separation of Concern herbeizuführen – glückt den Angreifen doch mal etwas, hält sich der Schaden so in Grenzen.
Und ganz wichtig: Verlässliches Monitoring, Alerting und Trending (MAT) der gesamten Plattform ist ein unbedingtes Muss. Hat ein Angriff Erfolg, dann will der Admin das naturgemäß schnellstmöglich erfahren – und das kann nur in der nötigen Zeit passieren, wenn entsprechende Werkzeuge wie Prometheus [3] am Werk sind und funktionieren. Auch der Einsatz von IDS- und IPS-Systemen wie Suricata [4] schadet nicht, weil sich damit automatisch Standardangriffe erkennen lassen.
De facto führt der Admin in Open Stack beim Thema Sicherheit der Benutzerdaten also einen Zwei-Fronten-Krieg. Zum einen hat er mit geeigneten Mitteln dafür zu sorgen, dass die Hardware keinen ungewollten Abfluss von Daten ermöglicht. Zum anderen muss er die virtuellen Setups von Kunden betreuen und dort das Abfließen von deren Benutzerdaten verhindern – für den Fall, dass doch mal jemand Keystone knackt.
Infos
-
Inspec: https://www.inspec.io]
-
Aide: https://aide.github.io]
-
Prometheus: https://prometheus.io
-
Suricata: https://suricata-ids.org
Der Autor

Martin Gerhard Loschwitz ist Senior Cloud Architect bei Mirantis und beschäftigt sich dort vorrangig mit Themen wie Open Stack, Ceph und Kubernetes.





