
© ktsdesign, 123RF
Die asynchrone Master/Slave-Replikation setzen MySQL- oder Maria-DB-Admins oft ein. Meist funktioniert sie problemlos, wenn sie aber aus dem Tritt gerät, muss der Admin wissen, was zu tun ist.
Der Slave hinkt dem Master immer ein wenig hinterher, das ist es ja gerade, was das Adjektiv “asynchron”, also ungleichzeitig, meint. Praktisch beträgt der Zeitabstand meist weniger als eine Sekunde und ist damit nicht relevant. Wenn er sich durch einen Fehler merklich vergrößert, wird es problematisch. Denn dann erhält der Nutzer, der vom Slave statt vom Master liest, veraltete oder schlimmstenfalls sogar irreführende Daten.
Deshalb sollte der DBA als Hüter einer Master/Slave-Replikation den Zeitverzug auf Seite des Slave immer im Blick haben. Manuell ermittelt er ihn so wie in Listing 1. In diesem Fall behauptet der Slave, dass er 3 Sekunden hinter dem Master zurück ist. Den Ausdruck »\G« kann der Admin hier im Maria-DB-/MySQL-CLI anstelle des Semikolons verwenden. Er bewirkt dann einen Umbruch, der jede Spalte in einer eigenen Zeile ausgibt. Das ist manchmal lesbarer, als alle Spalten in einer Zeile darzustellen. Zudem erleichtert dieses Format die Suche per »grep« in Skripten.
Listing 1
Zeitverzug ermitteln
01 SQL> SHOW SLAVE STATUS\G 02 *********************** 1. row ********************** 03 [...] 04 Seconds_Behind_Master: 3 05 [...] 06 1 row in set (0.000 sec)
Die Bedeutung des Wertes »Seconds_Behind_Master« ist exakt die Differenz aus der Systemzeit des Slave und jener Zeit, zu der genau der Master das Event geschrieben hat: »CURRENT_TIMESTAMP(Slave)« – »Event_Creation_Timestamp(Master)«. Bei einer schnellen Netzwerkverbindung ist dieser Wert eine gute Näherung dafür, wie weit ein Slave hinter einem Master hinterherhängt. Allerdings kann dabei auch eine ungenaue lokale Systemzeit eine Rolle spielen. Deshalb sollte man unbedingt NTP zur Synchronisation der Uhren nutzen.
Den Befehl aus Listing 1 könnte der Admin händisch in regelmäßigen Abständen ausführen, um zu sehen, ob und wie sich die Zeitdifferenz ändert. Viel praktischer ist es jedoch, das Ganze grafisch in der Monitoringlösung der Wahl darzustellen (Abbildung 1).
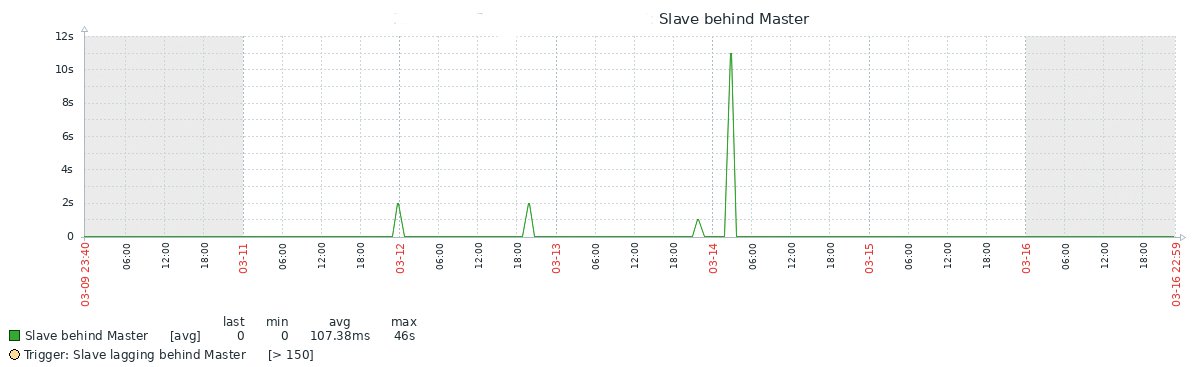
Abbildung 1: Das Slave Lag im Verlauf einer Woche, dargestellt durch ein Monitoringsystem.
Man könnte meinen, der Wert »NULL« bei »Seconds_Behind_Master« wäre ideal – doch das Gegenteil ist der Fall. »NULL« heißt hier nämlich, dass die Replikation aus irgendeinem Grund gar nicht mehr läuft. Eine gesunde Replikation sieht so aus wie in Listing 2: I/O- und SQL-Thread laufen (»Yes«), der I/O-Thread wartet auf den Master (»IO_Running«), der SQL-Thread wartet auf den I/O-Thread (»Slave_SQL_Running«), keine Fehler zu sehen (»Errno« und »Error«), kein Hinterherhinken – so sollte es im Idealfall sein.
Listing 2
Funktionierende Replikation
01 SQL> SHOW SLAVE STATUS\G 02 *************************** 1. row *************************** 03 Slave_IO_State: Waiting for master to send event 04 [...] 05 Slave_IO_Running: Yes 06 Slave_SQL_Running: Yes 07 [...] 08 Seconds_Behind_Master: 0 09 [...] 10 Last_IO_Errno: 0 11 Last_IO_Error: 12 Last_SQL_Errno: 0 13 Last_SQL_Error: 14 [...] 15 Slave_SQL_Running_State: Slave has read all relay log; waiting for the slave I/O thread to update it 16 1 row in set (0.000 sec)
Die häufigste Ursache für eine große Verzögerung zwischen Master und Slave sind lange laufende und/oder große Transaktionen (viele kleine Transaktionen mögen Datenbanken viel lieber), DDL-Operationen (»CREATE«, »ALTER«, »DROP«) sowie »UPDATE«- und »DELETE«-Statements auf Tabellen ohne Primary Key (bei älteren Maria-DB- und MySQL-Versionen). Eine wirksame Maßnahme zur Vorbeugung ist es deshalb, darauf zu achten, dass keine großen Tabellen ohne Primary Key vorkommen. Ansonsten muss der Slave nämlich für jedes »UPDATE«- und »DELETE ROW«-Event vom Master einen Full Table Scan ausführen, was dann das hohe Slave Lag zur Folge hat.
Im Monitoring wären dann typische Sägezahnkurven zu sehen (Abbildung 2). Wie schon gesagt, bedeutet ein Wert von >= 0 für »Seconds_Behind_Master«, dass die Replikation läuft, und »Seconds_Behind_Master: NULL« zeigt dagegen an, dass die Replikation steht und mit großer Wahrscheinlichkeit ein Problem hat (es sei denn, der Admin hat sie mit Absicht gestoppt).
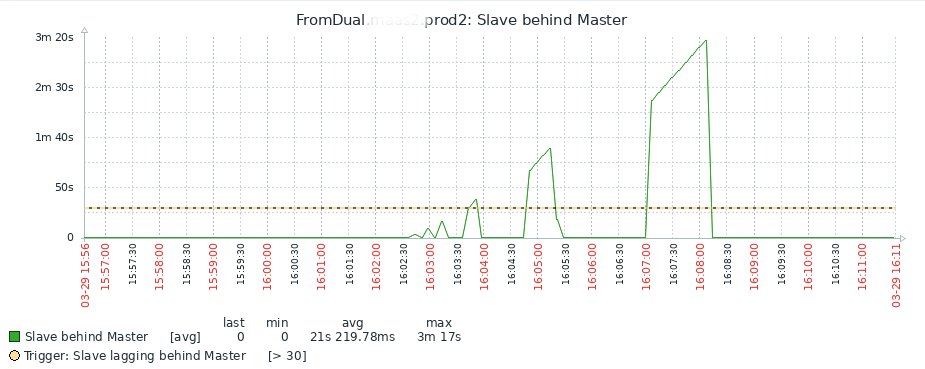
Abbildung 2: Sägezahnkurve beim Slave Lag, hervorgerufen durch DDL-Operationen oder große Transaktionen.
Die Maria-DB-/MySQL-Replikation ist eine alte und somit sehr ausgereifte Technologie. Das heißt, die Wahrscheinlichkeit, auf Bugs zu stoßen, ist relativ gering. Daher ist es sinnvoller, wenn sich der Administrator bei Replikationsproblemen fragt: “Was habe ich falsch gemacht?” Eine Fehlerursache im Bereich der Replikation selbst ist nämlich ziemlich unwahrscheinlich, wenn auch nicht vollkommen ausgeschlossen.
I/O-Probleme
Replikationsprobleme offenbart auch die Ausgabe des Befehls »SHOW SLAVE STATUS«. Wenn der I/O-Thread ein Problem hat, sieht das so aus wie in den Listings 3 oder 4. In Listing 3 kann sich der Slave nicht zum Master verbinden. Dies kann verschiedene Ursachen haben: Der User, mit dem sich der Slave auf den Master verbinden soll, ist nicht vorhanden oder Passwort, IP-Adresse oder Port sind falsch oder die Firewall macht dicht oder es gibt andere Netzwerkprobleme.
Listing 3
I/O-Probleme bei Replikation (1)
01 SQL> SHOW SLAVE STATUS\G 02 *************************** 1. row *************************** 03 Slave_IO_State: Connecting to master 04 [...] 05 Slave_IO_Running: Connecting 06 [...] 07 Last_IO_Errno: 2003 08 Last_IO_Error: error connecting to master 'replication@127.0.0.1:3338' - retry-time: 60 maximum-retries: 86400 message: Can't connect to MySQL server on '127.0.0.1' (111 "Connection refused") 09 [...] 10 1 row in set (0.000 sec)
Um die Ursache zu isolieren, empfiehlt es sich hier, das Problem des Slave mit dem CLI vom Slave aus nachzubauen:
mysql --user=replication --password --host=IP_vom_master --port=Port_vom_U master --execute="SELECT @@hostname"
Sobald dieser Befehl funktioniert, müsste der I/O-Thread des Slave eine Verbindung aufbauen können (»STOP SLAVE; START SLAVE;« hilft bei Ungeduld).
Im Fall von Listing 4 scheint der Slave ein Binary Log vom Master anzufordern (»binlog.000109«), das der aber nicht (mehr) zu kennen scheint. Dies lässt sich mit dem Befehl aus Listing 5 auf dem Master überprüfen.
Listing 5
Log-Check
01 SQL> SHOW BINARY LOGS; 02 +---------------+-----------+ 03 | Log_name | File_size | 04 +---------------+-----------+ 05 | binlog.000110 | 443 | 06 | binlog.000111 | 462 | 07 | binlog.000112 | 377 | 08 +---------------+-----------+
Listing 4
I/O-Probleme bei Replikation (2)
01 SQL> SHOW SLAVE STATUS\G 02 *************************** 1. row *************************** 03 Slave_IO_State: 04 [...] 05 Master_Log_File: binlog.000109 06 Read_Master_Log_Pos: 439 07 [...] 08 Slave_IO_Running: No 09 Slave_SQL_Running: Yes 10 [...] 11 Last_IO_Errno: 1236 12 Last_IO_Error: Got fatal error 1236 from master when reading data from binary log: 'Could not find first log file name in binary log index file' 13 [...] 14 1 row in set (0.000 sec)
Es wird in diesem Fall so sein, dass jemand oder etwas die Binary Logs auf dem Master gelöscht hat (»PURGE BINARY LOGS« oder »expire_logs_days«), bevor der Slave sie anforderte. Das heißt mit anderen Worten, der Slave war zu lange gestoppt. Und beim Aufräumen war das Skript nicht clever genug, um zu prüfen, ob der Slave die Binary Logs noch benötigt. In diesem Fall ist der Slave allerdings verloren und muss neu aus dem Master erstellt werden.
SQL-Probleme
Falls nicht der I/O-, sondern der SQL-Thread ein Problem hat, kann das aussehen wie in Listing 6 oder 7. Sofern er die Maria-DB-/MySQL-Replikation überwacht, sieht der Admin das sofort (Abbildung 3).
Listing 7
SQL-Probleme (2)
01 SQL> SHOW SLAVE STATUS\G 02 *************************** 1. row *************************** 03 [...] 04 Slave_IO_Running: Yes 05 Slave_SQL_Running: No 06 [...] 07 Last_SQL_Errno: 1032 08 Last_SQL_Error: Could not execute Delete_rows_v1 event on tabletest.test; Can't find record in 'test', Error_code: 1032; handler error HA_ERR_KEY_NOT_FOUND; the event's master log binlog.000112, end_log_pos 1383 09 [...] 10 1 row in set (0.000 sec)
Listing 6
SQL-Probleme (1)
01 SQL> SHOW SLAVE STATUS\G 02 *************************** 1. row *************************** 03 [...] 04 Slave_IO_Running: Yes 05 Slave_SQL_Running: No 06 [...] 07 Last_SQL_Errno: 1062 08 Last_SQL_Error: Could not execute Write_rows_v1 event on table test.test; Duplicate entry '2' for key 'PRIMARY', Error_code: 1062; handler error HA_ERR_FOUND_DUPP_KEY; the event's master log binlog.000112, end_log_pos 1149 09 Slave_SQL_Running_State: 10 [...] 11 1 row in set (0.000 sec)
Beide Fehler sind sehr eng miteinander verwandt. Beide wollen sagen, dass die Daten auf Master und Slave nicht identisch sind. Im ersten Fall ist eine Row auf dem Slave schon da, obwohl sie es nicht sein dürfte (»HA_ERR_FOUND_DUPP_KEY«), und im zweiten Fall fehlt eine Row auf dem Slave, die eigentlich da sein sollte (»HA_ERR_KEY_NOT_FOUND«). In beiden Fällen ist die Datenkonsistenz zwischen Master und Slave gestört und der Admin sollte ernsthaft überlegen, wie das der Fall sein kann. Mit großer Sicherheit ist nicht die Replikationstechnologie selber schuld.
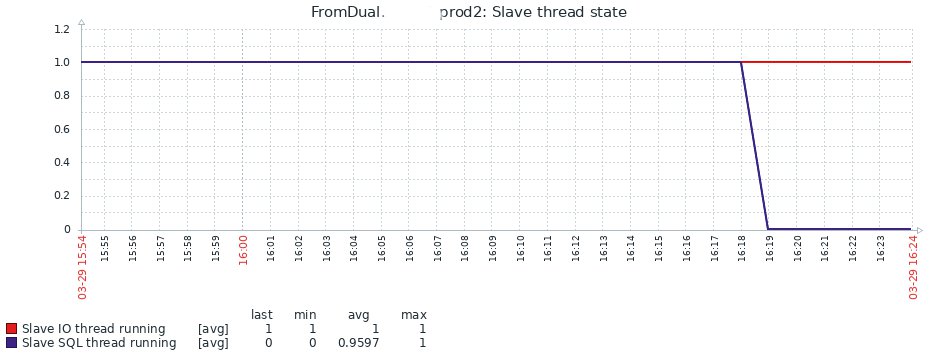
Abbildung 3: Eine Unterbrechung der Replikation wird im Monitoring sofort angezeigt.
Heilen und vorbeugen
Als erste Maßnahme drängt sich auf, das Problem zu beheben, und die sicherste Methode dafür ist es, den Slave neu aus den Daten des Masters wieder aufzubauen. Ein Workaround, um die Replikation schnellstmöglich wieder ins Laufen zu bekommen, wäre im ersten Fall, die Row, die zu viel ist, auf dem Slave einfach zu löschen (»DELETE FROM test.test WHERE id = 2;« bei »HA_ERR_FOUND_DUPP_KEY«). Welche Row Ärger bereitet, steht in der Fehlermeldung.
Im zweiten Fall – bei »HA_ERR_KEY_NOT_FOUND« –hilft es, die gleichen Daten wie auf dem Master auf dem Slave einzufügen (»INSERT INTO test.test VALUES (…);«). Wie die Row aussieht, steht im Binary Log »binlog.000112« des Masters vor Position 1383. Man kann die Events, die vom Master kommen, einfach überspringen (»STOP SLAVE; SET GLOBAL sql_slave_skip_counter=1; START SLAVE;«). Aber spätestens dann laufen die Daten zwischen Master und Slave auseinander.
Es ist auch unbedingt wichtig zu verstehen, dass dies nur ein Kurieren am Symptom und keine Bekämpfung der Ursache ist. Der Admin muss unbedingt verstehen, wie es zu dieser Situation kam. Zudem bedeutet das Wieder-zum-Laufen-Bekommen der Replikation überhaupt nicht, dass auch die Daten damit wieder korrigiert sind. Es können kurz darauf die gleichen Symptome wieder auftreten. Viel schlimmer sind aber noch Zeilen, die auf Master und Slave unterschiedliche Werte aufweisen. Die fallen nämlich bei einer normalen Replikation gar nicht auf.
Dass sich die Daten zwischen Master und Slave unterscheiden, kann mehrere Ursachen haben. Der häufigste Grund ist, dass das Backup des Masters kein sauberer, konsistenter Snapshot der Daten war. So könnte es sein, dass während des Backups noch Daten auf dem Master modifiziert wurden. Da lässt sich vermeiden, indem der Admin eine physische Backup-Methode wie Maria Backup oder Xtrabackup verwendet. Benutzt er dagegen doch »mysqldump«, so sollte er die Option »–single-transaction« (bei Inno DB) oder »–lock-all-tables« (bei MyISAM oder MyISAM-/Inno-DB-Mischbetrieb) einsetzen.
Die zweithäufigste Ursache, warum es zu Problemen kommt, ist, dass der Aufsetzpunkt des Slave (»CHANGE MASTER TO master_log_file=’nnn‘, MASTER_LOG_POS=’mmm’;«) falsch gewählt wurde. GTID Based Replication kann zwar dabei helfen, dieses Problem zu entschärfen, bringt aber andere, neue Schwierigkeiten mit sich.
Die dritte Möglichkeit, warum die Daten zwischen Master und Slave nicht konsistent sind, besteht darin, dass irgendjemand oder irgendetwas auf dem Slave Daten modifiziert hat. Das lässt sich mit der Variablen »read_only« oder »super_read_only« (bei MySQL) und »read_only« (bei Maria DB) verhindern.
Darüber hinaus gibt es noch einige weitere Möglichkeiten, warum Daten zwischen Master und Slave unterschiedlich sein können. Die Wahrscheinlichkeit, auf einen solchen Fall zu treffen, liegt aber unter zehn Prozent.
Der Master crasht
Es kommt vor, dass sich der Master in einer Master/Slave-Replikation unerwartet beendet, sei es durch Stromausfall oder durch äußere Einwirkung etwa eines Out-of-Memory-Killers oder des Admin. In diesem Fall besteht die Möglichkeit, dass der Slave ein Binary Log vom Master anfordert, das der nicht liefern kann, weil er es zuvor nicht sauber schließen konnte – so wie in Listing 8.
Listing 8
Probleme mit dem Master
01 SQL> SHOW SLAVE STATUS\G 02 *************************** 1. row *************************** 03 [...] 04 Last_IO_Errno: 1236 05 Last_IO_Error: Got fatal error 1236 from master when reading data from binary log: 'Client requested master to start replication from position > file size; the first event 'binlog.000114' at 644642725, the last event read from './binlog.000114' at 4, the last byte read from './binlog.000114' at 4.' 06 [...] 07 1 row in set (0.000 sec)
Dieses Problem kann der Admin beheben, indem er den Slave auf die erste Position des neuen Binary Log setzt:
SQL> CHANGE MASTER TO MASTER_LOG_FILE='binlog.000115', MASTER_LOG_POS=4;
Damit sollte der Fehler aus der Welt geschafft sein.
Was sonst noch zu Fehlern führt
Die eben besprochenen Szenarien sind die häufigsten Fälle (90 Prozent) von Problemen. Die restlichen 10 Prozent sind etwas schwieriger in den Griff zu kriegen. Um zu verstehen, was alles schiefgehen kann, muss sich der Nutzer zuerst genauer anschauen, wie die Maria-DB-/MySQL-Replikation überhaupt funktioniert (Abbildung 4).
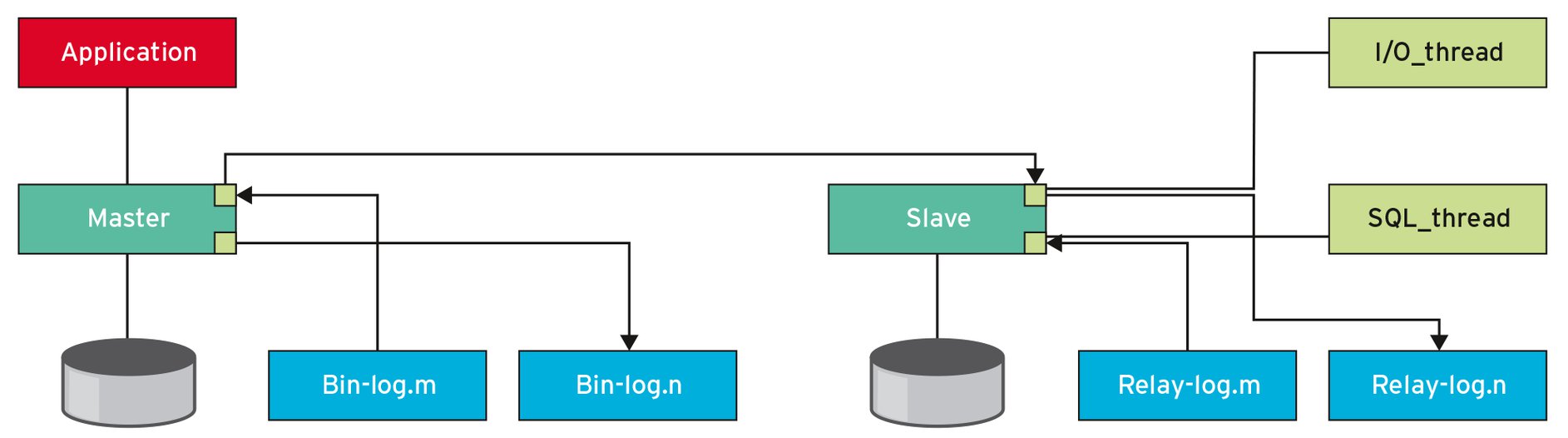
Abbildung 4: Schematische Darstellung der Prozesse bei einer Maria-DB-/MySQL-Master/Slave-Replikation.
Die Maria-DB-/MySQL-Instanz schreibt die Änderungen jedes »INSERT«-, »UPDATE«- oder »DELETE«-Statements (DML-Befehle) einerseits in die Tabellen der jeweiligen Storage Engine (Inno DB, My ISAM, Aria und so weiter), andererseits werden die Änderungen (Row Changes bei Row-Based-Replication (RBR), Statements bei Statement-Based-Replication (SBR)) auch ins Binary Log geschrieben.
Dass hierbei bereits ein Fehler auftritt, ist zwar nicht ganz auszuschließen, aber eher unwahrscheinlich. Um sicherzugehen, dass das Event auf der Platte weder verändert noch zerstört wird, schreibt die Datenbank einerseits die Event-Länge wie auch eine CRC32-Checksumme mit ins Event (»binlog_checksum«). Bei der Replikation fordert jetzt der I/O-Thread des Slave das nächste Event vom Master an, das der Master von Platte lesen muss. Bereits dieser Schritt kann das Event beschädigen. Der Master ist allerdings in der Lage, das zu verifizieren, was die Variable »master_verifiy_checksum« triggert, die allerdings per Default ausgeschaltet ist.
Anschließend wird das Event vom Master zum Slave über ein mehr oder weniger zuverlässiges Netzwerk übertragen, wobei das Event ebenfalls zu Schaden kommen kann. Um sicherzustellen, dass nichts passiert, überprüft es der I/O-Thread des Slave, der das Event anfordert, noch bevor er es auf seine eigene Platte ins so genannte Relay Log (quasi eine Kopie des Binary Log) schreibt.
Nachdem das Relay Log auf der Platte des Slave gelandet ist, kann es selber natürlich ebenfalls wieder Schaden nehmen. Aus diesem Grund prüft auch der SQL-Thread des Slave das Event noch ein weiteres Mal, bevor er es in die Datenbank schreibt.
In der Praxis trat beim Autor dabei kürzlich das folgende Problem auf: Alle paar Tage zeigte sich auf dem Slave ein Fehler im Maria-DB-/MySQL-Error-Log (Listing 9). Die Fehlermeldung ist recht aussagekräftig: Der I/O-Thread meckert, dass die Checksummenprüfung fehlschlägt. Später bemerkt er, dass er das Event nicht ins Relay Log schreiben kann. Das Event scheint kaputt auf dem Slave angekommen zu sein, sodass erstens die Checksumme nicht mehr stimmt und zweitens der I/O-Thread es nicht mehr in sein Relay Log schreiben konnte.
Listing 9
Fehler beim Schreiben des Log
01 [ERROR] Slave I/O for channel '': Replication event checksum verification failed while reading from network. Error_code: 1743 02 [ERROR] Slave I/O for channel '': Relay log write failure: could not queue event from master, Error_code: 1595
Zwei Aussagen des betroffenen Kunden haben dann geholfen, das Problem einzugrenzen: Nach mehrmaligem Stoppen und Starten des Slave hat sich das Problem jeweils von alleine wieder gelöst. Und: Dieser Master hatte mehr als einen Slave, und das Problem trat nur bei einem Slave auf.
Beide Aussagen deuten darauf hin, dass die Daten korrekt im Binary Log des Masters vorliegen (bei erneutem Anfordern konnten sie korrekt geliefert werden). Die zweite Aussage deutet darauf hin, dass das Problem nahe beim problematischen Slave liegen muss. Es stellte sich dann bei weiterem Nachforschen heraus, dass der Kunde ein Problem in seinem Netzwerk hatte, das die Events zerstörte.
Fazit
Die Master/Slave-Replikation für Maria DB/MySQL ist eine robuste und gut abgehangene Technologie. Trotzdem will jede Replikations-Technologien genau überwacht werden. Kritisch ist dabei vor allem, ob die Replikation überhaupt noch läuft und wie weit der Slave hinterherhinkt. Die Replikation kann auch aus unterschiedlichen Gründen brechen. Das sollte der Admin zeitnah erkennen und mit geeigneten Maßnahmen wieder reparieren. Die Ursachenforschung wiederum braucht hin und wieder auch etwas Spürsinn.





