
© Romolo Tavani, 123RF
In der Cloud-Computing-Praxis sind Backups gleich mehrfach wichtig: Kunden wollen ihre Daten sichern und Anbieter die essenziellen Details ihrer Plattform. Rette sich, wer kann.
Von der allgemeinen Notwendigkeit, Backups anzulegen, muss man heute kaum noch einen Administrator überzeugen. Und doch gewinnt das Thema im Kontext des Cloud Computings eine neue Brisanz: Alte Automatismen funktionieren nicht mehr. Und nicht selten bezichtigen Unternehmen und geschädigte Kunden sich gegenseitig, für das Anlegen von Sicherungskopien verantwortlich gewesen zu sein. Doch dann ist es oft schon zu spät und wichtige Daten sind unwiderruflich verloren.
Aus gutem Grund raten alle Cloudmigrations-Anleitungen dazu, sich ernsthaft Gedanken über das Thema Backup zu machen. Das Linux-Magazin erörtert, worauf Anbieter wie Kunden achten sollten.
Zwei Perspektiven
Für das Backup in konventionellen Setups ist die Lage ja in den meisten Fällen klar: Wer bei einem Dienstleister das Rundum-Sorglos-Paket bestellt, wird selbstverständlich davon ausgehen, dass der Anbieter sich auch um das Thema Backup kümmert. Dem Anbieter fällt dann die Aufgabe zu, alle Nutzdaten so zu sichern, dass sie im Falle eines Falles schnell wieder verfügbar sind.
Das umfasst einige technische Finessen, etwa inkrementell zurückrollbare Backups, wenn beispielsweise ein spezifischer Datenbankstatus wiederherzustellen ist. Der Kunde beschränkt sich in diesem Modell darauf, eine Recovery-Aktion per Zuruf auszulösen.
In Clouds funktioniert dieses Prinzip nicht mehr. Denn zunächst gibt es hier oft die klassische Anbieter-Kunden-Beziehung gar nicht mehr. Aus Sicht des Kunden ist der Anbieter der Plattform-Provider, doch die Website, die in der Cloud läuft, hat möglicherweise ein externes Unternehmen programmiert, und für den Betrieb ist man eigentlich selbst verantwortlich. Dass Betrieb eben auch bedeutet, sich um Backups zu kümmern, haben in den ersten Jahren des Hype rund um die Cloud viele Unternehmen auf die harte Tour gelernt. Stellt sich also die Frage, wie sich Backups jener Komponenten, die in der Cloud laufen, möglichst effizient anfertigen lassen.
Auch aus Sicht des Plattform-Providers ist das Thema Backup herausfordernd. Denn der Cloudanbieter rüstet sich beim Thema Backup eigentlich nicht für den Ausfall einzelner Komponenten. Viel eher geht es hier einerseits um Schutz gegen das berüchtigte Fatfingering, also das versehentliche Löschen von Daten. Und andererseits geht es um klassisches Desaster Recovery: Wie lässt sich ein neues Rechenzentrum möglichst schnell wiederherstellen, wenn ein Komet in das alte Rechenzentrum einschlug?
Am Anfang soll die Sicht der Anbieter stehen: Wie stellen Plattform-Provider sicher, dass sie Backups effizient und gut anlegen, sodass ein Restore schnell möglich ist?
Die Antwort auf diese Frage ist eine Gegenfrage: Was muss denn überhaupt in ein Backup, damit der Anbieter ein Restore in möglichst kurzer Zeit hinbekommt? Wo früher jede einzelne Datei in irgendwelchen Backups landete, ist es heute sinnvoll, sorgfältig zu differenzieren. Denn Automation ist gerade bei Cloudsetups meist elementarer Bestandteil des Konzepts und sorgt beim Thema Backup für neue Aspekte.
Automation ist wichtig
Wer ein Cloudsetup plant und aufbaut, kann es sich nicht leisten, auf Automation zu verzichten. Konventionelle Setups kleinerer Art mögen sich zu Fuß noch verwalten lassen. Bei riesigen Cloudsetups, die aus Servern und aus Infrastruktur bestehen, ist dieser Ansatz aber offenbar unnütz. Denn selbst wenn ein Setup sehr klein startet, ist Automation spätestens dann nötig, wenn es ans Skalieren in die Breite geht – genau dafür werden Clouds ja in den meisten Fällen gebaut. Kurz: Wer eine Cloud baut, automatisiert am besten von Anfang an.
Ein hoher Automationsgrad bedeutet aber auch, dass sich einzelne Komponenten des Setups in den meisten Fällen “aus der Dose” wiederherstellen lassen. Stirbt ein Rechner den Hardware-Tod oder gibt eine Festplatte ihren Geist auf, lässt sich nach dem Tausch der defekten Komponenten das dortige Betriebssystem problemlos aus der vorhandenen Automation wiederherstellen. Das Backup einzelner Systeme ist ja in derartigen Setups gar nicht nötig.
Boot-Infrastruktur funktionstüchtig halten
Damit der Prozess wie beschrieben funktioniert, müssen mehrere Aspekte des Betriebskonzepts passen. Zunächst soll die Boot-Infrastruktur vorhanden sein, die Dienste wie FTP, NTP, DHCP oder TFTP bietet (Abbildung 1). Denn nur wenn jene Dienste ihren Job verrichten, ist die Installation neuer Systeme überhaupt möglich. In einem RZ sollte die Boot-Infrastruktur – in der Regel genügt ein Server völlig – idealerweise redundant ausgelegt sein, notfalls mit klassischen Werkzeugen wie Pacemaker.
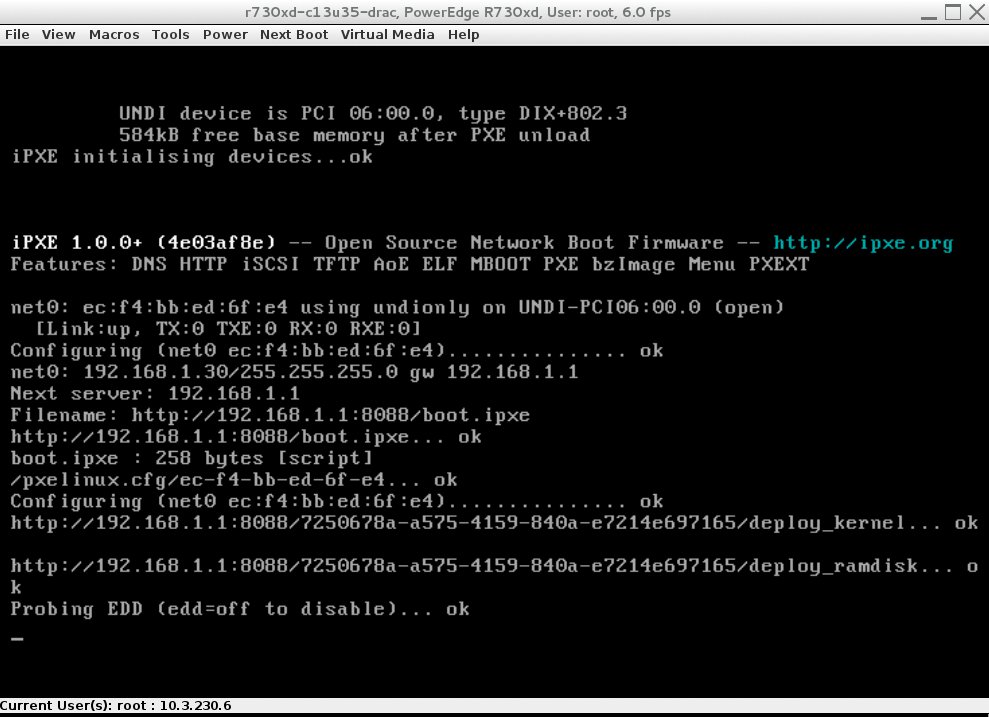
Abbildung 1: Wenn der Admin im Underlay Basis-Dienste wie PXE, DHCP und TFTP richtig baut, ist der tatsächliche Backup-Bedarf minimal.
Möchte ein Anbieter Geo-Redundanz erreichen, schadet es auch nicht, in einem zweiten RZ zumindest die Boot-Infrastruktur eines Setups als Hot-Standby zu betreiben, denn im Falle eines Falles ist die funktionierende Boot-Infrastruktur die Keimzelle eines neuen Setups.
Daraus ergibt sich auch, dass die Boot-Infrastruktur einer der wenigen Teile des Underlay ist, von denen regelmäßige Backups – und zwar an einem anderen Ort – anzulegen sind. Nota bene: Auch die Boot-Infrastruktur sollte so weit wie möglich automatisiert sein; NTP, TFTP, DHCP & Co. lassen sich problemlos per Ansible auf »localhost« ausrollen.
Die hierfür benötigten Rollen, so sie denn lokal geschrieben und nicht irgendwo aus dem Netz organisiert sind, sind Pflichtbestandteil des Underlay-Backups. Selbst jene, die bei den Rollen auf fertige Teile aus dem Netz zurückgreifen, sollten unbedingt die Ansible-Playbooks und die spezifischen Konfigurationsdateien der einzelnen Dienste sichern, denn die sind spezifisch für die jeweilige Installation. Dass sich für all diese Tasks ein Git-Verzeichnis eignet, das idealerweise an einen weiteren Ort synchronisiert wird, der außerhalb des Setups liegt, versteht sich von selbst.
Gelingt es im Falle eines Desasters, die Boot-Infrastruktur möglichst flott wieder auf die Beine zu stellen, lassen sich aus dieser in kürzester Zeit eine funktionale Plattform bootstrappen und der Betrieb wiederherstellen.
Das leidige Thema: Persistente Daten
Ein an einem anderen Ort derart hochgezogenes Setup wäre allerdings nackt, ihm fehlten die Daten. Hier ist es – wie oft im Cloudkontext – nötig, zwischen zwei Arten von Daten zu unterscheiden. Einerseits gibt es im Cloudsetup stets die Metadaten der Cloud selbst. Darunter fallen sämtliche Informationen über Nutzer, virtuelle Netzwerke, VMs und vergleichbare Details. Die andere Datenart, mit der Admins es in der Cloud in der Regel zu tun bekommen, sind Payload-Daten, also Daten, die Kunden in ihrem virtuellen Bereich der Cloud ablegen und speichern. Hier bieten sich viele Arten von Backup-Strategien an, nicht alle davon sind allerdings sinnvoll.
Leicht zu beantworten ist die Frage nach den Backups der Metadaten: Hier empfiehlt es sich, entsprechende Backups anzulegen. Die meisten Cloudlösungen setzen im Hintergrund ohnehin auf Datenbanken, in denen sie die eigenen Metadaten ablegen. Und das Sichern von MySQL, das etwa bei Open Stack ab Werk als Standardwerkzeug zum Einsatz kommt, ist ein gelöstes Problem.
Wer also die MySQL-Datenbanken der einzelnen Dienste regelmäßig ins Backup übernimmt, muss sich bei Open Stack nur noch um Spezialfälle separat kümmern: Manchmal verwenden etwa SDN-Lösungen eigene Datenbanken. Auch ein gelegentlich vergessenes Thema sind Betriebssystemabbilder in Open Stack Glance. Falls diese nicht auf einem zentralen Storage liegen oder jederzeit aus dem Internet erneut zu beschaffen wären, sollten hier ebenfalls Backups angelegt werden.
Wer Ceilometer nutzt, darf auch dessen Datenbank beim Sichern nicht vergessen, weil sonst die historischen Records für die Verrechnung der in Anspruch genommenen Ressourcen weg sind – und das ist im denkbar ungünstigsten Falle nicht nur ein technisches, sondern auch und vor allem ein rechtliches Problem.
Besondere Beachtung verdienen außerdem die Clouddienste, die selbst Backups für Kunden anlegen können. Gerade bei IaaS-Diensten findet sich diese Option häufig: Wer DBaaS in Open Stack mit Trove realisiert, kann von seinen Datenbanken in regelmäßigen Abständen automatisch Backups anlegen lassen (Abbildung 2). Hier bietet sich dem Anbieter die Wahl: Entweder kommuniziert er den Kunden klar und deutlich, dass diese für das dauerhafte Speichern der Backups selbst verantwortlich sind, oder er inkludiert die Backups jener Dienste in seine eigenen Backups.
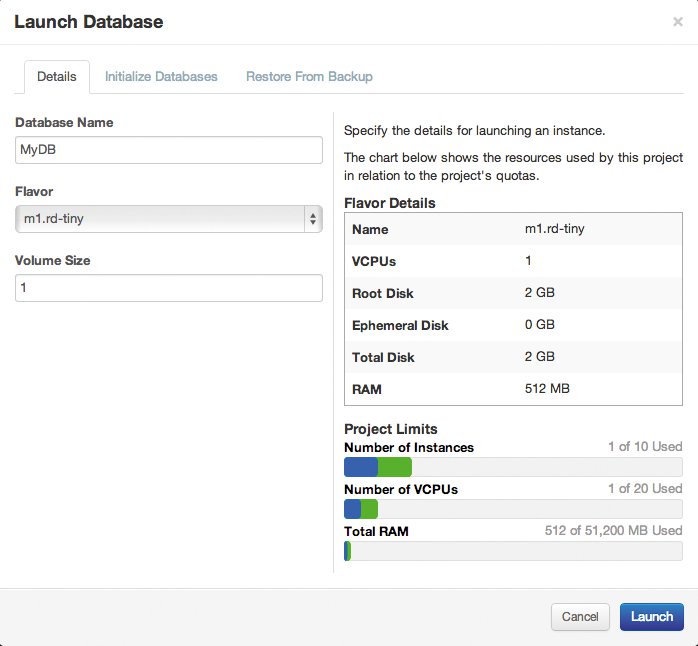
Abbildung 2: DBaaS – hier am Beispiel von Open Stack – bietet Backup- und Restore-Funktionen, auf die Anwender unbedingt setzen sollten.
Der zentrale Speicher
Im Hinblick auf Payload-Daten sieht die Sache allerdings ganz anders aus. Für sie setzen viele Unternehmen auf zentrale Storages, beispielsweise auf Ceph. Das ermöglicht es zwar, riesige skalierbare Speicher schnell und leicht zu bauen, schafft im Hinblick auf Backups aber eben auch einen Moloch. Wer aus der alten Welt konventioneller Setups kommt, fragt sich angesichts riesiger Ceph-Setups mit mehreren Petabyte nicht selten, wie man einen solchen Speicher sinnvoll in ein Backup verpackt.
Die Antwort ist denkbar simpel: Indem der Admin einen zweiten, gleich großen Speicher daneben stellt und regelmäßig spiegelt. Oder indem er Payload gar nicht oder nur selektiv und gegen Aufpreis mit Backups schützt. Logisch: Wer eine 5 Petabyte große Instanz von Ceph hat, braucht eigentlich auch einen 5-Petabyte-Cluster für ein Backup. Mit Erasure Coding lässt sich dabei im Zweifelsfalle auch noch tricksen, denn von den 5 Petabyte Brutto-Kapazität stehen effektiv ja nur gut 1,6 Petabyte zur Verfügung, wenn der Admin doppelte Redundanz in Ceph aktiviert hat.
Im Backup ist die Redundanz theoretisch gar nicht nötig; man könnte den Wert also auf 2 heruntersetzen und Erasure Coding aktivieren, das Raid 5 ähnlich ist. Am Ende wäre ein zweiter Speicher erforderlich, der zwar keine 5 Petabyte Größe hat, aber in Sachen Daten trotzdem einiges wegzustecken vermag.
Sind Backups Sache des Anbieters?
Aus Sicht des Anbieters viel eleganter ist der Ansatz, den große Unternehmen wie Amazon oder Azure fahren: Sie betrachten Backups als reines Kundenthema, und wie üblich gilt die Warnung, dass Kunden sich in der Cloud auf nichts verlassen sollten. Wer also Dienstleistung in AWS bucht, der weiß, dass er für die Backups seiner Daten selbst verantwortlich ist. Im Zweifelsfalle sind sie sonst einfach weg und Amazon übernimmt sogar dann keine Verantwortung, wenn es selbst durch einen Fehler zur Datenlöschung beigetragen hat.
Ob sich dieser Ansatz durchhalten lässt, hängt von verschiedenen Faktoren ab. Amazon ist freilich groß genug, um den Verlust selbst größerer Kunden problemlos verschmerzen zu können – auch wenn das natürlich nicht gewünscht ist. Die Struktur der eigenen Klientel spielt hierbei jedoch eine große Rolle.
Wer als Anbieter den eigenen Cloudkunden das Thema Backup überlassen möchte, sollte das klar und deutlich kommunizieren, und zwar bei jeder sich bietenden Gelegenheit. Ein tief in den AGB der eigenen Plattform vergrabener Absatz hilft nicht – denn für viele Kunden ist das Anlegen von Backups durch den Anbieter so normal, dass sie gar nicht auf die Idee kämen, das könnte ausbleiben. Der Schritt, Verantwortung für die eigenen Backups zu übernehmen, ist hier quasi Teil der Migration in die Cloud.
Backups aus Sicht der Kunden
Anders gestaltet sich die Situation aus Sicht der Kunden – auch wenn die fundamentalen Fragen sich hier gar nicht so sehr von denen unterscheiden, mit denen es auch die Admins der Plattform selbst zu tun haben. Klar ist: Nicht nur im Underlay einer Cloud sollte der Grad der Automation möglichst hoch sein, sondern auch in jenem Teil, in dem Kunden sich ihre eigene virtuelle Welt einrichten. Hier ist der Bedarf sogar noch höher, denn zur klassischen Automation gesellt sich noch die Orchestrierung.
Zur Erinnerung: Orchestrierung setzt unterhalb der Automation an. Sie macht sich die Tatsache zunutze, dass sich virtuelle Hardware in einer Cloud per API steuern lässt, nämlich über das API der Cloudumgebung. Es ist nicht schwer, sich vorzustellen, dass das händische Zusammenklicken einer vollen virtuellen Umgebung etwa in AWS oder Open Stack einige Zeit in Anspruch nimmt.
Schließlich fängt der Admin bei Adam und Eva an: Zunächst erstellt er sich ein virtuelles Netzwerk, das verbindet er per Router mit dem Provider-Netz für Internetzugriff. Dann folgen die einzelnen VMs der Plattform, die nach dem erfolgreichen Bootvorgang auch eingerichtet und konfiguriert sein wollen.
Stellt man sich eine virtuelle Umgebung mit Hunderten VMs vor, würde dieser Vorgang ewig viel Zeit in Anspruch nehmen. Orchestrierung löst das Problem: Hier definiert der Admin den gewünschten Zustand seiner virtuellen Umgebung mit Hilfe einer Template-Sprache. Führt er das Template aus, legt die Cloud alle in ihm beschriebenen Ressourcen in der richtigen Reihenfolge an.
Es gibt noch mehr Automatisierungsmöglichkeiten aus Nutzersicht: Per vorbereitetem Spezial-Image etwa lässt sich gleich das OS-Abbild verteilen, das dann ein Load Balancer braucht – falls der Admin nicht von vornherein auf LBaaS setzt und sich spezifische Dienste wie Load Balancer, Datenbanken und andere Server durch die Cloudplattform selbst bereitstellen lässt (Abbildung 3).
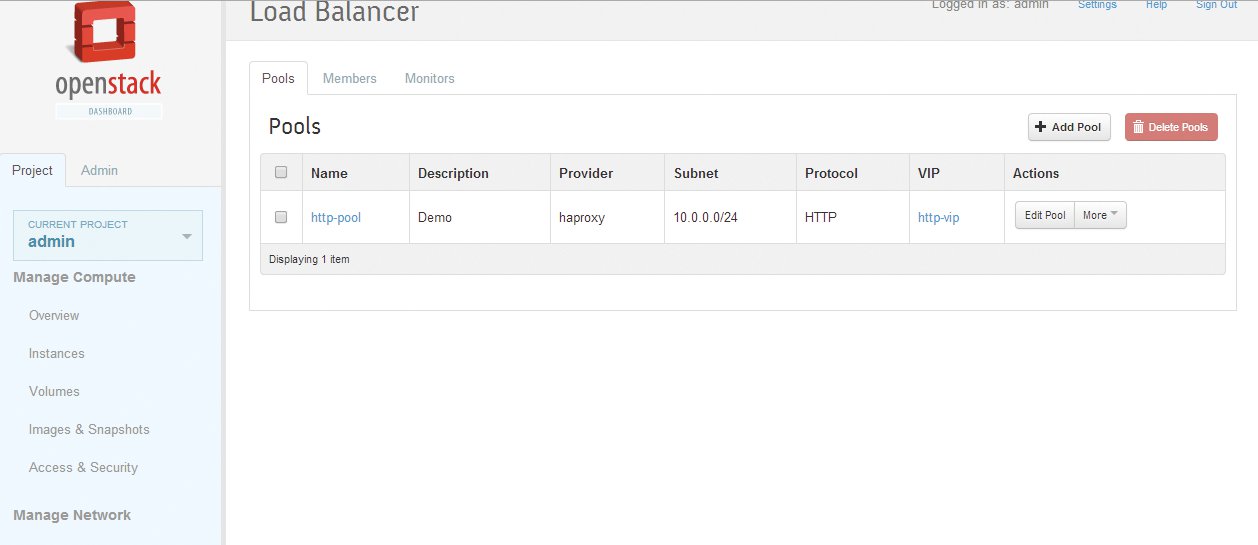
Abbildung 3: LBaaS macht den Load Balancer zu einer von der Cloud verwalteten echten Ressource und erleichtert und beschleunigt damit auch den Restore-Prozess ganz erheblich.
Grundsätzlich gilt: Je höher jener Anteil einer virtuellen Umgebung ist, der sich aus Templates ohne Probleme reproduzieren lässt, desto leichter ist das Thema Backup erledigt.
Weil ja keiner Backups will, aber alle Restore, soll auch dieser Aspekt nicht zu kurz kommen: Für den, der die inhärenten Features der jeweiligen Plattform nutzt, gestaltet sich in aller Regel auch der Restore-Prozess viel bequemer als bei Lösungen der Marke Eigenbau. Denn für Restore genügt es meist, über den jeweiligen Dienst eine neue Instanz zu starten und dabei ein vorhandenes Backup anzugeben – fertig ist der Lack.
Wer konsequent den LBaaS der Cloudplattform nutzt, freut sich darüber, dass neue Instanzen ihren Weg in den Load Balancer nach ihrem Start automatisch finden – das macht um so mehr Spaß, je weniger bei den einzelnen Instanzen spezifisch wiederherzustellen ist.
Persistente Daten identifizieren
Das A und O ist freilich, jene Daten zu identifizieren, die überhaupt zum Teil eines Backups werden müssen. Wer sein Setup vorbildlich und Cloud-ready baut, ist damit schnell fertig. Im besten Falle bestehen jene Daten tatsächlich nur aus dem Inhalt der Datenbank, die als Silo für die eigene Applikation im Hintergrund agiert. Das ist zwar eine Art Idealwelt, aber es lohnt sich durchaus, über dieses Konzept kurz nachzudenken.
Wer etwa in AWS oder Open-Stack-Clouds unterwegs ist, hat dort die Möglichkeit, eigene Images zu verwenden. Die baut der Admin idealerweise aus einem CI/CD-System wie Jenkins, das von der virtuellen Umgebung unabhängig ist und aus dem sich die Images schnell wiederherstellen lassen, falls mal etwas schiefgelaufen ist. Alternativ sind auch die Standard-Abbilder der Distributoren nutzbar, dann empfiehlt es sich allerdings, einen zentralen Automationshost zu haben, von dem aus sich neue VMs schnell betanken lassen.
Alle benötigten Dienste konsumiert ein Setup dieser Art so weit wie möglich aus der Cloud. Eigene VMs für Datenbanken & Co. sind Themen der Vergangenheit; der Anwender achtet lediglich darauf, dass er die Backup-Funktion von DBaaS nutzt und die Backups regelmäßig an einen sicheren Ort kopiert. Es empfiehlt sich, von einem externen System aus die CLI-Werkzeuge für die jeweilige Cloud zu verwenden und etwa Systemd-Timer zu nutzen, um den Download durchzuführen. Die eigentliche Applikation kommt bestenfalls in Form von Containern daher oder lässt sich aus einem Git auschecken und schnell in Betrieb nehmen.
Baut man ein Setup auf diese Weise Cloud-ready, sind die Backup-Anforderungen in dramatischer Art und Weise geringer als in konventionellen Setups, weil die Menge der Setup-spezifischen Daten viel kleiner ist.
Die Realität ist komplexer
Das beschriebene Szenario ist freilich das Idealbild für Applikationen in der Cloud – und praktisch nur für Leute erreichbar, die einer Cloud eine virtuelle Umgebung auf den Leib schneidern. Wer konventionelle Setups in die Cloud umzieht und dabei an den althergebrachten Standards nicht rüttelt, muss sich in logischer Konsequenz auch mit konventionellen Backup-Strategien befassen.
Ein paar Tricks und Tipps gibt es für solche Szenarien aber dennoch. Auch wenn die eigene Applikation nicht Cloud-ready ist, empfiehlt es sich, Nutzdaten und generische Daten strikt voneinander zu trennen. Wer eine Datenbank von einem physischen System in eine VM umzieht, sollte etwa darauf achten, dass der Ordner mit den Datenbankdaten auf einem separaten Volume liegt. Denn dann genügt es, lediglich die Daten des Volume ins Backup aufzunehmen statt der ganzen VM. Geht mal etwas schief, lässt sich der Volume-Inhalt – etwa auch aus einem Snapshot heraus – schnell wiederherstellen; es ist nicht nötig, die Daten mühsam von Hand wiederherzustellen.
Besonderes Augenmerk sollte der Admin in solchen Setups allerdings auf die Backup-Lösung legen, die er nutzt. Wenn er irgendeine Art von S3-kompatiblem Speicher zur Verfügung hat, bietet es sich an, eine Backup-Software mit jener Funktionalität einzusetzen (Abbildung 4). Denn dann lassen sich unmittelbar aus der Backup-Applikation heraus lokale Backups anlegen, was den Restore im Falle eines Problems schnell und unkompliziert ermöglicht.

Abbildung 4: Amazon S3 lässt sich für Backups auch direkt von der Kommandozeile aus nutzen, was die Automation solcher Lösungen sehr leicht macht.
Zugleich lässt sich aus derselben Software heraus auch ein (sogar verschlüsseltes) Backup an einem anderen Ort anlegen, etwa auf Amazons “echtem” S3-Speicherdienst – dieses Backup bietet selbst in jenen Fällen Sicherheit, in denen das ursprüngliche Rechenzentrum abbrennt. Amazon selbst bietet eine Anleitung für diese Art von Setup an [1].
Container: Kein Sonderfall
Die meisten Beispiele, die der Artikel bisher genutzt hat, beziehen sich auf klassische Vollvirtualisierung. Das bedeutet aber nicht, dass die beschriebenen Regeln und Grundsätze auf Container nicht ebenso anwendbar wären. Eigentlich gelten sie hier noch viel stärker – denn Cloudmigrationen, die konventionelle Applikationen in Container verfrachten, kommen nach der Erfahrung des Autors nicht so häufig vor. Hier ist der Normalfall eher, dass die Anwendung im Rahmen der Migration in die Cloud einem Redesign unterworfen und von Grund auf neu entwickelt wird.
Entsprechend gilt für Backups von Containern, dass es stets eine gute Idee ist, nur die tatsächlichen Nutzdaten – etwa den Inhalt einer Datenbank – in die eigenen Backups zu packen (Abbildung 5). Was sich aus Standardverzeichnissen im Falle eines Falles wiederherstellen lässt, hat im Container-Backup nichts zu suchen und verkompliziert im Zweifelsfalle die Wiederherstellung der Daten eher, als es sie erleichtert.
Abbildung 5: Was für virtuelle Maschinen in Cloudumgebungen gilt, das gilt für Container in Kubernetes umso mehr – mehr Automation, mehr Orchestrierung, weniger Backups.
Fazit
Wer sich mit dem Thema Backup bei Clouds beschäftigt, erkennt schnell, dass die Sache hier anders gelagert ist als bei konventionellen Setups. Aus Anbietersicht spielt Automation eine große Rolle: Lässt sich Automation in Form der Boot-Infrastruktur schnell wiederherstellen, geht das Bootstrapping der neuen Plattform ebenfalls schnell von der Hand – und ins Backup gehören nur noch spezifische Konfigurationsdateien der einzelnen Clouddienste sowie deren Metadaten. Alles andere ist generisch und lässt sich per Automation zu jedem Zeitpunkt beliebig oft reproduzieren.
Für Kunden hingegen wird es in der Cloud ungemütlicher. Wo früher noch das Mantra galt, dass der Anbieter sich zuverlässig um Backups kümmert, ist jetzt Do-it-yourself angesagt – es sei denn, man trifft mit dem Anbieter eine nur für diesen Zweck gemachte Sondervereinbarung. Gerade die großen Anbieter der Public Clouds bieten hierfür aber meist gar keine Produkte an, sodass der Kunde am Ende doch wieder auf die Eigeninitiative angewiesen ist.
Für weite Teile eines Setups gilt aber das, was im Underlay ebenso gilt: Automation, Orchestrierung und CI/CD sind der Schlüssel zum Erfolg. Von einer virtuellen Umgebung sollten am Ende nur die wirklich persistenten Daten im Backup landen, beispielsweise Kundendaten aus einer Datenbank.
Alle virtuellen Instanzen des Setups, die Infrastruktur und die in der Umgebung benötigte Software müssen hingegen jederzeit aus der Dose reproduzierbar sein. Wer diese Ratschläge beherzigt, hat meist sehr kleine Backups und trotzdem umfassende Freude in der Cloud.
Klar ist jedenfalls: Backups nach dem Staubsaugerprinzip haben in der Cloud nichts zu suchen. Es ist schlicht sinnlos, ganze VMs oder komplette Container in Backups zu verpacken – denn einerseits frisst das viel unnötigen Speicherplatz, weil man ständig dieselben Daten sichert. Und andererseits lassen sich Backups dieser Art auch nicht schneller wiederherstellen als Backups, die mit Tools der Cloud gemacht und auch mit diesen restored werden.
Wer die Werkzeuge der Cloud hingegen konsequent nutzt, macht sich das Leben auch in anderen Lagen einfacher: Datenbank-Updates sind viel leichter, wenn Datenbank und Datensatz voneinander getrennt sind. So lässt sich einfach eine neue DB-Instanz mit aktualisierter Software aus dem Boden stampfen, an die der Admin nur noch den alten Datensatz anhängt – fertig.
Infos
-
Amazon-Anleitung für Backups mit S3-Client: https://aws.amazon.com/de/getting-started/tutorials/backup-to-s3-cli/





