
© Elena Nichizhenova, 123RF
Soll ein Git-Verzeichnis verschiedene Komponenten enthalten und auch vielen Entwicklern dienen, hilft es, Regeln dafür aufzustellen. Das Linux-Magazin zeigt, welche für Ordnung im Repository sorgen.
In gewisser Weise ist John Bercow zum Symbolbild für die Wirren rund um den Brexit geworden: Als Speaker des House of Common fällt ihm die bisweilen eher undankbare Rolle zu, für Ordnung zu sorgen. Gerade während der sehr heftigen Brexit-Debatten ist das erwartungsgemäß ein schwieriges Unterfangen.
Und so darf sich mancher Administrator an John Bercow erinnern, wenn er einen Blick in die firmeninterne Gitlab-Installation wirft oder den Account seiner Firma auf Github besucht – und dort vor allem Chaos vorfindet.
In der Tat neigen Git-Verzeichnisse dazu, schnell zu vermüllen, wenn verbindliche Regeln im Hintergrund dem keinen Riegel vorschieben (Abbildung 1). Aber wie können die Regeln aussehen? Welche Maßnahmen sind sinnvoll? Dieser Artikel verrät, welche Ansätze sich in der Praxis des Autors bisher als Erfolge erwiesen haben. Neben der Frage der richtigen Struktur eines Git-Verzeichnisses geht es auch um Commit-Regeln, um Style Guides und sinnvolle Optionen, das Vier-Augen-Prinzip zu implementieren.
Abbildung 1: In Git-Verzeichnissen müssen – wie hier bei Nagios – bestimmte Regeln gelten.
Ganz am Anfang steht allerdings die Frage: Was liegt denn eigentlich im Git? Denn davon hängt schon ein Teil der Antwort auf die Frage ab, wie man ein Git-Verzeichnis am besten verwaltet.
Was liegt im Git?
Im Hinblick auf das Layout von Dateien gibt es in manchen Fällen gar keine echte Wahl. Wer etwa ein Python-Modul pflegt und das mit Py Setup bauen möchte, muss im Verzeichnis seines Quelltextes einer bestimmten Syntax folgen – das gilt für die meisten Progammier- und Skriptsprachen oder für die mit ihnen zusammenhängenden Buildsysteme.
Heutzutage liegen aber eben nicht mehr nur die Quelltexte von Programmen und Skripten in Git-Repositories, sondern zum Beispiel auch Konfigurationsdateien von Programmen. Und ganz egal, welcher Automatisierer zum Einsatz kommt – Puppet, Chef, Ansible, Salt oder noch eine andere Lösung: Sie alle haben Konfigurationsdateien und auch Programm-ähnlichen Quelltext (wie etwa die Module bei Ansible) und die müssen ebenfalls ins Git. Denn Devops-Prinzipien sehen vor, dass solche Dateien zentral verwaltet werden.
Ganz am Anfang der Überlegungen hinsichtlich guter Governance für den Inhalt des Firmen-Git steht deshalb eine Bestandsaufnahme: Welche Komponenten sollen im Git landen, bei welchen gibt es Vorgaben hinsichtlich des Layouts des Verzeichnisses und welcher Handlungsspielraum besteht? Daran schließt sich in aller Regel die zweite Frage an: ein Repository oder viele?
Heftige Reaktionen
Nach der Erfahrung des Autors entzündet sich an einer Frage immer wieder großer Streit: Was funktioniert besser – ein Repository für alles oder viele kleine Repositories? Augenscheinlich haben beide Ansätze ja Vor- und Nachteile. Als wichtiges Argument für einzelne Repositories gilt, dass sich unterschiedliche Entwickler so nicht ins Gehege kommen und in Ruhe an ihren Modulen arbeiten können. Es sei ja, so die Idee, möglich, zu jedem Zeitpunkt alle Repositories auf dem zentralen Host auszuchecken und sie so zu nutzen. Und in der Tat klingt das in der Theorie wie ein guter Ansatz. Die meisten Unternehmen folgen eben diesem Prinzip.
Ein Suchmaschinen-Anbieter aus Kalifornien folgt hingegen strikt dem Prinzip des monolithischen Repository (Monorepo), hat also nur ein Repository für alle entwickelten Komponenten – eine gewisse Firma namens Google. Sie hält der Theorie der vielen kleinen Repositories entgegen, dass sie sich im Kontext des Devops-Prinzips in mehrerlei Hinsicht negativ auswirken.
Einerseits fördern viele kleine Repositories beinahe zwangsläufig die Bildung von Silos. Entwickler interessieren sich dann gar nicht mehr für das, was in anderen Repositories passiert, und achten nur noch auf den Inhalt ihrer Verzeichnisse. Damit einher geht, dass sich zentrale Syntax-Vorgaben so nur schwer umsetzen lassen: Selbst wenn alle Mitarbeiter sie in Textform erhalten, so ist es doch wahrscheinlich, dass sich zwischen den einzelnen Repositories über die Zeit Unterschiede ergeben.
Das hat dann weder etwas mit bösem Willen noch mit Absicht zu tun, sondern ist der Tatsache geschuldet, dass Entwickler unterschiedliche Hintergründe haben und zum Teil auch an andere Best Practices gewöhnt sind. Schreiben aber immer nur dieselben paar Leute Commits für ein Repository, hält der Schlendrian früher oder später zwangsläufig Einzug, und man hat es mit einer größeren Menge von Git-Repositories zu tun, deren Syntax- und Style-Konventionen sich subtil voneinander unterscheiden.
Chaos beim Mergen
Das viel größere Problem dieses Ansatzes ist aber, dass es, zweitens, fast immer zu Problemen kommt, wenn die Inhalte der verschiedenen Repositories an einer Stelle zentral und kollektiv benötigt werden. Ein gutes Beispiel sind die typischen Automatisierer: Puppet, Ansible & Co. kommen quasi nie mit nur einem einzelnen Modul aus, sondern brauchen meist viele Module oder Rollen in einer spezifischen Kombination.
Wenn der Admin dann aber nicht davon ausgehen darf, dass er die Master-Branches der verschiedenen Git-Repositories gefahrlos miteinander kombinieren kann, sondern dass er von einzelnen Repositories auch noch spezifische Versionen braucht, ist das Chaos perfekt. Selbst wenn Admins solch ein Chaos irgendwie erfolgreich verwalten, schafft es doch ein ganz offensichtliches Einfallstor für Probleme – und zwar notlos.
Googles Monorepo-Ansatz schafft hier Abhilfe. Der Grundsatz lautet, dass jeder zur Firma gehörende Quelltext innerhalb eines Verzeichnisses desselben Repositories liegt und dass auch der Rollout stets aus eben diesem zentralen Repository heraus erfolgt.
Was freilich auch bedeutet: Überall dort, wo das Repository ausgecheckt ist, sind dieselben Dateien vorhanden, und zwar in denselben Versionen. Ein völliges Chaos beim Zusammenfügen der Inhalte wird auf diese Weise zumindest zur Hälfte vermieden.
Der Master ist Trumpf
Die andere Hälfte besteht darin, par ordre de Mufti festzulegen, dass bei der Produktion stets der Master-Branch jenes Monorepo ausgerollt zu sein hat. Oder anders formuliert: Master enthält zu jedem Zeitpunkt die neueste, lauffähige Version des ganzen Repository. Checkt ein Nutzer den Master-Branch des Repository aus, so kann er sich – zumindest in der Theorie – darauf verlassen, dass er funktionale Software erhält.
Entwicklung findet entsprechend in Branches statt: Startet ein Entwickler die Entwicklung einer neuen Funktion, tut er das in einem lokalen, separaten Branch. Den darf er zwar durchaus in das zentrale Repository pushen, doch das bedeutet nicht automatisch, dass andere in ihn ebenfalls Commits einspielen dürfen.
Vier Augen beim Mergen
Apropos Commits. Auch für die Arbeit der Entwickler mit ihren Branches hat Google engmaschige und verbindliche Regeln eingeführt: So soll das Feature, das ein einzelner Branch implementiert, stets so eng gefasst sein wie möglich. Das ist freilich ein Verweis auf die Idee des “Minimum Viable Product” sowie des “Slicing the Elephant”-Ansatzes, die beide im Agile- und Devops-Kontext eine wichtige Rolle spielen. Der Ansatz bringt mehrere Vorteile:
1. Wenn die durchgeführten Änderungen überschaubar sind, lassen sie sich auch einigermaßen leicht wieder zurückrollen, falls beim Deployment etwas schiefgeht.
2. Ein kleines Changeset ist durch einen Reviewer viel leichter und schneller zu durchblicken als riesige Veränderungen.
3. Es vergeht viel weniger Zeit zwischen der ersten Idee einer Funktion bis zum ersten vermarktbaren Produkt.
Insbesondere Punkt 2 spielt hier eine wichtige Rolle, weil die Review durch einen anderen Entwickler die Hürde ist, die eine Veränderung auf dem Weg aus einem Branch in den Master-Zweig des Repository überwinden muss. Hält ein Entwickler seine Arbeit an einem Feature also für beendet, erzeugt er einen entsprechenden Merge-Request und weist diesen einem berechtigten Kollegen zu.
Protected Branches helfen teilweise
Wer dem Braten nicht traut, kann zumindest in Gitlab auch die Permission-Keule auspacken und das Problem auf diesem Wege lösen: Hier unterscheidet Git mittlerweile zwischen der »Allowed to merge«- und der »Allowed to push«-Berechtigung (Abbildung 2).
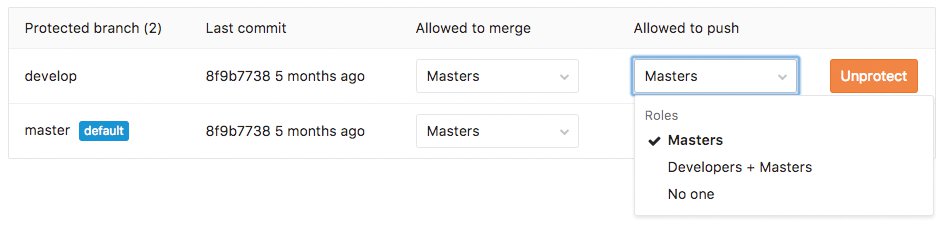
Abbildung 2: Gitlab kann mittlerweile zwischen »Allowed to merge« und »Allowed to push« unterscheiden.
In Kombination mit Protected Branches ist das eine sinnvolle Einrichtung. Ihr Ziel ist es, in einem Repository den Zugriff auf spezifische Branches einzuschränken, sodass andere Nutzer zwar in das Repository und andere Branches noch pushen können, aber eben nicht mehr in die geschützten Branches.
Weil »Allowed to merge« und »Allowed to push« nun zwei separate Berechtigungen sind, lässt sich festlegen, dass Nutzer zwar in Changes in einen Branch mergen dürfen, aber nicht direkt pushen. Wer den Master-Branch zum Protected Branch mit eben dieser Einstellung macht, erhält das gewünschte Resultat (Abbildung 3). Leider ist das Feature streng abhängig vom Anbieter der eigenen Git-Lösung: Gitlab beherrscht die Funktion mittlerweile, Github aber nicht – Git selbst implementiert schließlich gar keine echten Permissions, sondern überlässt diese Aufgabe den Drittanbieter-Lösungen.

Abbildung 3: Diese einfachen Settings in der Konfigurationsdatei ».gitconfig« sind ausreichend, um Ross und Reiter zu benennen.
Für Entwickler und Reviewer bedeutet das, dass Disziplin nötig ist – ein Entwickler sollte nie direkt zum Master pushen. Tut er es doch, sind ein Revert des Change und die anschließende normale Review-Prozedur die richtige Reaktion.
Mehr Code-Recycling
Wie beschrieben hilft ein Monorepo dabei, die Silobildung in Unternehmen zu verhindern. Es sorgt aber noch für einen weiteren, sehr praktischen Effekt: Es verringert die Menge an Code, die im Unternehmen doppelt und dreifach in sehr ähnlicher oder identischer Art und Weise entsteht. Das Problem kennt wohl jeder: Eine bestimmte Aufgabe in einem Programm oder einem Skript braucht eine Helfer-Funktion, die man mal eben zusätzlich zum eigenen Programm implementiert.
Wenn verschiedene Entwickler desselben Unternehmens auf dasselbe Ziel hinarbeiten, ist es allerdings sehr wahrscheinlich, dass sie ähnliche oder die gleichen Helferfunktionen brauchen. Wenn Quelltext in vielen Repositories lagert, die voneinander alle nichts wissen, kommt es zum beschriebenen Effekt.
Ein Monorepo verhindert die Entstehung des Problems: Hier bietet es sich an, im Stile einer Bibliothek und notfalls für diverse Skriptsprachen einen Fundus oft genutzter Funktionen zu schaffen. Das stellt einerseits sicher, dass alle mit denselben Helferfunktionen arbeiten, und beugt andererseits dem Wildwuchs und der Silobildung effektiv vor.
Das Monorepo und CI/CD
Mit der Idee eines firmenweiten Monorepo konfrontiert setzt bei manchem Admin spontan Schnappatmung ein. Auslöser ist oft die Frage, wie im Rahmen eines solchen Monorepo denn mit CI/CD-Frameworks umzugehen ist, die in vielen Unternehmen zum Einsatz kommen. Google ist groß genug, um das Problem effizient im Rahmen der – Google-eigenen – CI/CD-Umgebung zu lösen.
Der Hersteller arbeitet hier mit Triggern, die bei Commits in das Monorepo die betroffenen Teile identifizieren und eventuelle CI/CD-Prozesse nur für diese lostreten. Dass das bei einem Repository der Google-Dimension nicht nur sinnvoll, sondern lebenswichtig ist, leuchtet ein – es ist ja kaum vorstellbar, dass ein Commit etwa für Google Hangouts Tests für Google Earth auslöst.
Auch in kleineren Unternehmen hat ein Monorepo allerdings Nerv-Potenzial in Sachen CI/CD. Selbst wenn es nur um wenige Megabyte Quelltext geht, ist es leicht möglich, dass der Unterschied zwischen “Nur betroffene Teile laufen durch CI/CD” und “Alle Prozesse laufen durch” mehrere Minuten beträgt. Bei einer Vielzahl von Commits pro Tag kommt da einiges zusammen.
Die gute Nachricht: Den Entwicklern von CI/CD-Lösungen wie Jenkins ist der Trend hin zum Monorepo nicht verborgen geblieben. Und für die meisten Lösungen am Markt existiert ein Weg, nicht bei jedem Commit automatisch alle Vorgänge zu starten. In Jenkins kann etwa das Modul Jenkins Groovy aus einem Git-Commit die geänderten Dateien herausfinden und dann über das Nachladen von externen Skripten nur bestimmte Jobs anstoßen – in Abhängigkeit von den veränderten Dateien.
Diverse Einträge auf Stack Exchange [1] erläutern, wie eine Lösung für das Problem in Jenkins aussehen kann. Elton Minetto beschreibt in seinem Blog zudem einen Weg für die CI/CD-Lösung Drone.io, die zum gleichen Effekt führt [2]. Damit ist klar: Auf irgendeine Weise lässt sich Automation für jedes CI/CD-System erreichen, und Unternehmen sollte das nicht davon abhalten, den Monorepo-Ansatz ernsthaft in Betracht zu ziehen.
Den guten Sitten entsprechend
Wohl jeder Admin ist bei der Suche nach den Ursachen für ein Problem schon auf Git-Commit-Nachrichten gestoßen, die dem Muster “Fixed Bug” oder – fast noch schöner – “Fixed stuff” folgen. Solche Commit-Messages sind im Grunde eine Frechheit, denn sie stellen die Idee hinter Commit-Messages völlig auf den Kopf. Einerseits ist es dem Beobachter anhand von “Fixed Bug” noch nicht einmal möglich, Rückschlüsse auf den reparierten Bug zu ziehen, ohne sich den Quelltext anzuschauen. Und andererseits enthält die Commit-Message ja auch keine Informationen dazu, wie der Fix denn nun genau funktioniert.
Im blödesten Falle wühlt sich der Admin also durch den Quelltext-Teil des Commit und versucht aus diesem schlau zu werden. Das kostet ihn aber mit hoher Wahrscheinlichkeit mehr Zeit, als es den Autor des Change gekostet hätte, gleich eine ordentliche Commit-Message zu verfassen. Stoßen mehrere Leute auf die kryptische Commit-Nachricht, multipliziert sich dieser Effekt entsprechend.
Für Gitlab kursieren im Netz sogar Anleitungen, wie man durch Konfiguration des Dienstes eine spezifische Minimallänge von Commit-Nachrichten erzwingt. Wie erfolgreich das am Ende ist, darf als fraglich gelten, denn eigentlich sind mangelhafte Commit-Messages ja kein technisches Problem. Und wie so oft lässt sich dieses menschliche Problem durch Technik kaum lösen.
Der Admin tut aber gut daran, in seinem Regelwerk zu verankern, dass Commit-Nachrichten eine sinnvolle Aussage enthalten und möglichst präzise sein müssen. Die Leute, die nach dem Vier-Augen-Prinzip Commits überwachen, sollten idealerweise als Erste schreien, wenn eine Commit-Message nicht dem vorgegebenen Standard entspricht.
Gerade bei Gitlab macht sich zudem eine andere Unart breit: Oft finden sich in den Commit-Messages dort Commits, die augenscheinlich von Root kommen. Ist das der Fall, sind im Vorfeld mehrere Dinge schiefgelaufen. Einerseits hat der Entwickler sich nicht an die goldene Regel gehalten, dass Arbeiten auf dem System nie als Root durchzuführen sind. Und andererseits hat es der Entwickler auch versäumt, in der Git-Konfiguration vor seinem Commit einen Klarnamen samt E-Mail-Adresse zu setzen.
Wie das geht, verrät die Git-Dokumentation in einem der ersten Kapitel ausführlich [3]. Freilich sollten Entwickler darauf achten, dass sie die dort beschriebenen Befehle tatsächlich als die eigenen Nutzer ausführen und nicht wieder als Root – denn sonst ist der ganze Aufwand vergebens. Und auch hier gilt freilich wieder, dass Reviewer Commits von Root entsprechend zurückweisen sollten (Abbildung 2).
Hooks sorgen für Kommunikation
Oft besteht in Unternehmen das Problem, dass im Git zwar Arbeit stattfindet, diese ist aber nicht hinreichend im Unternehmen sichtbar. Repariert der Entwickler beispielsweise einen Bug, vergisst aber, im vom Git entkoppelten Ticketsystem eine entsprechende Notiz zu hinterlassen, hilft das nicht weiter. Im besten Falle landet das Problem wieder auf der Tagesordnung, wenn im Rahmen des in vielen Unternehmen üblichen Ticket-Aufräumens vorm Wochenende das entsprechende Ticket jemandem auffällt und dann eine entsprechende Nachfrage hinterlegt.
Das muss aber nicht sein. Fast alle gängigen Git-Implementierungen bieten die Möglichkeit der so genannten Hooks (oder auch Webhooks). Das Prinzip ist simpel: Findet eine Veränderung im Git-Verzeichnis statt, führt Git automatisch Arbeitsschritte durch, die mit diesem Repository verbunden sind. Ein Befehl im Nachgang eines Commit könnte etwa darin bestehen, eine entsprechende Nachricht über den Commit und die kurze Commit-Message in einem Chatsystem wie Hip Chat zu platzieren.
Auch das Updaten eines mit dem Repository assoziierten Tickets wäre eine praktische Möglichkeit. In den gängigen Lösungen Gitlab und Github gibt es Support für solche Hooks. Webhooks sind eine spezielle Ergänzung und bieten die Gelegenheit, beim Commit eine URL aufzurufen – meist per REST-Protokoll, um weitere Arbeitsschritte auszulösen (Abbildung 4).
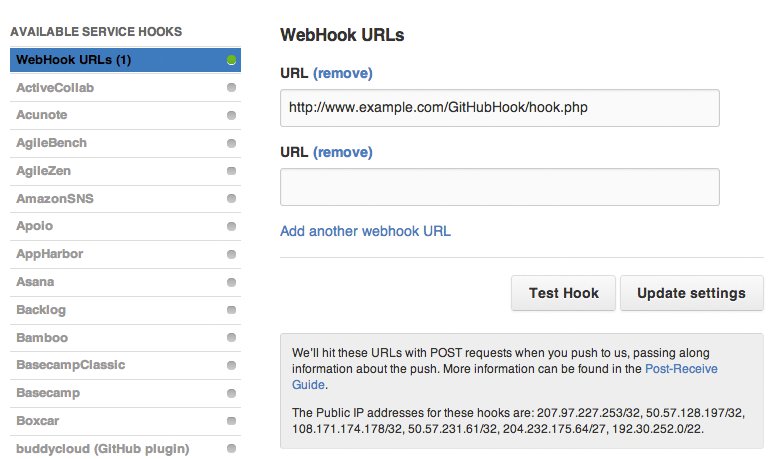
Abbildung 4: Webhooks bieten die Möglichkeit, beim Einchecken eines Commit eine URL aufzurufen.
Unternehmen tun gut daran, diese Hook-Systeme flächendeckend zu nutzen: So sorgen sie für regelmäßige Kommunikation und den gleichen Informationsstand bei allen Beteiligten. Aber Vorsicht: Mancher Admin hat sich selbst schon völlig ungewollt einer Denial-of-Service-Attacke ausgesetzt, indem er die Hooks so konfigurierte, dass für jeden Commit eine Mail in seiner Inbox landet. Wer das bei großen Monorepos tut, sieht sich flott einer Mailflut ausgesetzt.
Die Verzeichnisstruktur
Wer sich den Monorepo-Jüngern anschließt und sein Repository entsprechend aufbauen möchte, sieht sich schnell einem Problem gegenüber: Wie organisiert er die verschiedenen Ordner und Unterordner innerhalb des Repository gut und sinnvoll?
Hier hat es sich bewährt, auf der oberen Verzeichnisebene nach der grundsätzlichen Art des Inhalts zu unterscheiden. Automatisiert eine Firma mit Ansible, könnten etwa alle Ansible-Rollen und Playbooks im Ordner »ansible« auf der obersten Verzeichnisebene des Repository lagern. Wer Python oder Go-Inhalte baut, hinterlegt diese ebenfalls in entsprechend benannten Ordnern im Repository.
Wie die Verzeichnisstruktur innerhalb dieser Ordner dann im Detail aussieht, hängt streng vom Inhalt ab. Unter Umständen hat man Glück und der Hersteller selbst gibt vor, wie er sich das Ganze vorstellt – so wie Ansible es tut: Red Hat gibt auf der Website des Programms detailliert vor, wie eine ebenso gute wie sinnvolle Struktur in dem Ansible-Ordner aussehen kann.
Demnach gehören die Ansible-Rollen in den Unterordner Roles, die Playbooks sinnvollerweise direkt in den Ansible-Ordner (von wo aus sie auf Rollen verweisen) und andere Inhalte in eigene Unterordner wie Var für Variablen. Leider sind aber nicht alle Anbieter so gründlich darin, ihren Nutzern zu helfen.
Syntax-Vorgaben
Weniger auf die Struktur der Dateien im Repository und mehr auf die Art und Weise, wie Code im Repository entwickelt wird, bezieht sich der nächste Tipp. Unterschiedliche Entwickler bevorzugen unterschiedliche Syntax-Stile bei ihrer Arbeit. Und gerade bei Programmiersprachen sind Syntax-Vorgaben auch nicht so streng wie bei anderen Dateitypen. Eine Yaml-Datei etwa wird sogar syntaktisch inkorrekt und mithin ungültig, wenn man sich nicht penibel an das Yaml-Format hält (Abbildung 5).
Abbildung 5: In Yaml-Dateien gelten strikte Syntaxvorgaben, andere Dateien erfordern mehr Regulierungsbedarf.
Bei den meisten Programmier- und Skriptsprachen ist das jedoch anders. Hier haben Entwickler die Wahl zwischen Camel Case, Großschreibung, Kleinschreibung, einer riesigen Anzahl verschiedener Einrückungsmöglichkeiten und diverser anderer Möglichkeiten, auf das Format des Quelltextes im Repository Einfluss zu nehmen.
Das Problem, das mit dieser Freiheit einhergeht, liegt auf der Hand: Hat jeder Mitarbeiter des Unternehmens seine eigenen Vorstellungen von Syntax und Coding Style, entsteht in kürzester Zeit ein Wildwuchs. Gegen diese Art des Chaos gibt es allerdings ein Mittel: selbst definierte Standards.
Weil es selten sinnvoll ist, das Rad neu zu erfinden, schadet es nicht, sich auf die Style Guides großer Firmen zu verlassen: PEP 8 [4] und Googles Python Style Guide [5] liefern wertvolle Hinweise für Python. Für Shellskripte liefert ebenfalls Google einen guten Style-Guide [6]. Für Go machen die Go-Entwickler selbst viele Vorgaben und geben Tipps [7].
Noch eine Frage des Stils
Abschließend sei darauf hingewiesen, dass Syntaxvorgaben für die Dateien im Repository nicht ausreichen, um bestimmte Unsitten zu unterbinden. Wer etwa den Shell-Design-Vorgaben folgt, kann unter Umständen trotzdem Bashismen oder andere unerwünschte Konstrukte bauen. Wer einen eigenen Design-Guide verfasst, sollte sich deshalb nicht nur mit der Syntax in den Dateien beschäftigen, sondern auch beantworten, welche Konstrukte erlaubt sind.
Fazit
Monorepos bieten elementare Vorteile gegenüber einer Sammlung von diversen Kleinstrepositories, jede Firma sollte sie zumindest evaluieren. Wer dem Ansatz folgt und ein paar Regeln im Hinblick auf die Verzeichnisstruktur und andere Details trifft, stellt sicher, dass im Git-Repository Recht und Ordnung statt Kraut und Rüben herrschen.
Langfristig ist eine solche verbindliche Regelung für alle Beteiligten von Vorteil, auch weil etwa der Weggang einzelner Kolleginnen und Kollegen viel weniger Probleme verursacht.
Infos
-
CI/CD für Jenkins mit Monorepo: https://devops.stackexchange.com/questions/4355/triggering-specific-pipeline-builds-for-monorepos-in-jenkins
-
CI/CD für Drone.io mit Monorepo: https://hackernoon.com/continuous-integration-in-projects-using-monorepo-9b828d7a8dfa
-
Git-Basics konfigurieren: https://git-scm.com/book/en/v2/Getting-Started-First-Time-Git-Setup
-
Google Python Guide: https://github.com/google/styleguide/blob/gh-pages/pyguide.md
-
Google Shell Guide: https://google.github.io/styleguide/shell.xml
-
Go Guide: https://github.com/golang/go/wiki/CodeReviewComments
Der Autor

In seiner Freizeit ist er Debian-Entwickler und beruflich ist Martin Gerhard Loschwitz als Telekom Public Cloud Architect bei T-Systems beschäftigt. Dort widmet er sich vorrangig Themen wie Open Stack, Ceph und Kubernetes.






Die Idee eines Monorepo ist ja nicht schlecht, aber wie funktioniert das in der Praxis?
Man muss ja immer das gesamte Repository clonen. Habe eben mal gesucht, es gibt so was wie “Sparse Checkouts”, aber es wird dazugeschrieben, dass im Hintergrund dennoch das gesamte Repo geklont wird.
Also das kann vllt. eine Google machen, die wahrscheinlich zu jedem Arbeitsplatz 10 GBit/s-Anschlüsse gelegt haben und deren Arbeits-PCs mindestens Threadripper sind …. aber der gewöhnliche Entwickler mit seinem latent überforderten System wird doch durch so etwas nur ausgebremst.