
© dolgachov, 123RF
Dass künstliche Intelligenz (KI) tatsächlich das Allheilmittel für Probleme aller Art liefern wird, ist unbewiesen. Konkret und greifbar ist dagegen eine Anwendung im Monitoring, die dieser Artikel beschreibt.
Softwarelösungen und die zugrunde liegenden Server überwachen, das gehört genauso zu den Aufgaben eines IT-Dienstleisters wie das Monitoring der Performance etwa eines ERP-Systems. Unter dem Schlagwort User Experience messen die Admins die Leistungsfähigkeit des Systems dabei auch aus der Sicht der Endanwender. Denn oft weicht der Eindruck der Anwender von den Daten der Serverüberwachung ab.
Durch das Monitoring aus Sicht des Users lassen sich Probleme erkennen und beheben, bevor sie die Produktivität der Mitarbeiter beeinträchtigen.
APM vs. ITOA
Traditionell wurde Performance-Monitoring oft als klassisches Application Performance Monitoring (APM) implementiert. Heute machen es komplexe Cloud-basierte Netzwerke mit Tausenden von Endbenutzern unmöglich, alle Aktivitäten zu überwachen und die wenigen wichtigen Warnmeldungen zu filtern, die relevant für Ausfallzeiten oder Angriffe sind. Deshalb gibt es neben dem klassischen APM eine neue Technologie, die diese Probleme angeht: IT Operations Analytics (ITOA). APM und ITOA werden oft in die gleiche Schublade gesteckt, weil sie ähnliche Funktionen haben. Die zugrunde liegenden Prozesse und die Ergebnisse, die beide Verfahren erreichen, unterscheiden sich aber.
Zu APM gehören Werkzeuge und Prozesse, die die Leistung und Verfügbarkeit von Software-Anwendungen überwachen, um Performance-Verschlechterungen rechtzeitig zu erkennen und IT-Mitarbeiter darüber zu informieren. Das Hauptziel dabei ist die stetige Suche nach Abweichungen von der Norm.
Dabei kombinieren die Analysten die User Experience mit Leistungskennzahlen. Doch schnelle Maßnahmen, die sie auf dieser Grundlage einleiten können, reichen den meisten Unternehmen nicht mehr aus. Stattdessen möchten sie Vorfälle verhindern, das heißt künftiges Verhaltens vorhersagen. Genau das ist der Kern von ITOA: Zwischenfälle und Krisensituationen vermeiden, bevor sie Auswirkungen haben.
Im Zuge von ITOA sammelt Analysesoftware große Datenmengen und versucht in ihnen Muster zu erkennen. Dadurch wird offenbar, was in den Systemen vor sich geht und was in Zukunft wahrscheinlich passiert. Dadurch ergibt sich die Chance, Probleme zu lösen, bevor sie Auswirkungen haben. Bezogen auf ein Auto könnte das vielleicht bedeuten, dass der Bordcomputer davor warnt, dass ein Reifen in Kürze unzulässig wenig Druck aufweisen wird. Er kann den Fahrer darauf hinweisen, dass er durch einen Fahrstilwechsel noch die Möglichkeit hat, den Zeitpunkt hinauszuzögern, zu dem der Reifen endgültig platt ist.
Am besten setzt man ITOA zusätzlich zu vorhandenen APM-Tools ein. APM hat in erster Linie einen proaktiven Wert, ITOA dagegen wirkt prädiktiv (vorausschauend). Mehr dazu findet sich etwa bei [1].
Visualisierung und Alarmierung
Zurück zur künstlichen Intelligenz und ihrer Schlüsselrolle für erfolgreiches Performance-Monitoring. Als erstes Beispiel sollen zwei Alarme dienen, die jeder kennt. Das Monitoring zeichnet Daten über einen gewissen Zeitraum auf, um einen Mittelwert zu errechnen, um den sich die Werte normalerweise bewegen. Eine signifikante Abweichung vom Mittelwert löst einen Alarm aus.
Das kann sich für verschiedene Messungen wiederholen, und es wäre möglich, dass mehrere einzelne Alarme, wenn sie zusammen auftreten, noch einen weiteren Alarm auf einer anderen Ebene bewirken.
Mit Methoden aus dem Bereich der KI ist es hingegen möglich, mehrere Kurven gleichzeitig zu untersuchen und den Normzustand nicht mehr über einen einfachen Mittelwert oder ein Aufsummieren der einzelnen Messungen zu definieren, sondern viel mehr über das Verhalten mehrerer Kurven zueinander.
Das bedeutet in der Praxis beispielsweise, dass ein sprunghafter Anstieg der Prozessorauslastung nur dann als relevant beziehungsweise fernab der Norm zu werten ist, wenn keinerlei Aktivitäten der User oder Batch-Tasks den Ausschlag erklären. Statistische Methoden – insbesondere multivariate – lassen sich somit als Filter für die Alarmflut einsetzen, um weniger, dafür aber relevantere Alarme zu erhalten.
Auch bei der Visualisierung solcher Abweichungen von der Norm reicht der Mittelwert nicht immer aus. Beispielsweise in einem Szenario, in dem ein Prozess die User zunächst alle gleich schnell bedient (Abbildung 1, links) und dann einen Teil schneller, einen anderen langsamer (Abbildung 1, rechts). Hier ist der Mittelwert der Geschwindigkeit wenig aussagekräftig. Im schlechtesten Fall sieht die Kurve des Mittelwerts und dessen Standardabweichung vor und nach der Veränderung fast identisch aus (obere Kurve).
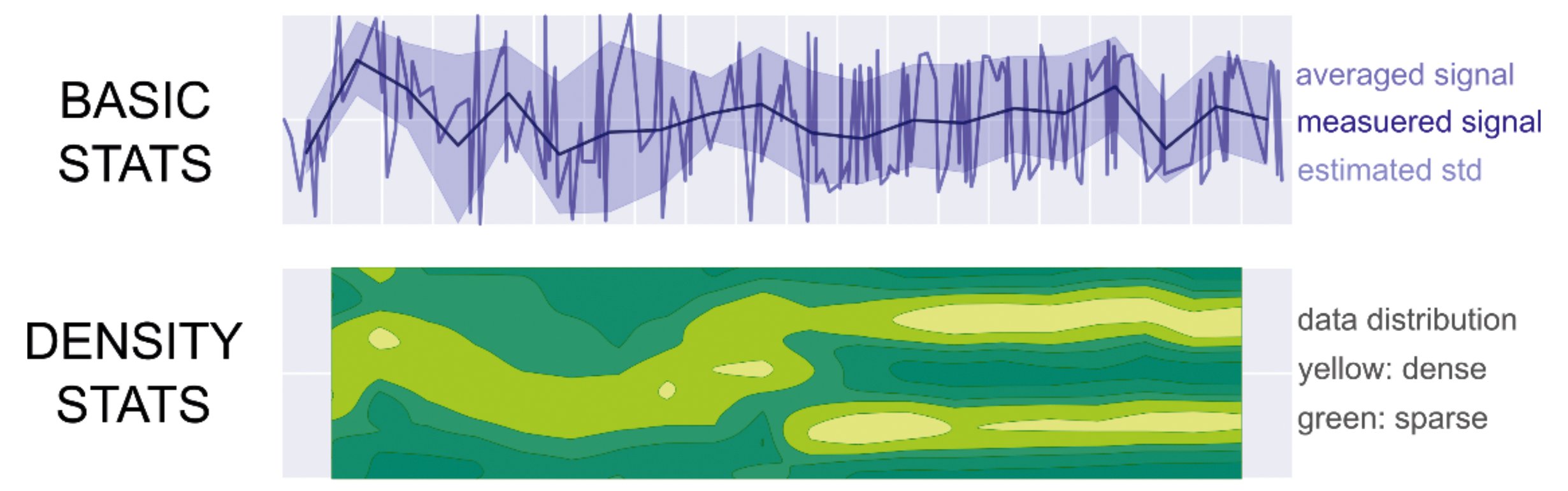
Abbildung 1: Der Mittelwert und die Standardabweichung (obere Kurve) lassen nicht erkennen, dass hier zwei verschiedene Geschwindigkeiten gleichzeitig auftreten (untere Grafik).
Eine Visualisierung hingegen, die die Wahrscheinlichkeitsdichte statt des Mittelwerts verwendet, macht den Split in die beiden Zustände nach der Veränderung nachvollziehbar (untere Kurve).
Anomaly Detection
Der Vorteil multivariater Methoden wird noch deutlicher im Bereich Anomaly Detection. Dabei geht es zum Beispiel darum, nach Bereichen zu suchen, die für die Analyse besonders interessant sind, und sie zu markieren. Wer die abnormale Funktion einer unternehmenskritischen Anwendung zu untersuchen hat, startet sehr wahrscheinlich mit etwas Vergleichbarem. Er wird sich mehrere Kurven und deren Verhältnis zueinander ansehen, um zu entscheiden, ob es sich um eine Abweichung von der Norm handelt.
Allerdings ist das menschliche Vermögen begrenzt, wenn es um die gleichzeitige Beurteilung von Kurven und deren Korrelationen geht. Ein Algorithmus, der auf Machine Learning basiert, kann hingegen mühelos Hunderte von Kurven miteinander ins Verhältnis setzen und kontrollieren, wie weit die momentane Beanspruchung vom gewohnten Verhalten abweicht.
Bekommt der Experte den Output eines solchen Algorithmus zusammen mit den eigentlichen Kurven präsentiert, lässt sich die Zeit für die Diagnose erheblich verkürzen. Betreffen derartige Berechnungen mehrere Teilbereiche des Systems, etwa unterschiedliche Server, dann ist schneller ersichtlich, welches Teilsystem am wahrscheinlichsten das Problem mit verursacht.
Eine Anomalie ist zunächst nur eine Abweichung von der Norm, sowohl in die positive als auch in die negative Richtung. Insbesondere ein gehäuftes Auftreten von Anomalien lässt sich als Marker für Änderungen im System auffassen. Abbildung 2 zeigt orange Markierungen. Je stärker die Farbe desto stärker die Abweichung vom Normalzustand.
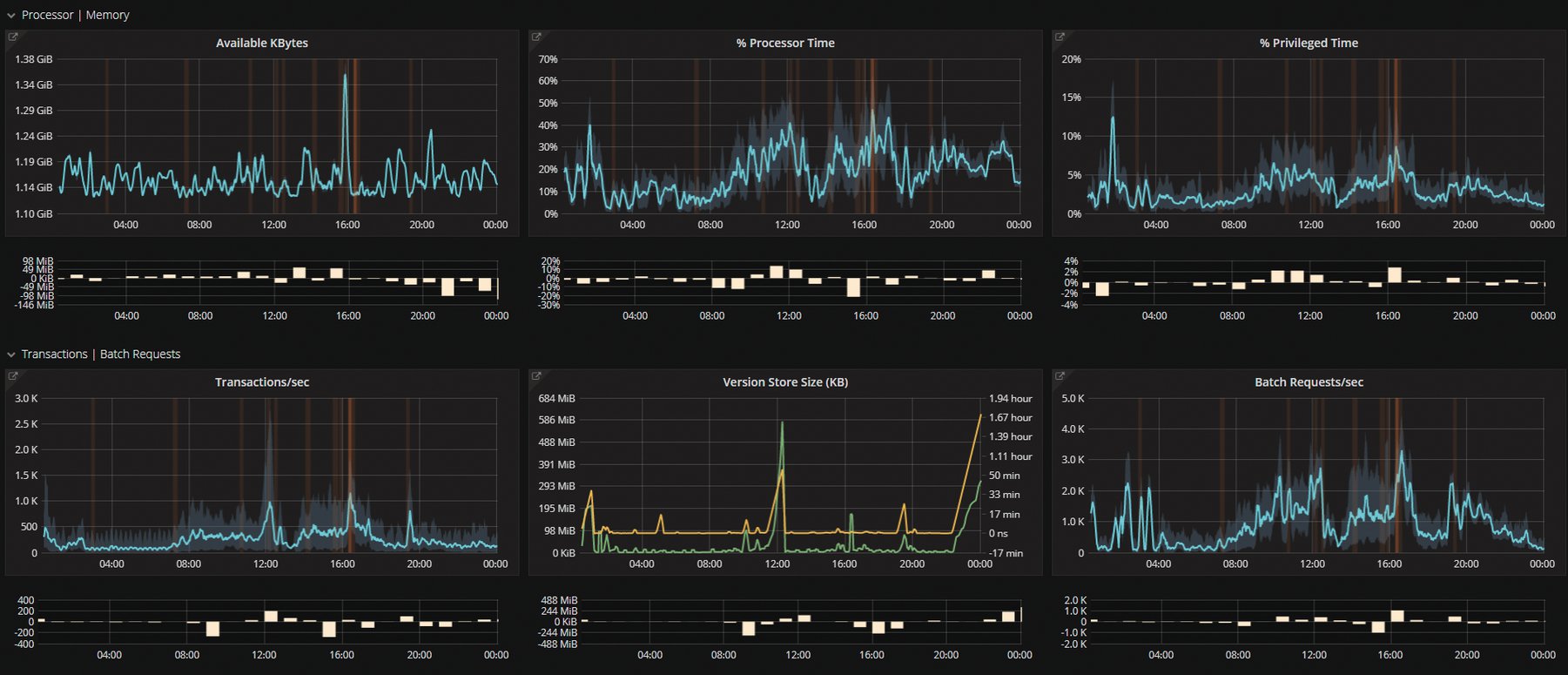
Abbildung 2: Normabweichungen werden hier farblich (orange) hervorgehoben.
Forecast
Häufige betreffen Kundenanfragen weder die Vergangenheit noch die Gegenwart, sondern die Zukunft. Wann ist der richtige Zeitpunkt für Investitionen, wie viel Speicherplatz wird gebraucht, mit welchem Wachstum ist zu rechnen? Bei unternehmenskritischen Applikationen ist es beispielsweise von großer Bedeutung, einen genauen Überblick über das Datenbankwachstum zu bekommen. Prognosen stehen hoch im Kurs.
Zeigen zu können, wie viel Speicherplatz sich durch Optimierungsmaßnahmen einsparen lässt, ist eine Sache, schon zu wissen, wie viel Speicherplatz wahrscheinlich freigegeben wird, noch bevor man mit den Optimierungsmaßnahmen begonnen hat, eine andere.
Ein Forecasting analysiert Daten aus der Vergangenheit. Interessant ist beispielsweise, ob sich eine Kurve zyklisch verhält, wächst oder fällt. Grundsätzlich gilt: Je mehr Daten zur Verfügung stehen, umso genauer lässt sich auch ihr künftiges Verhalten abschätzen. Dieses Wissen soll in die Planung einfließen.
Abbildung 3 zeigt die Screenshots einer solchen Implementierung. Ein Tortendiagramm macht es leicht, die am stärksten wachsenden Tabellen optisch zu identifizieren. Ein Balkendiagramm zeigt das Muster, mit dem die Datenbank über den gewählten Zeitraum gewachsen ist. Ein Singlestat Panel macht zusätzlich die gesamte Veränderung, die im gewählten Zeitraum aufgetreten ist, zugänglich.
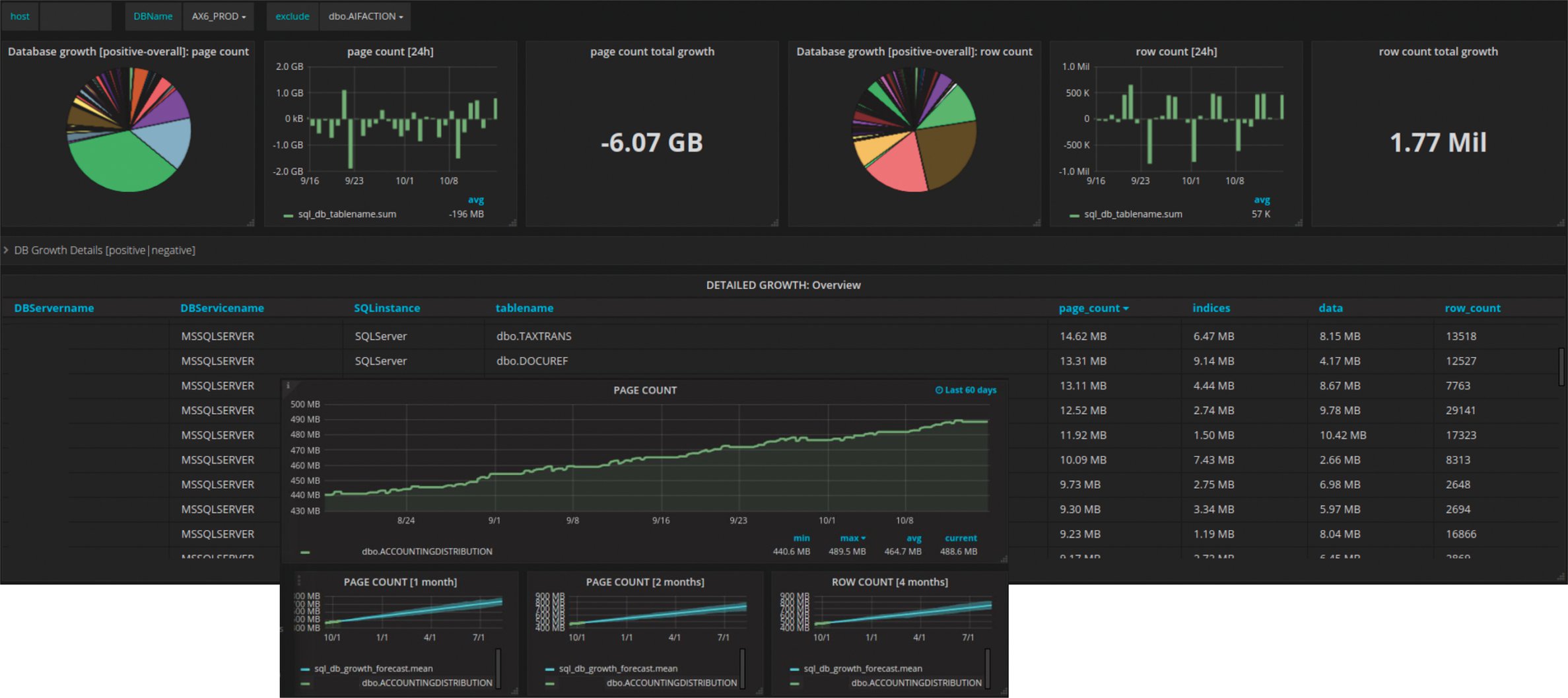
Abbildung 3: Verschiedene Diagrammtypen erleichtern die Vorausschau auf zu erwartende Entwicklungen.
Im Vordergrund hingegen werden basierend auf unterschiedlichen Zeiträumen der bereits vorhandenen Daten Prognosen für die nächsten Monate berechnet.
User Experience
Auch wenn die User Experience nicht wirklich zum Gebiet der KI gehört, so ist sie doch zusammen mit den Methoden der KI ein Schlüssel für das erfolgreiche Performance-Monitoring. Im Falle der Open-Source-Lösung Alyvix [2] lässt sich die Messung der User Experience etwa wie ein kleiner Roboter mit Stoppuhr vorstellen. Rund um die Uhr führt er definierte Schritte so aus, wie sie ein echter User zu diesem Zeitpunkt absolvieren würde.
Die Dauer jedes einzelnen Teilschritts misst die Software akkurat, so lässt er sich mit den zu anderen Zeiten erzielten Werten vergleichen. Die Ergebnisse kann der Analyst auf verschiedenen Ebenen (Abbildung 4) mit mehreren Genauigkeitsgraden einsehen, je nachdem, was er für die Analyse benötigt.
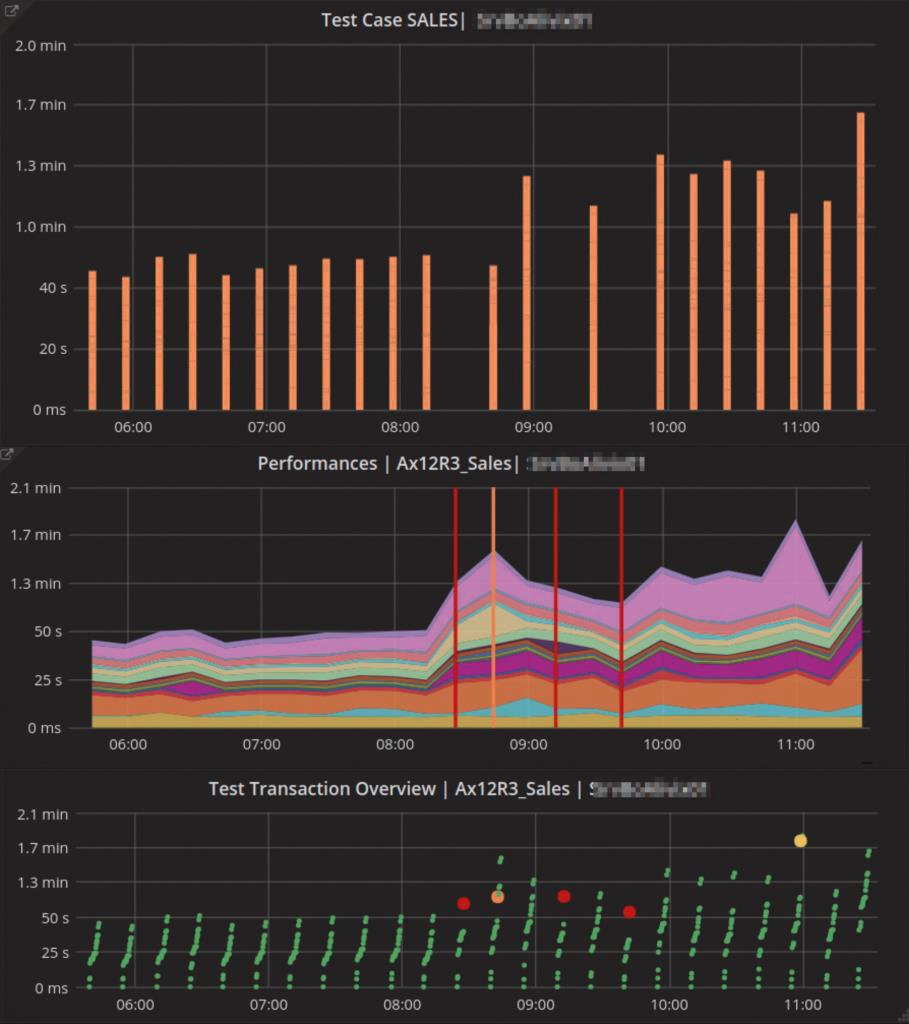
Abbildung 4: Messungen der User Experience.
Das oberste Panel zeichnet ein Balkendiagramm, das lediglich die Gesamtdauer eines Testlaufs als Balken und eventuelle Fehler als Auslassung anzeigt. Das mittlere Panel zeigt die Dauer verschiedener Teilschritte und deren Änderung über die Zeit. Im untersten Panel entspricht jeder Punkt einem ausgeführten Teilschritt und die Farbe des Punkts gibt gleichzeitig Auskunft, in welchem Status der jeweilige Teilschritt endete.
Diese Art des Visual Synthetic Monitoring ist zum Beispiel einsetzbar, um Fehlkonfigurationen in einem Produktivsystem frühzeitig zu identifizieren oder um eine Testumgebung mit einer Produktivumgebung zu vergleichen. So lässt sich unter anderem der Impact neuer Deployments auf die User Experience abschätzen.
Machine Learning und Deep Learning
Richtig interessant wird es, wenn es gelingt, Performance- und User-Experience-Daten miteinander zu analysieren. Im Machine-Learning-Kontext bedeutet das beispielsweise, dass alle verfügbaren User-Experience-Daten herangezogen werden, um die aktuelle Performance mit einem Label zu versehen. Wenn also mehrere Sonden die User Experience in einem gewissen Zeitraum als kritisch beurteilen, lässt sich dieser Bereich als Problemzone markieren.
Solche Label für Performance-Daten stehen sonst nur zur Verfügung, wenn ein Experte in zeitraubender Handarbeit entscheidet, welche Zeitabschnitte jeweils wie zu beurteilen waren.
Gleichzeitig bildet diese Art Label die Grundlage für jede Art einer überwachten Machine-Learning-Analyse. Denn wenn genügend gelabelte Daten gesammelt sind, ist es möglich, ein Modell zu trainieren, das aufgrund der Performance-Daten bereits das korrekte Label vorhersagt (in anderen Worten, den momentanen Zustand des Systems beurteilt).
Diese mathematische Beurteilung, die nicht auf Schwellenwerten, sondern auf der Erfahrung und der User Experience als Label basiert, kann einerseits Auskunft darüber geben, ob die vom Experten herangezogenen Metriken tatsächlich die größten Auswirkungen auf die User Experience haben. Andererseits kann sie dabei helfen, weitere relevante Metriken zu finden.
Das Beispiel in Abbildung 5 verdeutlicht, wie sich dieser Output in der Praxis nutzen lässt. Dabei überwacht das Performance-Monitoring mehrere Server zeitgleich. Für jeden einzelnen Server werden Performance-Daten entsprechend seiner Funktion aufgezeichnet. Die User Experience (unterer Teil der Grafik) dient als universelles Label für den gesamten Zeitraum. Das Ergebnis pro Server zeigt, welche Metriken für den jeweiligen Server am meisten Einfluss auf die User Experience hatten.
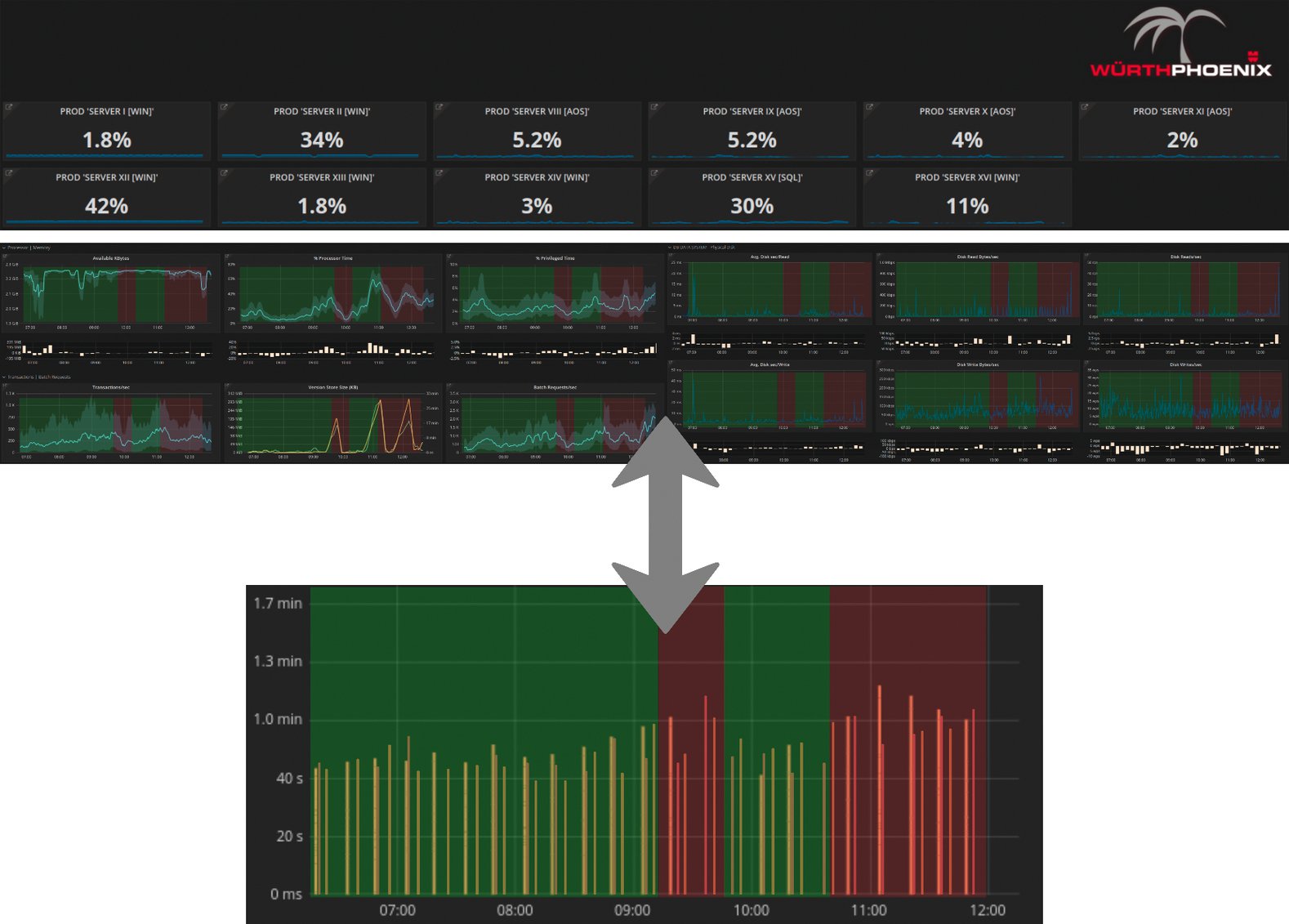
Abbildung 5: Performance-Daten stehen Daten aus der Messung der User Experience gegenüber.
Kommt dieses erste Ergebnis in einer weiteren Machin-Learning-Task mit Ensemble Setting zum Einsatz, lassen sich zusätzlich die am meisten für Änderungen der User Experience verantwortlichen Server identifizieren.
Fazit
Die Zeit für KI im Monitoring ist reif. Wichtig ist, bei der Auswahl der Methoden nicht wahllos irgendeinen Algorithmus auf Daten loszulassen, sondern dass der Analyst zielorientiert arbeitet, um mit kleinen Features die eine oder andere Frage mehr zu beantworten, die er mit klassischen Methoden nicht beantworten konnte. Wem das gelingt, der kann sich kurzfristig einen deutlichen Marktvorteil verschaffen und langfristig davon profitieren.
Für die Implementation von Machine-Learning-Algorithmen steht heutzutage eine Fülle von Open-Source-Lösungen zur Verfügung. Zusätzlich ist am besten eine gesunde Kombination aus Erfahrung, Marktkenntnis und Expertenwissen von Nutzen.
Infos
-
Blog von Herrn Alipour: https://www.ymor.com/resources/blog/apm-versus-itoa-the-difference)
-
Alyvix: http://www.alyvix.com





