
© Vadim Guzhva, 123RF
Das Dateisystem Lustre fliegt aus dem Kernel – gegen den Willen vieler Lustre-Entwickler und eventuell nur vorübergehend. Mit der Technologie für den Berkeley Packet Filter landet zudem eine interessante Option im Kernel 4.18, um Userspace-Code im Kernelspace laufen zu lassen.
Insgesamt haben die Kernelhacker die Aufräumarbeiten fortgesetzt, die mit dem Entfernen obsoleten Codes in Linux 4.17 begonnen hatte. Die Reduzierung sei nicht so drastisch wie in der letzten Kernelversion, aber dennoch bemerkbar, schreibt Torvalds in der Ankündigung des Release Candidate 1.
Ganz lassen die Sicherheitslücken Spectre und Meltdown die Entwickler allerdings noch nicht los, zumal nach den Spectre-Versionen 1 und 2 einige neue Schwachstellen aufgetaucht sind. Für die ersten beiden Versionen gibt es jetzt auch Patches für 32-Bit-ARM-Prozessoren, zudem warten Gegenmaßnahmen gegen Spectre 4.
Speculative Store Bypass Disable (SSDB) hielt bereits in Linux 4.17 Einzug, funktionierte dort aber nur mit Intel-CPUs. Die verantwortliche Lücke ermöglicht unter bestimmten Umständen das Auslesen eines Zeigers, bevor die CPU die Vorhersage verifiziert hat. In Linux 4.18 gibt es nun auch Patches für AMD- und ARM64-Prozessoren. Diese funktionieren aber nur im Zusammenspiel mit aktualisierten Versionen der jeweiligen Firmware.
Wesentlicher Schritt für den Netfilter-Ersatz
Viel Arbeit haben die Linux-Hacker laut LWN.net [1] in die Erweiterung BP-Filter für den Berkeley Packet Filter (BPF) gesteckt. Die soll das Filtern von Netzwerkpaketen beschleunigen und den bisherigen Firewall- und Paketfilter-Code langfristig ersetzen. Der wirkt dank der stetig steigenden Übertragungsraten inzwischen recht antiquiert.
BP-Filter hielt Anfang 2018 Einzug in den Kernel und legt die Grundlagen für ein beschleunigtes Filtersystem. Das aktuelle Patchset widmet sich der Interaktion mit dem Userspace. Das ist eine der Hürden, die Entwickler überwinden müssen, damit vorhandene Netfilter-Konfigurationen auch mit BP-Filter kooperieren.
Das Patchset rief aber Sicherheitsbedenken hervor, weil die mit einfachen Benutzerrechten erstellten Filterregeln im Kontext des Kernels laufen sollen. So wird es künftig möglich sein, dem Just-in-Time-Compiler von BP-Filter einfache IPtables-Regeln zu übergeben, die er automatisch in effiziente BPF-Programme konvertiert. Das aber erfordert die Interaktion zwischen Nutzer und Kernel.
Für die Konvertierungen haben die Entwickler daher den so genannten Usermode-Helfercode entworfen. Der Code ist in das normale Kernel-Subsystem integriert, wird dann “mit »objcopy«- und Makefile-Magie” in eine gewöhnliche Objektdatei konvertiert und mit dem Kernelmodul »bpfilter.ko« verlinkt.
Diesen Helfercode verwendet der Kernel, um im Userspace Code auszuführen. Er erzeugt einen neuen Userspace-Prozess, setzt die Prozess-ID als PID ein und generiert entsprechende Pipes, um mit dem neuen Prozess zu kommunizieren. Den Code selbst, zum Beispiel einen Paketfilter, verfrachtet der Kernel in eine »tmpfs«-Datei und führt ihn dort aus. Beim späteren Aufräumen schießt der Kernel den Helferprozess über dessen ID ab und schließt die Pipes.
Mehr als ein Paketfilter
BP-Filter steht noch am Anfang, das Modul in Linux 4.18 tut noch nicht viel. Die Entwickler um Maintainer David Miller wollen die eigentlichen Mechanismen erst einbauen, wenn der Helfercode einen Zyklus lang stabilisiert wurde. Langfristig dürfte diese neue Möglichkeit, vom Kernel kontrollierten Code im Userspace laufen zu lassen, recht umfassend zum Einsatz kommen – nicht nur für Paketfilter. Miller kündigte das Patch dann auch mit den ironischen Worten an: “Lasst den Wahnsinn beginnen” [2].
Eine weitere Neuerung für den Berkeley Packet Filter: Den JIT-Compiler gibt es nun auch für 32-Bit-Systeme (x86). Mit dem »AF_XDP«-Subsystem soll es BPF-Anwendungen künftig gelingen, im Benutzerkontext den Zero-Copy-Mechanismus des Netzwerkstacks zu verwenden, der ebenfalls seit Linux 4.18 mit an Bord ist. Das einfache Setzen eines Zeigers auf den Code im Puffer macht ein aufwändiges Kopieren überflüssig.
Eine ebenfalls neue Perspektive für BPF-Programme ergibt sich aus der Möglichkeit, an einem Socket den Aufruf »sendmsg()« zu verwenden. Damit schreiben die Programme beispielsweise IP-Adressen in ausgehenden Netzwerkpaketen um, wie es etwa in der Network Address Translation (NAT) geschieht.
Keine Lust mehr
Das verteilte Dateisystem Lustre ist aus dem Staging-Bereich des Kernels verschwunden. Dort harrte es seit mehreren Jahren der offiziellen Aufnahme in den Linux-Kernel. Da die Entwickler Lustre allerdings in einem Tree außerhalb des Kernels pflegten und Änderungen nur sporadisch in den Kerneltree integrierten, zogen sie den Groll des Kernelhackers Greg Kroah-Hartman auf sich. Dieser mahnte zunächst, den Lustre-Code im Staging-Bereich auf den aktuellen Stand zu bringen, um ihn dann kurzerhand aus Staging zu entfernen.
Eine Rückkehr in den Kernel bliebe den Lustre-Entwicklern aber nicht generell verbaut, sollten sie sich noch eines anderen besinnen. Sie könnten aktualisierten Code wieder einreichen, müssten ihn dann aber auch in den offiziellen Linux-Quellen weiterpflegen, schreibt Kroah-Hartman (Abbildung 1, [3]).

Abbildung 1: Greg Kroah-Hartman (hier auf der Linuxcon Europe 2016) wirft Lustre aus dem Staging-Bereich des Kernels.
Namespaces automounten
Für automatische Mounts im Containerumfeld ist die Möglichkeit wichtig, dass unprivilegierte Benutzer Dateisysteme einbinden dürfen. Das geht jedoch mit einem gewissen Risiko einher, falls das mit Rootrechten eingehängte Dateisystem manipuliert ist. Über diese Hintertür könnten sich Angreifer Zugriff auf weitere Kernelfunktionen verschaffen und fehlerhafte Dateisysteme womöglich Systemabstürze hervorrufen.
Auch deshalb sehen Entwickler wie Ted T’so das automatische Einbinden von Dateisystemen äußerst kritisch. Die Verantwortung für ein sauberes Dateisystem liege aber nicht bei den Dateisystem-Entwicklern, argumentiert Dave Chinner. In diesem Bereich werde es immer Fehler geben [4].
Möglichst viele der Bedenken wollen die Entwickler um Eric Biederman mit ihren jetzt eingereichten Patches zerstreuen. Ab Linux 4.18 dürfen zumindest Benutzer, die Rootrechte in ihrem Namensraum besitzen, Dateisysteme einbinden. Die zugehörigen Geräteknotenpunkte (Device Nodes) im nicht-privilegierten Namespace des Benutzers bleiben dem Kernel dabei verborgen.
Zugleich gilt die neue Regel nicht für alle Dateisysteme, sondern nur für solche, die die Kernelentwickler explizit dafür vorsehen. Sie lassen sich über den Fuse-Mechanismus im Userspace einhängen [5]. Diese bewährte Schnittstelle zwischen dem Mountsystem des Kernels und dem Benutzer (Abbildung 2) kommt mit so ziemlich allen Dateisystemen zurecht, die auch der Linux-Kernel kennt, gilt als robust und hält auch nach dem neuen Verfahren fehlerhafte Dateisysteme vom Kernel fern.
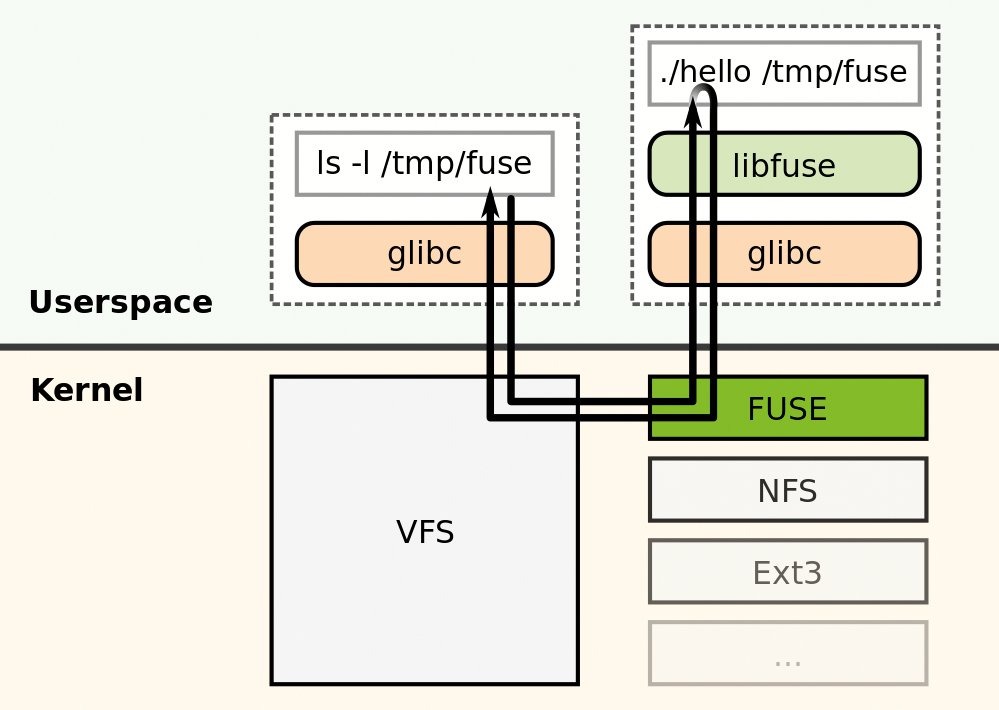
Abbildung 2: Fuse steht für Filesystem in Userspace und ist ein Kernelmodul. Quelle: Fuse, Sven, CC-BY-SA 3.0
Aus Sicht von Ted T’so stellt aber auch Fuse ein Sicherheitsrisiko dar. Biederman hält dagegen: Diese Lösung sei immer noch die sicherste, wenn es darum gehe, USB-Sticks oder Container automatisch in den Userspace einzubinden.
XFS modernisiert
Seit mehreren Kernelversionen schrauben die Kerntechniker am Fundament des Dateisystems XFS. Sie wollen die Grundlage für moderne Funktionen schaffen, die Btr-FS oder ZFS längst mitbringen. Vor diesem Hintergrund haben die XFS-Entwickler erste für den Anwender sichtbare Neuerungen umgesetzt.
Nutzer dürfen XFS-Dateisysteme ab Linux 4.18 auch im laufenden Betrieb umbenennen, wenn diese online sind. Zudem kann XFS Daten und Swapdateien künftig auch direkt per »fallocate()« manipulieren, auch funktioniert das Prüfen von Metadaten besser. Damit einher gehen erste Arbeiten, die eine Reparatur des Dateisystems im Onlinebetrieb ermöglichen.
Auch den Growfs-Code, der die Größe des Dateisystems verändert, haben die Entwickler überholt. Das soll den Weg für den Support von Subvolumes ebnen, wie ihn Btr-FS und ZFS mitbringen. Bis beide Funktionen fertig sind, werde es aber noch dauern, warnt Maintainer Derrick Wong [6].
Btr-FS kopiert nun Dateien zwischen Volumes deutlich schneller, vor allem bei großen Verzeichnissen mit Millionen Einträgen. Der neu eingeführte Code verhindert unnötige Zuweisungen, zugleich gelingt das Überprüfen bereits entfernter Inhalte besser. Ferner dürfen jetzt auch nicht-privilegierte Benutzer Subvolumes auflisten, allerdings steht dem Code noch ein Sicherheitscheck bevor.
Zu den Verbesserungen an dem auf Flashspeicher optimierten Dateisystem F2FS gehört die neue Option »fsync_mode=nobarrier«, die Zugriffe auf den Cache reduziert. Außerdem haben die Entwickler »fstrim« und »discard« überarbeitet.
Für die Grafikchips von Intel wurde am HDCP-Support (High-bandwidth Digital Content Protection) gefeilt, der bereits seit Linux 4.17 existiert. Auch erster Code für die übernächsten Generation der Intel-Chips namens Icelake ist im Kernel gelandet. Daneben gibt es einen neuen Treiber namens V3D DRM für den Videocore-V-Chip von Broadcom. Der soll in den nächsten Versionen des Raspberry Pi seine Arbeit aufnehmen.
Zumindest rudimentär unterstützt der freie Nouveau-Treiber nun den GV100-Chipsatz von Nvidia (alias Volta). Der zielt in erster Linie auf einige Highend-Quadro-Karten und den Tesla V100 mit Fokus auf Machine Learning ab. Der Linux-Kernel setzt ab sofort automatisch die richtige Auflösung, eine Hardwarebeschleunigung fehlt indes noch. Die kann erst kommen, wenn Nvidia die zugehörige Firmware freigibt.
Für die Vega-20-Grafikprozessoren von AMD gibt es ersten Code. Auch für die Grafikeinheit Vega M, die auf der aktuellen Polaris-Generation basiert und in einigen Intel-CPUs steckt, sind Codebeiträge eingeflossen, die aber noch nicht alle Funktionen abdecken.
Weitere Arbeit haben die Entwickler in den Support für Leistungsprofile und in Verbesserungen an den Taktraten aktueller Grafikchips von AMD investiert. Der in Linux 4.17 ergänzte AMDKFD-Treiber, der die Open-CL- beziehungsweise Rocm-Fähigkeiten von AMDs Grafikkarten nutzt, lässt sich jetzt mit den aktuellen Vega-Karten verwenden. Der Linux-Kernel liest zudem die Temperatur älterer Grafikeinheiten der Bristol-Ridge- und Stoney-Ridge-Reihe aus.
NSA-Algorithmen
Umstritten sind die Verschlüsselungsalgorithmen Speck und Simon vor allem deshalb, weil die NSA sie entwickelt hat. Mit Details zu den Algorithmen hält sich der US-Geheimdienst zurück. Die NSA bewirbt Speck und Simon als effiziente Verschlüsselungsalternativen, die sich vor allem für den Einsatz auf leistungsschwachen IoT-Geräten eignen.
Während Simon auf Hardware-Chips laufen soll, deckt Speck die Software-Seite ab. Speck128 und Speck256 sind bereits im Kryptostack von Linux 4.17 gelandet. Jetzt hat Ted T’so die beiden Speck-Versionen für den Einsatz auf etlichen Dateisystemen freigegeben, darunter etwa Ext 4 und F2FS. Die Verschlüsselungsalgorithmen sollen aber nur auf den schwächsten Android-Smartphones zum Zuge kommen, denen eine andere Verschlüsselung fehlt.
Dies und weitere Änderungen lassen sich in den Vorabversionen von Linux 4.18 testen. Der Quellcode dafür wartet wie üblich auf Kernel.org [7]. Folgt die Entwicklung der üblichen sechswöchigen Testphase, erscheint die finale Version von Linux 4.18 Ende Juli.
Infos
-
Berkeley Packet Filter: https://lwn.net/Articles/755919/
-
Miller gibt Patch frei: https://lkml.org/lkml/2018/5/23/748
-
Kroah-Hartman zu Lustre: https://lkml.org/lkml/2018/6/1/164
-
Chinner über Dateisystem-Bugs: https://lkml.org/lkml/2018/5/23/1064
-
Chinner über Fuse: https://lkml.org/lkml/2018/5/23/1123
-
Derrick Wong zu XFS: http://lkml.iu.edu/hypermail/linux/kernel/1806.0/03434.html
-
Kernel.org: https://www.kernel.org






